

Вас устраивает качество работы современных поисковых машин в Сети? Меня нет. Вот вы хотите найти что-то у себя в квартире, вполне определенную вещь, какую-нибудь мелочь. Обычно вы примерно знаете, где искать - даже если не стремитесь иметь идеальный порядок дома. Ну, а если эта вещь понадобилась другому человеку, которому нет дела до порядка в вашей квартире? Ничего не изменится - разделение труда и распределение полномочий - великая вещь, и искать все равно вам.
А что у нас с поиском в Сети? Все вещи вынесены из квартир на большую свалку. Ищите, что-нибудь обязательно найдете. Но вот способствует ли повышению скорости и качеству поиска увеличение размеров свалок и их количества?
WWW, поисковые машины и хаос
Сеть, как и всякий объект эволюции, имеет дело с организующим и дезорганизующим началами. Организующее начало проявляется обыденно - появление в океанах информации островов, на берегах которых можно быстро найти нужную вам информацию. Это и грамотно сделанный тематический авторский сайт, и удобный портал, или просто страничка с упорядоченными ссылками на ресурсы по некоторой теме. Второе, противоположное начало, способствует хаосу в Сети, исчезают страницы и сайты, повисают в пустоте ссылки. Несвежий контент заполняет Сеть. И сам черт сломит ногу в плохо спроектированных и неудачно исполненных сайтах.
Обратимся к поисковым машинам. Казалось бы, вот борцы против хаоса. Как ориентироваться в океане информации без них? Да, верно - именно поисковые машины позволяют найти нужную информацию, иногда они даже зеркалируют контент Web. Но, увы, хаос побеждает и их. Противостоять хаосу в одиночку, пытаться «спасти Вселенную» от него не удалось и не удастся никому из традиционных глобальных поисковых машин. Почему?
Вспомним, как работает обычная поисковая машина. С помощью роботов она «ползает» по Сети, в частности, по ссылкам и индексирует текстовый контент страниц, часто с учетом задаваемой автором простой метаинформации. Заметьте, одна поисковая машина пытается проиндексировать всю Сеть. Идем дальше. Как осуществляется собственно поиск по запросу пользователя? Совпадение слов запроса и слов страницы. Об анализе смысла запроса и соответствия его ресурсу Сети обычно речи не идет - отсюда так велика доля мусора на, казалось бы, хорошие запросы. И еще одно. Скажите, кто отвечает за качество поиска? Правильно, великий русский поэт. Вот и живут в индексах поисковых машин ссылки на несуществующие уже ресурсы, а разбираться со всем этим приходится нам с вами - чаще как посетителям, иногда как клиентам и покупателям. Что получается в результате? Поисковые машины индексируют лишь небольшую часть содержимого Сети, причем делают это с опозданием, а релевантность поиска иногда анекдотична. И получается, что поисковые машины, отчаянно борющиеся с хаосом, сами становятся его проводниками.
На глубине
Согласитесь, положение дел с глобальным поиском серьезное. Увы, это слабо сказано. Положение просто катастрофическое, и вот почему. На заре развития Всемирной Паутины ресурсы были в основном статические, и их было немного. Худо-бедно поисковые машины справлялись с этими объемами, хотя отставание наметилось сразу же. Но как только объем информации сайта, его сложность и требования к простоте поддержки переваливают за некоторую границу, становится выгоднее хранить информацию не на самих страничках, а отдельно, используя Web лишь как универсальный интерфейс к приложению, основанному на некотором структурированном хранилище данных. Посмотрите на любой современный крупный сайт. Это уже не набор страничек, связанных друг с другом, это приложение, в основе которого - база данных, учитывающая особенности предметной области сайта. Объем информации, хранящейся в такой базе, и ее сложность, вообще говоря, могут быть любыми.
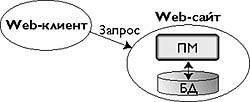 |
| Рис. 1. Поиск над структурированным хранилищем в основе сайта |
Как с этим обходятся глобальные поисковые машины? Не будет преувеличением сказать, что никак. Хотя вся информация доступна посетителю такого сайта, глобальная поисковая машина, не приспособленная для работы с динамическим контентом, уходит ни с чем. Однако практически каждый такой сайт имеет локальный поиск, либо основанный на базе данных, либо повторяющий по функциональности традиционный глобальный. Обратившись к этой поисковой машине, вы наверняка найдете то, что вам нужно, если, конечно, это имеется на сайте, и поиск работает корректно (рис. 1). Вот этот слой информации, погребенный под «сферами Шварцшильда» современных сайтов, и составляет львиную часть информации в Сети. Согласно [1], объем «глубинной» части Web (Deep Web) в 400 - 550 раз больше «поверхностной» (Surface Web) - проиндексированной всеми традиционными поисковиками, вместе взятыми. Мы ошибочно привыкли считать поверхностную часть Web самой Сетью. Но цифры говорят, что ошибаемся мы на порядки. И эти цифры продолжают расти, поскольку тенденция к хранению информации в структурированных источниках очевидна и по крайней мере в ближайшие годы не изменится.
Итак, что мы имеем? Традиционный поиск позволяет проиндексировать лишь ничтожную часть контента Сети и делает это плохо, поскольку ищет информацию не там, где ее больше, а там, «где светлее». Вы скажете, того, что проиндексировано, уже хватает с лихвой, чтобы завалить любого пользователя информацией по любой тематике. И что теперь, остается смириться с этим, пользоваться тем, что имеем и не желать странного?
Искусственный интеллект и Сеть
Кто ищет, тот что-то знает, поэтому попробуем подойти к проблеме с другой стороны. Самый естественный способ найти информацию - спросить. У кого (чего) и как - вот в чем вопрос? Можно спросить у знакомых, друзей и коллег. В нашей отечественной традиции это довольно распространенный способ, в том числе и при поиске ресурсов в Сети. Но на западе, где формула «время = деньги» более актуальна, точнее, время ценится гораздо дороже, чем у нас, такой способ выглядит довольно странно: знания о расположении информации в Сети, как и время по ее нахождению стоят денег, и дарить их вам никто не будет.
В 60-е годы в области искусственного интеллекта существовала эйфория от первых успехов, и казалось, что еще чуть-чуть, и машина станет понимать естественный язык, а затем и речь, и будет создан разум, пусть и не превосходящий человеческий, но довольно хорошо справляющийся со многими актуальными задачами. Поиск информации - именно такая задача, с появлением Сети она стала задачей первостепенной важности для искусственного интеллекта. Есть ли ей универсальное решение? Боюсь, что нет. Информация - слишком общее понятие. Интеллект - слишком сложный феномен. Искусственный интеллект - подражание «человеческому» способу решения некоторых задач - полезен там, где есть конкретная задача, например, распознавание образов. Искусственный разум - проблема, на порядки превосходящая возможности существующих на сегодня команд в области искусственного интеллекта вместе взятых, даже если они будут работать слаженно и вместе составлять некий поступательный вектор, чего сейчас нет.
Я невольно отождествил сейчас проблему поиска информации и проблему искусственного разума. Проблема поиска информации, и, - более категорично - поиска знаний, - предполагает понимание того, что ищется. Когда мне задают какой-нибудь неожиданный вопрос, мне легче на него ответить, узнав причину этого вопроса. Та же ситуация и с поиском - задавая вопрос кому-то (чему-то), вы предполагаете некоторый контекст, который можно раскрыть или до вопроса, или после, например, ответив на уточняющие вопросы. Или, если этот кто-то (что-то) уже настроен на контекст, то уточнять уже ничего не надо. Даже человек, «живущий» в Сети, может охватить лишь ничтожную часть контента, в основном ограниченную его интересами. Если говорить о поиске в Сети, человек, несмотря на довольно ограниченные ресурсы своей памяти, однозадачность и вовсе никакие вычислительные возможности, имеет неоспоримое преимущество перед поисковыми машинами с их колоссальными индексами - он понимает как вопросы, так и сам контент ресурсов, конечно, если он компетентен в спрашиваемой тематике. Конечно, запрягать живых людей в упряжку поиска в океанах информации - не выход из положения (все равно что плыть по этим океанам на веслах), хотя некоторые поисковые машины применяют ручной поиск, а уж при составлении рубрик это неизбежно.
Итак, мы стоим перед дилеммой - чтобы поднять поиск в Сети на качественно новый уровень, мы должны наделить интеллектом поисковые службы, но чтобы справиться с этой задачей, мы должны или создать некий сверхинтеллект, компетентный во многих предметных областях, а следовательно, превосходящий человеческий, или же создавать для каждой предметной области по своему интеллектуальному поисковому агенту. Естественно возникает вопрос - насколько дорого создать поискового агента, который был бы компетентным в некоторой узкой предметной области, коль скоро создать «машину, знающую все» пока нельзя? Насколько автономным от человека будет такой агент? И насколько он будет похож на человека в плане методов поиска информации и «пользовательского интерфейса», и чем будет отличаться от традиционных поисковых машин?
Поисковые домены
Попробую поделиться своими мыслями на этот счет. Не воспринимайте, пожалуйста, предложенные решения как нечто категоричное и законченное - самая большая ошибка в спорах - ответные реплики начинать со слова «нет» вместо «да». Приемлемое решение проблемы обычно собирается из многих идей, которые ошибочно считают несовместимыми, если рассматривают их через призму авторства, предубеждений или традиций. И только настоятельная необходимость решить проблему «мирит» идеи, а точнее, противоречивые слова и их авторов.
Итак, назовем агента, занимающегося поиском информации в Сети, поисковым доменом. Такое название пошло от доменов в Интернете, с одной стороны и от одного из значений слова domain - «предметная область». Наделим его следующими основными качествами.
- Пусть он будет компетентен в некоторой предметной области.
- К нему можно будет обратиться с поисковым запросом на естественном языке и получить ссылки на релевантные, с его точки зрения, ресурсы.
- При поиске ресурсов наш агент волен обращаться к любому такому же агенту, а также сам может отвечать на запросы других агентов, равно как и пользователей - все агенты априори равноправны.
- И, наконец, пусть агент настраивается человеком (группой), которые и будут отвечать за качество поиска, осуществляемого этим агентом.
- И, что не менее важно, архитектура такого распределенного поиска должна быть открытой, а стандарты и протоколы, на которых основано взаимодействие между агентами - стандартизованы.
Распределенность
Как уже говорилось, сейчас каждая существующая поисковая служба пытается проиндексировать всю Сеть в одиночку. Обратите внимание - наш поисковый домен может быть самодостаточен. Но смысл предложенного решения заключается в том, что поисковые домены составят самоорганизующуюся сеть, вместе складываясь в мозаику, каждый элемент которой важен именно на своем месте. Нагрузка по индексированию и поиску ресурсов должна распределиться по всей Сети. Основу этой сети должны составлять оконечные поисковые домены - поисковые машины, ответственные за поиск на конкретных сайтах (рис. 2).
Что сейчас не хватает уже существующим локальным поисковым машинам для интеграции в предлагаемую архитектуру? Прежде всего, нет универсального программного интерфейса обращения к ним - поле ввода на HTML-форме таковым интерфейсом не является. Во-вторых, для связывания поисковых агентов в сеть надо, чтобы эти агенты могли предоставлять внешнему миру информацию о своих особенностях, например, своей предметной области, поддерживаемых языках и т.д. Иными словами, необходима «визитная карточка» для каждого такого агента, которая бы позволяла решать, стоит ли обращаться конкретно к нему с конкретно этим запросом. Кроме того, оконечные поисковые домены сами выполняют роль визитной карточки для ресурса.
Но этого будет мало - помимо оконечных поисковых доменов («кирпичиков»), должны быть связующие домены - посредники. Сами они могут не иметь своего «подопечного» ресурса, но должны быть «знакомы» с другими (не обязательно оконечными) поисковыми доменами, и перенаправлять запросы на те из них, на которые сочтут нужным. И, разумеется, такой посредник сам должен быть известен другим посредникам.
Функция семантической корреляции
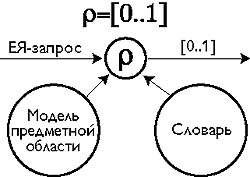 |
| Рис. 3. Функция семантической корреляции |
Одним из интересных решений организации «визитной карточки» ресурса может быть публикация ресурсом особой функции (рис. 3), у которой будет один текстовой входящий параметр - поисковый запрос, и результат - вещественное число от 0 до 1 (или от 0 до 1000). Эта функция должна оценивать корреляцию поискового запроса и предметной области ресурса. Иными словами, она должна моделировать понимание запроса применительно к данному ресурсу: 0 - запрос не относится к данному ресурсу, 1 - относится к нему как родной.
Такая функция может использоваться для «зондирования» интересующих нас ресурсов. Представьте, что вы ищете ресурсы по интересующему вас вопросу в определенной предметной области, и полнотекстовый поиск не может удовлетворить ваши потребности, поскольку о предметных областях, как и о вашем вопросе, не знает вообще ничего. Вы задаете список запросов, которые должны показать предметный «профиль» интересующего ресурса и пропускаете его через функцию семантической корреляции (ФСК). В результате получается портрет ресурса, заявленный самим ресурсом, в тех «лучах», которые вы выбираете сами при составлении тестового банка запросов. Повторив эту операцию с другими ресурсами, вы уже можете видеть сравнительные портреты ресурсов, и затем выбирать из этих «рентгенограмм» лучшую.
Но больше всего ФСК будет полезна при взаимодействии между поисковыми доменами. Вот, допустим, некий поисковый домен не имеет своего ресурса, а держит ссылки на 20 других. К нему поступает поисковый запрос, и он должен оптимальным образом использовать имеющиеся 20 связей с другими доменами для обслуживания нас с вами. Обращаться ко всем двадцати? И потом самому решать, какие ответы соответствуют запросу и насколько? В рамках всей поисковой сети такой подход приводил бы к перегрузке как каналов связи, так и вычислительных ресурсов доменов - один запрос привел бы к перегрузке некоторой части, а то и всей системы. Гораздо лучше выглядит решение, при котором каждый поисковый домен, получив задание, обращается сначала к ФСК своих связанных доменов, которые (чужие ФСК) могут по договоренности кэшироваться и на самом домене, а потом спрашивать те домены, ФСК которых отозвались на наш запрос приличными значениями.
Но за кадром пока остался такой вопрос - как из ФСК связанных доменов сделать ФСК данного домена? Более формальное определение ФСК - оценка вероятности получения релевантного ответа. А с вероятностями возможны довольно простые операции. Если нам надо построить поисковый домен, предметная область которого является пересечением других предметных областей, то ФСК от этих ПО надо просто перемножить. Если наша предметная область - объединение n других ПО, то вычисление ФСК осуществляется по следующей формуле:
(1 - f) = (1 - f 1)(1 - f 2)...(1 - f n) ,
где f - искомое значение ФСК, а fi - значения ФСК для составных предметных областей.
Усиливая эти примитивные принципы несколько более сложными, можно добиться приемлемого качества вычисления ФСК по функциям связанных доменов.
Ну, а как же вычислять ФСК в оконечных поисковых доменах? Здесь тоже возможно довольно простое и даже наглядное решение - слова возможных запросов размечаются в семантических классах (которых всего требуется не более десятка), каждому классу приписывается два числовых значения, которые условно можно назвать «семантическая плотность» и «семантический объем». Плотность обозначает значимость слов и фраз данного семантического класса по отношению к данной предметной области (как и сама ФСК, плотность может принимать значение от 0 до 1), а объем - вклад значимости лексем данного класса к значимости запроса в целом.
В самом простом случае ФСК - это плотность запроса, т. е. отношение семантической массы запроса к его семантическому объему. Незначимая лексика имеет малый семантический объем и нулевую семантическую плотность. Семантические классы значимой лексики - большую плотность и большой объем. Неизвестные слова - малую плотность и большой объем. Варьируя значения этих параметров, и по-разному разбивая лексику на семантические классы, можно довольно точно смоделировать семантическую корреляцию. Но лучшие результаты, конечно, получаются, если смоделировать само понимание запроса - это может потребовать разбора запроса в некоторой семантической грамматике, где на основе первичных семантических классов, выраженных лексемами, порождаются производные семантические компоненты и их плотность и объем вычисляются в зависимости от плотности и объема исходных составляющих, а также от их контекстного вхождения в запросе (рис. 4). Иными словами, выполняется семантически-ориентированный анализ запроса применительно к конкретной предметной области, но на выходе - не формальное представление запроса, а одно единственное значение - значение ФСК.
Как может выглядеть технически обращение к ФСК? Прошедшим летом информационно-софтверный мир выбросил флаг Web-служб. Техническая их основа - HTTP и язык XML, сами Web-службы - это приложения, интерфейсы которых доступны по HTTP. Вызов функции такой службы - это HTTP-запрос, в котором передаваемые параметры закодированы в XML-представлении (язык SOAP - [2]), а возвращаемые параметры передаются в HTTP-ответе, и тоже закодированы в XML. Кстати, не обязательно HTTP - ограничений на протоколы нет, это может быть и какой-нибудь почтовый протокол. Ни DCOM ни CORBA не смогут связать разрозненные гетерогенные системы в Сети так, как это могут сделать Web-службы по такой архитектуре, по крайней мере, сейчас. И именно Web-службы как нельзя лучше подходят к нашей задаче - «публикации» ФСК.
Почему естественный язык?
Первоначально идея связанных поисковых доменов появилась в связи с интерфейсами к базам данных, которые позволяют обращаться к базе данных на естественном языке (ЕЯ), как к референту, справочному киоску и т.д. Каждый ЕЯ-интерфейс относится к конкретной базе данных. В ситуации, когда баз данных и ЕЯ-интерфейсов к ним много, полезно иметь метаинтерфейс, который бы позволял обращаться ко всем доступным ЕЯ-интерфейсам одним запросом, и в случае необходимости выбирать для работы один из них. Выбор естественного языка и отказ от передачи формальных представлений запросов в данном решении обусловлен еще и тем, что сами данные, информация и знания часто описаны в ресурсах на естественном языке. Но более важная причина - универсальность представления запроса на естественном языке, ведь запрос может пройти через множество поисковых доменов, и дойти он должен без искажения его смысла. А самое емкое вместилище смысла запроса - это само его ЕЯ-представление.
Когда я вижу систему, которая понимает естественный язык, или говорит, что понимает, знаете, какое мое первое желание при работе с ней? Найти предел ее интеллектуальности. Так ребенок хочет сломать новую, яркую, мигающую цветными лампочками игрушку и посмотреть, как она устроена. Вполне понятно желание человека, который не верит в то, что машина сможет научиться думать (хотя сымитировать понимание - может) - «сломать» систему, называющую себя «искусственным интеллектом». А вот сломать, скажем, AltaVista или Yandex не хочется. Как не хочется ломать лопату или мясорубку.
Анализ ЕЯ, автоматическое понимание ЕЯ имеют давнюю историю со множеством подходов, которые очень часто противоречили друг другу, хотя критерий пригодности здесь только один - решение задачи понимания ЕЯ. К слову сказать, проблема машинного понимания ЕЯ не решена до сих пор. Почему? Искусственный интеллект - слишком общее и туманное понятие. То же справедливо и для обработки ЕЯ как одной из важных составляющих мира искусственного интеллекта. Задачи понимания ЕЯ как таковой нет. Есть множество довольно частных задач - и многие из них уже имеют приемлемые решения. Возьмем, к примеру, машинный перевод. Анекдотическое качество существующих систем перевода иллюстрирует ту идею, что орешек не по зубам, по крайней мере, пока. Но если выделить из проблемы наиболее актуальные частные задачи, и решать каждую из них в отдельности, можно получить приемлемое качество за приемлемую цену.
Этот принцип - «разделяй и властвуй» - как нельзя лучше подходит и для нашей задачи. В обработке ЕЯ известно, что чем специфичнее предметная область, к которой относится подмножество анализируемых ЕЯ-предложений, тем легче решать задачу автоматического понимания ЕЯ. Например, задача построения ЕЯ-интерфейсов к базам данных решена благодаря тому, что сам жанр ЕЯ-запросов к базе данных настолько прост, что анализ запросов в большинстве случаев может происходить без полного синтаксического разбора предложения, с использованием элементарных «смыслов» отдельных слов и фраз, привязанных к модели предметной области, и собиранием на их основе более сложных семантических компонентов, в конце концов образующих формальное представление запроса.
Каким же образом этот принцип может пригодиться в решении задач интеллектуального поиска? Вспомним про многообразие как структуры, так и ресурсов в Сети. Для электронного магазина в качестве поисковой машины подошло бы интегрированное решение, объединяющее ЕЯ-интерфейс к базе данных и традиционные службы сайта - ведь сама информация уже содержится именно в базе. Для электронной библиотеки необходима интеграция ЕЯ-интерфейса к базе данных и полнотекстового поиска. В некоторых случаях достаточно только полнотекстового поиска.
Но наибольшую роль в эффективности задачи понимания поискового ЕЯ-запроса должна иметь предметная область ресурса, а также его структура. Вы не отказались бы от такой службы на вашем любимом портале - возможности задать запрос типа:
- Новости о Linux (Microsoft, вирусах, ...) за прошлый месяц (день, неделю)?
Или:
- Погода на завтра-послезавтра в Москве, Питере.
А также:
- Статьи о поиске в «Открытых системах»
Да, именно так, простым русским (английским или любым другим) языком, без всяких AND, OR и прочих премудростей «advanced»-поисковых языков, все - через одно и то же поле ввода. Разумеется, такое решение имеет и недостатки - например, последний запрос имеет довольно много смыслов, и это уже обусловлено неизбежной неоднозначностью естественного языка как такового.
Но полноценное понимание ЕЯ без учета контекста практически невозможно, и при множественности смыслов контекст можно выбирать явно, особенно если он будет выражен просто и ясно, а не так, как во многих современных искалках - выдранным из текста документа куском, часто не относящимся ни к смыслу запроса, ни к теме документа.
В каждом конкретном случае понимание запросов на естественном языке должно быть организовано с учетом предметной области и строения ресурса, и, как правило, это не потребует сверхсложных систем анализа, поскольку решение этой задачи в конкретных узких рамках имеет вполне приемлемую стоимость. Особенно если учесть, что на кону - скачок в качестве поисковой службы в Сети.
Но более всего важно то, что принципы семантически-ориентированного подхода к анализу ЕЯ-запросов общие для многих языков. Например, русский и английский, довольно разные языки по грамматике, имеют так много общего с точки зрения жанра запросов к источникам данных, что могут наравне друг с другом анализироваться одной и той же системой анализа с вполне приличным качеством понимания (именно это и происходит в технологии InBASE). В условиях смешения языков Сети такая возможность может, пусть не сразу, но поколебать англоязычный шовинизм Interent, и поспособствовать равенству всех национальных языков.
Модель предметной области и структуры ресурса
Традиционные поисковики представляют Internet-ресурс в основном с учетом ссылок на него и текстового наполнения страниц ресурса. Что в этой модели не учитывается? Два довольно важных аспекта описания ресурса - структура и предметная область. Заходя на корпоративный сайт, вы увидите четкое деление, например такое: «О компании - Новости - Продукты - Контакты - Работа». Идете на портал - видите что-то типа «Горячие новости - Погода - Компьютеры - Спорт - Деньги - Техника - Юмор». Обратите внимание - структура сайта часто строится исходя из его предметной области и повторяет его, просто потому, что так удобнее посетителю. Мы привыкли к тому, что поисковым машинам до этого нет дела.
Избавим наших поисковых агентов от такого дефекта. Но для этого необходимо, чтобы ресурсы адекватно описывались. А кто сможет описать ресурс, как не его создатель? И описание его должно меняться синхронно с изменением самого ресурса.
Описание ресурса в Сети имеет два основных уровня. Первый - описание конкретного сайта, раздела или конкретной страницы. Второй - набор понятий и отношений между ними, т. е. онтология, в которой ведется описание ресурса, структура предметной области. Например, самая общая онтология для ресурса в Сети - название, адрес, язык, автор, владелец, дата создания, дата последнего обновления. Добавим сюда учет структуры сайта, а также базовые элементы онтологии о людях (человек имеет имя, фамилию, год рождения, возраст и т.д.), и можно будет понимать такие запросы как:
- ресурсы, которые не обновлялись больше года, на сайте «Рогов и Копыт»;
- страница Петра Иванова, 26 лет;
- средний возраст авторов домашних страниц.
Если же подключить к анализу ссылки между документами (а их учет в традиционных поисковых машинах - дело обязательное), то появляется возможность легко получать ответы на такие вопросы:
- На какой документ Borland больше всего ссылок?
- Кто ссылается в Рунете на документ www.abc.com/somedocument.htm?
И уж совсем хорошая служба получается, если учитывать предметную область и структуру каждого сайта:
- Страницы новостей порталов Медиа-Моста от 16:00 до 20:00 25 декабря? (новостной портал)
- Самая низкая цена на Palm IIIe в московских фирмах - не опт? (электронный магазин)
- Все реплики Ивана Иваныча в ответ на реплики Ивана Никифорыча? (чат)
Понимание всех этих запросов требует не так многого - описания модели предметной области, например, с помощью RDF, и лингвистического процессора, работающего в семантически-ориентированном подходе к анализу ЕЯ, преобразующего входные ЕЯ-запросы в формальное представление на некотором языке поиска данных или ресурсов, например, SQL, XQL, RDF-Query. Чем четче и грамотнее описать предметную область и структуру ресурса, тем проще организовать понимание таких запросов. Конечно, имеются довольно сложные проблемы, например, автоматическое выделение смысла из произвольного текста, - ведь большинство ресурсов в Сети вообще не имеет сколько-нибудь внятного формального описания, а RDF только начинает распространяться вслед за XML. Но в целом задача выглядит вполне решаемой.
Сценарии распределенного поиска
Распределенная модель имеет ряд отличий в механизме «раскрутки» поисковых доменов. Здесь проявляется скорее аналогия с Web-сайтами - поисковый домен имеет, как правило, четко определенную предметную область, что означает другую структуру «рынка поиска». В то время как глобальные поисковые службы практически повторяют функциональность друг друга, и их рынок достаточно однороден, домены поиска могут иметь вполне определенные «рыночные ниши» и круг пользователей. Модель связанных доменов сама по себе является промоушн-механизмом, существенную роль в котором играет качество работы.
Поясню на примере гипотетического домена, имеющего специализацию в поиске книг по определенной тематике (например, по экономике), назовем его доменом А. Предположим, в ответе на некоторый запрос («Адам Смит») присутствует несколько десятков ответов от оконечных доменов. Администратор данного домена может проследить все пути ответов, и все множество промежуточных доменов (подобно службе электронной почты). Анализируя предметные области оконечных и промежуточных доменов, а также экспериментируя с реальными запросами к ним, он может составить оценку качества их работы и переназначить ссылки своего домена таким образом, чтобы качество работы его для данной предметной области было максимальным.
Например, если один из связанных доменов (назовем его доменом Б) выдает ответы, не релевантные своей заявленной предметной области (ей может быть, например, история экономической науки), и дает ссылку на домашнюю страничку некоего Адама Смита, не имеющего никакого отношения ни к знаменитому экономисту, ни к экономике вообще, то у администратора домена А может быть несколько путей повышения качества своего домена. Во-первых, он может просто написать администратору домена Б и изложить проблему в надежде, что эта проблема может быть им решена. Во-вторых, он волен понизить «рейтинг« этого связанного домена, чтобы его менее релевантные по сравнению с остальными доменами ответы были подальше от вершины. И, наконец, он может просто исключить домен Б из списка связанных со своим доменом А. Для домена Б это будет означать уменьшение потока запросов, а следовательно, и «известности» домена. Такой механизм будет приводить к быстрому отсеву неадекватно отвечающих доменов. Оценивать качество своего домена можно и по количеству доменов, ссылающихся на него, а также по количеству и характеру запросов, приходящих к нему (и, разумеется, по прямой корреспонденции от администраторов доменов, держащих ссылки на данный, как в рассмотренном примере).
Все это позволяет говорить о саморегуляции этой службы. Для того чтобы набрать большее количество ссылок и больший поток запросов, домен вынужден постоянно следить за качеством работы. Попросив другого человека что-то найти (и в общем случае - что-то сделать), мы всегда оцениваем качество сделанной работы, и если это качество нас не устраивает, мы хорошо подумаем, обращаться ли к этому человеку в следующий раз. А если качественный поиск является целевой функцией, то наиболее адекватные поисковые домены будут наиболее популярны и со временем могут составить конкуренцию глобальным поисковым машинам.
Конкурентов у поисковых доменов потенциально больше, чем у современных глобальных поисковых машин: затраты и усилия на создание домена должны быть гораздо меньше. По сути, это просто установка на уже существующем Web-сервере приложения, не особенно требовательного к ресурсам машины - оно должно поддерживать предметно-зависимый словарь ограниченного размера и содержать модуль семантического разбора (в отличие от громадных баз индексов глобальных поисковых машин и поддержке большого потока запросов - предполагается, что нагрузка плавно будет распределена по доменам поиска). Правда, поддержка такого домена требует хорошего знания предметной области и постоянного контроля качества. Таким образом, в новой парадигме поиска роль человека, владеющего знаниями, и умеющего эти знания описывать, возрастает.
Открытая архитектура
Архитектура распределенного поиска имеет важное преимущество - контролируемость качества со стороны всех заинтересованных сторон. Однако этого недостаточно для повсеместного перехода на рельсы распределенного смыслового поиска. Что по-настоящему может способствовать распространению данной архитектуры - так это потенциальная открытость архитектуры и доступность кода. И RDF-описание ресурса со встроенным словарем, и задание ФСК в XML пригодно как для компьютерного процессинга, так и для понимания человеком. В Web открытость HTML-кода любой страницы способствовало распространению этой технологии, а также совершенствованию дизайна страниц и целых сайтов по принципу «подсмотри и сделай лучше». Принцип открытого кода завоевывает все больше сторонников и является гарантией качества.
Если в открытой архитектуре распределенного поиска существует поисковая служба, отличающаяся качеством работы в лучшую сторону, то он сам только выиграет, если сделает «кухню» своей работы открытой для повторения другими - чем надежнее и качественнее работают узлы сети, тем надежнее в целом сама сеть, и это сказывается положительной обратной связью на всех ее участниках.
Что дальше?
Описанная концепция открытого распределенного поиска имеет право на жизнь, только если удовлетворяет насущным потребностям. Воплотить же эту концепцию вряд ли кому под силу в одиночку. Общая стратегия распространения ее - открытость. Технологии, «перпендикулярные» по отношению к традиционным, только тогда берут верх, когда они качеством превосходят существующие, и не преследуют в своей основе корыстных интересов. Здесь и с тем и с другим все должно быть хорошо.
Вот несколько вопросов, которые на сегодняшний день нуждаются в конкретной проработке:
- разработка протокола взаимодействия поисковых доменов;
- разработка XML-языка описания ФСК;
- разработка пилотных модулей вычисления ФСК и перевода ЕЯ-запросов в формальное представление;
- разработка оконечных поисковых машин, интегрирующихся с данной технологией;
- создание полигона поисковых доменов.
Все только начинается...
Вы верите в свои силы и хотите способствовать претворению в жизнь этой архитектуры? Пишите.
Вам интересна концепция, но не ясны детали? Пишите.У вас есть идеи и предложения? Пишите.
Вы не верите в то, что это возможно и готовы поспорить? Обязательно пишите!
Об авторе
Влад Жигалов — сотрудник РосНИИ Искусственного интеллекта. С ним можно связаться по электронной почте: zhigalov@aha.ru
Литература
[1] Deep Web - Bright Planet?s white paper. http://www.completeplanet.com/tutorials/deepweb/
[2] Simple Object Access Protocol (SOAP) 1.1. W3C Note 08 May 2000. http://www.w3.org/TR/2000/NOTE-SOAP-20000508/
[3] Ashok, Neel, (1998). RDF Query Specification. Technical contribution to the W3C Query Languages Workshop, Dec 3 and 4, 1998. http://www.w3.org/TandS/QL/QL98/pp/rdfquery.html
[4] Deutsch and others, (1998). XML-QL: A Query Language for XML. Submission to the World Wide Web Consortium 19-August-1998. http://www.w3.org/TR/1998/NOTE-xml-ql-19980819
[5] RDF, (1999). Resource Description Framework (RDF) Model and Syntax Specification. W3C Proposed Recommendation 05 January 1999. http://www.w3.org/TR/PR-rdf-syntax
[6] Robie and others, (1998). XML Query Language (XQL). Position paper to the W3C Query Languages Workshop, Dec 3 and 4, 1998. http://www.w3.org/TandS/QL/QL98/pp/xql.html
[7] XSL, (1998). Extensible Stylesheet Language (XSL), version 1.0. World Wide Web Consortium Working Draft 16-December-1998. http://www.w3.org/TR/WD-xsl
Технология InBASE
На принципе семантически-ориентированного анализа работает ядро технологии InBASE, позволяющей строить естественно-языковые интерфейсы к базам данных, и не только. Сами запросы могут даже не напоминать естественный язык, а скорее традиционные поисковые запросы в 2 - 3 слова: вместо «объем продаж за первый квартал» - «продажи 1 кв.», вместо «кто работает над проектированием» - «проектирование, кто», вместо «дата сдачи системы» - «когда сдача» и т.д. InBASE выделяет смысл из всех этих фраз - в ограниченных предметных областях это сделать относительно легко.
Вот пример простых ЕЯ-запросов к ТВ-программе.
- Фильмы сегодня вечером?
- Что идет сейчас?
- Сколько в сумме длятся сериалы - по каналам?
Несколько запросов из музыкальной предметной области.
- Альбомы Deep Purple с Ричи Блэкмором?
- Все клавишники?
- Что сделал Гиллан с 75 по 84 год?
ЕЯ-интерфейсы могут строиться не только к базам данных. Было бы интересно, например, построить запрос к файловой системе.
- Какие исходники я правил на этой неделе?
- Самая старая программа?
- Сколько всего занимают на диске doc-файлы?
Или, например, к вашему почтовому клиенту:
- кто ответил на мое вчерашнее письмо о тестировании?
- Письма от А.С. две недели назад?
- Письма клиентов, оставшиеся без ответа
InBASE имеет промежуточное формальное представление запроса (Q-язык), очень схожее по своей парадигме с языком объектных запросов OQL, и задаваемую для каждого ЕЯ-интерфейса модель предметной области (МПО) на основе диаграммы классов. И Q-запрос, и МПО имеют свои XML-представления. Дальнейший перевод Q-запроса в SQL или любой другой формальный язык запросов (см. врезку о формальных языках запроса), или непосредственный поиск в случае ЕЯ-интерфейсов к файловой системе или почтовому архиву - дело чисто техническое, и отделено от процесса понимания запроса.
Описание ресурса в RDF
Стандарт RDF (Resource Description Framework) [5] включает две основные части - собственно способ описания ресурсов, а также способ задания схем, по которым описывается ресурс. Первая часть (www.w3.org/TR/PR-rdf-syntax) хороша для описания конкретной страницы, сайта, либо другого специфического ресурса как конкретного объекта (например, товара в e-магазине), тогда как вторая (RDF Schema - RDFS (www.w3.org/TR/PR-rdf-schema) служит для задания структуры предметной области и аналогична диаграмме классов в UML. На RDF можно описывать как структуру сайта, так и связанную с ним предметную область. Этот язык использует XML-синтаксис и описывает ресурсы в виде ориентированного размеченного графа - каждый ресурс может иметь свойства, которые в свою очередь также могут быть ресурсами или их коллекциями.
Под ресурсом может пониматься не только некоторый документ или набор документов в Сети, представленный своим URL, но и любой объект, который вы пожелали описать. Например, для документа можно задать свойства «заголовок», «описание», «авторство», причем для «авторства» как ресурса могут быть заданы «имя», «фамилия» и «e-mail», как свойства (Рис. 5).
Пример описания ресурса на RDF:
Домашняя страница
Влада Жигалова
Влад
Жигалов
zhigalov@aha.ru
Формальные языки запросов к источникам данных
Языков запросов к структурированным источникам данных много - выделю только те, которые наиболее актуальны.
SQL
Этот язык в реляционной парадигме является общим знаменателем под различными СУБД, и наиболее широко распространен в бизнес-приложениях. Первоначально разработанный для непосредственного получения пользователем информации из баз данных, сейчас он перекочевал в исходные коды программ, представляющих информацию в базе данных на основе таблиц и форм, а также в серверную часть многоуровневых приложений. Язык очень гибкий, но понять реальный SQL-запрос средней сложности к реальной базе средней же сложности сходу способен далеко не каждый программист, например:
SELECT Task_Information.FinishDate, Task_Information.Name, Task_Information.StartDate, Resource_Information.Name
FROM
Task_Information,
Resource_Information,
Assignment_Information
WHERE
Resource_Information.
ResourceUniqueID =
Assignment_Information.
ResourceUniqueID
AND Task_Information.
TaskUniqueID =
Assignment_Information.
TaskUniqueID
AND (Resource_Information.
Name = ?Иванов? AND
Task_Information.StartDate <=
#12/07/2000# AND #12/07/2000#
<= Task_Information.FinishDate)
Это SQL-представление, соответствующее ЕЯ-запросу «задачи Иванова сегодня» к базе данных MS Project.
OQL
Этот язык объектных запросов, Object Query Language, - аналог SQL в объектной парадигме представления знаний, с присущим этой парадигме удобством и ясностью. Считается синтаксически обратно совместимым с SQL. Характерно, что следующая версия стандарта SQL (условное название SQL-3) будет надмножеством OQL - будет с ним полностью совместима. Это соответствует общей тенденции кооперации реляционного и объектно-ориентированного подходов. С синтаксической точки зрения в этом языке удобно наличие аксессоров, то есть путей по связанным объектам. Например, чтобы получить имя человека, сделавшего заказ на определенный товар, надо составить такой аксессор:
Товар.Заказы.Клиент.Имя, а сам OQL-запрос будет выглядеть так:
select Товар.Заказы.Клиент.Имя from Товар where Товар.Имя = ?ТоварСБольшойБуквыТ?
В SQL это потребовало бы явного указания всех таблиц в запросе, и прописывания связей в явном виде, что сделало бы запрос менее читабельным.
XML QL
Этот язык - аналог SQL для XML-данных [4]. Синтаксически он сам является XML-выражением, где содержимое аналогов select, from, where - это XML-теги:
WHERE
Addison-Wesley
$a
IN "www.a.b.c/bib.xml"
CONSTRUCT
$a
