
Основной стержень такого подхода - методы выявления, восстановления и реконструкции параметров узкополосных сигналов, составляющих звука или речи. Примеры использования данного подхода свидетельствуют о его актуальности при решении задач распознавания и идентификации объектов по их акустическим признакам.
Технологии цифровой обработки акустических сигналов и изображений находят все более широкое применение в различных областях, в частности при идентификации пользователей или для построения многоуровневых систем защиты. Вместе с тем в перечне основных предъявляемых к соответствующим системам требованиям на первом месте стоит универсальность, быстрота и эффективность выполнения различных процедур обработки на основе использования стандартных недорогих технических средств, входящих в комплект традиционной офисной техники и компьютерной телефонии: ПК, сканера, принтера, звуковой платы, модема. Для реализации таких систем нужны подходы, позволяющие обрабатывать акустический сигнал и речь.
Можно ли нарисовать звук?
Известно, что в повседневной жизни через органы зрения мы воспринимаем гораздо больше информации, чем каким-либо другим способом, а поскольку зрительные зоны в мозге человека, по-видимому, доминируют, изображения играют центральную роль в жизни индивида [1]. Картинки приходят к нам во сне, с изображениями часто связана наша интеллектуальная деятельность. Наверное правильно было бы предположить, что информация, поступающая в мозг из других органов чувств, в том числе и через слух, тоже может быть преобразована в некие изображения, которые затем поступают в единый «центральный процессор» и обрабатываются схожими алгоритмами обработки в поисках крупиц новых знаний об окружающем нас мире. Развивая гипотезу о том, что любая информация, получаемая человеком извне, проходит стадию преобразования в изображения с последующей их целенаправленной обработкой, можно вывести последовательность процедур, пригодную для реализации в автоматизированных системах обработки данных различного рода, в том числе и речи.
Предобработка. Независимо от вида полученной информации осуществляется ее преобразование к общему виду первичных описаний в виде двухмерных матриц данных, имеющих неотрицательные значения, которые можно рассматривать как изображения, образы.
Обработка. На основе каких-либо общих принципов, методов и алгоритмов осуществляются преобразования полученных первичных описаний для достижения поставленных целей (сжатие, «шумоочистка», сравнение, распознавание и др.).
Получение новых знаний и принятие решений. Делаются заключения, исходя из характера и вида полученной из внешнего мира информации, а также результатов ее обработки для выполнения конкретных действий в соответствии с общей стратегией поведения индивидуума.
Практическая значимость этой гипотезы состоит в том, что интеллектуальные возможности человека по анализу и обработке визуальной информации, а также наработанный научный потенциал в области восстановления, распознавания и обработки изображений можно распространить сегодня на существующие технологии обработки информации иного рода, в том числе и на акустические сигналы и речь.
Люди воспринимают пространство как «глубину» и изображения, формируемые мысленным взором, представляются им трехмерными. Однако в точных дисциплинах редко применяется обработка трехмерных изображений, что объясняется очевидными техническими трудностями работы с ними, а также недостаточным пониманием природы процесса восприятия изображений. В большинстве практических приложений исследователи имеют дело с квазитрехмерными изображениями, когда по двум известным параметрам, например частоте и времени, строится некая двумерная матрица, значения которой определяются значениями третьего известного параметра, например мощностью или амплитудой рассчитанного мгновенного спектра.
Особенно это касается слухового восприятия, которое, как было показано в ряде исследований еще со времен Х. Гельмгольца, может быть описано моделью спектрального анализатора. Так, в 1946 году профессором Л.Л. Мясниковым было предложено в процессе исследований и распознавания речи использовать визуальный анализ динамических спектрограмм. В те же 40-е — 50-е большое внимание исследователей уделялось анализу структур, полученных в процессе обработки выходных сигналов линейки аналоговых фильтров. В 60-х в ряде физиологических исследований была подтверждена целесообразность «скользящего» спектрального анализа речевых сигналов. В работах Д. Розе отмечено, что каждые 60 - 100 мкс слуховая система человека как бы опрашивает состояние «гребенки» физиологических фильтров [2]. В совсем недавних исследованиях показано, что можно распознавать и восстанавливать речевые сигналы, используя полноразмерный спектральный анализ речи на основе динамических разверток коэффициентов спектральных преобразований [2,3].
Частотно-временные описания фонообъектов
Введем определение фонообъекта, представляющего собой реальный объект, генерирующий и излучающий акустический сигнал в полосе воспринимаемых слухом человека звуковых частот. Такой сигнал после несложных аналогово-цифровых преобразований, уже в цифровой форме, может записываться и хранится в памяти компьютера. Под категорию фонообъектов может попадать не только речь человека, но и любые другие акустические сигналы, в том числе и те, которые мешают правильному и качественному слуховому восприятию речи. Под сложным фонообъектом будем понимать совокупность простейших звуков (простейших фонообъектов), его составляющих.
Вокализованный участок речи с квазигармонической помехой можно представить как суперпозицию помехи и речевого сигнала, который в свою очередь можно рассматривать как совокупность звучания отдельных обертонов, входящих в состав данного исследуемого фрагмента речи. В таком примере, все приведенные звуковые слагаемые удобно рассматривать в виде суперпозиции узкополосных сигналов, имея в виду, что все спектральные составляющие каждого элементарного составляющего общего звука группируются в относительно узкой по сравнению с некоторой центральной частотой полосе. Впрочем, в ряде приложений иногда и сам сложный фонообъект также удобно рассматривать в виде узкополосного процесса.
Под следами фонообъектов мы будем понимать параметры узкополосных сигналов, составляющих исследуемый акустический сигнал - фонообъект. Подобное параметрическое описание аудиосигнала позволяет либо полностью повторить его звучание после синтеза звука по заданным параметрам, либо воссоздать и озвучить «новый» аудиосигнал по целенаправленно (сознательно) вновь созданным или измененным в первоначальном описании значениям отдельных параметров. Выявлением, модификацией, изменением, добавлением или удалением именно этих параметров в подавляющем большинстве случаев можно достичь решения конкретной поставленной задачи акустической и речевой обработки.
Понятно, что теперь разработка новых и совершенствование имеющихся компьютерных технологий обработки звука будет зависеть, прежде всего, от принятых количественных мер оценки узкополосных сигналов, составляющих аудио сигналы и речь. Поэтому желательно выбрать такую модель аналитического представления звукового сигнала, с которой в дальнейшем было бы удобно работать. Основные зависимости, описывающие аналоговые или дискретные представления аудиосигнала и речи по Гильберту, представлены на врезке.
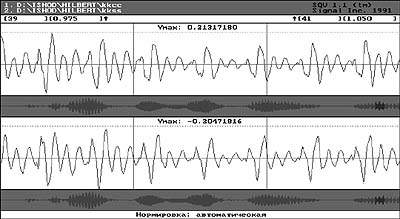 |
| Рис. 1. Квадратурные, косинусная (вверху) и синусная (внизу), составляющие фрагмента речевого сигнала |
На рис. 1, соответственно в верхней и нижней панелях, представлены волновые формы вокализованного фрагмента исходного звукового сигнала и сопряженного ему по Гильберту, а на рис. 2 показаны значения гильбертовских огибающей и косинуса фазы того же участка исходного сигнала.
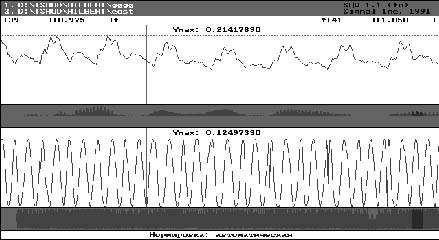 |
| Рис. 2. Функции огибающей (вверху) и косинуса фазы (внизу) по Гильберту исследуемого фрагмента речи |
Заметим, что на обеих, косинусной и синусной, составляющих аналитического сигнала (рис. 1) в полной мере нашло отражение то свойство, что когда значение одной из составляющих обращается в ноль, значение сопряженной составляющей достигает своего экстремума. Кроме того, в результате произведения гильбертовской огибающей и косинуса фазы (рис. 2), с точностью до постоянного множителя всегда можно получить исходный фрагмент речевого сигнала, волновая форма которого будет полностью повторять форму волны, представленную в верхней панели (рис. 1).
Предполагается, что количество простейших фонообъектов, входящих в состав сложного исходного звукового сигнала в заданном окне наблюдения выбирается в зависимости от конкретного приложения. Отметим, что описание фонообъекта в виде суммы узкополосных сигналов часто бывает более удобным, поскольку значение K - числа узкополосных составляющих исходного звукового сигнала, может быть выбрано любым, в зависимости от типа решаемой задачи обеспечения безопасности речевой связи. В частности, в некоторых приложениях, иногда сразу бывает необходимым даже сложный фонообъект изначально представлять как узкополосный процесс, можно принимать K=1, и тогда формулы (1),(2) и (3) существенно упрощаются, а в других удобней брать K(512. На вокализованных участках речи, как правило, можно задавать K в диапазоне (8?64).
Несмотря на то, что частные дискретные описания (2) и (3) общего представления исходного звукового сигнала по формуле (1)используются в приложениях довольно часто, тем не менее, в решении некоторых задач речепреобразования, возможно применение и других вытекающих из (1) описаний. В частности, возможно использование произвольных комбинаций уже известных по (2) и (3) представлений, а также других их видов при последующей их подстановке в (1). Таким образом, в приведенных в формуле (1) и ее частных случаях (2) и (3) описаниях звукового сигнала (фонообъекта) именно значения параметров гильбертовских огибающих и фаз как раз и являются теми следами фонообъектов, с которыми в дальнейшем мы и будем оперировать.
Формулы (2) и (3) наиболее хорошо подходят и для описания сложного фонообъекта в различных задачах цифровой обработки звука, когда слагаемыми его звучания могут выступать одновременно и узкополосные сигналы относящиеся к речи, например гармоники вокализованных участков, и узкополосные сигналы, относящиеся к помехам и/или шумам.
Отметим, что описание звуковых сигналов в виде ряда Фурье также может быть сведено к их представлению по формуле (1). В этом случае число узкополосных составляющих исходного звукового сигнала K принимается равным половине базы дискретного преобразования Фурье N. Кроме того, можно показать, что и большинство других распространенных видов описаний речевых сигналов можно привести к предложенному параметрическому описанию по формуле (1) и ее частным случаям (2) и (3), поскольку большинство из них первоначально можно отобразить через преобразование Фурье.
Результаты исследований показали, что данные, необходимые для расчета параметров узкополосных сигналов, составляющих исследуемый звук, могут содержаться в динамических спектральных развертках аудиосигнала - амплитудно-фазовых, частотно-временных мгновенных спектрах аудиосигнала, рассчитанных с заданным шагом наблюдения по времени и частоте. Эти развертки мгновенных комплексных спектров, идущие друг за другом по временной оси, и будут составлять столбцы формируемых динамических изображений спектрограмм. Для речевых сигналов это будут, прежде всего, изображения узкополосных сонограмм. Такие развертки, часто еще называемые матрицами динамических спектральных состояний (МДСС), можно получать в ходе динамического спектрального анализа-синтеза речи (ДСАС), скользя по исходному сигналу выбранным окном анализа с переходом от взвешенных им выборок к их частотному образу на базе принятого ортогонального базиса. Примером такого рода технологий может служить кратковременный Фурье анализ-синтез звуковых и речевых сигналов, часто используемый в цифровых системах речепреобразования.
Графические образы для анализа и обработки аудиосигналов
Что же следует из предыдущего, возможно, перегруженного математическими выкладками рассуждения? Следует новый подход к построению программных и программно-аппаратных средств аудио и речепреобразования на основе обычной вычислительной техники. Идея состоит в переводе звукового сигнала в графические образы (изображения спектрограмм и фазограмм) и обратно с одновременным применением различных методов цифровой обработки изображений. При этом принципиально, что обработке подвергаются двухмерные данные, которые, вообще говоря, не всегда принимают неотрицательные значения [1]. Схема данного подхода представлена на рис. 3.
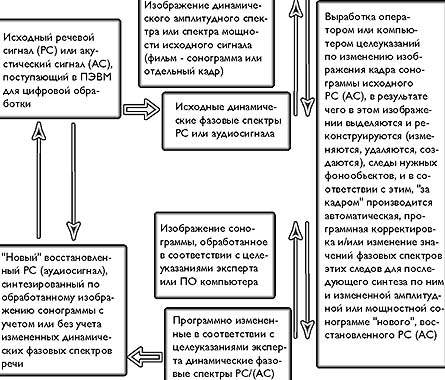 |
| Рис. 3. Схема анализа и обработки речи через обработку изображений их графических образов |
Основной стержень этого подхода - разработка и применение методов анализа, восстановления, реконструкции (модификации, добавления и удаления) и синтеза следов фонообъектов (узкополосных сигналов), составляющих исходный звук и присутствующих на частотно-временной сетке в виде полос различной толщины и цветовой насыщенности. Траектории, амплитуды и фазы среднего сечения таких полос в узлах частотно-временной сетки - и есть параметры узкополосных сигналов или следы фонообъектов, зная которые можно восстановить или модифицировать исходный звук или речь. Пример визуализации следов фонообъектов показан на рис. 4.
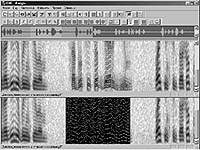 |
| Рис. 4. Визуализация узкополосных сигналов, составляющих звук или речь, на примере узкополосной сонограммы |
На верхней панели рис. 4 показана грубая волновая форма (осциллограмма) исследуемого фрагмента речи, состоящего из трех произнесенных фраз и двух пауз между ними. В средней панели представлено изображение динамической сонограммы этого же фрагмента, где следы фонообъектов проявляются на голосовых участках в виде узких, иногда извилистых полос различной толщины, а также в виде пятен (вырожденных полос) на паузных участках. На приведенных изображениях сонограмм время откладывается по оси абсцисс, а частота - по оси ординат, начиная с левого нижнего угла изображения. Максимальная мощность исследуемого узкополосного сигнала в узле частотно-временной сетки показана черным цветом, минимальная - белым, а промежуточные значения - различными уровнями серого.
В средней панели (рис. 4) в виде светлых линий посередине узкополосных сигналов обозначены траектории их движения на частотно-временной сетке, которые также можно рассматривать как совокупность контуров перепада яркости, или как цепочки локальных экстремумов. В нижней панели показано двоичное изображение траекторий узкополосных сигналов на выделенном участке. Используя данные об окне наблюдения, шаге динамического спектрального анализа-синтеза, частоте дискретизации, амплитуде, фазе и траектории движения по частотно-временной сетке узкополосных сигналов можно с очень высокой степенью точности по формулам (1), (2) и (3)восстановить исходный звук. Изменяя эти данные, можно достичь желаемого результата решения конкретной задачи аудио обработки.
Подобные изображения динамических сонограмм достаточно известны и нередко используются в задачах анализа речевых и акустических сигналов. Но только благодаря предложенному здесь подходу непосредственно по этим, или им подобным, изображениям графических образов звука можно производить различного вида процедуры цифровой обработки изображений с последующим переводом данных обновленных графических образов в звук. Кроме того, в большом количестве прикладных задач не всегда нужно учитывать исходные значения фазы. В таких случаях синтез производится непосредственно только по данным неотрицательных значений амплитудных или мощностных спектрограмм, с восстановлением по ним закона развития фазы во временной области с точностью до ее начального значения.
Практическая реализация предложенного подхода к анализу-синтезу и обработке аудиосигналов возможна при использовании уже имеющихся на рынке обычных компьютерных систем со звуковой платой и устройствами стыковки с выбранным каналом речевой связи, а также распространенных программ аудиообработки. Существует большое количество хороших программных цифровых анализаторов и редакторов аудиосигналов, предназначенных для визуального анализа звука во временной (осциллограммы, графики уровня мощности сигнала и др.) и частотной (сонограммы, кепстры и др.) областях. Среди западных программных продуктов такого рода следует отметить Cool Edit Pro 1.2, Dart Pro, Sound Forge, Wave Lab, Wave Studio, среди отечественных - SIS 5.2, «Win-Аудио», «Лазурь», Signal Quick Viewer 2, Signal Viewer.
Во многих известных звуковых редакторах имеется возможность выполнять простейшую обработку аудиосигналов во временной области с возможной оценкой полученных результатов в частотной области. Однако лишь несколько программных продуктов, например специальное программное обеспечение «Лазурь», способны производить сложные виды акустической обработки, в том числе и в частотной области, через анализ, модификацию и синтез графических образов звука - по изображениям динамических спектрограмм. В новой версии программы «Лазурь» реализована прямая возможность выборки интересующего участка изображения динамической спектрограммы исследуемого фонообъекта. К выбранному участку можно приложить либо собственные, интегрируемые в программу средства цифровой обработки изображений, либо преобразовать его в формат BMP, чтобы использовать мощный арсенал инструментов, предоставляемый популярными графическими редакторами типа Adobe Photoshop. После обработки выбранного участка изображения можно осуществить его обратную вставку на любое место на временной оси исходного сигнала посредством программы «Лазурь», с последующим синтезом (переводом в волновую форму звука) модифицированного изображения.
С помощью описанного подхода в процессе взаимодействия человека и компьютера на долю первого приходится лишь творческий процесс обработки звука и речи, представленных в виде графических образов. Этот процесс, сходен с работой художника-ретушера, улучшающего качество искаженных или зашумленных фотографий (кадров), вырезающего и обрабатывающего нужные участки, делающего необходимые пометки в кадре и т.п. Любое изменение изображения графического образа речи тут же приводит к синтезу нового речевого сигнала, изображение амплитудного спектра которого адекватно соответствует измененному графическому образу динамической спектрограммы.
Заметим, однако, что во многих приложениях можно использовать абсолютно различные представления графических образов акустического сигнала, а не только изображения динамических звуковых спектрограмм.
Некоторые практические приложения
Как уже отмечалось, под непосредственной обработкой изображений понимается выполнение различных операций над данными матричного вида, которые принципиально двумерны. Обработка изображений обычно включает наиболее полное устранение искажений из данных, которые затем должны быть представлены в виде изображений, для того чтобы ценная информация, содержащаяся в них, могла быть либо эффективно сжата в целях хранения, передачи или дальнейшего распознавания образов.
Информация о следах фонообъектов, содержащаяся в изображениях динамических спектрограмм, может подвергаться искажениям разного рода, вследствие чего звучание акустического сигнала часто оставляет желать лучшего. По аналогии с обработкой изображений различной природы [1] обработку изображений графических образов звукового сигнала с целью удаления различного рода искажений сигнала можно подразделить на коррекцию геометрических искажений (rectification); улучшение визуального качества (enhancement); восстановление (restoration) и реконструкцию (reconstruction).
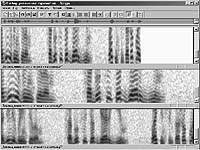 |
| Рис. 5. Изменение темпа и тембра речи |
При коррекции геометрических искажений в динамических спектрограммах выполняются пространственные преобразования, с помощью которых устраняются геометрические искажения или обеспечивается возможно более точное совмещение изображений относительно друг друга, как, например, в фотокартографии, когда используются широкоугольные объективы, расположенные на подвижных платформах (на самолетах и искусственных спутниках Земли) [1]. На рис. 5 показаны сонограммы того же фрагмента речи, что и на рис. 4, синтезированные по исходной сонограмме (центральная панель), но с изменением масштаба как по времени, так и частоте.
При изменении масштаба по времени сохраняются все индивидуальные особенности диктора, однако темп речи изменяется. Такой способ обработки речевого сигнала может найти применение в приложениях IP-телефонии - когда один из пакетов с блоком данных речевого сообщения запаздывает можно несколько «притормозить» воспроизведение ранее пришедшего блока. Небольшие до 20% отклонения в замедлении и ускорении темпа воспроизведения в той же полосе частот не сказываются на качестве речи и комфортности ее восприятии. Замедление темпа воспроизведения часто бывает полезным при прослушивании фонограмм с неважной разборчивостью. Ускорение темпа речевого сообщения иногда необходимо для быстрого прослушивания длинной речевой записи. Часто, особенно при некачественном радиоприеме, требуется скорректировать, диапазон частот принимаемого сигнала. Пример такой корректировки, полученной в результате сжатия частотного диапазона выбранной части исходного изображения сонограммы в Photoshop с последующей вставкой на свое место и синтезом по новой «картинке» в программе «Лазурь», показан в нижней панели рис. 5.
Цель улучшения визуального качества изображений акустических спектрограмм - получение улучшенных картинок, позволяющих визуально воспринимать полезную информацию без дополнительной сложной обработки. Техника улучшения визуального качества изображений доведена сегодня до совершенства, в особенности для изображений, получаемых с космических аппаратов [1]. Такого же улучшения можно достичь в результате подавления некоторых следов шума и помех, компенсации нелинейностей амплитудно-частотных характеристик носителя или устройства записи фонограмм, оптимизации контраста, подчеркивания границ изображений и других мер, осуществляемых над исследуемым изображением сонограммы в графическом редакторе типа Photoshop, с последующей вставкой и преобразованием в звук улучшенного изображения.
Применяя описанные здесь подходы к переводу звука в изображение и обратно после улучшения визуального качества, можно предложить новую дополнительную меру защиты конфиденциальных документов от фальсификаций и подделки - «речевую подпись», поскольку сами изображения сонограмм могут использоваться для передачи и хранения речи на бумажных носителях. При реализации технологий речевой подписи [4], связанных с защищаемым документом по смыслу и содержанию примерно так же, как и цифровая подпись, на стандартный лист бумаги наносится от 2 до 4 минут речи телефонного качества.
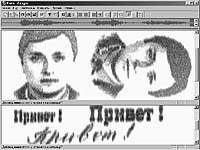 |
| Рис. 6. Примеры звуковой подписи и компьютерной стеганофонии |
В качестве экспериментальной проверки решения задач, связанных с технологией речевой подписи с помощью программы «Лазурь» были озвучены предварительно отсканированные сонограммы из статей в журналах «Спецтехника», «Конфидент» и ряде других изданий. В результате синтеза по сонограммам, полученным при помощи совершенно разных программных продуктов, был полностью восстановлен смысл, и даже индивидуальные особенности звучания содержащихся в них речевых сообщений. Причем после прослушивания ряда сонограмм, приводимых в некоторых работах в качестве изобразительных примеров результатов реализации некоторых методов шумоочистки, автор и его коллеги с удивлением узнали свои голоса, которые теперь в качестве тестовых файлов гуляют по российским просторам.
На основе предложенной технологии по любому заданному или известному изображению аудио сигнала можно синтезировать звук для последующего его хранения или передачи по каналам связи. В верхней панели рис. 6 показаны осциллограмма и спектрограмма звукового сигнала, синтезированного по отсканированному фотоснимку автора десятилетней давности. В нижней панели этого же рисунка представлена динамическая спектрограмма акустического сигнала, основой создания которого послужили образцы печатного и рукописного текстов. Такого рода пометки или маркеры можно использовать для решения некоторых задач скрытной передачи информации или идентификации и верификации ее владельца.
В большинстве же практических приложений рассматриваются вопросы восстановления и реконструкции изображений. Восстановление изображений иногда отождествляют с улучшением его визуального качества [1]. Однако необходимо проводить четкое различие между улучшением визуального качества и восстановлением и реконструкцией. Видеоинформация часто оказывается нераспознаваемой из-за нежелательных искажений.
Под восстановлением изображений понимается оценка параметров искажений, точный характер которых неизвестен и его использование для коррекции исходных данных при наличии некоторых априорных сведений только об исходном звуковом сигнале. Под реконструкцией же изображений в приложении к задачам аудиообработки подразумевается извлечение из этих изображений деталей об исходном звуке, необходимых для его последующей обработки при наличии априорных данных, как о самом исходном акустическом сигнале, так и о возможно присутствующих в его графическом образе искажениях.
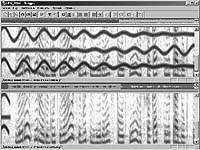 |
| Рис 7. Удаление следов мощной помехи из речевого сигнала |
Для того чтобы можно было на практике использовать методы восстановления и реконструкции, необходимо ввести соответствующие программные модули в систему обработки изображений графических образов звука. Эти методы могут стать частью библиотеки совместимых программных средств реализации традиционных способов обработки изображений. Задача восстановления или реконструкции изображений акустических спектрограмм редко основывается только на одном алгоритме или методе. Ее решение обычно состоит из несколько этапов и достигается совместным использованием методов улучшения визуального качества изображений и коррекции геометрических искажений. Вот почему возможность таких многоходовых комбинаций обработки изображений показана на рис. 3 в виде кольцевых стрелок. Согласно предложенному подходу после синтеза по восстановленным и реконструированным изображениям акустических спектрограмм всегда можно осуществить переход к волновой форме звукового сигнала с последующим его прослушиванием.
На рис. 7 показан пример восстановления разборчивости искаженного речевого сигнала, путем исключения из изображения сонограммы следов помехи (в виде жирных черных волнистых линий), существенно, на 25 дБ, превышающей речь по уровню мощности. Примеры технического закрытия речи - введения неразборчивости в речевой сигнал посредством различных видов модификации и реконструкции узкополосных составляющих речи на участках изображений ее сонограмм показаны на рис. 8. Проведя обратные графические преобразования, можно полностью восстановить речевой сигнал.
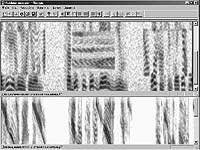 |
| Рис. 8. Примеры технического закрытия речи |
После того как произведена непосредственная обработка цифровых изображений через коррекцию улучшение, восстановление и реконструкцию графических образов аудио сигналов можно, в случае необходимости, приступать к процедурам сжатия и распознаванию образов. На рис. 9. приведен пример решения задачи сжатия речи путем «упаковки» графического образа речевого сигнала различными способами.
В случае исключения из исходного изображения сонограммы информации о мелодии основного тона (нижняя панель рис. 9) можно не только добиться очень высокой степени сжатия исходной речи, но и использовать такую сонограмму для поиска ключевых слов в потоке слитной речи по известным эталонным образцам также, представленных в подобной графической форме.
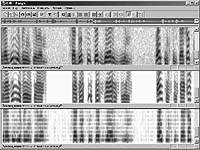 |
| Рис. 9. Примеры сжатия речи |
Находит свое экспериментальное подтверждение и гипотеза о проявлении индивидуальных особенностей голоса диктора в векторе начальных фаз узкополосных составляющих вокализованных участков, рассчитанных по формулам (2) и (3) и приведенных к одной выбранной опорной. Как известно фазовые соотношения спектральных составляющих речи, слабо влияют на ее слуховое восприятие и трудно поддаются математическому расчету, поэтому в ранних исследованиях по речевой обработке на них не обращали особого внимания. Действительно, если речевой сигнал просинтезировать только по изображению его сонограммы, над которой не было произведено никаких действий, и без учета значений мгновенных фазовых спектров, а только восстанавливая при синтезе закон изменения полной фазы без учета ее начального состояния, то звучание, узнаваемость и разборчивость нового, так созданного, звукового сигнала будут абсолютно неотличимы от исходного при корректно проведенных расчетах. Волновая же форма нового сигнала может быть совершенно другой по отношению к исходной осциллограмме.
Отметим, что, несмотря на математическую сложность реализованных в предложенном подходе алгоритмов их могут применять даже пользователи, обладающие минимальными навыками работы с компьютером и звукозаписывающей аппаратурой. Это обусловлено тем, что интерфейс задания пользователем необходимого алгоритма речевой обработки сводится к выдаче пользователем целеуказаний по обработке изображений динамических амплитудных спектров как искаженной, так и неискаженной помехами речи. В этом случае пользователь превращается в «художника», который с помощью «электронного ластика», «карандаша» и других предоставленных в его распоряжение программных инструментов выделяет из изображений спектрограммы следы речевого сигнала и затирает следы шумов и помех, проставляет стеганофонические маркеры и т.п. Таким образом можно, например, осуществить изменение темпа речи в заданном частотном диапазоне, для повышения комфортности ее восприятия, скорректировать функцию мелодии основного тона голоса говорящего, с целью достижения его неузнаваемости, выделить и систематизировать признаки работы различных речепреобразующих устройств.
Благодаря принятому подходу к анализу и обработке речи, через анализ и обработку ее графических образов (сонограмм), максимально сокращается время обучения пользователя проведению эффективной обработки речевых сигналов. За кадром остается выбор оптимальных характеристик линейного предсказания речи, порядка и коэффициентов цифровых фильтров, типов интерполяционных кривых, видов окон взвешивания отсчетов речевых сигналов и других параметров речевой обработки, способных существенно затруднить работу даже хорошо подготовленного в области речевых технологий специалиста.
Заключение
Таким образом, достаточно сложные задачи цифровой обработки звуковых сигналов и речи могут быть успешно решены с помощью сравнительно простых технических средств и понятных методов цифровой обработки изображений акустических спектрограмм.
Проведенные многочисленные эксперименты по использованию предложенного подхода обработки звука и речи через обработку их графических образов в компьютерных системах стандартного исполнения показали его высокие потенциальные возможности при осуществлении различных — даже очень сложных и ранее нереализуемых — алгоритмов обработки аудиосигналов. Данный подход может стать базовым при проектировании новых систем цифровой обработки аудиосигналов и оценке эффективности использования речепреобразующих устройств, уже имеющихся на рынке. Рисунки сонограмм, приведенные в статье, построены при помощи системы «Лазурь», поставляемой российской компанией «Ново», а рисунки осциллограмм получены при помощи Signal Quick Viewer 2 компании «Сигнал-ком».
Сергей Дворянкин (s_dvorn@mail.ru) — независимый автор (Москва).
Литература
1. Бейтс Р., Макдонелл М. Восстановление и реконструкция изображений: Пер. с англ. - М.: Мир, 1989. - 336 с.
2. Плотников В.Н., Белинский А.В., Суханов В.А., Жигулевцев Ю.Н. Цифровые анализаторы спектра. - М.: Радио и связь, 1990.
3. Дворянкин С.В. Компьютерные технологии защиты речевых сообщений в каналах электросвязи /Под ред. А.В. Петракова. - М.:РИО МТУСИ, 1999. - 52 с.
4. Дворянкин С.В., Минаев В.А. Технология речевой подписи, «Открытые системы». 1997, № 5. c. 68-71.
В качестве такой модели простого фонообъекта можно использовать аналитическое описание звукового сигнала по Гильберту:
s(t) = G(t) cos Y(t),
где G(t) и Y(t), соответственно, огибающая и полная фаза сигнала - , которые описывают этот аудио сигнал или речь в виде некоего узкополосного процесса в ограниченной полосе частот и связаны между собой посредством преобразований Гильберта. Подобным образом в ряде приложений, например, можно рассматривать и сам речевой сигнал в полосе частот телефонного канала связи 0,3?3,4 КГц. В то же время полную фазу можно представить в виде:
Y(t) = w0t + q(t) + j0 ,
где w0; q(t); j0 - соответственно центральная частота, нелинейная составляющая полной фазы и начальная фаза звукового сигнала, значения которых определяются через мгновенную частоту:
w(t) = dY(t)/dt.
Аудиосигнал, сопряженный по Гильберту по отношению к исходному можно представить как:
sG(t) = G(t)sin Y(t).
Вместе обе, косинусная s(t) и синусная sG(t), составляющие аудиосигнала представляют собой так называемый аналитический сигнал. Такое квадратурное описание звукового сигнала удобно при решении многих задач аудио обработки. Заметим, во-первых, что гильбертовская огибающая по определению может принимать только неотрицательные значения, и, во-вторых, что в некоторых случаях в качестве фазовой характеристики звукового сигнала удобно использовать не саму фазу Y(t), определенную через преобразование Гильберта, а ее косинус, значения которого лежат в диапазоне (1. Добавив к значениям косинуса полной фазы смещение большее либо равное +1, можно получить некие неотрицательные значения, необходимые для последующего построения изображений фазограмм).
Для описания сложного фонообъекта в дискретном, цифровом виде можно использовать следующее выражение:
![]() , (1)
, (1)
где gk(i) и Yk(i) значения Гильбертовской огибающей и фазы k-го фонообъекта, входящего в состав исследуемого звукового сигнала.
Часто на практике проще использовать следующие, являющиеся частным случаем (1), дискретные представления аудиосигнала:
![]() , (2)
, (2) ![]() , (3)
, (3)
где Ak- значение амплитуды k-ой узкополосной составляющей исходного аудиосигнала, а sn(nT) - функция, характеризующая шум или ошибку представления. Число значимых узкополосных составляющих исходного фонообъекта K в (1),(2) и (3) выбирается в зависимости от условий каждой конкретной решаемой задачи.
