

Программисты и ученые, как правило, пристрастны, когда речь заходит о достоинствах и недостатках различных языков программирования. Сравнив несколько языков, автор попытался получить объективную информацию о Си, Си++, Java, Perl, Python, Rexx и Tcl.
Для сопоставления была использована одна программа, которая предъявляет одинаковый набор требований ко всем языкам. Такой прием сужает область сравнения, но делает ее однородной. Кроме того, для каждого языка было проанализировано несколько отдельных реализаций программы, подготовленных различными программистами. Групповой подход имеет два преимущества. Во-первых, сглаживаются различия между отдельными программистами, которые могут лишить достоверности любые сравнения, основанные на единственном «образце» для каждого языка. Во-вторых, появляется возможность сравнить изменчивость характеристик программ, составленных на разных языках.
В ходе сравнительного исследования сопоставлялись различные аспекты каждого языка, в том числе длина программы, усилия, затраченные на программирование, время выполнения, занимаемое пространство памяти и надежность. Языки сравнивались индивидуально и по группам. Языки сценариев, такие как Perl, Python, Rexx и Tcl чаще интерпретируются, чем компилируются (по крайней мере, на этапе разработки программ), и обычно не требуют определения переменных.
Более традиционные языки программирования — Си, Си++ и Java — чаще компилируются, чем интерпретируются и требуют описания типов переменных. Поскольку многие считают язык Java очень неэффективным, я иногда относил Си и СИ++ к одной группе, а Java к другой.
Диаграммы и статистические методы
В качестве основного инструмента оценки в статье используется блочная диаграмма, показанная на рис. 1. Каждая линия представляет одно подмножество данных, имя которого указано слева. Каждым малым кружком обозначено одно значение данных. Остальная часть диаграммы помогает визуально сравнить два или несколько подмножеств данных. В затененном блоке заключена средняя половина значений, между верхними границами первой четверти (25%) и третьей четверти (75%). «Усы» слева и справа от блока показывают нижние и верхние 10%, соответственно. Жирная точка внутри блока — верхняя граница второй четверти (50%). Символ «M» и разорванная линия вокруг него показывает среднее арифметическое, плюс/минус среднеквадратическую ошибку.
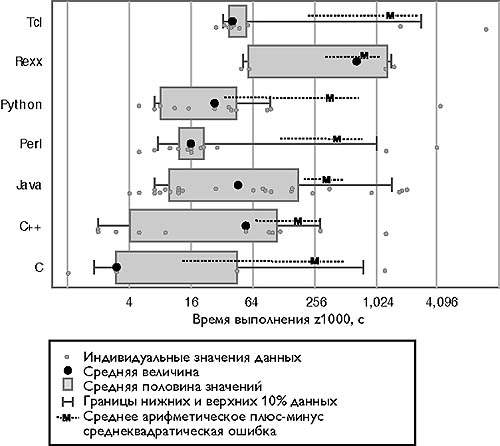
Рис. 1. Время работы программы с набором данных z1000
Исполнение трех программ было завершено безрезультатно по истечении примерно 21 минуты. Разброс отношений «плохих и хороших величин» составляет от 1,5 для Tcl до 27 для Си++. Обратите внимание на логарифмический масштаб оси. Пояснения к данному рисунку относятся также к Рис. 2-7. Более подробное описание дано в разделе «Диаграммы и статистические методы»
Для количественного описания разброса значений в группе было использовано отношение «плохих и хороших величин»: представьте, что данные разделены между верхней и нижней половинами, и отношение «плохих и хороших величин» представляет собой частное от деления среднего значения верхней половины на среднее значение нижней половины. На блочной диаграмме средним считается значение, полученное в результате деления величины у правого края блока на величину у левого края блока. В отличие от такой меры разброса величин, как среднеквадратичное отклонение, отношение «плохих и хороших величин» эффективно исключает резкие выбросы.
Самый важный вывод можно сделать непосредственно из диаграммы. Однако для перепроверки были выполнены статистические тесты. Для сравнения средних значений используется односторонний U-критерий Манна-Уитни (также называемый критерием суммы рангов Уилкоксона). Результат каждого теста — p, величина, характеризующая вероятность того, что наблюдаемая разница между двумя выборками лишь случайна, и что в действительности различия между двумя группами величин отсутствуют или имеют противоположный знак. Обычно само p-значение не приводится, а в тексте статьи указывается «... больше, чем ...», если 0 < p <= 0,10; или «... как правило, больше, чем ...», если 0,10 < p <= 0,20. Если p > 0,10, то «существенных различий нет».
В ряде случаев указаны доверительные интервалы для различий в средних значениях или для различий в логарифмах средних значений — т. е., отношений средних величин. Выбраны открытые уровни доверительности, с бесконечной верхней границей. Доверительные интервалы вычислены методом раскрутки (bootstrap), подробно описанным во многих источниках (см., например, [1]).
Учитывая опасения относительно достоверности данного исследования, количественные статистические выводы указывают лишь на общие закономерности и не должны рассматриваться как точные факты.
В таблице 1 показано число программ для каждого языка и платформы выполнения. Для оценки Java использовались комплекты разработчиков JDK 1.2.2 Hotspot Reference version или JDK 1.2.1 Solaris Production version with JIT, в зависимости от того, какая платформа обеспечивала большее быстродействие конкретной программы. Все программы выполнялись на рабочей станции Sun Ultra II/300 МГц с оперативной памятью емкостью 256 Мбайт, оснащенной операционной системой SunOS 5.7. Результаты для языков Си и Rexx получены на основании всего пяти и четырех программ, соответственно, и потому могут считаться лишь грубым приближением к действительности; для всех остальных языков результаты были получены после анализа 10 и более программ — приемлемо широкое представительство для достаточно точной оценки.
Во врезках «Задача: преобразование телефонных номеров» и «Достоверность сравнения» описаны организация и достоверность исследования. Читатели могут найти более подробное описание исследования в Web [2].
Результаты
Для оценки программ использовались три различных входных файла: z1000, содержащий 1000 непустых случайных телефонных номеров; m1000, содержащий 1000 произвольных случайных телефонных номеров, некоторые из которых могли быть пустыми; и z0, не содержащий телефонных номеров и служащий исключительно для измерения времени загрузки словаря.
Время выполнения программы
Я начал анализ с измерения полного времени выполнения, а затем исследовал отдельно этапы инициализации и поиска.
Полный набор данных z1000. Как показано на рис. 1, время выполнения всех программ за исключением Си++, Java и Rexx, составляет менее 1 мин. Сравнивая данные, можно сделать несколько значимых выводов.
- Среднее время выполнения программ Tcl незначительно больше, чем Java и даже Си++.
- Среднее время выполнения как для Python, так и для Perl меньше, чем Rexx и Tcl.
- Средний показатель Си++ может ввести в заблуждение. Из-за довольно большого разброса между соседними большими и меньшими величинами, среднее значение нестабильно. Критерий Уилкоксона, который учитывает весь набор данных, подтверждает, что среднее время для Си++, как правило, меньше среднего времени для Java (p = 0,18).
- Среднее время выполнения для Си меньше, чем для Java, Rexx и Tcl, и как правило, меньше чем для Perl и Python.
- Время выполнения для Tcl и Perl — за исключением двух очень медленных программ — как правило, более стабильно, чем время выполнения программ на других языках.
Не следует придавать особенно большого значения диаграммам для Си и Rexx, построенным всего по нескольким точкам. Время выполнения программ на Rexx может быть снижено примерно в четыре раза, если перекомпилировать интерпретатор Regina для использования хеш-таблиц большего размера; требования к памяти при этом возрастают незначительно. Если объединить языки всего в три группы (одна — Си и СИ++ , вторая — Java, третья — языки сценариев), то программы на Си и Си++ работают быстрее, чем Java (p = 0,074), и как правило, быстрее сценариев (p = 0,15).
Между средним временем выполнения программ на Java и сценариев нет существенной разницы. С вероятностью 80% сценарий будет выполняться в 1,29 раза дольше — а программа на Java по меньшей мере в 1,22 раза дольше — чем программа на Си или Си++. Отношение «плохих и хороших величин» значительно меньше для сценариев (4,1), чем для Java (18) и даже для Си и Си++ (35).
Только этап инициализации, набор данных z0. Затем я измерил время, необходимое для считывания, предварительной обработки и сохранения словаря. Соответствующие времена приведены на рис. 2. Результаты явно свидетельствуют, что Си и Си++ выполняют эту фазу быстрее, чем другие протестированные языки. И вновь, самыми быстрыми языками сценариев оказались Perl и Python. Как выяснилось (с вероятностью 80%) при сравнении укрупненных групп, программа на Java будет выполняться по крайней мере в 1,3 раза дольше, чем программы на Си и Си++, а для выполнения сценария потребуется по крайней мере в 5,5 раз больше времени. Сценарий будет выполняться по крайней мере в 3,2 раза дольше программы на Java.
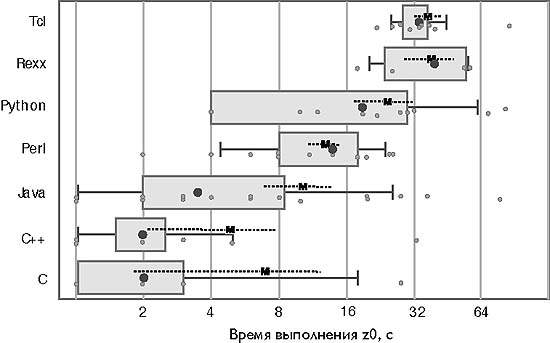
Рис. 2. Время, затраченное программой только на загрузку и предварительную обработку словаря (набор данных z0). Обратите внимание на логарифмический масштаб оси. Соотношение «плохих и хороших величин» в пределах от 1,3 для Tcl до 7,5 для Python
Только этап поиска. И наконец, я вычел время время этапа загрузки (набор данных z0) из полного времени выполнения (набор данных z1000), чтобы получить время только поискового этапа программы. На рис. 3 показаны соответствующие времена, из которых можно сделать следующие выводы.
- Очень быстрые программы составлены на всех языках, за исключением Rexx и Tcl, а очень медленные программы встречаются на всех языках.
- Среднее время выполнения программ на Tcl больше, чем время программ на языках Python, Perl и Си, но меньше, чем на Rexx.
- Среднее время выполнения программ на Python меньше, чем времена для Rexx и Tcl, и как правило, меньше, чем время выполнения Java (p = 0,13).
- Среднее время выполнения программ на Perl меньше средних показателей для Rexx, Tcl и Java.
- Среднее время Си++ существенно отличается от результатов любого другого языка.
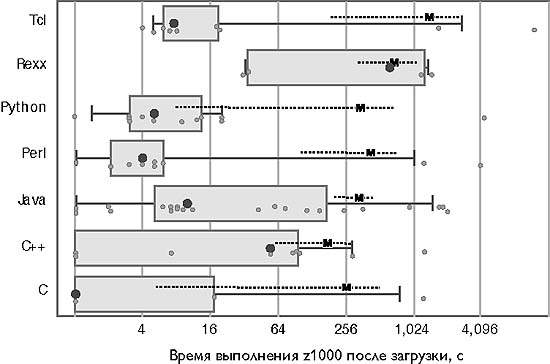
Рис. 3. Время, затраченное программой только на поиск, вычисленное как разность между временем работы с набором данных z1000 и набором данных z0. Обратите внимание на логарифмический масштаб оси. Соотношение «плохих и хороших величин» в пределах от 2,9 для Perl до 50 для Си++
Сравнение укрупненных групп свидетельствует об отсутствии серьезных различий между любыми группами. Однако можно с вероятностью 80% утверждать, что разброс времени выполнения сценариев по крайней мере в 2,1 раза меньше, чем у Java, и по крайней мере в 3,4 раза меньше, чем у Си и Си++.
Требования к памяти
На рис. 4 показан общий размер процесса в конце обработки входного файла z1000. Из него можно сделать несколько выводов.
- Очевидно, что наиболее эффективно память используется в программах групп Си и Си++, а наименее эффективно — в программах группы Java.
- За исключением Tcl, лишь немногие сценарии потребляют больше памяти, чем худшая половина программ на Си и Си++.
- Для сценариев Tcl требуется больше памяти, чем для других сценариев.
- Относительный разброс требований к памяти программ на Python и Perl, как правило меньше, чем программ на Си и в особенности Си++.
- Некоторые сценарии занимают большие области памяти.
- При сравнении укрупненных групп можно утверждать с вероятностью 80%, что в среднем программы на Java занимают по крайней мере на 32 Мбайт больше памяти (297%), чем программы на Си и Си++, и по крайней мере на 20 Мбайт больше (98%), чем сценарии. Сценарии занимают по крайней мере на 9 Мбайт больше памяти (85%), чем программы на Си и Си++.
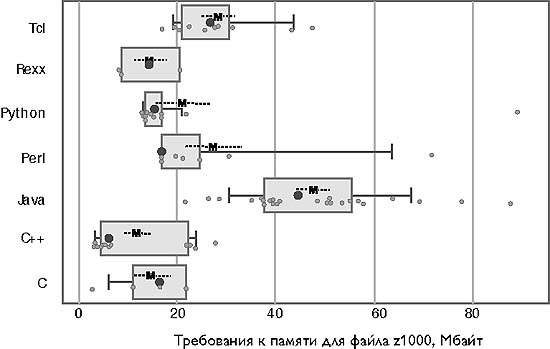
Рис. 4. Объем памяти, необходимый программе, в том числе для размещения интерпретатора или исполняющей системы, собственно программы и всех статических и динамических структур данных. Соотношение «плохих и хороших величин» в пределах от 1,2 для Python до 4,9 для Си++
Из этих данных можно заключить, что требования Java к памяти обычно вдвое выше требований сценариев, а сценарии не обязательно менее эффективно используют память, чем программы, составленные на Си и Си++, хотя и не могут превзойти экономную программу на Си или Си++.
Здравый смысл подсказывает, что алгоритмическим программам свойствен компромисс между временем выполнения и объемом используемой памяти: для увеличения скорости работы обычно нужно выделить программе больше места. В исследованном нами наборе программ это правило действует для всех трех несценарных языков, но для сценарных языков справедливо, скорее, обратное правило: сценарии, использующие больше памяти, как правило, работают медленнее сценариев, занимающих меньше памяти.
Длина программ и число комментариев
На рис. 5 показано число строк исходного файла каждой программы, в которых содержится любая семантическая информация программы: операторы, определения или по крайней мере разделители, такие как закрывающая фигурная скобка. Несценарные файлы обычно вдвое или втрое длиннее сценариев. Даже самые длинные сценарии короче средних несценарных исходных текстов. Вместе с тем, плотность комментариев в сценариях значительно выше (p = 0,020): в несценарных программах в среднем содержится на 22% больше строк с комментариями, чем строк с операторами; для сценариев этот показатель составляет 34%.

Рис. 5. Длина программы: число строк исходного текста без комментариев. Соотношение «плохих и хороших величин» в пределах от 1,3 для Си до 2,1 для Java и 3,7 для Rexx
Надежность программ
При работе с входным файлом z1000 три программы — одна на языке Си, одна на Си++ и одна на Perl — не выдали корректных результатов, поскольку не могли загрузить большой словарь или из-за истечения времени, отведенного на завершение этапа загрузки. Две программы на Java имели почти нулевую надежность и отказали по другим причинам; а одна программа на Rexx выдала много результатов, используя некорректный, только форматирующий сценарий — ее надежность составила 45%.
Отбросив эти явно ошибочные программы — тем самым, были исключены 13% программ на Си и Си++, 8% программ на Java и 5% сценариев — и сравнив остальные по языковым группам, мы обнаружили, что программы на Си и Си++ менее надежны, чем Java и сценарии. Однако эти различия были вызваны лишь несколькими программами с дефектами и потому не могут служить основанием для общих выводов.
Однако учитывая, что эти различия подчиняются тем же закономерностям, что и доля совершенно неработоспособных программ, которые были исключены из рассмотрения, можно заключить что различия в надежности среди языковых групп — реальный факт. Причиной преимущества сценариев может быть доступность более исчерпывающих тестовых данных для программистов, как объясняется во врезке «Достоверность сравнения».
Затем я сравнивал поведение при работе с входным файлом m1000, в котором могут содержаться телефонные номера без цифр, лишь с тире и наклонными чертами. Такие телефонные номера должны преобразовываться в пустые записи, но программисты склонны забывать о таких требованиях, читая задание. Поэтому на файле m1000 проверяется добротность программы. Большинство программ успешно справились с этой ситуацией, но половина программ Java и четыре сценария — один Tcl и три на языке Python — зависли на первом пустом телефонном номере, после того, как было выдано 10% результатов. Обычно сбой происходил из-за неправильного индекса строки или массива. Среди прочих программ, 15 — одна составленная на Си, пять Си++, четыре Java, две Perl, две Python и одна Rexx — не смогли обработать пустые телефонные номера, но в остальном работали корректно; их надежность составила 98,4%.
В целом, надежность сценариев, по-видимому, не ниже надежности несценарных программ.
Время работы и продуктивность труда
На рис. 6 показано общее время, затраченное на проектирование, составление и тестирование программы, сообщенное авторами сценариев и измеренное для программистов несценарных программ.

Рис. 6. Полное время, затраченное на реализацию программы
Программисты сценарной группы измеряли и сообщали время работы: время языков «несценарной» группы измерялось экспериментатором. Соотношение «плохих и хороших величин» в пределах от 1,5 для Си до 3,2 для Perl. Три величины для Java — рабочее время 40, 49 и 63 час — выходят за границы диаграммы и потому не показаны.
Мы обнаружили, что время составления сценариев с общей медианой 3,1 часа более чем вдвое меньше, чем несценарных программ с общей медианой 10,0 часов, хотя вероятно, различие преувеличено из-за неполной достоверности эксперимента.
К счастью, можно одновременно проверить два фактора, а именно, корректность сообщений о времени, затраченном на составление программ, и равенство квалификации программистов в сценарной и несценарной группах. Оба этих фактора, если они действительно играют роль, должны способствовать снижению времени работы сценарной группы: я предполагаю, что субъективные сообщения будут содержать уменьшенное, а не преувеличенное время работы программы, а в случае появления различий мы ожидали обнаружить более квалифицированных программистов в сценарной группе, поскольку в 1997 и 1998 годах, когда проводилось исследование, программисты Java были менее опытными, чем специалисты по другим языкам. В основу данной проверки положено старое практическое правило, согласно которому число строк исходного текста, выдаваемых программистом в час, не зависит от языка программирования. В нескольких широко применяемых методах оценки трудозатрат — в том числе Cocomo [3] Барри Боэма и таблицах языков программирования для оценки функциональных точек [4] Кейперса Джонса — явно предполагается, что почасовое число строк исходного текста не зависит от языка программирования. На рис. 7 показаны оценки рабочего времени, составленные на основе этого правила. Судя по достоверно известному диапазону продуктивности при работе с Java, все величины, за исключением трех лучших результатов для Tcl и лучших времен для Perl, выглядят правдоподобно.
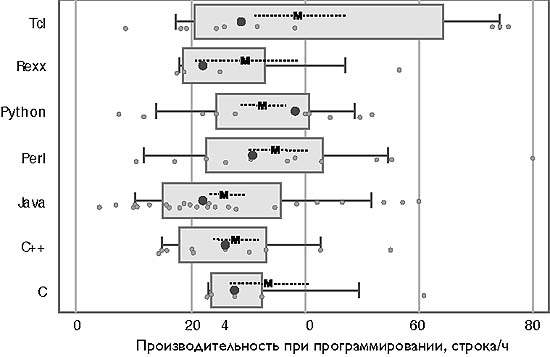
Рис. 7. Число строк исходного текста, написанных за полный рабочий час. Соотношение «плохих и хороших величин» в пределах от 1,4 для Си до 3,1 для Tcl
Ни одно из медианных различий не имеет явной статистической значимости, хотя отличия Java от Си, Perl, Python и Tcl (0,07 <= p <= 0,10) близки к критической величине. Даже при рассмотрении результатов по значительно более многочисленным укрупненным группам, различия между Си/Си+ и сценариями незначительны (p = 0,22), и только Java менее продуктивна, чем сценарии (p = 0,031) — разница составляла по меньшей мере 5,2 строки/час, с 80% достоверностью.
Данное сопоставление придает дополнительную достоверность нашему сравнительному исследованию затрат рабочего времени. Время, сообщенное программистами сценариев, по-видимому, лишь слегка занижено, или точно соответствует действительности. Таким образом, подтверждается двукратное преимущество языков сценариев в затратах рабочего времени. Временные затраты при работе с Java кажутся преувеличенными, поскольку в период проведения исследования Java-программисты были менее опытными, чем другие программисты.
Структура программы
При рассмотрении методов, избранных программистами, работающими с разными исследуемыми языками, обнаруживаются поразительные различия. Большинство программистов в группе сценариев использовали реализованные в языках ассоциативные массивы и сохраняли словарные слова для последующего считывания по числовым кодам. Поисковый алгоритм просто пытается извлечь данные из массива, используя в качестве ключа префиксы возрастающей длины, построенные на основе оставшейся части текущего телефонного номера. Каждое совпадение дает новое частичное решение, обработка которого будет завершена позднее.
В отличие от них, почти все несценарные программисты выбрали одно из следующих решений: в простейшем случае, они сохраняли весь словарь в массиве, обычно как в исходной символьной форме, так и в соответствующем номерном представлении. Затем они выбирали и проверяли одну десятую часть всего словаря для каждой цифры шифруемого телефонного номера, ради сокращения пространства поиска используя в качестве ключа только первую цифру. Такая процедура приводит к простому, но неэффективному решению.
Более изощренный подход состоит в использовании 10-арного дерева, каждый узел которого представляет определенную цифру, а узлы на высоте n представляют n-ный символ слова. Слово хранится в узле, если путь от корня к данному узлу представляет числовой шифр слова. Это решение — самое эффективное, но для построения и прохождения дерева требуется сравнительно большое число операторов. В Java многочисленность результирующих объектов приводит к большому расходу памяти из-за необходимости выделять чрезвычайно крупные области для хранения каждого объекта в текущих реализациях среды исполнения Java-программ.
В сценариях содержится меньше операторов, чем в несценарных программах, поскольку основная часть поисковых операций выполняется с помощью внутренних алгоритмов хеширования ассоциативных массивов. В отличие от них, в несценарных программах приходится явно задавать элементарные шаги поискового процесса. Эти различия еще более усугубляются усилиями — или их отсутствием — на построение структур данных и описание переменных.
Хотя хеш-таблицы реализованы в библиотеках классов как для Java, так и для Си++, ни один из программистов, работающих с несценарными языками не воспользовался ими, предпочитая строить дерево вручную. И наоборот, авторы сценариев с готовностью применяют встроенные в их языки хеш-таблицы.
Важнейшие выводы
Сравнительный анализ 80 реализаций программы кодирования телефонных номеров на семи различных языках принес следующие важнейшие результаты.
- Проектирование и составление программ на языках Perl, Python, Rexx и Tcl занимает не более половины времени, необходимого для программирования на Си, Си++ и Java — а длина исходного текста вдвое меньше.
- Явных различий в надежности между программами различных языковых групп не обнаружено.
- Типичный сценарий занимает примерно вдвое больше памяти, чем программа на Си или Си++. Программы на Java занимают втрое и вчетверо больше памяти, чем программы на Си и Си++.
- Программы на Си и Си++ выполняют инициализацию программы преобразования телефонных номеров, которая заключается в считывании словарного файла размером в 1 Мбайт и построении 70-килобайтной внутренней структуры данных, в три или четыре раза быстрее, чем программы на Java и примерно в пять или десять раз быстрее, чем сценарии.
- На основном этапе программы преобразования телефонных номеров ведется поиск во внутренней структуре данных, и программы на Си и Си++ работали всего примерно вдвое быстрее Java. Сценарии, как правило, работают быстрее программ на Java.
- Среди сценарных языков Perl и Python выполняли оба этапа быстрее, чем Tcl.
- Разброс любых исследованных параметров программ, возникший вследствие различий между программистами, работающими на одном языке — отраженный отношениями «плохих и хороших величин» — в среднем такой же или больше разброс характеристик, вызванного различиями языков.
Учитывая многочисленность реализаций и широкий круг программистов, результаты данного исследования, при критическом к ним отношении, вероятно, достаточно надежны, несмотря на отмеченные факторы, снижающие достоверность. Однако результаты следует считать корректными только для проблемы преобразования телефонных номеров; обобщение на различные области применения будет рискованным. Например, вызывает сомнения, что относительные результаты группы сценарных языков полностью подтвердятся при решении других проблем.
Несмотря на эти недостатки, прямое сопоставление различных языков программирования может принести полезную информацию. Например, можно сделать вывод, что издержки Java при работе с памятью по-прежнему огромны в сравнении с Си и Си++, однако время выполнения программ стало вполне приемлемым. Языки сценариев превратились в разумную альтернативу Си и Си++, даже для задач, связанных с обширными вычислениями и обработкой крупных массивов данных. Их относительное время выполнения и требования к памяти часто приемлемы, а программировать на них гораздо быстрее, по крайней мере, при составлении небольших программ.
Я считаю, что необходимо провести дополнительные, более масштабные исследования, подобные описанному в данной статье. Такая работа необходима, чтобы рассеять туман рекламы поставщиков и предвзятости специалистов, до конца выяснить достоинства, недостатки и особенности каждого языка. Такие знания помогут поднять индустрию программирования на новый уровень.
Лутц Прехельт (lutz@prechelt.de) — руководитель службы контроля качества компании abaXX Technology (Штуттгарт, Германия).
1. E. Bradley and R. Tibishirani, «An Introduction to the Bootstrap,» Monographs on Statistics and Applied Probability 57, Chapman and Hall, New York, 1993
2. L. Prechelt, An Empirical Comparison of C, C++, Java, Perl, Python, Rexx and Tcl for Search/String-Processing Program, Tech Report 2000-5, Fakultat fur Informattik, Universitat Karlsruhe, Germany, Mar. 2000.
3. B.W. Boehm, Software Engineering Economics, Prentice Hall, Englewood Cliffs, N.J., 1981
4. C. Jones, Software Productivity Research, Programming Languages Table, Version 7, 1996.
An Empirical Comparison of Seven Programming Languages, Lutz Prechelt, IEEE Computer, October 2000, pp. 23-29. Copyright IEEE CS, Reprinted with permission. All rights reserved.
Достоверность сравнения
Любое сравнение языков программирования, основанное на сопоставлении образцовых программ, достоверно лишь в той мере, в какой могут считаться одинаковыми способности программистов, работающих с этими языками. В нашем случае, должен был быть сопоставимым лишь общий уровень программ, а не их индивидуальные качества. Ряд факторов мог отрицательно влиять на сопоставимость 80 программ, проанализированных в ходе данного исследования.
Программы получены из двух различных источников. Программы на Java, Си и Си++ были составлены в 1997 и 1998 годах во время контролируемого эксперимента, в котором участвовали студенты старших курсов факультета вычислительной техники (L. Prechelt and B. Unger, A Controlled Experiment on the Effects of PSP Trimming: Detailed Description and Evaluation, Tech Report 1/1999, Fakultat fur Informattik, Universitat Karlsruhe, Germany, Mar. 1999). Программы на Perl, Python, Rexx и Tcl были составлены в различных условиях добровольцами, которые откликнулись на приглашение, опубликованное в нескольких конференциях. Поэтому авторы имели разные уровни подготовки и опыт.
Квалификация программистов
Вероятно, что публичный призыв к сотрудничеству может привлечь только весьма компетентных программистов, поэтому сценарные программы составлялись в целом более квалифицированными специалистами, чем программы на несценарных языках. Однако два обстоятельства позволяют предположить, что данное противоречие не внесло серьезных ошибок в результаты исследования. Во-первых, за некоторыми исключениями, студенты — авторы несценарных программ — достаточно опытны и умелы. Во-вторых, значительная часть авторов сценариев сообщили, что лишь начинают работать с соответствующими языками или не имеют основательной программной подготовки. Среди них были конструктор сверхбольших микросхем, системный администратор и социолог.
В несценарной группе программисты на Java имели меньший опыт работы со своим языком, чем программисты на Си и Си++, поскольку в 1997 и 1998 годах Java был еще новым языком. В сценарной группе программисты на Perl имели более высокую квалификацию, чем другие участники эксперимента; по-видимому, язык Perl привлекает особенно талантливых программистов — по крайней мере, таково мое личное впечатление.
Точность измерения времени работы
Мы точно знаем время программирования в условиях контролируемого эксперимента с несценарными языками, однако ничто не мешало авторам сценариев занизить время, потраченное ими на составление программ. Хуже того, некоторые из авторов, очевидно, приступили к работе спустя много дней после того, как ознакомились с требованиями, предъявляемыми к программам. Один программист сообщил, что начал составлять программу через две недели после прочтения объявления «... в это время подсознательно я мог уже работать над решением.»
Однако практика показывает, что в среднем сроки работы над сценариями также верны: данные для всех языков вполне соответствуют общеизвестной инженерной истине, что «число строк исходного текста, написанное за один час, не зависит от языка». К нашему удовлетворению, те же данные подтверждают, что квалификация авторов сценариев не выше, чем программистов другой группы.
Различие задач и условий работы
Главным требованием к несценарной группе была правильность программы; приемный контроль подразумевал высокую надежность и по меньшей мере некоторую степень эффективности.
К сценарной группе наряду с главным критерием корректности предъявлялись восемь дополнительных качественных требований. Вместо приемного контроля несценарной группы авторам сценариев были предоставлены входные и выходные данные z1000 для собственного тестирования. В обоих случаях различия могут дать преимущество сценарной группе.
Выводы
В целом, метод сбора данных заранее дает ряд значимых, хотя и скромных преимуществ сценарной группе. Также вероятны различия между средними уровнями квалификации программистов, работающих с двумя любыми языками. Чтобы исключить отрицательное влияние этих факторов на достоверность результатов, мы пренебрегаем малыми различиями между языками, поскольку причиной их может быть некорректность данных. Однако крупные различия, по всей вероятности, достоверны.
Вернуться
| Язык | Число программ | Компилятор или платформа выполнения |
| Tcl | 10 | Tcl 8.2.2 |
| Rexx | 4 | Regina 0.08g |
| Python | 13 | Python 1.5.2 |
| Perl | 13 | Perl 5.005.02 |
| Java | 24 | Sun JDK 1.2.1/1.2.2 |
| Си++ | 11 | GNU g++ 2.7.2 |
| Си | 5 | GNU gcc 2.7.2 |
Задача: преобразование телефонных номеров
Во всех программах данного исследования реализованы одинаковые функции преобразования телефонных номеров в строки слов, как показано ниже.
Сначала программа загружает в память словарь объемом 73 113 слов из 938-килобайтного плоского текстового файла, в каждой строке которого хранится одно слово. Затем программа считывает «телефонные номера» из другого файла, преобразует их один за другим в последовательности слов и распечатывает результаты. Преобразование выполняется в соответствии с жестко заданным соответствием символов и цифр:
| e | fng | rwx | dsy | ft | am | civ | bku | lop | ghz |
| 0 | 111 | 222 | 333 | 44 | 55 | 666 | 777 | 888 | 999 |
Это значит, что цифра 5 может быть преобразована в символ «a» или символ «m». Программа должна найти такую последовательность слов, чтобы последовательность символов в этих словах точно соответствовала последовательности цифр в телефонном номере. Должны быть найдены и отпечатаны все возможные решения. Программа генерирует решение слово за словом, и если на каком-то этапе не может отыскать словарного слова, то в данную позицию результата может быть вставлена единственная цифра телефонного номера. Для многих телефонных номеров решений не существует. Например, для номера 3586-75 программа выбирает следующие слова из словаря, содержащего слова «Dali», «um», «Sao», «da», «Pik» и 73 108 других:
3586-75: Dali um 3586-75: Sao 6 um 3586-75: da Pik 5
Обрабатывая каждый номер, программа должна составить список частичных решений, а для эффективного доступа к словарю он должен быть встроен во вспомогательную структуру данных, например, 10-арное цифровое дерево.
