
Университет Южной Калифорнии, Лос-Анжелес
Хранилища данных
Хранилища знаний
Базы данных и базы знаний
Разведка знаний
Представление знаний
Онтологии
Другие описательные атрибуты знаний
Фильтрация знаний
Поиск знаний
Инструментальные средства
Средства интеллектуального поиска
Визуальные модели
Пока сотрудники бьются на рынке за потребителя товаров и услуг своих корпораций, они теряют доступ к большим объемам данных. А поскольку сами корпорации, расширяясь, шагают через границы государств, географические барьеры еще больше затрудняют доступ к информации, а лучше сказать, к знаниям корпорации. Эти и другие факторы заставляют как большие, так и малые компании искать новые методы управления знаниями. Можем ли мы сегодня создать систему, которая охватывала бы все необходимые сотрудникам корпорации знания и обеспечивала бы доступ к ним? По данным одного из отчетов, 40% компаний, входящих в список «Fortune 1000» , имеют в своем составе специального сотрудника (CKO -Chief Knowledge Officer), ответственного за создание инфраструктуры и развитие культуры совместного использования знаний .
Итак, что такое «управление знаниями» (Knowledge Management - KM)? Начнем с самого простого объяснения. КМ - это установленный в корпорации формальный порядок работы с информационными ресурсами для облегчения доступа к знаниям и повторного их использования с помощью современных информационных технологий. При этом знания классифицируются и распределяются по категориям в соответствии с предопределенной, но развивающейся онтологией структурированных и полуструктурированных баз данных и баз знаний. Основная цель КМ - сделать знания доступными и повторно используемыми на уровне всей корпорации.
Ресурсы знаний различаются в зависимости от отраслей индустрии и приложений, но как правило, они включают руководства, письма, новости, информацию о заказчике, сведения о конкурентах и данные, накопившиеся в процессе работы. Для применения систем КМ используются разнообразные технологии: электронная почта; базы и хранилища данных; системы групповой поддержки; браузеры и системы поиска; корпоративные сети и Internet; экспертные системы и системы баз знаний; интеллектуальные системы.
В системах искусственного интеллекта базы знаний генерируются для экспертов и систем, основанных на знаниях, в которых компьютеры используют правила вывода для получения ответов на вопросы пользователя. Хотя приобретение знаний для получения компьютерных заключений все еще остается важным вопросом, большинство современных разработок КМ обеспечивают знания в удобной для восприятия форме, или поставляют ПО для обработки этих знаний.
Традиционно проектировщики систем КМ ориентировались лишь на отдельные группы потребителей - главным образом менеджеров, работающих с тем, что обычно называется Исполнительной информационной системой (EIS -Executive Information System). Такая система содержит набор инструментальных средств для нисходящего доступа к базам данных, - все, что необходимо для поддержки принятия решений в процессе управления корпорацией. Более современные КМ системы спроектированы уже в расчете на целую организацию. Если руководству организации необходим доступ к информации и знаниям, рядовые сотрудники тоже могут быть заинтересованы в этой информации. Кроме того, технология КМ идеально подходит для рабочих групп, не связанных с управлением, например, групп поддержки клиентов, когда запросы пользователей и ответы на них кодируются и вводятся в базу данных, доступную всем сотрудникам компании, обслуживающим клиентов.
Чем больше накапливается информации, тем сложнее становится хранить ее на бумажных носителях или запоминать. К несчастью, бумажные документы имеют ограниченный доступ, и их трудно изменять. А если из организации уходит высококвалифицированный специалист, потеря ценных знаний и опыта зачастую оказывается для компании невосполнимой. Поэтому предприятия сейчас переходят к использованию хранилищ данных, чтобы все сотрудники могли использовать накопленную информацию, вносить при необходимости изменения, архивировать данные и т. д.
Хранилища данных
Во многих компаниях одним из первых инструментариев КМ были хранилища данных, которые работают по принципу центрального склада. Хранилища данных отличаются от традиционных БД тем, что они проектируются для поддержки процессов принятия решений, а не просто для эффективного сбора и обработки данных. Как правило хранилище содержит многолетние версии обычной БД, физически размещаемые в той же самой базе. Данные в хранилище не обновляются на основании отдельных запросов пользователей. Вместо этого вся база данных периодически обновляется целиком.
Хранилища данных могут быть очень внушительных размеров. Например, банк Chase Manhatten Bank имеет хранилище объемом более 560 Гбайт, компания MasterCard OnLine - 1,2 Тбайт. Когда все данные содержаться в едином хранилище, изучение связей между отдельными элементами данных может быть более плодотворным, а результатом анализа становятся новые знания. Альтернативный подход, называемый «разведка знаний», применяется для поиска в данных дополнительных, скрытых в них знаний.
Хранилища знаний
Если хранилища данных содержат в основном количественные данные, то хранилища знаний ориентированы в большей степени на качественные данные. КМ-системы генерируют знания из широкого диапазона баз данных (включая Lotus Notes), хранилищ данных, рабочих процессов, статей новостей, внешних баз, Web-страниц (как внешних, так и внутренних), и конечно, люди, представляют свою информацию. Таким образом, хранилища знаний подобны виртуальным складам, где знания распределены по большому количеству серверов.
|
Наиболее интересные Web-узлы с информацией по хранилищам данных: http://www.cio.com/CIO http://pwd.starnetinc.com/larryg http://www.dw-institute.com/lessons http://www.dbpd.com http://www.dbnet.ece.ntua.gr/~dwq http://www.credata.com |
В некоторых случаях в роли интерфейса к реляционной базе данных может выступать Web браузер. Например, компания Ford Research and Development использует СУБД Oracle, доступную для просмотра с помощью Web-браузеров. База данных содержит руководства и правила проектирования, спецификации и требования. Другим распространенным корпоративным приложением является база знаний кадровых ресурсов, содержащих данные о квалификации и профессиональных навыках сотрудников. Эта информация может включать данные об образовании, перечень специальностей, сведения об опыте работы и т. д.
В свое время система Lotus Notes обеспечила один из первичных инструментариев для хранения качественной и документальной информации. Однако сегодня, в связи с бурным развитием Internet, КМ-системы в корпоративных решениях все чаще используют Web-технологии.
Базы данных и базы знаний
Знания можно извлекать из рабочих процессов, обзоров новостей и широкого диапазона других источников. Знания, приходящие из рабочих процессов, базируются на рабочих материалах, предложениях и т. п. Кроме того, базы знаний могут быть спроектированы в расчете на ведение хронологии деятельности предприятия, касающейся, например, работы с клиентами.
Базы данных для обучения. Обучающие БД могут использоваться для поддержки операций или генерации информации о бизнесе в целом. Например, обучающая база данных Национального агентства безопасности (NSA - National Security Agency) содержит три типа уроков: информационные, уроки успеха и проблемы . Информационный урок может описывать, как служащий NSA принимает на себя временные обязанности в случае опасности. В «Уроках успеха» приводится позитивный опыт разрешения трудной ситуации. В «Уроках по проблемам» показаны примеры типичных ситуаций возникновения ошибок и возможные пути их устранения. Аналогично, компания Ford Motor имеет специальные файлы TGRW (things gone right/wrong - события, которые могут происходить правильно или неправильно) , в которых собирается информация о действиях, облегчающих выполнение задачи и о разного рода препятствиях. Обычно первый тип знаний бывает легче собрать хотя бы из-за того что, если знания архивируются, то мало кто из служащих захочет, чтобы его имя было связано с возникающими в корпорации проблемами.
|
Наиболее интересные Web-узлы с информацией по хранилищам знаний: http://ksi.cpsc.ucalgary.ca/AIKM97/ http://www.apqc.org/b2/ http://www.km-forum.org http://www.sveiby.com.au http://www.bring.com/OrgLrng.htm |
Базы знаний оптимальных решений. Обычно подобные знания накапливаются в процессе использования различных тестов при поиске эффективных путей решения задач. После того как организация получила знания о наилучшем решении, доступ к ним может быть открыт для сотрудников корпорации. Например, компания Huges Electronics, входящая в состав General Motors, ведет базу данных лучших проектов реконструкции предприятий. С каждым проектом связывается краткое описание и информация для контакта с ответственными лицами. Часть данных может меняться в ходе реконструкции. Когда подобная информация доступна в простой базе данных, можно надеяться, что она будет востребована кем-то еще в организации. Консалтинговые фирмы были одними из первых, кто начал разработку БД оптимальных решений для помощи своим клиентам.
Обзоры новостей обеспечивают средства формального интегрирования внешней информации. Например, компания KPMG оказывающая профессиональные услуги, занимается фильтрацией, сортировкой и предварительным подбором новостей для своих заказчиков .
Разведка знаний
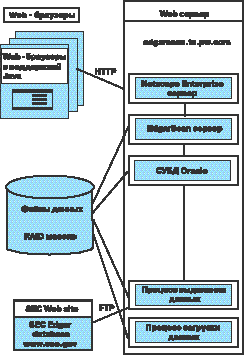 Рис.1. Архитектура системы EdgarScan | Разведка знаний представляет собой новое и быстро развивающееся направление, использующее методы искусственного интеллекта, математики и статистики для «выуживания» знаний из хранилищ данных. Грегори Пятецки-Шапиро и Вильям Фролей определяют термин «разведка знаний» как «нетривиальное извлечение точной, ранее неизвестной и потенциально полезной информации из данных» . Этот метод включает инструментарий и различные подходы к анализу как текста, так и цифровых данных. Например для генерации знаний из финансовой информации в системе EDGAR (Electronic Data Gathering and Retrival System) была разработана система EdgarScan, благодаря которой информация стала доступной в Internet (http://edgarscan.tc.pw.com). Данные периодически извлекаются из системы EDGAR (http://www.sec.gov) и запоминаются в базе Oracle (Рис.1). Наличие доступа к этой числовой информации дает пользователям возможность отслеживать изменения в процессе сравнения различных предприятий. |
Другая система Odie (On demand Information Extractor) каждую ночь сканирует около 1000 статей с последними новостями для извлечения знаний об изменениях в управлении . Odie, разработанная для американских и европейских обозревателей новостей, использует распознавание стилизованных фраз в статьях деловых новостей и знания о синтаксических правилах для распознавания соответствующих событий в сфере бизнеса. Сейчас исследуется возможность использования функции , которая отслеживает полуструктурированный текст для сбора информации о других типах событий, связанных с бизнесом, например, крупных приобретений.
Представление знаний
Системы КМ представляют знания как в форме, удобной для нашего восприятия, так и в машиночитаемом виде. В первом случае доступ к знаниям можно получить используя браузеры и системы интеллектуального поиска. Но иногда знания, доступные в машиночитаемой форме, могут быть спроектированы как базы знаний экспертных систем для поддержки принятия решений.
В представлении знаний для восприятия человеком используется широкий диапазон подходов, и способ представления знаний во многом зависит от ситуации. Например, автор данной статьи помогал разрабатывать КМ-систему для обслуживания клиентов в области модемной связи . Система собирала данные об определенных модемах (технические спецификации, данные, картинки и т. д.) и обобщала их в базе знаний. Если у клиента возникал вопрос или желание посмотреть, как выглядит конкретный модем, все необходимое можно было найти в базе знаний. Поскольку отдел поддержки клиентов ведет учет возникающих затруднений, то все случаи обращения пользователей индексируются по клиентам, модемам и типам проблем. Соответственно, если кто-то уже сталкивался с подобной проблемой, то ее решение можно обнаружить в базе данных.
В других случаях, когда информация имеет декларативный характер (факт или утверждения), текст или правила могут использоваться для представления информации и знаний. Например, руководства, информационные бюллетени или другие подобные типы знаний обычно выглядят как документы, списки или правила (хотя могут быть добавлены связи между знаниями для упрощения поиска и понимания). Организационные правила основаны на общепринятых нормах поведения и записываются обычно в форме «Если А, то В». Например, «если у Вас рождается ребенок, то Вам полагается 8 недель отпуска». Подобные адаптированные правила могут в дальнейшем использоваться в базах знаний, основанных на правилах.
С другой стороны, если информация фильтруется, то она может быть представлена как набор декларативных утверждений, не зависящих от конкретной ситуации. Хотя фильтрация позволяет быть уверенным, что знания полны и непротиворечивы, но могут быть несколько упрощены по сравнению с исходной информацией.
Используя машиночитаемые знания, экспертные системы «подводят» пользователя к рекомендованным решениям. Экспертные системы могут быть интегрированной частью КМ-систем. Хотя последние иногда содержат элементы искусственного интеллекта, эти элементы используются только для поиска знаний, представленных в форме, удобной для восприятия человеком. Необходимы исследования для расширения сферы использования искусственного интеллекта и базирующихся на знаниях систем в КМ. Нам нужно узнать, какие формы представления знаний лучше подходят для конкретных типов знаний и как искусственный интеллект может быть в дальнейшем интегрирован в КМ-системы.
Онтологии
Онтология - это точное описание концептуализации . В КМ-системах корпорации онтологические спецификации могут ссылаться на таксономию задач, которые определяют знание для системы (Таксономия - теория классификации и систематизации сложноорганизованных областей деятельности, обычно имеющих иерархическое строение. Прим. пер.). Онтология определяет словарь, совместно используемый в КМ-системе для упрощения коммуникации, общения, запоминания и представления. Разработка и поддержка онтологии в масштабе целого предприятия требует постоянных усилий для ее развития. Онтология, в частности, необходима для того, чтобы пользователь мог работать с базами данных оптимальных решений, относящихся к широкому кругу проблем предприятия и легко распознавать, какое решение может ему подойти в конкретной ситуации. Так как предприятия часто вовлечены в различные виды деятельности, то для одной КМ-системы может потребоваться несколько онтологий. Для транснациональных компаний онтология должна быть переведена на разные языки, чтобы хранящаяся в базах знаний информация была доступна всем сотрудникам.
По мере необходимости практически все предприятия, использующие КМ-системы, разрабатывали свою собственную онтологию. Поскольку разработка онтологий требовала определенных капиталовложений, компании рассчитывали получить с их помощью преимущество перед конкурентами. По крайней мере одна корпорация выразила заинтересованность в разработке совместно используемой многими компаниями онтологии для того, чтобы спроектировать систему в сжатые сроки и с меньшими затратами. Со временем отрасли промышленности придут, вероятно, к коалиции или к форме подписки на централизованное обслуживание по тем же самым причинам.
Другие описательные атрибуты знаний
Кроме онтологии, для использования знаний огромное значение имеют дополнительные описательные атрибуты. Примерами описательных атрибутов могут служить: «сотрудник», «организация» и «статус информации». Теоретически все базы знаний хранят информацию о контакте или сотруднике, включая имя, дату контакта, роль контактирующего лица в генерации знаний (например, руководитель проекта) и т. д. Многие базы знаний хранят организационную информацию, например, сведения о том, в каком подразделении разработан проект или собраны знания. Статус информации также представляет собой типичный описательный атрибут и может включать, например, признак состояния данного элемента: планируемый, применяемый сегодня или уже использовавшийся. Это может быть также запись о том, предназначена информация только для внутреннего использования или же может быть распространена за пределами организации.
Фильтрация знаний
Качество и актуальность знаний зависит от многих факторов. Например от того, кто поставляет знания в систему. Поскольку качество знаний изменяется от источника к источнику, системы часто пересортировывают знания, чтобы они были полными и достоверными. Например, компания GM Hughes Electronics собирает удачный опыт реконструкции предприятий в базе данных, комбинируя человеческие и компьютеризированные знания. Редактор просматривает каждую позицию базы данных и определяет, насколько она полезна и уместна . В Национальном Агентстве Безопасности команда из пяти человек принимает решение о том, включать ли предлагаемые уроки в обучающую базу данных .
| К сожалению, качество и актуальность знаний, помещаемых в базу, зависит от множества факторов, например, от источника знаний |
Фильтрация не всегда выполняется сотрудниками компании. Чаще всего используется фильтрация сообщений электронной почты по приоритетам и категориям. Кроме того, применяются различные средства, позволяющие отслеживать качество баз данных. Оценка обычно зависит от потребностей конкретных сотрудников, рабочих групп или интересов всего предприятия. Однако в таких системах степень важности поступающей информации существенно зависит от пользователя: одни могут охарактеризовать информацию как «очень важная», «важная» и т.д. Другие решают, каким уровнем должна быть помечена информация перед тем, как она будет им доставлена. Допустим, очень занятому менеджеру, вероятно, было бы удобно, чтобы информация называлась «очень важной». Таким образом, информация, отмеченная ранее, как «важная», не попадет в число «очень важной», и менеджер не всегда увидит необходимую или очень важную информацию. В свою очередь менеджер может установить свой уровень важности, чтобы быть уверенным, что вся действительно «очень важная» информация будет получена. В конечном итоге, это приводит не только к «инфляции» важности, но и к наводнению информацией, а именно с ним такая система и должна бороться.
Поиск знаний
Базы знаний могут быть очень большими. Например, база Ford имела в июне 1997 г. объем, эквивалентный 30 тыс. страниц бумажного текста . Базы знаний обычно содержат огромное количество информации, поэтому поиск нужной информации становится экстремально критической функцией. Большинство современных методов поиска включают инструментальные средства, средства интеллектуального поиска и визуальные модели.
Инструментальные средства
Широкий диапазон хорошо известных инструментальных средств поиска (AltaVista, Excite, Infoseek, Lycos, WebCrawler, Yahoo) был использован для информационной навигации в Internet. Все они могут быть адаптированы для внутрикорпоративных нужд при работе с КМ-системами. Кроме того, многие компании разработали альтернативные методы условного поиска. Например, Andersen Consulting имеет «центральное хранилище интерфейсов (карты знаний), которые связываются с знаниями» . Пользователи могут выбирать карту для навигации при поиске знаний, хранящихся в многочисленных БД, причем не зная точно, в какой именно базе данных следует искать.
Средства интеллектуального поиска
С помощью средств интеллектуального поиска мы находим нужные данные в информационном наполнении Internet или корпоративных сетей. Например, InfoFinder изучает интересы пользователей по наборам классифицированных ими сообщений или документов. Кроме того, InfoFinder использует эвристические методы для сбора дополнительных, более точных сведений. Базируясь на синтаксисе сообщений, InfoFinder пытается определить ключевые фразы, которые помогают понять задачу пользователя. Например, один из эвристических подходов предполагает извлечение любых слов, целиком состоящих из заглавных букв, таких как ISDN, так как это, вероятно, соответствует представлению аббревиатур или технических имен. Другой эвристический метод заключается в том, чтобы не обращать при этом внимания на слова, если они используются для усиления, например «NOT». Еще один способ - включение перечислений, нумерованных списков, секций заголовков и описаний диаграмм. Все это позволяет InfoFinder находить документы, предугадывая запросы пользователя.
Визуальные модели
Среди новых тенденций в области проектирования систем поиска для эффективных КМ можно выделить метод визуальных моделей. Два инструментария - Perspecta и InXight - представляют различные методы визуализации знаний.
Perspecta (http://www.perspecta.com) создает интеллектуальный контекст, используя метаинформацию, выделенную из исходных документов, включая структурированную информацию в БД и целевых документах, или неструктурированные данные в офисных документах и Web-страницах. Для неструктурированных документов Perspecta имеет специальное средство Document Analysis Engine, которое выполняет лингвистический анализ и автоматически помечает документы. Сервер интеллектуального контекста анализирует помеченную информацию, идентифицирует взаимосвязи между документами и строит многоразмерное информационное пространство, используя специальный язык пометок (Information Space Markup Language). Пользователь «летит» сквозь информационное пространство, манипулируя мышью. Для экономии ресурсов данные выгружаются клиенту с помощью информационного потокового протокола (Information Streaming Transport Protocol), который является расширением HTTP.
Компания InXight Software (http://www.inxight. com), отпочковавшаяся от Xerox PARC, выпустила собственное средство визуализации VizControl, предлагающее несколько форматов визуализации. Каждый из них развивает метод «фокус контекст», когда интересующие пользователя данные выводятся на передний план и в тоже время сохраняется структура даже очень больших наборов данных. Одно из таких инструментальных средств, гиперболический браузер (или «рыбий глаз»), использует гиперболическую геометрию для расширения информационного пространства при работе с иерархическими структурами, которые расширяются экспоненциально с увеличением глубины. Таким образом, гиперболический браузер может показать 1000 узлов в окне размером 600х600 пикселов, в центре которого высвечивается текст довольно большого объема (для сравнения, условный 2D-браузер может показать на экране лишь около 100 узлов) . Пользователь перемещается по информационному пространству, щелкая мышью на узле или передвигая указатель мыши по гиперболической плоскости.
Эксплуатация КМ-систем требует определенной культуры совместного использования знаний. Применяется ли КМ централизованно (как, например, в Buckman Laboratories, где отдел информационных систем превратился в отдел передачи знаний ), или в децентрализованной системе (наподобие той, что использует Hewlett-Packard ) совместное использование знаний в любом случае актуально. Как утверждает Том Дэйвенпорт , Lotus тратит около 25% от общего объема затрат, чтобы ее служба поддержки клиентов работала в режиме разделения знания. Buckman Laboratories на своей ежегодной конференции называет 100 ведущих компаний, где практикуется совместное использование знаний. АВВ при оценке менеджеров учитывает не только результаты их решений, но также и знания, использованные в процессе принятия решений.
Способы стимулирования оценки вклада в создание КМ обычно зависят от уровня или функции организации и конкретного приложения, для которого предназначена КМ-система. Группа корпоративного обучения компании Hewlett-Packard предоставила, например, по 2000 бесплатных авиа миль первым пятидесяти читателям и еще по 500 миль всем, кто внес свою лепту в наполнение базы знаний .
Будут ли такие стимулы актуальны в воспитании некоторых культурных норм, при которых служащие будут заинтересованы в том, чтобы участвовать в КМ-системах, мы узнаем позже. Ясно, однако, что внедрять такие системы выгодно, когда предприятия начали применять КМ-системы для обеспечения собственной конкурентоспособности, стало очевидно, что таким способом системы могут упростить повторное использование имеющихся знаний и создавать новые знания, позволяющие заметно усовершенствовать процессы принятия решений.
Литература:
B. Roberts, «Intranet as Knowledge Management», Web Week, Sept. 9, 1996, p.30
L. Payne, «Making Knowledge Managment Real at the National Security Agency,» Knowledge Magement in Practice, Aug./Sept. 1996.
A. Stewart, «Under the Hood at Ford», Webmaster, June 1997, pp.26-34.
T. Davenport, «Some Principles of Knowledge Management», http://www.bus. uteaxas.edu/kman/pubs.htm.
W. Andrews, «Information Feeds that are Tailored to Enterprise Needs», Web Week, April 21, 1997, pp. 32,34.
G. Piatetsky-Shapiro and W. Frawley, Knowledge Discovery in Databases, AAAI Press, Menlo Park, Calif., 1991.
D. Steier, S. Huffman, and D. Kadlish, «Beyond Full Text Search: AI Technology to Support the Knoledge Cycle, «AAAI Spring Symp. Knowledge Management, AAAI Press, Menlo Park, Calif., 1997.
D. O?Leary and P. Watkins, «Integration of Intelligent Systems and Conventional Systems», Int?l J. Intelligent Systems in Accounting, Finance, and Management, Vol. 1, No. 2, 1992, pp. 135-145.
T. Gruber, «A Translational Approach to Portable Ontologies,» Knoledge Acquisition, Vol. 5, №. 2, 1993, pp.199-220.
C. Bernstein, «Global Sharing of Consulting Knowledge,» Knowledge Acquisition, Vol. 5, №. 2, 1993, pp. 199-220.
B. Krulwich and C. Burkey, «The Information Finder Agent: Learning Search Query Strings Through Heuristic Phrase Extraction,» IEEE Expert, Sept.-Oct. 1997, pp. 22-27.
J. Lamping, R. Rao, and P. Piroly, «A Focus+Context Technique Based on Hiperbolic Geometry for visualizing Large Hierarchies,» Proc. SigChi, ACM Press, New York, 1995.
T. Davenport, «Knowledge Management at Hewlett-Packard, Early 1996,» http://www.bus.utexas.edu/kman/pubs.htm, 1997.
Об авторе
Дэниэл Е. О?Лири (Daniel E. O?Leary), главный редактор журнала IEEE Expert, профессор Университета Южной Калифорнии. Его исследовательские интересы: воздействие интеллектуальных факторов на индивидуальные личности, организации и коммерческие структуры, а также интеграция усилий по реконструкции управленческих структур.
Daniel E. O?Leary «Enterprise Knowledge Management», - IEEE Computer, 3, March 1998, pp. 54-61. Reprinted with permission, Copyright IEEE CS. All rights reserved.
