

Одна из задач, которую надо решить онлайновой службе, — превратить как можно больше посетителей в пользователей. Решение это тесно связано с понятием «барьер освоения». Любое приложение применительно к любому пользователю (а пока что только посетителю) имеет свой барьер освоения. Не преодолевшие этот барьер так и останутся всего лишь посетителями, причем одноразовыми.
Посетитель vs. пользователь
Почему уходит посетитель? Потому что ему либо действительно не нужно это приложение (сайт), либо он не смог (не захотел) разобраться в нем. Первый случай оставим, а вторым займемся вплотную.
Практически все причины неудачного освоения приложений — на совести разработчиков: посетитель всегда прав, даже (и особенно) когда его нет. Уровень эргономики и дизайна приложения обычно является следствием несколько более общих факторов. Приложение имеет не просто определенный набор функций, но некоторую предметную область, определяемую назначением и областью применения этого приложения. Предметная область применительно к приложению имеет несколько аспектов:
- то, как ее представляет пользователь;
- то, как ее представляет разработчик;
- то, как она отражена в схеме базы данных (если таковая есть);
- то, как она отражена в пользовательском интерфейсе.
Высота барьера освоения зависит в первую очередь от того, насколько естественно выражена в пользовательском интерфейсе и в поведении приложения модель предметной области с точки зрения пользователя, а также насколько они традиционны и узнаваемы. Квалификация пользователей и степень адекватности им представления предметной области могут существенно различаться. Поэтому приложения часто предоставляют на выбор несколько режимов работы: для начинающих, для продвинутых пользователей и т.д.
Важно, чтобы пользователь и приложение говорили на одном языке. Каждый не раз сталкивался с ситуацией, когда приложение странно ведет себя и выдает невнятные сообщения, а пользователь выполняет непонятные действия — просто они говорят на разных языках.
Насколько естественен естественный язык
Естественный язык (ЕЯ) в данном контексте — способ общения человека с компьютером. Человек владеет своим родным языком куда лучше, чем искусственными — будь то языки программирования и разметки, или языки визуального взаимодействия, тот же язык кликов и окошек. Нам не приходится, зайдя в обычный магазин, рыться в каталоге товаров, мы просто спрашиваем у продавца-консультанта «а где...?» или «а у вас есть...?»
Кстати, и человек не всегда может помочь. Здесь-то и нужен тот, кто вмещал бы и довольно большой объем знаний, и мог бы ответить на произвольные вопросы к ним. В супермаркетах счет на товары идет на десятки тысяч, ни один консультант не в состоянии разобраться во всех. Выходом является симбиоз базы данных и системы понимания вопросов пользователя — естественно-языковой интерфейс к базе данных.
Доступ к данным на естественном языке — тема, активно разрабатываемая с 60-х годов в русле искусственного интеллекта, — переживала вместе с ним все его взлеты и падения. Эта тема неразрывно связана с проблемой понимания естественного языка как такового. В целом можно сказать, что объем усилий, затраченных на решение этой проблемы научным сообществом, несопоставим с результатом. Данная область науки — ЕЯ-процессинг, находясь на стыке лингвистики и информатики, оказалась в целом не готова к появлению Сети, «неожиданно» породившей и массу реальных задач для решения, и рынок, и потребность в доступе к данным на естественном языке. Основной причиной такого положения можно считать неадекватность изначально выбранных средств: взятый из задачи машинного перевода синтаксический фронтальный анализ не был способен решить задачу понимания, в том числе задачу понимания поисковых запросов. Синтаксическая норма и без того понятие условное, — не слишком естественный способ для формулировки поискового запроса к источнику данных. В разговорном же жанре синтаксически правильное предложение — скорее исключение, чем норма.
Заблуждением было бы и прямое перенесение коммуникативных особенностей общения между людьми на человеко-машинное общение. То, что естественно в одном случае, неестественно в другом, и наоборот. Например, диалоговое общение человека и машины на ЕЯ до сих пор является малопригодным для практического применения: разговор с «тупой» системой, как правило, удовольствия мало кому доставляет, а создание по-настоящему умных диалоговых систем требует огромных затрат. Обращение человека к машине на ЕЯ — особый, не до конца изученный жанр языка. Практика общения с ЕЯ-системами показывает, что человек, как неизбежно более гибкое существо, нежели машина, в условиях сильного мотивирования «притирается» к ситуации и начинает говорить, набирать или писать так, чтобы система все-таки заработала, а не так, как он говорил бы с человеком. А в отсутствии мотивирования просто теряет интерес к системе.
В результате Internet-революции ярлык «естественно-языковой» приобрел новый смысл. Произошло расслоение: с одной стороны, под ЕЯ подразумевают очень большую свободу выражения, сопоставимую с той, что происходит при общении между людьми. Это традиционно для области искусственного интеллекта, особенно для его отражения в СМИ и научной фантастике — вспомним HAL-9000 Артура Кларка. С другой стороны, чтобы найти информацию в Сети, пользователь сейчас использует набор ключевых слов (как правило, не более двух), объединенных в один запрос. Возможности уточнить тут же, в запросе, тематику поиска, нет, поскольку сами поисковые системы, как правило, не интересуются предметной областью запросов и ресурсов. Между тем многие глобальные поисковые машины и называют это запросом на естественном языке. Локальные поисковые машины, например, по каталогам товаров, работают по той же схеме, что и глобальные, — ищут слова, подстроки или документы, но не объекты с заданными свойствами, хотя задача пользователя состоит именно в этом.
Даже в самых посещаемых Internet-магазинах поиск, как правило, заключается в нахождении в текстовых полях базы данных подстрок или слов, которые заданы в поисковом запросе. Курьез: потенциальный покупатель ищет товар с некими свойствами, а находит слова или подстроки: в ныне уже покойном электронном магазине www.xxl.ru на запрос «вино» в результат попадал и «балык свиной». Иногда пользователю вместо товара предлагают просто ссылку на страницу, подменяя задачу поиска: так, в одном известном Internet-магазине при помощи еще более известного движка поиска в ответ на запрос «футболки» выдаются ссылки типа: Футболка (Размер: 14 кБ, дата последнего обновления: 15 мая 2001 г.).
ЕЯ: спрос и предложение
Итак, с одной стороны — большие ожидания, с другой — подмена понятия. Реальное же состояние дел где-то посередине. До HAL еще далеко, но при достаточном ограничении предметной области поговорить с машиной уже можно. Основная сложность состоит в том, что совместить грамматику языка с его семантикой, и далее — с прагматикой конкретной области, довольно трудно: язык чрезвычайно многозначен, на вычислительном уровне это приводит к комбинаторному взрыву. Если грамматику языка формально описать можно один раз, а синтаксические анализаторы сами по себе работают удовлетворительно, то увязка с «семантическим крылом» лингвистической теории сильно зависит от задачи и в общем случае проделывается каждый раз заново. Выходом является отказ от «синтаксического крыла» теории, и концентрация на предметной области и ее прямом выражении в языковых конструкциях.
Интеграция с голосом пока в том же половинчатом состоянии: само по себе распознавание голоса работает уже с удовлетворительным качеством, но качественных решений, позволяющих интегрировать все уровни понимания речи, как это, по-видимому, и происходит у человека, тоже пока не видно.
Между тем обращение на ЕЯ к источникам данных выглядит очень привлекательным. Преимущества такого способа достаточно очевидны:
- минимальный барьер освоения: пользователь просто вводит запрос в поле ввода или проговаривает его в микрофон;
- задача понимания информационной потребности практически целиком возлагается на ЕЯ-систему;
- путь до нужных данных удается сократить до одного шага;
- пользователь сосредотачивается на том, что ему надо найти, а не на том, как это сделать.
Все эти преимущества подразумевают некоторый идеальный случай, когда система понимания настолько интеллектуальна, что позволяет понимать не только адекватные для базы данных, предметной области и жанра ЕЯ-запросы, но и надежно распознавать случаи нерелевантных запросов. Важным критерием является соотношение цена/эффект, которое помогает определить, применять ли традиционный или ЕЯ-интерфейс.
Цена же определяется несколькими параметрами: время построения ЕЯ-интерфейса, необходимый уровень квалификации его конструктора, усилия по его сопровождению и по интеграции в другие приложения.
Как понимать
Подходов к решению задачи понимания ЕЯ-запросов несколько. Лобовой и самый трудный — через синтаксические конструкции. Подлежащее, сказуемое, прямое дополнение и т.п. — из них строится синтаксическое представление запроса, используя морфологические характеристики (часть речи, род, падеж, лицо и т.д.). Это представление ничего не говорит о смысле запроса.
Следующий слой — семантика. Он уже гораздо ближе к смыслу запроса. В нем используется синтаксическая информация из предыдущего слоя, а также информация из семантических словарей. Каждое слово в словаре имеет характеристики, позволяющие определять смысловые отношения между ним и другими словами, точнее, их значениями. Например, глагол «продавать» может иметь семантические связи с тем, кто продает, что продает, кому, за сколько, когда и т.д. Значение слова «компьютер» имеет смысловые отношения с множеством других слов и их значений; скажем, компьютер может быть товаром, может быть инструментом (это отношения типа «общее-частное»), может быть куплен, продан, собран, загружен, «подвешен». Полное описание связей между смыслами слов (а одно слово часто имеет несколько смыслов) образует тезаурус, представляющий собой большую сеть со словами и их смыслами в качестве узлов.
С помощью таких тезаурусов выполняется построение семантического представления запроса. Основная задача при этом — отсечь ненужные смыслы, постараться выделить с помощью синтаксических связей достоверные семантические конструкции. Эту работу наш мозг выполняет автоматически, и мы даже не задумываемся о многообразии смыслов слов, которые слышим и читаем. В плане вычислительных ресурсов компьютера эта работа оказывается очень емкой. В больших предложениях, особенно с сильно многозначными словами, это часто приводит к комбинаторному взрыву — перебор множества смыслов и связей между ними, а также многозначность синтаксических конструкций (одному и тому же предложению может быть сопоставлено несколько синтаксических представлений) занимает неприемлемо большое время.
Это лишь одна проблема, стоящая на пути понимания ЕЯ-запросов в традиционной синтаксически-ориентированной парадигме. Вторая сложность — типичные ЕЯ-запросы не укладываются в прокрустово ложе правильных синтаксических конструкций. На это влияют вольное словоизменение и словообразование в виде неологизмов сетевой общественности, большой процент имен собственных и сокращений, игнорирование правил пунктуации — короче, от естественного языка во всем его многообразии иногда остается лишь лексика, причудливым образом исковерканная. И, наконец, необходимые в этом подходе семантические словари — очень трудоемкая составляющая, для многих предметных областей они просто отсутствуют, а их разработка требует чрезвычайно высокой квалификации.
Еще один подход к анализу ЕЯ-запросов основан на шаблонах. Он появился, пожалуй, самым первым, и с точки зрения программной реализации наиболее прост. Суть его в том, что возможные запросы покрываются набором шаблонов-конструкций, позволяющих отождествляться с запросом и выдавать в результате предопределенные конструкции. Например, запросы типа «телефоны Siemens» можно покрыть шаблоном («Телефоны»|«Аппараты»|«Модели», ПРОИЗВОДИТЕЛЬ) где ПРОИЗВОДИТЕЛЬ — название любой фирмы-производителя, которое может быть задано аналогичным шаблоном, скажем, («Alcatel»|«Benefon»|«Siemens»|...). Основной недостаток такого подхода заключается в необходимости предусмотреть все возможные способы выражений на естественном языке, т.е. исчислить грамматику. Но, увы, современный Internet-язык совсем не похож на литературный, и поисковые запросы синтаксическими шаблонами в чистом виде покрыть довольно трудно. Если же основываться на семантической грамматике, придется для каждой новой предметной области писать шаблоны заново.
Наверное, было бы странным, если бы не существовало обходного пути, позволяющего решить задачу минимальной кровью, где-то сократив путь, где-то скомбинировав преимущества нескольких подходов. В середине 70-х в Новосибирском Академгородке лаборатория искусственного интеллекта выполняла разработки по той же тематике — автоматическое понимание естественно-языковых запросов к информационным системам. Набросали макет системы, состоящий из 25 правил анализа запросов. Интересно было уже то, что система, почти без всяких лингвистических знаний, больших семантических и морфологических словарей, решала поставленную задачу — понимала ЕЯ-запросы в узкой предметной области. Основной принцип, выведенный при решении этой задачи в лаборатории под руководством А.С. Нариньяни, был таков: использовать по минимуму синтаксическую информацию, и, наоборот, по максимуму всю доступную семантико-прагматическую информацию (о предметной области и ее отношению к лексике запросов), собирая смысл запроса «снизу-вверх», из элементарных смыслов лексем, по определенным правилам.
Вкратце, система работала так: словам сопоставлялись типизированные семантические компоненты, сейчас это принято называть объектами. Компоненты не имели отношения к грамматике языка; никаких существительных и причастий среди типологии компонентов не было, а были исключительно прагматические образования, позволяющие решать вполне конкретную задачу. Например, слово «цена» сопоставлялось компоненту «Атрибут» с ориентацией на конкретное поле базы данных с ценой товара (ориентация — одно из ключевых понятий этого подхода); «больше» — компонент «Отношение» с указанием имени отношения («>»); «не» — «Отрицание» и т.д. Помимо слов заносились устойчивые словосочетания, «словокомплексы». Каждый словокомплекс мог также быть объектом тех же классов (компонентов), что и обычные слова.
Этот подход отличается прагматичностью в анализе запросов. Дело в том, что запросы, выраженные совершенно по-разному с точки зрения семантики (не говоря уже о синтаксисе), выражают одну и ту же потребность пользователя — получение некоторой информации. Запросы вида «выдай мне...», «покажи...», «хочу...», «все...», «какие...» говорят об одном и том же — системе надо выдать пользователю некую информацию об объектах поиска. В запросе может говориться о том, какими свойствами эти объекты должны удовлетворять: «мощные пылесосы», «MP3-плейеры подешевле», «телефон с виброзвонком не дороже 150» и т.д. Таким образом, именно эта информация важна для понимания запроса, а некоторая часть слов — балласт, сбрасываемый на начальной стадии анализа, что повышает эффективность процесса понимания.
Данный подход резко снизил время создания ЕЯ-интерфейсов и уменьшил требования на уровень квалификации создателей и настройщиков ЕЯ-интерфейсов, исключив из оборота лингвистические знания. Ведь словарь, который надо наполнить для конкретного ЕЯ-интерфейса, состоит обычно из нескольких сотен словарных статей и не претендует на полноту и законченность, как тезаурус, а делается исключительно под конкретный ЕЯ-интерфейс. В среднем на создание работающего (но не полного) ЕЯ-интерфейса уходит два-три человеко-дня. Во-вторых, этот подход, не основываясь на синтаксисе конкретного языка, является нейтральным по отношению к выбору естественного языка — например, запросы на русском и английском одинаково хорошо понимаются одними и теми же правилами анализа. И, наконец, правила анализа построены таким образом, что позволяют выявить смысл запроса, с точки зрения грамматики языка совершенно невозможного.
Концепция естественного поиска
Как можно расшифровать ярлык «естественный поиск»? Обратите внимание, в нем нет слова «языковой», что было бы логично. Возможность понимания естественно-языковых запросов — лишь средство, чтобы пользователю было удобно, чтобы он чувствовал себя хозяином контекста.
В Сети можно обнаружить множество удобных поисковых служб. В основном это локальный поиск в множествах объектов, которые поддаются формальному описанию. Поиск заключается в задании параметров поиска — ограничениями на значения свойств объектов заполняется форма, дальше — кнопка Submit, и — результат. Итак, основная задача, которую может решать пользователь с помощью приложения естественного поиска — выбор объектов из различных множеств по значениям их атрибутов. Характерный пример — выбор мобильного телефона: ведь моделей более 200, а параметров, потенциально влияющих на выбор — около 50.
Когда набор параметров велик, форма с множеством элементов управления может занять целый экран. Это обычно приводит к тому, что пользователем воспринимается лишь небольшая часть информации, которая содержится в форме. Традиционным выходом, концентрирующим внимание, является разбиение большой формы на несколько и объединение их в «мастер» (wizard). Тогда на каждом шаге внимание пользователя целиком приковывается к текущему экрану.
Но и этот способ в чистом виде уязвим для критики. Попытки задать набор атрибутов, который был бы достаточен для нахождения объектов из исходного множества и в то же время не загромождал интерфейс пользователя, подобны попыткам проплыть между Сциллой и Харибдой. Многие пользователи «сами с усами» и охотно пропустили бы многие шаги в подобных «мастерах». К тому же часто последующие шаги не видны, и пользователь не знает, что ему придется делать дальше.
Включение сюда одного сквозного поля ЕЯ-запроса добавляет естественности. Пользователь теперь может не только видеть, что к текущему шагу уже задано и выбрано, но и корректировать на каждом шаге предыдущий выбор довольно простым способом — редактируя это одно текстовое поле. Конечно, обойтись можно и им одним, но наивных пользователей одинокое пустое поле ввода часто обескураживает: а что и как можно спросить? В условиях, когда пользователь слабо представляет себе предметную область, все-таки необходим гид.
Имеет смысл показывать на каждом шаге, сколько объектов удовлетворяют уже заданным условиям, а там, где это уместно — показывать сами объекты. Какой смысл продолжать увлекательное путешествие по «мастеру», если выбор уже сузился до одного или даже нуля объектов?
Поиск и выбор всегда итерационны. Это подразумевает требование на облегчение переходов от запроса к запросу, сокращение издержек на такие переходы. Одним из путей облегчения труда пользователей является вывод «информационного окружения» объектов — не только значений свойств объектов, но и других объектов и множеств, ближайших к объектам выдаваемым. Например, при выдаче товара можно давать ссылку на список товаров данного производителя, а также на список товаров той же ценовой группы. Подобных принципов может быть множество, и думаю, читатель добавит без труда еще несколько, пользуясь своим опытом разработки, использования или посещения приложений.
Естественно-языковая паутина
Но вернемся к естественному языку. ЕЯ-интерфейсы, если вдуматься, заполонили Web до краев, но никто этого не замечает. Речь идет о самых обычных гиперссылках, не зря многие современные поисковые системы вслед за Google используют их текст при оценке релевантности результата поиска. Текст гиперссылок можно считать запросом на естественном языке, а то, что выдается при переходе по гиперссылке — это результат такого запроса. Формальным языком здесь выступает URL, но сейчас Web-мастерам и Web-программистам приходится самим соотносить одно с другим.
Автоматически это можно сделать с помощью настоящих ЕЯ-интерфейсов. Предположим, получив по своему запросу список сотовых телефонов, пользователь решил детально рассмотреть характеристики одного из них. Было бы удобно, если бы он мог сравнить этот телефон с другими, причем выбор для сравнения зависит от характеристик данного. Тогда рядом с выводимыми весом, размерами, производителем, ценой и т.д. надо выводить ссылки («телефоны с весом 100-120», «телефоны тоньше 20 мм», «телефоны Motorola», «цена 70-100»), предугадывая возможный набор желаемых характеристик моделей. Причем можно действовать не только ссылками, но и диалоговыми окнами (check box) и списками (list box), позволяя выбирать несколько таких предустановленных в текущем контексте условий и нажимать на Submit один раз. Ну, и самое интересное: текст на ссылках и в диалоговых окнах — просто входная информация для ЕЯ-интерфейса, нет нужды программировать адреса ссылок типа page.asp?attr1=val1&attr2=val2. Вот пример ссылки нового типа — NLRL (Nature Language Resource Locator):
inbase.artint.ru/nl/phones.asp?qquery=Сравнить Ericsson R320s и Motorola T2288
Текст после «qquery=» затем будет выведен в поле ввода на странице, которая откроется по этой ссылке или по Submit.
Это всего лишь возможные технические решения. Не будем углубляться в детали — важнее понять потенциал использования естественного языка как основы для построения приложений естественного поиска. Прежде всего, сокращаются усилия программистов по созданию и настройке таких приложений. Ведь настройка подобной информационной среды — забота маркетолога, а уж родным языком маркетолог должен владеть получше, чем Бейсиком или Перлом. Кстати, так можно осмысленно и ненавязчиво сопроводить пользователя до покупки, наиболее выгодной данному Internet-магазину.
Следующее не менее важное следствие — стирание границ между поиском и навигацией. Ведь гиперссылку можно считать за фиксированный поисковый запрос, а поле ввода запроса представить как поле редактирования ссылки. Конечно, такое слияние этих двух вещей не может быть полным и не претендует на универсальность: их природа все равно различна. Но технологии понимания естественного языка здесь выступают естественным связующим звеном между пользовательским Web-интерфейсом и источниками данных.
Напиши себе портал
Если в основе Web-службы лежит база данных, то без промежуточного слоя между базой данных и Web-интерфейсом не обойтись. Этот слой сильно завязан на базу данных и практически неотделим от предметной области, вот только пользователь часто не видит предметной области сайта — она скрыта под толстым слоем Web-дизайна. А видит он множество страничек, с множеством текстов, картинок и ссылок.
Приходя на сайт с вполне определенной целью, часто теряешься: как много всего, что, наверное, нужно типичному посетителю, но проблема в том, что мы не всегда типичные посетители, особенно когда заходим на сайт не в гости, а «по делам». Где тут у вас контактная информация? Так, среди нескольких десятков ссылок на первой страничке находим неприметные «Контакты». Где взять демо-версию? «Продукты» — «Демо» — «Downloads». Это уже маршрут, надо выбрать нужное направление, затем свернуть в нужный коридор и войти в нужную дверь. Между тем структура большинства сайтов обычно укладывается в ряд шаблонов, которые можно довольно просто типизировать.
Там, где есть формальное описание предметной области, можно применить и понимание запросов в контексте этого описания, и чем четче оно, тем надежнее понимание. «Контактная информация», «Где скачать демо» — это готовые ЕЯ-запросы. В идеале, когда сайт строится сразу на основе некоторой онтологии (системе сущностей и отношений между ними, как, например, в www.communiware.ru), то и поиск на таком сайте можно сделать на высшем уровне. Почти любой сайт имеет раздел новостей. «Новости за неделю», «Новости о...», «Последняя новость» — все эти ЕЯ-запросы ничем не отличаются от тех, которые задавались бы непосредственно к базе данных — они и здесь будут пониматься без проблем. Более того, при этом открываются возможности создания входов в онлайновые приложения через «авторские ссылки» — запросы, которые пользователь такого приложения пожелает разместить на отдельной страничке, которая принадлежит ему и только ему подконтрольна. Таким образом, мы получаем портал с настраивающимся интерфейсом когда от пользователя требуется только сформулировать текст ссылок-запросов да разместить их по вкусу. Либо оставить одно поле ввода, как на www.ya.ru и www.google.com — чем не выдающееся дизайнерское решение для портала?
Справочники — в развес
Опыт показывает, что естественно-языковые системы без конкретного приложения напоминают праздничный салют: интересно, красиво, но бесполезно. Польза начинается при комбинировании ЕЯ-интерфейсов с другими сервисами. Сказанное относится к Web-службам в модели B2C. Однако ЕЯ-интерфейсы хороши не только для общения конечных пользователей с приложениями — это еще и прекрасный способ общения между самими службами.
Одна из таких служб — справочники. Речь идет о следующей модели: на некотором сервере поддерживается в актуальном виде база данных, представляющая интерес для множества пользователей. Например, база с характеристиками сотовых телефонов, которыми торгует сейчас великое множество электронных и обычных магазинов. Каждый электронный магазин или тематический информационный ресурс вынужден поддерживать подобные каталоги самостоятельно. На первый взгляд, это не так уж и сложно, однако, если вспомнить о многообразии моделей, чуть ли не еженедельное появление новинок и количество значимых параметров у подобных товаров, то поддержка в актуальном и полном виде подобных каталогов — задача непростая. Напрашивается мысль о вынесении этой работы в отдельную службу (рис. 1).
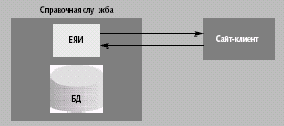 |
| Рис. 1. Организация справочной Web-службы |
Итак, спрос на высококачественный структурированный контент должен быть. А что с предложением? Сами по себе качественные справочники в Сети — вещь обычная, однако речь здесь о модели B2B — потребителем информации является другой бизнес, причем необходима техническая интеграция стороннего информационного наполнения в службы сайта потребителя и эта информация должна быть структурирована — типичная Web-служба. Как организовать доступ к справочнику? Основная сложность предоставления подобных услуг — соглашения между сторонами об интерфейсе. В электронном магазине хранится информация, специфичная для данного магазина: названия товаров, цены, а информация о характеристиках товара может быть получена от Web-службы. Но, во-первых, это потребует хранения либо на стороне Web-службы уникальных кодов товаров, либо, наоборот — на стороне потребителя информации — идентификаторов, под которыми хранятся товары в справочной Web-службе.Во-вторых, задача поиска и выбора товаров должна решаться на сайте магазина, но данные для этого хранятся в базе удаленного сервиса.
Чем может помочь здесь естественный язык? Прежде всего, можно отказаться от безликих идентификаторов товаров и их хранения на ответной стороне — естественно-языковое выражение названия товара здесь необходимо и достаточно для его идентификации. Причем это название может довольно сильно варьироваться на стороне потребителя — правильно построенный ЕЯ-интерфейс одинаково хорошо поймет и «Ericsson T28», и «Сотовый телефон Ericsson T28s», и «Мобильный телефон Ericsson T-28», несмотря на то, что в базе данных название фирмы-производителя, категории и марки товаров, как правило, хранятся в разных полях и таблицах. Во-вторых, ЕЯ-интерфейс — это все-таки очень удобный интерфейс: на запрос «Все характеристики Ericsson R380» выдается табличка с множеством характеристик данного телефона в виде XML или HTML, и остается только встроить этот ответ Web-службы в страничку сайта электронного магазина. Нет нужды даже знать, какие там бывают характеристики. Если же надо иметь отдельные свойства товаров, то можно использовать запросы типа «размеры и вес Ericsson R380» или «изображение Siemens S45».
Итак, все, что нужно для получения данных через ЕЯ-службу, — некий базовый URL, соглашения по кодированию результата запроса и владение языком, причем один и тот же ЕЯ-интерфейс может быть настроен на работу с несколькими языками. В результате ЕЯ-доступ к структурированному качественному информационному ресурсу намного повышает привлекательность этого ресурса в силу сокращения усилий по его использованию. Это касается и многих других случаев применения Web-служб. Их бизнес-модель может быть ориентирована как на применения категории B2C (например, посетители порталов), так и на B2B (доступ по подписке из приложений). Естественно-языковое выражение запроса — самое емкое, понятное человеку (тут самое время вспомнить, что разработчик Web-службы — тоже человек) и нейтральное к особенностям строения источника данных, именно это позволяет использовать его там, где вот уже 10 лет безраздельно царил SQL. Можно перечислить другие темы для Web-служб, где доступ на ЕЯ может послужить стартовым ускорителем к их распространению, и где уже сегодня возможно создание прибыльных служб: расписание поездов и самолетов, программа телепередач, репертуары театров и кинотеатров, наличие лекарств в аптеках.
***
Web — среда бурно развивающаяся и со временем в ней меняется буквально все, в частности, интерфейсы Web-приложений (например, закодированные в URL) могут измениться и тогда связь между приложениями прервется. ЕЯ-запрос как основа ссылки, является универсальным способом создания устойчивых интерфейсов: что бы ни менялось, ЕЯ-выражение функции получения некоторых данных инвариантно. Только существенное изменение предметной области может «сломать» подобный интерфейс.
Влад Жигалов (zhigalov@aha.ru) — сотрудник РосНИИ искусственного интеллекта, (Москва)
Системы построения ЕЯ-интерфейсов
Ограничимся двумя примерами систем English Query и InBASE. Помимо них, существуют еще несколько, например, English Language Frontend (www.elfsoftware.com) и EazyAsk (www.easyask.com), все они, как и English Query, предназначены только для английского языка.
English Query
Современные системы построения ЕЯ-интерфейсов так или иначе комбинируют все подходы к анализу естественного языка. Система English Query от Microsoft основана на синтаксически-ориентированных шаблонах, связываемых с моделью предметной области, и, через нее — со схемой базы данных. При настройке необходимо задать модель базы данных и предметной области, а затем — для каждого отношения в базе данных (а отношением считается и связь между классом и его атрибутом, например, между товаром и его ценой) задать синтаксический шаблон английской грамматики, выбираемый из списка.
Этот продукт позволяет строить ЕЯ-интерфейсы только для английского языка и работает только с Microsoft SQL Server, в этом смысле это лишь утилита, поставляемая с SQL-сервером, именно так она и позиционируется. В целом же этот продукт очень интересен. Например, в нем есть встроенная обучаемая база знаний, с которой можно пообщаться на английском языке — она запоминает факты, правила и отвечает на вопросы по этой базе. Довольно странно только, что эта замечательная способность не совмещена с пониманием запросов к базе данных.
InBASE
История этой отечественной разработки (http://inbase.artint.ru) довольно показательна. Основанная на семантически-ориентированном анализе и продолжающая ряд естественно-языковых технологий лаборатории искусственного интеллекта ВЦ АН Новосибирска, затем фирмы «Интеллектуальные технологии», а теперь и РосНИИ искусственного интеллекта, эта разработка вышла под названием InterBASE в начале 90-х годов. В 1990 году этот продукт получил первую премию ассоциации искусственного интеллекта СССР. В 1994 году проект был заморожен — его основные разработчики уехали из страны. Упоминание об этом продукте и его демо-дистрибутив и сейчас можно найти в некоторых каталогах. Реализованный как приложение DOS, InterBASE позволял строить ЕЯ-интерфейсы к dBase-совместимым базам данных. В 1996 году начался судебный процесс с Borland по поводу торговой марки InterBASE на территории России.
К 2001 году InterBASE был воссоздан, по-прежнему основываясь на семантически-ориентированной парадигме. InBASE представляет собой библиотеку COM-компонентов и среду настройки ЕЯ-интерфейсов, т.е. построен по схеме комплекта разработчика, как и English Query. Существенным отличием от старой версии является появление промежуточного уровня запросов — Q-языка, являющегося подмножеством языка объектных запросов OQL, и уровня описания предметной области в виде диаграммы классов UML.
В полном соответствии с особенностями семантически-ориентированной парадигмы, InBASE позволяет строить ЕЯ-интерфейсы ко многим языкам — для русского и для английского используется один и тот же Л-процессор. Интересной особенностью InBASE является возможность моделирования предметной области на естественном языке: есть класс словарных статей «Толкование», в котором смысл слова можно описать простой фразой. Например, для ЕЯ-интерфейса к базе данных о персонале слово «мать» толкуется как «женщина, имеющая детей», именно так это и вводится в систему при настройке. Еще пример толкования из базы данных об участниках конференции: «докладчик» = «участник с докладом». Это позволяет настраивать ЕЯ-интерфейсы людям, не обладающим навыками инженеров знаний.
