

Совмещение объектной и реляционной систем активно обсуждается в прессе — спектр мнений чрезвычайно широ, начиная с идеи о практической идентичности данных моделей, требующей лишь незначительного расширения одной из них, и кончая явным противопоставлением, ведущим к выводу о невозможности их объединения. Критике в той или иной мере подвергаются обе модели.
Не вдаваясь в подробности можно сказать, что недостатки каждой модели неразрывно связаны с их преимуществами и фактически противоположны друг другу. Реляционные системы (R-системы) критикуются за отсутствие гибкости, являющейся следствием формальностии (а следовательно, строгости и стабильности), а объектные (O-системы) - за отсутствие формальности, являющейся следствием гибкости. [1,6,7,8, 19,21,22,23]
Данная работа исходит из практической завершенности как реляционной так и объектной концепций. Цель данной статьи - показать, что эти концепции абсолютно не противоречат друг другу и не требуют каких-либо изменений для того, что бы использоваться в общей системе, обладающей всеми свойствами как объектных,так и реляционных систем.
Это идея основывается на следующих утверждениях:
- Один и тот же набор данных может одновременно описываться несколькими разными моделями
- Реляционная и Объектная модели - разные модели.
- Структуру любой сложности можно нормализовать.
Рассмотрим эти утверждения подробнее
Один и тот же набор данных может одновременно описываться разными моделями
Рассмотрим следующий пример. Программа написанная на O-языке, например С++, сохраняет свои данные в виде обьектов в ОЗУ компьютера. ОЗУ, которое является хранилищем данных, описывается некоторой моделью данных (которую можно назвать моделью ОЗУ) и позволяет сохранять данные в виде набора адресуемых элементов памяти. Программа написанная на О-языке, позволяет представить эти же данные в виде идентифицируемых наборов информации (т.е. обьектов) имеющих определенную структуру (определяемую типом класса объекта), из чего следует , что для каждого элемента хранилища (в данном случае ячейки ОЗУ) тем или иным образом определено 1) о каком именно объекте он содержит информацию 2) какое место занимает этот элемент в структуре этого объекта и ( поскольку место в структуре определяется именем и это же имя определяет семантическое значение - или смысл - данного элемента) то, какой смысл имеет данная информация для этого объекта. Можно сказать, что объектом в данном случае является осмысленный и идентифицируемый набор элементов хранилища(ОЗУ).
Что же можно понимать под разными моделями данных? Можно рассмотреть этот вопрос с точки зрнения классификации моделей данных. В настоящее время выделяют три уровня моделирования прикладной области - концептуальный, логический и физический[18,20]. В приведенном примере можно выделить модели концептуального уровня ( объектная модель языка C++) и физического уровня (модель ОЗУ). Таким образом, можно предположить, что разными являются модели относящиеся к разным уровням. Однако такое определение является весьма условным.
Более строго разными моделями данных можно назвать ортогональные модели. Определение ортогональных моделей является весьма нетривиальным. В рамках данной статьи интересным представляется следствие ортогональности (основанное на том, что модель данных можно определить как множество возможных типов данных [2]): любой тип данных определенный в модели М* ортогональной данной модели М, может рассматриваться в данной модели М только как скалярный (базовый) тип[6,8,10,12, 13,15]. В приведенном примере такими скалярными типами, используемыми в объектной модели языка С++, являются базовые типы int, char и т.п. описывающие возможные типы элементов хранилища данных, т.е. определенные в модели ОЗУ. Таким образом можно сказать, что один и тот же набор данных может одновременно описываться несколькими ортогональными моделями.
Реляционная и Обьектная модели - разные модели
Реляционная и объектная модели относятся к разным уровням моделирования прикладной области. Реляционная модель относится к логическому уровню моделирования, объектная модель является концептуальной. Для того чтобы более четко определить разницу между этими моделями рассмотрим системы, основанные на них.
Системой можно назвать множество закономерностей определяющих существование и взаимодействие элементов этой системы. Для того, чтобы описать некую систему, введем следующие операции.
- Операция ADR(X) (где X - элемент системы) является необходимой и достаточной для однозначной идентификации элемента Х системы, т.е. ADR(Xi)!=ADR(Xj) (при Xi!=Xj) и ADR(Xi) =ADR(Xj) (при Xi = Xj). Возвращает величину необходимую для однозначной идентификации элемента X.
- Операция IS(X) возвращает тип элемента Х. Поскольку тип можно определить как множество имен атрибутов, то можно сказать, что в системе существует некое множество являщееся объединением всех множеств имен атрибутов всех типов, которое в дальнейшем будем называть пространством определения типов. Таким образом операция IS(X) проецирует элемент X на простанство определения типов.
В случае O-систем операция ADR(X) возвратит уникальное значение А ( или OID) объекта Х или, говоря по другому, спроецирует объект Х на адресное пространство ( пространство значений OID ) системы. Можно сказать, что результатом операции ADR(X) будет (А) где A - адрес. Исходя из определения операции ADR(X), действительным является выражение Аi!=Аj (где Хi!=Хj). Кроме того из самой возможности сравнивать Ai и Aj следует что IS(Ai) = IS(Aj). Для сохранения адресов используются элементы особого базового типа - ссылки или указатели.
Следует сказать, что в общем случае пространство определения типов О-системы является сложным и многомерным, что следует из многобразия способов типообразования в этой системе.[5,18] Одним из этих способов является наследование. Этот способ присущ только О-системам и позволяет при определении новых типов использовать уже существующие, более общие по смыслу, базовые типы. Благодаря наследованию в О-системах один и тот же атрибут может быть определен в разных типах. На иллюстации класс В является наследником класса А и поэтому атрибут I определенный в классе А определен также и в классе-наследнике В. [1,5,16]
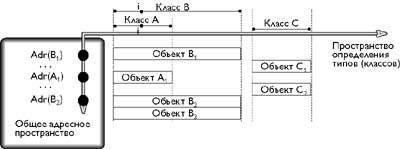 |
| Рис. 1. Простейшая реализация O-системы |
Для того чтобы изобразить пространство R-системы необходимо вспомнить о ключе.Это понятие является одним из основных для R-систем и определяется следующим образом: ключом отношения называют такое подмножество внутри множества имен атрибутов отношения, что кортежи отношения могут быть однозначно определены значениями соответствующих атрибутов этого подмножества. Таким образом ключ состоит из набора значений которые однозначно определяют любую строку таблицы. Определенное значение ключевого поля (или полей), принадлежащих записи некоторой таблицы, позволяет найти эту запись внутри этой таблицы.[1,4]
Для однозначной идентификации кортежа Х некоторого отношения R операция ADR(X) должна вернуть выражение вида (R,K), которое звучит как «Ключ K кортежа X отношения R где R = IS(X)» . На этом определении основывается понятие внешнего ключа, который может быть назван R-аналогом ссылок и указателей O-систем. Определение подобного рода позволяет ввести в R-системы (рис. 2) механизм поддержки ссылочной целостности не позволяющий присвоить ссылке(внешнему ключу) значение выходящее из области значений первичного ключа соответствующего отношения.
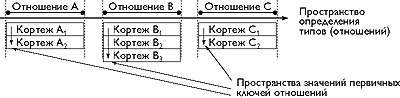 |
| Рис 2. R-система |
Если сравнивать пространства R- и O- систем то можно отметить два различия:
1. в O-системе объекты существуют в едином адресном пространстве в то время как в R-системе для каждого отношения существует свое собственное пространство значений первичного ключа. Можно сказать, что в O-системе адресное пространство является характеристикой присущей системе в целом и понятие «адрес» вводится до начала описания каких-либо классов, в то время как в R-системе пространство первичного ключа отношения R является характеристикой только этого отношения и и оно не определено до описания самого этого отношения. Данные рассуждения верны также и для элементов системы позволяющих сохранять адрес. Существующий в O-системах ссылочный тип данных определяется системой и не зависит от типа объектов на который ссылка указывает. Возможно объявить неопределенную ссылку (в C++ - это указатель void* ) или на класс, который является базовым для любого другого класса и существует в системе по умолчанию (в Java - ссылка на объект класса Object). В R-системах внешний ключ должен быть связан с первичным ключом определенного отношения, и следовательно может быть объявлен только после того как это отношение описано.
2. В пространстве определения типов: рис.1 иллюстрирует наследование - одно из ключевых понятий O-систем. На рисунке класс B является наследником класса А.
Основные свойства системы, объединяющей R- и O- системы, должны складываться из свойств присущих каждой из этих систем в отдельности. Следовательно
- все данные, имеющиеся в такой системе должны быть представлены как объекты прозвольной структуры.
- все данные, имеющиеся в такой системе должны быть представлены в виде реляционных переменных [9]
Кажется, что наиболее простым путем создания системы имеющей свойства R- и O-систем будет расширение R-системы за счет введения в нее общего адресного пространства и применения к отношениям операции наследования. Рассмотрим это подробнее.
Создание общего адресного пространства в R-системе
Расcмотрим пару (R,K) подробнее. Поскольку она описывает результат операции ADR(X), однозначно идентифицирующей кортеж Х внутри системы, можно сказать что (Ri,Ki)!=(Rj,Kj) при Хi!=Хj. Отдельные части описываемой пары данное условие не поддерживают и возможен случай когда Ki = Kj при Хi!=Хj. Можно предположить, что исключение подобных случаев является одним из условий приведения R-системы к O-системе. Выполнение условия Ki!=Kj (при Хi!=Хj) не будет нарушать R-систему, поскольку (Ri,Ki)!=(Rj,Kj) не становиться от этого менее строгим. Однако следует заметить, что в R-системах невозможно однозначное сравнение между Ki и Kj поскольку в них могут существовать такие Ki и Kj что IS(Ki)!=IS(Kj) (поле или поля первичного ключа разных отношений могут иметь разный тип). Таким образом для создания общего адресного пространства в R-системе требуется введение другого условия IS(Ki) =IS(Kj).
Эти рассуждения приводят нас к введению в R-систему понятия RecID - идентификатора, позволяющего однозначно определить любой кортеж системы. Следует заметить, что поле содержащее RecID является ключевым для любой таблицы хотя может быть и не определено явно как ключ.
Введение RecID не представляет особой сложности. Смысл, однако, заключается не в самом RecID. Важным является возможность использовать его значение для инициализации ссылок (или указателей), которые позволяют другим частям системы обращаться к данному кортежу. Можно рассмотреть два случая:
- ссылочный элемент, содержащий RecID, является внешним ключом (здесь RecID должен являться первичным ключом некоторого отношения R). Следовательно этот элемент может ссылаться на кортежи только одного отношения (этого отношения R). Можно сказать, что здесь теряется смысл RecID, как элемента позволяющего идентифицировать любой кортеж любого отношения;
- ссылочный элемент не является внешним ключом. Конечно, этот элемент может ссылаться на любой кортеж, существующий в системе. Однако в данном случае отсутствует контроль ссылочной целостности, и возможно такая ситуация когда ссылка указывает на отсутствующий кортеж.
Применение наследования для отношений
Взглянем еще раз на рис.(1) описывающий пространство O-системы. Класс B является наследником класса А. Таким образом для операции IS(Bi) (где Вi - объект класса B) возможно два варианта правильного ответа - класс А и класс В. Можно сказать, что IS(Bi) = IS(Aj) в то время как IS(Ai)!=IS(Bj). Эта закономерность является следствием гибкости O-систем в их способности определять новые типы.
Применим к отношениям наследование и определим отношение Rn+1 как наследник Rn. Из этого следует что для кортежа Х относящемуся к Rn+1 действительным будет IS(X) = IS((Rn)X) и в в то же время IS((Rn)X)!=IS(X) где (Rn)X - кортеж Х представленный как кортеж отношения Rn или, говоря по другому, приведенный к базовому типу Rn. Тогда операции ADR(Х) возвратит пару (Rn+1, K) где K - ключ кортежа Х в адресном пространстве отношения Rn+1=IS(X). Соответственно ADR((Rn)Х) возвратит пару (Rn, K) где K - тот же самый (поскольку он наследуется) ключ в адресном пространстве отношения Rn=IS((Rn)X). Сравнение этих пар приведет к следующему выводу : ADR(Х) = ADR((Rn)Х) и в то же время ADR((Rn)Х)!=ADR(Х). Поскольку операция ADR определяется как операция однозначно определяющая элемент системы (т.е. ADR(Xi) !=ADR(Xj) (при Xi!=Xj) и ADR(Xi) =ADR(Xj) (при Xi = Xj) где Xi и Xj - элементы системы) данный вывод говорит о принципиальной невозможности применить к отношениям операцию наследования. Можно сказать, что элемент реляционной системы (кортеж) описываемый типом R, в связи с особенностями адресации (пара (R,K) ), может входят только в одно множество R которое определяется существованием данного типа (схемы отношения) R. Таким образом тип отношения и тип класса не могут быть одним же типом. Это является достаточным, для того что бы сказать, что реляционная и объектная модели являются разными моделями.
Однако, поскольку разные модели могут одновременно использоваться для описания одного и того же набора данных, можно предположить, что для этого могут использоваться реляционная и объектная модели. Для этого эти модели следуют рассматривать как ортогональные. И для того, что бы соотнести эти модели вспомним о том, что
Структуру любой сложности можно нормализовать
Блок информации любой сложности можно сохранить как набор записей различных таблиц.[2,1] Говоря по другому любой объект можно представить как набор кортежей различных отношений. Эта идея является основой проектирования реляционных БД и используется с момента их создания. По мнению автора именно эту идею нужно рассматривать как основу для создания системы объединяющей свойства объектных и реляционных систем. Причина, по которой существующие в настоящее время реляционные системы не обладают объектными свойствами заключаеться не в том, что эта идея является неверным. Она является неполной.
Для того чтобы понять что имеется в виду, вернемся к примеру с программой сохраняющей свои данные в ОЗУ. Мы можем сказать, что в ОЗУ может быть сохранена любая информация (во всяком случае до сих пор это удавалось). Соответсвенно информация о некотором моделируемом объекте (здесь мы исходим из того, что любая программа в той или иной мере является способом моделирования некой предметной области) представляет из себя некоторое множество элементов ОЗУ. Важным является тот факт, что это верно для любой программы, будь она написана на Си, FORTRAN или ассемблере (все эти языки используют разные парадигмы программирования и не являются объектными)- в любом случае некоторому моделируемому объекту можно поставить в соответствие некоторое множество элементов ОЗУ, сохраняющие данные о этом объекте. Преимущество объектных систем заключается в том, что только они позволяют явно поставить в соответсвие объекту моделируемой области ИДЕНТИФИЦИРУЕМЫЙ и ОСМЫСЛЕННЫЙ(или, по другому, ИМЕЮЩИЙ ОПРЕДЕЛЕННУЮ СТРУКТУРУ) набор элеметов ОЗУ, который также (в терминах О-систем) называется объектом.
Аналогичные рассуждения верны и для объекта, данные о котором необходимо сохранить в реляционной базе данных. Из того факта, что информация о объекте с произвольной внутренней структурой может быть сохранена в реляционной системе, необходимо сделать следующий вывод: любому объекту можно поставить в соответствие ИДЕНТИФИЦИРУЕМЫЙ и ОСМЫСЛЕННЫЙ набор кортежей.
Рассмотрим это положение по частям:
1) объект есть идентифицируемый набор кортежей. Набору кортежей содержащему данные о некотором объекте можно поставить в соответствие уникальный идентификатор, который фактически является объектным идентфикатором(OID), используя который мы можем обращаться к даному набору кортежей;
2) объект есть осмысленный набор кортежей. Объект описывается типом, каждому атрибуту которого ставиться я в соответствие определенное семантическое значение. Это семантическое значение определяет смысл кортежа в объекте и ,кроме того, позвляет обращаться к этому кортежу как к атрибуту объекта.
Очень важно понимать, что речь здесь идет о смысле, который присущ кортежу как атрибуту обьекта. Дело в том, что любой кортеж может обладать собственным смыслом, и этот смысл определяется отношением в которое этот кортеж входят. Кортеж сам по себе является семантически значимым набором данных. И этот осмысленный набор данных осмыслен также в контексте обьекта, атрибутом которого он является. В этом нет никакого противоречия. Рассмотрим следующий пример.
Некоторая организация занимается рассылкой корреспонденции. Для каждого клиента определен адрес, по которому эту корреспонденцию нужно высылать. Клиенты могут быть как юридическими, так и физическими лицами. В контракте на обслуживание юридических лиц необходимо указывать регистационную информацию, включающую юридический адрес. В контракте для физических лиц необходимо указывать их паспорные данные. Возможная иерархия классов в О-системе моделирующей деятельность фирмы выглядит следующим образом (в скобках указана сохраняемая информация):
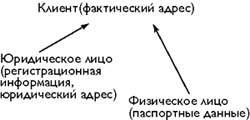 |
В каждый объект класса «Юридическое лицо» будет входит три набора данных, три поля, каждое из которых содержит определенную информацию об этом объекте: 1) фактический адрес 2) регистационная информация 3) юридический адрес. Каждый из этих наборов данных содержит информацию о их состоянии в процессе определенного взаимодействия с другими объектами окружающего мира, информацию определяющую возможность этого взаимодействия. Говоря по другому, каждый из этих наборов данных содержит информацию об одной из многих сущностей этого объекта.
Рассмотрим поля содержащие юридический и фактический адреса. В принципе, почтовая корреспонденция может быть послана по любому из этих адресов. Структура этих полей абсолютно одинакова. Эта структура определяется их собственным смыслом (т.е. их смыслом вне объекта, атрибутами которого являются эти поля), определяется их сущностью, которая может быть выражена словом «адрес». Информация содержащаяся в таких полях является достаточной для установления определенной связи (например почтовой) с содержащими их объектами. Чтобы послать письмо важно наличие у объекта-получателя поля с сущностью «адрес», а какой объект - человек или фирма - данным адресом идентифицируется, какой текст находится в письме, что представляет данный адрес в контексте объекта - вся эта информация совершенно неважна для того чтобы письмо было послано по почте объекту, которому этот адрес принадлежит. Разница между этими полями (в одном случае адрес является юридическим, в другом - фактическим) существует только если рассматривать их в контексте объекта. Именно класс определяет по какому из этих адресов письмо должно быть послано.
Обратим особое внимание на то, что вне контекста класса все информационное содержимое полей, имеющих сущность «адрес», определяется только содержащимися в них данными. Только эти данные являются существенными.[11] Из этого следует, что в сущности адрес имеет реляционную природу и может рассматриваться как схема соответсвующего отношения. Тоже можно сказать и про сущность «регистрационная информация».
Рассмотрим наш пример более формально. Существует класс A описывающий клиентов, которым надо рассылать корреспонденцию.. Этот класс включает поле X1 содержащее фактический адрес клиента; это поле является котрежом отношения ADDR соответствующего сущности «адрес». Существует производный класс В (фирма) включающий поле X2 (юридический адрес) являющееся кортежом того же отношения ADDR и поле Y1 являющегося кортежом другого отношения LegIn соответствующего сущности «регистрационная информация». Создадим объект ОА класса А идентифицируемый OID1 и объект ОВ класса В идентифицируемый OID2.
В нашем примере мы имеем дело и с классами (объектная модель) и с отношениями (реляционная модель). Поскольку объектная и реляционная модели могут рассмариваться только как ортогональные, этот пример может быть проиллюстрирован следующим образом (рис. 4)
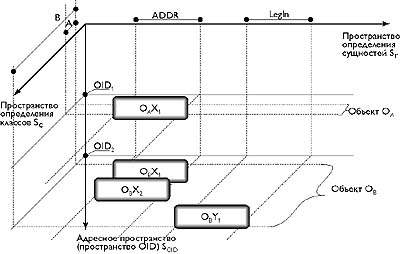 |
| Рис. 4. R*O-система |
Проекция этой системы (которая в силу отрогональности R- и O-компонентов автор называет R*O - системой) на плоскость (SC-SOID) дает следующую картину (рис.5)
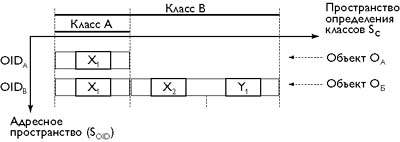 |
| Рис. 5. O-проекция R*O-системы |
(Еще раз необходимо повторить, что пространство определения объектных типов является сложным и многомерным. Однако в любом случае оно может рассматриваться как проекция пространства с большим числом измерений )
Видно что данная проекция является О - системой, где каждый ее элемент (т.е. один из кортежей содержащих информацию об объекте) может быть идентифицирован выражением вида { ( адрес объекта в системе).(положение элемента в схеме (т.е. в классе) описывающей данный объект) }. Поэтому для однозначного определения элементов для каждого из них должна поддерживаться следующая информация.
- OID объекта, к которому относится данный элемент.
- Информация о положении данного элемента в схеме описывающий класс, к которому данный обьект принадлежит. Каждому полю каждого класса можно поставить в соответствии идентификатор SID (Semantic ID) определяющий семантическое значение этого поля в контексте класса.
Именно эта информация является существенной для того чтобы кортеж мог рассматриваться как осмысленная часть идентифицируемого объекта.
Проекция R*O-системы на плоскость (SR-SOID) будет выглядеть следующим образом (рис.6)
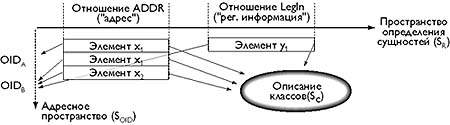 |
| Рис. 6. R-проекция R*O-системы |
Пунктирные стрелки показывают что:
- каждый элемент принадлежит к тому или иному объекту, имеющему соответствующим OID;
- каждый элемент описан как поле класса этого объекта - для каждого элемента существует SID.
Далее будет показано, что эта информация также может быть описана в терминах реляционной модели.
Таким образом реляционная и объектная системы могут быть рассмотрены как ортогональные проекции общей R*O-системы. Можно предположить, что свойства R*O-системы определяются произведением свойств ее проекций. Объект существующий в этой системе является идентифицируемым и осмысленным набором кортежей. Отношение является доменом атрибута скалярного(базового) типа.
Языковая конструкция
Тот факт, что R*O - система полностью описывается ее проекциями (реляционной и объектной), позволяет предположить, что язык используемый для описания системы должен объединять конструкции языка реляционных БД (например SQL) и O-языка (например Java или С++). Например следующая конструкция
CREATE TABLE ADDR
{
...
};
class Client
{
...
ADDR postaddress;
...
};
вводит в класс Client поле postaddress описывающее запись созданной ранее таблицы ADDR. Для каждого объекта данного класса существующего в системе, в таблице ADDR будет существовать запись, принадлежащая этому объекту, и имеющая семантическое значение postaddress. Такую запись можно назвать полем табличного типа или табличным атрибутом объекта. (Надо заметить, что объект может содержать кортежи любых, в том числе и производных отношений).
Подобный подход может представлять интерес, поскольку подразумевает неизменность исходных языковых конструкций и, вместе с тем, придает им новые возможности. В принципе, можно использовать языковые конструкции любых О- и R- языков. Отметим, что в данном случае SQL не является встроенным языком и, соответственно, О-язык не является базовым языком. Скорее О-язык можно рассматривать как расширение DDL SQL позволяющее объединить отдельные записи в виде сложных объектов.
Сущность «ОID».
Представим адресное пространство R*O-системы в виде отношения OIDs имеющего поле OID в качестве первичного ключа. Ранее отмечалось, что информация о OID является существенной для любого кортежа RxO системы. Поэтому любое отношение, содержащее информацию об объектах, должно иметь поле OID, которое должно быть объявлено как внешний ключ, ссылающийся на поле OID отношения OIDs. Данная связь определяет, атрибутами каких именно объектов являются определенные кортежи этих отношений . После этого проекцию SR-SA можно будет представить в следующем виде (рис.7)
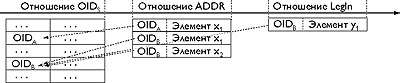 |
| Рис. 7. R-проекция после введения таблицы OID (классы на рисунке не представлены) |
Отношение OIDs фактически отражает наличие сущности являющейся общей и обязательной для любого объекта. Смысл данной сущности можно выразить выражением «идентифицируемый объект». Множество значений первичного ключа (поля OID) отношения OIDs фактически является адресным пространством O-проекции R*O-системы. Существование любого объекта системы определяется существованием кортежа отношения OIDs, содержащего уникальный OID этого объекта. Очевидно,что отношение OIDs может содержать и другую информацию, существенную для любого объекта системы. К информации такого рода относится информация определяющая класс объекта (СlassID).
Объектные типы (схемы классов)
Подробное рассмотрение возможных способов представления объектных типов в терминах R-системы не является целью данной статьи. Поэтому предлагаемую далее схему можно рассматривать только как пример описывающий принципы сохранения информации о классах в таблицах реляционной БД.
Рассмотрим два класса - A,В - где В наследуется от А. В пространстве определений типов O-системы данная ситуация выглядит следующим образом.
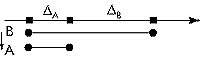 |
Обратим внимание на то, что отличает между собой типы А и В. Это некоторая разность ЖB = В - А. В данном случае ЖB означает, что множество имен атрибутов класса составляющих эту Ж впервые определено в типе В. Можно описать ЖA = A. С другой стороны A=ЖA, B = ЖA+ЖB(или B=A+ЖB что фактически описывает операцию наследования существующую в O-языках; возможен вариант описывающий множественное наследование B=A1+A2+...+Ak+ЖB).
Для того чтобы лучше описать структуру этих таблиц необходимо вернуться к рис.4 изображающему пространство R*O-системы (рис. 8).
Каждый класс может быть представлен как сумма Ж. В данном случае класс A = ЖA, а класс B = ЖA+ЖB. Ж-ы являются непересающимися подмножествами простанства определения типов классов. Каждая из этих Ж содержит именованные ( здесь: x1, x2, y1) поля различных сущностей ( здесь: сущности ADDR и LegIn).
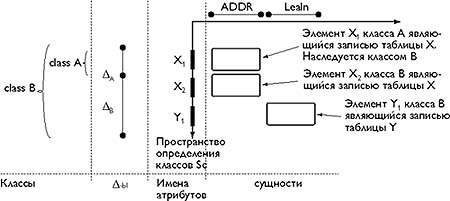 |
| Рис 8. проекция R*O-системы на плоскость SC-SR (Классы состоят из Ж являющихся набором имен сущностей) |
Вся эта информация может быть описана с помощью трех отношений.
1.CLASSES (табл.1) - определяет существующие в системе классы. Из того факта, что каждой Ж, существующей в системе, может быть поставлен в соответствие некоторый класс, в котором описываются поля входящие в эту Ж, следует что число классов равно числу Ж (и наоборот). Таким образом можно сказать, что отношение CLASSes описывает также все Ж которые существуют в данной системе.
2.DELTAS (табл.2) - содержит информацию о том из каких Ж состоит класс. Поскольку каждой существующей в системе Ж соответствует некоторый класс, данная таблица содержит также полную информацию о наследовании для всех существующих в системе классов.
3.ATTRIBUTES (табл.3) - содержит информацию обо всех существующих в системе атрибутах классов, опрелделяет в какие Ж и, соответственно, в какие классы эти атрибуты входит. Здесь каждому атрибуту любого из описанных в системе классов ставится в соответствие уникальный идентификатор SemanticID. Поскольку информация о семантическом значении (наравне с OID) является существенной для любого кортежа R*O-системы, содержащей пользовательские данные, каждый кортеж должен содержать поле SID, в котором это значение будет сохраняться. Это поле должно быть объявлено как внешний ключ ссылающийся на поле SemanticID таблицы SCHEME.
Отношения CLASSes, DELTAs и ATTRIBUTes, являющиеся фактически каталогом классов, вместе с полем SID, существующем во всех таблицах данных, являются механизмом, позволяющим определить семантическое значение (смысл) записи в контексте класса объекта, атрибутом которого эта запись является. Можно также предположить, что спроектированный соответствующим образом каталог классов может сохранять всю информацию о классах (константы, методы и т.д.).
После введения отношения OIDs и каталога классов R-проекция R*O-системы примет следующий вид (рис.9).
 |
| Рис. 9. R-проекция после введения отношения T_OID и каталога классов (на рисунке из каталога классов имеется только отношение ATTRIBUTes) |
Объекту R*O-системы, имеющего атрибут, являющийся кортежем отношения, тем самый присущ смысл характерный для данного отношения.
Пример: Если объект включает кортеж отношения адрес, то он является адресуемым объектом в самом что ни на есть бытовом смысле этого слова - ему можно направить почтовую корреспонденцию и определить его положение на карте
С другой стороны для каждого кортежа R*O системы определено его семантическое значение (смысл) в контексте содержащего его объекта. Это семантическое значение можно использовать для поиска и выборки информации.
Пример: мы можем получить информацию о фактических адресах клиентов или о юридических адресах фирм.
Важным является то, что семантическое значение наследуется. Операция поиска и выборки информации на основании семантического значения действует не только для класса, в котором это семантическое значение определено, но и для всех классов являющихся его наследниками.
Пример: Описав класс «Клиент» создадим запрос возвращающий информацию о фактических адресах клиентов.
SELECT ... FROM Client.postaddress
И, поскольку этот запрос основывается на наследуемом семантическом значении ( соответсвующем выражению « фактический адрес»), то он будет возвращать информацию о фактичеких адресах всех клиентов независимо от того, являются ли они физическими или юридическими лицами. Этот запрос будет работать независимо от наличия и количества классов производных от класса «Клиент» даже если на момент создания запроса эти классы еще не описаны.
Группы повторения
Более общим является случай когда отношение, входящие в R*O-систему, содержит произвольное количество кортежей имеющих одинаковые значения полей OID и значения полей SID. Эти записи представляют из себя множество полей идентифицируемого этим OID объекта, имеющими одинаковое семантическое значение SID в контексте класса данного объекта и, таким образом, являются группой повторения.[1]
class Client
{
...
ADDR [] otheraddresses;
...
};
В данном случае в каждом объекте класса Client может содержаться любое количество записей ранее созданной таблицы ADDR имеющих семантическое значение otheraddress. Отметим, что R*O не определяет какие-либо конструктивы позволяющие упорядочить элементы группы повторения - возможный порядок может определяться лишь информацией содержащейся в них:
ADDR [ORDER BY .../*имена атрибутов отношения ADDR*/...] otheraddresses
Связи и ссылки
Все связи имеющиеся в R*O-системе фактически являются связями между отношениями т.е . связями характерными для R-системы. Однако существует особый случай который описывает связи характерные для O-систем
Связи между объектами в O-системах осуществляются с помощью элементов специального типа, которые могут быть названы ссылками(или указателями). Понятие «ссылка» определяется и поддерживается системой; структура элемента имеющего тип «ссылка на объект определенного класса» не зависит от типа объекта на который данная ссылка указывает.
По сути дела ссылка определяет существование осмысленной связи между двумя идентифицируемыми объектами. В терминах R*O, где существование объекта определяеться существованием кортежа отношения OIDs, содержащим OID некоторого объекта, эта связь может быть описана парой значений OID. Одно значение соответствует содержащему эту ссылку объекту, второе определяет объект, на который первый объект ссылаеться. Кроме того, должно быть определено семантическое значение ссылки в контексте содержащего ее объекта. [2].
Исходя из этого, для описания и сохранения элементов ссылочного типа можно использовать специальное отношение LINKs (табл.4).
Отношение LINKs соответствует сущности, смысл которой можно выразить выражением «осмысленная связь между идентифицируемыми объектами».
В связи с тем, что поле refOID отношения LINKs является внешним ключом, связывающим эту отношние с отношением OIDs, кортеж этого отношения, а следовательно и объект, существование которых определено этим кортежем, невозможно удалить до тех пор, пока в системе будут присутствовать ссылки (кортежи отношения LINKs) на данный объект. Таким образом для поддержки O-ссылочной целостности в R*O-системе используются реляционные механизмы.
Пары значений OID и refOID некоторого кортежа отношения LINKs описывает соотношение «содержащий -включенный», существующее между двумя идентифицируемыми объектами системы. Следует отметить, что все пары OID и refOID, существующие в отношении LINKs, в целом описывают сложную неоднородную сетевую структуру переменной глубины, которая является следствием возможного существования в системе любого числа элементов любого числа полей любого числа ссылочных типов, описанных в любом числе классов. [2]
Однако наличие в этой таблице поля SID, определяющего семантическое значение ссылок в контексте содержащих их объектов, позволит определить для множества ссылок, имеющих одинаковое семантическое значение, правила, присущие связи, которая этим семантическим значением характеризуется.
Пример: предположим, что в системе должна сохраняться информация о людях (физических лицах) являющихся сотрудниками фирм (юридических лиц). Логично описать это, определив в классе «Фирма» множество ссылок на объекты класса «Человек» имеющих семантическое значение «сотрудник» = SIDX (это множество является группой повторения).
Class Person extended Client
{
....
}
Class Firm extended Client
{
Person [] emloyee;
...
}
Существует правило, согласно которому человек (объект идентифицируемый неким OIDY) может являться сотрудником только одной фирмы. Тогда в множества кортежей отношения LINKs (среди всех ссылок существующих в системе) не может существовать более одного кортежа со значениями поля SID = SIDX и поля refOID = OIDY.
Пример: предположим, что в системе должна сохраняться информация о родственных связях людей (имеется в виду связь «родитель - ребенок»). Логично описать эту связь, определив в классе «Человек» множество ссылок на объекты класса «Человек» имеющих семантическое значение «ребенок» = SIDК (это множество является группой повторения).
Class Person extended Client
{
Person [] children
....
}
Тогда множество кортежей отношения LINKs имеющих данное семантическое значение определяет существование однородной структуры переменной глубины, которая фактически описывает генеалогическое древо. Поскольку человек (объект идентифицируемый неким OIDМ) обязательно должен иметь двух родителей., в множества кортежей отношения LINKs (среди всех ссылок существующих в системе) должно существовать два кортежа со значениями поля SID = SIDK и поля refOID = OIDM.
R*O поддерживает ссылочные конструкции характерные для навигационного способа доступа к данным [14,22,25] присущего сетевым и иерархическим системам [2].
Пример (использует два предыдущих примера ) предположим, что необходимо получить информацию о детях сотрудников фирмы. Для этого логично использовать констукцию
... employee.children ...
которая является примером навигационного способа доступа к данным. В терминах R*O эта конструкция описывает реляционное соединение 2-х подмножеств кортежей отношения LINKs : 1) подмножество кортежей имеющих семантическое значение «сотрудник» (по полю refOID) с подмножеством кортежей имеющих семантическое значение «ребенок» (по полю OID).
Таким образом R*O позволяет представить ссылочные конструкции в терминах реляционных систем.
Триггеры R*O-системы
Триггеры являются ключевым механизмом реализации активности данных, и способом поддержания их целостности. [1]
Исходя из того, что каждый элемент R*O-системы:
- является кортежем некоторого отношения (имеет определенный реляционный смысл);
- принадлежит объекту (имеет смысл в контексте этого объекта) можно сказать, что реакция на изменения данных содержащихся в этом элементе должна состоять из двух частей. Эти части служат для описания правил;
- характерных для сущности, описывающей элемент (R-правила);
- характерных для объекта, которому элемент принадлежит (O-правила).
R-триггеры являются прямым аналогом триггеров реляционной БД. Эти триггеры являются способом поддержания закономерностей, присущих некоторой сущности.
Пример: Для сущности «АДРЕС» можно определить следующее правило: «Если страна - Россия, то вводимый ZIP-код (индекс), должен содержать шесть цифр». Данное правило должно выполняться для любого кортежа отношения «АДРЕС», вне зависимости от смысла, который данный кортеж имеет в контексте объекта
O-триггеры - действия происходящие в ответ на определенные изменения объекта и служащие для поддержания закономерностей присущих классу этого объекта. Объект в R*O-системе существует как набор записей различных таблиц. Изменение объекта есть изменение этих записей. В ответ на операцию производимую с записью и основываясь на семантическом значении SID, поддерживаемую для этой записи, система вызывает описанный в классе процедуру, которую можно рассматривать как триггер на определенное действие производимое с соответствующим полем. Этот триггер может быть назван семантическим триггером поля этого класса.
Семантические триггеры позволяют скрывать особенности и ограничения присущие полям, то есть фактически могут рассматриваться как один из механизмов инкапсуляции данных в объектах класса.
Пример: для атрибута содержащего физический адрес клиента можно определить следующее правило - «Физический адрес обязательно должен содержать индекс (ZIP-код)». Для юридического адреса, имеющего чисто формальное значение, индекс можно и не указывать.
Еще о триггерах
Триггеры реляционной БД должны выполнять код реализующий R- и O- правила. Однако эти триггеры могут контролировать не только данные объекта. Структура класса описывающего данный объект также налагает ограничения на возможные манипуляции с записями, из которых он состоит. Эти ограничения могут быть названы
S-правила (Structure)
Рассмотрим процесс создания объекта. Существование объекта любого класса определяется существованием кортежа отношения OIDs. Таким образом в процессе создание объекта в таблице OIDs должна появится запись, содержащая идентификатор вновь созданного объекта. Все остальные действия по созданию объекта могут выполняться триггером реляционной БД, определенным как триггер на добавление записей таблицы OIDs. В процессе выполнения этот триггер, на основании записей таблиц классов описывающих структуру класса создаваемого объекта производит добавление записей в таблицы сохраняющие данные этого объекта. Для каждой добавленной записи значение поля OID устанавливается равным значению поля OID создаваемого объекта. После этого триггер вызывает конструктор данного класса, производящий инициализацию созданного объекта. Схожим образом может быть реализован процесс уничтожения объекта. Также S-триггеры должны отвечать за поддержку стуктурной целостности объекта в процессе его существования.
Следует отметить, что именно каталог классов фактически является набором S-правил, а код содержащийся в триггере любой таблицы, служит лишь для проверки того, насколько выполняемое в текущий момент действие соответствует данному описанию. Поэтому этот код не зависит от таблицы и может генерироваться по умолчанию.
R*O и объектно-реляционная модель
Отметим, что основным предположением, на котором основываеться R*O является предположение об ортогональности объектной и реляционной моделей представления данных. Существующая объектно - реляционная модель также основывается на этой посылке. С точки зрения этой модели класс является доменом атрибута отношения. Следует отметить, что R*O не противоречит этому (это следует хотя бы из того, что в R*O определен специальный тип позволяющий сохранять OID объектов в реляционных кортежах). Более того - следует рассматривать это утверждение как равноправную составляющую R*O модели. Таким образом из ортогональности объектной и реляционной моделей данных следует два взаимодополняющих утверждениня:
- отношение является доменом атрибута скалярного(базового) типа класса;
- класс является доменом атрибута отношения.
Соблюдение этих принципов позволяет описать все существующие в системе данные в терминах как объектной так и реляционной моделей рассматривая объект как:
- осмысленную совокупность сущностей опредляющих его связи с другими объектами;
- носителя информации существенной для описания сущностей и связей между ними.
Заключение
Реляционная модель является моделью хранения данных. Существуют разные модели хранения данных. Например ОЗУ компьютера также описывается определенной моделью, однако никто не говорит о том, что эта модель противоречит (или не противоречит) модели данных используемой программой написанной на С++ и сохраняющей свои данные в ОЗУ в виде объектов. Конечно реляционная база данных является гораздо более сложным хранилищем данных чем оперативная память. Более того - реляционная модель обладает собственной семантикой - семантикой сущностей и связей между ними. Имеено наличие собственной семантики отличной от семантики O-систем (которая в первую очередь направлена на адекватное описание сложных структур) и требующей выполнения определенных условий является основным затруднением в объединение этих R- и O- систем. Предлагаемая R*O- система является попыткой преодоления данного затруднения.
Система, основанная на R*O-модели
- обеспечивает поддержку и хранение сложных объектов;
- дает возможность определять новые типы и расширять существующие, в т.ч. за счет множественного наследования. Наследуются не только объектные но и реляционные свойства;
- обеспечивает целостность объектных ссылок за счет реляционных механизмов;
- поддерживает нереляционные (сетевые и иерархические) структуры;
- позволяет создавать триггеры являющиеся механизмом инкапсуляции данных;
- для описания объектов системы могут использоваться существующие O-языки;
- являясь надмножеством R-систем может быть создана на основе существующих в настоящее время реляционных БД использующих SQL, который может быть расширен для реляционного доступа к объектам и их данным.
Евгений Григорьев (grg@comail.ru) — ИT-менеджер компании Intercosmetic.
1. Крис Дейт. Введение в базы данных. Изд. 6-е. Киев, «Диалектика», 1998.
2. Дж.Мартин.Организация баз данных в вычислительных системах. Изд. 2-е 1980 «Мир» (Москва)
3. А.В. Замулин Системы программирования баз данных и знаний 1990 Наука (Новосибирск)
4. Д. Мейер. Теория реляционных баз данных. 1984 «Мир» (Москва)
5. Гради Буч Объектно-ориентированое Проектирование с примерами применений 1992 Диалектика(Киев) & И.В.К. (Москва)
6. Х.Дарвин, К.Дэйт. Третий манифест. «СУБД» № 1/1996
7. М. Аткинсон, Ф. Бансилон, Д. ДеВитт, К. Диттрих, Д. Майер, С. Здоник. Манифест систем объектно-ориентированных баз данных. «СУБД» № 4/1995
8. Системы баз данных третьего поколения: Манифест. «СУБД» № 2 1995
9. C.J.Date. Persistence Not Orthogonal to Type. Database Programming & Design OnLine October 1998
10. C.J. Date. Encapsulation Is a Red Herring. DataBase Programming & Design OnLine September 1998
11. C.J. Date. An Analysis of Codd?s Contribution to the Great Debate Intelligent Enterprise. 1999 Vol. 2, No7
12. C.J. Date. The relational model will stand the test of time. Intelligent Enterprise, 1999, Vol. 2, No 8
13. C.J. Date. When?s an extension not an extension? Intelligent Enterprise, June 1, 1999, Volume 2, Number 8
14. Девид Васкевич Стратегии Клиент/Сервер 1996 Диалектика (Киев)
15. С.Д. Кузнецов. Третий манифест Кристофера Дейта и Хью Дарвена: предпосылки и обзор http://www.citforum.ru/database/digest/date_3m_1.shtml
16. В. Шринивасан, Д. Т. Чанг Долговременное хранение объектов в объектно-ориентированных приложениях. «Открытые системы» № 3/1999
17. С.Д. Кузнецов. Направления исследований в области управления базами данных: краткий обзор. «СУБД» № 1/1995
18. В. В. Пржиялковский Абстракции в проектировании БД. «СУБД» № 1-2/1998
19. В. В. Пржиялковский Новые одежды знакомых СУБД: Объектная реальность, данная нам «СУБД» № 4/1997
20. М.Р. Когаловский Абстракции и модели в системах баз данных «СУБД».№ 4-5/1998
21. Базы данных: достижения и перспективы на пороге 21-го столетия. Под ред. Ави Зильбершатца, Майка Стоунбрейкера и Джеффа Ульмана, «СУБД» № 3/1996
22. Ким Вон Технология объектно-ориентированных баз данных. Открытые системы № 4/1994
23. Михаэл Стоунбрейкер Объектно-реляционные системы баз данных. «Открытые системы» № 4/1994
24. А. Ю. Медников, А.Ю.Соловьев. Объектно-ориентированные базы данных сегодня или завтра? «Открытые системы» № 4/1994
25. Джим Грей. Управление данными. Прошлое настоящее и будущее. «СУБД» № 3/1998
| Столбец | Тип | Ключ | Описание |
| ClassID | TypeCID | Primary | Идентификатор класса ( и Ж) |
| ClassName | char[...] | Имя класса |
| Столбец | Тип | Ключ | Описание |
| ClassID | TypeCID | Primary, references CLASSes (ClassID) | Идентификатор класса |
| DeltaID | TypeCID | Primary, references CLASSes (ClassID) | Идентификатор Ж |
| Столбец | Тип | Ключ | Описание |
| SemanticID | TypeSID | Primary | Идентификатор элемента схемы классов |
| DeltaID | TypeCID | References CLASSes (ClassID) | Идентификатор Ж-ы содержащей его (так же можно рассматривать как идентификатор класса где описан этот атрибут) |
| Name | Char[...] | Имя поля | |
| TableName | Char[...] | Табличный тип данного поля (имя отношения кортежем которого это поле является) |
| Столбец | Тип | Ключ | Описание |
| OID | TypeOID | References (OIDs)OID | OID объекта, содержащего ссылку |
| SID | TypeSID | References (SCHEMA)SemanticID | SID, определяющий смысл ссылки в объекте |
| RefOID | TypeOID | References (OIDs)OID | OID объекта, на который указывает ссылка |
