

Рассмотрены, в частности, пути решения проблемы задержек, особенности различных архитектур, построенных на использовании коммутаторов. Приведены краткие сведения о подсистеме ввода/вывода и конструктивных особенностях AlphaServer GS, дано сопоставление архитектурных характеристик этих серверов и аналогичных систем, в частности, систем ссNUMA последнего поколения.
На сегодняшний день архитектура ccNUMA больших многопроцессорных серверов является наиболее совершенной и вместе с традиционной МРР-архитектурой с распределенной (как физически, так и логически) оперативной памятью определяет погоду на рынке суперкомпьютерных систем. Из пяти ведущих производителей мощных серверов (IBM, Hewlett-Packard, Compaq, SGI и Sun Microsystems) первые четыре предлагают системы архитектуры ccNUMA. Возможно, в недалеком будущем к ним присоединится и Sun.
Говоря «наиболее совершенная» по отношению к ccNUMA, я имею в виду, что по сравнению с обычной архитектурой МРР она поддерживает две важнейшие дополнительные функции: представление физически распределенной оперативной памяти как (логически) общего поля памяти для всех процессоров сервера, и обеспечение когерентности кэшей этих процессоров. Поскольку данные особенности являются дополнительными по отношению к обычной МРР-архитектуре, ccNUMA является, очевидно, и более сложной в реализации.
В статьях [1,2] рассмотрена архитектура ccNUMA-систем нового поколения, появившихся в прошедшем году, — SGI Origin 3x00 и HP Superdome соответственно. Однако в 2000 году было представлено три новых ccNUMA-сервера, и хронологически первым из которых был Compaq AlphaServer GS (модели GS80/160/320), хотя его регулярные поставки начались лишь в конце года [3]. Важнейшие особенности всех трех систем, как показано в [2], оказались весьма близки. Здесь я уделю больше внимания некоторым ключевым особенностям архитектуры серверов GS, в частности, обсуждению задержек по обращению в оперативную память. Эти вопросы принципиально важны для архитектуры ccNUMA как таковой. Изложение в этой части основывается главным образом на публикации [4], которая является основным источником информации о деталях архитектуры ccNUMA-серверов AlphaServer GS.
Серверы серии GS продолжают линию серверов на базе процессоров Alpha, восходящую еще к DEC AlphaServer 8200/8400. Вместо этих систем Compaq выпускает сейчас серверы GS60E и GS140 соответственно, обладающие сходной SMP-архитектурой. Во всех серверах серии GS применяются процессоры Alpha 21264 [5], но по остальным характеристикам ccNUMA-системы GS80, GS160 и GS320 ушли от своих предшественников далеко вперед, что не удивительно, поскольку серверы 8400 были выпущены еще пять лет назад. Для краткости далее под термином «серверы GS» в этой статье будут пониматься только модели с архитектурой ccNUMA.
Архитектура серверов GS
 |
| Рис.1. Архитектурная схема серверов GS320 |
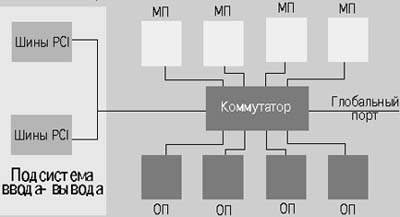
На рис. 1 приведено общее строение узла серверов GS. По аналогии с МРР, в архитектуре ccNUMA для обозначения основного строительного блока наиболее употребим именно этот термин. Производители обычно используют собственные названия, например, Compaq называет такие узлы QBB (Quad Building Block), что указывает на наличие в узле до 4 процессоров.
QBB построен на процессоре Alpha 21264A/731 МГц с внешним кэшем второго уровня емкостью 4 Мбайт, а также содержит подсистему ввода-вывода и оперативную память. Все эти компоненты соединены между собой посредством локального коммутатора, порты которого имеют пропускную способность 1,6 Гбайт/с. Однако имеется еще один порт, который связывает QBB между собой и обладает пропускной способностью, равной 3,2 Гбайт/с. Таким образом, суммарная пропускная способность коммутатора — 17,6 Гбайт/с.
Два модуля QBB могут быть соединены этими портами межсоединения напрямую, что позволяет построить 8-процессорную конфигурацию (модели GS80). Для построения более мощных конфигураций в серверах GS применяется глобальный коммутатор, к портам которого подключаются порты межсоединения всех QBB (рис. 2). К глобальному коммутатору можно подсоединить до 8 QBB, что отвечает максимальной конфигурации в 32 процессора.
 |
| Рис.2 Модуль QBB |
Подобно архитектуре других ccNUMA-cистем, применение двухуровневых коммутаторов позволяет линейно масштабировать пропускную способность ввода/вывода, пропускную способность и емкость памяти и процессорные ресурсы путем добавления модулей QBB. Масштабируется также и межсоединение: задействуются порты глобального коммутатора. Недостатком такого подхода по сравнению с SMP-архитектурой является, как известно, дополнительная задержка, возникающая при обращении процессора к оперативной памяти, находящейся физически в другом QBB. Подобные задержки — единственный фактор, препятствующий эффективному применению при распараллеливании обычной SMP-модели общего поля памяти.
Производительность архитектуры ccNUMA
Как уже отмечалось, проблема задержек является центральной для архитектуры ccNUMA и ее целесообразно рассмотреть подробнее.
Более общей проблемой, нежели задержки при обращении в удаленную оперативную память, является обеспечение высокой производительности ccNUMA-серверов. Здесь важны не только очевидные базовые параметры — производительность процессора, пропускная способность оперативной памяти при обращении к локальной памяти и т.п., но и характеристики, обеспечивающие высокий «КПД» использования этих базовых параметров при решении распараллеленных задач в многопрограммном режиме.
Можно различать три основных варианта распараллеливания [4].1) Отсутствие разделения ресурсов и данных: однонитевая программа при отсутствии иной нагрузки.
2) Разделение ресурсов, но не данных: на компьютере выполняется много не взаимодействующих между собой нитей-процессов.
3) Разделение и ресурсов, и данных: как и в предыдущем случае, но нити могут взаимодействовать через общее поле памяти.
Наиболее однозначен, очевидно, анализ первого случая. В [4] для него вводится понятие задержки ненагруженной (idle) системы и более общее понятие задержки запроса (demand latency). Задержка запроса — это время, которое нужно функциональным устройствам процессора, чтобы «добраться» до команд и данных. Для уменьшения задержек запроса используются хорошо известные методы — предварительная выборка в кэш, внеочередное спекулятивное выполнение команд и др.
Современные суперскалярные микропроцессоры способны выдавать в вычислительную систему несколько одновременно обрабатываемых запросов к памяти (outstanding request). Задержки при обработке подобных запросов [4] названы видимыми (perceived) и зависят от задержки ненагруженной системы, пропускной способности памяти и числа одновременно обрабатываемых запросов. С увеличением последнего параметра видимая задержка уменьшается, производительность системы растет. Если пропускная способность памяти недостаточно велика, а число одновременно обрабатываемых запросов большое, пропускная способность станет узким местом системы. Таким образом, от архитектуры требуется:
- поддержка низких задержек ненагруженной системы;
- повышение числа одновременно обрабатываемых запросов;
- поддержка пропускной способности памяти на уровне, достаточном для обслуживания всех одновременно обрабатываемых запросов, которые может выдать процессор.
Теперь можно перейти к рассмотрению ситуации, для которой характерно наличие многих одновременно выполняющихся независимых нитей (вариант 2 — например, когда рабочая нагрузка представляет собой смесь нераспараллеленных задач). В этом случае все приведенные для однонитевого случая требования должны применяться ко всем процессорам — задержка ненагруженной системы должна оставаться минимальной, несмотря на увеличение числа процессоров и емкости памяти; пропускная способность памяти должна пропорционально увеличиваться так, чтобы, в частности, не возникло ограничений на число одновременно обрабатываемых запросов в расчете на один процессор и чтобы каждый процессор смог бы достичь свой наилучшей видимой задержки. Для достижения этих целей необходимо иметь эффективную подсистему оперативной памяти и межсоединения.
Подсистемы оперативной памяти и межсоединение
Конечно, всегда хочется иметь память большой емкости и с большой пропускной способностью. Разработчики серверов GS проанализировали факторы, влияющие на пропускную способность памяти, в первую очередь при случайных обращениях в оперативную память, а также в «патологически плохих» ситуациях. Естественно, речь не идет о том, что RDRAM может обеспечить пропускную способность большую, чем SDRAM, и т.п. — имеется в виду архитектура подсистемы памяти на «макроуровне». Было обнаружено, что наиболее важны структура расслоения (чередования адресов) оперативной памяти и топология подсоединения блоков памяти. Наиболее эффективным здесь является расслоение между портами памяти в коммутаторе. Второе по важности — расслоение между независимо связанными массивами SDRAM (independently interconnected array), где ограничением является пропускная способность порта памяти. Наконец, наименее эффективно расслоение внутри SDRAM — оно ограничивается пропускной способностью на контактах SDRAM-модулей (хотя при последовательном обращении в память оно помогает).
В серверах серии GS имеется до 32 портов памяти с расслоением, до 64 портов независимо связанных массивов памяти, а еще 4-кратное расслоение внутри SDRAM, что обеспечивает в максимальной конфигурации 32-процессорных серверов GS320 (8 QBB) 256-кратное расслоение памяти. Насколько известно автору, это пока уникальный для отрасли показатель.
Емкость оперативной памяти узла QBB достигает 32 Гбайт, а сервера в целом — 256 Гбайт. Память в QBB распределяется между четырьмя конструктивами «несущих». Сегодня поставляются модули памяти емкостью 1, 2 или 4 Гбайт [6].
Для того чтобы максимально использовать потенциал высокой пропускной способности памяти узла QBB (6,4 Гбайт/с), в серверах GS используется две специальные стратегии: агрессивное планирование ресурсов памяти и агрессивное управление пропускной способностью каналов данных. Первая поддерживается специальной логикой в QBB, обеспечивающей переупорядочивание до 28 запросов к памяти. Вторая основана на буферизации запросов полузаказными микросхемами (ASIC) в локальном и глобальном коммутаторах. (По утверждению самой Compaq [4], коммутаторы в HP V2600 и Sun UE10000 не имеют средств буферизации.) Подобная буферизация позволяет эффективно обрабатывать конфликтные ситуации при обращении к одному «выходному» порту коммутатора сразу из нескольких «исходных» портов.
Важным фактором, влияющим на поддержание высокой пропускной способности памяти в серверах GS, является отказ от разделения порта коммутатора сразу несколькими процессорами. Такая ситуация типична для многих современных многопроцессорных серверов (в частности, для НР V2600, Sun UE10000 [7], SGI Origin 3x00). Как уже отмечалось, это может стать потенциально узким местом архитектуры.
Еще одна важная особенность архитектуры GS — принцип низкой занятости (occupancy). Под занятостью понимается время, в течение которого запрос занимает ресурс компьютера. Теоретически сервер GS может поддерживать до 500 одновременно обрабатываемых запросов (на практике — 200-300) [4]. Как низкая занятость, так и отказ от разделения процессорных портов коммутатора разными процессорами позволяют уменьшить видимую задержку в серверах GS.
Теперь мы можем обратиться к соотношению локальных задержек — при обращении в локальную (внутри QBB) и удаленных задержек (в памяти других QBB). Локальная задержка ненагруженной системы в QBB составляет примерно 330 нс. Аналогичная задержка по отношению к удаленной памяти почти втрое больше — 960 нс. Это существенный прогресс по сравнению с системами ccNUMA предыдущего поколения.
В [4] среднюю задержку Тс определили как
Тс = Тл?рл + Ту?qу (1),
где Тл — локальная задержка ненагруженной системы, Ту — удаленная задержка ненагруженной системы, рл — доля обращений к локальной памяти, ру — доля обращений к удаленной памяти (ру = 1-рл). Однако следует отметить, что методики определения задержек разными производителями отличаются в деталях; задержки могут быть по чтению из памяти или по записи в память, а также зависят от более тонких факторов.
Программное обеспечение, в частности, ОС, также может непосредственно влиять на задержку. В частности, ОС Unix для систем ccNUMA позволяет влиять на расположение страниц памяти (в локальной или удаленной памяти). Другой пример — кэширование памяти в узлах системы ccNUMA; подобный кэш появился еще в серверах Convex SPP1x00 [8]. Все это означает, что к прямому сопоставлению задержек разных систем ccNUMA надо подходить осторожно. Поэтому, хотя формально соотношение локальной и удаленной задержек в SGI Origin 3x00 и HP Superdome по приводимым производителями данным оказывается лучше (близко к 1:2 для SGI Origin 3x00), по мнению Маккалпина, автора тестов STREAM для пропускной способности оперативной памяти, можно говорить лишь о незначительном преимуществе этих систем перед GS [2].
Тем не менее, имеет смысл привести некоторые известные данные, которые можно использовать в качестве своего рода первого приближения. Локальная задержка (на тракте процессор-маршрутизатор-память) в Origin 2000 составляет cвыше 300 нс (там устанавливается два процессора на узел), в Origin 3x00 она уменьшена до 180 нс. В HP Superdome локальная задержка составляет 260 нс, а удаленная — до 415 нс. С увеличением числа портов на коммутаторе задержка возрастает (в HP V2200 она равна 540 нс), и соответственно падает с уменьшением числа процессоров в системе безотносительно к тому, используется ли коммутатор или обычная системная шина SMP-компьютеров (в 8-процессорном HP N4000 задержка равна 130 нс).
Наконец, интересно сопоставить задержку серверов GS c задержками Sun UE10000, которые, можно считать, имеют SMP-архитектуру и, наряду с HP Superdome и SGI Origin 3x00, потенциально конкурируют с серверами Compaq. Задержка ненагруженной системы в UE10000 составляет 600 нс. Если в серверах GS свыше 55% ссылок локальны, средняя задержка ненагруженной системы оказывается лучше, чем в UE10000. Если же локализация обращений в память оказывается хуже, ситуация меняется на противоположную [4]. Еще раз напомним, что данный вид задержек — лишь один из компонентов видимой задержки.
Теперь, с учетом приведенного общего анализа, нетрудно провести некоторое сопоставление различных возможных типов архитектур. Очевидно, идеальной по задержкам была бы архитектура с одним небольшим коммутатором, однако, это ограничивает масштабируемость сервера из-за небольшого числа портов коммутатора. Если коммутатор будет иметь много портов, сильно возрастает задержка ненагруженной системы. Если вместо этого заставить процессоры и память разделять порты (это, в частности, имеет место в Sun UE10000, HP V2600 и SGI Origin 3x00), можно ограничиться средним числом портов, и задержка ненагруженной системы будет приемлема. Но разделение портов может существенно ограничить пропускную способность системы, поэтому разработчики серии GS пошли иным путем — в созданной ими архитектуре осуществляется двухуровневая коммутация: маленькие коммутаторы внутри QBB соединяются через глобальный коммутатор (рис. 2).
По оценкам [4], даже если 75% трафика — это обращения к удаленной памяти, то при наличии четырех одновременно обрабатываемых запросов в расчете на один процессор иерархическая коммутация дает лучшие видимые задержки, чем архитектура с разделением портов. Если же 50% трафика локальны, то достаточно уже двух одновременно обрабатываемых запросов на процессор. Из этого разработчики серии GS сделали вывод, что иерархическая система коммутаторов — лучшая архитектура для видимых задержек. Как уже отмечалось, в HP Superdome и SGI Origin 3x00 также применяется сходный архитектурный подход.
Хотя здесь больше внимания уделялось задержкам, весьма важен высокий уровень пропускной способности для работы с памятью как таковой. Данные тестов STREAM свидетельствуют, что по этому параметру серверы GS лидируют [1].
Когерентность кэша
Мы рассмотрели два типа нагрузки из трех (одна нить и несколько независимых нитей). Теперь же можно обратиться к производительности системы в ситуации нескольких взаимодействующих нитей. К обычным для предыдущих случаев требованиям (минимальная занятость, высокая пропускная способность без узких мест в архитектуре, эффективная подсистема памяти и др.) добавляются новые требования — обеспечение когерентности кэш-памяти процессора и согласованности данных в памяти. Эти требования возникают при распараллеливании в модели общего поля памяти.
При обеспечении когерентности кэша и согласованности работы процессоров с оперативной памятью возникает дополнительный трафик, и необходимо, чтобы это не оказалось фактором, ограничивающим пропускную способность при масштабировании конфигурации (росте числа процессоров и емкости памяти). Конкретнее, при этом не должны увеличиваться задержки и занятость [4].
Наиболее часто в SMP-системах применяются схемы поддержки когерентности, основанные на snoop-протоколе. Этот протокол, однако, создает существенный дополнительный трафик, «съедая» часть пропускной способности в больших SMP-серверах. В ccNUMA-серверах обычно используются схемы обеспечения когерентности, основанные на памяти каталогов [9]. Традиционные схемы с полными (исчерпывающими) каталогами, в которых каждому блоку памяти и любому процессору ставится в соответствие определенное число бит, удовлетворяет всем указанным требованиям. Однако по мнению разработчиков GS, увеличение емкости памяти каталогов делает эту схему экономически невыгодной.
Другой подход — схемы с управляемыми (кэшируемыми) каталогами. При этом достигается хорошая пропускная способность, но из-за реализации политики замещения кэша возрастает занятость. В серверах GS используется модифицированная схема с полными каталогами, в которой ограничена длина битовых строк, имеющихся для всех блоков памяти. При этом обеспечивается хорошая пропускная способность и занятость при относительно небольшой стоимости данного решения. Применяемая в этой схеме дополнительная память тегов распределена между всеми модулями QBB. Очевидно, что с увеличением емкости разделяемых данных и взаимозависимости нитей по данным средние задержки будут возрастать.
В ряде схем поддержки когерентности кэша разрешение ситуации зависимости по данным осуществляется путем повторения обращения процессора к памяти. Это происходит, когда обращение идет к области памяти, к которой уже имеется обрабатываемое обращение. При этом задержки могут возрастать непредсказуемо. В других схемах такое обращение к оперативной памяти не отвергается, а ставится в очередь ожидания. Используемая для организации таких схем аппаратура вызывает повышение занятости, что отрицательно сказывается на видимых задержках.
В серверах серии GS применяется новый протокол когерентности кэша, в котором отсутствуют постановка в очередь ожидания или повторение запросов, и обеспечивается низкая задержка. В этом протоколе дополнительные задержки возникают только у обращений, имеющих зависимость. Подробности этого протокола, а также описание схем реализации согласованности памяти в серверах GS можно найти в [4].
Подсистема ввода/вывода и конструктивные особенности
Обратимся теперь к особенностям реализации подсистемы ввода/вывода и тесно связанными с ними конструктивными особенностями серверов [6, 10].
Подсистема ввода/вывода QBB содержит до 8 шин PCI и до 28 PCI-адаптеров. Пропускная способность порта коммутатора — 1,6 Гбайт/с, что больше, чем пропускная способность ввода/вывода у целого SMP-сервера класса GS60E/GS140 (1,2 Гбайт/с). Всего в ccNUMA-cерверах GS320 до 64 шин PCI и до 224 PCI-слотов (против максимум 144 слотов в GS140).
Некоторые конструктивные особенности GS можно продемонстрировать на примере старшей модели этого ряда — GS320. Этот сервер включает не менее 3 шкафов (в том числе, шкаф электропитания системы), а также может содержать дополнительные «ящики» (drawer) — дисковые полки StorageWorks или «корзины» PCI. Применение конструктива ящиков обеспечивает целый ряд преимуществ, в том числе повышает надежность и модульность.
В главном (master) ящике ввода-вывода 13 PCI-слотов, два последовательных и один параллельный порты и порты клавиатуры и мыши. Он содержит также интегрированный адаптер FastEthernet и UltraSCSI-шину для подключения системной консоли. Стандартно в GS320 имеется 14 отсеков для жестких дисков (могут применяться диски емкостью 9, 18 или 36 Гбайт, суммарно до 504 Гбайт. В минимальную конфигурацию входит также модуль QBB, модуль памяти 1, 2 или 4 Гбайт, CD-ROM и жесткий диск емкостью 9,1 Гбайт. Добавляемые PCI-корзины содержат по 4 PCI-шины (2 шины по 4 слота плюс 2 шины по 3 слота), всего до 16 PCI-корзин, итого до 64 PCI-шин и 224 PCI-слотов. Однако операционные системы Tru64 UNIX и OpenVMS имеют некоторое ограничение: в одном аппаратном разделе может быть не более 26 PCI-адаптеров и не свыше 26 SCSI-контроллеров.
Следует отметить большие возможности применения концентраторов UltraSCSI, а также устройств Fibre Channel, в том числе концентраторов и коммутаторов. Все эти технические детали сами по себе, возможно, и не столь интересны, но поскольку подобные вещи используются в сетях хранения (SAN — storage area network) и имеются еще PCI-платы для образования кластерных конфигураций с каналами Memory Channel, подсистема ввода/вывода GS предоставляет пользователям очень широкие возможности. При необходимости можно в дополнительных шкафах разместить PCI-корзины и полки StorageWorks с внешними устройствами.
Учитывая универсальное (с точки зрения областей применения) предназначение GS-cерверов, разработчики уделили особое внимание средствам повышения надежности, отказоустойчивости и обеспечения непрерывной доступности. В частности, и с этими целями в серверах GS обеспечена поддержка аппаратного разбиения всей системы на разделы. Сompaq обеспечила также более гибкую систему динамического разбиения серверов, работающих под управлением OpenVMS со средствами Galaxy. В этом варианте разбиение на разделы происходит под управлением ядра ОС и служит для целей планирования рабочей нагрузки. Этот метод передачи ресурсов между приложениями характеризуется низкой задержкой [11].
В числе других особенностей, направленных на повышение надежности, укажем на применение ЕСС-кодов в памяти и межсоединении. Такими кодами защищена, в частности, передача информации, связанная с обеспечением когерентности кэша. В серверах GS обеспечена возможность применения избыточных вентиляторов и блоков питания по схеме «N+1». Поддерживается горячая замена блоков питания, подсистемы ввода/вывода и процессорных модулей, содержащихся в QBB.
В состав AlphaServer GS входит также специальная сеть микроконтроллеров диагностики, управления и мониторинга состояния. Кроме того, имеется управляющая консольная машина, работающая от собственного источника питания, что обеспечивает возможность сервисного обслуживания даже при отказе процессора или основного источника питания сервера.
Производительность
Интересно отметить, что хотя процессоры Alpha 21264A, используемые в серверах Compaq архитектуры ccNUMA, имеют наибольшую тактовую частоту, по характеристикам внешней кэш-памяти они уступают процессорам в серверах DS20E. В последних применяются Alpha 21264/667 МГц, но с кэшем второго уровня емкостью 8 Мбайт — вдвое больше, чем у Alpha 21264/731 МГц в серверах серии GS. Кэш второго уровня в DS20E построен по более совершенной технологии DDR SRAM, что повышает его пропускную способность. Поэтому в DS20E, имеющим всего два процессора, задержки памяти значительно ниже, чем в GS. В результате показатели SPECint95/fp95 для DS20E составляют 40,1/83,6 против 39,5/58,8 в серверах GS (для сравнения, для HP N4000 с процессорами PA-8600/550 МГц эти показатели равны 41,4/58,8).
SPEC95 дают оценку производительности одного процессора; естественно, что в задачах с большим числом используемых процессоров и соответственно с большим числом выполняемых нитей серверы GS оставят DS20E далеко позади. Compaq приводит также результаты, показанные на тестах SPECint_rate95/SPECfp_rate95, которые характеризуют производительность серверов в многозадачной среде и показывают превосходство GS над системами IBM SP2, HP V2600, Sun UE10000, Fujitsu GP7000F. Аналогичные результаты получаются при использовании тестов SPECint_rate2000/SPECfp_rate2000, на которых GS опережают, в частности, IBM SP2, HP N4000 и SGI O2200. Что касается тестовых данных по SPECint2000/fp2000, характеризующих производительность процессоров, то с учетом лидерства Alpha 21264A по производительности результаты и здесь оказались вполне предсказуемыми: процессоры в GS320 обгоняют процессоры IBM SP2, HP N4000 и SGI O2200 [12].
Пока нет данных для тестов, традиционно используемых для научно-технических приложений, например, Linpack. Однако компанией приводятся результаты замеров производительности на тестах SAP R/3 Tier 2 (продажа и дистрибуция), где серверы GS также обгоняют конкурентов. В качестве другой иллюстрации можно указать на результаты тестов в области систем поддержки принятия решений TPC-H (300 Гбайт), где по обрабатываемым запросам в час (QphH) 32-процессорный Compaq GS320 опередил 32-процессорную IBM NUMA-Q 2000 и 32-процессорный сервер HP 9000 V2500 (табл. 1).
На основании доступных публикаций от Compaq складывается впечатление, что разработчики компании стали больше уделять внимания применению больших систем AlphaServer в сложных коммерческих приложениях, в то время как раньше упор делался на приложения расчетного характера. К сожалению, на момент подготовки статьи единственными данными, позволяющими осуществить прямое сопоставление производительности серверов GS и других систем ccNUMA последнего поколения, оказались результаты тестов ТРС-С. По их данным 32-процессорные серверы GS320 достигли производительности 155179 tpmC, что чуть ниже, чем у 64-процессорного Sun UE10000 (156873 tpmC), и уступает 48-процессорному HP Superdome (197024 tpmC). Лидером же среди серверов оказался IBM eServer pSeries 680 (220807 tpmC при 24 процессорах). Кроме того, что эти результаты разумно сопоставлять при равном числе процессоров, известно, что эти тесты характеризуются аномально большой зависимостью от разных факторов, в частности, от используемого программного обеспечения и деталей конфигурации системы. Пока же результаты оценки производительности серверов GS говорят о лидерстве этих систем в данном классе архитектур с близким числом процессоров. Однако не меньшее, если не большее значение имеет сама архитектура GS, — использованные в ней решения принципиально важны для развития архитектуры ccNUMA, как таковой.
Литература
[1] Михаил Кузьминский. «Кирпичные компьютеры. Серверы нового поколения архитектуры NUMA компании SGI», Открытые системы, 2000, №9, c.10-15
[2] Михаил Кузьминский. «Архитектура серверов HP Superdome», «Открытые системы», 2000, №12, c.9-13
[3] Михаил Кузьминский. Computerworld Россия, 2000, №27-28
[4] New Compaq AlphaServer GS Series. Architecture White Paper, Compaq, 2000
[5] Михаил Кузьминский. «Микроархитектура Alpha 21264», «Открытые системы», 1998, №1, c.7
[6] «Cемейство Compaq AlphaServer GS: GS80, GS160 и GS320», Compaq, М., 2000
[7] М. Кузьминский. «Серверы UltraEnterprise 10000». «Открытые системы», 1997, №5, c.13-17
[8] В. Шнитман. «Cистемы Exemplar SPP1200», Открытые системы, 1995, №6, c.42
[9] М. Кузьминский. «Архитектура S2MP — свежий взгляд на ccNUMA», «Открытые системы», 1997, №2, c.14-21
[10] http://www.compaq.com/alphaserver/download/ gs_series_profile_new.pdf
[11] Михаил Кузьминский. «Доменная архитектура многопроцессорных компьютеров», «Открытые системы», 2000, № 10, c. 33-36
[12] http://www.compaq.com/alphaserver/download/ alphaserver_gs_benchmark_performance_v2.pdf
Михаил Кузьминский — старший научный сотрудник Центра компьютерного обеспечения химических исследований РАН. С ним можно связаться по телефону (095) 135-6388
| Компьютер | Число МП | QphH | долл./QphH | CУБД |
| Compaq GS320 | 32 | 4951.9 | 983 | Informix |
| IBM NUMA-Q 2000 | 32 | 4027.2 | 652 | DB2 |
| HP V2500 | 32 | 3714.9 | 1119 | Informix |
