
Известно, что компания Hewlett-Packard совместно с Intel ведет работы над 64-разрядным микропроцессором с кодовым названием Merced; тем не менее она объявила и о продолжении работ над линией собственных чипов РА-8х00 с архитектурой PA-RISC. Эти микропроцессоры на сегодня являются, вероятно, основным оппонентом микропроцессоров DEC Alpha в гонке за наибольшую производительность, хотя на некоторых тестах их опережают IBM P2SC/135. Наиболее ярко ситуация видна на примере пиковой производительности с плавающей запятой: 1200 MFLOPS у Alpha 21164/600, 800 MFLOPS для PA-8200/200, 540 MFLOPS у IBM P2SC/135, 500 MFLOPS для Sun UltraSPARC/250 и, наконец, 390 MFLOPS у SGI/MIPS R10000/ 195 (конечно, "реальные" тесты могут приводить к сильно отличающейся последовательности). В данной статье на основе рассмотрения архитектуры микропроцессоров серии PA-8x00 анализируются некоторые важнейшие архитектурные особенности современных микропроцессоров, во многом определяющие их производительность.
Что нужно для того, чтобы микропроцессор работал быстро на любых приложениях? Высокая тактовая частота, большое количество параллельно работающих функциональных исполнительных устройств (ФИУ); "умение" загрузить работой все эти устройства на самых разных приложениях; кэш-память большой емкости с высокой пропускной способностью (ПС) и низкими задержками при обращении, причем желательно, чтобы в нее помещалось рабочее множество страниц приложения; системная шина с высокой ПС и т. д.
Из-за ограничений современной технологии эти требования часто находятся в противоречии между собой и, конечно, с требованием получить достаточно высокий выход годных чипов при достаточно низкой цене. Если поднимается тактовая частота, то трудно выполнить сложные операции за 1 такт, поэтому конвейеры часто разбиваются на большее число ступеней (суперконвейерный подход, характерный, например, для Alpha 21064 [1]). Но при этом возрастает время, необходимое для заполнения длинных конвейеров.
Если увеличивается число ФИУ (суперскалярный подход), то возникает задача обеспечения их загрузки, для чего используется, в частности, техника внеочередного (out-of-order) и "спекулятивного" (на основе предсказания, в какую ветвь программы произойдет условный переход) выполнения команд. При этом возрастает сложность микропроцессора и соответственно его площадь, что чревато уменьшением выхода годных чипов. В сочетании с короткими конвейерами это затрудняет увеличение тактовой частоты. В качестве примеров такого подхода можно привести микропроцессоры IBM c архитектурой POWER2/P2SC [2] и SGI/MIPS R10000 [3]; сюда же относится и HP PA-8000 [4].
Сегодня явно видна тенденция к созданию суперскалярных чипов с высокой тактовой частотой. Однако способов достижения этого решения может быть несколько. Например, у микропроцессоров Alpha, традиционно имеющих высокие тактовые частоты, укорачиваются конвейеры (Alpha 21164) и возрастает число ФИУ, а также появляются возможности внеочередного выполнения команд (Alpha 21264). А в микропроцессорах HP PA-RISC 8000, 8200 и 8500 и SGI/MIPS R10000 и R12000 в первую очередь планируется увеличение тактовой частоты. Рассмотрим этот процесс на примере эволюции семейства PA-8x00.
Микропроцессор PA-8000
На рис. 1 изображено "строение" микропроцессора PA-8000 [5], который стал первым 64-разрядным микропроцессором от HP с системой команд PA-RISC 2.0 [6]. Все последующие модели - PA-8200 и PA-8500 - не только двоично совместимы с PA-8000, но и имеют практически то же самое строение. PA-8000 с тактовой частотой 180 МГц имеет следующие особенности:
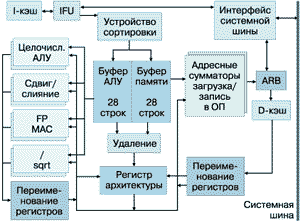
Рисунок 1.
Заполнение IRB осуществляет устройство сортировки, получая по 4 команды из устройства выборки команд IFU. Выполненные команды изымаются из IRB устройством "освобождения" (retire), до 4 команд за такт. IRB состоит из 2 блоков по 28 строк каждый; в одном буферизуются команды, предназначенные для целочисленных ФИУ или ФИУ с плавающей запятой, а в другом - команды загрузки регистров/записи в память.
Для сравнения, чип R10000 имеет 3 очереди команд по 16 строк каждая (к целочисленным ФИУ; к ФИУ c плавающей запятой; загрузки регистров/ записи в память); в Intel Pentium Pro аналогичный IRB буфер имеет емкость 40 строк [7], в AMD K6 - 24 строки [8].
В РА-8000 используется сразу два метода предсказания переходов: статический, при котором для большинства условных переходов переход "назад" предсказывается совершающимся, а "вперед" - нет, и динамический, основанный на таблице истории переходов BHT (Branch History Table), имеющей 256 трехразрядных строк - использующей "историю" трех последних переходов.
Для более детального знакомства с архитектурой PA-8000 можно рекомендовать работы [4,5], а здесь рассмотрим только строение кэш-памяти. В РА-8000 она имеет уникальную особенность: в качестве первичной используется внешняя кэш-память. Традиционное двухуровневое построение кэш-памяти современных микропроцессоров имеет недостаток - увеличение задержек при обращении к кэш-памяти второго уровня по сравнению с одноуровневым строением кэша. Для коммерческих приложений типа обработки транзакций требуется кэш команд большой емкости, который трудно разместить на основном чипе. Аналогичная ситуация часто имеет место для сложных приложений научно-технического характера - в кэш-памяти требуется держать вещественные числа.
Следствием всего этого стало принятие в РА-8000 редкого решения - использовать в качестве первичного внешний кэш как для команд, так и для данных. При этом задержка при обращении в кэш составляет 2 такта. В качестве аналога можно привести пример известного микропроцессора MIPS R8000, у которого внешний G-кэш емкостью 4 Мбайт является первичным для операндов с плавающей запятой. Подобная конструкция в некоторых ситуациях более эффективна, чем двухуровневая организация в MIPS R10000, хотя многочиповая структура R8000 ведет к удорожанию микропроцессора и делает более сложной проблему увеличения тактовой частоты. Поэтому для повышения эффективности работы кэша в R10000 используется неблокирующаяся кэш-память, позволяющая не прерывать работу микропроцессора при наличии до 4 непопаданий в кэш. РА-8000 также обладает неблокирующимся кэшем: до 10 непопаданий в кэш данных не останавливают работу. Что касается I-кэша (команд) первого уровня, то такой большой его емкости, как в РА-8000, среди других микропроцессоров пока нет.
Важным преимуществом РА-8000 является применение собственных выделенных шин, соединяющих основной чип с кэшами команд и данных. Это характерно и для MIPS R8000, R10000, но в Sun UltraSPARC [9] и DEC Alpha 21164 обмен данными с внешним кэшем протекает по той же шине, по которой происходит обмен данными с оперативной памятью. В случае небольшой емкости кэша, например в Intel Pentium Pro (512 Кбайт), может возникнуть особенно большая дополнительная нагрузка на системную шину, поэтому разработчики Intel используют в Pentium Pro и Pentium II архитектуру Dual Independed Bus, включающую выделенную шину во вторичный кэш.
Микропроцессор РА-8200
Компания анонсировала PA-8200 в октябре 1996 г. [10, 11]. Естественно, перед Hewlett-Packard стояла задача увеличения тактовой частоты. Учитывая применение фирмой технологии 0.5 мкм, это было сделать непросто. Поэтому в следующей версии, РА-8200, тактовую частоту планировалось увеличить ненамного, от 180 до 220 МГц. Некоторые характеристики этого микропроцессора приведены в таблице 1. Уже в период подготовки данной статьи к печати HP объявила о поставках многопроцессорных серверов V-класса на базе PA-8200 с тактовой частотой 200 МГц.
Таблица 1.
Сравнительные характеристики процессоров PA-8x00.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Переход к SRAM-технологии 4 Мбит позволил для РА-8200 в 2 раза увеличить емкость кэш-памяти: до 2 Мбайт - кэш команд и до 2 Мбайт - кэш данных, при сохранении времени доступа в 2 такта. Если емкость кэша команд РА-8200 будет оставаться непревзойденной еще достаточно долго, то емкость кэш-памяти данных уступает конкурентам, имеющим внешний кэш размером 4 Мбайт (R10000 или Alpha 21164).
Узким местом в РА-8000, по мнению разработчиков из НР, являются большие задержки при неправильном предсказании переходов и "непопадании" в буфер TLB, отвечающий за ускорение преобразования из виртуальных адресов в физические. Так, отсутствие нужной строки в TLB приводит к задержке в 61 такт [11]. Чтобы уменьшить вероятность возникновения этих ситуаций, емкость буфера TLB была увеличена с 96 до 120 строк, а BHT - c 256 до 1024 строк, при этом алгоритм заполнения кэша предсказания переходов также был модифицирован. Для сравнения, TLB в R8000 имеет емкость 384 строки, в R10000 - 64 строки. Что касается BHT, то в других микропроцессорах чаще используется 2-разрядное поле истории переходов; например, емкость BHT в R10000 составляет 512 строк, в PowerPC 620 планировалось 2048 строк.
По утверждению разработчиков, в результате внесенных в PA-8200 изменений удастся достигнуть увеличения производительности приложений на 35-75% (эти и нижеследующие оценки производительности относятся к тактовой частоте 220 МГц). Наиболее ощутимо увеличение производительности для коммерческих приложений, в которых важно предсказание переходов и характерна частая "смена" адресов, требующая обращений в TLB. Косвенным результатом возрастания емкости BHT является также увеличение эффективной пропускной способности системной шины на 20%. Кроме этого, были внесены изменения в организацию доступа к оперативной памяти, обеспечивающие дополнительную буферизацию и внеочередной доступ к памяти. Оценка базовых величин SPECint95/fp95 составляет 15.5/25 соответственно.
HP полагала, что РА-8200 будет лидером по этим показателям вплоть до появления DEC Alpha 21264 [10], однако по оценкам DEC ее микропроцессор Alpha 21164/600 МГц имеет более высокие показатели SPECint95/fp95 = 18/27.
Микропроцессор РА-8500
Очевидно, что показатели производительности РА-8200 будут существенно превышены чипом Alpha 21264, появление которого планируется на конец 1997 г. Однако компания HP считает, что она сможет "обогнать" этот чип, выпустив чип РА-8500 и реальные компьютерные системы на его основе [10].
Если в РА-8200 разработчики выжимали все из используемой уже в РА-8000 технологии 0.5 мкм, то в РА-8500 запланирован переход к гораздо более высокой тактовой частоте - 400 МГц - и соответственно переход к технологии 0.25 мкм. Одновременно изменения в архитектуре при переходе от РА-8200 к РА-8500 более существенны, чем при переходе от РА-8000 к РА-8200.
Кэш-память. Основным, кардинальным изменением в РА-8500 по сравнению с РА-8200 является отказ от внешней кэш-памяти в пользу ее интеграции на основной чип. А именно, в РА-8500 на основном чипе расположен I-кэш емкостью 512 Кбайт и D-кэш емкостью 1 Мбайт. Очевидно, что это стало возможным лишь благодаря уменьшению базовых размеров элементов в новой технологии 0.25 мкм. Столь большая емкость кэш-памяти на основном чипе также само по себе уникальное явление - кэш займет 3/4 площади всего кристалла.
В отличие от предыдущих микропроцессоров 8000, кэш РА-8500 является многоканальным, частично-ассоциативным (set-associative). Сегодня разработчики высокопроизводительных микропроцессоров часто предпочитают этот тип кэша прямоадресуемому (direct-mapped). Это обусловлено тем, что обычно частично-ассоциативный кэш обеспечивает более высокую вероятность нахождения в нем данных по сравнению с прямоадресуемым кэшем той же емкости.
Когда прямоадресуемый кэш заполняется, возникают проблемы, куда положить очередную порцию запрошенных данных. В n-канальном частично-ассоциативном кэше (n-way set-associative) имеется до n мест, куда можно положить запрошенные данные. Однако в прямоадресуемом кэше можно получить более низкое время доступа. Для более ясного понимания ситуации полезно рассмотреть гипотетический пример, предложенный на одной из телеконференций Usenet автором известных тестов STREAM Дж. Мак-Калпином (J. McCalpin) из SGI.
Пусть вероятность попадания в прямоадресуемый кэш L2 составляет 80% от случаев непопадания в кэш L1, а в частично-ассоциативный кэш - порядка 85-90%, скажем 87%. Пусть попаданию в кэш отвечает задержка 20 нс для прямоадресуемого кэша и 24 нс - для частично-ассоциативного кэша, а непопаданию в кэш - 100 нс. Тогда средние задержки будут составлять:
0,80 * 20 + 0,20 * 100 = 36 нс
(для прямоадресуемого кэша)
0,87 * 24 + 0,13 * 100 = 34 нс
(для частично-ассоциативного кэша).
Как и в РА-8000, в РА-8500 D-кэш имеет 2 банка и допускает 2 одновременных доступа в оперативную память. Доступ к двум банкам D-кэша осуществляется через буфер переупорядочения адресов ARB. ARB получает адреса, рассчитанные адресными сумматорами РА-8500, и расставляет приоритеты по доступу к оперативной памяти для этих адресов. I-кэш РА-8500 является 4-канальным частично-ассоциативным и обеспечивает блок IFU 128 битами команд за такт.
В РА-8000 для поддержания высокопроизводительного внешнего кэша требовалась многоразрядная шина, что приводило к удорожанию микропроцессора. Эти потребности в существенной степени устраняются в РА-8500 с кэшем на основном чипе. С целью поддержания целостности данных D-кэш в РА-8500 защищен кодами, автоматически корректирующими одиночные (одноразрядные) ошибки. В I-кэше используется просто контроль по четности, и при возникновении ошибки генерируется ситуация непопадания в кэш, так что соответствующая строка кэша будет повторно загружена из оперативной памяти.
Рассмотрение эволюции строения кэш-памяти в ряду РА-8000 - РА-8200 - РА-8500 демонстрирует некоторые общие тенденции и проблемы, характерные для современных высокопроизводительных микропроцессоров RISC-архитектуры. Чаще всего переходу к более высоким тактовым частотам отвечает многоуровневая организация кэша (три уровня в Alpha 21164, два уровня в MIPS R10000), что обычно увеличивает задержки при обращении к внешнему кэшу, усложняет микропроцессор и повышает его стоимость. IBM в микропроцессоре P2SC с частотой 135 МГц интегрировала D-кэш на основном чипе. Однако этот кэш имеет емкость только 128 Кбайт, а кэш L2 в этом микропроцессоре не предусмотрен [2].
Интеграция кэша столь большой емкости прямо на чипе РА-8500 является, несомненно, большим успехом HP. Хотя по емкости кэша РА-8500 и уступает внешним кэшам чипов других производителей, плюсы одноуровневого строения кэш-памяти PA-8500 гораздо весомее.
Предсказание переходов. Еще одна область постоянных усовершенствований современных микропроцессоров - предсказание переходов. Его роль еще более возрастает в случае применения внеочередного спекулятивного выполнения команд, которое, похоже, уже в ближайшее время станет общеупотребительным. Причина повышенного внимания к этому вопросу обусловлена большими задержками, возникающими при неверном предсказании переходов, что грозит существенной потерей производительности. Используемые в микропроцессорах методы предсказания переходов, как уже было сказано, бывают статические и динамические. Как динамический, так и статический подходы имеют свои преимущества и недостатки [12].
Статические методы предсказания используются реже. Такие предсказания делаются компилятором еще до момента выполнения программы. Соответствующие действия компилятора можно считать оптимизацией программ. Такая оптимизация может основываться на сборе информации, получаемой при тестовом прогоне программы (Profile Based Optimisation, PBO) или на эвристических оценках. Результатом деятельности компилятора являются "советы о направлении перехода", помещаемые непосредственно в коды выполняемой программы. Эти советы использует затем аппаратура во время выполнения. В случае, когда переход происходит, или наоборот - как правило, не происходит, советы компилятора часто бывают весьма точны, что ведет к отличным результатам. Преимущество статического подхода - отсутствие необходимости интегрировать на чипе дополнительную аппаратуру предсказания переходов.
Большинство производителей современных микропроцессоров снабжают их различными средствами динамического предсказания переходов [13], производимого на базе анализа "предыстории". Тогда аппаратура собирает статистику переходов, которая помещается в BHT. Некоторые типичные ситуации, когда динамическое предсказание переходов лучше статического, указаны в [12], например, если в условном переходе в теле некоторой команды Unix проверяется какой-либо ключ или переход в подпрограмме сортировки, направление которого зависит от "степени отсортированности" подаваемого на ее вход списка. В обоих случаях компилятор не может выработать эффективные рекомендации на этапе трансляции программы. В то же время схемы динамического предсказания переходов легко справляются с такими задачами. В этом смысле динамическое предсказание переходов "мощнее" статического.
Однако у динамического предсказания есть и свои слабые места - это проблемы, возникающие из-за ограниченности ресурсов для сбора статистики [12]. Как уже отмечалось, РА-8000 может использовать оба подхода, и при компиляции можно указать, какой режим предсказания переходов будет применен. В РА-8500 предложено интересное усовершенствование, позволяющее объединить оба подхода. В ВНТ данного чипа использованы стандартные 2-разрядные счетчики переходов [14], но в счетчике не суммируются нули и единицы в соответствии с тем, был или не был произведен переход. Вместо этого собирается статистика о том, сделан ли переход согласно статическому предсказанию компилятора или нет. В случае, если статическая рекомендация оказалась не соответствующей действительному направлению перехода, счетчик возрастает на 1, а при правильном предсказании - уменьшается на 1. Когда осуществляется предсказание перехода, аппаратура микропроцессора просматривает накопленное значение счетчика, и если он равен 0 или 1 - используется статическое предсказание, а если 2 или 3 - предсказывается переход, противоположный статической рекомендации. Такое построение блока предсказания переходов РА-8500, по мнению авторов [12], позволяет скомбинировать преимущества двух подходов.
Заключение
В статье не рассматриваются некоторые важные усовершенствования, предложенные разработчиками в РА-8500, например модернизированная системная шина с ПС, равной 2,2 Гбайт/с - основное внимание было сконцентрировано на двух главных особенностях РА-8х00, строении кэш-памяти и предсказании переходов, которые имеют важное значение для архитектуры микропроцессоров как таковой. Ясно, что РА-8500 с точки зрения архитектуры представляет собой уникальную разработку, особенно если учесть, что компания Hewlett-Packard уже готовит к выпуску реальные рабочие станции и серверы на основе данных микропроцессоров.
Литература
[1] А. Шадский. Семейство DEC Alpha AXP. Открытые системы, # 3, 1994, cc. 12-16.
[2] М. Кузьминский, Computerworld/Россия. # 14, 1997.
[3] В. Аваков. Микропроцессор MIPS R10000. Открытые системы, # 6, 1995, cc. 62-69.
[4] М. Кузьминский. Микропроцессор PA-RISC 8000. Открытые системы, # 5, 1995, cc. 15-18.
[5] D. Hunt. Advanced Performance Features of the 64-bit PA-8000, Proc. IEEE Compcon, March 5-9, 1995, San-Francisco, California, pp. 123-128.
[6] G. Kane. PA-RISC 2.0 Architecture, Prentice Hall, 1996.
[7] М. Кузьминский. Открытые системы сегодня, # 5, 1995.
[8] М. Кузьминский. Computerworld/Россия, # 18, 1997.
[9] В. Шнитман. Архитектура процессоров UltraSPARC, Открытые системы, # 2, 1996, cc. 5-13.
[10] L. Gwennap. HP pumps Up PA-8x00 Family, Microprocessor Report, Vol. 10, # 14, October 28, 1996 (http://www.hp.com/computing/framed/technology/pa-8200/docs/101996 ar.html).
[11] Paul L. Perez. The HP PA-8200 RISC CPU Evolving Performance from a Revolutionary Processor, presentation at Microprocessor Forum, Oct. 22, 1996 (http://www.hp.com/computing/framed/micropro/pa-8200/docs/8200mpr.html).
[12] G. Lesartre, D.Hunt. PA 8500: The continuing evolution of the PA-8000 family (http://www.hp.com/computing/framed/technology/micropro/pa-8500/docs/8500.html).
[13] L. Gwennap. New Algorithm Improves Branch Prediction, Microprocesor Report, v. 9, # 4, 1995, pp. 18-19.
[14] J. Lee, A. Smith. Branch prediction Stratrgies and Branch Target Buffer Design, IEEE Computer, v. 17, # 1, 1984, pp. 6-22.
