

Специалистам нашего института было поручено создать поисковый сервер, включающий образы как азербайджанских, так и зарубежных информационных ресурсов. В статье приводится описание разработанной поисковой системы, которая содержит механизмы индексирования, поиска и диалога с пользователями на естественном языке.
По своей структуре Internet - это достаточно гибкая информационная сеть, предоставляющая широкие возможности для размещения любых данных, однако их неоднородность, несистематизированность, а также отсутствие надлежащего структурированного оформления хранимой информации выявляет существенные недостатки Сети:
- информация в Internet размещена беспорядочно, отсутствует закономерность ее сбора и хранения, и, как следствие, нужные сведения разбросаны по разным узлам по всему миру;
- имеет место хаотичность, неполнота либо избыточность и взаимная противоречивость данных. Сбор информации производится случайным образом неорганизованно, систематический единый подход к организации информационного обеспечения серверов отсутствует.
И поскольку сайты создаются независимо друг от друга, их содержимое не может быть согласованным. В этой ситуации, с одной стороны, технология создания информационных служб Internet (информационных систем и услуг, предоставляемых Сетью) удобна для размещения любых данных, но, с другой стороны, с увеличением объема информационных ресурсов выуживать из Всемирной Паутины нужные данные становится все сложнее.
Для поиска необходимой информации пользователи вынуждены каждый раз «пронизывать» всю Сеть, затрачивая массу времени и определенные информационные, сетевые и материальные ресурсы. Однако эту проблему можно решить, причем без изменения структуры сети - достаточно лишь создать некоторую обслуживающую систему (посредника между пользователями и информационными ресурсами), которая хранит образ содержания сетевых информационных ресурсов, банков данных и архивов файлов. Причем образы являются структурированными базами данных в виде индексов или тематических каталогов, разбитых на удобные для поиска элементы, которые содержат не сами данные из документов, Web-страниц, архивов и т.д., а лишь метаинформацию о том, где они хранятся. Речь идет о поисковой системе, которая предоставляет пользователю совокупность ключей и ссылок на нужную информацию и создает иллюзию структурированности Сети.
Сегодня существует много поисковых систем, определяющих местоположение информации, хранимой на серверах Internet [1,2]: Yahoo, Excite, AltaVista, Lycos, Stars, Infoseek, Aport и т.д. Некоторые из них представляют собой тематические каталоги, содержащие разнообразные документы, Web-страницы, файлы и т.д. Другие позволяют искать документы разного содержания по сайтам всего мира. Они отличаются по видам предоставляемых услуг, охватываемых тем и сайтов, а также по алгоритмам индексирования и каталогизации [3]. В первом случае поисковые системы представляют собой тематические каталоги, которые подобно библиотечным имеют в своем распоряжении образы, составленные по направлениям и содержащие вложенные подкаталоги по узким темам. В таких системах поиск ведется или по тематике, определяемой названием каталога, или по ключевым словам - терминам из тезаурусов. Для создания тематических каталогов необходимо знание предмета - здесь требуется помощь специалистов и экспертов. Каталоги обычно составляются администратором поисковой системы вручную и имеют иерархическую древовидную структуру.
Поисковые системы второго типа работают без вмешательства специалистов и экспертов в предметной области. Образы информационных ресурсов создаются специальными программами - роботами, которые «гуляют» по узлам и собирают информацию в свои базы данных [4,5] - индексы документов (Web-узлов, файлов ключевых слов и адресов источников). В этом случае тематическое разделение документов отсутствует, и поиск ведется исключительно по ключевым словам.
Поисковых систем существует довольно много, однако пользоваться ими не всегда удобно, по разным причинам. Подключение к ним требует значительных сетевых ресурсов: прием и передача мультимедийной информации, интерактивный сеанс с сервером поисковой системы. Кроме того, к известным поисковым серверам одновременно обращаются многие пользователи Internet, что существенно увеличивает трафик и забивает каналы связи.
При этом нельзя сказать, что поисковые серверы содержат исчерпывающую информацию - поисковые роботы не могут полностью охватить все информационные ресурсы и индексировать их. А зарубежные поисковые роботы из-за объективных и субъективных причин не всегда добираются до информационных ресурсов периферийных зон Internet, в том числе и Азербайджанских.
Исходя из этого, перед нами была поставлена задача создания поискового сервера в Азербайджанской части Internet, включающего образы как республиканских, так и зарубежных информационных ресурсов. Поисковая система должна была включать все механизмы индексирования, поиска и диалога с пользователями на естественном языке, позволяя один раз пройти по сети и создать структурированную базу данных - образ информационных серверов всемирной паутины.
Структура поисковой системы
Поисковая система - это комплекс программных систем и баз данных, каждая из которых является самостоятельным блоком и может взаимодействовать с другими. Основными элементами поисковой системы, разработанной в Азербайджанской части Internet, являются (рис.1):
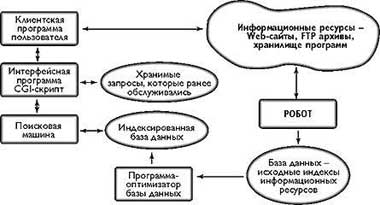 |
| Рис. 1. Структура поисковой системы академической сети |
- программа робота, которая проходит по узлам Internet и индексирует документы сайтов, создавая образы информационных ресурсов Сети;
- программа-преобразователь, оптимизирующая структуру индексной базы данных;
- база данных поисковых систем, содержащая образы (индексы) информационных сайтов Internet;
- поисковая машина - программа поиска информации в базах данных поисковой системы по запросам пользователей;
- интерфейсная программа, позволяющая сформулировать запросы для поиска необходимой информации с помощью CGI-скриптов.
Программа - робот независимо от других подсистем регулярно, один или два раза в неделю составляет индексы и по указанным информационным источникам (Web-серверам, FTP-архивам, хранилищам программ и т.д.) создает исходную базу данных - образы информационных ресурсов. Эти образы включают в себя ключевые слова, встречающиеся в документах, файлах и т.д., а также их URL-адреса.
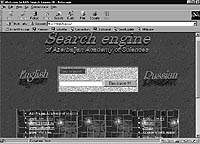 |
| Рис. 2. Интерфейсное окно поисковой системы |
Интерфейс построен на сервисной CGI-программе, которая работает с обычным браузером и дает пользователю возможность подготовить запросы и передать их поисковой машине. Интерфейсная программа выводит на экран окно (рис.2), включающее поле для ключевых слов, ссылки на часто используемые сайты, кнопки переключения на специальные режимы и т.д. На экране имеется также кнопка «Find it now», инициирующая поиск, который можно запустить и клавишей Enter.
При инициализации процесса поиска машина получает от интерфейсной программы запрос пользователя и ведет поиск в базе данных ключевых слов. Результат возвращается CGI-программе, которая передает его пользователю в специальной форме (рис.3). На экран выводится по 25 найденных документов, на следующие документы можно перейти, нажав кнопку «Next Page», а на предыдущие - кнопку «Last Page».
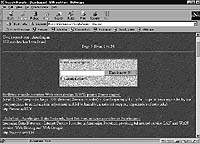 |
| Рис.3. Окно результатов поиска (Запрос - ключевое слово «Azerbaijan») |
Результаты поиска также записываются во временную базу данных - в кэш-память. В дальнейшем, при вторичном обращении к поисковой системе с таким же запросом, CGI-программа выдает ответ, не обращаясь к поисковой машине.
Поисковый робот использует HTTP протокол при обращении к Web-узлами для загрузки документов. На входе он требует указать составленный администратором файл со списком URL-адресов серверов (Servers.lst), которые требуется проиндексировать, а на выходе выдает файл индексов с промежуточной структурой (Source.txt). Робот использует так называемый «стандарт исключения для роботов», который позволяет запретить тем или иным поисковым роботам индексировать ту или иную страницу или весь сервер целиком. В соответствии с этим стандартом информация о запрете на действия поисковых роботов хранится в файле /robots.txt из корневого каталога Web-сервера. Если данный файл пуст или вовсе отсутствует на сервере, робот начинает индексировать всю информацию на сервере без ограничений, начиная с первой страницы (обычно это index.html).
Следует отметить, что в том случае, если на сервере имеется файл /robots.txt и в нем прописаны запреты на индексирование каких-либо страниц с помощью инструкций «User-Agent:» и «Disallow:», то робот пропускает все запрещенные здесь страницы.
Существует два способа выбора Web-серверов для индексирования. В первом названия серверов определяются администратором поисковой системы (причем заранее известно, какие серверы будут индексироваться). Администратор заносит URL-адреса всех Web-серверов в текстовый файл Servers.lst, содержащий список адресов Web-серверов. Каждая строка (запись) представляет собой адрес отдельного сервера. Робот извлекает адрес первого сервера из этого файла и индексирует его, потом извлекает адрес второго сервера и т.д. В этом случае все внешние ссылки, ведущие на другие серверы, исключаются.
Второй способ отличается от первого тем, что здесь в файл Servers.lst вводится одна запись - URL-адрес стартового сервера, а далее, в процессе индексации, обрабатываются как внутренние, так и внешние ссылки. Таким образом обеспечивается переход на другие серверы. Здесь заранее неизвестно, какие серверы будут индексироваться. В отличие от предыдущего способа направление «движения» робота регулировать невозможно.
Следует также отметить, что в первом варианте робот перестает действовать, как только завершается обработка всех страниц на указанных серверах. Если робот обнаруживает внешнюю ссылку, он заносит ее в дополнительный файл серверов NewServers.lst для последующего использования администратором поисковой системы, в частности, как прототип следующего файла - источника серверов для робота. При втором способе процесс индексирования может продолжаться до бесконечности (возможно существование бесконечного числа ссылок, выводящих на новую страницу или на новый сервер) или завершиться преждевременно (на последующих страницах не окажется ни одной ссылки на другие страницы или серверы). Поэтому на каком-то этапе необходимо прервать процесс искусственно (возможно, вручную). Во время индексирования для управления страницами робот использует МЕТА-таги языка HTML: атрибуты NAME и HTTP-EQUIV, а индексируется содержимое параметров «Description» и «Keywords».
После завершения процесса робот передает управление программе, которая преобразует структуру полученной базы в специальную структуру и позволяет уменьшить время доступа к данным, а также сократить размер базы. Эта структура эффективна именно для баз данных, содержащих индексы поисковых систем. Составленная таким образом база данных используется и другими компонентами поисковой системы.
Анализ экспериментального исследования поисковой системы
Программы компонентов поисковой системы разработаны на языке Delphi 5.0 в среде Windows NT 4.0 на базе ПК-сервера. Сейчас система развивается, и ведется работа по созданию более «интеллектуальных» алгоритмов для робота и поисковой системы, функционирующих, в свою очередь, на более мощной платформе, Solaris 2.5, на базе станции SPARCstation 10. В новой версии для определения степени релевантности документов пользовательским запросам применяются методы теории искусственного интеллекта и нечетких множеств. Выбор терминов и ключевых слов из тела документа основан на гибридном методе, включающем статистический, множественный и лингвистический методы. В результате индексирования терминам присваиваются коэффициенты важности, определяющие степени соответствия терминов содержанию документов.
Поисковый робот запускается один раз в неделю в ночное время, когда загрузка каналов связи минимальна. Робот индексирует практически все азербайджанские и множество зарубежных сайтов. Объем базы данных индексов составляет 400-500 Mбайт, увеличиваясь при каждом индексировании. Количество документов, т. е. Web-страниц, индексированных роботом, превышает два миллиона.
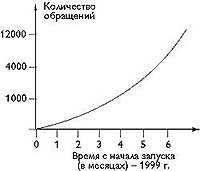 |
| Рис. 4. Рост обращений к поисковой системе |
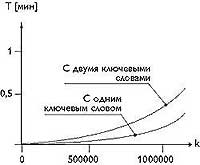
На рис.4 приведена статистика роста числа обращений к системе с начала ее функционирования. Кроме того, были исследованы характеристики поисковой системы: время реакции, полнота и точность поиска (релевантность найденных документов к запросу). Для определения этих характеристик были взяты средние значения результатов выполнения 20 разных тестовых запросов без учета задержки в каналах связи. Во время проведения теста база данных поисковой системы содержала свыше миллиона Web-страниц. В результате проведенных опытов был построен график зависимости времени обработки запроса пользователей от количества документов в базе поисковой системы (рис.5).
Здесь t - время реакции системы на запросы пользователей, k - количество индексов в базе. Из рисунка видно, что для обработки запроса с одним ключевым словом требуется меньше времени, чем для поиска по двум ключевым словам, причем это особенно заметно при больших объемах базы. Кроме того, следует отметить, что время реакции системы также зависит от технического обеспечения сервера и интенсивности обращений.
 |
| Рис. 5. Зависимость времени реакции системы от количества индексов |
Данные измерения проведены на двухпроцессорном сервере NetFRAME Pentium II/400, при интенсивности обращений 100 запрос/мин без пиков.
Средние значения, взятые по результатам проведенных опытов, показывают, что полнота выборки документов составляет 30%, а точность выборки - 60%. Такие значения характеристик полноты и точности связаны с тем, что индексирование документов проводится по содержанию с одновременным использованием ключевых слов и названия документа. Автоматический индекс включает в базу все вхождения терминов, за исключением служебных слов. Таким образом, поисковая машина на основе статистического анализа выбирает более релевантные документы.
Заключение
Созданная поисковая система в азербайджанской части Internet позволяет повысить эффективность поиска по информационным ресурсам Сети и существенно уменьшить внешний трафик, а также нагрузку на внешний канал. Эффективность достигается за счет сокращения времени, затраченного на поиск в целом.
Известно, что процедура поиска включает в себя отправку запроса поисковой системе, поиск в ее базе данных и получение результатов поиска. Соответственно, полное время поиска можно разделить на время отправки запроса, время поиска в базе и время получения результатов. Причем если поисковый сервер является удаленным, то время отправки и получения значительно превышает время поиска в базе.
Несмотря на то, что поисковые службы оказывают услуги бесплатно, стоимость поиска растет пропорционально росту затраченного на него времени. Если поисковый сервер находится за рубежом, то для отправки запроса и получения результатов требуется еще больше времени, соответственно, стоимость поиска растет.
Разработанная система позволяет оптимально организовать поиск информации для азербайджанских пользователей. Кроме того, на сегодня это единственный путеводитель по информационным ресурсам республики, который доступен всем пользователям Internet из любой точки мира.
литература
[1] Павел Храмцов «Информационно-поисковые системы Internet», // Открытые Системы, № 3, Москва, 1996.
[2] V.N.Gudivada «Information search on World Wide Web», // Computer Weekly, Moscow, N 35, 1997.
[3] Robert Filman, Feniosky Pena-Mora «The compare of search systems of Internet», // ComputerWeekly, 40_98, c.15
[4] Charles P.Kollar, John R.R. Leavitt, Michael Mauldin, Robot Exclusion Standard Revisited, http://www.kollar.com/robots.html, June 2, 1996.
[5] Martijn Koster, Standard for robot exclusion, http://info.webcrawler.com/mak/projects/ robots/robots.html.
Об авторе
Вагиф Касумов, заведудющий лабораторией Информационно-Телекоммуникационного Научного Центра Академии Наук Азербайджана, сетевой администратор. С ним можно связаться по email: vagif@dcacs.ab.az
