
Разбирается технология подготовки Web-версий статистических сборников, реализованная для Университетской информационной системы «Россия» (УИС «Россия» — www.cir.ru).
Основное требование к Web-версии сборника - хорошая структурированность представленной информации. Это касается не только ее четкого разделения на взаимосвязанные блоки, каждый из которых обладает достаточной смысловой завершенностью, но и организации интуитивно понятного доступа к каждому ее элементу.
Основные задачи
Информационный блок «Статистика России» объединяет более двадцати самостоятельных электронных изданий, каждое из которых имеет свое оглавление и свой стиль оформления. Реально исходные электронные версии сборников различных организаций представлены в разных форматах, включая обычный текст ASCII, документы RTF, HTML, форматы Word и Excel, а также графические файлы в форматах GIF и JPG. При подготовке Web-версии возникают следующие задачи:
- преобразование электронной версии публикации в HTML-формат (разбиение на части с сохранением логической структуры, обработка оглавления, сносок, примечаний, расстановка ссылок на связанные разделы внутри текста);
- интеграция различных публикаций (единообразное оформление, создание сводного оглавления, поддержка ретроспективы);
- навигация по сайту и возможность сквозного поиска;
- ведение сайта (удаление, изменение, добавление документов, поддержка целостности).
Этапы конвертирования
Итак, первая задача - это преобразование информации в формат, понятный любому браузеру. Современные текстовые редакторы поддерживают возможность сохранения документов в формате HTML, однако результат подобного преобразования оставляет желать лучшего. Проблема заключается в том, что сама по себе подобная операция не позволяет отразить специфику и реализовать все дополнительные возможности web-публикации. Весь документ сохраняется в одном файле, который получается излишне объемным. Практически не используются гипертекстовые возможности, за исключением перехода к разделам оглавления, а также прямой и обратной навигации по сноскам. Для полноценного преобразования в формат HTML документ желательно разбить на части согласно его логической структуре. Следует обратить особое внимание на оформление оглавления, сносок, примечаний и других элементов навигационного и вспомогательного характера, расставить ссылки на взаимосвязанные разделы документа.
Как показывает практика, при наличии хорошо подготовленного оригинал-макета, процесс его конвертации в HTML-формат с выделением смысловых блоков и построением развитой гиперссылочной структуры в основном можно автоматизировать. Процесс разбивается на несколько этапов:
- сохранение публикации в формате HTML с использованием стандартных средств (например, функция «Сохранить как Web-страницу» в Word или Excel);
- разметка логической структуры полученного HTML-файла с помощью некоторого набора правил-эвристик. В файле документа расставляются специальные пометки, определяющие гиперссылки, выделяются самостоятельные смысловые блоки (сноски, примечания, таблицы, графики и т.п.), формируются заголовки, как отдельных блоков, так и сборника в целом;
- преобразование размеченного макета в HTML-страницы, предоставляемые конечному пользователю. При этом происходит «разрезание» текста на отдельные компоненты в соответствии с предложенной разметкой и построение связей между ними по заданным правилам. Производится также оформление заголовков и вставка таблиц стилей.
Подобная технология конвертирования обладает следующими достоинствами: процесс разбора документов Word может оказаться весьма сложным, а благодаря использованию стандартных средств преобразования в HTML-формат отпадает необходимость разбирать исходный формат документа. Для обработки макетов публикаций, оформленных по-разному, необходимо менять только код программы, отвечающей за второй этап. Практика показывает, что объем этой программы получается на порядок меньше, чем объем программы, реализующей третий этап. Неизменность программы, преобразующей размеченный файл в систему взаимосвязанных HTML-документов, позволяет легко решить проблему единообразного оформления публикаций, поступающих из разных источников.
Для выделения обособленных фрагментов текста используются специальные теги разметки, структура которых аналогична структуре тегов HTML, но заключены они не в угловые, а в фигурные скобки.
Теги разметки
Приведем краткое описание нескольких основных тегов разметки. Тег {BLK}...{/BLK} используется для выделения части текста в отдельный HTML-файл. Параметр ID позволяет задать уникальный идентификатор блока, который может затем использоваться для ссылок на этот блок. Необязательный параметр WINDOW определяет, в каком окне браузера отображать блок при переходе на него по ссылке. С помощью параметра BCKGRND можно задать имена файлов, в которых содержится HTML-текст, размещаемый непосредственно перед и непосредственно после содержимого блока. В этих текстах обычно задается кодировка документа, его фон, шрифт, используемый по умолчанию, подключаются таблицы стилей.
Тег {FN}...{/FN} позволяет выделять тела сносок в текущем блоке и помещать их в отдельный файл, отображаемый в специальном фрейме. Количество сносок может быть достаточно большим, поэтому для удобства просмотра они отображаются в отдельном фрейме, расположенном под основным документом, а не в конце документа. Тег {HL}...{/HL} используется для выделения текста определенным стилем. Параметр NAME задает имя стиля. Необязательный параметр LINK позволяет вынести ссылку на выделяемый текст в начало файла. Эта функция может оказаться полезной, если выделяемый текст - это заголовок раздела. Метку в тексте можно поставить с помощью тега {LBL ID=?lid?}, а сослаться на нее с помощью тега {RT LBLID=?lid?}...{/RT}, при этом метка ищется только в текущем блоке. Если параметр LBLID заменить параметром BLKID, то можно сослаться на другой блок.
Часто возникает другая задача, связанная с необходимостью извлечь информацию из одной части текста и поместить ее в другую часть. Например, в начале текста имеется оглавление, состоящее из перечня разделов и номеров страниц, а требуется в конце каждого раздела написать соответствующий ему номер страницы. Эту процедуру легко осуществить с помощью следующих двух тегов: тег {SD KEY=?key? VALUE=?value?} позволяет сохранить значение value за ключом key, с помощью тега {GD KEY=?key?} значение value можно вставить в текст.
Автоматическая и ручная разметка
Подавляющее большинство правил-эвристик для автоматической расстановки тегов удается записать в виде достаточно компактных регулярных выражений. Благодаря этому программы, осуществляющие автоматическую разметку, имеют сравнительно небольшие размеры (200-300 строк на языке Perl).
Если текст имеет сложную логическую структуру, автоматическая разметка может быть скорректирована и дополнена вручную с помощью текстового редактора. Именно необходимость обеспечить возможность удобной ручной разметки вынуждает оформлять теги разметки фигурными, а не угловыми скобками, как это принято в HTML или в XML. Такое различие в оформлении тегов позволяет расставлять теги перед первым этапом, например в редакторе Word (угловые скобки Word сохраняет в виде < и >). Кроме того, размеченный файл можно просмотреть в Web-браузере, при этом отображаются теги, оформленные фигурными скобками, в отличие от тегов, оформленных скобками угловыми.
Способы хранения и отображения ссылок
Для сайта, содержащего большое количество документов, необходимо обеспечить удобную навигацию по коллекциям документов и сайту в целом. Для крупных информационных ресурсов в Internet стал стандартным определенный набор возможностей: переход с любого документа на главную страницу сайта, к основным его разделам, а также на страницу поиска по серверу. Многие сайты предоставляют возможность просмотра карты сервера. Удобной является функция последовательного просмотра документов: для каждого документа предоставляются ссылки на следующий и предыдущий документы (если таковые имеются), а также возможность перейти к вышестоящему разделу оглавления, в котором находится документ. Нахождение многих файлов может достигаться с помощью нескольких альтернативных структур доступа (в УИС «Россия» помимо полиграфических оглавлений каждого сборника или доклада используются три сводных тематических оглавления, включающих более 3000 пунктов). В этом случае необходимо обеспечить независимую навигацию по каждой из этих структур доступа.
Ссылки, которые нужно поместить на странице рядом с документом, подразделяются на общие для всех документов сайта и контекстно-зависимые - уникальные для каждого документа. Общие ссылки легко реализовать, поместив их в отдельный HTML-фрейм. Существует несколько способов реализации отображения контекстно-зависимых ссылок:
- добавление ссылки в каждый HTML-файл при создании файлов;
- добавление ссылки автоматически перед передачей файла пользователю, например, при помощи скрипта CGI;
- отображение ссылок в отдельном фрейме, который будет меняться в зависимости от отображаемого документа.
Первый вариант не требует содержания на Web-сервере дополнительных программ или структур данных, допускает просмотр файлов с диска (без Web-сервера) и легко реализуется в случае, если все необходимые ссылки известны на момент создания файлов. Однако в случае, если все необходимые для отображения ссылки заранее неизвестны, этот вариант неудобен для поддержания и изменения содержания сайта, поскольку при добавлении одного документа нужно проставить ссылки на него в разных местах. Этот вариант очень широко используется для многих коллекций документов [1, 2].
Разнообразие навигационных возможностей может существенно осложнить поддержку сайта. Если связи между документами хранить в самих документах, то могут возникнуть осложнения при удалении старых и добавлении новых файлов. Задача существенно упрощается, если связи между документами хранить в централизованном хранилище ссылок, которое может представлять собой один или несколько файлов описания карты сервера или базу данных. Подобное отделение связей между документами от них самих позволяет во многом упростить и автоматизировать ведение сайта. Оно дает возможность разрабатывать и совершенствовать альтернативные структуры доступа к данным, внося изменения в централизованное хранилище ссылок, не прибегая к масштабным коррективам базы в целом. Второй и третий варианты реализации отображения ссылок представляют собой различные методы организации выдачи документов с использованием централизованного хранилища ссылок.
Особенностью второго варианта, использующего специальные программы на Web-сервере (CGI-скрипты, Java-сервлеты и т. п.), которые добавляют ссылки в передаваемые пользователю документы, является то, что для просмотра файлов необходим Web-сервер с установленной программой обработки файлов. При этом пользователю можно выдавать страницы простой структуры - без фреймов и Java-скриптов, которые понятны любому Web-браузеру. Этот вариант широко используется при создании Web-сайтов крупных компаний, Web-порталов [3]. Однако этот вариант не всегда удобен для специалистов, сопровождающих предметную область (публикации), поскольку просмотр текущей редакции блока документов требует использования Web-сервера. Кроме того, может возникнуть необходимость дублирования отдельных коллекций документов на компакт-дисках, в этом случае необходимость использования Web-сервера затруднит подготовку публикации.
Для реализации навигации в УИС «Россия» был выбран третий вариант. Централизованное хранилище ссылок представляет собой несколько файлов карты сервера.
Реализация
В файле карты сервера для каждого документа указываются:
- разделы оглавлений, к которым относится данный документ;
- документы, являющиеся следующими и предыдущими для полиграфического и сводного оглавления;
- ссылки, которые необходимо соотнести этому документу;
- информацию о том, как и где эти ссылки отображать.
В отдельный фрейм на сайте помещается java-апплет, который загружает файл карты сервера и отслеживает содержание фрейма с отображаемым документом (при помощи вызова функций JavaScript). При смене документа апплет выбирает из карты сервера информацию о том, какие ссылки необходимо отобразить, и на основании этой информации формирует HTML-файл навигации, который отображается в отдельном (третьем) фрейме. Содержание фрейма с апплетом не изменяется при просмотре данного сайта.
Важен выбор формата файла карты сервера. Этот файл содержит информацию о структуре сайта, одно или несколько оглавлений сайта, а также информацию о том, как нужно отображать навигационный фрейм. Поскольку редактированием этого файла обычно занимаются специалисты определенной предметной области, составляющие сводные оглавления, а также дизайнеры, необходимо обеспечить возможность его наглядного отображения и удобного редактирования.
Так как отдельно взятое оглавление представляет собой многоуровневый список, удобным форматом для хранения файла карты сервера является XML, позволяющий определять сколь угодно сложные иерархические структуры данных. Для наглядного просмотра структуры XML-файла можно использовать любой браузер, а при надлежащем выборе используемых тегов XML-файл можно отображать как HTML-файл без изменений (технология XHTML). Несомненны преимущества XML и для разработчиков программ, сопровождающих файл-карту: существует богатый набор API-интерфейсов для работы с XML, обеспечивающий разбор структуры файла и автоматическое обнаружение ошибок. Кроме того, в случае необходимости несложно расширить набор поддерживаемых тегов в файле карты сервера.
Файл карты сервера УИС «Россия» имеет иерархическую структуру, позволяющую реализовать наследование ссылок. Так, например, ссылка, по которой осуществляется переход на главную страницу сайта, указывается в одном месте и автоматически наследуется всеми документами.
К каждому узлу дерева может быть приписано некоторое количество тегов . Для того чтобы создать файл навигации для некоторого документа, программа находит все теги с атрибутом HREF, соответствующим данному документу и затем для каждого такого листа дерева собирает последовательно все теги , приписанные к каждому из вышестоящих узлов дерева иерархии.
Файл карты сервера также включает теги вспомогательного характера (например, тег для подключения внешних файлов). Программа обработки файла карты сервера игнорирует любой текст, кроме текста внутри тегов ..., а также любые теги, не известные программе. Это позволяет добавлять в файл карты сервера дополнительные HTML-теги так, чтобы можно было наглядно представлять структуру карты сервера при просмотре файла как HTML-документа. Кроме того, планируется использовать файл карты сервера для автоматической генерации оглавлений разделов сайта. При этом теги оформления, которые сейчас игнорируются программой обработки карты сервера, могут быть полезными при автоматической генерации оглавлений.
Недостаток предложенного решения в том, что файл карты сервера имеет большой размер (в нашем случае - 1,5 Мбайт) и его передача при входе на сайт происходит достаточно долго. Проблема решается, если перенести приложение обработки файла карты сервера на сторону сервера.
В УИС «Россия» файл карты сервера постоянно загружен в память специальной программой обработки, к которой апплет обращается по протоколу HTTP. Апплет посылает серверу запрос, содержащий информацию о текущем отображаемом документе, а сервер возвращает уже готовый HTML-файл, который затем отображается в навигационном фрейме. Такое решение потребовало небольшой переработки кода приложения для создания Java-сервлета обработки запросов. При этом одновременно сосуществуют два варианта решения - для отладки или для создания версии публикации на компакт-диске (без использования сервлета) и для сайта (с использованием).
Статья подготовлена на основе доклада авторов на Всероссийской научной конференции «Научный сервис в Internet» (Новороссийск, 2000).
Литература
[1] The Java Tutorial, http://java.sun.com/docs/books/tutorial/
[2] The Javadoc tool, http://java.sun.com/products/jdk/1.2/
docs/tooldocs/javadoc/
[3] Спецификация CGI, http://hoohoo.ncsa.uiuc.edu/cgi/interface.html
[4] Java API for XML Processing, http://java.sun.com/xml/
Об авторах
Михаил Агеев (ageev@mail.cir.ru) и Виктор Ламбурт (lamburt@mail.cir.ru) — сотрудники Центра информационных исследований (Москва). Сергей Журавлев (zhuravlev@mail.cir.ru) — сотрудник НИВЦ МГУ (Москва).
Использование XML-файла карты сервера
Для данного файла карты сервера и документа «Основные показатели промышленности», находящегося по относительному адресу stat/Publications/Prom1998/1/Prom1998_01_0020.htm, программа обработки карты сервера ищет все ссылки вида (таких ссылок в данном случае имеется две - одна в дереве полиграфического оглавления и одна в дереве сводного оглавления). Затем, для каждой из этих ссылок последовательно производится поиск вышележащих по иерархии XML-файла блоков ... и тегов для формирования HTML-файла фрейма навигации. Для первой ссылки (внутри полиграфического оглавления) это будут:
1) тег
- : создаются стрелки навигации по соседним документам внутри полиграфического оглавления;
2) тег : формируется ссылка на полиграфическое оглавление в виде картинки  ;
;
3) тег : создается ссылка на главную страницу УИС РОССИЯ в виде картинки  .
.
Аналогично, для второй ссылки (внутри сводного оглавления) будут созданы стрелки навигации по соседним документам внутри сводного оглавления и ссылка на сводное оглавление. Тег также находится в дереве иерархии второй ссылки, но он не будет включен в HTML-файл фрейма навигации, поскольку он уже был туда включен при обработке первой ссылки.
Для экономии места из представленного здесь файла карты сервера вырезаны некоторые несущественные детали. На рис. 1 показано, как выглядит страница «Основные показатели промышленности» в УИС «Россия».
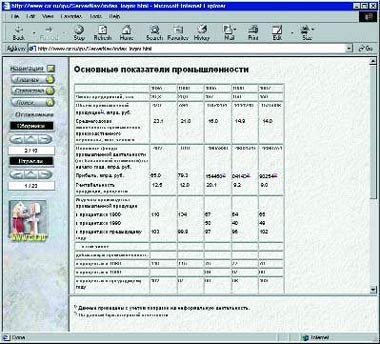 |
| Рис. 1. Вид страницы «Основные показатели промышленности» |
При просмотре файла карты сервера УИС «Россия» как HTML-страницы наглядно отображается структура оглавлений и отображаемые ссылки. Это позволяет легко создавать файлы карты сервера и находить ошибки в структуре оглавлений без использования специализированных средств отображения. Тот же файл карты сервера при просмотре браузером как HTML-страницы показан на рис. 2.
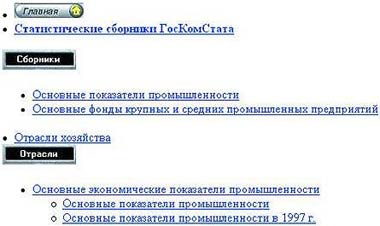 |
| Рис. 2. Файл карты сервера как HTML-страница |
Для реализации программы обработки XML-файлов карты сервера в УИС РОССИЯ используется Java API for XML Parsing [4].
