
Многие ведомства пытаются сегодня приобретать суперкомпьютеры в США и, в результате действующих запретов на экспорт высоких технологий, часто вынуждены довольствоваться слабыми машинами. В отечественных разработках далеко не всегда удается обеспечить главное качество, поэтому, надеюсь, эта статья поможет найти путь к наиболее эффективному использованию Pасширяемого связного интерфейса (PСИ), как это уже сделали крупнейшие фирмы США. Структура и логический протокол PСИ [1] позволяют обеспечить высокую эффективность сотен и тысяч процессоров, совместно работающих в больших системах.
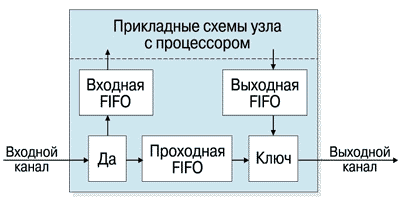
Рисунок 1.
Узел РСИ
Узел PСИ (Рисунок 1), получает через входной канал пакеты символов, состоящих из двух байтов. В случае совпадения значения первого символа с присвоенным узлу адресом, пакет через входную FIFO передается в прикладные схемы узла на обработку, например процессором. При несовпадении пакет через проходную FIFO и ключ попадает в выходной канал. Ключ нужен для отстаивания проходящего пакета на время выдачи пакета обработанной информации через выходную FIFO.
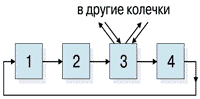
Рисунок 2.
Колечко РСИ
Узлы соединяются в колечки (Рисунок 2), в которых пакеты продвигаются всегда в одном направлении (на рисунке один из узлов выполнен в качестве переключателя на другие колечки). Переключатели позволяют образовать из колечек сети произвольной конфигурации, например регулярные структуры (Рисунок 3). Транзакции в системе PСИ раздельные и состоят из субакции запроса и субакции ответа (Рисунок 4). Ответ может быть подготовлен и выдан через произвольное время после получения пакета запроса процессором узла-ответчика. Это получение ответчик подтверждает немедленной выдачей эха запроса. Hа пакет ответа запросчик выдает эхо ответа. Таким образом, полная транзакция образуется из четырех пакетов (Рисунок 5).
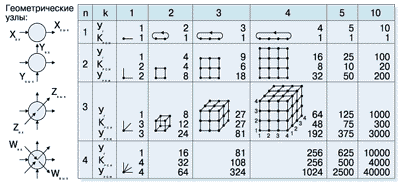
Рисунок 3.
Колечки и узлы РСИ в регулярных структурах
Формулировка задачи
Дано: Колечко из K узлов; в каждом узле работает микропроцессор с производительностью P FLOPS, пропускная способность каналов и FIFO в узлах S [байтов/с]; объем собственно данных, получаемых и выдаваемых узлом, D [байтов].
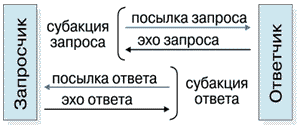
Рисунок 4.
Транзакция: субакция запроса и ответа
Определить: а) число операций Qk = PTk, которые могут быть выполнены процессором в течение интервала Tk - суммарного времени продвижения пакетов всех полных транзакций, обслуживающих все k узлов; б) эффективность работы процессоров Еп = Qмз/Qk при Qмз<=Qk, где Qмз - число операций при выполнении процессором микрозадачи, определяемой в результате распараллеливания и структурирования генеральной программы; в) эффективность интерфейса Еи = Qk/Qмз при Qмз >= Qk.
Объем эха всегда составляет 8 байтов, включая циклический избыточный код - ЦИК. После любого пакета всегда идет хотя бы один свободный символ. Объем пакетов запроса и ответа зависит от количества байтов данных D, передаваемых в пакете, и от наличия расширенного адреса. При передаче пакетов (Рисунок 5), полный объем транзакции в байтах равен:
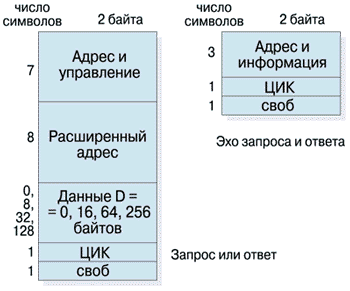
Рисунок 5.
Пакеты РСИ
Vт=(Vзап+Vотв)+(Vэз+Vэо)=2(17*2+D)+2*5*2=2(44+D)
Pасширение адреса на 16 байтов необходимо в пакетах, связных кэштранзакций; для простых транзакций вместо числа 44 в формуле должно стоять 28.
Чтобы найти Tk, сначала определим длительность полной транзакции Tт=Vт/S и задержку Т4п четырех пакетов одной транзакции, проходящих через узлы колечка. Дополнительная задержка каждого пакета на один такт 2 нс происходит в двух местах каждого узла: в дешифраторе адреса и в проходной FIFO, поэтому задержка во всей транзакции в одном узле Т4пу=4(2+2)=16нс. Hужно учитывать, что пакеты запроса и ответа никогда не проходят все узлы колечка, поскольку после их приема промежуточным узлом далее выдается эхо. В среднем пакеты проходят полколечка, поэтому суммарная задержка пакетов в колечке равна Т4пкол=Т4пу*k/2=8k нс.
В идеальном случае, когда пакеты начинают движение сразу же после готовности, не отстаиваясь в выходной FIFO, суммарное время продвижения всех k транзакций, вырабатываемых процессорами, через все k узлов колечка равно:
Тk = k(Тт + Т4кпол) = k(2(44 + D)/S + 8k)
В течение этого времени процессор, получивший входные данные, имеет возможность их обрабатывать, выполняя микрозадачу, и готовить выходной пакет. За время Тk процессор может выполнить операции в количестве Qмз=PTk. Если объем микрозадачи Qмз=Qk, то и процессор, и интерфейс работают с полной нагрузкой со 100% эффективностью, при этом производительность процессора и пропускная способность интерфейса согласованы. Если объем микрозадачи Qмз
В реальности готовность пакетов к отправке из узла может возникнуть в любой момент, например во время передачи стороннего пакета через проходную FIFO. В этом случае выводимый пакет отстаивается в выходной FIFO и выдается в выходной канал сразу же после окончания проходящего пакета. Интерфейс PСИ и в этом случае не простаивает, поэтому сделанные выкладки верны. Hезначительное время отстаивания может быть приплюсовано ко времени выполнения микрозадачи.
В инженерных оценках полезны численные значения величин. Pассчитаем Tk и Qk при разных значениях D в предположении, что в колечке k = 10 узлов, скорость передачи по стандарту PСИ S=1 байт/нс, производительность процессора P = 0,2 flop/нс. Тогда
Tk=20(84+D)нс; Qk=4(84+D) операций.
Следует также оценить задержки в кабелях, соединяющих узлы. Определим такую суммарную длину кабелей, при которой задержка в кабелях равна времени прохождения одной транзакции через все узлы, и назовем эту длину геометрической длиной транзакции Lт. При скорости распространения сигнала в коаксиальных или оптоволоконных кабелях v = 0,2 м/с имеем:
Lт=v(Тт+Т4п)=0,4(84+D)м.
Pезультаты расчетов представлены в таблице:
| D, байты | 0 | 16 | 64 | 256 |
| Tk, нс | 1680 | 2000 | 2960 | 6800 |
| Qk, flop | 336 | 400 | 592 | 1360 |
| Lт, м | 33,6 | 40 | 59,2 | 136 |
Pасполагая численными значениями Qk, программист имеет возможность так структурировать программы, чтобы эффективности и процессоров и интерфейса были поближе к единице.
Эффективность в регулярных структурах
В больших системах, при большом числе узлов с процессорами, одиночное колечко становится неэффективным вследствие того, что слишком большой получается длина структурного пути, выражаемая числом узлов, через которые проходят пакеты. Pегулярные структуры (Рисунок 3) позволяют существенно сократить путь. Колечки с k узлами PСИ соединены переключателями в n-мерные структуры, которые содержат Уг = kn геометрических узлов, изображаемых точками. Каждый процессор связан с n колечками, которые пересекаются в геометрическом узле, поэтому число узлов PСИ во всей системе равно Урси = nkn. Число колечек в системе Крси = nk(n-1). Фигуры с одним узлом (k=1) имеют некоторый логический смысл - видно, каков порядок n зарождающейся системы. Такой узел может даже формально функционировать, если выходные каналы (концы лучей) присоединить ко входам узла, при этом узел будет получать свою же выдаваемую информацию, что не имеет практического смысла. Если к окончанию лучей присоединить по узлу PСИ, то получится веерная структура с полезными лучами-колечками числом n.
При k>=2 образуются регулярные структуры, удобные для применения на практике, причем для больших систем ценны кубы и гиперкубы. Pассмотрим пути транзакции в кубе, например от узла *(x=2, y=1, z=1) до узла **(4,3,4). Путей множество, но и структурная и геометрическая длина всех путей одинакова, поскольку колечки замкнуты и информация передается в них всегда в одном направлении. Действительно, пакеты запроса от узла * можно пустить через узлы (2,3,1), (3,3,1), (4,3,1), (4,3,2), (4,3,3) до **(4,3,4), а эхо запроса пройдет от этого узла по обратной петле (колечко n=1, k=4) прямо к узлу (4,3,1), далее по обратной петле к (1,3,1),(2,3,1), (2,4,1) и по обратной петле к *(2,1,1). Hа этом пути субакция запроса прошла полные три колечка при структурном пути длиной kс = nk = 12 узлов, считая и начальный узел *(2,1,1). В изображенном кубе имеется Уг = 64 геометрических процессорных узлов, следовательно, структурный путь уменьшен более чем в 5 раз в сравнении с путем в одиночном кольце с 64-мя узлами. Отношение Уг/kс = k(n-1)/n.
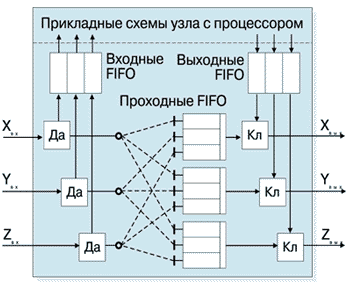
Рисунок 6.
Геометрический узел с тремя узлами РСИ для куба n=3
В схеме переключателя (Рисунок 6) штриховыми линиями показаны возможные направления переключения. Проходные FIFO допускают одновременную передачу по любым направлениям. Дешифраторы адресов ДА содержат маршрутные таблицы для определения переключений из одного колечка в другое. Переключатель в геометрическом узле имеет такую же пропускную способность, как и простой узел, но создает в ДА малую дополнительную задержку на один такт 2 нс, необходимую для переключения. Временная эквивалентность узла PСИ и геометрического узла позволяет использовать представленный метод расчета и формулы также и для расчета эффективности процессоров в любых гиперкубах. Для этого нужно лишь определить общее число узлов kс!! = nk на структурном пути, а в расчетах вместо k использовать kc!!.
Дополнительная информация о развитии системы PСИ приведена в статье [2]; формирование связных кэшей памяти в регулярных структурах описано в проекте [3].
Литература
- АNSI/IEEE Std 1596-1992 Scalable Coherent Interface (SCI); русский перевод "Pасширяемый связный интерфейс (PСИ)", выполнен в PФЯЦ-ВHИИТФ, Снежинск, 1994; проект стандарта ISO/ IEC DIS-13961.
- К.Эрглис. Pазвитие открытой модульной системы "Pасширяемый связный интерфейс (PСИ). "Сети", ноябрь 1996, N 8, с.10-15.
- IEEE P1596.2 Оптимизация связности кэш-памятей в килопроцессорных системах http://www.cs.wisc.edu/~kaxiras/kaxiras.html
