

Является ли XML базой данных?
Прежде чем приступить к обсуждению XML и баз данных, необходимо ответить на естественно возникающий вопрос: «А является ли XML базой данных?». Если строго придерживаться определения базы данных, то «XML» - в том случае, если под этим термином подразумевается XML-документ, - базой данных не является. Хотя XML-документ содержит данные, без дополнительного программного обеспечения, которое служит для обработки этих данных, он является базой данных не в большей степени, чем любой другой текстовый файл.
Если говорить более широко, то есть, подразумевая под «XML» собственно XML-документ и сопровождающие XML инструменты и технологии - ответ будет звучать как «да, но». «Да», потому что XML предоставляет множество функций баз данных: хранение (XML-документ), схемы (DTDS, язык определения схем XML), язык запросов (XQL, XML-QL, QUILT и другие), интерфейсы для языков программирования (SAX, DOM) и так далее. «Но», потому что многие функции присущие классическим базам данных все же отсутствуют: эффективное хранение, индексация, обеспечение безопасности, обработка транзакций и поддержка целостности данных, многопользовательский доступ, триггеры, поддержка запросов ко многим документам и т.д.
Таким образом, хотя допустимо использовать XML в качестве базы данных в средах, где нет больших объемов информации, большого количества пользователей, а также не требующих высокой производительности, он совершенно не подходит для многих реальных задач, предполагающих поддержку большого числа пользователей, жесткие требования к целостности данных и производительности. Кроме того, учитывая невысокие цены на такие продукты, как dBASE и Access, нет серьезных причин использовать XML в качестве базы данных даже тогда, когда это возможно с учетом особенностей области применения.
Почему следует использовать базы данных?
Первое, что необходимо уяснить для себя, рассматривая вопрос о применении XML и базы данных, - почему последняя должна стать основным инструментом. Есть ли необходимость получать доступ к унаследованным данным? Требуется ли место для хранения Web-страниц? Используется ли база данных приложением электронной коммерции, в котором XML играет роль средства передачи данных? Ответы на эти вопросы повлияют на выбор базы данных и промежуточного ПО (если оно будет использоваться), а также на способ применения базы данных.
Например, допустим, используется приложение электронной коммерции, в котором XML играет роль транспорта данных. Можно с уверенностью утверждать, что данные отличаются большой структурированностью и что такие аспекты, как сущности и кодировки, применяемые в документах XML, не имеют решающего значения, в конце концов, важны сами данные, а не то, как они физически хранятся в документе. Если используется относительно простое приложение, реляционная база данных и промежуточное ПО в качестве транспорта данных могут удовлетворить все требования. Если же это крупное и сложное приложение, потребуется полная среда разработки приложений, поддерживающая XML.
С другой стороны, возникают и такие задачи, как поддержка Web-сайтов с большим количеством XML-документов, содержащих, в основном, текстовую информацию. Таким сайтом нужно не только управлять, нужно обеспечивать доступ для многочисленных пользователей. Скорее всего, структура документов здесь весьма неоднородна, а использование сущностей имеет принципиальное значение, поскольку они составляют основу структурирования документов. В этом случае, возможно, возникнет потребность в базах данных с «естественной поддержкой» XML, которые обеспечивают поддержку версий, отслеживание использования сущностей и язык запросов наподобие XQL.
Данные и документы
Пожалуй, наиболее важным фактором выбора базы данных является то, для чего планируется ее использовать - для хранения данных или документов. Если необходимо хранить данные, нужно выбирать базу данных, настроенную на хранение данных, т. е. реляционную или объектно-ориентированную, а также промежуточное программное обеспечение, предназначенное для передачи данных от базы данных в документы XML. С другой стороны, потребность в хранении документов, заставляет выбирать систему управления информационным обеспечением, которая ориентирована специально на хранение документов.
Хотя можно и самостоятельно обеспечить хранение документов в реляционной или объектно-ориентированной базе данных, это просто будет повторением работы, которую уже проделали другие, те кто создавал средства управления информационным обеспечением. Аналогично, хотя такие системы, как правило, разворачиваются поверх объектно-ориентированной или иерархической базы данных, использовать их в качестве лишь базы данных - задача не их легких.
Определить, что нужно хранить - данные или документы - можно, просто просмотрев XML-документы. Дело в том, что XML-документы подразделяются на две категории: ориентированные на данные и на документы.
Документы, ориентированные на данные
Документы, ориентированные на данные, характеризуются четкой упорядоченной структурой, их глубокой проработкой (наименьший независимый элемент данных может располагаться на уровне атрибута), кроме того, смешанного информационного наполнения нет, либо оно присутствует в минимальном объеме. Порядок, в котором появляются однородные элементы, часто не имеет значения. Хорошим примером в данном случае служат XML-документы, содержащие заказы на продажи, графики полетов, меню ресторанов и так далее. Документы, ориентированные на данные, обычно создаются для машинной обработки; возможности XML используются здесь в минимальной степени - он играет роль транспорта.
Документ, ориентированный на данные, может выглядеть, например, следующим образом.
ABC Industries
123 Main St.
Chicago
IL
60609
981215
Гаечный ключ:
нержавеющая сталь, отливка,
пожизненная гарантия.
Сепаратор:
алюминий, гарантия -
один год.
Следует обратить внимание, что в мире XML многие документы, содержащие большой объем текстовой информации, ориентированы на данные. Так, например, страница на Amazon.com, где приводится информация о книге, содержит в основном текст, при этом имеет весьма жесткую структуру. Большая часть текста повторяется во всех аналогичных страницах, объем текста, приходящегося на каждую страницу, строго ограничен по объему.
Таким образом, страница может быть построена на базе простого, ориентированного на данные документа XML - содержащего информацию, соответствующую каждой странице, которая извлекается из базы данных и таблицы стилей XSL для добавления стереотипного текста. В общем случае любой Web-сайт, на котором производится динамическое создание документов HTML путем заполнения шаблона данными из базы данных, может быть заменен ориентированными на данные XML-документами и одной или более таблицами стилей XSL.
В качестве примера можно рассмотреть следующий документ, содержащий лизинговый договор.
ABC Industries
договаривается о передаче в долговременную
аренду собственности
123 Main St., Chicago,
IL from XYZ
Properties на срок не
менее
TimeUnit=»Months»>18
по цене
Currency=»USD»
TimeUnit=»Months»>1000.
Его можно построить при помощи следующего XML-документа и простой таблицы стилей.
ABC Industries
123 Main St., Chicago,
IL
XYZ Properties
18
1000
Документы, ориентированные на документы
Документы, ориентированные на документы, не имеют жесткой структуры, не отличаются глубиной проработки данных (минимальный независимый элемент располагается на уровне элемента смешанного информационного наполнения или целого документа), кроме того, они характеризуются большим объемом смешанного информационного наполнения. Порядок, в котором возникают однородные элементы, почти всегда важен. Хорошим примером служат книги, электронная почта, рекламные объявления и практически все документы XHTML. Подобные документы, как правило, предназначены для людей.
Вот пример подобного документа.
Гаечный ключ Full Fabrication Labs, Inc. гаечный ключ небольшого размера. Гаечный ключ, производится в двух ориентациях, изготавливается из нержавеющей стали. Ручка имеет резиновый наконечник для удобства работы. Допустима подгонка. You can:Закажите ваш собственный ключ Дополнительная информация о ключах Загрузить каталог Ключ будет стоить вам всего 19,99 долл., если вы закажете его прямо сейчас, кроме того, вы получите в подарок молоток для тонкой работы.
Данные, документы и базы данных
На практике далеко не всегда возможно провести четкую границу между разными типами документов. Например, документы, по сути являющиеся ориентированными на данные, такие как инвойсы, могут содержать неструктурированные данные с небольшой глубиной проработки, например, описания запчастей. Напротив, документы, которые в принципе являются ориентированными на документы, например руководства пользователя, могут содержать проработанные данные с четкой структурой (часто метаданные), типа, имени и регалий автора и выходных данных. И все же, охарактеризовав документы как ориентированные на данные или на документы, легче понять, с чем придется работать - с данными или документами, а, следовательно, существенно упростить для себя решение вопроса о том, какую систему выбрать.
Для хранения и/или извлечения данных нужна база данных (как правило, реляционная, объектно-ориентированная или иерархическая) и промежуточное ПО (либо встроенное, либо предлагаемое независимыми компаниями), или же XML-сервер (платформа для создания распределенных приложений, таких как приложения электронной коммерции, которые используют XML для передачи данных), или Web-сервер, поддерживающий XML (Web-сервер, способный строить XML-документы на базе данных, получаемых из базы). Для хранения документов нужна специальная система управления информационным наполнением. Вопросы использования систем обоих типов рассмотрены в разделах «Хранение и извлечение данных» и «Хранение и извлечение документов». Список ПО приводится в XML Database Products.
Хранение и извлечение данных
Источником данных того типа, которые характерны для документов, ориентированных на данные, являются либо база данных (в этом случае возникает необходимость представить их в формате XML), либо XML-документы (в этом случае придется обеспечивать хранение их в базе данных). Примером первых служат огромные объемы унаследованных данных, которые хранятся в реляционных базах данных; примером последних - данные, создающиеся в Web. Эти данные надо хранить в базе данных для последующей обработки. Таким образом, может сложиться потребность в программах, которые преобразуют данные из XML-документов в формат базы данных, или наоборот. Могут потребоваться и оба типа преобразований, и, соответственно, ПО для их выполнения.
Преобразование данных
При хранении информации в базе данных, часто можно отбросить большой объем информации о документе, такой как название и описатели DTD, а также физическую структуру, т. е. определения сущностей и использования, порядок атрибутов и однородных элементов, способ хранения двоичных элементов (Base64 или неинтерпретируемых сущностей, или что-либо еще), разделы CDATA и информацию о кодировании. Аналогично, при извлечении данных из базы данных и формировании XML-документа, последний, вероятнее всего, не будет содержать CDATA или использования сущностей (отличных от заранее определенных сущностей lt, gt, amp, apos и quot), а порядок однородных элементов и атрибутов, скорее всего, определит порядок поступления данных из базы.
Хотя на первый взгляд это производит удручающее впечатление, все это вполне разумно.
Рассмотрим в качестве примера случай, когда XML используется в качестве формата данных для передачи заказов на покупку из одной базы данных в другую. В этом случае, действительно, не имеет значения, хранятся ли номера заказов в документе до или после даты заказа, как не имеет значения и то, хранится ли имя покупателя в разделе CDATA, в качестве внешней сущности или непосредственно в PCDATA. Важно только чтобы соответствующие данные передавались из одной базы данных в другую. Таким образом, ПО для передачи данных должно поддерживать иерархические данные (именно в таком порядке будет сгруппирована информация об одном заказе) и только немногое другое.
Одним из последствий игнорирования информации о документе и его физической структуре, становится то, что при восстановлении документа после хранения его в базе, результат отличается от оригинала, даже в, так сказать, каноническом понимании слова «отличие». Допустимо это или нет, зависит от конкретной задачи, на основании чего и делается выбор базы данных и промежуточного ПО.
Отображение структуры документа на структуру базы данных
Для передачи данных между XML-документом и базой данных необходимо обеспечить соответствие структуры документа и структуры базы данных и наоборот. Существуют два основных способа достижения этого - на базе шаблонов и на базе моделей.
Отображения на базе шаблонов
При отображении на базе шаблонов какого-либо заранее определенного способа отображения структуры документа на структуру базы данных не существует. Вместо этого, команды встраиваются в шаблон, который обрабатывается промежуточным ПО для передачи данных. В приведенном ниже шаблоне (который не используется никаким реальным продуктом) предложения SELECT встроены в элементы .
Есть места на следующие рейсы: SELECT Airline, FltNumber, Depart, Arrive FROM Flights Мы надеемся, что вы найдете то, что вам подходит
При обработке промежуточным ПО передачи данных, каждое предложение SELECT будет заменено результатами его выполнения в формате XML.
Есть места на следующие рейсы:
ACME
123
Dec 12, 1998 13:43
Dec 13, 1998 01:21
...
Мы надеемся, что вы
найдете то, что вам подходит
Отображения на базе шаблонов отличаются чрезвычайной гибкостью. Например, в некоторых продуктах наборы результирующих значений можно поместить на любое место в наборе результатов, в том числе использовать их в качестве параметров последовательных предложений SELECT, не ограничиваясь только форматированием самих результатов, как показано в приведенном примере. Другие продукты поддерживают такие элементы программирования как циклы и конструкции «если-то». Есть и такие, которые поддерживают параметризацию предложений SELECT, например, средствами параметров HTTP.
В настоящее время поддержка отображений на базе шаблонов предлагается только для передачи данных из реляционной базы данных в XML-документ.
Отображения на базе моделей
При отображении на базе моделей, модель данных некоторого рода накладывается на структуру документа XML, и результат отображается, либо косвенно, либо прямо, на структуры базы данных, и наоборот. Потеря в гибкости оборачивается большей простотой, поскольку системы, основанные на определенной модели, как правило, более эффективны с точки зрения пользователя. Так как результат передачи данных из базы данных в XML-документ соответствует единой модели, в продукты, поддерживающие отображение на базе моделей, часто интегрируется XSL, что позволяет добиться гибкости, свойственной моделям на базе шаблонов.
Существуют две общие модели для просмотра XML-документов. В первой, используемой многими пакетами промежуточного ПО для передачи данных между XML-документом и реляционной базой данных, XML-документ моделируется при помощи одной или набора таблиц. Иными словами, структура XML-документа должна выглядеть как в приведенном ниже примере, при этом не существует в случае, если используется одна таблица.
| ... ... ... ... |
Термин «таблица» можно понимать как один набор результатов (при передаче данных из базы данных в XML) или одну таблицу или вид с возможностью обновления (при передаче данных из XML в базу данных). Если нужно получить данные из более чем одного набора результатов (при передаче данных из базы) или XML-докумнеты содержат элементы, с большей глубиной вложенности, чем необходимо для представления набора таблиц (при передаче данных в базу данных), передача оказывается невозможной.
Вторая общая модель для данных в XML-документе - это дерево объектов, зависящих от данных, в котором элементы, как правило, соответствуют объектам, а атрибуты и PCDATA соответствуют свойствам. Эта модель отображается непосредственно на объектно-ориентированные или иерархические базы данных и может быть отображена на реляционные базы данных при помощи традиционных объектно-реляционных методов отображения или объектных видов SQL 3. Следует обратить внимание, что эта модель не имеет ничего общего с документной объектной моделью Document Object Model; последняя создает модель документа как такового, а не данных в этом документе.
Например, документ, содержащий заказ на покупку можно рассматривать как дерево объектов пяти классов - Orders, SalesOrder, Customer, Line и Part - как показано на следующей диаграмме.
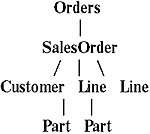 |
При моделировании XML-документа в виде дерева объектов, зависящих от данных, нет необходимости, чтобы элементы соответствовали объектам. Например, если элемент содержит только PCDATA, скажем, как элемент CustName в заказе, его вполне допустимо рассматривать как свойство, поскольку, как и свойство, он содержит единственную скалярную величину. Аналогично иногда оказывается полезным моделировать элементы со смешанным или элементарным содержанием, такие как свойства. Примером может служить элемент Description в документе- заказе, хотя это элемент со смешанным содержанием в формате XHTML, рациональнее рассматривать описание как единое свойство, поскольку его фрагменты сами по себе лишены смысла.
Есть и другие модели данных в XML-документе. Например, атрибуты ID и IDREF позволяют использовать XML-документ для представления направленного графа. Однако эти представления, похоже, не поддерживаются существующим промежуточным ПО достаточно широко.
Типы данных, нулевые значения, наборы символов и все прочее
В этом разделе рассматриваются вопросы, относящиеся к хранению данных их XML-документов в базах данных. В принципе, найти промежуточное ПО, ориентированное специально на разрешение этих вопросов, вряд ли возможно, однако, надо знать об их существовании, и учитывать это, выбирая инструментарий по другим критериям.
Типы данных
XML не поддерживает типов данных, что бы ни подразумевалось под этим термином. За исключением неинтерпретируемых сущностей все данные в XML-документах текстовые, даже если они представляют другие типы данных, такие как даты или целые числа. Вообще говоря, промежуточное ПО преобразует данные из текстового представления (в XML-документе) в другие типы (в базе данных) и наоборот. Однако число текстовых форматов, распознаваемых как тот или иной тип данных, скорее всего, будет ограничено, например, числом форматов, поддерживаемых данным JDBC-драйвером. Даты, вероятнее всего, создадут проблемы, поскольку число возможных форматов дат весьма велико. Числа, при обилии международных форматов, также могут создать трудности.
Двоичные данные
Есть два общих способа хранения двоичных данных в XML-документах: неинтерпретируемые сущности и кодирование Base64 (MIME-кодирование, которое отображает двоичные данные на подмножество US-ASCII). И тот, и другой способ создают проблемы для реляционных баз данных, поскольку правила, определяющие запись и извлечение двоичных данных из базы данных могут быть весьма жесткими и вызвать трудности для промежуточного ПО.
Кроме того, нет стандартной нотации, указывающей, что тот или иной элемент содержит данные, закодированные методом Base64, поэтому промежуточное ПО может вовсе не распознать, что имеет дело с закодированными данными. И, в заключение, нотация, связанная с неинтерпретируемыми сущностями или элементами, закодированными по Base64, может быть проигнорирована промежуточным ПО при хранении этих данных в базе. Поэтому, если двоичные данные представляют важность, необходимо убедиться, что промежуточное ПО поддерживает их.
Пустые величины
В терминологии баз данных пустые величины обозначают простое отсутствие данных. Они принципиально отличаются от значения 0 (для чисел) и нулевой длины (для символьных строк). Для примера можно привести данные, сгенерированные аппаратурой метеорологической станции. Если термометр не работает, в базу данных будет записываться пустая величина, а не 0, который значил бы в данном случае нечто совершенно иное.
XML также поддерживает концепцию пустых величин при помощи необязательных типов элементов и атрибутов. Если значение необязательного типа элемента и атрибута - пустая величина, он просто не включается в документ. В случае баз данных, пустые элементы или атрибуты, содержащие строки нулевой длины не являются пустыми величинами: они содержат строки нулевой длины.
При отображении структуры XML-документа на базу данных и наоборот следует уделять особое внимание этим необязательным элементам и атрибутам, они должны отображаться на столбцы, которые могут содержать пустые значения, и наоборот. Результатом невнимательности в данном случае будет, скорее всего, ошибка подстановки (при передаче данных в базу) и некорректный документ (при извлечении данных из базы).
Так как специалисты по XML понимают пустые величины в более широком смысле, чем имеющие дело с базами данных - так, например, в мире XML элементы, на имеющие содержания, и строки нулевой длины считаются «пустыми величинами» - надо проверить, как выбранное промежуточное ПО обрабатывает это. Некоторые продукты предлагают пользователю определить, что значит «пустая величина» в XML-документе.
Наборы символов
По определению, XML-документ может содержать любой символ в кодировке Unicode за исключением некоторых, используемых в качестве управляющих. К сожалению, многие базы данных предоставляют ограниченную поддержку Unicode или не предоставляют вовсе, поэтому требуется специальная конфигурация для обработки кодировок символьных данных, отличных от ASCII.
Команды обработки
Команды обработки не являются частью «данных» XML-документа и, скорее всего, большинство промежуточного ПО, не будет их обрабатывать. Проблема здесь в том, что - особенно при непосредственном отображении структуры XML-документа в структуру базы данных - что такие команды возникают в любом месте документа. Поэтому промежуточному ПО трудно «решить», где хранить и как извлекать их. Если это может привести к искажению восстановленного из базы данных документа, и если точность воспроизведения является актуальной, необходимо убедиться, что промежуточное ПО умеет работать с такими командами.
Хранение разметки
Как уже упоминалось выше, иногда оказывается полезным хранить элементы с элементарным или смешанным содержанием в базе данных без дальнейшей интерпретации. Самым распространенным способом обеспечить это является хранение в базе данных самой разметки. Однако это создает сложности при извлечении документов: невозможно определить, является ли элемент разметки, извлеченный из базы данных, действительно элементом разметки, или это некий символ, который может иметь отношение, например, к сущностям lt и gt.
Это иллюстрируется следующим описанием.
Пример путаницы:
Оно хранится в базе данных как:
Пример путаницы:
База данных не «знает», является ли и разметкой или текстом. Для этого есть несколько решений, например, помечать элементы разметки флажками или использовать сущности для символов, не являющихся разметкой, однако, надо убедиться, что эти способы приемлемы для других приложений, работающих с данными. Например, если необходимо найти знак «меньше» («<») и lt-сущность («<»), хранящиеся в базе данных, следует помнить об этом.
Генерация DTD из схемы базы данных и наоборот
Самый распространенный вопрос, возникающий при передаче данных между XML-документами и базой данных, - как выработать XML DTD на основании схемы базы данных и наоборот. В двух словах, это весьма очевидная процедура, однако, ее результаты оказываются значительно менее полезны, чем хотелось бы многим пользователям. (Стоит заметить, что, чаще всего, эта процедура над DTD/реляционной схемой выполняется однократно, во всяком случае, большинством приложений, и всеми вертикальными приложениями. Исключение составляют инструменты, которые хранят случайные XML-документы в реляционных базах или которые представляют реляционные данные в виде XML-документов, в последнем случае непонятно, насколько вообще полезны DTD.)
Ниже приведен пример (упрощенной) процедуры генерации реляционной схемы из DTD.
- Для каждого элемента с элементарным или смешанным содержанием создается таблица и столбец с первичным ключом.
- Для каждого типа элемента со смешанным содержанием создается отдельная таблица, в которой хранятся PCDATA, связанная с родительской таблицей через первичный ключ родительской таблицы.
- Для каждого атрибута с единственным значением и для каждого единичного производного типа элемента, содержащего только PCDATA, создается столбец в этой таблице. Если производный тип элемента или атрибут является необязательным, столбцу приписывается свойство хранения пустых величин.
- Для каждого многозначного атрибута и для каждого многократного производного элемента, содержащего только PCDATA, создается отдельная таблица, в которой хранятся величины, связанные с родительской таблицей через первичный ключ родительской таблицы.
- Для каждого производного типа элемента или смешанного содержания создается связь с таблицей родительских элементов, с таблицей производных элементов через первичный ключ родительской таблицы.
Ниже приведен пример (упрощенной) процедуры генерации DTD из реляционной схемы.
- Для каждой таблицы создается элемент.
- Для каждого столбца таблицы создается атрибут или производный элемент, содержащий только PCDATA.
- Для каждого отношения первичного ключа/внешнего ключа, в котором первичный ключ принадлежит столбцу таблицы, создается производный элемент.
К сожалению, эти процедуры имеют ряд недостатков. Например, на основании DTD нет возможности четко прогнозировать типы данных или длины столбцов. Любой прогноз, например, сделанный на основании прочтения документа образца, может быть легко разрушен простым помещением в документ данных другого «типа» или символом другой длины. (Долгосрочным решением этой проблемы является использование типов данных в документах схем XML.) Аналогично, при генерации DTD из реляционной схемы, нет возможности прогнозировать порядок производных элементов или предположить, следует ли вообще передавать столбец, такой как внутренний идентификатор строк базы данных. И в том, и в другом случае возможны коллизии именования.
Несмотря на эти недостатки, приведенные алгоритмы дают неплохой фундамент, от которого можно отталкиваться при генерации DTD из реляционных схем и наоборот.
Хранение и извлечение документов
Все больше документов порождается в формате XML или в других форматах, например, RTF, PDF или SGML, которые затем преобразуются в XML. (Более подробно о документах, сформированных из данных, вставляемых в шаблон, говорится в конце подраздела «Документы, ориентированные на данные».) Таким образом, тем, кто работает с XML-документами, а не с данными, хранящимися в XML-документах, возможно, потребуется хранить и извлекать документы, кроме того, им могут понадобиться все средства преобразования их в другие форматы и из них. В этом разделе обсуждается только первый случай, информация об инструментарии, поддерживающем разнообразные преобразования, можно обратиться на любой из Web-сайтов, содержащих сведения о ПО, перечисленном в подразделе «Дополнительные ссылки».
Если используются наборы очень простых документов, возможностей файловой системы или некоторой системы контроля версий (например, такой, которая используется для контроля версий программного обеспечения) могут оказаться вполне достаточно. Однако усложнение набора документов, ставит вопрос о приобретении системы управления информационным наполнением.
(Термин «система управления информационным наполнением» противопоставляется термину «система управления документами», чтобы подчеркнуть то обстоятельство, что первая, как правило, позволяет разбивать документы на отдельные фрагменты, такие как, например, процедуры, главы или боковые поля, а также метаданные, такие как автор, имена, даты переизданий и номера документов. В ряде случаев это удобнее, чем манипулировать документом целиком. Это не только упрощает такие задачи, как организация работы нескольких авторов над одним документом, но и позволяет собирать законченные документы из существующих компонентов.
В отличие от ситуации, которая возникает при хранении данных из XML-документов в базе данных, системы управления информационным наполнением, как правило, поддерживают неизменность документов, поскольку такие вопросы как физическая структура документов в ряде случаев может быть очень важна для работы с ними. Системы управления информационным наполнением обладают также целым рядом других возможностей, в том числе:
- контроль версий и доступа;
- поисковые механизмы;
- редакторы;
- издательские подсистемы, такие как вывод на бумажный носитель, на компакт-диск или в Web;
- совместное использование информационного наполнения и стилей;
- расширяемость за счет написания скриптов и иного программирования;
- интеграция данных из баз данных.
Напомню, что мой опыт распространяется в основном только на базы данных, а не системы управления информационным наполнением, поэтому я не буду входить в дальнейшие детали. К счастью, эти детали не имеют решающего значения, поскольку наиболее сложные технические аспекты таких систем решены прозрачно для пользователя.
Системы управления информационным наполнением и реляционные базы данных
В силу широкой распространенности реляционных баз данных, а также и потому, что фраза «хранение XML-документов в базе данных» для многих означает, по существу, использование системы управления информационным наполнением, принято считать, что реляционные базы данных очень хорошо подходят для хранения XML-документов (в противоположность данным в этих документах). Однако так ли это на самом деле, до сих пор до конца непонятно.
С одной стороны, многие их тех, кто пытался решить эту задачу, уверены, что такой метод никуда не годится, объясняя это тем, что реляционные базы данных изначально лишены многих возможностей, которые требуются для реализации управления информационным наполнением. В числе таких возможностей: поддержка упорядоченности, иерархии, нерегулярных структур, а также поля чрезмерно гибкой длины. Так, например, для хранения информации о заказе, в котором элементы PCDATA и производные элементы появляются в родительском элементе, ее придется хранить в отдельном столбце и производить упорядочение производных элементов вручную. Кроме того, при помощи языка запросов SQL трудно сформировать запрос «выдать все главы, в которых в третьем параграфе упоминается деталь 123, жирным шрифтом».
С другой стороны, большое число систем управления информационным наполнением, таких как - BladeRunner (компания Interleaf), SigmaLink (STEP), Parlance Content Manager (XyEnterprise) и Target 2000 (Progressive Information Technology), основаны на реляционных базах данных. Одна из причин этого предпочтения состоит в лучшей масштабируемости реляционных баз данных по сравнению с объектно-ориентированными.
Не вызывает сомнений, что реляционная база данных сама по себе не является системой управления информационным наполнением. Иными словами, тем, кто принял решение реализовывать такую систему на основе реляционной базы данных, придется либо приобрести именно систему управления информационным наполнением на основе реляционной базы данных, и смириться с некоторыми ограничениями функциональности, почти неизменно сопровождающие готовые продукты, либо писать свою собственную систему.
Наиболее чувствительным ограничением покупных систем, пожалуй, является то, что они не поддерживают хранение XML-документов в форме неинтерпретируемых сущностей в одном столбце. Недостатки этого очевидны, в том числе, невозможность создать новый документ из элементов существующих документов. Впрочем, работать с ними несложно и в некоторых случаях оправдывает себя, например, в случае, если описание написано в XHTML и нет необходимости дробить его на более мелкие фрагменты. Более того, функции обработки текстов реляционных баз данных постоянно совершенствуются, пополняясь полнотекстовой индексацией, способностью обрабатывать специализированные запросы, такие как запросы, допускающие приближенный результат, или запросы, использующие тезаурусы для поиска синонимов. Другими словами, можно пожертвовать возможностью хранить документы в виде неинтерпретируемых сущностей в одном столбце ради простоты управления документами.
К счастью, реляционные базы данных все более подстраиваются под XML, поэтому возможности покупных продуктов часто оказываются шире простого хранения документов в одном столбце. Хотя многие из этих новых XML- ориентированных возможностей касаются все-таки передачи документов, нежели управления ими, они вполне удовлетворяют потребностям целого ряда приложений, особенно тех, которые занимают как бы промежуточное положение, между средствами передачи данных и управления информационным наполнением.
Тем, кто принял решение написать собственную систему, стоит хорошо подумать, прежде чем приступить к делу. Если полнофункциональная система управления информационным наполнением действительно нужна, это занятие может оказаться пустой тратой времени - повторением уже проделанной другими, весьма тяжелой работы. С другой стороны, упрощенную систему стоит разработать самостоятельно. Одна из таких систем была описана Майком Бирбеком, и ссылка на это описание приведена в списке рассылки XML-L. В этой системе пять таблиц.
- Определения атрибутов: специфицирует атрибуты, в том числе их типы, допустимые значения и т.д.
- Связь элемент/атрибут: определяет, какие атрибуты применяются к каким элементам.
- Определение контекстной модели: задает, какой элемент может содержать другие элементы.
- Значения атрибутов: содержит значения атрибутов и указателей на соответствующие строки таблиц определения атрибутов и связь элемент/атрибут.
- Значения элементов: содержит значения элементов (PCDATA или указатели на другие значения элементов), порядок элементов в родительском элементе, указатель на строку, содержащую родительский элемент, и указатель на соответствующую строку в таблице связь элемент/атрибут.
Три первых таблицы эквивалентны простому определению DTD; две следующих содержат действительные данные. Обращаясь с последовательными запросами к этим двум таблицам можно восстановить любую часть XML-документа. Более подробно это описано в разделах «Record ends, Mixed content, and storing XML documents on relational database» и «storing XML documents on relational database» архива XML-L (см. listserv.heanet.ie/ xml-l.html) за декабрь 1998 года.
Информация о других стратегиях хранения иерархий, таких как XML, в реляционной базе данных, приведена в разделе «XML documents in relational databases» архива XML-L за ноябрь 1998 года.
Базы данных, поддерживающие XML
Список новых СУБД, поддерживающих XML, приведен в обзоре XML Database Products.
Дополнительные ссылки
Ниже приводятся ссылки на другие статьи и технические описания, связанные с XML и базами данных.
- Интерфейсы XML API для баз данных, в том числе исходный код для реализаций SAX и DOM (www.javaworld.com/javaworld/jw-01-2000/jw-01-dbxml.html).
- Моделирование реляционных данных в XML (www.extensibility.com/xml_resources/modeling.htm).
- XML-представление реляционной базы данных. Полное описание табличной модели XML-документа (www.w3.org/XML/RDB.html).
Комментарии и отзывы
Пожалуйста, направляйте мне свои комментарии и отзывы. Прошу вас обратить внимание, что я часто бываю в отъезде, и ответ может прийти через несколько недель.
Выражаю свою благодарность Джону Ковану, Дилану Уолшу, Нику Литону и другим за их полезные замечания.
Об авторе
Рональд Буре — независимый программист, автор и исследователь XML. Специализируется на базах данных и схемах. Автор ряда статей, посвященных XML. Поддерживает актуальный перечень XML-инструментария баз данных XML Database Products (www.rpbourret.com/xml/XMLDatabaseProds.htm). В настоящее время работает над второй версией XML-DBMS, распространяемой в исходных текстах программы для передачи данных между XML и реляционными базами данных, а также над книгой об XML и базах данных, которая выйдет в свет следующей весной или летом. Адрес его электронной почты: rpbourret@rpbourret.com.
Ronald Bourret, XML and Databases, http://www.rpbourret.com/xml/XMLAndDatabases.htm. Copyright 1999, 2000 by Ronald Bourret. Перевод печатается с разрешения автора статьи.
