

Да, но только если проблема действительно имеет важное значение, программа действительно работает слишком медленно, и есть определенная надежда на то, что ее можно заставить работать быстрее, в то же время обеспечив корректность, надежность и прозрачность. Быстрая программа, которая работает неправильно, ваше время отнюдь не экономит.
Таким образом, первый принцип оптимизации - не оптимизировать программу без нужды. Достаточно ли хороша программа в том виде, в котором она уже существует? Помогает ли знание того, как программа будет использоваться и в какой среде она будет работать, в том, чтобы увеличить ее производительность? Программы, написанные для того чтобы получить хорошую отметку в колледже, никогда потом не используются, и их скорость редко имеет значение. Вопрос скорости не имеет никакого значения для большинства персональных программ и редко используемых инструментальных средств, тестовых оболочек, экспериментов и прототипов. Однако время работы коммерческого продукта или центрального компонента, такого, как графическая библиотека, может оказаться крайне важным, поэтому нам нужно понять, как стоит относиться к вопросам производительности.
В каких случаях нам следует попытаться увеличить скорость работы программы? Каким образом это можно сделать? На что можно рассчитывать? В этой главе рассказывается о том, как заставить программу работать быстрее и использовать меньше памяти. Скорость обычно вызывает самый большой интерес, именно поэтому мы будем говорить главным образом о быстродействии. Пространство (оперативная память, диск) - значительно реже вызывает беспокойство, но в некоторых случаях может иметь критически важное значение, поэтому данному вопросу мы тоже уделим некоторое время и место на этих страницах.
Наилучшая стратегия состоит в том, чтобы использовать самые простые и ясные алгоритмы и структуры данных, подходящие для данной конкретной задачи. Затем измерьте производительность, чтобы понять, нужны ли какие-либо изменения; настройте опции компилятора так, чтобы сгенерировать максимально быстрый код; оцените, какие изменения в самой программе будут иметь наибольший эффект; каждый раз вносите только по одному изменению и заново оценивайте производительность продукта; сохраняйте простые версии для тестирования внесенных изменений.
Измерение - это критически важный компонент улучшения производительности, поскольку рассуждения и интуиция - ошибочные принципы и должны быть дополнены таким инструментарием, как временные команды и модули, составляющие профили. Увеличение производительности имеет много общего с тестированием, в частности в том, что здесь также важно автоматизировать процессы, вести тщательные записи и использовать регрессивные тесты, чтобы убедиться в том, что изменения сохраняют корректность программы и не сводят на нет предыдущие достижения.
Если вы весьма разумно выбрали алгоритмы и изначально хорошо написали программу, может оказаться, что в дальнейшем в ее совершенствовании нет необходимости. Зачастую незначительные изменения способны решить любые проблемы с производительностью в хорошо спроектированном коде, в то время как плохо спроектированная программа требует существенной переработки.
Узкое место
Давайте начнем с описания того, как устранить узкое место в критически важной программе в своей локальной среде.
Наша входящая почта проникает на машину через узкое входное отверстие, называемое шлюзом, который соединяет внутреннюю сеть с Internet. Сообщения электронной почты из внешнего мира - десятки тысяч в день для сообщества в несколько тысяч человек - появляются на шлюзе и передаются во внутреннюю сеть; эта система сортировки изолирует нашу частную сеть от общедоступной Internet и позволяет нам сообщить всем членам сообщества имя только одной машины (то есть шлюза).
Одна из обязанностей шлюза - это отсеивание «спама», то есть невостребованной электронной почты, которую распространяют службы, имеющие не всегда чистые намерения. После первых успешных тестов фильтра «спама» служба была сделана постоянной и доступной для всех пользователей почтового шлюза; проблема сразу стала очевидной. Шлюзовая машина, довольно старая и уже работающая на пределе, перестала справляться с нагрузкой, поскольку фильтрующая программа требовала слишком много времени (намного больше, чем требовалось для всей остальной обработки каждого сообщения), из-за чего возникали длинные очереди сообщений и доставка сообщений задерживалась на много часов.
Это пример реальной проблемы с производительностью: программа выполняет свою работу недостаточно быстро и у пользователей такие задержки вызывают ряд неудобств. Программа просто должна была работать намного быстрее.
Несколько упрощая, можно сказать, что фильтр «спама» работает следующим образом. Каждое входящее сообщение рассматривается как отдельная строка и модуль проверки текстовых шаблонов анализирует эту строку с тем, чтобы выяснить, содержит ли она какие-либо фразы, которые однозначно относятся к «спаму», к примеру, высказывание типа «заработайте миллион долларов в свободное время». Поскольку подобные сообщения обычно возвращаются, предлагаемая методика фильтрации «спама» весьма эффективна и если какое-либо сообщение не удалось отловить сразу, фраза добавляется в список, чтобы ее можно было отследить в следующий раз.
Ни одно из существующих утилит, выполняющих сравнение цепочек символов, такие как grep, не имеют нужно сочетания производительности и набора возможностей, поэтому для «спама» был создан специальный фильтр. Исходная программа была очень проста. Она проверяла, содержит ли сообщение какую-либо из известных фраз (шаблонов).
/*isspam: проверяет, содержит ли
цепочка mesg какой-либо
из шаблонов pat */
int isspam(char *mesg)
{
int i;
for (i=0; i < npat; i++)
if (strstr(mesg, pat[i]) != NULL) {
printf («спам: найдено соответствие
для ?%s?
, pat[i]);
return 1;
}
return 0;
}Как можно сделать эту программу быстрее? Цепочка символов должна быть найдена и функция strstr из Си-библиотеки - лучший способ эту цепочку найти, поскольку функция эта стандартная и эффективная.
После профилирования (методики, которая позволяет определить, сколько времени тратится на работу каждой части программы) стало ясно, что реализация strstr, использовавшаяся в фильтре «спама», имела плохие характеристики. Изменив механизм работы strstr, ее можно было сделать намного эффективнее для решения конкретно данной задачи.
Существующая реализация strstr выглядит примерно следующим образом.
/* простая функция strstr:
использовать strchr для поиска
первого символа */
char *strstr (const char *s1,
char *s2)
{
int n;
n = strlen(s2);
for ( ; ;) {
s1 = strchr(s1, s2[0]);
if (s1 == NULL)
return NULL;
if (strncmp (s1, s2, n) == 0)
return (char *) s1;
s1++;
}
}Она была написана в стремлении сделать ее максимально эффективной и фактически при обычном использовании она работала быстро, поскольку для выполнения своей работы применяет хорошо оптимизированные библиотечные функции. Она вызывает strchr для поиска следующего появления первого символа шаблона, а затем вызывает strncmp для того чтобы проверить, соответствует ли оставшаяся часть цепочки оставшейся части шаблона. Таким образом, большая часть исходного сообщения просто пропускается, поскольку функция ищет только первый символ шаблона и затем быстро сканирует остальное. Так почему же эта программа работает так медленно?
На это есть несколько причин. Во-первых, strncmp в качестве аргумента получает длину шаблона, которая вычисляется с помощью функции strlen. Но шаблоны - это фиксированные строки, поэтому нет никакой необходимости каждый раз при анализе нового сообщения заново считать их длину.
Во-вторых, strncmp имеет сложный внутренний цикл. В нем не только сравниваются байты двух строк, но и отслеживается символ окончания � для обеих цепочек и при этом уменьшается переменная, начальное значение которой было равно длине цепочки. Поскольку длина всех строк априори известна (хотя strncmp об этом и не знает), поэтому всех этих сложностей можно избежать. Нам также известно, что счетчики правильные и нет нужды тратить время на проверку символа конца строки.
В-третьих, strchr - тоже очень сложная функция, поскольку она должна проанализировать каждый символ и отслеживать символ �, который свидетельствует об окончании цепочки символов. Для данного вызова isspam сообщение является постоянным, поэтому время, которое тратится на поиск � - тратится бесполезно, поскольку нам известно, где заканчивается сообщение.
Наконец, хотя strncmp, strchr и strlen по отдельности работают эффективно, накладные расходы на вызов этих функций сравнимы с расходами на вычисления, которые они будут выполнять. Было бы эффективнее выполнять всю работу в специальной, тщательно написанной версии strchr и избежать вызова других функций.
Именно такого рода проблемы чаще всего являются причиной низкой производительности - подпрограмма или интерфейс в общем случае работают хорошо, но в нетрадиционной ситуации, которая, как правило, и возникает в данной конкретной программе, выполняется далеко не лучшим образом. Существующая функция strstr работала прекрасно, когда и цепочка символов, и шаблон были короткими и менялись при каждом вызове, но когда цепочка длинная и фиксированная, накладные расходы серьезно мешают.
Учитывая вышесказанное, strstr была переписана так, чтобы она просматривала шаблон и цепочки символов в сообщении вместе в поисках соответствий, не вызывая никаких подпрограмм. Полученная реализация имела предсказуемое поведение, то есть в некоторых случаях работала несколько медленнее, но намного быстрее при фильтрации «спама» и, что важнее, никогда не работает уж очень плохо. Чтобы проверить корректность и производительность новой реализации был создан пакет тестов на производительность. Этот пакет включает в себя не только простые примеры, такие как поиск слова в предложении, но и экстремальные случаи, например, поиск шаблона, состоящего из одной буквы x в цепочке, содержащей тысячу букв e и шаблона, содержащего тысячу букв x в цепочке из одной буквы e. Оба этих случая функция strstr в своей первоначальной реализации обрабатывала крайне медленно. Такие крайние случаи - основная составляющая процедуры оценки производительности.
В библиотеку была добавлена новая реализация функции strstr и фильтр «спама» стал работать на 30% быстрее, что весьма неплохой результат, учитывая, что изменена была всего одна функция.
К сожалению, производительность по-прежнему была неудовлетворительной.
При решении проблемы важно правильно поставить вопрос. До сих пор мы стремились найти самый быстрый способ поиска текстового шаблона в строке. Но на самом деле задача состоит в том, чтобы найти большое фиксированное множество текстовых шаблонов в длинной цепочке символов. Учитывая это, нужно признать, что strstr вовсе не обязательно является правильным решением.
Наиболее эффективный способ увеличить скорость работы программы - использовать лучший алгоритм. Получив более четкое представление о том, в чем же состоит задача, пришло время подумать о том, какой алгоритм будет работать лучше всего.
Базовый цикл:
for (i = 0; i < npat; i++)
if (strstr(mesg, pat[i]) != NULL)
return 1;сканирует сообщение npat раз; предполагая, что не найдены никакие соответствия, он проверяет каждый байт сообщения npat раз, выполняя всего strlen(mesg)*npat сравнений.
Лучший подход - инвертировать цикл, сканируя сообщение один раз во внешнем цикле, одновременно выполняя поиск всех шаблонов параллельно во внутреннем цикле:
for (j = 0; mesg[j] != ?�?; j++) if (некоторый шаблон начинается в mesg[j]) return 1;
Увеличить производительность позволило простое наблюдение. Чтобы увидеть, что какой-нибудь шаблон начинается в сообщении в позиции j, нам не нужно проверять все шаблоны, а нужно только те, которые начинаются с того же символа, что и mesg[j]. Грубо говоря, имея всего 52 буквы (прописные и строчные), мы можем предположить, что придется выполнить всего strlen(mesg)*npat/52 сравнений. Поскольку буквы распределяются неравномерно (слов, начинающихся с буквы s намного больше, чем с буквы x) производительность вырастет не в 52 раза, но определенно вырастет. Фактически, мы создаем хеш-таблицу, используя в качестве ключа первые буквы шаблонов.
Учитывая, что приходится выполнять некоторые предварительные вычисления для создания таблицы, в которой шаблоны начинаются с каждого символа, isspam осталась короткой (см. рис. 1). Двумерный массив starting[c][] хранит для каждого символа c индексы тех шаблонов, которые начинаются с данного символа. Компаньон этого массива - nstarting[c] указывает, сколько шаблонов начинается с буквы c. Без этих таблиц внутренний цикл будет работать от 0 до npat раз, то есть около тысячи; с таблицами он обычно выполняется не более 20 раз. Наконец, элемент массива patlen[k] содержит предварительно вычисленный результат strlen(pat[k]).
 |
| Рис. 1. Окончательная версия isspam, использующая в качестве ключа первую букву шаблона |
На следующем рисунке показаны схематические изображения структур данных для набора из трех шаблонов, которые начинаются с буквы b (см. рис. 2).
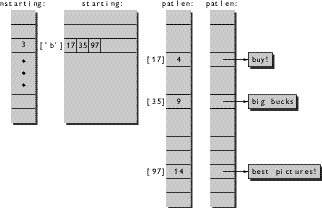 |
| Рис. 2. Схемы структур данных |
Код, создающий эти таблицы, очень прост:
int i;
unsigned char c;
for (i = 0; i < npat; i++) {
c = pat[i][0];
if (nstarting[c] >= NSTART)
eprintf(«слишком много
шаблонов (>=%d)» «начинается
с ?%c?, NSTART, c);
starting[c][nstarting[c]++] = i;
patlen[i] = strlen(pat[i]);
}Функция eprintf печатает сообщение об ошибке и завершает программу.
В зависимости от входного параметра фильтр «спама» теперь работает в пять - десять раз быстрее, чем с усовершенствованной функцией strstr и от семи до 15 раз быстрее, чем первоначальная реализация. Добиться увеличения в 52 раза не удалось, частично из-за неравномерного распределения букв, частично потому, что в новой программе цикл более сложный, а частично и потому, что по-прежнему выполняется много сравнений, не приводящих к результату, но фильтр «спама» больше не является узким местом при доставке почтовых сообщений. Проблема с производительностью решена.
Теперь имеет смысл еще раз вернуться к ситуации с фильтром «спама», чтобы понять, какие в этом случае можно извлечь уроки. Самое важное, убедитесь, что вопрос о производительности действительно стоит остро. Все эти усилия не имели бы никакого смысла, если бы фильтрация «спама» не была узким местом. Как только мы осознали, в чем заключается проблема, мы использовали профилирование и другие методики для того, чтобы изучить поведение системы и понять, в чем же действительно заключается задача. Затем мы убедились, что решаем правильную задачу, проверив всю программу, а не сосредоточиваясь только на функции strstr, что было бы очевидным, но неверным предположением. Наконец, мы решили правильную задачу, использовав лучший алгоритм и проверили, что он действительно работает быстрее. Как только программа стала работать достаточно быстро, мы прекратили дальнейшую оптимизацию. Зачем выполнять лишнюю работу?
Finding Performance Improvements, Brian Kernighan and Rob Pike, IEEE Software, March/April 1999, pp. 61-65, Reprinted with permission, Copyright IEEE CS, All rights reserved.
Excerpted from the book THE PRACTICE OF PROGRAMMING by B. Kernighan and R. Pike. Copyright 1999, Addison Wesley Longman Inc., Reprinted with permission of Addison Wesley Longman.
«Он в обещаньях был могуч, как раньше,
А в исполненьях, как теперь, ничтожен».
Шекспир, «Генрих VIII»
Пер. Б. Томашевского
Когда я писал свою книгу «Исполнение кода», свое исследование я начал с небольшой книги «Элементы стиля программирования» Брайана Кернигана и П. Дж. Плоджера (McGraw-Hill, 1978). Я читал подряд все книги и статьи, в которых упоминались «Элементы стиля программирования» (ровно по списку Science Citation Index). К тому времени, как я все это прочитал, я закончил большую часть исследований, необходимых для того, чтобы написать «Исполнение кода»
Что касается исследований, которые я позаимствовал из «Элементов стиля программирования», я был счастлив узнать, что Брайан Керниган и Роб Пайк работали над схожей книгой «Практика программирования» - книгой, призванной рассказать о принципах и методах, которым не учат в школе. Брайан Керниган работает в Центре компьютерных исследований в лаборатории Bell Laboratories, принадлежащей корпорации Lucent Technologies. Роб Пайк, также сотрудник Центра компьютерных исследований, возглавлял работы по проектированию и реализации операционных систем Plan 9 и Inferno. Мы публикуем выдержку из седьмой главы, которая называется «Производительность».
Стив Макконнелл, главный редактор журнала IEEE Software
