
Большинство специалистов считают, что для ускорения передачи данных между приложениями и сетью необходимо исключить из маршрута ядро операционной системы и централизованный сетевой стек, организовав пересылку данных непосредственно через сетевой интерфейс пользовательского уровня. Наличие подобного интерфейса позволяет максимально точно адаптировать уровень сетевого взаимодействия к требованиям каждого конкретного процесса. Таким образом, приложения получают возможность посылать и принимать сетевые пакеты, не обращаясь к функциям операционной системы. В результате существенно сокращается время задержки и повышается общая пропускная способность сети.
К сожалению, несовместимость предлагаемых решений и нежелание производителей идти на компромисс препятствуют дальнейшему прогрессу и не позволяют воплотить полученные достижения исследователей в конкретные продукты. А ведь именно практическая реализация могла бы создать необходимые предпосылки для действительно широкого распространения данных интерфейсов. Корпорации Intel, Microsoft и Compaq предложили новую спецификацию Virtual Interface Architecture [1], предназначенную для построения кластерных архитектур и системных сетей. Коммерческие продукты, соответствующие спецификациям VIA, уже представлены (в качестве примера можно привести сетевой интерфейс GNN1000 компании GigaNet, http://www.giganet.com). Технология развивается, появляются новые системы и сетевые интерфейсы пользовательского уровня с течением времени становятся все более и более совершенными.
VIA создавался на базе нескольких ранее существовавших прототипов, в том числе, на основе разработки университета Корнелла U-Net [2]. Мы постараемся описать основные особенности этих архитектур и подробно остановимся на следующих вопросах.
- Каким образом предоставить приложениям прямой доступ к аппаратным средствам сетевого интерфейса, сохранив при этом высокий уровень безопасности, который исключал бы взаимное влияние приложений друг на друга?
- Как спроектировать эффективный и одновременно гибкий программный интерфейс. С одной стороны, приложения должны получить доступ к сетевому интерфейсу и управлять буферизацией, планированием процессов и адресацией. С другой — от программного интерфейса требуется поддержка широкого спектра различных аппаратных реализаций?
- Как организовать управление ресурсами и особенно памятью. Приложения должны учитывать расходы на преобразования виртуальных адресов в физические. В то же время от приложений необходимо скрыть специфические детали конкретных реализаций, а операционная система обязана взять на себя управление процессом распределения ресурсов?
- Как обеспечить справедливую стратегию доступа к сети, минуя ядро, которое при использовании традиционных стеков протоколов играет роль центрального пункта управления и планирования?
Факторы эффективности
Эффективность сети, как правило, характеризуется ее пропускной способностью, то есть скоростью передачи бесконечного потока информации. Однако в последнее время увеличивается число приложений, чувствительных к времени получения ответа из сети (задержке) и к снижению реальной пропускной способности при пересылке большого количества коротких сообщений.
Малая задержкаЗадержка возникает главным образом из-за вычислительной перегрузки, когда процессор не успевает обрабатывать сообщения в исходной и конечной точках соединения. Дело в том, что процессор отвечает за управление буферами, проверку контрольных сумм, копирование сообщений, а также обеспечивает контроль за потоками, прерываниями и сетевыми интерфейсами.
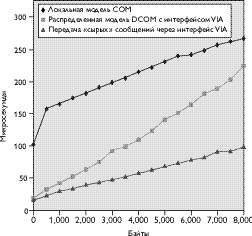 | Рис. 1. График задержки подтверждения приема необработанного сообщения. Время получения подтверждения приема локального вызова удаленной процедуры под управлением ОС Windows NT (локальная модель COM) в сравнении с вызовом удаленной процедуры через архитектуру Virtual Interface Architecture с использованием интерфейса GigaNet GNN1000 (распределенная модель COM с интерфейсом VIA). В случае обхода ядра удаленный вызов выполняется быстрее локального. График задержки подтверждения приема необработанного сообщения, переданного через интерфейс VIA (передача «сырых» сообщений через интерфейс VIA) показывает, что резервы для оптимизации протокола DCOM еще далеко не исчерпаны. |
Как показано на рис.1, подтверждение приема при вызове удаленной процедуры с использованием сетевого интерфейса пользовательского уровня происходит гораздо быстрее по сравнению с выполнением аналогичной локальной операции в среде Windows NT. Обработка удаленного вызова производится средствами распределенной компонентной объектной модели Microsoft DCOM и архитектуры VIA интерфейса GNN1000. В случае локального вызова используется компонентная объектная модель COM. Кроме того, на рисунке показана задержка подтверждения приема «сырых» сообщений, проходящих через виртуальный интерфейс (это значение принимается за базовый показатель при оценке накладных расходов протокола DCOM).
Малое время задержки имеет очень важное значение для построения кластерных систем корпоративного уровня, которые должны обладать высокой готовностью и масштабируемостью. Система управления кластерами и кластерные серверные приложения опираются на специальный протокол циклического опроса, который позволяет восстановить состояние системы в случае возникновения ошибок. Протокол обслуживает переменное число «участников», должен получать ответ в каждом цикле опроса и крайне чувствителен к любой задержке. Кластерные приложения предъявляют высокие требования к надежности (в частности, при выполнении операций резервного копирования и тиражирования) и используют специальные средства межузлового взаимодействия для синхронизации процессов передачи данных между отдельными компонентами системы. Кластерные приложения допускают возможность масштабирования только в том случае, если скорость межузлового взаимодействия во много раз превышает скорость ответа системы на запросы клиентов. Эксперименты с сервером Microsoft Cluster Server, показали, что если малого времени задержки при организации межкластерного взаимодействия добиться не удается, масштабируемость ограничивается восемью узлами [3].
Для приложений, требующих интенсивной обработки, многие специалисты предлагают использовать сети рабочих станций. Однако написание программ для таких сетей представляет собой слишком сложную задачу. Кроме того, для повышения эффективности подобных архитектур, необходимо уменьшить затраты на организацию взаимодействия локальных сетей.
Высокая пропускная способность для коротких сообщенийРост потребности в высокой пропускной способности при пересылке коротких сообщений (их размеры, как правило, не превышают 1 Кбайт) обусловлен теми же самыми причинами, что и увеличение спроса на коммуникационные технологии, позволяющие добиться малого времени задержки. Web-серверы, например, очень часто получают и пересылают множество небольших сообщений сразу нескольким пользователям.
Уменьшив размер сообщения, передаваемого с максимальной скоростью, можно воспользоваться стандартными протоколами потоков данных (таких, как TCP). Требования этих протоколов к размеру буфера прямо пропорциональны задержке связи. Размер окна TCP, к примеру, зависит от пропускной способности сети. Один из способов обеспечить максимальную пропускную способность при минимальных затратах состоит в том, чтобы попытаться добиться наименьшей задержки в локальных сетях, сохранив при этом приемлемые размеры буфера.
Гибкие коммуникационные протоколыТрадиционный барьер между приложениями и протоколами затрудняет разработку более эффективных сетевых прикладных систем. Во главу угла ставятся два вопроса: интеграция приложений со средствами управления буфером протокола и оптимизация маршрута. В обычных системах недостаточность средств управления интегрированным буфером влечет за собой слишком большие накладные расходы при обработке информации. Без рационального управления буфером не удастся снизить расходы на обслуживание пересылок информации между приложением и ядром.
Существует несколько способов построения гибких и эффективных коммуникационных протоколов. Можно воспользоваться экспериментальными или оптимизированными версиями традиционных протоколов для интеграции универсальных механизмов с протоколами, разработанными для конкретных приложений. Перспективная технология проектирования протоколов подразумевает управление кадрами на уровне приложений. При этом система буферизации полностью интегрируется со средствами обработки, специфическими для конкретных приложений; при этом многие уровни протоколов оказываются невостребованными и подменяются высокоэффективным, монолитным маршрутом передачи. Можно также задействовать специальный компилятор для трансляции протоколов. Наконец, известны технологии (например, генерация быстрого маршрута в коммуникационной системе Ensemble), основанные на формальных средствах для автоматического создания оптимизированного стека протокола. Эта технология основана на управлении полным стеком протоколов, в том числе и его самыми нижними уровнями, и требует, чтобы стек функционировал в общем адресном пространстве.
Основные этапы разработки интерфейса
Сетевые интерфейсы пользовательского уровня, базирующиеся на сообщениях, позволяют приложениям обмениваться данными за счет явной пересылки и приема сообщений. Они похожи на привычные интерфейсы передачи сообщений между несколькими компьютерами (такие, как MPI, Intel NX и Thinking Machines CMDD). Все сетевые интерфейсы пользовательского уровня, о которых идет речь, предоставляют возможность одновременного обращения к сети сразу нескольким пользователям. Для обеспечения нужной степени защиты процедуры настройки в них отделены от непосредственной передачи данных. В процессе настройки принимает участие и операционная система. Она отвечает за защиту и исключает взаимное влияние приложений друг на друга. При передаче же данных интерфейсы в обход операционной системы выполняют лишь простые проверки, обеспечивающие необходимый уровень защиты.
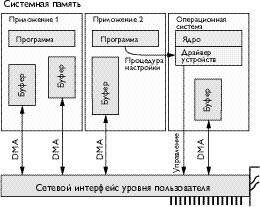 | Рис. 2. Архитектура доступа к системной памяти. Системная память, в которую загружены два приложения, осуществляющие доступ к сети с использованием сетевого интерфейса уровня пользователя. Обычный драйвер устройств операционной системы управляет аппаратными средствами интерфейса. Драйвер устройств обеспечивает прямой доступ приложений к интерфейсу. Приложения выделяют буферы в собственном адресном пространстве и при помощи интерфейса пересылают информацию сообщений в буферы и в обратном направлении, используя механизм прямого доступа к памяти (direct memory access, DMA). |
На рис.2 показана системная память, в которой находятся два приложения, осуществляющие доступ к сети при помощи сетевого интерфейса пользовательского уровня. Драйвер устройств операционной системы управляет аппаратными средствами интерфейса традиционным способом, осуществляя контроль за доступом приложений к оборудованию. Приложения выделяют буферы сообщений в собственном адресном пространстве и обращаются к драйверу устройств для получения доступа к сетевому интерфейсу. После соответствующей настройки они автоматически инициируют процесс передачи и приема, а интерфейс пересылает информацию в буферы приложений и в обратном направлении, используя обычный механизм прямого доступа к памяти. Архитектура сетевого интерфейса пользовательского уровня варьируется в зависимости от особенностей конкретных приложений и сетей — от способа определения приложениями местоположения пересылаемых сообщений, от местонахождения выделяемых для приема информации буферов, от порядка уведомления приложений о поступивших сообщениях. В некоторых сетевых интерфейсах (например, в интерфейсах Active Message или Fast Message) операции передачи и приема реализованы в виде функций, помещенных в пользовательскую библиотеку, которая загружается при инициализации каждого процесса. В других (например, в U-NET и VIA) для каждого процесса создаются очереди, которыми манипулируют сами приложения. Эти очереди обслуживаются аппаратными средствами интерфейса.
Истоки параллельной обработкиСетевые интерфейсы пользовательского уровня, базирующиеся на сообщениях, создавались на основе традиционных моделей передачи сообщений между компьютерами. В этих моделях отправитель определяет адрес памяти источника данных и узел конечного процессора, а получатель в явной форме пересылает входящие сообщения в область памяти адресата. Учитывая семантику операций передачи и приема, библиотека сетевого интерфейса пользовательского уровня должна либо буферизовать сообщения (в этом случае они пересылаются через промежуточный библиотечный буфер), либо обеспечить поддержку дорогостоящего коммуникационного канала между отправителем и получателем, своевременно уведомляя их о судьбе каждого сообщения. В обоих случаях накладные расходы слишком велики. Интерфейс Active Message [4] создавался именно для того, чтобы уменьшить эти накладные расходы. Данная концепция основывалась на использовании примитивов, с помощью которых можно было эффективно реализовать на практике все многообразие коммуникационных операций. Основная идея заключалась в том, чтобы поместить в каждое сообщение адреса отвечающих случаю обработчиков, после чего заставить сетевой интерфейс вызывать нужные обработчики при получении соответствующих сообщений. Размещение обработчика в сообщении привело к повышению быстродействия процедур управления: во время выполнения клиентского кода данные каждого сообщения эффективно взаимодействовали с окружающей вычислительной средой.
От протокола Active Message не требовалось буферизации сообщений. Он строился на основе обработчиков, которые непрерывно извлекали сообщения из сети. В различных версиях Active Message не предусматривались возможности управления потоками и ретрансляции сообщений, поскольку все эти механизмы уже были реализованы в связывающей параллельные машины сети. Хотя протокол Active Message неплохо отвечал потребностям первого поколения коммерческих компьютеров с массовым параллелизмом, непосредственное обслуживание полученных сообщений процессорами с многоступенчатыми конвейерами с течением времени все более и более осложнялось. Авторы некоторых версий попытались реализовать обработчики в виде прерываний, но слишком высокая стоимость такого решения заставила их прибегнуть сначала к скрытому, а затем и к явному опросу в конце процесса передачи. Таким образом, вновь встал вопрос о непроизводительных издержках. Проведение опроса вызывало возникновение задержек еще до обнаружения поступившего сообщения и приводило к накладным расходам, даже если сообщений не было.
Появление протокола Fast Message [5] позволило решить все возникшие вопросы за счет замены процедур обработки буферизацией и проведения явного опроса. При помощи буферизации удалось отложить запуск обработчиков в тех случаях, когда функции сетевого обслуживания не поддерживались, у приложений же была уменьшена частота проведения опроса, что в свою очередь привело к снижению издержек. Операция передачи определяла узел назначения, обработчик и местоположение данных. Согласно концепции Fast Message сообщения передавались и помещались в буфер на приемной стороне. При приеме вызова получателем протокол Fast Message запускал обработчики всех незавершенных сообщений.
Таблица. Быстродействие процедур подтверждения приема стандартных сокетов и сетевых интерфейсов уровня пользователя в сети Myricom Myrinet
| Myrinet | U-Net | VMMC-2 | AM-II | Fast Messages | VIA | |
| Задержка, мксек | 250 | 13 | 11 | 21 | 11 | 60 |
| Пропускная способность, Мбайт/с | 15 | 95 | 97 | 31 | 78 | 90 |
В случае перемещения процедуры буферизации обратно на уровень сообщений она оптимизировалась в соответствии с особенностями машины-получателя и обрабатывалась функциями управления потоком, которые помогали избежать тупиковых ситуаций и обеспечивали надежную связь в неустойчивых сетях. Высокая эффективность буферизации коротких пакетов на уровне сообщений была доказана на практике (эти решения нашли отражение в версии протокола Active Message II, AM II). Сообщения в этом случае пересылались адресату без использования буферов.
U-NetТехнология U-Net стала первой разработкой, которая коренным образом отличалась как от Active Message, так и от Fast Message. В табл.1 показана производительность протокола U-Net и четырех последующих реализаций сети Myricom Myrinet [6]. Технология U-Net поддерживает сетевой интерфейс, который по своему функциональному назначению близок к аппаратной реализации интерфейса локальных сетей. В этом случае не выделяется никаких буферов. Буферизация сообщений организована в неявном виде, все сообщения находятся под контролем. Вместо вызова функций API-интерфейса (как это было в прежних интерфейсах) в памяти организуется набор очередей, через которые сообщения и пересылаются. В сущности протоколы Active Message и Fast Message определяют тонкий слой программного обеспечения, который отвечает за поддержку унифицированного интерфейса с оборудованием сети. Со своей стороны, интерфейс U-Net специфицирует аппаратные операции, посредством которых оборудование предоставляет стандартный интерфейс непосредственно программному обеспечению пользовательского уровня.
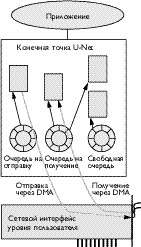 | Рис. 3. Архитектура U-Net. Каждое приложение получает доступ к сети через конечные точки U-Net. В конечной точке находятся очереди передачи и приема, а также свободная очередь, которые указывают на буферы, выделенные приложением. Аппаратные средства интерфейса обращаются к очередям, чтобы определить, какой буфер пересылает сообщения внутрь, получателю (получение через DMA) и за пределы системы (отправка через DMA). |
Технология U-Net хорошо подходила к кластерной среде, в которой использовались стандартные сетевые технологии (например, Fast Ethernet или ATM). Сеть должна была не только поддерживать параллельную обработку, но и обеспечивать традиционное потоковое взаимодействие. Машины внутри кластера взаимодействовали с внешними узлами при помощи тех же самых сетевых средств.
Архитектура. В технологии U-Net конечные точки содержат три очереди сообщений (см. рис. 3). В очередях хранятся дескрипторы для буферов сообщений, подготовленных к отправке (очередь на отправку), буферов, освобожденных для получения сообщений (свободная очередь), и буферов уже полученных сообщений (очередь на получение). При отправке сообщения обработчик помещает дескриптор в очередь на отправку. Дескриптор содержит указатели на буферы сообщения, их длину и адрес назначения. Сетевой интерфейс извлекает дескриптор, проверяет его адрес назначения, преобразует адреса виртуальных буферов в физические адреса и пересылает данные при помощи механизма прямого доступа к памяти (DMA, direct memory access).
При приеме сообщения сетевой интерфейс извлекает из заголовка корректную конечную точку адресата, удаляет нужные дескрипторы из соответствующей свободной очереди, транслирует их виртуальные адреса, пересылает данные в память, используя механизм DMA, и помещает дескриптор в очередь на получение в конечной точке. Приложение может обнаружить поступившее сообщение путем опроса очереди на получение, установления блокировки до поступления сообщения (как при вызове системного вызова select в ОС Unix) или при получении асинхронного уведомления (например, сигнала) о поступлении сообщения.
Защита. В протоколе U-Net процессы, получающие доступ к сети на сервере, защищены друг от друга. Механизм U-Net помещает очередь в каждой конечной точке только в адресное пространство того процесса, который владеет данной конечной точкой. При этом все адреса являются виртуальными. Протокол U-Net следит за тем, чтобы процессы не отправляли сообщения по произвольным адресам, и предотвращает прием сообщений, предназначенных для других адресатов. По этой причине процессы должны предварительно настроить коммуникационные каналы перед отправкой и приемом сообщений. Каждому каналу ставится в соответствие конечная точка, определяется адресный шаблон как для исходящих, так и для входящих сообщений. Когда процесс создает канал, операционная система проверяет шаблоны, чтобы гарантировать выполнение нужной стратегии для всех исходящих сообщений и обеспечить однозначное соответствие между входящими сообщениями и конечной точкой получателя.
Точная форма шаблона адреса зависит от особенностей сети. В версиях для ATM шаблон просто определяет идентификатор виртуального канала, в версиях для Ethernet шаблону соответствует усовершенствованный пакетный фильтр.
Технология U-Net не обеспечивает устойчивых гарантий при выходе за рамки поддерживаемой сети. В общем случае сообщения могут быть утеряны, возможно также многократное поступление одного и того же сообщения.
AM-II и VMMCКоммуникационные примитивы, в основе которых лежит концепция разделения памяти, поддерживаются двумя моделями: модель AM-II, представляющая собой одну из версий протокола Active Message, была разработана в университете Беркли [7], а модель Virtual Memory Mapped Communication создавалась в Принстонском университете в рамках кластерного проекта Shrimp [8]. В этих моделях исключено избыточное копирование, выполняющееся в конечных точках получателя при использовании протоколов Fast Message и U-Net. Технологии Fast Message и U-Net помещают поступившие сообщения в буфер и гарантируют доступность этого буфера приложениям. Приложение должно скопировать данные по месту назначения в том случае, если их необходимо сохранить после того, как освобожденный буфер будет возвращен в очередь.
Протокол AM-II поддерживает примитивы put и get, которые позволяют инициатору процесса определить адреса данных в удаленных точках: процедура put перемещает блок локальной памяти по удаленному адресу, а процедура get получает удаленный блок. В модели VMMC используется примитив, примерно аналогичный процедуре put. Во всех случаях для пересылки данных в конечную точку вмешательства получателя не требуется, поскольку отправитель и получатель предварительно согласовывают адреса удаленной памяти. Примитивы put и get модели AM-II соответствуют обработчику протокола Active Message; технология VMMC использует особую операцию уведомления. Интерфейс VMMC требует, чтобы коммуникационные процессы точно определяли всю память, требуемую организацию связи, с тем, чтобы ее нельзя было разбить на страницы. Протокол VMMC-2 [9] усиливает данное ограничение, организуя управление памятью за счет контролируемого пользователем преобразования специального буфера. Перед использованием области памяти для отправки или приема данных приложение должно зарегистрировать эту область в списках VMMC-2, после чего становится возможной трансляция в буферы быстрого преобразования адресов UTLB. Протокол VMMC-2 создает буфер по умолчанию. В результате отправитель может пересылать данные без предварительного запроса адреса буфера у получателя.
Архитектура виртуального интерфейсаАрхитектура VIA сочетает в себе базовые операции U-Net, пересылку удаленной памяти VMMC и буфер UTLB, используемый в протоколе VMMC-2. Обработка открытых виртуальных интерфейсов (VI), которая представляет идентификаторы сети, во многом напоминает конечные точки U-Net. На рис.4 показано, что каждый виртуальный интерфейс управляет двумя очередями (на отправку и на получение). Эти очереди представлены в виде связанных списков дескрипторов сообщений. Каждый дескриптор указывает на один или несколько буферов дескрипторов. Чтобы отправить сообщение, приложение добавляет новый дескриптор в конец очереди на отправку. После передачи сообщения протокол VIA устанавливает в дескрипторе бит завершения операции, а приложение извлекает дескриптор из очереди, когда он оказывается в ее начале. При приеме приложение добавляет дескрипторы для свободных буферов в конец очереди на получение. Протокол VIA заполняет их по мере поступления сообщений.
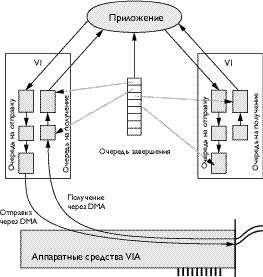 |
| Рис. 4. Механизмы очередей в архитектуре виртуального интерфейса |
Каждый виртуальный интерфейс связан с одним удаленным VI. В этом заключается отличие от конечной точки U-Net, которая может объединять несколько каналов. В модели VIA процесс способен создать одну или несколько очередей завершения и связать их с несколькими виртуальными интерфейсами. Сетевой интерфейс заполняет точки входа в очередь завершения. Каждая точка входа является указателем на полностью обработанную очередь сообщений, предназначенную для отправки или получения.
Архитектура VIA обеспечивает прямую передачу информации между локальной и удаленной памятью. Операции удаленного чтения и записи через канал DMA аналогичны операциям put и get AM-II и примитивам передачи VMMC.
Чтобы обеспечить нужную степень защиты, интерфейс VIA позволяет процессу определять, какие области памяти доступны для операций RDMA. Управление памятью в архитектуре VIA осуществляется точно так же, как и в модели VMMC-2. Буфер UTLB встроен в сетевой интерфейс. Вся память, используемая для организации связи, должна быть зарегистрирована до того, как VIA к ней обратится. Это касается всех очередей, дескрипторов и буферов. После регистрации области система возвращает идентификатор. В дальнейшем обращение производится через соответствующий идентификатор области и виртуальные адреса.
Новые решения
Как уже было сказано ранее, архитектура сетевого интерфейса пользовательского уровня VIA в той или иной степени отличается от других технологий. Эти различия явились следствием попыток оптимизировать работу сетевого оборудования и программной среды. В наибольшей степени нововведения затронули структуру очередей, стратегию управления памятью и механизм мультиплексирования сообщений.
Структура очередейОчереди протоколов U-Net и VIA представляют собой структуру, очень похожую на большинство сетевых устройств. Выбор очередей вместо процедурного интерфейса (используемого в протоколах Fast Messages и Active Messages) обеспечивает поддержку более высоких уровней программного управления, с помощью которых можно напрямую манипулировать буферами и дескрипторами. Это в свою очередь позволяет преодолеть порог, необходимый для осуществления контроля за завершением операций.
Очереди — один из наиболее естественных способов выделения состояний начала и завершения операции. Помещение дескриптора в очередь отправки инициализирует передачу; сетевой интерфейс сигнализирует об окончании операции также при помощи дескриптора. Таким образом, появляется возможность выполнять реальную передачу и прием в асинхронном режиме.
Очереди позволяют собрать разрозненные дескрипторы и воссоздать из набора несмежных буферов первоначальную структуру сообщения. К примеру, при использовании технологии скользящего окна (в этом случае передаваемое окно перемещается внутри большого буфера данных) протокол помещает информацию в отдельный буфер. Впоследствии сетевой интерфейс объединяет данные и информацию протокола.
Управление памятьюОт качества управления интегрированным буфером, который создается между приложением и сетевым интерфейсом, зависит эффективность устранения избыточного копирования данных, а также выделения и освобождения ресурсов. Однако подобная интеграция еще более усложняет систему, поскольку приложения используют виртуальную адресацию буферов сообщений, в то время как механизму прямого доступа к памяти нужны физические адреса. Поэтому специальная процедура должна преобразовывать виртуальные адреса в физические всякий раз, когда буфер взаимодействует с сетевым интерфейсом. Кроме того, операционная система обязана следить за доступностью страниц памяти для интерфейса DMA и хранить константы, необходимые для преобразования данных.
Управление памятью архитектуры VIA создавалось на основе механизма UTLB протокола VMMC-2. Интерфейс UTLB возлагал на приложение ответственность за трансляцию виртуальных адресов в физические. Приложение должно было направить операционной системе запрос на отображение области памяти до размещения в ней буферов. Преимущество такого подхода состояло в том, что операционная система могла определить схему отображения в сетевом интерфейсе. После этого трансляция всех виртуальных адресов осуществлялась при помощи обычной процедуры просмотра. Основной недостаток заключался в том, что от приложения требовалось интеллектуальное управление областями памяти. В простейшем случае выделялся фиксированный набор дескрипторов и идентификаторы области памяти хранились в дескрипторах буферов. Однако если приложение напрямую передавало информацию за пределы внутренней структуры данных, оно должно было выдавать запрос на новую трансляцию для каждой операции передачи, а на это требовалось дополнительное время. В протоколе U-Net, напротив, приложения могли размещать буферы в любом месте виртуального адресного пространства, а преобразование виртуальных адресов в физические возлагалось на сетевой интерфейс [10]. Поэтому интерфейс включал в себя механизм TLB, который отображал пары <идентификатор процесса; виртуальный адрес> на физические страницы и управлял правами доступа по чтению и записи.
Недостаток подхода U-Net заключался в том, что приложение могло обратиться к адресу, который не был представлен в буфере TLB интерфейса. Если адрес пересылается буферу, интерфейс должен передать ядру сервера запрос на трансляцию, а эта процедура в свою очередь требует сложного и дорогостоящего квитирования связи (накладные расходы для NT в этом случае составят около 20 мкс).
Чтобы буфер TLB в момент поступления сообщения мог предоставить необходимую информацию, интерфейс должен перетранслировать элементы для каждой свободной буферной очереди. Если для поступившего сообщения недоступен ни один из предварительно преобразованных буферов, интерфейс не принимает сообщение. Процедура трансляции запроса «на лету» очень сложна, поскольку за прием информации отвечает обработчик прерывания, который обладает лишь ограниченным доступом к информационным структурам ядра.
Основное преимущество схемы распределения памяти U-Net заключается в том, что ядро сервера способно ограничить объем памяти, требуемый сети, за счет сокращения количества допустимых входов в интерфейсный буфер TLB. Это примерно аналогично предварительному выделению и корректировке размеров фиксированного буферного пула, расположенного в стеках ядра сети. Отличие состоит в том, что при использовании технологии U-Net набор страниц буферного пула с течением времени может меняться.
Интерфейс VIA, который частично перекладывает функции управления памятью с операционной системы на приложения, имеет более серьезный скрытый недостаток. Если приложению нужна схема отображения, операционная система обязана предоставить ее. В противном случае возникает риск сбоя приложения. После создания схемы отображения ОС не может перераспределять ресурсы, например, воздействовать на процессы с высоким приоритетом. Если серверы и рабочие станции обрабатывают множество приложений, открыто подключаемых к сети, и каждое приложение использует, скажем, 200-300 Кбайт буферного пространства, то весьма значительная часть физической памяти тратится на поддержку функционирования сети.
При работе с протоколом U-Net, напротив, в памяти должны оставаться только точки входа в интерфейсный буфер TLB. Интерфейс может удалить из памяти схему расположения приложений, не использующих сетевые буферы, создавая, таким образом, необходимые условия для разбиения памяти на страницы и размещения в ней обычных приложений.
Мультиплексирование и демультиплексированиеСетевой интерфейс пользовательского уровня должен распаковывать поступающие сообщения и помещать их в очередь на получение. При отправке сообщений интерфейс обязан обеспечить требуемый уровень защиты (например, путем проверки адресной информации). Сложность обеих операций во многом зависит от типа используемой сети.
Технология мультиплексирования VIA ориентирована исключительно на соединения. До начала процедуры передачи данных между двумя виртуальными интерфейсами обязательно должна быть установлена связь. В спецификациях не описываются детали представления соединения на сетевом уровне, поэтому интерфейс VIA может работать поверх Ethernet и даже поверх протокола IP, определив предварительно порядок подтверждения установления связи между конечными точками и используя специальное поле для поддержки различных соединений.
Учитывая особенности соединения VIA, приложения, работающие в сетях VIA, не могут взаимодействовать с приложениями других сетей. К примеру, серверный кластер, использующий внутреннее соединение VIA для организации взаимодействия с клиентами за пределами кластера, должен применять обычные сетевые интерфейсы.
Протокол U-Net обеспечивает большую гибкость процессов мультимлексирования и демультиплексирования. В среде Fast Ethernet сетевой интерфейс реализует полный пакетный фильтр, который не ориентирован на соединения. Когда приложение открывает коммуникационный канал, оно определяет шаблоны для анализа заголовков входящих и исходящих пакетов. Агент ядра проверяет шаблоны, чтобы исключить конфликты с другими приложениями и размещает их в уплотненных структурах данных. Технология обработки пакетов U-Net обеспечивает возможность взаимодействия с общим стеком протокола, а также поддерживает отправку и прием многоадресных сообщений.
Процедура фильтрации должна быть реализована в виде динамического анализатора пакетов, совместимого с различными сетевыми протоколами и соответствующего природе полей идентификаторов, не имеющих фиксированной позиции в сообщении. К пакетному фильтру предъявляются более жесткие требования, нежели ранее, поскольку иного пути передачи неопознанных пакетов ядру операционной системы просто не существует. Безопасный маршрут больше не воспринимается как опция, потому что задача управления интерфейсными очередями на получение возлагается на операционную систему. Версия протокола U-Net для Fast Ethernet справляется с этой проблемой при помощи стандартного сетевого интерфейса и встраивания дополнительных функций в обработчик прерываний. Соответственно пакетный фильтр не отличается особой сложностью.
Доступ к удаленной памятиУправление чтением и записью при помощи механизма RDMA усложняет реализацию архитектуры VIA. При записи принимаемого сообщения интерфейс должен не только правильно определить местонахождение VI, но и извлечь из сообщения целевой адрес памяти, преобразовав его при этом к нужному виду. Основная трудность здесь заключается в том, чтобы корректно обработать ошибки процедуры управления передачей. Интерфейс обязан проверить контрольную сумму пакета, прежде чем данные будут записаны в память. В этом случае гарантируется целостность данных в конечной точке маршрута. Проверить это непросто, потому что в большинстве сетей контрольная сумма находится в конце пакета, и интерфейс вынужден полностью разместить пакет в буфере еще до начала передачи данных в основную память через канал DMA. Альтернативный вариант — включение в заголовок отдельного поля для контрольной суммы.
Чтение через канал RDMA тоже не всегда протекает гладко. Сетевой интерфейс за короткий промежуток времени может получить больше запросов на чтение, чем способен обслужить. В этом случае запросы для последующей обработки помещаются в очередь. Если очередь переполняется, запросы отбрасываются. Чтобы обеспечить надежное чтение через канал RDMA, интерфейс VIA ограничивает механизм реализации запросов на чтение процедурами, гарантирующими надежную доставку.
Разработчики технологии VIA, проанализировав существующие сетевые интерфейсы пользовательского уровня, почерпнули для себя немало полезного и успешно завершили проектирование согласованных спецификаций. Пользователи, которым удалось познакомиться с этими исследованиями, смогли без особого труда адаптироваться к особенностям VIA и остались довольны возможностями коммерческих аппаратных средств. Но поскольку основной областью применения архитектуры VIA стали серверные сети, нельзя не упомянуть об одном существенном упущении разработчиков по сравнению с технологией U-Net: интерфейс VIA не может взаимодействовать с серверами, которые используют обычные сетевые интерфейсы.
Чтобы извлечь максимальную выгоду из сочетания интерфейса VIA с высокоскоростными сетевыми технологиями, требуются дополнительные исследования, которые помогут найти пути проектирования протоколов с малым временем задержки, упорядочения объектов при минимальных затратах, создать эффективные синхронизирующие механизмы для протоколов, определить оптимальный график установления связи и управления сетевой памятью. Наиболее серьезные изменения затронут механизм управления памятью. Буферы UTLB модели VMMC-2 и архитектура VIA просты в реализации, но отбирают дополнительные ресурсы у общего страничного пула. Буфер TLB интерфейса U-Net поддерживает тесное взаимодействие с операционной системой и реализует справедливый механизм управления памятью, но данный подход является более дорогостоящим и потребует дополнительных затрат в случае потери информации.
Таким образом, несмотря на то, что сегодня сетевые интерфейсы пользовательского уровня VIA доступны каждому, конструкторам придется еще немало потрудиться, прежде чем разработчики приложений смогут забыть о головной боли. Впрочем, в конце концов, исследователи наверняка справятся с возникшими препятствиями, а пользователи сумеют освоить особенности VIA.
ОБ АВТОРАХ
Торстен фон Айкен — преподаватель информатики в университете Корнелла. Сфера его научных интересов связана с высокопроизводительными сетями и технологиями обеспечения безопасности серверов Internet. Адрес электронной почты Айкена — tve@cs.cornell.edu.Вернер Фогельс — научный сотрудник кафедры вычислительной техники университета Корнелла. Он занимается исследованием и разработкой высокодоступных распределенных систем, уделяя особое внимание корпоративным кластерным технологиям.
Thorsten von Eiken, Werner Vogels, Evolution of Virtual Interface Architecture. IEEE Computer, November 1998, pp. 61-68. Reprinted with Permission, Copyright IEEE CS, 1998, All rights reserved.
От качества управления интегрированным буфером, который создается между приложением и сетевым интерфейсом, зависит возможность исключить избыточное копирование данных, а также эффективность выделения и освобождения ресурсов
Технология мультиплексирования VIA ориентирована исключительно на соединения. До начала процедуры передачи данных между двумя виртуальными интерфейсами обязательно должна быть установлена связь
Литература
[1] D.Dunning et al., «The Virtual Interface Architecture», IEEE Micro, Mar-Apr. 1998, pp. 66-76.
[2] T.von Eicken et al., «U-Net: A User-level Network Interface for Parallel and Distributed Computing», Proc.15th Symp. Operating Systems Principles, ACM Press, New York, 1995, pp.40-53.
[3] W.Vogels et al., «Scalability of the Microsoft Cluster Service», Proc. Second Usenix Windows NT Symp., Usenix Assoc., Berkeley, Calif., 1998, pp.11-19.
[4] T.von Eicken et al., «Active Messages: A Mechanism for Integrated Communication and Computation», Proc. 19th Symp. Computer Architecture, IEEE CS Press, Los Alamitos, Calif., 1992, pp.256-266.
[5] S.Pakin, M.Lauria, and A.Chien, «High Performance Messaging on Workstations: Illinois Fast Messages (FM) for Myrinet», Proc. Supercomputing?95, ACM Press, New York, 1995.
[6] N.J.Boden et al., «Myrinet: A Gigabit-per-Second Local Area Network», IEEE Micro, Feb. 1995, pp.29-36.
[7] B.N.Chun, A.M.Mainwaring, and D.E.Culler, «Virtual Network Transport Protocols for Myrinet», IEEE Micro, Jan.-Feb. 1998, pp.53-63.
[8] M.Blumrich et al., «Virtual-Memory-Mapped Network Interfaces», IEEE Micro, Feb. 1995, pp.21-28.
[9] C.Dubnicki et al., «Shrimp Project Update: Myrinet Communication», IEEE Micro, Jan.-Feb. 1998, pp.50-52.
[10] M.Welsh et al., «Memory Management for User-Level Network Interfaces», IEEE Micro, Mar.Apr., 1998, pp.77-82.
[11] M.Bailey et al., «Pathfinder: A Pattern Based Packet Classifier», Proc. Symp. Operating Systems Design and Implementation, Usenix Assoc., Berkekey, Calif., 1994, pp.115-123.
