
Объектно-ориентированные модели быстро завоевывают популярность у программистов. В большинстве приложений применяются данные, постоянно хранящиеся в памяти, поэтому реальную практическую пользу могут принести только те приложения, которые поддерживают такого рода объекты.
Для реализации этой поддержки предлагаются три класса решений. Первый подход предполагает поддержку долговременного хранения объектов при помощи шлюзов. То есть объектно-ориентированные приложения получают доступ к данным, постоянно находящимся в стандартном, не объектно-ориентированном хранилище. В другом подходе используется объектно-реляционные СУБД. Третий подход опирается на объектно-ориентированные СУБД, в данном случае возможность долговременного хранения объектов поддерживается в объектно-ориентированном языке программирования. Последний подход называется также поддержкой долговременного хранения в языке программирования. В этой статье будут рассмотрены вопросы выбора системы и метода поддержки долговременного хранения объектов для приложений разных типов. В разных продуктах предлагаются различные пользовательские интерфейсы и интерфейсы программирования, позволяющие создавать и манипулировать хранимыми объектами.
Кроме того, здесь будут описаны достоинства и недостатки ряда механизмов реализации долговременного хранения объектов, в том числе, требования, предъявляемые определенной реализацией, и ограничения, налагаемые каждым из трех подходов. В силу того, что некоторые приложения должны совместно использовать данные, будут рассмотрены способы взаимодействия таких приложений друг с другом. И, наконец, перечислены проблемы, вызванные тем, что разработанные в объектно-ориентированном стиле и унаследованные приложения обращаются к одним и тем же данным, а также приведены способы решения этих проблем.
Объектно-ориентированные модели, а также подходы к разработке архитектуры программ и программированию [1-5] быстро завоевывают популярность у большинства разработчиков современных приложений. В большинстве их применяются данные, постоянно хранящиеся в памяти, поэтому реальную практическую пользу могут принести только те приложения, которые поддерживают такого рода объекты. До появления подобных приложений в большинстве разработок для организации долговременного хранения данных использовались реляционные СУБД. (Этот метод широко используется и сейчас.)
Реляционные СУБД, как правило, применяются для хранения данных в традиционных бизнес-приложениях, таких как поддержка банковских транзакций и управление складским хозяйством. Реляционная модель [6] положена в основу многих коммерческих СУБД (например, DB2, Informix, Oracle, Sybase), а язык SQL [7] стал, по существу, широко распространенным стандартом как для извлечения, так и для обновления данных. Основа реляционной модели очень проста — данные представляются как таблицы, состоящие из строк и столбцов. Список типов хранимых данных ограничивается несколькими базовыми типами: целые, символьные и десятичные, а также включает в себя некоторые специальные, например, BLOB (большие двоичные объекты). Расширение системы типов путем добавления новых типов данных, как правило, невозможно. Поддерживаются отношения в форме, предполагающей, что столбцы могут состоять только из атомарных объектов, то есть не могут содержать множеств, списков или таблиц. Реляционные СУБД завоевали огромную популярность. Эти системы как нельзя лучше отвечают требованиям целого класса задач, с простыми моделями данных и обработкой большого объема запросов. Использование стандартного декларативного языка обработки запросов SQL дало разработчикам возможность реализовать прозрачный доступ к реляционным базам данных различных производителей.
В противоположность простым моделям данных, используемым традиционными бизнес-приложениями, основанными на реляционных СУБД, в объектно-ориентированных приложениях активно применяются многочисленные сугубо объектные механизмы, такие как расширяемые пользователем типы данных, инкапсуляция, наследование, динамическое связывание методов, сложные и составные объекты, идентичность объектов. Таким образом, становится необходимым преодолеть ограничения реляционных СУБД для того, чтобы создавать более сложные приложения. Многие разработчики предложили решения по реализации долговременного хранения. К настоящему времени сложились три основных подхода к поддержке долговременного хранения объектов: подходы, предполагающие использование шлюзов, использование объектно-реляционных СУБД и использование объектно-ориентированных СУБД. Последний подход называют иначе поддержкой долговременного хранения в языке программирования. Каждый из них обязан своим возникновением поддержке определенного класса приложений, поэтому на каждый наложили свой отпечаток тех требований, на соответствие которым он был ориентирован. Далее в статье будет приведен обзор трех подходов поддержки долговременного хранения объектов.
Подход к поддержке долговременного хранения объектов на базе шлюзов (Gateway-based object persistence, GOP) дает возможность использовать объектно-ориентированную модель программирования и в то же время использовать традиционные, не объектно-ориентированные хранилища для организации хранения объектов. GOP, как правило, используется в тех случаях, когда пользователям требуется написать приложение «поверх» уже существующего хранилища, применяя, однако, объектно-ориентированную модель программирования. Объекты приложения имеют иную модель данных, нежели хранилище, которое, собственно, и применяется для долговременного хранения объектов. Поэтому системы GOP должны обеспечивать соответствие объектно-ориентированной схемы приложения и не объектно-ориентированной схемы хранения данных, которая используется при размещении данных в памяти. Во время выполнения приложения эти системы переводят объекты из представления, применяемого в хранилище, в представление, применяемое в приложении, и наоборот. Для простоты использования системы GOP делают процесс такого преобразования прозрачным для программиста, разрабатывающего приложение. Поддержка долговременного хранения реализована в нескольких системах, в том числе, VisualAge C++ Data Access Builder, SMRC [8], ObjectStore Gateway, Persistence, UniSQL/M, Gemstone/Gateway и Subtleware/SQL. Этот подход представляет собой ни что иное, как использование ПО промежуточного слоя, не зависящего ни от приложений, ни от данных.
Работу по стандартизации GOP выполнил консорциум Object Management Group, основанный в 1989 году для придания официального статуса сложившимся де-факто стандартам распределенных объектов. Наиболее важной из принятых ею спецификаций стала архитектура CORBA, которая определяет фундаментальную архитектуру взаимодействия объектов. Независимо от CORBA были одобрены спецификации, напрямую связанные с долговременным хранением объектов: Persistent Object Service, Object Query Service, Object Relationships Service, Object Transaction Service и Object Security Service.
Идея объектно-реляционных СУБД (ОРСУБД) опирается на предположение, что наилучший способ удовлетворить требования объектно-ориентированных приложений — расширить реляционную модель. Реляционная модель убедительно доказала свою состоятельность, а SQL, по существу, стал мировым стандартом. Поэтому, объектно-реляционные СУБД добавляют поддержку объектно-ориентированных моделей данных за счет расширения реляционной модели данных и языка запросов, сохраняя в относительной неприкосновенности популярные технологии реляционной СУБД.
На рынке представлены два класса объектно-реляционных СУБД: построенные посредством «скрещивания» различных продуктов (например, Informix), и те, что были (или будут) созданы за счет расширения существующих реляционных СУБД.
Такой подход служит примером восходящего метода разработки, он ориентирован на данные (или базы данных).
Как и следовало ожидать, вся деятельность по стандартизации в этой области разворачивается вокруг расширения стандарта SQL. Комитет X3H2 (он отвечает за спецификации, связанные со стандартом SQL) работает над объектными расширениями SQL, начиная с 1991 года. Эти расширения стали частью нового проекта стандарта SQL, получившего известность под условным названием SQL3 [10].
Принципиально иная идея положена в основу объектно-ориентированных СУБД (ООСУБД). Она состоит в том, что лучший способ обеспечить возможность долговременного хранения объектов — это реализовать долговременное хранение объектов, используемых в объектно-ориентированных языках программирования (object-oriented programming language, OOPL), таких как Си++ или Smalltalk. Так как ООСУБД, можно сказать, уходят корнями в объектно-ориентированные языки программирования, то их часто называют системами долговременного хранения на базе языков программирования. Однако объектно-ориентированные СУБД — это нечто больше, чем язык программирования с добавленными возможностями долговременного хранения. Исторически сложилось так, что объектно-ориентированные СУБД создавались в расчете на рынок приложений САПР, где крайне важны такие функции, как быстрый доступ с возможностями навигации, поддержка версий и обработка транзакций, предполагающих выполнение последовательности операций в базе данных. Объектно-ориентированные СУБД поддерживают приложения, обладающие такими возможностями, как поддержка долговременного хранения объектов, созданных в разных языках программирования, распределение данных, улучшенные модели обработки транзакций, поддержка версий, динамическая генерация новых типов. Но даже несмотря на подобное разнообразие, очень немногие из этих возможностей имеют реальную объектную ориентацию, которая, получает дополнительное «подкрепление» в системах с объектно-ориентированными СУБД и приложениях для них. На рынке представлено несколько объектно-ориентированных СУБД (например, Gemstone, Objectivity/DB, ObjectStore, Ontos, O2, Itasca, Matisse). Это пример нисходящего подхода, ориентированного на приложения (или язык программирования).
Стандарт на ООСУБД выработан консорциумом Object Database Management Group (ODMG), состоящим в основном их производителей таких СУБД. ODMG выработала стандарт ODMG-93, который опубликован в [11]. ODMG-93 определяет характер языков Object Definition Language, Object Query Language, а также отображения Си++ и Smalltalk на ODL и OQL. Консорциум работает над отображением языка Java на ODL и OQL.
Оставшаяся часть статьи подразделена на три больших раздела: модели данных, доступ к данным и совместное использование данных.
В разделе моделей будут рассмотрены различные механизмы языков программирования, используемые при объектно-ориентированной разработке. В разделе, посвященном доступу к данным, внимание будет уделено созданию и организации доступа к хранимым данным. И, наконец, в разделе совместного использования данных, будут изучены вопросы совместного использования долговременно хранимых данных. Во всех трех разделах будут представлены различные специальные функции, кроме того, проведено сравнение трех подходов к поддержке долговременного хранения данных (GOP, ОРСУБД и ООСУБД). Для лучшего понимания этих вопросов во всех разделах подготовлены таблицы, в которые сведены основные выводы.
Модели данных
В приложениях, которые написаны на существующих объектно-ориентированных языках программирования, например, Си++ и Smalltalk, используется целый ряд объектно-ориентированных механизмов, таких как инкапсуляция, наследование и динамическое связывание. Предполагается, что читатель с ними знаком. Хотя объектно-ориентированные СУБД могут и не поддерживать все функции, предлагаемые «истинными» объектно-ориентированными языками программирования, поддерживаемые ими модели данных значительно сложнее моделей данных, поддерживаемых традиционными реляционными СУБД. Объектно-реляционные СУБД сейчас только начинают поддерживать многие из этих возможностей.
Табл. 1. Модели данных
| Функция | Долговременное хранение объектов GOP | Объектно-реляционные СУБД (ОРСУБД) | Объектно-ориентированные СУБД (ООСУБД) |
| Идентичность объектов (OID) | Ограниченная поддержка за счет возможностей средствами | Ограниченная поддержка базы данных идентификации строк | Поддерживается |
| Сложные объекты (содержащие данные не в первой нормальной форме) | Можно реализовать поддержку за счет отображения схем | Поддерживаются расширения реляционной модели данных | Поддерживается |
| Составные объекты (формирование групп объектов для копирования, удаления и т. д.) | Можно реализовать поддержку за счет отображения схем (возможны ограничения) | Ограниченная поддержка при помощи комбинации триггеров, абстрактных типов данныхи наборов типов | Поддерживается с использованием библиотек классов |
| Отношения | Могут поддерживаться при помощи отображения схем и генерации кодов | Возможна полная поддержка, включая поддержку ссылочной целостности | Поддерживаетсяс использованием библиотек классов |
| Инкапсуляция | Поддерживается на уровне приложений, но не баз данных | Поддерживается использованием абстрактных | Поддерживается,но цепочки символов остаются неинкапсулированными |
| Наследование | Могут поддерживаться при помощи отображения схем (однако возможны технические ограничения) | Будет поддерживаться (отдельное наследование для таблиц и абстрактных типов данных | Поддерживается как в языках объектно-ориентированного программирования (OOPL) |
| Переопределение, совмещение и динамическое распределение методов | Поддерживается как в OOPL | Поддерживается | Поддерживается как в OOPL |
Одна из основных трудностей, с которой справляются объектно-ориентированные СУБД за счет поддержки моделей данных объектно-ориентированных языков программирования — это проблема, название которой можно перевести как импеданс (или расхождение) моделей [13]. Она выражается в том, что модель данных, используемая в приложении, отличается от модели данных базы данных. Это различие, в свою очередь, приводит к двум проблемам в приложениях, в результате которых и возникает расхождение:
- Программист, разрабатывающий приложение, должен оперировать двумя различными языками программирования, с различным синтаксисом, семантикой и типами систем, а именно, прикладным языком программирования (например, Си++ или объектное расширение Кобола) и языком манипулирования базами данных (то есть, SQL). Логика приложения реализуется средствами прикладного языка, в то время как SQL используется для создания и манипулирования данными в базе.
- При извлечении данных из реляционной базы, они должны быть переведены из представления, в котором они там хранились, в представление, соответствующее представлению данных в памяти, характерному для данного приложения. Аналогично, все обновления данных должны быть переданы базе данных при помощи другого предложения SQL, то есть требуется еще одно преобразование из представления, используемого в приложении, в представление базы данных. Весь обмен данными между базой данных и приложением приводит к ненужной дополнительной обработке, которой можно было бы избежать, будь модели данных приложения и базы данных одинаковыми.
ООСУБД устраняют это расхождение благодаря поддержке моделей данных, используемых в одном или нескольких объектно-ориентированных языках программирования. Поэтому, в ООСУБД модель данных, используемая приложением, идентична той модели, которая используется СУБД для хранения данных. Наиболее успешно ООСУБД справляется со второй проблемой, несколько хуже — с первой, особенно когда используются запросы в терминах объектов.
В ОРСУБД расхождение моделей также частично устранено благодаря наличию средств для создания моделей данных, соответствующих основным объектно-ориентированным языкам программирования. Однако модели данных, используемые приложениями, могут быть близки, но не идентичны моделям тех баз, где данные хранятся. Иными словами, ОРСУБД менее успешно решает вторую проблему, но значительно лучше разрешает первую, особенно при выполнении объектных запросов.
ОРСУБД могут в значительной степени смягчить вторую проблему, обеспечивая выполнение значительных фрагментов приложения сервером баз данных. Такая поддержка, как правило, обеспечивается за счет расширения свойственной РСУБД поддержки хранимых процедур поддержкой методов и других объектно-ориентированных механизмов.
Поддержка долговременного хранения объектов на базе шлюзов (GOP) призвана устранить расхождение с помощью инструментария отображения схем и автоматической генерации кода. При этом подходе у пользователя должна сложиться иллюзия использования только одной модели -модели данных приложения. (Исключение составляют те пользователи, которые и определяют соответствие модели данных используемой в приложении, и используемой в СУБД.) У пользователя создается представление, что применяется объектно-ориентированная СУБД, таким образом первая проблема решается просто. Кроме того, GOP предоставляет средства автоматизации и оптимизации требуемых преобразований, что частично снимает вторую проблему.
Как и следовало ожидать, поддержка объектно-ориентированной модели данных предполагает решение нескольких сложных задач
Идентичность объектовИдентичность объектов — это одна из основных задач, которую приходится решать при реализации долговременного хранения объектов. Если программа выполняется в рамках отдельного процесса, объекты могут создаваться, копироваться, уничтожаться, к тому же к ним может предоставляться доступ. Поскольку никакой из этих промежуточных объектов не существует дольше, чем существует сам процесс, в качестве идентификатора (ID) объекта (OID) в рамках процесса может использоваться его адрес в виртуальной памяти. В СУБД OID, как и данные, должны храниться постоянно. OID по определению соответствует только одному объекту в базе данных. Ссылка в приложении на тот же OID объекта и на другой объект в базе данных означает ссылку на идентичные объекты.
В СУБД, отличных от объектно-ориентированных, также приходится решать проблему идентичности объектов (или идентичности записей), но здесь она, как правило, сводится к идентичности значений. Реляционные СУБД обычно поддерживают доступ к долговременно хранимым данным по значению. Это значит, что если в приложении требуется доступ к определенной строке базы данных, необходимо составить запрос с указанием имени отношения, в котором находится эта строка, и значения первичного ключа, равного значению первичного ключа этой строки таблицы. Использование только такой формы доступа к долговременно хранимым данным в объектно-ориентированных приложениях даст некорректный результат, поскольку объекты могут иметь идентичные значение, но быть при этом различными объектами. Связано это с тем, что объектно-ориентированные приложения поддерживают значения, которые могут быть составными объектами, то есть один объект может содержать другой объект. Например, два служащих могут иметь автомобиль одного производителя, одной модели и года производства, однако, очевидно, что соответствующий объект автомобиль не может иметь статус разделяемого между двумя владельцами. То есть, в каждом объекте служащий будет объект автомобиль, полностью идентичный по значению аналогичному объекту другого служащего. Должен поддерживаться прямой доступ к OID объекта в базе данных.
В среде GOP, где превалируют распределенные и гетерогенные системы, трудно ожидать или требовать одинакового представления OID. Поддержка идентичности объектов в GOP должна быть ограничена возможностями файловой системы или базы данных (например, реляционной, сетевой, плоскими файлами), где хранятся соответствующие данные.
Некоторые ОРСУБД начинают поддерживать OID наряду с традиционной поддержкой идентичности на базе значений. В качестве одного из методов поддержки OID здесь используется создание ID для каждой записи базы данных, независимо от значений этой записи. После этого, можно организовать доступ к каждой записи объектно-реляционной базы данных при помощи ID.
Лучше всего поддержка OID реализована в ООСУБД. В СУБД ObjectStore [14], например, в качестве эквивалента OID можно рассматривать ссылки базы данных. Приложение просто должно предоставить ссылку, после чего база данных, к которой относится ссылка, автоматически выделяет и выдает искомый объект. Возможно, однако, что объект более не существует, и поиск объекта средствами ссылок базы данных в ObjectStore может привести к ошибочному результату. Другие ООСУБД также обеспечивают поддержку OID подобным, но не идентичным способом.
Сложные объектыМеханизм поддержки сложных объектов позволяет объектам содержать атрибуты, которые сами также являются объектами. Иными словами, схема объекта не находится в первой нормальной форме, в отличие от реляционных таблиц (что означает, что их компоненты, или столбцы, сми могут иметь только базовый тип, например, целый, символьный или BLOB). Экземпляры атрибутов могут образовывать сложные объекты, в том числе списки, наборы и вложенные объекты. Вот пример определения сложного объекта в C++-подобном синтаксисе:
class Person {
char *name;
int age;
Car car;
Set children;
List phones;
Set same_age;
}В приведенном примере, экземпляром класса Person является сложный объект, который содержит два основных атрибута (имя и возраст), встроенный объект Car (автомобиль), множество объектов Person, список символьных строк (телефоны) и другое множество объектов Person, причем все объекты — встроенные.
Поддержка сложных объектов крайне важна для моделирования схем, типичных для большинства объектно-ориентированных приложений. Объекты, которые определяются внутри других объектов (например, атрибут Car внутри класса Person), целиком входят в содержащий их объект — компоненты сложных объектов автоматически создаются (рекурсивно) при создании объекта верхнего уровня и автоматически уничтожаются при его уничтожении. Связь между сложным объектом и его компонентом действительна всегда, и ее нельзя устранить.
В системах GOP необходимо реализовать отображение сложных объектов модели данных приложения на данные в хранилище. Любое отображение, как правило, сопровождается генерацией ориентированного на приложение кода, которые осуществляет взаимные преобразования моделей данных приложения и базы данных. Такие отображения оказываются весьма неэффективными, если база данных не имеет возможностей хранения сложных объектов. Рассмотрим, например, два следующих решения для хранения массива фиксированной длины для сложного объекта в реляционной СУБД:
- Элементы массива хранятся в наборе, где один столбец соответствует каждому элементу массива (для каждого элемента потребуются несколько столбцов, если элемент массива сам является сложным объектом).
- Элемент массива хранится в отдельной таблице, каждый набор которой хранит один элемент массива с индексом этого элемента в массиве.
Очевидно, ни одно из этих решений не отличается высокой эффективностью (и не работает вообще, для всех массивов переменной длины). Другое решение предполагает использование для хранения сложного объекта поля BLOB.
ОРСУБД предоставляет расширения реляционной модели данных, обеспечивающие поддержку данных не в первой нормальной форме, таких как списки, наборы, множества и т. д. Эти расширения модели данных используются затем для определения сложных объектов в приложении.
ООСУБД исключительно сильны в поддержке сложных объектов, так как они основаны на объектно-ориентированных языках программирования, которые обладают расширенными возможностями определения сложных объектов в модели данных.
Составные объектыСоставные объекты — это независимые объекты, находящиеся между собой в определенной взаимосвязи и потому образующие некоторую группу. Как правило, составные объекты используются в приложениях как группы объектов, которые являются частью родительского объекта, который, в свою очередь, является обычно набором. Составной объект представляет собой объект, который может обрабатываться как принадлежащий некоему определенному объекту, но на который другие объекты могут указывать обычным способом. Объект-владелец может указывать на подчиненный объект специальным указателем.
Приведем пример приложения, в котором требуется поддержка составного объекта. Объект «автомобиль» может состоять из других объектов, таких как «двигатель», «сцепление», «колеса», «кузов» и так далее. Вполне возможно, что при разработке новых моделей, двигатель (а, следовательно, и объект «двигатель») остается неизменным, в то время как другие элементы, например кузов, меняются от модели к модели. В этом случае, некоторые элементы объекта «автомобиль» и его компонентов необходимо обрабатывать как единую сущность, одновременно обеспечивая возможность совместного использования других составляющих объектов в другими объектами — проектами других автомобилей.
Пример определения составного объекта выглядит следующим образом.
class Car{
char *name;
char *model;
Ref engine;
CompositeRef body;
...
}С проблемой составных объектов связан вопрос каскадов удаления и копирования. В определенных приложениях при удалении составного объекта, составлявшие его компоненты оставляются для возможного использования в других объектах, что для рассматриваемого примера может интерпретироваться как использование двигателя снятой с продажи модели автомобиля в новой машине. При копировании объектов обязательно копировать все компоненты, входящие в его состав. Другими словами, в то время как каскадирование удаления может быть необязательным, каскадирование копирования (называемое также глубоким копированием) совершенно необходимо. Такие свойства необходимо определять, используя свойства составных объектов.
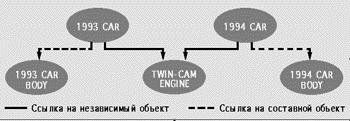 |
| Рис. 1. |
В системах GOP поддержка составных объектов осуществляется за счет сочетания отображения схем и генерации кода, ориентированного на приложение. Однако поскольку системы GOP зависят от базы данных, где хранятся данные, они могут накладывать ограничения на поддержку (например, кластеризация на объектном уровне может быть невозможной в хранилище, в результате чего нельзя будет поддерживать подобную возможность и для составных данных).
ОРСУБД предлагают поддержку составных объектов, используя для этого комбинации триггеров, абстрактные типы данных и составные типы. В то время как каскадирование удаления и копирования реализовать довольно просто, неясно, как ОРСУБД будут поддерживать кластеризацию компонентов составных объектов. Это связано с тем, что не все такие системы в состоянии поддерживать кластеры строк различных таблиц на одной и той же дисковой странице.
Составные объекты поддерживаются не всеми ООСУБД. В ObjectStore, к примеру, реализована полная поддержка составных объектов. В Versant расширение класса можно рассматривать как составной объект, в котором собраны все экземпляры класса. Удаление объекта автоматически приведет к удалению их из расширения класса. В результате определения расширения для класса удаляются все экземпляры класса.
ОтношенияОтношения — это обобщение ограничений ссылочной целостности в реляционный СУБД, где конкретный внешний ключ указывает на первичный ключ, и это отношение автоматически поддерживается базой данных. Отношения в СУБД представляют собой ссылки между объектами в базе данных; удаление передается автоматически, задание одной «стороны» равноправного отношения приводит к автоматическому формированию другой «стороны» и при удалении точки входа с одной «стороны» также приводит к автоматическому удалению противоположной точки входа в другой (то есть, поддерживается ссылочная целостность).
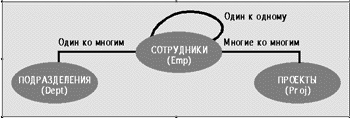 |
| Рис. 2. |
На рис. 2 приведен пример трех типов отношений, которые наиболее часто встречаются в приложениях. В первом отношения «сотрудников» (представленных классом Emp) могут устанавливаться через отношение, являющегося примером отношения «один к одному». Кроме того, «сотрудники» находятся в определенном отношении к «подразделениям» (представленным классам Dept). Это отношение является отношением типа «один ко многим», то есть каждый сотрудник может работать только в одном подразделении, в то время как в подразделении может быть много сотрудников. И, наконец, сотрудники работают над «проектами» (представленными классом Proj), что иллюстрирует отношение «многие ко многим», то есть сотрудник может работать над несколькими проектами и над проектом может трудиться несколько сотрудников.
В системах GOP подобные отношения поддерживаются на уровне приложений путем комбинации отображения схем и генерации соответствующих запросов во время выполнения. Отношения, реализованные на уровне приложений, нужно отобразить на базу данных, используя средства базы, такие как первичные ключи, внешние ключи и идентификаторы записей. Это накладывает определенные ограничения на возможности этой модели, и особенно влияет на производительность, поскольку извлечение взаимосвязанных объектов может потребовать выполнения многочисленных сложных запросов с операциями объединения к традиционным реляционным базам данных. Спецификация OMG Relationships Service описывает также отношения, в которых могут находиться несколько объектов (более двух), для чего требуется специальный объект, описывающий отношения.
Объектно-реляционные системы обеспечивают полную поддержку отношений. Идентификаторы записей и наборов в ОРСУБД, наряду с гарантией ссылочной целостности, могут быть использованы для полной поддержки отношений.
Поскольку ООСУБД допускает использование списков и множеств внутри объектов, эти отношения могут быть реализованы между объектами со встроенными наборами указателей для хранения связей. Далее будут приведены описания схем с использованием языка ODL стандарта ODMG [11].
В разных ООСУБД используются различные вариации приведенного синтаксиса для определения таких схем.
class Emp {
Ref dept
inverse emps_in_dept;
List> projects
inverse emps_in_proj;
Ref spouse
inverse spouse;
...
}
class Dept {
Set> emps_in_dept
inverse dept;
...
}
class Proj {
Set> emps_in_proj
inverse projects;
...
}Поддержка «ненормализованных» объектов в ООСУБД делает представление отношений «многие ко многим» более компактным, чем в аналогичной реляционной схеме. Так, например, в реляционной схеме требуются промежуточные таблицы для моделирования отношений «многие-ко-многим», например, между сотрудниками и проектами.
ИнкапсуляцияПредставление об инкапсуляции с точки зрения языка программирования принципиально отличается от метода доступа к ADT (абстрактным типам данных), который называется наследованием, и внутренней структуры данных, используемой для реализации ADT. Наследование ADT доступно пользователям ADT и не изменяется при любых изменениях внутренней структуры ADT. Этот подход называют иногда процедурной инкапсуляцией. В объектно-ориентированных языках программирования под ADT, как правило, понимают класс, а под интерфейсом набор публичных методов. Например, стек ADT может иметь методы push(elemtype), empty(), pop(), и стек сам по себе может быть реализован как массив фиксированной длины. Впоследствии, если будет принято решение изменить реализацию стека для использования структуры данных, отличающейся большим динамизмом, например, связанный список, никакие из приложений в стеке менять не потребуется (в некоторых случаях, приложения потребуется только перекомпилировать).
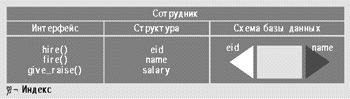 |
| Рис. 3. |
Для реализации долговременного хранения объектов, требуется еще один уровень реализации, дополнительно к интерфейсу и внутренней структуре, которые предусмотрены для ADT в языках программирования. Речь идет о физической реализации базы данных. Физическая реализация базы данных определяет (1) отсортированы ли хранящиеся данные по первичному ключу или хранятся в неупорядоченном виде; (2) первичные и вторичные индексы доступны для доступа к данным; (3) каковы стратегии кластеризации (например, объект Department может храниться в виде физического кластера со всеми объектами Employee, которые принадлежат этому объекту Department). На рис. 3 класс Employee имеет интерфейс к трем методам hire(), fire() и give_raise(). Структура данных каждого объекта Employee представляет собой запись с тремя полями, а именно, eid, name и salary. Физическая база данных состоит из объектов Employee, хранящихся в виде файлов отсортированных по eid и проиндексированных двумя индексами — один eid (первичный кластеризованный индекс) и name (вторичный, некластеризованный индекс).
Инкапсуляция в системах GOP поддерживается на уровне приложений, но не в модели данных, которая используется для хранения данных в нижележащем хранилище. Для объектов, инкапсулированных в приложении, требуется применить механизм преобразования, которые опирается на отображение схем и генерацию библиотек кодов, ориентированных на приложение. Такая схема отличается исключительной гибкостью, поскольку различные приложения могут использовать одни и те же данные и различные правила инкапсуляции.
ОРСУБД поддерживает инкапсуляцию при помощи ADT. Объекты самих таблиц не являются инкапсулированными, поскольку объектно-реляционные системы («обратно») совместимы с реляционными моделями. Схема таблицы используется в запросах SQL, поэтому инкапсуляция не имеет здесь никакого значения.
ООСУБД отклоняются от строгой процедурной инкапсуляции ADT, поддерживаемой языками программирования, и допускают иногда прямой доступ к структурам классов в обход методов. Нарушение правил инкапсуляции, как правило, выполняется в ООСУБД для обработки незапланированных запросов. Обращение к классу только через метод может оказаться неэффективным, а иногда и привести к неадекватному результату, если для получения требуемого ответа не предусмотрено метода. Запрос можно рассматривать как динамически определяемую процедуру, используемую для получения ответа путем просмотра внутренней структуры одного или более классов объектов. Незапланированные запросы рассматриваются более подробно в последующих разделах.
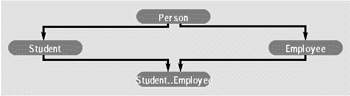 |
| Рис. 4. |
Наследование. Наследование часто используется в объектно-ориентированных системах для уточнения ранее определенных явлений. Например, в университетской базе данных может быть использована иерархия наследования, приведенная на рис. 4. Наследование, которое само по себе является мощным средством моделирования, в сочетании в инкапсуляцией позволяет выстраивать сложные иерархии классов. Известны несколько типов наследования, используемых в различных языках программирования, и это накладывает свой отпечаток на ООСУБД. Здесь описаны два основных типа наследования, а именно, наследование на основе операций, и структурное наследование.
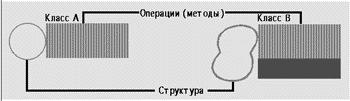 |
| Рис. 5. |
В случае наследования на основе операций, говорят, что класс В наследует классу А (или, что то же самое, класс В является подклассом или подтипом класса А), если для каждого (публичного) метода в классе А существует метод в классе В с идентичным интерфейсом. Другими словами, для вызова метода экземпляры класса А могут быть заменены экземплярами класса В. Наследование на основе операций проиллюстрировано на рис. 5. Следует заметить, что структуры класса А и класса В полностью различны, но это не влияет на то, что класс В является подклассом А. Примером языка, где реализовано наследование на основе операций служит Smalltalk.
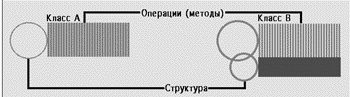 |
| Рис. 6. |
При структурном наследовании говорят, что класс В наследует классу А, если для каждого (публичного) метода в классе А существует эквивалентный (публичный) метод в классе В с идентичным интерфейсом, и класс В является подмножеством класса А. Другими словами, экземпляр класса А может быть заменен экземпляром класса В для доступа к структурированной информации А в дополнение к вызову метода. Структурное наследование проиллюстрировано на рис. 6. Структурное наследование накладывает больше ограничений, чем наследование на базе операций. Примером языка, поддерживающего структурное наследование, служит C++.
Разработчикам приложений, которые добиваются возможности работы на нескольких платформах, следует иметь в виду, что для приложений, где используется структурное наследование не так легко добиться переносимости и расширяемости, нежели для приложений, использующих только наследование на основе операций. Объектная модель IBM SOM [15], которую можно использовать для разработки единого приложения, выполняющегося на множестве платформ, поддерживает только наследование на основе операций. Преимуществом структурного наследования является компактность объектов, а также то, что большинство вызовов методов могут быть передаваться во время компиляции. Это оказывается весьма эффективным. Наследование на основе операций требует больше работы (такой как просмотр методов и проверки целостности) во время исполнения, что замедляет обработку приложений, что может оказаться весьма ощутимым, если осуществляется доступ к миллионам объектов и к каждому их них применяется по несколько методов.
Множественное наследование — это термин, который используется, когда требуется описать ситуацию, в которой один класс наследует сразу нескольким. На рис. 4 класс Student_Employee наследует как классу Student, так и классу Employee, и является примером класса множественного наследования. Множественное наследование может затруднить обеспечение переносимости, поскольку различные системы, которые реализуют эту возможность используют несовместимые правила для разрешения конфликтов, например, между именами унаследованных методов.
 |
| Рис. 7. |
В системах GOP наследование может поддерживаться с помощью отображения. Оно, однако, может быть достаточно сложным (как в случае сложного объекта, о котором рассказывалось ранее). К примеру, иерархия, представленная на рисунке 7 с помощью таблиц, может быть реализована двумя различными способами.
- В одном случае таблица может быть предназначена для иерархии наследования, содержащей классы Student, Employee и Person. Эта таблица имеет столбцы для хранения всех атрибутов всех классов в иерархии наследования. Кроме того, может существовать специальный столбец, в котором указывается, к какому именно типу объекта относится данная строка, а именно, Student, Employee или Person. Эта схема, очевидно, предусматривает использование большого пространства для атрибутов, которые не относятся к конкретному объекту, но при этом столбцы хранить все же нужно.
- Нормализованная версия, которая предназначена для хранения тех же самых данных в трех отдельных таблицах — по одной для каждого класса, то есть Student, Employee и Person. Все остальные таблицы должны совместно использовать первичный ключ (то есть первичный ключ для таблицы корневого класса — это тот же ключ, на который указывают объекты в любой таблице подкласса). Таблицы для подкласса будут содержать только столбцы для атрибутов данного конкретного класса, тем самым позволят избежать нерационального использования пространства, как в первом случае.
Использовать решения, аналогичные обсуждаемым выше, применительно к модели наследования иногда чересчур сложно, так как приложение, которому требуется доступ ко всем объектам Person, требует создания сложных запросов с тем, чтобы выяснить, какие объекты принадлежат к классу Person или какому-либо из подклассов (поскольку объект Student или Employee также считается объектом Person).
Объектно-реляционные СУБД поддерживают наследование, но для таблиц и ADT используются две отдельные иерархии.
Объектно-ориентированные СУБД поддерживают возможности наследования в уже существующих объектно-ориентированных языках программирования и, в отличие от SQL3, сами по себе не требуют создания новой семантики. Однако, для того, чтобы обеспечить межъязыковую поддержку для объектов, хранящихся в базе данных (то есть, доступ к объекту Smalltalk из программы, написанной на Си++) они накладывают определенные ограничения на возможности языка программирования, которые могут использоваться при разработке таких приложений.
Переопределение, совмещение и динамическое связываниеНаследование дает пользователям иерархии классов возможность расширить иерархию за счет переопределения методов, определенных на более высоких уровнях в иерархии классов. Такое переопределение методов позволяет по-иному реализовать для подкласса метод, декларированный в классе более высокого уровня. Кроме того, объектно-ориентированные системы программирования позволяют совмещать методы, то есть новый метод может быть определен с именем уже существующего метода, но с другим набором аргументов (называемым также сигнатурой). Переопределение и совмещение методов весьма полезны при создании удобочитаемого кода, но в сочетании с поддержкой позднего связывания (при котором разрешение метода откладывается до момента исполнения программы) они становятся крайне важны для разработки приложений, которые допускают последующую модификацию библиотек классов, с которыми работает приложение. Это проиллюстрировано в примере, приведенном на рис. 7. Базовый класс Person имеет свою собственную реализацию метода display(), что распространяется и на производных классы Student и Employee. Благодаря свойствам наследования ссылка на объект Student или Employee может также храниться в наборе, называемом teenagers, который представляет собой набор ссылок на объекты person, без программы, указывающей на подтип конкретных типов отображаемых объектов:
Set> teenagers; Ref person; ... for person in teenagers do person.display(); ...
В системах GOP объекты в приложении представляют собой объекты языка программирования. Эти методы не существуют в базе данных и работают, используя только объектное представление данных. Данные из базы данных должны преобразовываться в объектное представление; код приложения исполняется как размещенная в оперативной памяти программа. Таким образом, методы распределяются с помощью механизмов, заложенных в язык программирования.
ОРСУБД хранят оба метода и данные в самой базе данных и могут распределять методы по объектам на сервере баз данных. Распределение методов основано на общей функциональной модели (вызывая функцию с объектом в качестве первого аргумента), а не в соответствии с классической объектной моделью (которая основана на передаче сообщения объекту). Кроме того, методы могут использоваться в запросах, хранимых процедурах и функциях, определенных пользователем, а также в прикладных программах.
ООСУБД обычно исполняют методы на клиенте, поскольку эти методы написаны на языке программирования, среда которого может поддерживаться только на клиенте. Большинство систем методы в базе данных не хранят.
Доступ к данным
После обсуждения различных характеристик моделирования данных, мы попытаемся выяснить, как могут создаваться и храниться объекты приложений, а также поговорим о поддержке различных типов доступа. В этом разделе будет коротко рассмотрено взаимодействие между клиентом и сервером, в частности метод, с помощью которого объекты передаются между клиентом и сервером. Наконец, будут обсуждены несколько важных моментов, касающихся поддержки приложений, в том числе эволюции схемы, ограничений целостности и триггеров. В таблице 2 приведены результаты этого обсуждения.
Табл. 2. Доступ к данным
| Характеристика | Поддержка долговременного хранения объектов на базе шлюза (GOP) | Объектно- реляционная СУБД (ОРСУБД) | Объектно-ориентированная СУБД (ООСУБД) |
| Создание и доступ к хранимым данным | Поддерживается (может быть не полностью прозрачен для приложения) | Поддерживается (не прозрачен, поскольку приложение всегда выполняет определенное действие) | Поддерживается (степень прозрачности зависит от конкретного продукта) |
| Навигация | Может поддерживаться за счет прозрачной установки соответствия доступа к объектам и операций лежащей в основе базы данных (для обеспечения приемлемой производительности необходима выборка с упреждением и/или кэширование) | Сейчас поддерживается с помощью объединений (для эффективной поддержки используется идентификация строк) | Эффективно поддерживается большинством продуктов |
| Обслуживание незапланированных запросов | Поддерживается за счет использования специализированного языка запросов к хранилищу (не достаточно хорошо интегрирован с представлением объектов) | Превосходная поддержка (пока остается нерешенным вопрос о расхождении моделей) | Поддерживается, но с ограничениями |
| Сервер объектов или сервер страниц | Сервер объектов | Сервер объектов | Может использоваться сервер страниц или сервер объектов |
| Эволюция схемы | Ограниченная поддержка (предоставить полную поддержку может оказаться крайне сложно) | Поддерживается | Поддерживается |
| Ограничения целостности и триггеры | Не поддерживается | Поддерживается | Не поддерживается |
Самый лучший стиль организации долговременного хранения — сделать это способом, независмо от типа. Иногда в приложении создают временные объекты и объекты долговременного хранения одного и того же типа. Обычно существует два основных способа (иногда в одной системе поддерживаются оба) обеспечить долговременное хранение экземпляров объектов - либо за счет совмещения нового оператора, либо потребовав, чтобы каждый класс имел долговременно хранимые экземпляры, наследуемые от общего класса, чье определение и реализация предлагаются системой баз данных.
При операторном подходе для создания экземпляра класса используется глобальный многократно пергруженный оператор new. Приложения, которым требуется создать хранимые экземпляры класса, будут вынуждены создавать объекты, используя новый оператор, предлагаемый системой. Пример, в котором создаются новые объекты с применением операторного подхода, выглядит следующим образом.
Ref temp_emp = new Employee; // В предыдущей строке создается // временный объект employee Ref pers_emp = new (myDB) Employee;
Первый из приведенных выше операторов создает временный объект, а второй — хранимый объект в базе данных myDB. Преимущество операторного подхода в том, что определения классов приложения остаются неизменными и, таким образом, все средства языка программирования, могут применяться в своем исходном виде. Возможно, что при подобном подходе существующие приложения для работы со временными данными можно довольно легко приспособить с учетом доступа к хранимым данным. Недостаток этого решения в том, что информация о схеме должна тем или иным образом быть передана в ООСУБД за счет преобразования средствами языка программирования. Такие ООСУБД, как ObjectStore и O2, используют этот подход для организации долговременного хранения.
Наследование из общего класса — еще один популярный способ обеспечить долговременное хранение. Этот подход применяется во многих ООСУБД, в частности в Objectivity и Versant. Системы GOP, такие как VisualAge C++ Data Access Builder также используют это решение. При подобном подходе долговременное хранение объекта реализуется с помощью особого типа объекта, другими словами, свойство долговременного хранения не ортогонально типу. Достоинством наследования из общего класса является то, что информацию о схеме можно получить по результату вызова производных и переопределенных методов. Это в свою очередь означает, что определенные методы должны быть реализованы в каждом классе, которому требуется содержать хранимые экземпляры, но это обстоятельство компенсируется тем, что существующие ООСУБД обеспечивают автоматическую генерацию файлов с определением классов приложения. Разработчику приложения необходимо только реализовать методы приложения для данного класса, поскольку методы, ориентированные на конкретную базу данных, генерируются автоматически. К сожалению, однако, эта схема почти всегда приводит к множественному наследованию, которое необходимо приложению для объединения иерархии наследования системы с иерархией наследования приложения. Поскольку множественное наследование во многих объектно-ориентированных программных системах поддерживается не очень хорошо, в результате получается сложное и недостаточно мобильное приложение.
Чтение данных долговременного хранения может выполняться практически прозрачно для приложения в системах всех трех типов. Однако с обновлением данных дело обстоит иначе. В системе GOP, обновление обычно не прозрачно и приложению необходимо точно информировать систему об объектах, которые были изменены (здесь возможна определенная инкапсуляция, к примеру, при обновлении отношений, но изменение атомарного поля, такого как целое, инкапсулировать невозможно). В ОРСУБД обновление осуществляется с помощью отдельной декларации UPDATE и, следовательно, непрозрачно. Наконец, ООСУБД различаются по степени прозрачности, начиная от ObjectStore, где обновление можно сделать полностью прозрачным, до таких систем, как Versant, где приложение должно в обязательном порядке промаркировать «затронутые» объекты. Фактически, стандарт ODMG-93 имеет специальный интерфейс, определенный для маркировки «затронутых» объектов из приложения.
НавигацияКак уже упоминалось в начале статьи, стимулом для развития ООСУБД становятся приложения, требующие быстрого доступа (например, тестирование и разводка интегральной схемы может оказаться операцией, требующей значительных ресурсов процессора и для которой необходим быстрый доступ к объектам компонентов). Некоторые из этих ООСУБД (например, ObjectStore) предлагают очень быстрый доступ к данным за счет использования возможностей ОС по обработке исключений, вызванных отсутствием страниц [16]. Обычно при первом доступе к элементу данных в базе этот элемент помещается в оперативную память, и последующий доступ к нему будет выполняться очень быстро. В некоторых случаях, к примеру, в ObjectStore, хранимые в ООСУБД данные идентичны по размеру и структуре своим копиям в оперативной памяти и, как следствие, после первого обращения весь последующий доступ к этому элементу данных происходит столь же быстро, как и при работе программы, размещаемой в оперативной памяти. Столь высокая производительность достигается за счет тесной интеграции кода приложения с кодом клиента базы данных, что в конечном итоге снижает уровень защиты. Таким образом, высокая производительность при навигации обходится недешево и разработчики приложения должны иметь в виду, чем им приходится расплачиваться при работе с ООСУБД.
Навигация в системах GOP может поддерживаться за счет установки соответствия между обращениями к объектам и обращениями к базам данных, где эти объекты хранятся. «Родные» алгоритмы навигации, применяемые в реляционной базе данных, могут казаться малопроизводительными (для доступа к каждому объекту генерируется один запрос SQL). GOP позволяет увеличить производительность двояко: (1) за счет поддержки кэша большого объема для хранения объектов приложения в оперативной памяти; (2) за счет предоставления механизмов выборки (упреждающей выборки) объектов до того, как они потребуются. Такую упреждающую выборку обычно следует определить в приложении, тем самым, гарантируя, что все необходимые объекты могут быть выбраны с упреждением за один запрос.
Обслуживание незапланированных запросовОгромный успех реляционных СУБД во многом объясняется тем, что они поддерживают язык обработки незапланированных запросов (стандарт SQL). Как уже отмечалось ранее, SQL отличается от языков программирования, используемых приложениями, в силу чего и между запросом и приложением возникает расхождение моделей.
Система GOP обычно не реализует нового языка запросов для объектов. Приложения, использующие GOP, таким образом, для обработки запросов обычно применяют язык запросов хранилища (это почти всегда SQL). Запрос выполняется на основе базовой модели данных, которая не является объектно-ориентированной и, таким образом, не всегда корректно работает с объектной моделью приложения.
Объектно-реляционные СУБД великолепно поддерживают запросы и неплохо выполняют большую часть работы по оптимизации и управлению индексами. К сожалению, некоторое расхождение остается, поскольку модель данных приложения может по-прежнему отличаться от модели данных базы данных. За счет переноса большей части приложения на ОРСУБД с помощью ADT, определяемых пользователем функций и методов, приложения могут в значительной степени устранить это несоответствие. Проблема, однако, в том, что поскольку клиентские машины имеют большой кэш и значительные вычислительные ресурсы, такой подход, ориентированный на сервер, может себя не оправдать и, возможно, окажется неприемлемым для приложений, предусматривающих интенсивное интерактивное взаимодействие.
Язык обработки запросов, поддерживаемый в ООСУБД, представляет собой расширение некоторого объектно-ориентированного языка программирования. Следовательно, ООСУБД компенсирует расхождение моделей данных за счет использования систем одного и того же типа для обработки незапланированных запросов и программных методов. Обычно языки запросов ООСУБД не подчиняются правилам инкапсуляции и позволяют обращаться к структуре данных. Это неминуемо, поскольку незапланированные запросы по своей природе требуют выполнения произвольных вычислительных операций с данными, которые невозможно заранее определить, используя фиксированный набор методов. В отличие от ОРСУБД, объектно-ориентированные СУБД не поддерживают динамическое создание представления данных. Производные атрибуты, тем не менее, могут быть реализованы с помощью более статичного подхода, а именно использования иерархии наследования и позднего связывания. Поддержка запросов в разных коммерческих ООСУБД существенно различны. Некоторые из этих систем до недавнего времени не предлагали язык запросов, или предоставляли поддержку запросов без оптимизации и управления индексами. Другие ООСУБД, такие как ObjectStore, поддерживали запросы, в которых могла использоваться только одна операция объединения, в противоположность SQL, который позволяет работать с произвольными реляционными выражениями. Запросы ObjectStore могут начинаться только из одного корневого набора, а полученный результат не может динамически генерировать новые типы. Тем не менее, ObjectStore предлагает поддержку управления индексами, автоматическое изменение индексов в случае обновления данных и оптимизацию запросов. Наконец, ООСУБД (например, O2), поддерживают неограниченный и мощный язык запросов в сочетании с оптимизацией запросов и управлением индексами. В последнее время язык запросов, предлагаемый в различных объектно-ориентированных базах данных, постепенно начинает приближаться к стандарту на обработку объектных запросов - языку OQL, определяемому в ODMG-93, который, к сожалению, не полностью совместим со стандартом SQL.
Сервер объектов или сервер страницВ клиент-серверной архитектуре существует «разделение труда» между клиентом и сервером, а системам управления базами данных необходимо обеспечить эффективное использование этих ресурсов как на клиенте, так и на сервере. Клиент реляционной СУБД обращается к данными с сервера с помощью механизма, известного как доставка запроса (см. рисунок 8). Речь идет о том, что клиент посылает SQL-запросы на сервер. Сервер, при получении запроса, его оптимизирует, выбирает подходящий план доступа, используя все имеющиеся индексы, и выполняет запрос.
Результат запроса — это набор реляционных кортежей, которые возвращаются клиенту. Затем клиент обрабатывает данные и в случае необходимости инициирует новые запросы. Кортежи, возвращаемые сервером клиентам — это таблицы в первой нормальной форме, за исключением крупных объектов (например, BLOB).
 |
| Рис. 8. |
Появление относительно недорогих рабочих станций с мощными процессорами и памятью большой емкости позволило изменить используемую в компьютерных системах модель, ориентированную на сервер, на модель, предусматривающую более сбалансированное распределение рабочей нагрузки между клиентом и сервером. Эта эволюция затронула и ООСУБД и позволила осуществлять иное распределение ресурсов между клиентом и сервером, чем в реляционных СУБД. Традиционная архитектура ООСУБД предусматривает перенос большей части работы с сервера на клиент, чем в традиционной РСУБД. Во многих ООСУБД (например, в ObjectStore), вся работа, за исключением наиболее существенных операций, связанных с управлением памятью, параллелизмом и восстановлением, переносится на клиент. ООСУБД, таким образом, осуществляет передачу данных, а не передачу запросов, как это происходит в реляционных СУБД. Данные, пересылаемые между клиентом и сервером, могут быть либо объектами (то есть сервер предоставляет объекты клиенту), либо страницами (когда сервер предоставляет клиенту страницы, содержащие объекты, не зная какие именно объекты размещены на странице). Далее мы более детально рассмотрим архитектуру сервера страниц и сервера объектов.
 |
| Рис. 9. |
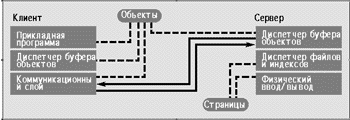
Архитектура сервера объектов представлена на рисунке 9. Сервер объектов может получать запросы или на один объект (используя, к примеру, идентификатор объекта), или набор объектов. Как показано на рисунке 9, связь между клиентом и сервером базируется на объектах и кэш объектов поддерживается как на клиенте, так и на сервере (это возможно благодаря быстрому снижению цен на оперативную память). Сами же объекты хранятся на диске, физически объединенные в страницы, но управление ими полностью осуществляется сервером, при том, что клиенту практически ничего не известно об этом представлении.
Преимущество архитектуры сервера объектов состоит в том, что запросы, и, что более важно, методы могут исполняться как на клиенте, так и на сервере. Это значит, что взаимодействие между сервером и клиентом можно минимизировать, используя вспомогательные структуры данных, такие как индексы, с тем, чтобы проанализировать запросы на сервере. Управление блокировкой и ограничениями значительно упрощается, поскольку критически важные задачи могут выполняться на сервере. Архитектура сервера объектов позволяет реализовать предоставление полномочий и защиту того же уровня, что и в реляционных СУБД. Фактически, реляционную СУБД можно рассматривать как сервер объектов, который обслуживает примитивные объекты (кортежи в первой нормальной форме).
С другой стороны, серверы объектов имеют множество недостатков, что затрудняет их реализацию. К примеру, обработка запросов в случае обновления данных существенно усложняется: или измененные на клиенте данные должны передаваться на сервер перед исполнением там любого запроса, или запросы должны параллельно исполняться на клиенте и на сервере, а полученные результаты — объединяться. Первая стратегия обеспечивает слишком низкую производительность и в случае обновления данных кэширование становится практически бесполезным, в то время как вторая стратегия порождает серьезные проблемы, связанные с обработкой распределенных запросов. Когда объект одновременно существует и на сервере, и на клиенте, возникает практический вопрос, связанный с объектно-ориентированными языками программирования, для работы которых требуется среда реального времени. Исполнение методов на сервере означает, что программа, реализующая этот метод, сама должна храниться в базе данных, а СУБД должна ?понимать? требования среды исполнения всех языков программирования, объекты которых размещаются в базе данных. Наконец, поскольку объекты хранятся на страницах жесткого диска сервера, сервер объектов должен упаковывать и распаковывать эти объекты для обмена ими с клиентами. Это увеличивает рабочую нагрузку сервера и может привести к появлению узких мест. (См. [13], где проведено исследование трех альтернативных клиент-серверных стратегий для ООСУБД). Производительность сервера объектов может измениться и за счет необходимости передавать полные объекты через API-интерфейс, что может значительно снизить скорость работы в случае больших объектов.
 |
| Рис. 10. |
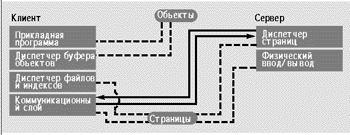
Альтернативой архитектуре сервера объектов является архитектура сервера страниц (представлена на рисунке 10), где передача между клиентом и сервером осуществляется постранично. Сервер в архитектуре сервера страниц выполняет минимальные функции, такие как восстановление и хранение страниц. Объекты существуют только на клиенте. Сравнение сер
