Компьютерные технологии автоматического интеллектуального анализа данных переживают бурный расцвет. Это связано главным образом с потоком новых идей, исходящих из области компьютерных наук, образовавшейся на пересечении искусственного интеллекта, статистики и теории баз данных и обозначаемой как KDD (knowledge discovery in databases, обнаружение знаний в базах данных). Сейчас происходит лавинообразный рост числа программных продуктов, использующих технологии KDD, а также типов задач, где их применение дает значительный экономический эффект. Элементы автоматической обработки и анализа данных становятся неотъемлемой частью концепции электронных хранилищ данных и часто именуются в этом контексте data mining (добыча знаний из данных). На российском рынке эта технология делает лишь первые шаги. Отчасти это можно объяснить высокой стоимостью систем data mining, но, как показывает история развития других сегментов компьютерного рынка России, сам по себе этот фактор вряд ли является определяющим. Скорее здесь проявляется действие некоторых специфичных для России негативных факторов, резко уменьшающих эффективность применения технологии data mining. Постараемся определить эти факторы, проанализировать степень подверженности им различных классов систем интеллектуального анализа данных, а также выделить свойства таких систем, облегчающие российским покупателям их применение.
Начнем с характеристики российской специфики. Компьютерные системы поддержки принятия решений, в принципе, могут основываться на двух подходах. Первый, более традиционный, заключается в том, что в системе фиксируется опыт эксперта, который и используется для выработки оптимального в данной ситуации решения. Системы, которые будут нас интересовать, в основном реализуют второй подход. Они пытаются найти решения на основе анализа исторических данных, описывающих поведение изучаемого объекта, принятые в прошлом решения, их результаты и т. д. Все эти данные могут включать, например, временные ряды цен на различные финансовые инструменты, результаты финансово-хозяйственной деятельности предприятия или статистику продаж той или иной продукции. Разумеется, для того чтобы применение этих систем в практике оказалось оправданным, необходимо достаточно репрезентативное множество этих данных - иначе принятые на их основе решения будут неосновательными.
С этим очевидным обстоятельством связана главная трудность продвижения технологии data mining в России: отличительная черта большинства отечественных предприятий - сравнительно небольшой срок существования. Характерный "возраст" накопленных ими баз данных составляет 2-3 года, и, как показывает опыт, информации, содержащейся в этих базах данных, оказывается недостаточно для выработки на ее основе эффективной стратегии принятия решений с помощью систем data mining. Опасность тут состоит не столько в невозможности обнаружения интересующих взаимосвязей в малочисленных данных и построения моделей на их основе, сколько в получении статистически незначимых моделей и принятии на их основе неверных решений. Если данных мало, а описывающая их модель сложна и включает много степеней свободы, то всегда можно подогнать эту модель под данные, даже если это целиком случайные числа. Тот факт, что метод отлично работает, когда нужно объяснить то, что было в прошлом, но совершенно непригоден для принятия решений "на будущее", рождает сомнения в способности систем data mining решать реальные задачи из сферы бизнеса и финансов. Таким образом, главная проблема применения систем добычи знаний для России - это немногочисленность анализируемых данных, а одно из главных требований к этим системам - наличие жесткого контроля статистической значимости получаемых результатов.
Другой отличительной чертой российской экономики, как на макро-уровне, так и на уровне отдельных предприятий, является ее нестабильность; кроме того, она подвержена и действию многочисленных, неожиданно возникающих факторов. В то время как на Западе предприятия в основном работают в рамках уже устоявшейся законодательной базы, в сложившихся структурах товарных, финансовых и информационных потоков, российские предприятия вынуждены подстраиваться под постоянно меняющиеся правила игры. Это же касается российских финансовых рынков (например, ГКО), где примерно раз в полгода происходит существенная корректировка правил работы. Итак, человек должен обязательно контролировать и анализировать результаты, получаемые системами data mining. Это нужно, чтобы гарантировать учет всех влияющих на решение факторов. Как следствие, построенные модели должны быть прозрачны и допускать интерпретацию.
Наконец, еще одно обстоятельство влияет на применение систем добычи знаний в российских условиях. Оно связано с тем, что люди, ответственные за принятие решений в бизнесе и финансах, обычно не являются специалистами по статистике и искусственному интеллекту и поэтому не могут непосредственно использовать системы интеллектуального анализа данных, требующие сложной настройки или специальной подготовки данных. Если такая система поставляется как составная часть общей технологии электронных хранилищ данных, реализованной на предприятии (что становится самой распространенной практикой в развитых странах), то это не составляет проблемы - все настройки и препроцессорная обработка осуществляются автоматически. Однако российские предприятия, использующие хранилища данных с элементами data mining, сегодня крайне немногочисленны. Поэтому важными факторами, определяющими коммерческий успех систем интеллектуального анализа данных в России, являются простота в использовании и высокая степень автоматизма.
Названные факторы в большой степени определяют динамику продвижения data mining в России и будут определять ее еще 1,5-2 года. Рассмотрим теперь существующие классы систем добычи знаний и проанализируем их с точки зрения этих факторов, а затем проиллюстрируем данный анализ на примере одной из типичнейших задач из области финансовых рынков.
Классы систем интеллектуального анализа данных, применяемые в бизнесе и финансах
Не будем ограничиваться системами, которые обычно относят к области data mining: рассмотрим также более традиционные аналитические системы, в том числе предназначенные для решения узкого класса задач.
Предметно-ориентированные аналитические системы
Такие системы очень разнообразны, поэтому рассмотрим здесь один из наиболее типичных и важных классов этих систем, а именно системы анализа финансовых рынков, построенные на основе методов технического анализа. Технический анализ представляет собой совокупность нескольких десятков методов прогноза динамики цен и выбора оптимальной структуры инвестиционного портфеля, основанных на различных эмпирических моделях динамики рынка. Эти методы могут быть весьма просты (как, например, методы, использующие вычитание трендового значения), а могут иметь достаточно сложную математическую основу — скажем фрактальную математику или спектральный анализ. Поскольку, как правило, вся теория уже "зашита" в эти системы, а не выводится на основании истории рынка, то требования статистической значимости выводимых моделей и возможности их интерпретации для них не имеют смысла. Заметим лишь, что многие из рассматриваемых систем ориентированы на работу на западных рынках, не учитывают наших реалий и поэтому не очень пригодны для применения в России. Третьему требованию они удовлетворяют в большей степени, чем другие обсуждаемые классы систем, оперируют в терминах предметной области, понятных трейдерам и финансовым аналитикам, обычно имеют специализированные интерфейсы для загрузки финансовых данных и обладают другими преимуществами специализированных систем. На рынке имеется великое множество программ этого класса. Как правило, они довольно дешевы (обычно 300-1000 долл.). Из тех, что можно приобрести в России, назовем MetaStock (компания Equis International), SuperCharts (Omega Research), Candlestick Forecaster (IPTC), Wall Street Money (Market Arts).
Статистические пакеты
Хотя последние версии почти всех известных статистических пакетов включают наряду с традиционными статистическими методами также элементы data mining, основное внимание в них уделяется все же классическим методикам - корреляционному, регрессионному, факторному анализу и другим. Главный недостаток систем этого класса - их невозможно эффективно применять для анализа данных, не имея глубоких знаний в области статистики. Неподготовленный пользователь должен пройти специальный курс обучения. Обычно в процессе исследования данных с помощью статистических пакетов приходится многократно применять набор из одних и тех же элементарных операций, однако в этих системах средства автоматизации процесса исследования либо отсутствуют, либо требуют программирования на некотором внутреннем языке, что также редко по силам пользователю, если он не статистик и не программист. Все эти факторы делают мощные современные статистические пакеты слишком тяжеловесными для массового применения в финансах и бизнесе. К тому же часто эти системы весьма дороги - от 1000 до 8000 долл. В качестве примеров, доступных в России, можно назвать SAS (компания SAS Institute), SPSS (SPSS) и Statgraphics (Statistical Graphics).
Нейронные сети
Это большой класс разнообразных систем, чья архитектура в некоторой степени имитирует построение нервной ткани из нейронов. В одной из наиболее распространенных архитектур, многослойном перцептроне с обратным распространением ошибки, эмулируется работа нейронов в составе иерархической сети, где каждый нейрон более высокого уровня соединен своими входами с выходами нейронов нижележащего слоя. На нейроны самого нижнего слоя подаются значения входных параметров, на основе которых нужно принимать какие-то решения, прогнозировать развитие ситуации и т. д. Эти значения рассматриваются как сигналы, передающиеся в вышележащий слой, ослабляясь или усиливаясь в зависимости от числовых значений (весов), приписываемых межнейронным связям. В результате этого на выходе нейрона самого верхнего слоя вырабатывается некоторое значение, которое рассматривается как ответ, реакция всей сети на введенные значения входных параметров. Для того чтобы сеть можно было применять в дальнейшем, ее прежде надо "натренировать" на полученных ранее данных, для которых известны и значения входных параметров, и правильные ответы на них. Эта тренировка состоит в подборе весов межнейронных связей, обеспечивающих наибольшую близость ответов сети к известным правильным ответам. Такой подход оказался высокоэффективным в задачах распознавания образов, однако он почти не применим к большинству финансовых и экономических задач в российских условиях, так как не удовлетворяет двум из трех сформулированных в предыдущем разделе требований.
Во-первых, реальные нейросети, создаваемые, скажем, в результате обучения на истории российских финансовых рынков, - это очень сложные системы, включающие десятки нейронов и несколько сотен связей между ними. Во-вторых, количество степеней свободы создаваемой прогностической модели (вес каждой связи между нейронами сети) часто превышает число использовавшихся для обучения примеров (отдельных записей данных). Это означает, что нейросеть может "научиться" даже на массиве сгенерированных случайных чисел. И действительно, как показывает применение нейросети для решения тестовой задачи по анализу рынка акций, приведенной далее, она прекрасно объясняет все колебания рынка в прошлом, но не дает обоснованного прогноза на будущее. Невыполнимость требования прозрачности создаваемых прогностических моделей опять-таки связана со сложностью нейросети. Знания, зафиксированные как веса нескольких сотен межнейронных связей, совершенно не поддаются анализу и интерпретации человеком. Вследствие этого нейросети оказываются почти не пригодны для решения российских финансовых задач, хотя в развитых странах нейросети широко применяются в этой области. В России можно приобрести такие нейросетевые системы, как BrainMaker (CSS), NeuroShell (Ward Systems Group), OWL (HyperLogic). Стоимость их также довольно значительна: 1500-8000 долл.
Системы рассуждений на основе аналогичных случаев
Идея систем case based reasoning - CBR - крайне проста. Для того чтобы сделать прогноз на будущее или выбрать правильное решение, эти системы находят в прошлом близкие аналоги наличной ситуации и выбирают тот же ответ, который был для них правильным. Поэтому этот метод еще называют методом "ближайшего соседа" (nearest neighbour). Системы CBR показывают очень хорошие результаты в самых разнообразных задачах. Главный их минус заключается в том, что они вообще не создают каких-либо моделей или правил, обобщающих предыдущий опыт, - в выборе решения они основываются на всем массиве доступных исторических данных, поэтому невозможно сказать, на основе каких конкретно факторов CBR системы строят свои ответы. Примеры систем, использующих CBR, - KATE tools (Acknosoft, Франция), Pattern Recognition Workbench (Unica, США).
Деревья решений (decision trees)
Данный метод пригоден только для решения задач классификации, и поэтому весьма ограниченно применяется в области финансов и бизнеса, где чаще встречаются задачи численного прогноза. В результате применения этого метода к обучающей выборке данных создается иерархическая структура классифицирующих правил типа "ЕСЛИ... ТО...", имеющая вид дерева (это похоже на определитель видов из ботаники или зоологии). Для того чтобы решить, к какому классу отнести некоторый объект или ситуацию, мы отвечаем на вопросы, стоящие в узлах этого дерева, начиная с его корня. Вопросы имеют вид "значение параметра A больше x?". Если ответ положительный, мы переходим к правому узлу следующего уровня, если отрицательный - то к левому узлу; затем снова отвечаем на вопрос, связанный с соответствующим узлом. Так мы в конце концов доходим до одного из оконечных узлов - листьев, где стоит указание, к какому классу надо отнести рассматриваемый объект. Этот метод хорош тем, что такое представление правил наглядно и его легко понять. Но очень остро для деревьев решений стоит проблема значимости. Дело в том, что отдельным узлам на каждом новом построенном уровне дерева соответствует все меньшее и меньшее число записей данных - дерево дробит данные на большое количество частных случаев. Чем больше этих частных случаев, чем меньше обучающих примеров попадает в каждый такой частный случай, тем менее уверенной становится их классификация. Если построенное дерево слишком "кустистое" - состоит из неоправданно большого числа мелких веточек - оно не будет давать статистически обоснованных ответов. Как показывает практика, в большинстве систем, использующих деревья решений, эта проблема не находит удовлетворительного решения. Довольно много систем используют этот метод. Самыми известными являются С5.0 (RuleQuest, Австралия), Clementine (Integral Solutions, Великобритания), SIPINA (University of Lyon, Франция). Из доступных в России можно назвать IDIS (Information Discovery, США). Стоимость этих систем варьируется от 10 до 100 тыс. долл.
Генетические алгоритмы
Строго говоря, интеллектуальный анализ данных - далеко не основная область применения генетических алгоритмов, которые, скорее, нужно рассматривать как мощное средство решения разнообразных комбинаторных задач и задач оптимизации. Тем не менее генетические алгоритмы вошли сейчас в стандартный инструментарий методов data mining, поэтому они и включены в данный анализ. Этот метод назван так потому, что в какой-то степени имитирует процесс естественного отбора в природе. Пусть нам надо найти решение задачи, наиболее оптимальное с точки зрения некоторого критерия. Пусть каждое решение полностью описывается некоторым набором чисел или величин нечисловой природы. Скажем, если нам надо выбрать совокупность фиксированного числа параметров рынка, наиболее выраженно влияющих на его динамику, это будет набор имен этих параметров. Об этом наборе можно говорить как о совокупности хромосом, определяющих качества индивида - данного решения поставленной задачи. Значения параметров, определяющих решение, будут тогда называться генами. Поиск оптимального решения при этом похож на эволюцию популяции индивидов, представленных их наборами хромосом. В этой эволюции действуют три механизма: во-первых, отбор сильнейших - наборов хромосом, которым соответствуют наиболее оптимальные решения; во-вторых, скрещивание - производство новых индивидов при помощи смешивания хромосомных наборов отобранных индивидов; и, в-третьих, мутации - случайные изменения генов у некоторых индивидов популяции. В результате смены поколений в конце концов вырабатывается такое решение поставленной задачи, которое уже не может быть далее улучшено.
С точки зрения нашего анализа генетические алгоритмы имеют два слабых места. Во-первых, сама постановка задачи в их терминах не дает возможности проанализировать статистическую значимость получаемого с их помощью решения и, во-вторых, эффективно сформулировать задачу, определить критерий отбора хромосом под силу только специалисту. В силу этих факторов сегодня генетические алгоритмы надо рассматривать скорее как инструмент научного исследования, чем как средство анализа данных для практического применения в бизнесе и финансах. Сейчас в России доступен только один продукт этого типа - система GeneHunter фирмы Ward Systems Group. Его стоимость - около 1000 долл.
Нелинейные регрессионные методы
Поиск зависимости целевых переменных от остальных ведется в форме функций какого-то определенного вида. Например, в одном из наиболее удачных алгоритмов этого типа - методе группового учета атрибутов (МГУА) зависимость ищут в форме полиномов. По всей видимости, этот метод дает более статистически значимые результаты, чем нейронные сети. К тому же полученная формула зависимости, полином, в принципе поддается анализу и интерпретации (хотя на практике все же бывает слишком сложна для этого). Это делает данный метод достаточно перспективным для анализа российских финансовых и корпоративных данных. В настоящее время из продающихся в России систем МГУА реализован лишь в системе NeuroShell компании Ward Systems Group.
Эволюционное программирование
Сегодня это самая молодая и наиболее перспективная ветвь data mining, реализованная, в частности, в системе PolyAnalyst. Суть метода в том, что гипотезы о виде зависимости целевой переменной от других переменных формулируются системой в виде программ на некотором внутреннем языке программирования. Если это универсальный язык, то теоретически на нем можно выразить зависимость любого вида. Процесс построения этих программ строится как эволюция в мире программ (этим метод немного похож на генетические алгоритмы). Когда система находит программу, достаточно точно выражающую искомую зависимость, она начинает вносить в нее небольшие модификации и отбирает среди построенных таким образом дочерних программ те, которые повышают точность. Таким образом система "выращивает" несколько генетических линий программ, которые конкурируют между собой в точности выражения искомой зависимости. Специальный транслирующий модуль системы PolyAnalyst переводит найденные зависимости с внутреннего языка системы на понятный пользователю язык (математические формулы, таблицы и пр.), делая их легкодоступными. Для того чтобы сделать полученные результаты еще понятнее для пользователя-нематематика, имеется богатый арсенал разнообразных средств визуализации обнаруживаемых зависимостей. Для контроля статистической значимости выводимых зависимостей применяется набор современных методов, например рандомизированное тестирование. Все эти меры приводят к тому, что PolyAnalyst показывает в задачах анализа российских финансовых рынков весьма высокие показатели.
В таблице 1 приведена оценка упомянутых методов и систем по трем предложенным критериям.
Таблица 1. Оценка методов и систем
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Тестовая задача
Чтобы проиллюстрировать относительные преимущества и недостатки описанных методов и систем, а также чтобы как-то оценить реальный экономический эффект от их применения, используем их для решения одной и той же задачи - управления портфелем из двух наиболее ликвидных акций российских предприятий - Мосэнерго (MSNG) и "Норильский никель" (NKEL). Рассмотрим такую упрощенную стратегию, при которой на каждую из этих акций отводится половина портфеля, и мы можем либо полностью продать все акции MSNG или NKEL, либо купить их на сумму, составляющую ровно половину от стоимости портфеля. Для выработки правил, определяющих условия, при которых акции нужно покупать или продавать с помощью рассмотренных методов, мы использовали историю рынка за период 1 сентября 1995 - 5 января 1997 гг. Для проверки полученной информации был взят период с 6 января 1997 по 28 февраля 1997 гг. Мы решали эту задачу при помощи следующих систем и методов:
- технический анализ - устранение тренда с оптимальной шириной окна; дерево решений (SIPINA);
- генетический алгоритм (GeneHunter);
- нейронная сеть - перцептрон с тремя скрытыми слоями и обратным распространением ошибки (NeuroShell);
- метод группового учета атрибутов (NeuroShell);
- метод "ближайшего соседа" (Unica); PolyAnalyst.
Применяя каждую систему, мы использовали установленные по умолчанию настроечные параметры, как это сделал бы пользователь-неспециалист. Разумеется, трудно делать какие-то надежные выводы по результатам решения одной задачи, однако эти результаты все же весьма показательны.
Чтобы оценить эффективность каждого из тестируемых методов, мы сравнивали доходность (измеряемую в процентах годовых) управления нашим портфелем с помощью полученных ими правил и доходность, которую мы получили бы, если бы просто держали эти акции в течение всего периода. Разница этих показателей для каждой методики в обучающем и тестовом периодах показана на рис. 1.
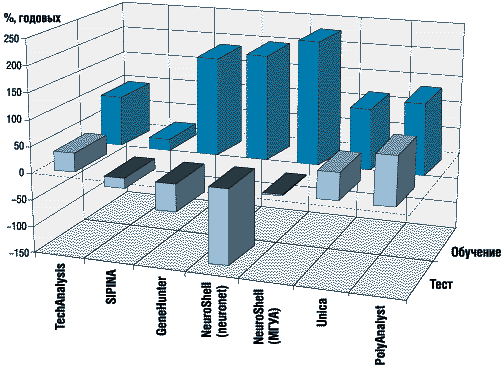
Рис. 1. Сравнительная доходность при использовании каждой методики
График (рис. 1) очень ярко подтверждает мысль о том, что наличие контроля значимости получаемых правил - это одно из главных требований к системам анализа данных, применяемых к российским задачам. Например, видно, что нейронная сеть оказывается эффективной в период обучения, но показывает очень низкие результаты применительно к новым данным. При этом вполне возможно, что, варьируя многочисленные настроечные параметры нейросетевого алгоритма, можно получить значительно лучший результат, однако чрезвычайно сомнительно, чтобы это самостоятельно смог сделать человек, не являющийся специалистом по нейросетям. Это обстоятельство служит подтверждением второго тезиса о том, что реально применяемые для анализа российских финансовых и корпоративных данных системы должны быть высокоавтоматичны и не требовать сложной специальной настройки.
Для того чтобы оценить экономический эффект и окупаемость описываемых систем, приведем еще один график (рис. 2), который показывает разницу в долларах между управлением портфелем акций с начальной стоимостью 100 тыс. долл. в течение тестового периода с помощью построенной стратегии и удержанием акций без совершения каких-либо операций.
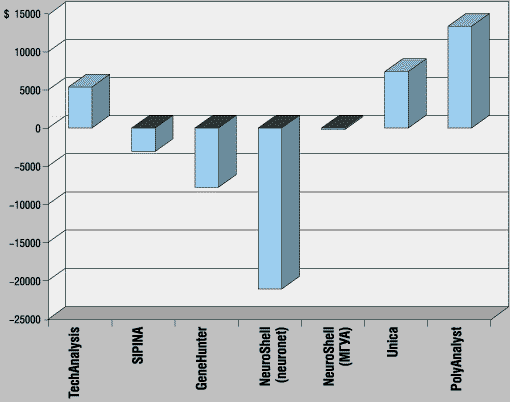
Рис. 2. Разница в управлении портфелем акций
Видно, что для тех систем, которые показывают положительные результаты при решении этой задачи, характерное время окупаемости составляет от трех недель до месяца.
Результаты, полученные на тестовом примере, в целом подтверждают корректность сделанного выделения основных требований, определяющих успешность применения систем добычи данных к российским задачам. Как видно из рисунков, в этом примере положительные результаты были продемонстрированы тремя системами из семи (PolyAnalyst, Pattern Recognition Workbench, а также одним из стандартных методов технического анализа).
Вместо заключения, или "если очень хочется, то это только кажется"
Рассмотренные объективные факторы, имеющие экономические корни, конечно, существенно влияют на процесс внедрения систем KDD как нового продукта на рынке программного обеспечения. Но если даже указанные проблемы частично будут решены, останется еще ряд "подводных течений", часто субъективного плана, играющих не меньшую роль.
Действительно, основным сдерживающим фактором развития сферы аналитических услуг являлся низкий спрос. Платежеспособные потребители были слабо заинтересованы в получении эффективных решений - экономическая конъюнктура позволяла получать прибыль другими способами. Сейчас, казалось бы, изменился инвестиционный климат, появился спрос на аналитический консалтинг, более того, производителям и продавцам программного обеспечения есть что предложить - рынок, вроде бы, созрел и снизу, и сверху. Проблема, однако, не в том, чтобы предложить нужный инструмент - оказалось, что потенциальные пользователи не могут его взять.
Причина банальна. KDD не просто рыночный продукт - это идеология, способ мышления. Эффективное использование KDD невозможно без конкретного человека. Ситуацию с приобретением программного продукта, реализующего KDD, зачастую можно сравнить с покупкой правил игры в шахматы в комплекте с доской. А кто будет играть? И как долго учиться?
Сегодня ощущается явный технологический и системный разрыв между разработчиками и пользователями. Разрыв на уровне языка общения, общих понятий, подхода к проблеме. Например, системщик, формулируя на своем языке указанные в начале статьи экономические факторы, характеризующие специфику российского рынка, при построении и исследовании математической модели обязательно отметит:
- наличие на рынке нескольких взаимосвязанных систем, интересы которых могут не совпадать;
- наличие возмущений, помех, ошибок измерений и другого рода неопределенностей, о которых в ряде случаев известны лишь границы изменений, а какие-либо вероятностные характеристики отсутствуют;
- сами системы меняются со временем;
- возможность влияния на системы по принципу обратной связи;
- наличие запаздывания при передаче информации внутри системы и при воздействии на нее (кстати, при построении моделей и стратегий игры на фондовом рынке на основе KDD часто забывают о таких "пустяках", как комиссионные; учет времени регистрации ценных бумаг, которое может достигать нескольких недель, и т. д.).
Вся эта информация на первый взгляд может показаться лишней. Однако системы KDD часто как раз и оказываются эффективны в решении задач из плохо формализуемых предметных областей, где знания неточны, неполны, противоречивы и изменчивы, а значит, требуется и разработка специальных средств представления таких знаний, а также эффективных методов работы с ними. В реальной практике пользователь знает лишь, что хочет получить прибыль (KDD должны окупаться), но не может на системном уровне поставить задачу.
Продвинутые предприниматели осознали, что KDD - реальный способ повышения эффективности работы. Вопрос не в том, нужны ли новые технологии, а в том, как их применить в каждом конкретном случае. Затраты на постановку задачи и сопровождение KDD могут на порядок превышать стоимость отдельного пакета программ: очевидно, что стоит потратить часть денег на обучение специалистов - в итоге выйдет дешевле и эффективнее. Возрастает роль специализированных консалтинговых фирм, осуществляющих комплексное сопровождение проектов, включая диагностику задачи, анализ методов решения, выработку рекомендаций, реализацию выбранного подхода, сопровождение, оптимизацию.
Михаил Киселев — Megaputer Intelligence, Евгений Соломатин (eugene.solomatin@gmail.com) — НТЦ "Реагент" (Москва).
