

Фактически, каждый раздел представляет собой часть исходного компьютера, на которой работает своя собственная ОС. Будет в статье и анализ возможностей, предоставляемых разделами и, в первую очередь для управления рабочей нагрузкой и построения отказоустойчивых систем.
В 70-е и 80-е на компьютерном рынке господствовали мэйнфреймы, которые могли комплектоваться целым рядом ОС, каждая из которых имела свои плюсы, минусы и своих приверженцев. Поэтому часть приложений работала в среде одной ОС, а часть - в какой-либо другой. Соответственно получалось, что хотя теоретически приложения могли работать на одном и том же мэйнфрейме, практически это могло оказаться не так. Приобретать по мэйнфрейму для каждой ОС было бы слишком накладно. Поддержка концепции виртуальной машины [1] позволяет запустить на одном компьютере одновременно более одной ОС и при этом удается достигнуть непрерывности вычислительного процесса в случае обновления версии ОС. Система виртуальных машин создает у пользователя иллюзию, что он имеет в монопольном распоряжении собственный компьютер.
Каждая виртуальная машина также может работать с многопользовательской ОС и использовать часть ресурсов реального компьютера (часть времени процессора, часть памяти и т.д.). Некоторые из ресурсов могут быть монопольно отданы в распоряжение виртуальной машины (например, магнитный диск или лента), другие - разделяются между виртуальными машинами. При обновлении версии ОС она устанавливается на одной виртуальной машине, в то время как другие виртуальные машины под управлением промышленных версий ОС продолжают обслуживать пользователей. Однако, поскольку большинство ресурсов виртуальных машин были обычно общими, выход из строя соответствующего аппаратного компонента реального компьютера приводил к прекращению работы всех виртуальных машин. Хотелось бы исключить или свести к минимуму возможность краха виртуальных машин.
Другая проблема системы виртуальных машин - существенные накладные расходы на организацию их функционирования. Производительность ОС и приложений, работающих на виртуальной машине, ниже, чем на реальной.
Первым проектом, в котором возникла концепция системы виртуальных машин, был проект IBM 7044X-7044M [1], а в IBM System/370 появился уже полноценный продукт - VM/370. Эта система виртуальных машин претерпела впоследствии много изменений (версии VM/SP, VM/XA, VN/ESA) и стала самой распространенной в компьютерной индустрии. Сегодня, в связи с многократным увеличением доступных ресурсов ПК программное обеспечение виртуальных машин разработано даже для них.
Однако в классе больших многопроцессорных систем прогресс пошел несколько в ином направлении - к организации разделов (или доменов). Раздел - это часть аппаратуры большого компьютера, которая сама по себе является компьютером, работающим под управлением собственной ОС. При этом желательно, чтобы у разделов вообще не было бы общей аппаратуры. Концепции виртуальных машин и разделов могут использоваться совместно: система виртуальных машин может работать в любом разделе.
Первым шагом в этом направлении стала концепция доменов, реализованная в мэйнфреймах Amdahl в первой половине 80-х. Введение доменов диктовалось стремлением избежать накладных расходов, возникающих из-за необходимости поддержки работы виртуальных машин. За каждым доменом закреплялась своя ОС, она работала в своей памяти, а замедление работы происходило лишь из-за немонопольного использования процессорных ресурсов, которые выделялись в рамках простой схемы квантования.
Однако настоящий расцвет концепции разделов наступил в мэйнфреймах IBM, где они назывались LPAR (Logical PARtition), а ответственный за их поддержку компонент, системный менеджер процессорных ресурсов - PR/SM. В старших многопроцессорных моделях IBM ES/9000 с водяным охлаждением (серия 9021) стало возможным организовать до 20 разделов PR/SM. При этом компьютеры физически состояли из двух половин, каждая со своим источником электропитания, что позволяло выключать питание и проводить сервисные или ремонтные работы на одной половине без прерывания обслуживания пользователей.
Кстати, применение LPAR для мэйнфреймов IBM обеспечивает еще одну характерную только для них черту. За десятилетия своего развития мэйнфреймы претерпели огромные архитектурные изменения; поддерживать совместимость «снизу вверх» в течение столь длительного срока было весьма непросто. Когда в 90-е годы появились ES/9000, единственной возможностью обеспечить совместимость с IBM S/370 было создание LPAR, работающего в режиме S/370 [2]. Благодаря поддержке во внешних устройствах мэйнфреймов возможности подключения более чем к одному каналу хоста, такие внешние устройства могут разделяться несколькими разделами LPAR.
Наиболее мощные из современных многопроцессорных серверов архитектур SMP или ccNUMA, обошли мэйнфреймы как по числу процессоров, так и по емкости памяти. Учитывая, что используемая в них ОС Unix была более неустойчива по отношению к сбоям, чем MVS/ESA, актуальность поддержки концепции разделов для RISC-систем оказалась еще выше, чем для мэнфреймов. Однако по пути реализации этой концепции производители SMP-серверов шли достаточно долго.
Convex/HP
Еще в серверах SPP1000, появившихся в 1994 году, и содержащих до 128 процессоров, компания Convex реализовала архитектурную идею подкомплекса (subcomplex) [3], которую можно считать шагом на пути к полностью независимым друг от друга разделам. В SPP1000 идея подкомплексов возникла в процессе решения проблемы распределения ресурсов между различными группами задач; применение разделов является одним из типичных современных методов ее решения.
Каждому подкомплексу приписывается часть процессоров и часть памяти для монопольного использования. Процессоры из одного гиперузла SPP1000 [3] могут быть отнесены к разным подкомплексам, но один процессор не может быть приписан более чем к одному. На рис. 1 приведен пример подобного разделения 32-процессорной системы.
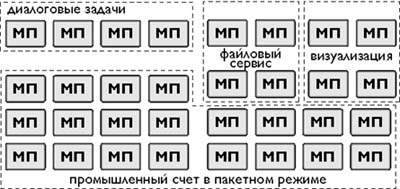 |
| Рис. 1. Подкомплексы серверов Convex SPP |
Кроме распределения процессоров и памяти порциями по 16 Мбайт, подкомплексу выделяется CTI-кэш, в котором буферизуются данные при обращении к памяти других гиперузлов. CTI-кэш подкомплекса также может приращиваться порциями по 16 Мбайт. Добавление/удаление CTI-кэш может происходить в любое время, однако задачи выполнения функций единой ОС процессоры выполняют без оглядки на границы подкомплексов.
Применение подкомплексов поддерживалось и в последующих поколениях SPP-серверов (SPP1200 [4], SPP1600, SPP2000 [5]), а после вхождения Convex в состав корпорации Hewlett-Packard эта линия продолжилась в серверах Класса V (а затем и в представленных совсем недавно серверах HP Superdome).
Следующим шагом были домены (разделы), которые уже имели свои собственные средства ввода-вывода и могли работать со своей ОС. Примером таких доменов являются, в частности, архитектурные решения, предложенные Sun Microsystems, Unisys и Compaq.
Домены Sun Ultra Enterprise 10000
В момент своего появления серверы Ultra Enterprise (UE) 10000 были, вероятно, самыми мощными RISC-системами SMP-архитектуры с точки зрения числа процессоров и пропускной способности системной шины (Gigaplane XB). Домены в этих серверах стали первой полноценной реализацией архитектурной идеи разделов в мире открытых систем, допускающей работу разных ОС в разных разделах.
Динамическая система доменов позволяет разбить сервер UE 10000 на «подкомпьютеры», каждый из которых включает в себя не менее одной системной платы [6]. Напомним, что системная плата в UE 10000 - это не плата типа backplane или midplane, содержащая шину Gigaplane XB, а некоторая «сборка» из четырех микропроцессорных модулей, модуля памяти и модуля ввода-вывода. В типичной для систем с архитектурой MPP/ccNUMA терминологии системную плату можно было бы назвать узлом.
Каждый домен имеет собственные внешние устройства (диски, сетевые платы и т.д.). Однако домены физически не полностью отделены друг от друга: все они разделяют общую шину Gigaplane XB, сбой которой может привести к краху всей системы. Налицо классический пример «общей точки сбоя», которой при построении систем высокой готовности надо избегать.
В различных доменах UE 10000 могут работать различные версии Solaris, что позволяет, в частности, установить новую версию ОС перед передачей ее в промышленную эксплуатацию, проверить работу новых драйверов и т.п. Администрирование доменов UE 10000 осуществляется централизованно с использованием средств сервисного процессора SSP. Sun предлагает, в частности, интересную возможность использовать один из доменов как межсетевой экран, связанный с другими доменами сверхбыстрой шиной Gigaplane XB.
Домены в компьютерах Unisys
Компания Unisys имеет огромный опыт разработки и производства не только SMP-серверов, но и мэйнфреймов [7]. Поэтому неудивительно, что сначала домены были реализованы именно в мэйнфреймах. Это, несомненно, способствовало успешной реализации доменного подхода в рамках «фирменной» архитектуры CMP (Cellular MultiProcessing), которую можно охарактеризовать как «перестраиваемую» SMP-архитектуру, позволяющую комбинировать кластеризацию и SMP при построении многопроцессорных архитектур [8].
Интересно отметить, что CMP конструировалась в расчете на Merced, но пока в них применяются Xeon. Это означает, что с появлением IA-64 можно ожидать выхода на рынок сразу нескольких систем на этой базе, поддерживающих разбиение на разделы. В качестве другого примера можно указать, в частности, NUMAflex-системы Origin/Onyx 3x00 от SGI.
CMP-серверы от Unisys содержат до 32 процессоров. Статически и динамически создаваемые домены имеют SMP-архитектуру и должны содержать число процессоров, кратное 4. Таким образом, 32-процессорный сервер может быть разбит на 8 4-процессорных доменов, или на 4 8-процессорных домена, или на какую-либо смешанную комбинацию. Такие домены образуют кластер, причем его узлы-домены общаются между собой через память.
В каждом домене своя ОС. Имеется три типа разделения общего поля памяти всего сервера между доменами. Во-первых, каждая ОС может иметь свою память. Во-вторых, каждая ОС может иметь свою память, и плюс к этому образуется память, общая для всех ОС. В-третьих, каждая ОС может иметь свою память, и плюс к этому может быть несколько подобластей памяти, общих для некоторых ОС.
Что касается диапазона допустимых ОС, то он определяется богатым выбором: NT, SCO UnixWare или любой другой клон Unix.
Разделы Compaq AlphaServer GS
Серверы AlphaServer GS160/320, обладающие архитектурой ccNUMA, содержат до 32 микропроцессоров Alpha 21264. В этих системах поддерживается два типа разделов [9].
Прежде всего - это программные разделы (soft system partition), динамически поддерживаемые механизмом Galaxy, входящим в состав ОС OpenVMS. Все такие разделы работают под управлением одной ОС. Главной задачей этого типа разделов является управление рабочей нагрузкой. Программные разделы позволяют распределять (с низкой задержкой) специфические ресурсы между специфическими приложениями. Нетрудно видеть, что это «слабый» вариант формирования разделов, некоторым аналогом которого можно считать подкомплексы системы Convex SPP.
«Сильный» вариант разделов в серверах GS - аппаратные разделы (hard partition), в каждом из которых уже может работать своя ОС. Динамическое конфигурирование аппаратных разделов в компьютерах GS позволяет проводить модернизацию ОС одновременно с промышленной эксплуатацией в другом разделе. Естественно, что этот подход также можно использовать для управления рабочей нагрузкой. Аппаратные разделы серверов GS можно рассматривать как идеальную платформу для задачи консолидации серверов.
Разделы в SGI NUMAflex
Наиболее продвинутая реализация архитектурной идеи разделов предлагается сегодня в компьютеры ccNUMA-архитектуры SGI Origin/ Onyx 3x00 [10]. Эти системы являются первыми компьютерами с архитектурой NUMAflex, разработанной в SGI. Данная архитектура чрезвычайно гибка с точки зрения построения различных конфигураций, а поддержка разделов лишь одно из проявлений этой гибкости.
Как и некоторые другие производители SMP/ccNUMA-серверов, свой путь к полноценным разделам SGI начала, исходя из требований задачи обеспечения эффективного управления рабочей нагрузкой. В середине 90-х в SMP-серверах Challenge/Power в ОС IRIX 6.0-6.2 поддерживалась команда «pset» (processor set), определяющая процессорные наборы, включавшие в себя часть процессоров системы. Запускаемая на выполнение задача могла быть приписана к одному из таких наборов, что обеспечивало ее выполнение именно на соответствующих процессорах. Для иллюстрации того, что это в ряде случаев способствует повышению производительности, можно указать на ситуацию с заполнением кэша. В том случае, если выполнение процесса на каком-либо процессоре завершается и продолжается на другом, возникнут дополнительные расходы в связи с необходимостью заполнения кэш-памяти нового процессора данными и командами, на что требуется значительное время.
В ОС IRIX 6.4, которая поддерживает архитектуру ccNUMA, эта команда была заменена новым аналогичным средством. Эти возможности усовершенствованы в IRIX 6.5. В частности, появилась возможность указать на память узлов, где желательно выполнять задачу. Это позволяет уменьшать задержки из-за обращения в удаленную память чужих узлов. Это средство аналогично подкомплексам в архитектуре SPP.
Полноценные разделы у SGI появились лишь в этом году, когда компания выпустила компьютеры с архитектурой NUMAflex. Однако реализованные в NUMAflex возможности являются на сегодня наиболее совершенными.
Система Origin 3x00 может содержать до 512 процессоров, при этом ее можно разделить на не более чем 32 раздела. Образующийся набор представляет собой сильно связанный кластер (рис. 2). Минимальный раздел должен содержать один С-кирпич, включающий два или четыре процессора [10]. Каждый раздел имеет также собственные средства ввода/вывода, свой IP-адрес и работает под управлением собственной версии Irix. Поскольку системы Origin 3x00 также готовы и к использованию Itanium, и в этом случае будет применяться ОС Linux, можно надеяться на то, что аналогичные Irix средства будут доступны и в рамках Linux.
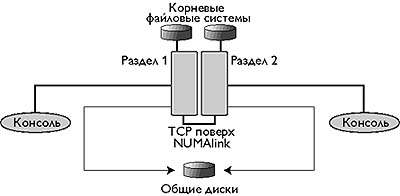 |
| Рис. 2. |
Для обеспечения коммуникаций между разделами-узлами кластера используется NUMAlink - стандартное межсоединение Origin 3x00. Это дает гораздо более высокую пропускную способность и более низкие задержки, чем традиционные каналы связи между узлами кластеров. Пиковая пропускная способность каналов NUMAlink в Origin 3x00 составляет 3.2 Гбайт/с. Большая производительность при обмене данными между узлами обеспечивается также благодаря тому, что пересылки осуществляются непосредственно из памяти одного узла в память другого. Подобное копирование было доступно и в кластерах DEC с технологией Memory Channel, однако там для передачи данных используются более медленный протокол на основе PCI.
Коммуникации между разделами возможны с использованием трех различных механизмов: c использованием обычного драйвера и сокетов - на основе TCP/IP и UDP; с использованием драйвера, допускающего несколько логических каналов между разделами; с использованием интерфейсов общего поля памяти. Кроме того, SGI обещает поставлять средства MPI, работающие поверх соединений NUMAlink, что обеспечит высокую эффективность распараллеливания.
Очевидно, что данная технология эффективна для управления рабочей нагрузкой. Каждый раздел может работать со своим ядром ОС, что обеспечивает необходимую гибкость при смене версий ОС без прерывания промышленной эксплуатации. Чтобы было понятнее, насколько высокий уровень динамичности создания разделов стал доступен, отметим, что раздел создается обычной командой IRIX «mkpart».
Конфигурирование разделов происходит в оперативном режиме либо через интерфейс командной строки, либо через более удобный графический интерфейс, который будет доступен в скором будущем.
Рассмотрим теперь вкратце механизм идентификации аппаратных ресурсов. Этот механизм используется для обеспечения высокой отказоустойчивости серверов Origin 3x00. Каждый С-кирпич в системе имеет уникальный номер модуля, который сохраняется в системном контроллере первого уровня, отвечающем за данный кирпич. Копия этого номера сохраняется также в NVRAM. Аналогично идентификационный номер каждого раздела также размещается в системных контроллерах первого уровня. Все С-кирпичи, принадлежащие одному разделу, содержат одинаковый идентификационный номер этого раздела. При первоначальной загрузке в разделах осуществляется динамическая идентификация новой аппаратуры, и создаются таблицы, содержащие идентификационные номера модулей и разделов.
Все кирпичи Origin 3x00, независимо от их типа, помещаются в стойки, и каждая стойка, содержащая C-кирпичи, имеет системный контроллер второго уровня, который взаимодействует с контроллерами первого уровня через отдельную внутреннюю сеть. Это позволяет управлять каждым разделом системы из общей точки. Каждый С-кирпич имеет независимое электропитание, благодаря чему в будущем SGI собирается обеспечить конфигурирование разделов даже когда питание не подведено к системе, и ОС раздел не работает.
Описанный механизм идентификации аппаратных ресурсов помогает изолировать разделы в случае сбоя, предотвращая распространение ошибочной информации. При сбое в разделе идентификационная информация используется для генерации заградительного сброса (reset fence) на всех каналах, где маршрутизатор (это - неотъемлемая часть архитектуры NUMAflex) отвечает иному идентификатору раздела.
Таким образом, если в обычной SMP-системе сбой приведет к прекращению выполнения всех задач и падению всей системы, то сбой раздела на серверах NUMAflex вызывает лишь заградительный сброс на интерфейсе маршрутизатор-маршрутизатор. На остальные разделы сбой не повлияет. Поскольку в архитектуре NUMAflex нет общей системной шины, образование разделов приводит к исчезновению характерной для SMP-систем общей точки сбоя.
Если разделом является вся стойка, можно отключить питание во всей ее инфраструктуре - это не повлияет на другие стойки и разделы. Таким образом, обеспечивается максимально возможная изоляция. На выключенной стойке можно проводить ремонтные работы и сервисное обслуживание (многие компоненты SGI 3x00 и без того уже имеют возможность горячей замены).
Очевидно, что такая конструкция способствует отказоустойчивости всей системы. При сбое раздела на нем выполняется операция shutdown, и возможное распространение ошибочных данных на другие разделы будет предотвращено.
Обеспечивается также «отказоустойчивость» отдельных заданий за счет создания контрольной точки и последующего рестарта. Наконец, задания, выполняющиеся сразу в нескольких разделах, могут использовать контрольную точку в сбойном разделе для последующего рестарта в этом или даже другом разделе [11].
При разбиении NUMAflex-сервера на разделы с переходом к кластерной структуре можно построить классическую кластерную систему высокой доступности (HA). От обычного HA-кластера он будет отличаться высокой производительностью каналов, соединяющих узлы - в качестве них будет использоваться соединения NUMAlink.
Заключение
Итак, перечислим основные преимущества разделов/доменов:
- эффективное управление рабочей нагрузкой (разделение ресурсов между коллективами пользователей, группами задач и т.п.);
- обеспечение работы разных ОС на одной вычислительной установке, и, в частности, модернизация ОС при одновременном продолжении промышленной эксплуатации текущей версии ОС;
- повышение отказоустойчивости путем устранения общих точек сбоя и образования НА-кластеров.
Думаю, что в будущем это архитектурное решение будет «стандартом» при построении отказоустойчивых многопроцесорных систем общего назначения.
Литература
[1] Г. Лорин, Х. Дейтел, Операционные системы, М.: Финансы и статистика, 1984
[2] J. Hoskins, «IBM ES/9000. A business perspective», 2nd Ed., John Wiley & Sons, Inc., N.Y., 1993
[3] SPP1000 Systems Overview, Convex Compuetr Corp., 1994
[4] В. Шнитман,«Открытые системы», 1995, № 6, с. 42
[5] В. Коваленко,«Открытые системы», 1997, № 1, с. 5
[6] М. Кузьминский,«Открытые системы», 1997, № 5, с. 13
[7] М. Кузьминский,«Открытые системы», 1996, № 5, с. 5
[8] М. Кузьминский,«Computerworld Россия», 1998, № 33
[9] М. Кузьминский,«Computerworld Россия», 2000, № 27-28
[10] М. Кузьминский,«Открытые системы», 2000, № 9, c. 10
