

Когда произносится слово «кэш», большинству приходит на ум кэш процессора, который дублирует данные оперативной памяти. Однако об этом кэше мы поговорим позже. В действительности, идея дублирования данных встречается и на более низком уровне. В процессоре суперкомпьютеров Cray, например, были оперативные и сверхоперативные регистры. Фактически в коде программы факт необходимости подгрузки данных учитывался заранее. Сегодня эта идея в некотором виде возвращается. У некоторых процессоров предусмотрена возможность явного указания кэшу заранее подгрузить данные; соответствующий код вставляется в программу компилятором.
Кэш — что может быть более знакомо для программистов? Суть кэша состоит в дублировании данных с целью ускорения выполнения операций. Если остановиться именно на таком варианте определения, то окажется, что идеей кэша пронизано абсолютно все в компьютере и в операционной системе. Можно даже утверждать, что процесс вычислений представляет собой всего лишь обмен данными между носителями и, главное, их кэшами. (Впрочем, настаивать на подобной формулировке я не стану.)
Дом, который построил Cray
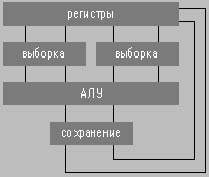 |
| Рис.1. Возможная схема выборки |
Рассмотрим какую-нибудь простенькую операцию. Поскольку тип процессора не важен, поэтому пусть она будет трехадресной: add r1, r1, r12. Что в ней интересного? Один и тот же регистр r1 используется дважды. Ну и что тут такого? До тех пор, пока мы не говорим о деталях организации процессора, ничего. А если говорим? В этом случае все становится интереснее. В простейшем варианте (ну, не станем говорить о спекулятивном выполнении команд) можно представить себе следующую схему. Что такое набор регистров? Это просто набор бит. Схема выборки сложнее, чем этот набор бит (см. рис. 1). Так это же все еще надо как-то разместить на кристалле. Эти же схемы выборки могут друг другу мешать. А что нам мешает их полностью разделить? В итоге получается достаточно забавный результат. Регистры дублируются так, что при сохранении данных они записываются в оба экземпляра, а при чтении первый операнд читается из первого набора, а второй — из второго. Следующий этап еще круче. А зачем это мы имеем два набора регистров и так неэффективно их используем? Надо бы разрешить их использовать по особому запросу программистов (бит в управляющем регистре). В результате имеем два режима работы: первый — набор регистров один, но регистры можно использовать на любом месте; второй — наборов регистров два, но каждый из операндов должен быть из своего набора. Во втором случае, помимо этого, возникает необходимость в дополнительных операциях пересылки. Именно такое решение встретилось мне однажды в одном специализированном процессоре. Дело былое.
Вокзал
Как устроен кэш? Здесь все и всем очевидно: если при обращении по определенному адресу оказывается, что данные есть в кэше, то обращения к памяти (или следующему уровню кэша) игнорируются, и данные забираются непосредственно из кэша. Но уже в этот момент с точки зрения реализации возникает несколько проблем. Во-первых, вместе с копией данных необходимо хранить теги, которые указывают адрес и состояние оных данных; во-вторых, данные извлекаются не по адресу, а по содержимому этих самых тегов. В том случае, когда требуется получить данные по какому-то адресу, необходимо сравнить данный адрес со всеми адресами, которые присутствуют в кэше. Очевидно, что последовательное сравнение с точки зрения производительности абсолютно не оправданно — интересен только вариант с параллельным выполнением сравнения всех элементов. Затевать кэширование ради отдельных слов не интересно, поскольку именно начальная стадия выборки и занимает максимум времени. Из памяти в кэш забирается целая порция данных — строка кэша. Соответственно в теге нужно сохранять не весь адрес, а только адрес минус число бит, которое необходимо для выбора байта в строке. Обычно размер кэш—линии составляет 16-64 байта и бывает различен даже в серии однотипных процессоров (эксперименты создателей...). Что означает, что кэш полностью ассоциативный? Это означает, что каждый теговый регистр является компаратором и все компараторы кэша способны одновременно выполнить сравнение и, соответственно, выборку нужного элемента. Это достаточно крутое действие, поэтому возникают определенные технологические ограничения на размер подобного кэша. Обычно размер этот ограничен десятками килобайт.
Предположим, нам не хватило объема полностью ассоциативного кэша первого уровня (если он вообще есть; как правило, это не так). Что дальше? Кэш следующего уровня должен быть большим, очень большим. Из этого следует, что сделать его полностью ассоциативным нельзя. Но что делать?
Вот в этот момент и появляется идея разделить кэш на несколько частей, так, чтобы за каждую часть отвечал один компаратор. Самый простой способ состоит в том, чтобы место конкретной строки в кэше полностью определялось частью бит из адреса. При обращении к такого рода кэшу (прямо адресуемый кэш) используется банальная адресация, и далее просто надо проверить тот факт, что по данному адресу лежат именно те данные, которые необходимы, т.е. тег содержит физический адрес запрошенных данных. Для реализации этого варианта нужна «обычная» память и один компаратор. Данная схема выглядит достаточно скучной, но используется в ряде архитектур. Следующий шаг заключается в том, что мы сначала прямо выбираем «подкэш» на несколько линий и там делаем сравнение. Как правило, подкэш содержит 4-8 линий, или путей. Например, 8 линий имеет PowerPC. Если не рассматривать полностью ассоциативные кэши, то самое большое количество путей («вокзал») имеет кэш для ARM940T — по 64 линии в 4 сегментах. Впрочем, уже в следующем ядре ARM946E-S числе путей ограничено четырьмя.
Как выглядит физический адрес данных у подобного процессора? Это может быть что-то типа:
aaaaaaaaaaaaaaaaaasasssssaaaaaaooooo
В этой строке a — просто часть адреса данных, o — смещение в рамках кэш-линии, s — номер сегмента кэша (фактически адрес подкэш). В принципе, до тех пор, пока речь идет о физических адресах, положение бит адреса для выбора сегмента кажется не очень существенным. Однако обычно сегментные биты располагаются достаточно низко. Зачем? Опять все определяется производительностью. Еще раз рассмотрим процедуру обращения к определенным данным в памяти:
Виртуальный адрес -> физический адрес -> кэш (если попали) -> основная память
Казалось бы, в этой схеме нечего сэкономить. Все этапы должны выполняться последовательно. Это почти так. Виртуальный адрес в простейшей форме обычно выглядит следующим образом:
Номер_страницы смещение_в_пределах_страницы.
Ясно, что размер страницы (например, 4 Кбайт) существенно больше размера кэш-линии. Если оставшиеся от смещения в рамках кэш-линии биты использовать для сегмента, то выбор сегмента кэш-памяти можно начать до того, как станет известен реальный адрес. Ну а вот после извлечения адресов кэш-линий и параллельного (если повезет) выполнения преобразования виртуальный адрес -> физический адрес их результаты можно будет сравнить. Попробуем посчитать. Пусть число путей — 4, а размер страницы — 4 Кбайт. Быстрый доступ с упреждающей выборкой можно обеспечить для 16 Кбайт (максимальное использование бит эквивалентно прямому умножению). Скажем, 16 Кбайт на данные и 16 Кбайт на инструкции — такова организация кэша первого уровня для P6. Если при данной скорости работы кэша нужно его увеличить, то можно либо увеличивать размер страницы, либо число подъездных путей, либо использовать еще какие-то характеристики кроме соотношения код/данные. В противном случае нужно тратить дополнительное время на селекцию и, например, удлинять конвейер.
Как происходит замена элемента (линии) в кэш-памяти? Если количество одновременно адресуемых элементов невелико, то используется алгоритм LRU (предсказывающего оракула, напомню, у нас нет), который достаточно просто реализовать аппаратно (см. например [1]). А вот для «многопутных» кэшей (вспомним тот же ARM940T) обычно предпочитают оракула в виде псевдослучайного датчика.
Следующий специфичный момент в работе кэша связан с многопроцессорной обработкой. Что будет, если две переменные окажутся в одной кэш-линии, которая будет прочитана одновременно двумя процессорами? Например:
int number_of_active_processes; pQueue pQprocs;
Один процессор меняет число активных процессов, а другой перетрясает очередь. И любые эффекты уже, заметим, сказываются на работе ОС. Ясно, что если изменение и сброс элементов кэша происходят независимо, то ждать чего-либо хорошего нельзя. Фактически возникнут две (возможно, как-то пересекающиеся) очереди. Значит, обновление кэшей должно проходить синхронно. Известны алгоритмы (например, snooping для Pentium [4]), предполагающие, что при обнаружении модификации кэш-линии, которая, заметим, может быть и у других процессоров, следует объявить все кэш-линии с данным физическим адресом у всех остальных процессоров устаревшими. Указание факта модификации требует цикла на шине, который анализируется всеми остальными процессорами. Заметим, что в принципе можно не требовать когерентности состояния кэш-линии и памяти, однако, в любом случае, когда другой процессор запросит данные из этой модифицированной данным процессором линии, то эти данные должны быть предоставлены процессором либо сразу через шину, либо через память.
Принцип когерентности (он явным образом входит в название ccNUMA) для высокопроизводительных систем должен поддерживаться не только для процессоров, но и для высокопроизводительных систем ввода/вывода. Впрочем, здесь уже проявляется роль другого кэша.
Мастерские
Зададимся следующей целью: написать для конкретной архитектуры максимально мерзкую с точки зрения производительности программу. Это, кстати, позволяет достичь сразу нескольких целей: получить оценку снизу на производительность архитектуры, найти неприятные для нее режимы работы, разработать рекомендации по оптимизации алгоритмов.
Итак задача первая: как «пробить» полностью ассоциативный кэш? «Интересный» эффект возникает в том случае, когда мы будем использовать объем, превышающий объем кэша. При этом вовсе не обязательно «загаживать» все байты кэша. Достаточно «пройтись» только по одному байту в каждой кэш-линии. При этом, правда, надо еще вспомнить о том, что не все процессоры делают попытку чтения кэш-линии при записи (см. номер с memcpy), но все делают это при чтении.
Как пробить многопутный кэш? Проще всего сделать так, чтобы все данные попадали в рамки одного сегмента. Тогда, если удастся занять места больше, чем содержит один сегмент, то... производительность просядет. Для этого, оказывается, достаточно занять очень малую часть кэш-памяти. Основываясь на этом, можно даже попытаться определить и число путей, и размер кэша, линии и т.п. Пробуем:
/* Это описания и всякая там инициализация */ #include #include #include #include #define MAX_POWER 21 /* Надеюсь, что кэш данных у вас меньше 2 Мбайт */ #define MAX_CACHE (1<
Тут главное — иметь памяти больше, чем произведение реального числа путей на размер кэша.
p = calloc(MAXWAYS, MAX_CACHE);
if(p==NULL){perror(«Cache»); exit(1);}Попробуем определить число путей на нашем «вокзале». Для этого попытаемся использовать по одному байту с шагом в размер кэш-памяти. Нормально работающая кэш-память всегда может накрыть непрерывную область в свой размер. MAX_CACHE мы взяли с запасом, но, скорее всего, он кратен размеру кэш-памяти. Это автоматически обеспечивает, что байты с таким смещением оказываются в одном сегменте. Количество «последовательно» просматриваемых байт определяется переменной j. Сумма s, скорее всего, лежит на регистре (вы не забыли ключей оптимизации?):
for(j=1; j<=MAXWAYS; j++){
gettimeofday(&t1, &tz);
for(cycle = CYCLES; cycle>0; cycle—){
for(i=j;i>0;)s+=p[—i*MAX_CACHE];
}
gettimeofday(&t2, &tz);
dt[j] = (t2.tv_sec-t1.tv_sec)*1000000.
+ (t2.tv_usec-t1.tv_usec);
}Остается сравнить времена. Если окажется, что j больше, чем «путевость» кэша, то каждое обращение за элементом из массива p приводит к перезагрузке кэш-линии. Именно этот факт нам и хочется пронаблюдать. Время соотносится с одним обращением — поэтому делим на j. Мы вправе ожидать, что разницу времен между последовательными значениями j (число путей и число путей+1) при количестве путей 8 составит десяток процентов. Именно эту величину — 10% — и зафиксируем в программе. (Реальный рывок может оказаться больше.)
for(j=1; j<=MAXWAYS; j++){
d2 = dt[j]/j;
printf(«Time for %d is %8.3fus
»,
j, d2, s);
if(d2>d1*1.1){printf(«Number of ways
is %d
», j-1); break;}
d1 = d2;
}Стоит обратить внимание, что, например, при числе путей равном 4, заняв всего 4 байта, возможности кэша по ускорению данной программы оказываются исчерпанными; уже обращение к пятому байту покажет всю его несостоятельность. При этом абсолютно не важно, сколько реально есть кэш-памяти. Еще один важный момент: программа не обязана выдавать абсолютно правильного значения — она определяет именно размер кэша данных, при этом явно пытаясь использовать тот факт, что кэш инструкций и данных различен (кэш данных предполагается однородным, а алгоритм замены его содержимого — LRU).
Итак, j у нас на единицу больше числа путей. Этого достаточно, для того чтобы определить сам размер кэша данных. Что произойдет, если, зафиксировав j, начать уменьшать шаг между последовательными обращениями к массиву p? До тех пор, пока шаг больше или равен размеру кэша или сегмента кэша, каждое обращение будет приводить к перезагрузке линии. Но стоит сделать шаг меньше сегмента кэша, то произойдет рывок в производительности, т.к. перезагрузки исчезнут. Пробуем:
for(nbit = MAX_POWER; nbit>0; nbit—){
gettimeofday(&t1, &tz);
for(cycle = CYCLES; cycle>0; cycle—){
for(i=j;i>0;)s+=p[(—i)<Следующим этапом мы можем определить размер одной кэш-линии. Для этого в одну кэш-линию попытаемся наступить обеими ногами; главное — найти оптимальную ширину между ними:
nbit++; /* На бит больше кэша */
/* Кэш-линия меньше 1024, изменяем
расстояние прыжка 1-1024 */
d2 = 1.e10;
for(k=1; k<1024; k<<=1){
gettimeofday(&t1, &tz);
for(cycle = CYCLES; cycle>0;
cycle—){
/* основной трюк nb — nb+k */
for(i=j-1;i>=0;i—){nb = i<1.3*d2)break;
d2 = d1;
}
printf(«Size of cacheline is %d
bytes
», k);Почему эта программа срабатывает? Пока k меньше размера кэш-линии и для p[nb], и для p[nb+k], мы выполняем загрузку одной кэш-линии. Однако в тот момент, когда k становится равным размеру кэш-линии, мы начинаем загружать для каждого из них по отдельной строке. Мы вправе рассчитывать на существенное увеличение времени. Соответственно и коэффициентик равняется 1,3.
Программа добросовестно определила размер кэшей в ОС Linux. Но не кажется ли вам, что где-то я вас обманываю? Все изложенное выше должно абсолютно корректно работать с физическими адресами памяти, но ведь в Unix-то используются виртуальные адреса. Весь фокус в том, что за распределение отвечают сегментные биты, а это означает, что все происходит безотносительно к старшим битам.
Обратите внимание, что компьютеры плохо относятся к «хорошо» расположенным данным. Т.е., например, располагая данные в дереве по адресам с большими степеням двойки (см. классический алгоритм «система двойников» [5]), можно ухудшить производительность в том случае, когда данные используются одновременно и с одинаковыми смещениями.
Стрелочник
Следующий кэш, который опять же интегрирован в процессор, необходим для быстрого преобразования виртуального адреса в физический. Вспомним размер процесса. Если адресное пространство — 32-разрядное, то мы имеем право на 4 Гбайт. Если страница равняется 4 Кбайт, то нам потребуется 1 Мстраниц. Ясно, что объемчик описателя великоват и хранится частично в памяти, а частично и на диске ([2]). Также ясно и то, что всякий раз для преобразования адреса использовать еще одно обращение к памяти — явный перебор. Соответственно на процессоре образуется еще один кэш — кэш преобразования виртуального адреса в физический. В данном случае для поиска используется только та часть адреса, которая отвечает за номер страницы. Как подгружается кэш преобразования адреса? Оптимальным вариантом, естественно, кажется аппаратная подгрузка. Особых высот этот механизм достигал в семействе MC680x0 от Motorola, реализованный на отдельной микросхеме MMU, позволял определять страницы размером до 1 байта, что даже использовалось в сетевом оборудовании для сборки пакетов без перемещения данных. Но уже MC68040 использовал страницы по 4 Кбайт. Аппаратная подгрузка кэша преобразования адреса предполагает специфическое «аппаратное» распределение данных в памяти. Например, микросхема MC68551 позволяла организовывать дерево страниц до 5 уровней, при этом отдельные поддеревья могли иметь разное число уровней (для сравнения: в Pentium 2-3 статических уровня). При этом, естественно, появляются и какие-то ограничения для операционной системы, необходимость что-то продублировать в «своем» формате. При указанных объемах информации наличие накладных расходов не желательно. А что делать с 64-разрядными машинами и адресами? Для «монстров» было принято решение о полном отказе от аппаратной загрузки транслятора адреса TLB.
Каждая строка в TLB содержит не только пару адресов (виртуальный адрес страницы, физический адрес страницы), но и характеристики страницы, т.е. возможность читать, писать, выполнять, использование кэширования, форма кэширования, порядок байт для процессоров, которые способны поддержать оба LSB/MSB и т.п. ([3]).
Как всегда, возникает вопрос об организации самого TLB. Это ассоциативная память, которая должна содержать массу компараторов. Естественно, для памяти этого типа можно повторить все, что было сказано для обычной кэш-памяти. TLB бывает полностью ассоциативным, сегментированным, разделенным на память для инструкций и данных и т.п. Типичный размер TLB — в пределах сотни записей. Как подпортить жизнь TLB? Ответ очевиден. Если «ходить конем», т.е. обращаться к отдельным словам на страницах, то можно заставить TLB перегружаться, а это увеличит время выполнения программы. Пусть, например, MAX_TLB равно 100, PSIZE — 4096. Заменим нашу программу на следующую:
p = calloc(MAX_TLB, PSIZE);
if(p==NULL){perror(«Cache»); exit(1);}
for(j=1; j<=MAX_TLB; j++){
gettimeofday(&t1, &tz);
for(cycle = CYCLES; cycle>0; cycle—){
for(i=j;i>0;)s+=p[—i*PSIZE];
}
gettimeofday(&t2, &tz);
d2 = (t2.tv_sec-t1.tv_sec)*1000000.
+ (t2.tv_usec-t1.tv_usec);
printf(«Time for %d is %8.3fus
»,
j, d2/j, s);
}Поведение программы на первых витках цикла мы уже изучили. Посмотрим, что происходит за пределами первой десятки (j>10). Тогда обнаружится тот факт, что значение d1/j в момент перехода, например, от 64 к 65 существенно изменяется. Речь идет уже об увеличении не на 10-30%, а в полтора и более раз. Если же сравнивать с началом, то и вовсе становится грустно. Связано это исключительно с необходимостью перезагрузки TLB.
Если заменить чтение элемента на запись (вместо s+=p[—i*PSIZE] в программе надо написать p[—i*PSIZE]=0), то мы получим почти чистый эффект TLB, так как кэш для чистой записи часто не используется. Можно еще ухудшить ситуацию и использовать цикл, подобный следующему:
for(;;)for(i=0;i<100;i++)p[PSIZE*i]=0;
Программы данного типа вообще крайне эффективно загружают процессор. При этом тип операционной системы практически не важен. Эффект этот связан с тем, что каждое обращение за новым элементом массива p приводит и к перезагрузке TLB и кэш-линии, и требует удержания всего выделенного под p массива в памяти. Если запустить эту программу несколько раз, а общий объем выделенной памяти за счет области подкачки существенно превысит размер оперативной, то... через некоторое время будет достигнуто состояние, оптимальное для администрирования, поскольку все пользователи сбегут.
Ясно, что с адресным бардаком надо как-то бороться. Как это можно сделать? Основной способ борьбы заключается в структурированном выделении памяти. Например, использовать механизм пулов.
Если мы работаем, например, с деревом, то можно выделять память для каждого элемента посредством вызова malloc. Однако это приведет к перемешиванию в памяти разнотипных данных, что в общем случае скорее всего плохо отразится на скорости работы. Более логичным является выделение места под серию элементов дерева. В результате все элементы дерева окажутся на ограниченном количестве страниц. Подобный метод очень популярен внутри ОС. Unix, например, для каждого процесса в системном режиме отводит собственное адресное пространство, соответственно могут быть проблемы с TLB. Эффективное использование TLB ядром в значительной степени достигается механизмом выделения места. Везде, где это возможно, Unix предпочитает массивы, а не списки.
Поезд отправляется
Вернемся к вопросу о когерентности кэша. Что будет, если мы хотим отправить пакет в сеть? Операционная система будет собирать пакет в кэше. Что будет происходить в тот момент, когда сетевому контроллеру будет необходимо отправить пакет в путь? Ясно, что в этом случае необходимо, чтобы данные были забраны корректные из кэша. Добиться этого можно следующими способами в зависимости от возможностей контроллера: потребовать, чтобы сборка пакета происходила в реальной памяти без использования кэша или при работе кэша в режиме прозрачной записи; перед выдачей команды контроллеру потребовать сброса части кэша (задавая диапазон физических адресов) или всего кэша (как минимум модифицированной части кэша) в память; потребовать от контроллера поддержки режима когерентности кэша. Аналогичная проблема возникает и при чтении: вдруг в кэш-памяти осталась «грязь» от предыдущего состояния буфера. И решения схожие: использование некэшируемой области обмена, возможность объявить зону буфера «некорректной».
Первый из подходов отличается дешевизной и практически всегда используется в малопроизводительных устройствах. Страница памяти (если работа с устройством не идет через пространство ввода/вывода) объявляется некэшируемой, а любое обращение идет, минуя кэш, — медленно, но верно. Поскольку для внешних устройств (как, впрочем, иногда и для межпроцессорных коммуникаций) очень существенен порядок обновления памяти (это же регистры), то это именно их режимчик. Не следует при этом забывать и про управляющую директиву volatile для исключения излишней оптимизации Си.
Второй вариант чрезвычайно популярен, хотя и реализуется в разных архитектурах по-разному. В некоторых случаях используется возможность сброса конкретного кусочка кэша с учетом адреса буфера. Например, для семейства M68000 можно посмотреть процедуру cache_push в ..../arch/m68k/mm/memory.c (здесь и далее упоминаются файлы ядра Linux 2.4.3). Для PowerPC имеется команда eieio, которая сбрасывает всю модифицированную часть кэша. Она в Linux (см. .../arch/ppc/kernel/misc.S) используется для выполнения следующих требований: гарантии сброса буферов, гарантии определенного порядка обновления памяти, организации связи в SMP-архитектурах.
Наиболее любопытно этот вариант реализуем в процессорах семейства ARM. Элементы кэша здесь нельзя адресовать по физическому адресу данных, которые он содержит. Однако элемент кэша можно адресовать явно по номеру сегмента и позиции в нем. Соответственно корректный вариант сброса всего кэша в память предполагает выполнение цикла по всем сегментам и элементам кэша — мечта системщика (желающие посмотреть на этот цикл пристальнее могут заглянуть, например, в ../arch/arm/mm/proc-arm920.S). Только отказ от содержимого кэша делается в ARM одной операцией, но он, увы, приводит к полной потере всех данных кэша.(Возможно, именно некоторые «изюминки» в поведении ARM и привели к тому, что один из Linux-программистов заявил, что «ненавидит ARM».)
Третий вариант — самый трудоемкий в реализации (необходимо «вставить» поддержку кэш-когерентности в подсистему ввода/вывода), но и потенциально самый эффективный.
Камера хранения
О буферном кэше уже было немного написано в мартовском номере. Буферный кэш позволяет оптимизировать дисковый ввод «в среднем». В основном ускоряется последовательная работа с файлами. Буферный кэш плохо помогает при «прокачивании» больших объемов данных и хаотическом доступе к диску. В принципе увеличение буферного кэша должно помогать работе подсистемы ввода/вывода за счет уменьшения обмена с диском. Однако при чрезмерно большом размере буферного кэша ситуация может смениться на противоположную: может произойти увеличение потока ввода/вывода по причине более частого замещения страниц процессов (типичная борьба за ресурсы между процессами и буферным кэшем).
Вода для паровоза
Попробуем теперь рассмотреть работу диска. Конечно же, диск тоже имеет свой кэш, целью которого является агрегирование данных перед отправкой их непосредственно на носитель или, наоборот, в компьютер.
Рассмотрим работу SCSI-дисков. Из литературы можно узнать, что размер их кэша уже исчисляется мегабайтами. Однако это не означает, что мегабайты эти готовы быть использованы по любому запросу. Формально обмен данными между компьютером и диском, например, при записи представляется следующим образом:
Процесс -> буферный кэш -> SCSI-шина -> дисковый кэш -> носитель
Одна SCSI-шина обычно обслуживает несколько устройств, а иногда и несколько компьютеров. Поскольку передача отдельных блоков данных может идти по шине только последовательно, то для обеспечения нормальной производительности дисков и возможности параллельного выполнения операций, скорость шины должна в несколько раз превышать скорость работы дисков. Скажем, если мы хотим иметь возможность подключить к одной шине хотя бы пять устройств, каждое с собственной скоростью в 20 Мбайт/с, необходима шина со скоростью минимум в 100 Мбайт/с. Из того же, что диск имеет шину на 80 Мбайт/с, ничего узнать о скорости работы самого диска нельзя. Скорее всего, она меньше этих 80 Мбайт/с — иначе диск используется не оптимально.
Для обеспечения параллельного выполнения операций необходима возможность отключения процессора/устройства от шины в тот момент, когда требуется выполнение промежуточных операций наподобие перемещения головок. Как правило, запись на диск происходит за два-три обмена по шине: передача команды «хочу записать блоки по адресу», передача данных, получение признака корректного/некорректного завершении операции.
Устройства могут договориться об оптимальной скорости обмена данными между ними, причем скорость эта может быть различной для разных пар. Учитывая эту скорость и ряд других характеристик, о которых могут договориться устройства, диск может запускать обмен данными с процессором (операция чтения) еще до того, как все данные поступят в кэш, рассчитывая, что остальное удастся добрать на проходе. Аналогичная ситуация и с записью. Все это очень напоминает стандартную задачу с бассейнами и перекачкой воды.
За доставку не отвечаем
Мы говорили о том, что устройства могут выполнять операции параллельно. А возможна ли параллелбность в рамках одного устройства? Естественно — да. В некоторых случаях (RAID-ы) эта параллельность естественная, т.к. в ней участвуют несколько носителей, в других используется та или иная очередность. Например, одновременно два процессора могут обращаться к одному диску. Ясно что при этом операции будут как-то упорядочены. Тут же появляется и вторая роль кэша — удержание данных для нескольких параллельных операций. Более того, для появления параллельности операций нет необходимости в появлении еще одного процессора. Уже SCSI-2 стандарт (про дальнейшие и не говорю) предполагает возможность выполнения до 256 параллельных операций для 8 подустройств от одного инициатора. При этом мы доверяем диску выбор оптимального порядка выполнения. А если этих процессоров-инициаторов на шине много? Умножайте.
Сразу становится ясно, что для обеспечения всего этого кэш диска должен быть фрагментирован. Как правило, никто не пытается за этим явно следить, но способ деления кэша в принципе должен выбираться в зависимости от характера работы и назначения компьютера. Например, при чтении документации на диске Barracuda оказалось, что тот готов использовать либо серверный режим (мало, но больших сегментов), либо режим рабочей станции (наоборот). Выбранный режим фиксируется на диске и используется до его смены.
SCSI-устройства достаточно управляемы. Это позволяет различными способами добиваться повышения производительности. В частности, повышения производительности можно добиваться и за счет игры с целостностью. При этом за часть характеристик отвечает ОС, в разной мере используя предоставленные стандартом возможности, а за часть диск при установке соответствующих характеристик.
Например, одним из великолепных (и не самых опасных) средств ускорения работы устройств является изменение характера работы со статусом операции. Это проявляется в операциях записи. В принципе (целостность!) статус операции определяется только после того, как данные реально запишутся на носитель. Как правило, данные, которые добежали до кэша диска, добегут и до носителя. Что если мы будем считать операцию законченной в тот момент, когда данные будут переданы в кэш? Мы немного рискуем, но не очень сильно. Ведь время между двумя событиями достаточно мало. Реальный риск заключается в синхронизации факта записи с каким-либо другим событием, типа: файл переписан на другой диск, его можно удалить с текущего. И тут облом!
Этот режим выбирается специальными командами установки режима работы и тоже сохраняется на диске.
Другой пример любопытного режима. Предположим, что мы одновременно пишем на диск несколько блоков, которые составляют вместе блок базы данных. Что при этом происходит с головками диска? Возможно, что только в момент поступления 4-5 блока произойдет совпадение и мы сможем начать перенос данных на носитель. Должны ли мы делать это? Это тоже вопрос целостности. Если мы начинаем запись с 4-5 блока, доходим до конца и, прождав оборот, дописываем начало. Что произойдет, если сбой будет при записи 2-3 блока? Окажется, что мы сменили только начало и конец блока базы данных, но не сменили что-то в середине. Обидно. Далее возможно самое интересное. Один из стандартных алгоритмов проверки целостности записи (без проверки самих элементов) проверяет только тот факт, что метка времени в начале логического блока и конце его совпадает. Вау! Тест может ничего не заметить. А скорее всего, именно поэтому возможность начать запись с произвольной точки была предусмотрена как конфигурируемый параметр и отменена по умолчанию в одном из дисков.
Прибытие поезда
Ясно, что это только краткое описание некоторых фокусов некоторых кэшей компьютера. Это очень большая тема, т.к. можно, например, говорить о кэше баз данных, да и сами диски могут быть просто кэшем для библиотеки того или иного типа.
Литература
[1] Микропроцессорные структуры. Инженерные решения. М.: «Радио и связь», 1990
[2] Игорь Облаков. «Открытые системы», 2000, № 4
[3] Игорь Облаков. «Открытые системы», 2000, № 5-6
[4] И.И. Шагурин, Е.М. Бердышев. Процессоры семейства Intel P6 Pentium II, Pentium III, Celeron и др. Архитектура, программирование, интерфейс. М.: Горячая линия — Телеком, 2000
[5] Д. Кнут. Искусство программирования. Третье издание, ИД «Вильямс», 2000
Игорь Облаков (ioblakov@bigfoot.com) — технический директор ЗАО РАПАС (г.Москва)
