
Нейрон (биологический) - одна из 1015 клеток мозга, способная генерировать электрический импульс, в случае, когда суммарный потенциал превысит критическую величину. Соединяясь друг с другом, нейроны образуют сеть, по которой путешествуют электрические импульсы. Контакты между нейронами (синапсы), могут менять эффективность передачи сигналов (вес связи) от нейрона к нейрону. Самая популярная на сегодняшний день гипотеза основана на том, что именно нейронные сети мозга обрабатывают информацию. При этом «обучение» сети и запоминание информации базируется на настройке значений весов связей между нейронами.
Нейрокомпьютинг - это технология создания систем обработки информации (например, нейронных сетей), которые способны автономно генерировать методы, правила и алгоритмы обработки в виде адаптивного ответа в условиях функционирования в конкретной информационной среде. Нейрокомпьютинг представляет собой фундаментально новый подход, а рассматриваемые в рамках этого подхода системы обработки информации существенно отличаются от упомянутых ранее систем и методов. Данная технология охватывает параллельные, распределенные, адаптивные системы обработки информации, способные «учиться» обрабатывать информацию, действуя в информационной среде. Таким образом, нейрокомпьютинг можно рассматривать как перспективную альтернативу программируемым вычислениям, по крайней мере, в тех областях, где его удается применять.
Новый подход не требует готовых алгоритмов и правил обработки - система должна «уметь» вырабатывать правила и модифицировать их в процессе решения конкретных задач обработки информации. Для многих задач, где такие алгоритмы неизвестны, или же известны, но требуют значительных затрат на разработку ПО (например при обработке зрительной и слуховой информации, распознавании образов, анализе данных, управлении), нейрокомпьютинг дает эффективные, легко и быстро реализуемые параллельные методы решения. Заметим, что представляет интерес также и обратная задача: анализируя обученную систему, определить разработанный ею алгоритм решения задачи.
Информационные структуры, которые в первую очередь входят в область нейрокомпьютинга - это нейронные сети, хотя иногда рассматриваются и другие классы адаптивных структур обработки информации: обучающиеся автоматы; генетические обучающиеся системы; системы запоминания информации, адаптирующиеся к конкретным данным; имитационные системы, работающие по принципу «отжига»; ассоциативные системы памяти; обучающиеся системы, построенные на принципах нечеткой логики.
Модельная нейронная сеть (artificial neural network) - это параллельная система обработки информации, состоящая из обрабатывающих элементов (нейронов), которые локально выполняют операции над поступающими сигналами и могут обладать локальной памятью. Элементы связаны друг с другом однонаправленными каналами передачи сигналов. Каждый обрабатывающий элемент имеет единственный выход, иногда разветвляющийся на несколько каналов (связей), по каждому из которых передается один и тот же выходной (результирующий) сигнал обрабатывающего элемента. Правила образования результирующего сигнала (правила обработки информации внутри элемента) могут варьироваться в широких пределах, важно лишь, чтобы обработка была локальной. Это означает, что обработка должна зависеть от текущих значений входных сигналов, поступающих на элемент через связи и от значений, хранящихся в локальной памяти элемента.
Считается, что теория нейронных сетей, как научное направление, впервые была обозначена в классической работе МакКаллока и Питтса 1943 г., в которой утверждалось, что, в принципе, любую арифметическую или логическую функцию можно реализовать с помощью простой нейронной сети. В 1958 г. Фрэнк Розенблатт придумал нейронную сеть, названную перцептроном, и построил первый нейрокомпьютер Марк-1 . Перцептрон был предназначен для классификации объектов. На этапе обучения «учитель» сообщает перцептрону к какому классу принадлежит предъявленный объект. Обученный перцептрон способен классифицировать объекты, в том числе не использовавшиеся при обучении, делая при этом очень мало ошибок.
Новый взлет теории нейронных сетей начался в 1983-1986 г. г. При этом важную роль сыграли работы группы PDP (Parallel Distributed Processing) . В них рассматривались нейронные сети, названные многослойными перцептронами, которые оказались весьма эффективными для решения задач распознавания, управления и предсказания. (Многослойные перцептроны занимают ведущее положение, как по разнообразию возможностей использования, так и по количеству успешно решенных прикладных задач.)
Многослойный перцептрон
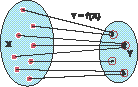 Рис.1. Функция f ставит в соответствие каждому вектору X из m - мерного пространства некоторый вектор Y из p-мерного пространства |
Рассмотрим функцию Y=f(X), которая ставит в соответствие m-мерному вектору X некоторый p-мерный вектор Y (Рис. 1). Например, в задаче классификации вектор X- это классифицируемый объект, характеризуемый m признаками; вектор Y, состоящий из одной единицы и остальных нулей, является индикатором класса, к которому принадлежит вектор X (позиция единицы означает номер класса). Функция f ставит в соответствие каждому объекту тот класс, к которому он принадлежит. |
Предположим, нам нужно найти функцию f. Воспользуемся методом обучения на примерах. Предположим, что имеется репрезентативная выборка векторов Xi, для которых известно значение функции Yi=f(Xi). Набор пар (Xi,Yi) будем называть обучающей выборкой. Рассмотрим теперь нейронную сеть, называемую многослойным перцептроном, определив, как устроены элементы сети («нейроны»), какова архитектура связей между элементами и по каким правилам будет происходить обучение сети.
Элемент сети функционирует в дискретном времени и на основании поступивших сигналов формирует результирующий сигнал. Элемент имеет несколько входов, каждому из которых предписан определенный «вес». Сигналы, поступающие по входам, суммируются с учетом соответствующих весов, и суммарный сигнал сравнивается с порогом срабатывания. Если суммарный сигнал меньше порога, то сигнал на выходе элемента близок или равен нулю, в противном случае сигнал близок к единице.
Каждый элемент входного слоя имеет один вход (с весом 1), по которому поступает соответствующая компонента вектора X. Каждый элемент скрытого слоя получает сигналы ото всех элементов входного слоя. Тем самым, элемент скрытого слоя имеет m входов, связывающих его с элементами входного слоя. Связи от элементов входного слоя к элементам скрытого слоя характеризуются матрицей «весов» связей w1, компоненты которой определяют величину эффективности связи. Каждый элемент выходного слоя получает сигналы ото всех элементов скрытого слоя. Таким образом, подавая на входной слой сети вектор X, мы получаем вектор активности элементов скрытого слоя и затем вектор Y на элементах выходного слоя. Результат работы сети зависит от числовых значений весов связей между элементами.
Обучение сети состоит в правильном выборе весов связей между элементами. Выбираются такие веса связей, чтобы суммарная среднеквадратичная ошибка для элементов обучающей выборки была минимальной. Достичь этого можно разными методами . После обучения перцептрона проводится процедура тестирования, позволяющая оценить результаты работы. Для этого обучающую выборку обычно делят на две части. Одна часть используется для обучения, а другая, для которой известен результат, задействована в процессе тестирования. Процент правильных результатов работы сети на этапе тестирования является показателем качества работы перцептрона.
Надо сказать, что для очень многих практических задач удается достичь на удивление высокого качества работы сети (порядка 95% и выше). Существует ряд математических теорем , обосновывающих возможность применения многослойных перцептронов для аппроксимации достаточно широкого класса функций f.
Проиллюстрируем применение многослойных перцептронов на примере решения задачи сжатия информации. Такая необходимость часто возникает в различных приложениях, в частности, при распознавании образов существует этап предобработки, когда исходные данные представляются в компактной, удобной форме. Результаты этого этапа зачастую определяют успех в решении задачи распознавания.
Популярный метод сжатия информации был предложен в 1987 г. G.Cottrell, P.Munro, D.Zipser . Рассмотрим трехслойный перцептрон, у которого число элементов входного и выходного слоев одинаково, а число элементов скрытого слоя значительно меньше. Предположим, что в результате обучения на примерах (на векторах обучающей выборки) перцептрон может воспроизводить на выходе тот же самый вектор X, который подается на входной слой перцептрона. Такой перцептрон автоматически осуществляет сжатие информации: на элементах скрытого слоя возникает представление каждого вектора, которое значительно короче, чем длина вектора, подаваемого на вход. Предположим, что некоторый набор векторов нужно передавать по линии связи, предварительно сжимая информацию и тем самым уменьшая число каналов, необходимых для ее передачи. Поместим на одном конце линии входной и скрытый слои перцептрона, а результат работы элементов скрытого слоя (короткие векторы) будем передавать по линии связи. На другом конце линии поместим копию скрытого слоя и выходной слой, тогда переданный короткий вектор с элементов скрытого слоя перейдет на элементы выходного слоя, где будет воспроизведен исходный вектор (декомпрессия).
Решение конкретных задач
При решении конкретной задачи, связанной с анализом или обработкой каких-либо данных, удобно предположить, что анализируемые данные являются векторами многомерного евклидова пространства, где они располагаются в соответствии с некоторой функцией распределения. Примерами таких задач могут служить измерения, полученные в ходе физических, биологических и других экспериментов, результаты медицинской диагностики, телеметрическая информация и многое другое. Каждый вектор мы будем называть объектом, а координаты вектора - признаками. При этом размерность пространства признаков (обозначим ее m) может достигать десятков тысяч. Например, величины яркостей в последовательно расположенных m пикселах изображения, или же m последовательных точек в звуковом потоке. Другими словами, будем считать, что данные возникают в процессе работы генератора случайных объектов, который в соответствии с функцией распределения порождает векторы заданной длины m.
Опыт решения реальных задач показывает, что объекты не заполняют все m- мерное пространство, а располагаются, как правило, на некоторой поверхности, имеющей невысокую размерность (десятки, сотни). Это означает, что существуют такие «обобщенные» признаки (комбинации исходных признаков), которые наиболее точно характеризуют исходные объекты.
Существует такой способ кодирования данных, называемый переходом к «естественным» координатам, который, в определенном смысле, можно считать оптимальным. Доказана единственность системы «естественных» координат, а также известно, что эти координаты обладают рядом важных свойств, например, признаки объектов в «естественных» координатах являются попарно независимыми. «Естественные» координаты могут использоваться для широкого класса вероятностных распределений.
Для нахождения «естественных» координат предлагается использовать многослойные перцептроны определенного типа, которые называются репликативными (копирующими) нейронными сетями. Показано, что в процессе обучения адаптивной репликативной нейронной сети можно построить систему «естественных» координат, которая соответствует данным, использованным для обучения. Оказалось, что в результате перехода к системе «естественных» координат происходит не только значительное сокращение размерности задачи, но и фильтрация шума, который мог присутствовать в исходных данных.
Естественные координаты
Рассмотрим некий генератор данных в m-мерном пространстве. Предположим, что генерируемые им данные заполняют не все пространство, а лишь некоторое многообразие размерности n, где n << m. Многообразие, на котором расположены данные, можно представлять как сложную поверхность, которая в окрестности каждой своей точки похожа на поверхность n - мерной сферы. Утверждается, что на многообразии существует такая функция распределения, которая сколь угодно близка к исходной функции распределения генератора в смысле средних значений. Это утверждение позволяет вместо исходных данных, представляемых большим числом признаков, рассматривать генератор данных в пространстве небольшого числа измерений. В большинстве практических задач встречается именно такая ситуация.
Естественные координаты вводятся следующим образом. Рассмотрим взаимно-однозначное непрерывное отображение n-мерного многообразия в n-мерный единичный куб. Это означает, что каждый вектор X, лежащий на n-мерном многообразии, представляется вектором с n координатами, причем каждая координата является числом, равномерно распределенным между нулем и единицей.
Метод естественных координат является обобщением метода главных компонент. Естественные координаты точно так же зависят только от внутренней, заранее определенной, вероятностной структуры многообразия данных: равные объемы внутри единичного куба соответствуют множествам с равной вероятностью на многообразии данных, хотя их геометрические размеры могут значительно различаться. Однако в отличие от метода главных компонент, где используются декартовы координаты, естественные координаты могут отражать более сложную вероятностную структуру многообразия данных.
Естественные координаты - это единственная координатная система из независимых компонент, которая обеспечивает оптимальное кодирование информации, с учетом вероятностной структуры генератора данных.
Репликативные нейронные сети
Как построить естественные координаты для какого-либо генератора данных? Рассмотрим репликативную нейронную сеть - многослойный перцептрон с тремя скрытыми слоями, число элементов входного и выходного слоев которого одинаково. Первый и третий скрытые слои состоят из обычных для многослойного перцептрона элементов, с S-образной передаточной функцией. Размеры этих слоев подбираются в процессе обучения сети.
Для вектора длины m, подаваемого на входной слой, строится его отображение f в единичный куб. Для обученной сети это отображение реализует представление исходного вектора в системе естественных координат u, которое воспроизводится в среднем скрытом слое. Дальнейшее прохождение информации от среднего скрытого слоя до выходного слоя дает отображение g (обратное f) из единичного куба в исходное m-мерное пространство с заданной функцией распределения F(x).
Средний скрытый слой состоит из n элементов, где n - предполагаемая размерность многообразия данных. Передаточная функция элементов среднего скрытого слоя имеет вид наклонной или ступенчатой функции.
Цель обучения репликативной нейронной сети состоит в том, чтобы вектор, воспроизводимый выходным слоем сети, совпадал с вектором, поданным на входной слой. Передаточная функция элементов выходного слоя выбирается линейной. Обучение проводится на обучающей выборке, полученной с помощью генератора данных с функцией распределения F(x). Утверждается, что обученная репликативная нейронная сеть строит в среднем скрытом слое представление исходных векторов в естественных координатах. Таким образом, входной вектор длины m передается на средний слой и там представляется естественными координатами в n-мерном единичном кубе (n << m). Дальнейшая передача информации по сети от среднего скрытого слоя к выходному дает обратное отображение: вектор в естественных координатах переходит в m-мерный вектор, расположенный близко к входному.
Удаление шума. Репликативная сеть имеет еще одно интересное свойство: она способна удалять аддитивный шум, присутствующий в исходных данных. Предположим, что вектор данных состоит из двух слагаемых: информационной части вектора и шумового случайного компонента, выбираемого в каждой точке многообразия данных в соответствии с условной плотностью распределения. Утверждается, что репликативная нейронная сеть приводит шумовой компонент к среднему значению, и результат, получаемый на выходе сети, является суммой двух слагаемых: информационной части вектора (такая же как и у входного вектора) и среднего значения шума в данной точке многообразия. Если среднее значение равно нулю, то выходной слой воспроизводит правильную информационную компоненту вектора, удаляя случайный шум. То же самое верно и для среднего скрытого слоя, где к вектору естественных координат добавляется среднее значение шума. Полученный результат позволяет объяснить известное наблюдение, что репликативные нейронные сети способны выполнять «чистку» анализируемых данных.
Определение размерности. До сих пор мы предполагали, что размерность многообразия данных n известна. К сожалению, такое бывает достаточно редко. Тем не менее эту размерность можно оценить. Рассмотрим большое количество данных, произведенных генератором и упорядочим их по возрастанию евклидова расстояния до некоторой фиксированной точки из этого же набора. Такое упорядочение данных позволяет оценить размерность многообразия вблизи зафиксированной точки.
Возьмем первые k векторов из упорядоченного набора, рассмотрим гауссовский ковариационный эллипсоид и определим количество не слишком коротких осей эллипсоида. Эту величину назовем локальной размерностью и нарисуем график ее зависимости от числа k. Обычно этот график линейно возрастает при увеличении k, но при некотором его значении наклон графика резко уменьшается и на графике образуется «колено». Соответствующую величину k будем рассматривать как аппроксимацию размерности в окрестности выбранной точки. Повторяя описанную процедуру определения локальной размерности для других точек, находим оценку размерности многообразия данных n, как наибольшее из значений локальной размерности. Найденная размерность n используется в качестве размерности системы естественных координат.
Если значение n, используемое для нахождения естественных координат, меньше, чем реальная размерность многообразия данных, то полученные естественные координаты будут образовывать решетку, заполняющую все пространство, подобно фракталу, похожему на ковер Серпинского. С другой стороны, если значение n больше, чем реальная размерность, то координатные объемы в естественной системе координат будут «сплюснуты» в такие множества, у которых по крайней мере один характерный размер много меньше других. Таким образом, чтобы найти правильное значение размерности, нужно маневрировать между Сциллой заполнения пространства (когда величина размерности выбирается слишком малой) и Харибдой сильной деформации координатной решетки в естественных координатах (когда величина размерности выбрана слишком большой).
Знание размерности многообразия данных и выбор правильного значения величины n может помочь избежать неэффективного использования системы естественных координат. Аналогичное замечание справедливо и для векторов «испорченных» шумом, где также нужно выбрать число элементов в среднем скрытом слое, после чего сеть может быть натренирована для очистки шума.
В заключение скажем несколько слов об обучении репликативных нейронных сетей и настройке архитектуры сети. Известно, что обучение многослойного перцептрона с тремя скрытыми слоями - задача весьма сложная. Полутоновое изображение размером 192 х 256 пикселей (слева) было сжато, а затем, с помощью частично обученной репликативной нейронной сети возвращено к исходному размеру. Сначала изображение разделяется на непересекающиеся фрагменты размером 64 х 64 пиксела. Полученный 4096-мерный вектор, компоненты которого являются восьмибитовым числами, означающими яркость пиксела, подается на вход нейронной сети для обучения. Репликативная нейронная сеть имеет m=4096 элементов во входном и выходном слоях, n=40 элементов в среднем скрытом слое и по 410 элементов в первом и третьем скрытых слоях. Реализуемый такой сетью коэффициент сжатия - 102,4 : 1. Количество настраиваемых в процессе обучения весов связей равно 3 396 476. После реконструкции изображения границы между фрагментами были сглажены.
Один из подходов к обучению репликативной нейронной сети основан на том, что мы знаем, каким должен быть выходной сигнал у элементов среднего скрытого слоя. Это должны быть естественные координаты. Таким образом, можно использовать такой метод обучения, благодаря которому элементы среднего скрытого слоя более активно производят выходные сигналы, равномерно и плотно заполняющие внутреннюю часть n- мерного единичного куба, а также обладают свойствами естественных координат. Также очень важно использовать на этапе обучения ступенчатую функцию в качестве передаточной функции элементов среднего скрытого слоя.
Практическое использование репликативных нейронных сетей
Решающим аргументом в вопросе о практическом применении репликативных сетей является то обстоятельство, что подавляющее большинство генераторов данных сильно структурированы и могут быть смоделированы посредством многообразия данных с относительно малой размерностью n. Прежде всего это означает, что если может быть построена подходящая система естественных координат (не фрактальная и не «сплюснутая»), то эти координаты можно задействовать вместо исходных векторов данных. Такой подход заметно упрощает решение многих задач распознавания образов, управления, сжатия информации и т.д., поскольку вместо исходных векторов с большим числом признаков m, могут использоваться естественные координаты с малым числом компонент n (обычно m намного больше чем n).
Интересно отметить, что репликативные нейронные сети дают компактное и эффективное представление произвольных наборов векторов, имеющих сложное вероятностное распределение в пространстве, за счет того, что средний скрытый слой имеет меньше элементов, чем входной и выходной слои.
Анализ экспериментальных данных, полученных при изучении коры головного мозга, показывает, что задачи «правильного» кодирования информации, сжатия информации, перехода от одного способа представления информации к другому решаются нейронными сетями коры на различных этапах обработки сенсорных сигналов. Вполне возможно, что основная функция коры головного мозга - создание, поддержка, обучение и использование такого рода нейронных сетей. Если окажется, что аналоги репликативных нейронных сетей (для представления информации и фильтрации шума) действительно существуют в коре мозга, то изложенные здесь результаты можно будет сформулировать гораздо проще, что позволит разработать новые практические методы нейрокомпьютинга. Эта возможность несомненно заслуживает внимания исследователей.
Будущее нейрокомпьютинга
О нейрокомпьютинге впервые заговорили в 1940-гг., затем после разработок 1950-х и 1960-гг. наступил период затишья, длившийся с 1968 по 1985 гг., в 1986 г. начался ренессанс, и сейчас можно сказать, что скоро мы станем свидетелями небывалого взрывного роста в сфере нейрокомпьютерных технологий. Сегодня уже открыто немало новых возможностей в таких областях как аппроксимация функций, идентификация систем и анализ данных. В широком смысле, такие работы являются важным вкладом в науку и имеют большое экономическое значение.
Однако все попытки понять и смоделировать процессы обработки мозгом информации пока особого успеха не имели. Несмотря на то, что обширные работы по нейронному моделированию ведутся уже более 50 лет, нет ни одной области мозга, где процесс обработки информации был бы ясен до конца. Также ни для одного нейрона в мозге мы пока не можем определить код, который он использует для передачи информации в виде последовательности импульсов. Грядущий взрывной рост в сфере нейрокомпьютерных технологий по всей вероятности будет связан с новыми открытиями в области нейронного моделирования. Как только мы разгадаем тайну функционирования хотя бы одной области мозга, так сразу, по-видимому, получим представление о работе многих других его областей.
Открытие биологических основ обработки информации вызовет невиданную активность в построении искусственного мозга. Это будет беспрецедентный по своему размаху научный и технологический проект. По сравнению с ним прошлые гигантские проекты, такие как исследование космоса, создание ядерного оружия, молекулярная биология и генная инженерия покажутся весьма скромными. Дело в том, что новый проект очень быстро даст огромный экономический эффект. И наконец-то у нас появится возможность строить «умные» машины, известные нам прежде лишь по фантастическим романам, способные многое изменить к лучшему в нашей жизни.
Литература
1. Hecht-Nielsen R. Neurocomputing. Addison-Wesley, 1989
2. Hecht-Nielsen R. Replicator neural networks for universal optimal source coding. Science, v. 269, pp.1860-1863, 1995
3. Hecht-Nielsen R. The nature of real-world data. Workshop on Self- Organizing maps. Helsinki, June 1997.
4. Ф. Розенблатт Принципы нейродинамики. Перцептроны и теория механизмов мозга. //Москва, Мир, 1965
5. Parallel Distributed Processing: Explorations in the microstructure of cognition. Rumelhart D.E., McClelland J.L. (eds.), v.I, II, MIT Press, 1986
6. А. Горбань , Д. Россиев Нейронные сети на персональном компьютере. //Новосибирск, Наука, 1996.
7] Hecht-Nielsen R. Kolmogorov?s mapping neural network existence theorem. Int. Conf NN, IEEE Press, v. III, pp.11-13, 1987
8. Cottrell G.W., Munro P., Zipser D. Image compression by back propagation: An example of extensional programming. Proc. 9th Annual Confer, Cognitive Soc., pp. 461-473, 1987.
Роберт Хехт-Нильсен (Robert Hecht-Nielsen) - профессор Калифорнийского университета в Сан-Диего (США).
