

Метакомпьютинг, как подход к организации распределенных вычислений в гетерогенной сетевой среде, завоевал свое место в практике [1]. Теперь, когда сформирован базовый слой программных технологий, самое время приступить к построению следующего уровня — уровня управляемого разделения ресурсов Вычислительной Сети (Grid).
Распределенные вычисления становятся магистральным направлением развития компьютерной индустрии. Например, корпорации Sun Microsystems, Dell и IBM, участвуя в конференции Supercomputing 2000 [2], высказали одинаковую точку зрения на будущее отрасли: на смену отдельным, независимым суперкомпьютерам должны прийти группы высокопроизводительных серверов, объединенных в кластеры. В частности, совместные с компанией America Online планы Sun предусматривают развертывание мощного территориально распределенного суперкомпьютера. И другой аспект: один из архитекторов Вычислительной Сети Ян Фостер опубликовал в почтенном журнале Nature [3] сообщение о сути подхода, адресуя его широкому научному сообществу, претендуя, тем самым, на фундаментальность.
Начиная в ИПМ им. Келдыша работы по распределенным вычислениям, мы понимали, что тема эта обширная, и следует опираться на мировой опыт, поэтому много усилий было потрачено на исследование [4-10] соответствующих программных средств. В практическом плане перед нами ставилась задача создания экспериментального стенда, на котором можно было бы опробовать те или иные решения. Сегодня такой стенд создан и включает сетевой кластер с управляющей системой PBS и Globus. Аппаратная конфигурация расширяется на вторую площадку института, что позволит получить территориально разнесенные узлы. Это дает возможность перейти к реализации проекта программного распределения (диспетчеризации) заданий в Вычислительной Сети.
Вычислительная Сеть
В середине 90-х для именования инициатив по созданию инфраструктуры распределенных вычислений родился термин Grid (мы предлагаем в качестве эквивалента использовать выражение «Вычислительная Сеть»). За прошедшее время этот термин наполнился реальным содержанием, но одновременно стал излишне популярным. Им обозначают совершенно разные вещи от новых сетевых технологий до искусственного интеллекта. В статье [11] лидеры направления излагают свое видение того, что собственно является предметом технологий Вычислительной Сети.
Их цель — создать из отдельных географически распределенных установок интегрированный вычислитель. Такая Вычислительная Сеть (ВС) состоит из обычных компьютерных ресурсов: процессоров, оперативной памяти, внешней памяти, файлов, баз данных. Задача состоит в том, чтобы эти ресурсы можно было использовать независимо от места своего физического расположения.
Иными словами, хотелось бы работать с ВС как с обычным многопроцессорным компьютером. Хотелось бы сохранить такие характеристики вычислительных систем, как предсказуемость и надежность. Подразумеваются и новые свойства: ВС динамически формируется из распределенных узлов, которые могут свободно подключаться и отключаться и управлять выделением своих ресурсов в общее пользование, тем самым в значительной степени сохраняя автономию. На первый план выходят такие характеристики, как масштабируемость архитектуры и защищенность ресурсов.
Поэтому, что в отличие от замкнутых конфигураций, ВС не может ни управляться, ни администрироваться вручную. Эти функции должны выполняться автоматически на основе общих правил управления.
Направления деятельности
Задача создания ВС имеет комплексный характер. Для ее решения необходимо сбалансированное продвижение в трех направлениях: разработка нового класса программного обеспечения, которое и придает коммуникационной сети новое качество; развитие коммуникационной и вычислительной базы; создание приложений, адекватных возможностям среды.
Хотелось бы обратить внимание на несколько обстоятельств. Коммуникационное направление бессмысленно, по-видимому, сводить только к наращиванию мощности сетевого оборудования, увеличению пропускной способности каналов и т.п. Требуются новые решения [12] по управлению сетевым трафиком (например, на основе протокола IPv6), интеллектуальной маршрутизации, обеспечению безопасности, так что первое и второе направления тесно связаны.
Важность третьего направления мы почувствовали на собственном опыте. ВС строится для того, чтобы интегрировать такие объемы ресурсов, на которые прежде никто не мог рассчитывать. Поэтому отсутствие готовых приложений — естественная ситуация, весь вопрос в том, будет ли она меняться? Есть надежды, что будет. Такой оптимизм связан с инициативой отечественного физического (НИИЯФ МГУ, ИТЭФ, ОИЯИ, ИФВЭ, СПИЯФ) и телекоммуникационного (телекоммуникационный центр «Наука и Общество») сообщества по включению российских исследователей в проект обработки данных с ускорителя LHC [13], строящегося в Церне. Это долговременный и широкомасштабный проект, идеально отображающийся на распределенную обработку ВС. В данном случае это будет европейская сеть DataGrid, к которому, как можно надеяться, будет подключен российский сегмент [14].
Однако при всей важности конкретных применений ВС, не следует терять из вида и иной аспект — создание принципиально нового инструмента с новой моделью вычислений. Поэтому, извлекая опыт из практической реализации прикладных проектов [15], в программных и инженерных решениях для ВС приоритет должен отдаваться общим и инструментальным подходам, несмотря на то, что такой путь более труден. Продуктивность инструментального подхода подтверждена практикой, если вспомнить о революционных изменениях, порожденных персональными вычислениями, машинной графикой, Internet. Потенциал технологий ВС не менее высок, а его раскрытие — мощный стимул для информатики в целом, включая и прикладные области, и системное программирование, и инженерные разделы.
 |
| Рис.1. Вычислительная Сеть Пользователь запускает задание, находясь в точке А, задание считается на процессорах в точках B и С, программа для счета хранится на файл-сервере в точке D, а данные должны браться из базы, размещенной в точке E |
Текущее положение
Первые предложения по новому способу организации сетевых вычислений [16] были, как и положено, немного романтическими. Предполагалось конструирование метакомпьютера, охватывающего по крайней мере континент. По мере того, как продумывались конкретные технологии, обнаружилось, что практически все традиционные способы работы в сети нуждаются в пересмотре. В результате возобладал прагматизм, и текущий момент можно охарактеризовать как этап создания ограниченных (корпоративных или региональных), но полноценно функционирующих конфигураций, которые можно интерпретировать как одну из форм виртуальных организаций [11]. Исходная постановка остается все еще отдаленной перспективой по причине отсутствия масштабируемых решений для технологий разделения ресурсов. ВС активно развиваются крупнейшими организациями. Вот только несколько примеров: National Technology Grid (Национальный научный фонд США), Information Power Grid (НАСА), DISCOM (Министерство энергетики США), European Data Grid.
Ограничиваясь только вопросами программного обеспечения ВС, рассмотрим систему Globus, которая даже сейчас является далеко не единственно возможным вариантом. Globus изначально строили снизу вверх, рассматривая в качестве основной цели интероперабельность, т.е. возможность свободного подключения к Сети при условии сохранения управляемой автономии ее участников. Способ достижения этой цели — стандартизация протоколов удаленного доступа к ресурсам, управления ими и их разделения. Любопытно, что другой проект, Legion, первоначально разработанный для Виргинского университета, напротив, начинался со структуры и понятий высокого уровня в духе абстрактных типов данных, но в конце концов пришел почти к тем же самым протоколам, что и Globus.
Система Globus
Globus — это свободно распространяемая с исходными текстами программная система, включающая: утилиты пользователя и администратора, несколько сетевых служб, а также средства разработки. Globus работает на всех наиболее распространенных вариантах Unix.
Архитектура ВС на базе Globus
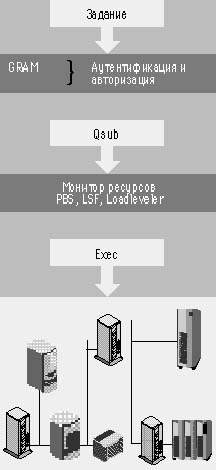 |
| Рис. 2. Архитектура ВС |
ВС, построенная на базе системы Globus, образуется из отдельных локальных пулов компьютеров — Globus-узлов. В каждом узле есть хотя бы один компьютер (шлюз) с установленным программным обеспечением Globus и запущенными сетевыми службами. В последней версии Globus предполагается некоторое структурирование Сети в подмножества узлов, образующих виртуальную организацию с общей политикой безопасности и общей информационной базой. Выполняя утилиты, пользователь одного узла может работать с удаленными ресурсами других узлов при выполнении следующих условий протокола безопасности:
- пользователь должен обладать действующим сертификатом стандарта X.509;
- политика безопасности, установленная администрацией удаленного узла должна признавать этот сертификат;
- владелец сертификата должен быть зарегистрирован на компьютерах узла.
Запущенные на шлюзе службы открывают ресурсы данного узла для доступа извне, поддерживая протоколы обмена, основанные на стеке TCP/IP, безопасности и управления заданиями.
Интерфейс доступа к удаленным ресурсам
Набор пользовательских утилит, состоящий из трех групп — управления заданиями, доставки файлов и информационного обслуживания — образует командную среду, в которой можно выполнить задание на удаленном компьютере и получить с него результаты.
1. Группа управления заданиями включает утилиты globusrun, globus-job-run, globus-job-submit, соответствующие разным вариантам запуска задания на удаленный узел. Как и полагается в Unix, утилиты имеют большое количество опций, которые мы не будем подробно описывать, но приведем общий формат одной из утилит:
globus-job-submit OPTIONS REQUEST
OPTIONS = [-dumprsl] [-dryrun]
[-std{out|in|err}
[-stage] file]
[-mdshost host] [-mdsport port]
[-mdsbasedn baseDN]
[-mdstimeout timeout]
REQUEST = resource [-np count]
[-q queue]
[-p project] [-directory dir]
[-env env_arg [-env env_arg2] ... ]
[-maxtime minutes] [-jobtype jobtype]
[-x sub-RSL] [-stage] executable
[args...]Globus-job-submit осуществляет запуск исполняемого файла в пакетном режиме — с освобождением терминала. Это может быть, например, скрипт или файл типа .EXE, указанный в опции executable. С помощью опций stage может быть заказана доставка на исполняющий компьютер стандартных файлов stdout, stderr, stdin с любых узлов ВС, в частности с узла, на котором выдана команда submit. Во всех командах управления место запуска задается прямым указанием адреса (контактной строки) исполнительного узла в опции resource:
globus-job-submit supercomputer .keldysh.ru /bin/echo «Hello Globus World»
Здесь supercomputer.keldysh.ru — адрес узла, на который направляется выполнение программы /bin/echo (в предположении, что она там есть). В качестве результата globus-job-submit выдает ярлык задания, используемый в следующих командах управления.
Запрос состояния:
globus-job-status https://supercomputer.keldysh.ru: 4526/8849/977215500/
Единственный параметр — это и есть ярлык, пользователь просто копирует его из строки терминала после отработки globus-job-submit.
Получение стандартного вывода:
globus-job-get-output https://supercomputer.keldysh.ru: 4526/8849/977215500/
Снятие задания:
globus-job-cancel https://supercomputer.keldysh.ru: 4526/8849/977215500
2. Доставка файлов данных. Трудно представить программу, которую стоит выполнять удаленно и которая обходится только стандартными файлами. Для пересылки файлов данных предназначена подсистема GASS (а также более продвинутая GSIFTP). Она включает серверную часть, средства запуска сервера, аппарат кэширования и клиентские утилиты для пересылки файлов между двумя узлами, заданными URL. Далее приведен пример одной из утилит копирования:
globus-url-copy [-binary|-ascii] sourceURL destURL globus-url-copy https://gass.globus.org/pub /file.dat /tmp/file.dat
Средства работы с файлами Globus позволяют в принципе организовать доставку необходимых для программы файлов данных на исполняющий компьютер, однако, уровень автоматизации здесь пока явно недостаточен. Запуск задания должен производиться специальным скриптом, осуществляющем подкачку файлов данных средствами GASS до начала выполнения программы.
3. Информационная служба. Утилиты управления Globus могут запускать задания только по конкретному адресу. Каким образом найти в Сети подходящий узел с учетом того, что программа подготовлена для определенной компьютерной платформы и ей требуется некоторый объем ресурсов? Это можно сделать с помощью команд информационного поиска. Ведением базы данных о состоянии вычислительных ресурсов (метаданных) занимается информационная служба MDS. Она базируется на протоколе LDAP [9, 10], наследуя принципы организации информации и способы доступа к ней. В частности поисковые запросы по форме практически совпадают с фильтрами LDAP:
grid-info-search -b ?o=Argonne National Laboratory, o=Globus, c=US? ?(&(objectclass=GlobusServiceJobManager) (manufacturer=sun))? schedulertype contact
В этом примере ищутся узлы Аргоннской национальной лаборатории, располагающие компьютерами Sun, и выводятся их контактные строки (их можно указать в качестве адреса при запуске задания).
Запрос на поиск можно направить на любой шлюз (он указывается в параметрах grid-info-search) с запущенной службой MDS. При этом выбор адресата определяет сферу поиска. В первых версиях Globus поддерживался только один сервер MDS — в Аргоннской лаборатории, и на нем хранились данные обо всех узлах стенда GUSTO. В версии 1.3 перешли на распределенную модель GRIS — GIIS. В этой модели на каждом узле работает локальная база данных GRIS, которая может быть связана с сервером организации GIIS, собирающим данные с нескольких GRIS.
Перечисленные три группы пользовательских утилит образуют представляющийся достаточным арсенал средств, которым располагает пользователь ВС.
Новое качество
Правомерен, тем не менее, вопрос о том, в чем заключается новое качество предлагаемых средств. Казалось бы, командам управления заданиями можно поставить в соответствие telnet, доступ к файлам GASS — это аналог ftp, а информационная служба MDS — база данных. Мы относим к достижениям Globus следующее.
- Разработаны «не интерактивные» варианты протоколов удаленного доступа к ресурсам — работающие без участия пользователя, но от его имени и с его правами. Только благодаря наличию таких протоколов возможно программное управление ВС. Примеры принципиально новых возможностей — запуск задания с параллельной обработкой на десятки и сотни узлов или наш проект программной диспетчеризации заданий.
- Указаны, реализованы или приспособлены для вычислительных задач три «интеллектуальных» протокола: аутентификации (SSL), управления заданиями (GRAM) и информационного обслуживания (LDAP).
- Предложен способ организации ВС в виде иерархии: ресурсный пул — Монитор ресурсов — GRAM.
Элементарная ячейка ВС — узел предполагает определенную внутреннюю организацию. Узел образуется из одного или нескольких компьютеров, объединенных закрытой (локальной) сетью, но для вычислительной Сети они выглядят как совокупность ресурсов с одной точкой доступа — через GRAM. Ресурсный пул имеет общее управление — Монитор ресурсов, который, взаимодействуя с ОС составляющих компьютеров, согласованно распределяет их ресурсы, а также контролирует время и объемы использования. В частности, он регулирует процессорную загрузку компьютеров и распределяет между ними задания. Фактически в качестве Мониторов ресурсов применяются системы пакетной обработки заданий [4], причем Globus поддерживает программный интерфейс с несколькими типами таких систем (Condor, PBS, Loadleveler, LSF и т.д.). Интерфейс реализован в компоненте GRAM — Jobmanager, который, отрабатывая запросы, поступающие от пользовательских утилит Globus, вводит задания в кластер (команда Qsub), управляет ими (Qdel, Qalter) и определяет их состояние (Qstat). Рассмотрим, как работает эта архитектура, интерпретируя дистанционный запуск задания — команду job-submit.
- Паспорт задания (который формируется из опций команды) пересылается на порт второго компонента GRAM — Gatekeeper.
- Gatekeeper производит аутентификацию пользователя по протоколу SSL. Проверяется: достоверность сертификатов пользователя и GRAM (он тоже сертифицирован); наличие закрытых ключей, однако, эти ключи по сети не передаются; доступность данного узла для владельца сертификата в связи с конфигурируемой политикой безопасности узла.
- Если все хорошо, то происходит авторизация пользователя путем фиксированного конфигурационным файлом отображения сертификата в локальный профиль ОС.
- Затем порождается процесс Jobmananger, который производит доставку файлов, устанавливает обратные вызовы для отслеживания состояния и передает задание Монитору ресурсов.
- Монитор ресурсов ставит задание в одну из своих очередей и через какое-то время запускает на счет.
Доступность и разделение ресурсов
Средств системы Globus в известной степени достаточно для работы в распределенной среде, обеспечения глобальной доступности всех узлов Globus, доставки на них файлов и запуска заданий, что и было показано на экспериментальных стендах (GUSTO, I-WAY). Но годятся ли эти средства для промышленной эксплуатации? В своем современном состоянии Globus лишь в малой степени учитывает (компоненты MDS-GIIS, DUROC) коллективный характер использования Сети. Проблема возникает, например, если нужно запустить задачу, а все узлы уже загружены. Тогда у пользователя есть две возможности и обе не из приятных: либо, положившись на удачу, послать задачу на какой-то узел, где оно встанет в очередь Монитора ресурсов, либо периодически продолжать поиск свободного узла.
Диспетчеризация в глобальной среде
Необходимость создания технологий разделения ресурсов осознается многими [17], в том числе и самой командой Globus [11]. На это направлен и наш собственный проект автоматической диспетчеризации заданий в сети, образованной из вычислительных ресурсов нескольких организаций. Идея состоит в том, чтобы ввести новый программный компонент — Метадиспетчер, которому пользователи направляют свои задания для их распределения по свободным исполнительным узлам.
Проект реализован в виде надстройки над стандартными компонентами системы Globus, так что архитектура Сети остается неизменной, представляя собой согласованное объединение узлов Globus. На один из узлов устанавливается Метадиспетчер и запускается поддерживающий его работу интегрирующий информационный сервер GIIS, который собирает данные о состоянии со всех обслуживаемых узлов.
Задания запускаются по фиксированному в пределах сети адресу Метадиспетчера
grid-job-submit metascheduler.keldysh.ru /jobmanager-meta <ресурсный запрос> <стандартные параметры Globus>
и хранятся там, пока Метадиспетчер не найдет свободный подходящий узел. При поиске (диспетчеризации) исполнительного узла для задания: по ресурсному запросу определяется список подходящих для него узлов; периодически и в связи с изменениями состояний узлов производится попытка направить на них задание.
Метадиспетчер добавляет промежуточное звено в цепочке запуска задания, однако базовая функциональность Globus от этого не меняется: из точки запуска можно по-прежнему управлять заданием, а после окончания получить его вывод.
Самое существенное в новой функциональности — диспетчеризация. После того, как задание принято Метадиспетчером, происходит пересылка исполнительного файлов и файла ввода на сервер, где работает Метадиспетчер. Этот дополнительный механизм включен с учетом того, что время ожидания задания в глобальной очереди Метадиспетчера до передачи задания на исполнительный узел может быть значительным, а с машиной пользователя может произойти всякое, например, сбой. Буферизация файлов позволяет отключить машину пользователя сразу после ввода задания.
Способ реализации Метадиспетчера
С точки зрения архитектуры Globus Метадиспетчер можно интерпретировать как интерфейс с Монитором ресурсов, только не отдельного узла, а их совокупности — так сказать, интерфейс следующего уровня. Такое представление удается отразить и на программном уровне: Метадиспетчер реализован в виде компонента Jobmanager специального типа. Gatekeeper, второй компонент интерфейса GRAM, отвечающий за безопасность, используется практически без изменений.
Потребовалась минимальная коррекция, чтобы включить поддерживаемое протоколом SSL полное делегирование полномочий пользователя при передаче сертификата по сети. Таким способом решается задача транзитивной передачи прав в распределенной программной системе: Метадиспетчер наследует контекст безопасности от исходного сертификата и имеет возможность отправить задание на исполнительный узел от имени и с правами пользователя, естественно, без его участия — никакие пароли в этот момент не вводятся.
В целом реализация Метадиспетчера выполнена полностью в рамках протоколов системы Globus с помощью его API-интерфейсов.
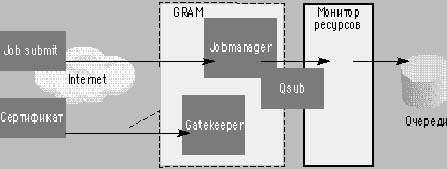 |
| Рис.3. Последовательность запуска задания в системе Globus |
Информационная поддержка диспетчеризации
Диспетчеризация заданий в ВС — один из самых важных архитектурных вопросов. Масштабируемость ВС предполагает, по-видимому, многоуровневое управление. В проектируемой нами ВС оно двухуровневое: нижний уровень — это Монитор ресурсов, верхний — например, Метадиспетчер. Монитор ресурсов, т. е. система пакетной обработки, ведет очереди поступающих к нему заданий и распределяет их по своим ресурсам в локальной сети. Метадиспетчер делает то же самое, но диспетчеризация происходит по множеству, подключенных к нему, Мониторов ресурсов. Естественно, что принимаемые на верхнем уровне решения должны опираться на знания о доступности в данный момент ресурсов, которыми располагает их Монитор.
Рассматриваются два подхода к организации взаимодействия уровней управления. В первом предполагается наличие протокола, по которому Монитор выдает информацию о состоянии своих ресурсов. На этот подход ориентируются создатели Globus, используя для интерфейса команду Qstat, которая есть у всех поддерживаемых систем пакетной обработки — и в этом, пожалуй, главное его достоинство. Понятно, однако, что возможности подобного способа ограничены по двум причинам. Во-первых, выдаваемая Qstat информация ориентирована на пользователей и не содержит многих нужных для диспетчеризации параметров состояния. Действующие установки системы Globus уже столкнулись с необходимостью расширения стандартных средств. Во-вторых, и это более принципиальное обстоятельство, любой набор данных о состоянии будет не полным для планирования, так как ход вычислительного процесса определяется политикой управления Монитора ресурсов. Она устанавливается его администратором, может меняться во времени и описать ее в виде данных, по-видимому, невозможно.
Перспективнее выглядит второй, относительно новый подход, базирующийся на протоколе резервирования ресурсов [18]. В этом варианте Монитор должен быть способен сообщать, в какой момент времени в будущем он может запустить на счет задание с данным запросом к ресурсам. Неприятность, правда, в том, что способностями резервирования обладают пока только такие Мониторы, как Loadleveler и PBS.
Мы считаем, что в архитектуре ВС найдут место оба подхода, а в реализации Метадиспетчера по понятным причинам ориентировались на интерфейс опроса состояния ресурсов.
Реализованная схема диспетчеризации опирается на информационную службу Globus — MDS (Meta Directory Service), представляющую собой совокупность LDAP-серверов со следующей организацией. Во-первых, на каждом шлюзе системы Globus работает служба типа GRIS (Grid Resource Information Service), содержащая данные о состоянии ресурсов — метаданные — своего узла. Во-вторых, на некоторых узлах может быть сконфигурирован сервер типа GIIS (Grid Information Index Server), собирающий метаданные со всех подключенных GRIS-серверов.
Кроме LDAP-серверов к MDS относятся поставщики метаданных — программы, автоматически с определенным периодом запускающиеся на шлюзе, опрашивающие состояния компьютеров узла и обновляющие базу данных GRIS. Несколько поставщиков метаданных включены в дистрибутив Globus, и для того, чтобы посмотреть, какую информацию они собирают, можно выполнить команду grid-info-search. Определен также механизм подключения новых поставщиков.
Метадиспетчер призван решить две задачи. Во-первых, для каждого задания он отбирает те узлы, которые содержат требующиеся ему ресурсы, тем самым гарантируя корректность запуска. Например, в гетерогенной среде может производиться селекция по архитектуре компьютеров или емкости оперативной памяти. Во-вторых, Метадиспетчер хранит задание в собственной очереди, пока не найдется узел, на котором задание будет запущено на счет, а не поставлено в очередь Монитора ресурсов.
Поскольку Метадиспетчер распределяет задания между несколькими узлами, он использует службу GIIS, выдавая поисковые запросы для получения контактных адресов подходящих узлов. Далее полученный список упорядочивается по текущей загрузке процессоров и делаются попытки запустить задание на каждый узел по порядку. Диспетчеризация выполняется периодически, либо в связи с изменением состояний ресурсов: завершением задания, поступлением нового и т. д.
Даже в рамках такой простой схемы Метадиспетчер должен располагать информацией о конфигурации вычислительных установок (платформа, число процессоров) и о текущем состоянии их ресурсов (загрузка процессоров, свободная память). Различие в том, что в первом случае речь идет о статической информации, а во втором — о динамической. Однако стандартные поставщики в системе Globus собирают метаданные только с одного компьютера — шлюза узла. Поэтому мы дополнили Globus программой, выдающей данные о каждом компьютере кластера.
Заключение
Сегодня уже можно реально строить Вычислительную Сеть; по крайней мере, программные средства для этого имеются, например, Globus. Конечно, можно говорить о недостатках реализации, неэффективности каких-то компонентов и отсутствии той или иной функциональности. Важно другое: в Globus предложен хороший способ организации ВС, заложена основа программного обеспечения, которое действительно работает. Но система Globus сама по себе не создает ВС, даже если ограничиваться программными вопросами. Как и для всякой распределенной системы управления, необходим комплекс мероприятий по формированию интегрированной среды. Можно предложить следующую последовательность действий.
- Организация узлов. Налаживается коллективная обработка заданий в локальной сети: устанавливается Монитор ресурсов, обеспечивается однородный (по всем компьютерам) доступ к файловой системе, конфигурируется ПО Globus.
- Политика безопасности. Согласуется политика безопасности по всей Сети: налаживается служба сертификации пользователей и их регистрации на компьютерах. На установках системы Globus производится согласованное конфигурирование прав доступа [19].
- Информационная служба. На одном из узлов запускается интегрирующий сервер GIIS. На остальных узлах конфигурируется связь местного сервиса GRIS с общим сервером GIIS.
- Метадиспетчер. Как дополнительное программное обеспечение для централизованного управления заданиями на узле с сервером GIIS может быть установлен Метадиспетчер.
ВС будет работать даже через Internet, однако решение сформулированной в начале статье задачи — работать с ней как с одним компьютером, — еще впереди. Globus предоставляет хорошую базу, в том числе для развития, что и демонстрирует проект Метадиспетчера, но на роль полноценной Сетевой операционной среды пока не претендует.
Литература
[1] В. Коваленко, Д. Корягин. Вычислительная инфраструктура будущего. «Открытые системы», 1999, № 11-12
[2] Дэн Нил. Кластеры вместо суперкомпьютеров. Computerworld Россия, 2001, № 2
[3] http://www.nature.com/nature/webmatters/grid/grid.html
[4] В. Коваленко, Е. Коваленко. Пакетная обработка заданий в компьютерных сетях. «Открытые системы», 2000, № 7-8
[5] В. Коваленко. Проблемы сетевых файловых систем. «Открытые системы», 1999, № 3
[6] Е. Хухлаев. Metamake — средство подготовки программ в сетевой гетерогенной среде, Препринт ИПМ РАН, № 28, Москва, 1999
[7] Д. Волков. Дума о миграции. «Открытые системы», 1999, № 4
[8] Д. Волков. Кластерная система Condor. «Открытые системы», 2000, № 7-8
[9] М.К. Валиев, Е.Л. Китаев, М.И. Слепенков. Служба директорий LDAP как инструментальное средство для создания распределенных информационных систем. Препринт ИПМ РАН, № 23, Москва, 2000
[10] М.К. Валиев, Е.Л. Китаев, М.И. Слепенков. «Использование службы директорий LDAP для представления метаинформации в глобальных вычислительных системах. Препринт ИПМ РАН, № 29, Москва, 2000
[11] I. Foster, C. Kesselman, S. Tuecke. The Anatomy of the Grid: Enabling Scalable Virtual Organizations. http://www.globus.org/research/papers/anatomy.pdf
[12] В. Васенин. Internet: от настоящего к будущему. «Открытые Системы», 2000, № 12
[13] А. Шевель. Технология GRID. «Открытые системы», 2001, № 2
[14] В. Кореньков, Е. Тихоненко. Организация вычислений в научных отраслях. «Открытые Системы», 2001, № 2
[15] S. Barnard, R. Biswas, S. Saini, R. Van der Wijngaart, M. Yarrow, L. Zechter, I. Foster, O. Larsson. Large-Scale Distributed Computational Fluid Dynamics on the Information Power Grid using Globus, http://www.globus.org/documentation/incoming/paper1.pdf
[16] C. Catlett and L. Smarr. Metacomputing. CACM, 35(6): 44-52, 1992
[17] http://www.cs.nwu.edu/~jms/sched-wg/
[18] I. Foster, C. Kesselman, C. Lee, R. Lindell, K. Nahrstedt, A. Roy. Advance Reservations and Co-Allocation. http://www.globus.org/documentation/incoming/iwqos.pdf
[19] Ян Фостер и др. Инфраструктура аутентификации в национальном масштабе. «Открытые системы», 2001, № 2
Виктор Коваленко (kvn@keldysh.ru), Евгения Коваленко, Дмитрий Корягин, Эдуард Любимский, Евгений Хулаев — сотрудники Института прикладной математики им. М.В. Келдыша РАН.
Один из наиболее значимых результатов по распределенной обработке данных получен в проекте IPG (НАСА) [15]. В 1999 году были опубликованы результаты счета сильно связанного программного кода из области аэродинамики на двух удаленных машинах. В численных экспериментах моделировался воздушный поток, обтекающий возвращаемый космический аппарат.
Моделирование производилось с помощью модифицированной версии известной программы Overflow на компьютерах SGI Origin 2000. На каждом временном шаге рассчитывались значения переменных потока, путем разбиения окружающего пространства на несколько сотен перекрывающихся сеток переменного размера и формы. В исходном варианте Overflow устроена таким образом, что для точек на границах сетки она ждет значений от всех смежных сеток и только затем вычисляет новое значение граничных точек. В параллельном варианте сетки распределяются по разным процессорам. Если две смежные сетки попадают на один процессор, время межсеточного обмена пренебрежимо мало. Если же они обрабатываются разными процессорами, обмен происходит в виде сообщений протокола MPI. Внутри одного компьютера время передачи сообщения остается небольшим, однако оно существенно возрастает, когда процессоры находятся на удаленных машинах. Понимая это, в НАСА использовали метод «отложенного обновления границ», в котором для вычисления точек на шаге (n+1) используются значения шага (n-1), а коммуникации совмещаются с вычислениями.
При счете по оригинальной версии Overflow-D2 на двух близких Origin 2000, соединенных каналом HIPPI, среднее время на один шаг составило 16,2 с. Отложенное обновление границ уменьшило время до 12,7 с. При этом точность результатов оказалась почти такой же. Самым интересным был третий тест на двух Origin 2000, разнесенных на расстояние 1800 миль. В этом тесте коммуникации строились на базе Globus, точнее, на MPICH-G, Internet-версии интерфейса MPI. Как и ожидалось, скорость упала до 21,4 с на шаг, однако не это самое важное. Была продемонстрирована возможность счета сильно связанных программ в глобальных сетях с хорошей точностью и с умеренным падением производительности. Стали понятны узкие места и способы их исправления. В распределенном тесте для коммуникаций использовалось Internet-соединение DS3, которое существенно медленнее HIPPI и не обеспечивает асинхронной доставки сообщений, что необходимо для отложенного обновления границ. При этом время на коммуникации оставалось меньше времени счета шага. Поэтому развитие работ предполагает поддержку асинхронности, например, с помощью выделения коммуникационного процессора.
Реализация Метадиспетчера средствами Globus
Евгений Хухлаев, Алексей Ермаков, Константин Никитин, Виктор Коваленко, Елена Толстова
Концепция Вычислительной Сети позволяет за счет программных решений и стандартного сетевого оборудования получить из географически распределенных ресурсов вычислительные мощности, намного превосходящие возможности современных суперкомпьютерных архитектур. В работе разбирается способ реализации Метадиспетчера — системы управления заданиями в гетерогенной вычислительной Сети в виде надстройки над базовым программным аппаратом — Globus. Метакомпьютерная система Globus была выбрана в качестве базовой при разработке Метадиспетчера, потому что в ее рамках создан значительный задел в этих направлениях. Кроме «готовых к употреблению» и доступных в исходных текстах комплексов программ Globus предлагает набор API-интерфейсов вместе с соответствующими библиотеками, позволяющих реализовать собственные комплексы или модифицировать уже готовые.
В реализуемом проекте Метадиспетчера применяются пока несложные методы планирования, однако при дальнейшем развитии проекта авторы рассчитывают на использование методов, применяемых эффективными планировщиками, работающими в локальных мониторах ресурсов, считая, что разумное планирование в Сети невозможно без привлечения механизмов резервирования ресурсов.
Работа выполнена при финансовой поддержке Российского фонда фундаментальных исследований (проект № 99-01-00389) и Министерства промышленности, науки и технологий РФ (гос. контракт № 203-3(00)-П).
Авторы статьи — сотрудники ИПМ им. Келдыша РАН. С ними можно связаться по адресу huh@keldysh.ru.
