


Процессы управления инцидентами и управления проблемами во многом похожи, но имеют и существенные различия. Опишем каждый из процессов по отдельности, а затем сравним их с различных точек зрения, обсудив способы реализации.
Управление инцидентами
Основная цель процесса управления инцидентами (incident management) — восстановление нормальной работоспособности системы в максимально короткие сроки и минимизация отрицательного влияния на бизнес, пользующийся службами, работоспособность которых оказалась нарушенной [1-3]. Под «нормальным функционированием служб» понимается функционирование, соответствующее зафиксированному в соглашении об уровне обслуживания (service level agreement,SLA).
К инцидентам не могут быть отнесены события, не касающиеся качества предоставляемых ИТ-услуг, а также те, которые, снижая это качество, не выходят за оговоренные в SLA рамки. Особое место занимают случаи, когда клиент не ощутил на себе наличия инцидента (скажем, если все необходимые меры были приняты в автоматическом режиме или обслуживающим персоналом еще до того, как качество реально снизилось). Примеры: автоматическое архивирование данных и освобождение рабочего диска при приближении к моменту его переполнения; переход на резервный сервер при сбоях основного и т.д. Тем не менее, такие случаи не могут быть исключены из списка инцидентов. Правильная организация требует отработки и таких инцидентов в соответствии с полной процедурой (т.е. с последующим отображением в отчетах и принятием необходимых мер по их предотвращению в будущем).
Всякому процессу управления инцидентами можно дать формальное краткое описание путем перечисления набора характеристик.
Входными данными для описания инцидентов служат:
- детальное описание инцидента, полученное от Service Desk, служб обеспечения оперативного функционирования сетей или серверов и т.д.;
- описание конфигураций и элементов, возможно связанных с инцидентом. Описания берутся из CMDB, базы данных единиц конфигурации, к которым относятся все элементы ИТ-инфраструктуры (оборудование, программное обеспечение, документация, предоставляемые службы и т.д.);
- информация (при ее наличии) из базы проблем и базы известных ошибок;
- описание способа разрешения.
Результат процесса управления инцидентами может быть следующим:
- запрос на временное внесение изменений для устранения инцидента, обновленная регистрационная запись инцидента, включающая способ разрешения и/или обхода;
- разрешенный (устраненный) и закрытый инцидент;
- сообщение для клиента;
- управленческая информация (отчет).
Возможные мероприятия по управлению инцидентами:
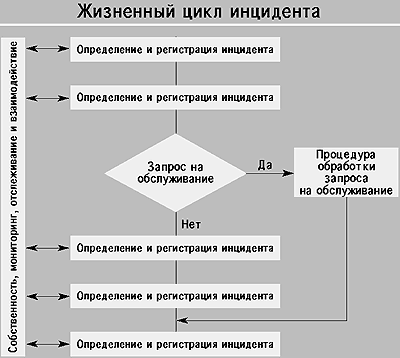
- определение и регистрация инцидента;
- классификация инцидента и начальная помощь;
- исследование и диагностика;
- разрешение инцидента и восстановление системы;
- закрытие инцидента;
- собственность, мониторинг, отслеживание и взаимодействие.
Роли и функции управления инцидентами:
- группы поддержки первой, второй и третьей линий, а также группы специалистов и внешние партнеры (роли); менеджер управления инцидентами (роль); менеджер Service Desk (функция).
Возможные метрики:
- общее число инцидентов;
- среднее время устранения или обхода инцидента по различным типам инцидентов;
- процент инцидентов, устраненных за время, не превышающее оговоренного в SLA;
- средняя стоимость устранения инцидента;
- процент инцидентов, закрытых без привлечения иных специалистов;
- число и процент инцидентов, устраненных удаленно (без визита к пользователю).
В целях обеспечения соблюдения временных рамок, выделенных для выполнения тех или иных действий, применяется функциональная и иерархическая эскалация. Под «эскалацией» понимается организационный механизм, помогающий контролировать время устранения инцидента; он должен использоваться при реализации всех мероприятий в процессе разрешения инцидента. Его суть состоит в необходимости либо обязательной передачи информации об инциденте более квалифицированным специалистам, либо информировании руководства о невозможности устранить инцидент в оговоренные сроки.
Передача инцидента от Service Desk на вторую линию поддержки (функциональная эскалация) требуется при невозможности устранить инцидент на первой линии. Автоматизированная функциональная эскалация возможна, но должна быть тщательно спланирована в соответствии с SLA.
Иерархическая эскалация оказывается необходимой при невозможности устранения инцидента либо за выделенное время, либо с необходимым качеством. Как правило, она осуществляется персоналом службы Service Desk в соответствии с их опытом и вручную. Автоматизированная иерархическая эскалация тоже используется и может строиться на основе учета временных интервалов. Целесообразно чтобы она осуществлялась до времени, установленного в SLA; при этом соответствующий руководитель получит возможность предпринять дополнительные действия.
Эффект от внедрения процесса управления инцидентами
Перечислим наиболее важные полезные качества, которые приобретаются в результате внедрения процесса управления инцидентами. Для бизнеса в целом это:
- снижение отрицательного воздействия на бизнес со стороны инцидентов, достигаемое повышением эффективности и сокращении времени при их устранении;
- проактивное (упреждающее) определение необходимости расширения и коррекции важных для бизнеса систем;
- доступность необходимой для бизнеса управленческой информации, соотнесенной с условиями SLA.
Ряд полезных качеств приобретает и работа ИТ-подразделения:
- усовершенствованный мониторинг, позволяющий измерить производительность в соответствии с SLA;
- улучшенная информация для управления качеством обслуживания;
- более оптимальная загрузка персонала и более эффективная его работа;
- исключение потерь и некорректного учета инцидентов и запросов;
- более точное ведение базы данных единиц конфигурации CMDB;
- лучшее удовлетворение потребностей клиентов.
Работа же без системы управления инцидентами может обернуться рядом неприятностей. Отсутствие лиц, ответственных за устранение и эскалацию инцидентов, приводит к путанице при устранении сбоев и снижает качество обслуживания. Специалисты службы поддержки отвлекаются от исполнения своих обязанностей, что снижает эффективность их труда. Пользователи для устранения инцидентов и проблем вынуждены общаться друг с другом, отвлекаясь от основных обязанностей. Всякий раз приходится заново анализировать инциденты — даже те, которые происходят регулярно и должны быть известны.
Управление проблемами
Основная цель процесса управления проблемами — минимизация неблагоприятного влияния на основную деятельность организации инцидентов и проблем, возникающих в результате ошибок в ИТ-инфраструктуре, а также предотвращение повторного возникновения инцидентов, связанных с этими ошибками. Для этого осуществляется поиск и выяснение причин инцидентов, и осуществляются действия, направленные на улучшение ситуации или устранение выявленных причин.
Процесс управления проблемами носит как реактивный, так и проактивный характер. Первый вариант касается разрешения проблем, связанных с возникшими инцидентами, второй направлен на выявление и устранение проблем, способных привести, но пока не приведших к возникновению инцидентов.
Контроль проблем и ошибок вместе с проактивным управлением проблемами составляют сферу ответственности процесса управления проблемами. На языке формальных определений, «проблема» — это неизвестная основная причина возникновения одного или нескольких инцидентов, а «известная ошибка» — успешно диагностированная проблема, для которой найден обходной путь или способ устранения.
Как и для процесса управления инцидентами, приведем группы основных характеристик процесса управления проблемами. Хотя некоторые из них и совпадают, указать их все имеет смысл, поскольку речь идет о разных процессах.
Входными данными для описания служат:
- детали инцидента, заимствованные из управления инцидентами;
- детальное описание конфигураций из CMDB;
- все известные обходные пути (из управления инцидентами).
Возможные мероприятия:
- контроль проблем и ошибок;
- проактивное предотвращение проблем;
- идентификация трендов;
- анализ накапливаемой информации и подготовка отчетов;
- подготовка управленческой информации.
Результаты могут быть следующими:
- описание новых известных ошибок;
- запросы на внесение изменений;
- обновленная регистрационная запись проблемы, включающая вариант решения проблемы и/или любой доступный обходной путь;
- для разрешенных проблем закрытая регистрационная запись проблемы;
- поиск аналогов инцидента среди известных ошибок и рассматриваемых проблем;
- управленческая информация.
Роли и функции: сотрудники, ответственные за обработку проблем (роли); менеджер управления проблемами (роль).
Возможные метрики:
- число инициированных запросов на внесение изменений, а также влияние этих запросов на надежность и доступность охваченных ими служб;
- время, затраченное на работы по исследованию и диагностике на каждое подразделение, с учетом деления на типы проблем;
- число и влияние возникших инцидентов до выявления причины проблемы или до регистрации известной ошибки;
- отношение объема усилий по немедленной помощи и поддержке к плановому;
- число проблем и ошибок, сгруппированных по различным признакам (статус, службы, влияние, категории, пользовательские группы);
- среднее и максимальное время, расходуемое на закрытие проблемы или согласование известной ошибки, рассчитываемое с момента регистрации проблемы, сгруппированное по кодам влияния и группам поддержки;
- ожидаемое время устранения открытых проблем;
- общее затраченное время на все закрытые проблемы.
Эффект от внедрения процесса управления проблемами
Перечислим наиболее важные полезные качества, которые приобретаются в результате внедрения процесса управления проблемами.
- Качество служб. Управление проблемами помогает поддерживать непрерывный цикл постоянного повышения качества ИТ-служб.
- Сокращение числа инцидентов. Процесс управления проблемами является инструментом для сокращения числа возникающих инцидентов, отрицательно влияющих на бизнес организации.
- Непрерывное решение. В результате работы процесса сокращается число и влияние на бизнес уже решенных проблем и известных ошибок.
- Усовершенствованное обучение. Процесс основывается на концепции использования накопленных знаний из прошлого и предоставляет возможности для анализа трендов и предотвращения сбоев, либо снижения их значимости и влияния на основной бизнес.
- Увеличение числа инцидентов, разрешаемых при первом обращении. Это достигается путем предоставления в распоряжение Service Desk рекомендаций по путям предотвращения и обхода возникающих инцидентов.
В свою очередь, отказ от реализации процесса сулит ряд неприятностей. Действующая исключительно «по факту» служба поддержки начинает действовать только тогда, когда услуга уже не доступна. Складывается инфраструктура, предполагающая применение пользователями ИТ-средств самостоятельно. Неэффективная, дорогая и слабо мотивированная служба поддержки многократно решает одни и те же проблемы, никак не учитывая предыдущий опыт.
Реализация и внедрение
Мы уже обращали внимание на основное отличие рассматриваемых процессов, учтенное в формировании ключевых метрик качества. Задачей управления инцидентами является устранение инцидентов в максимально короткие сроки. Управление же проблемами должно исключить возможность повторного возникновения инцидента по той же самой (а иногда — и по аналогичным) причинам.
В организационном плане это означает, что никто не может исполнять обязанности по обоим этим процессам одновременно, поскольку он был бы не в состоянии правильно расставить приоритеты. В качестве выхода из положения при традиционной ограниченности штата рекомендуется четко определить в инструкциях временные или иные рамки, позволяющие специалисту однозначно исполнять роль только в одном из процессов. Например, сотрудник службы эксплуатации сетей банка в критичное для работоспособности время прохождения основных платежей обязан при возникновении сбоев предпринять все меры по максимально быстрому устранению этих сбоев и восстановлению работоспособности систем, исполняя роль специалиста по управлению инцидентами. В относительно менее критичное время этому специалисту запрещается реагировать на возникающие инциденты и предписывается заниматься анализом накопленной информации о сбоях и поиском их причин и, тем самым исполнять мероприятия по управлению проблемами.
Допустимо (и рекомендуется) совмещение функций Service Desk и функций управления инцидентами. Однако важно помнить, что это разные процессы: первичное общение с пользователями не входит в функции процесса управления инцидентами. К тому же, пользователь может обратиться в службу поддержки не только в связи с возникшим инцидентом, но и по иной причине (потребность в информации, необходимость пополнения расходуемых материалов и т.д.). С другой стороны, при некоторых способах реализации (например, в случае построения службы поддержки на основе Web-технологий, когда пользователь самостоятельно вносит все необходимые данные в формы) необходимость выделенной службы Service Desk оказывается под вопросом. В то же время ни в коем случае нельзя отказываться от управления инцидентами — откуда бы ни поступило сообщение об их возникновении, кто-то обязательно должен отвечать за их устранение.
Понятно, что реализация управления проблемами при отсутствии управления инцидентами практически невозможна: основой и источником данных для рассмотрения проблемы является информация, накапливаемая в ходе анализа и обработки инцидентов. Порой оказывается допустимым внедрение только управления инцидентами. Обычно управление проблемами отсутствует у фирм-посредников — имея свою собственную диспетчерскую службу, такие компании организуют прием и регистрацию обращений клиентов, помогают им при наличии возможности устранить инцидент при помощи консультации, передают более сложные заявки субподрядчикам и контролируют их действия, реализуя тем самым управление инцидентами. В то же время, они не занимаются анализом проблем, поскольку не являются собственно эксплуатирующей организацией. Часто исключают управление проблемами и в случае, если нет возможности или желания этим заниматься. В отдельных случаях даже рекомендуется для анализа проблем привлекать внешних специалистов, поскольку для этого требуется очень высокая квалификация, а также дорогостоящее оборудование. Примером могут служить традиционные обращения в компании, специализирующиеся на построении и обслуживании телекоммуникаций, для определения реальной загрузки сетей передачи данных: соответствующее оборудование стоит дорого, а необходимость его использования возникает чрезвычайно редко.
В отношении средств автоматизации ITIL рекомендует, как минимум, наличие возможностей глубокой интеграции между инструментарием для управления проблемами и инцидентами. Действительно, при анализе проблем важно иметь возможность рассмотрения всех зарегистрированных инцидентов с различных точек зрения. В свою очередь, для более эффективного общения с пользователями при возникновении новых инцидентов, соответствующим специалистам необходим доступ к находящимся в рассмотрении или уже закрытым проблемам и известным ошибкам.
Это легко понять на примере следующей ситуации. Пользователь обращается в службу поддержки с сообщением о резком увеличении времени отклика от сервера. Оператор, просматривая список анализируемых проблем, находит запись о выполнении работ по анализу снижения производительности сервера, после чего сообщает пользователю, что его сообщение зарегистрировано и связано с рассматриваемой проблемой, а устранение ожидается через такое-то время, о чем пользователю будет сообщено дополнительно. При отсутствии возможности просмотра списка проблем, оператор не мог бы связать инцидент с конкретно анализируемой проблемой, в дальнейшем быстро отследить факт его устранения и сообщить об этом пользователю.
Производители инструментария стараются учитывать упомянутые рекомендации. Например, HP OpenView Service Desk 3.0 имеет модульную структуру. В виде отдельного модуля реализованы возможности регистрации и управления обращений пользователей, инцидентов и проблем, что вполне соответствует упомянутым рекомендациям: интеграция в данном случая является максимально полной. Пользователи системы, построенной на основе этого продукта, имеют возможность строить связи между регистрационными записями всех перечисленных типов, осуществлять поиск по контексту и с учетом этих связей, определять известные способы решения проявляющихся неисправностей. Разделение этих функций может снизить эффективность работы инструментального средства, а как следствие — и качество реализации процессов. В то же время, в основе всякого решения по управлению ИТ-инфраструктурой лежит учет имеющегося оборудования, приложений, документации и т.д. — всего того, что и составляет эту инфраструктуру. Такие возможности также доступны в рамках HP Service Desk 3.0. Кроме того, в виде отдельных модулей реализованы возможности, предназначенные для автоматизации управления изменениями и управления соглашениями SLA. Интеграция всех перечисленных модулей реализуется в максимально полном объеме, предоставляя возможность использовать рассматриваемый продукт в качестве основы для построения комплексной системы управления ИТ.
Продукт компании Remedy строится несколько сложнее, основой его является Remedy Action Request System, устанавливаемая на сервере. К системе в качестве прикладной части могут дополнительно приобретаться функциональные модули: Help Desk, Asset Management, Change Management и Service Level Agreement. Каждый из модулей может использоваться как самостоятельно (без других прикладных модулей), так и в составе комплексного решения. Вопросы автоматизации процессов управления проблемами и инцидентами, как и в случае решения от HP, реализуются в модуле Remedy Help Desk. При этом имеются некоторые отличия и реализуются отдельные собственные подходы к пониманию данных процессов, но основные пожелания и требования ITIL полностью учтены.
Рекомендации и возможные трудности
Для успешного внедрения процессов управления инцидентами и проблемами
необходимо выполнение, как минимум, следующих условий.
- Наличие актуальной и своевременно обновляемой базы CMDB. Если эта база недоступна, информация об имеющих отношение к инциденту единицах конфигурации будет добываться вручную, что существенно увеличит время обработки инцидента и повысит ее сложность.
- Доступность обновляемой базы знаний по ошибкам/проблемам и способам их разрешения, а также обхода. Наличие такой базы позволяет быстро разрешать многие проблемы. Желательно иметь возможность подключения к ней аналогичных баз, разработанных другими организациями и компаниями. Возникающие при этом вопросы совместимости могут привести к большим сложностям, поэтому рекомендуется использовать решения с открытой архитектурой, содержащие средства для импорта и экспорта данных. В последнее время все чаще в качестве стандартного способа доступа к информации используется Web-интерфейс, являющийся удобным и понятным, а также широко распространенным.
- С точки зрения потенциально конфликтной ситуации между управлением проблемами и управлением инцидентами (из-за их разных целей), необходимо организовать совместную работу и сотрудничество исполнителей обоих процессов. При этом нельзя забывать о том, что из тех же соображений один и тот же человек не может исполнять и те и другие обязанности одновременно: ему будет очень трудно найти баланс интересов.
- Организация эффективной автоматизированной системы регистрации инцидентов с возможностями детальной и качественной классификации, являющейся чрезвычайно важным элементом для организации функционирования как службы Service Desk, так и рассматриваемых процессов в чистом виде. Использование для этих целей бумажных технологий не рекомендуется.
Весьма удобно, если инструментальные средства, используемые для реализации рассматриваемых процессов, обладают следующими дополнительными возможностями:
- автоматической регистрацией инцидентов, происходящих в наиболее важных устройствах (серверы, сетевое оборудование и т.д.), для чего может потребоваться создание дополнительных интерфейсов;
- автоматической эскалацией инцидентов при нарушении временных графиков;
- гибкой маршрутизацией инцидентов, поскольку персонал служб поддержки может быть размещен в различных помещениях и зданиях;
- автоматическим поиском необходимых данных в базе CMDB;
- специальными решеними для облегчения классификации инцидентов;
- интеграцией с телефонными системами;
- наличием разнообразных диагностических модулей.
Проиллюстрируем перечисленные возможности на примере уже упоминавшегося Service Desk 3.0. Будучи представителем семейства продуктов HP OpenView, Service Desk содержит возможности получения сообщений от других продуктов данного семейства, в том числе от Network Node Manager, средства мониторинга и управления сетевыми устройствами, и VantagePoint Operations, средства мониторинга и управления серверами и приложениями. Данные продукты могут в автоматическом режиме, на основании собираемой информации о контролируемых объектах, генерировать запросы для Service Desk, которые автоматически передаются и анализируются операторами службы поддержки или обрабатываются в автоматическом режиме. При соответствующей настройке источниками аналогичных сообщений могут стать и иные диагностические средства. Продукт предусматривает возможности автоматического информирования путем отправки сообщений руководителей соответствующих уровней при нарушении сроков устранения инцидента. В нем реализованы расширенные возможности по поиску необходимой информации среди уже учтенных проблем, инцидентов и иных данных. В продукте представлены возможности интеграции с почтовыми, телефонными и пейджинговыми системами.
В виду актуальности и полезности перечисленных дополнительных возможностей, производители программных решений стараются включать их в свои продукты. Многое из сказанного о HP Service Desk относится и к продуктам других производителей, в том числе, Remedy, Tivoli, CA, Peregrin, FrontRange.
Тем, кто берется за работу по внедрению рассматриваемых процессов, надо быть готовым к разнообразным трудностям. Среди них:
- отсутствие поддержки со стороны руководства и персонала, что может вести к недостатку ресурсов для реализации;
- непонимание потребностей бизнеса, отсутствие согласованных уровней обслуживания, слабо определенные цели, возможности и ответственности различных служб;
- сопротивление изменениям и невозможность внесения изменений в сложившуюся практику работы;
- недостаток знаний для разрешения инцидентов, неправильная подготовка персонала, слабо формализованные правила взаимодействия пользователей со службами поддержки и различных служб между собой;
- слабая интеграция с другими процессами, некачественные средства автоматизации, невозможность связать регистрационные записи инцидентов и соответствующих им проблем существенно снижает возможности процесса, в том числе, возможности прогнозирования проблем.
***
Мы остановились на двух наиболее часто упоминаемых в связи с устранением возникающих неисправностей процессах управления элементами ИТ. Являясь довольно понятными на интуитивном уровне, данные процессы при этом сложны для реализации с точки зрения необходимости четкого соблюдения организационных мероприятий и процедур. Будучи во многом схожими, процессы управления инцидентами и управления проблемами обладают и существенными различиями, проистекающими из их основных целей. Максимальную важность при внедрении процессов приобретают используемые для этих целей средства автоматизации. К сожалению, первоисточники по ITIL доступны очень ограниченному кругу заинтересованных: стоят они весьма недешево, заказать их непросто, а получить — еще сложнее. Изложенные в статье требования и пожелания к инструментарию основываются на реальном опыте эксплуатации разнообразных средств и анализе путей решений возникавших при этом вопросов.
Литература
1. З. Алехин. ITIL — основа концепции управления ИТ-службами. «Открытые системы». 2001, № 3
2. З. Алехин. Service Desk — цели, возможности, реализации. «Открытые системы». 2001, № 5-6
3. CCTA. Best Practice for Service Support. London: The Stationery Office, 2000
Заурбек Алехин (alekhin@i-teco.ru) — руководитель проекта компании i-Teco (Москва).
Что такое инцидент
Согласно принятому в ITIL определению под «инцидентом» понимается «любое событие, не являющееся элементом нормального функционирования службы и при этом оказывающее или способное оказать влияние на предоставление службы путем ее прерывания или снижения качества».
Основные категории инцидентов
Приложения:
- служба недоступна;
- ошибка в приложении, не дающая клиенту нормально работать;
- исчерпано дисковое пространство.
Оборудование:
- сбой системы;
- внутренний сигнал тревоги;
- отказ принтера.
Заявки на обслуживание:
- поступление заявки на получение дополнительной информации, совета, документации;
- забытый пароль.
Большинство групп ИТ-специалистов имеет отношение к устранению тех или иных инцидентов. Служба Service Desk отвечает за мониторинг процесса устранения всех зарегистрированных инцидентов, поскольку является собственником всех таких инцидентов. Этот процесс в большей степени реактивный; для эффективного реагирования на инциденты должен быть определен формальный метод работы сотрудников, включающий использование необходимого программного обеспечения.
Те инциденты, которые не могут быть разрешены непосредственно службой Service Desk, должны быть переадресованы соответствующим специалистам. Способ разрешения инцидента или вариант его обхода должны быть установлены и доведены до пользователей как можно быстрее. Это вытекает из главной цели — минимизации отрицательного влияния на основную деятельность пользователей. После устранения причины инцидента и восстановления службы до оговоренного в SLA уровня инцидент закрывается.
