Врезка 1
15.12.2000
2370 прочтений

![]()
|
Вернуться к статье
|
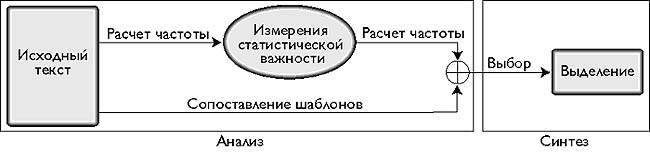 |
Рис. 1. Архитектура извлечения фрагментов текста (реферирование без опоры на знания)
Поочередная обработка каждого предложения исходного текста. Весовые коэффициенты основываются на измерениях статистической важности (от частоты упоминания термина до операций сопоставления образцов), наличие специальных терминов и расположения предложения в тексте. Весовые коэффициенты предложения, полученные на этапе анализа, передаются непосредственно на вход компонента синтеза, на котором извлекаются предложения с наивысшими коэффициентами, определенными по степени сжатия. |
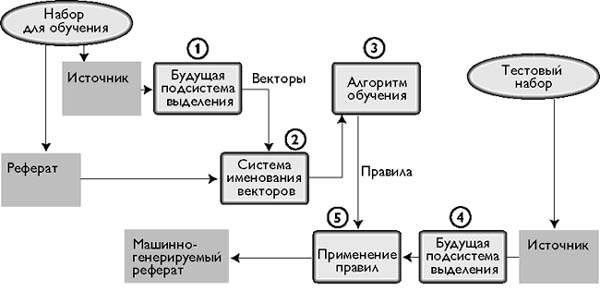 |
Рис. 2. Классификатор с обучением порядку реферирования (1)
На этапе обучения вектор характеристик представляет каждое предложение источника (2). Классификатор помечает каждый вектор в соответствии с однородностью информации в предложениях и реферате. Затем он направляет набор обучающих примеров на (3) алгоритм обучения, который запоминает правила классификации, дабы установить, может ли то или иное предложение быть включенным в реферат. На этапе тестирования рефераты отсутствуют. Вместо этого, классификатор (4) преобразует каждое предложение тестового набора в вектор характеристик и (5) проверяет соответствие имеющимся в его распоряжении правилам для формирования реферата. |
Вернуться к статье
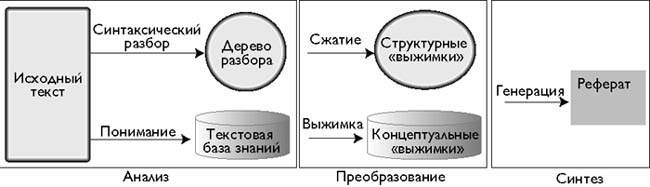 |
Рис. 3. Архитектура формирования реферата (реферирование с опорой на знания)
Формирование краткого изложения опирается на два базовых подхода, которые можно комбинировать. При первом подходе (вверху), на этапе анализа создается дерево разбора, которое на этапе преобразования подвергается сжатию путем отсечения или перегруппировки ветвей в соответствии со структурными критериями, такими как скобки или подчиненные предложения. В итоге получаются структурные «выжимки» текста, имеющие значительно менее сложную структуру. При втором подходе (внизу), на этапе анализа создается концептуальное представление всей содержащейся в документе информации на основании базы знаний. На этапе преобразования оно сжимается путем объединения и обобщения информации. В итоге формируются концептуальные «выжимки», то есть менее подробное концептуальное представление. На этапе синтеза в обоих подходах создается естественно-языковой реферат. |
Вернуться к статье
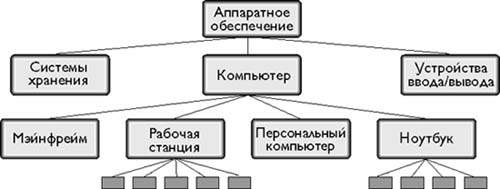 |
Рис. 4. Схема работы сжатия на базе обобщения
Текстовая база знаний состоит из концептуальных классов (таких как Laptop) и их экземпляров (таких как конкретный продукт). Экземпляры, весовой коэффициент которых больше нуля (значение коэффициента отражает число упоминаний данного понятия в тексте), считаются активными. Понятие считается важным, когда отношение числа экземпляров к числу активных экземпляров больше числа активных экземпляров. Как видно из диаграммы понятия класса Workstation являются важными, поскольку он имеет три активных экземпляра (зеленые квадраты). С другой стороны, понятие Laptop не является важным, поскольку активен только один экземпляр. Способность выявлять важные понятия означает, что средство реферирования может обобщать большее число абстрактных характеристик содержимого текста. Например, он может обобщить упоминания, связанные с Workstation, с темой Computer или Hardware. |
|
|
Вернуться к статье
|

