
Информационно-поисковые системы Internet - тот самый инструмент, который позволяет ориентироваться в огромном информационном пространстве Сети. Сегодня многие пользователи находят необходимые материалы, обращаясь к услугам поисковых служб Lycos, Altavista или OpenText. Как правило в ответ на запросы выдается список ссылок на информационные источники, по мнению системы наилучшим образом отвечающие потребностям пользователя. При этом списки содержат количество документов, найденных на каждое слово запроса и условные веса для каждого из документов списка. Каким же образом системы присваивают эти веса и как вообще ищут документы? Другой вопрос, который сегодня все больше волнует разработчиков специализированных баз данных WWW - это структура навигационных графов Website, их корректировка и жизненный цикл страниц. Сегодня еще мало кто задумывается о завтрашнем дне Web сервера корпорации и планирует стратегию его масштабирования или оптимизации, однако, рано или поздно все эти вопросы возникнут и готовить основу для их решения имеет смысл уже сейчас, используя накопленный опыт эксплуатации, моделирования и анализа Web серверов и установленных на них информационно- поисковых систем (ИПС). Статья представляет собой попытку описания процедуры коррекции гипертекстового графа системы на основе анализа статистики обращений к серверу. При этом можно также оценивать эффективность изобразительных средств реализации самих страниц.
В описании ИПС "Паук" [1] (одна из немногих отечественных систем, индексирующих информацию в World Wide Web) имелась следующая фраза: "Не ждите от нас детального описания системы, поскольку она является предметом авторского права, с которым мы не собираемся расставаться." Будем надеяться, что авторы имели ввиду свои права на компьютерные коды, реализующие систему. Однако хотелось бы заметить, что даже такие монстры Internet, как Lycos и Altavista не делают большого секрета из теоретических основ, составляющих базис своих систем. Да и, собственно говоря, чего скрывать, если большинство основных открытий в области ИПС с ограниченным контролем словаря индексирования относятся еще 70-ым годам. Хорошо известны такие системы как INIS, INSPEC, STN, NTIS, MEDLAR, не менее популярны и реферативные базы данных ВИНИТИ. Опыт эксплуатации именно этого класса систем и лег в основу современных информационно-поисковых систем и служб Internet. История их развития началась с системы WAIS[2] -первой распределенной ИПС Сети.
ИПС гораздо старше систем управления базами данных - они благополучно пережили конкуренцию со стороны последних и продолжают успешно развиваться в своей экологической нише, оказывая влияние и на ресурсы глобальных компьютерных сетей. На недавней конференции WWW были представлены обзор Yuwono и Lee[3] и предложения по развитию подобных систем, которые снова базируются на архитектуре ИПС. Причин такого консерватизма несколько. Во-первых, эти системы имеют строго определенную структуру документа хранения, которая наиболее полно описана в стандарте для разработчиков распределенных ИПС - Z.3950. К слову, этот стандарт по своим потенциальным возможностям столь обширен, что ни одна из существующих систем не реализует его в полной мере. А ежели известна структура документа, то, соответственно не нужно "огород городить" из многих отношений, подгоняя реализацию в рамки реляционной модели данных, - здесь эта модель просто не будет эффективной ни с точки зрения реализации системы, ни с точки зрения ее администрирования.
Во-вторых, поиск строится на основе преобразования предложений некоторого информационно-поискового языка в запросы информационной системы. Язык может основываться на терминах, словоформах или устойчивых словосочетаниях, всю совокупность которых обычно называют словарем системы. Как показала практика, наилучшим решением здесь являются инвертированные списки. При этом можно над одним уровнем списков строить другие списки и т.д. Почему же этот способ предпочтительней всех остальных, скажем хеширования? Причин, как минимум две: очень сложно построить на множестве слов хороший алгоритм хеширования - слишком много "дырок" или слишком большие получаются списки, но главное, что это и не требуется - актуализация словаря носит периодический, а не перманентный характер.
Казалось бы, при создании словаря информационных ресурсов Internet последний тезис должен был бы пошатнуться из-за быстрого роста публикаций в сети и постоянного опроса сети "паучками" - программами сканирования [4]. Но все не так просто - в дело вступают те самые языки запросов и модели информационных массивов и потоков, которые используются в теории информационного поиска на протяжении вот уже почти 20 лет и, надо сказать, хорошо себя зарекомендовали.
Векторная и линейная модель индексирования и поиска документов
В литературе, как отечественной, так и зарубежной, нет четкого различия между векторной и линейной моделями. Мартин Бертчи [5] и Дж.Солтон[6] относят способ представления документов, равно как и алгоритм индексирования и поиска к векторной модели. И.И. Попов [7] же называет ее линейной моделью индексирования и поиска, а Решетников свою модель [8], построенную на векторном представлении документов именует алгебраической. Будет справедливо, если представление документов и поиск информации в массиве разделим на две модели. Следуя этой логике, векторной будем называть модель описания информационного массива, а линейной - модель поиска информации в массиве. Такое разделение обусловлено тем, что документы записываются в виде двоичных векторов, в то время как поисковые запросы - это линейные преобразования над этими векторами.
В векторной модели информационного потока можно выделить несколько основных понятий: словарь, документ, поток и процедуры поиска и коррекции запросов.
Под словарем понимают упорядоченное множество терминов, мощность которого обозначают как D.
Документ - это двоичный вектор размерности D. Если термин входит в документ, то в соответствующем разряде этого двоичного вектора проставляется 1, в противном же случае - 0. Обычно все операции в линейной модели индексирования и поиска документов выполняются над поисковыми образами документов, но при этом их как правило называют просто документами.
Информационный поток или массив L представляют в виде матрицы размерности NxD, где в качестве строк выступают поисковые образы N документов. При таком рассмотрении можно сформулировать процедуру обращения к информационной системе следующим образом:
(1) L x q = r;
где q - вектор запроса, r - отклик системы на запрос.
Это традиционное определение процедуры поиска документов в ИПС, которое используется Солтоном с 1977 года [9]. Оно было введено для решения проблемы автоматического индексирования документов, но оказалось чрезвычайно полезным и для описания процедуры поиска.
Существуют и другие определения процедуры обращения пользователя к системе, например в работе [8], но для описания работы распределенных ИПС Internet больше подходит определение Солтона - в подавляющем большинстве этих систем применяются информационно-поисковые языки типа "Like This". Данный подход хорошо известен как вычисление мер близости "документ-запрос".
В работе [10] приведено 24 меры близости. Однако, в современных распределенных ИПС Internet реально используются только 6. При этом наиболее часто в качестве меры близости рассматривают определение Солтона, например, системы RBSE и WAIS, и его же улучшенную меру близости - системы WebCrawler и Lycos.
Начало применению запросов типа "Like This" положила система WAIS. Именно в ней был впервые сформулирован отказ от использования традиционных информационно-поисковых языков булевого типа и было заявлено о переносе центра тяжести информационного поиска на языки, основанные на вычислении меры близости "документ-запрос". Основная причина такого подхода - желание снять с пользователей заботу по формулированию запросов на информационно-поисковых языках и дать им возможность использовать обычный естественный язык. Ради справедливости следует отметить, что от запросов на естественном языке практически сразу отказались. Система просто проводила нормализацию лексики и удаляла из списка терминов запроса общие и стоп-слова. Тем самым практически один в один выполнялись условия линейной модели индексирования и поиска. После этой процедуры система вычисляла меру близости по выражению и в соответствии с полученными значениями ранжировала информационный массив. Практически все ИПС Internet устроены по этому принципу. Единственным исключением является применение более сложных мер близости, которые в любом случае базируются на выражении (1).
Коррекция запросов по релевантности
Другим важным способом улучшения качества поиска в информационно-поисковых системах Internet стала процедура коррекции запроса по релевантности. Пионером здесь также выступила система WAIS. Пользователю предоставлялась возможность отметить документы, которые являлись релевантными его запросу. После этого запрос расширялся терминами этих документов и снова вычислялось выражение (1) для поисковых образов документов всего массива. В рамках линейной модели индексирования и поиска эта процедура может быть также выражена через матричные выражения.
В литературе по информационному поиску часто можно встретить термин "профиль"[7], который относят к запросам пользователей. Но информационный профиль или тематический профиль имеется и у информационной системы. Наиболее просто тематический профиль системы материализуется в виде классификации, которая применяется в данной системе или рубрикаторе. Не исключение и информационные системы Internet, в которых профиль играет еще и роль навигационного средства, позволяющего получить доступ непосредственно к набору документов, попадающих в тот или иной раздел классификации. При этом многие системы Internet имеют несколько профилей, которые могут быть соотнесены с фасетной классификацией [6].
Естественно, что при таком положении дел в моделях, предназначенных для описания работы ИПС так же должно быть введено понятие профиля и выявлена его актуальность для информационного поиска.
Определим операцию расширения запроса как:
(2) LT x r0 = q1
В данном выражении LT - это транспонированная матрица L. Однако, это не совсем точно. Обычно пользователь не использует свое право отметки релевантных документов и только их термины используются в расширенном запросе или получают больший вес перед терминами других документов [2]. Поэтому в выражение (2) надо ввести еще матрицу - F, призванную учитывать фактор пользователя.
(3) LT x Fk-1 x rk-1 = qk L x qk = rk;
Как видно из (3) матрицы Fk-1 составляют систему фильтров пользователя, при помощи которых он корректирует свой запрос. Эти фильтры имеют в реальных системах конкретную интерпретацию. Так в WAIS и Lycos пользователь просто помечает релевантные документы. В этом случае фильтры превращаются в диагональные матрицы, которые в релевантных документах имеют главную диагональ с единицами, а в нерелевантных - с нули. Но, в общем случае, на диагонали можно размещать и веса релевантности. Эти фильтры могут быть и недиагональными. В этом случае пользователь будет взвешивать документы не только самостоятельно, но и с учетом их связи с другими документами массива, как релевантными, так и нерелевантными, например с учетом его гипертекстовых связей. Но в любом случае совершенно естественно предположить, что система предпочтений пользователя в течение одной сессии работы с ИПС остается неизменной, иначе пользователь просто не знает, что же он в самом деле ищет. Тогда все фильтры одинаковы и не изменяются от шага к шагу:
(4) F0 = F1 = F2 = ... = Fk-1 = Fk = F
В конечном итоге, если пользователь просто переберет все документы массива, то можно составить диагональную матрицу, например, состоящую из нулей и единиц, если речь идет о моделировании системы WAIS.
Процесс коррекции запроса не бывает бесконечным. Обычно он завершается, когда пользователь устает просматривать найденные документы, и приходит к выводу, что нашел искомое, либо действительно больше нет новых релевантных документов. В принципе, даже при прямом просмотре, второй результат является концом процедуры поиска информации. Это значит, что начиная с некоторого вектора отклика этот самый отклик не изменяется:
(5) (L x LT x F) x rk-1 = rk; (A x F) x r = lr:rk = lrk-1.
Из (5) следует, что процесс коррекции запросов по релевантности должен сходиться к собственному вектору матрицы ( L x LT x F). Если при этом пользователь хочет добиться максимального различия документов по степени релевантности, которая фактически определяется значениями компонентов вектора r, тогда речь идет о собственном векторе при максимальном собственном числе. Аналогичный результат можно получить и для набора терминов, которые характеризуют информационную потребность пользователя.
Однако, кроме профилей пользователя при моделировании взаимодействия пользователя и информационной системы. Существенную играет роль сам информационный массив, а точнее набор информационных образов документов массива, скажем, в ранжировании документов по степени релевантности. А именно об этом и идет речь в линейной модели индексирования и поиска информации. Чем ближе оказываются документы к информационной потребности пользователя, тем проще структура матрицы F. Идеальный случай, если эта матрица будет единичной - тогда пользователь вообще не нуждается в ручной коррекции, а система сама проранжирует все документы.
Приведенная трактовка процедуры коррекции запроса и профиля информационной системы имеет аналоги в других методах анализа информационных потоков. Если надо различить какие-либо группы пользователей по их тематике с применением некоторой информационной структуры, то можно прибегнуть к факторному анализу статистики посещения страниц. В этом случае главные компоненты [18] будут задаваться собственными векторами корреляционной матрицы, которая позволяет определить направление максимального разброса показателей посещений, что соответствует собственному вектору при максимальном собственном числе.
Модели индексирования и поиска информации
Одной из ключевых проблем разработки технологии распределенных ИПС Internet является реализация процедуры автоматического индексирования информационных ресурсов Сети. Совершенно очевидно, что методы ручного индексирования для систем, которые функционируют в Internet, не могут быть признаны удовлетворительными в силу следующих причин:
-
Internet - это огромный распределенный информационный ресурс, который просто физически трудно охватить.
-
Информационные ресурсы Internet постоянно изменяются и для актуализации поискового аппарата необходима постояннодействующая система коррекции.
Достаточно нескольких примеров для подтверждения приведенных положений. Согласно [12] число серверов World Wide Web, а значит и документов в этой распределенной информационной системе Internet, удваивается каждые 60 дней. Время жизни почтового сообщения или сообщений Usenet в большинстве систем Internet - 5 суток. Это означает, что такие системы как Altavista и Lycos обязаны обновлять свои поисковые индексы каждую неделю. Имея свой сервер HTTP и наблюдая за статистикой его посещений, можно убедится, что на самом деле это делается значительно реже.
Многие системы (Yahoo, InfoSeek, WebCrawler) индексируют документы простым приписыванием терминов из их названий или гипертекстовых ссылок, однако системы OpenText, Lycos и Altavista осуществляют индексирование на основе применения показателя точности (различительной силы термина), предложенного Солтоном. Как показано в работе [11] понятие точности термина тесно связано с частотой его встречаемости в массиве документов. Эта частота используется и при ранжировании документов при выдаче их пользователю. Сегодня в ИПС Internet наиболее популярен поиск с ранжированием документов. Выражаясь точнее применяется просто ранжирование всех документов в соответствии с мерами близости "документ-запрос" и выдача ссылок на первые n документов с наибольшим рангом. В [3] рассмотрены четыре наиболее популярные меры близости, используемые в информационных системах Internet:
-
расширенный двоичный алгоритм поиска;
-
алгоритм наибольшего цитирования;
-
TFxIDF алгоритм;
-
расширенный векторный алгоритм поиска.
Следует отметить, что наиболее эффективным из этих алгоритмов является TFxIDF, предложенный Солтоном и уточненный в работе [3]. Одним из компонентов меры близости TFxIDF является частота встречаемости терминов в массиве документов.
Обычно плотность функции распределения частоты встречаемости терминов описывают гиперболическим распределением, известным как Закон Ципфа.
Но дело собственно не в самой формуле, задающей плотность распределения частоты встречаемости терминов, а в форме этого распределения. Если плотность подчиняется гиперболическому закону, то, по большому счету нет каких либо четких границ выделения терминов из словаря. Другое дело, если плотность задается распределением с ярко выраженным максимумом, тогда термины должны выбираться из окрестности этого максимума.
Как уже говорилось, наиболее распространенным алгоритмом индексирования в Internet является предложенный еще в 1979 году [9] алгоритм, основанный на различительной силе термина. Суть его в том, что для индексирования используют те термины, которые имеют высокую частоту встречаемости внутри документа и низкую во всем информационном массиве. Сама характеристика вычисляется как отношение частоты встречаемости термина в документе к частоте встречаемости термина в массиве. Используя эту меру системы индексирования документу приписывают первые 20-40 символов, которые и составляют его поисковый образ. Выбор этой меры объясняется простыми прагматическими соображениями, которые становятся очевидными при сравнении выражения с другими способами взвешивания терминов [11] . Здесь следует отметить, что во многом привлечение Alpha-кластеров в проект AltaVista обусловлено опытами по внедрению более ресурсоемких алгоритмов расчета значений качества терминов для процедуры индексирования документов.
С точки зрения [12] и экспериментальных результатов можно сделать два вывода:
-
для того, чтобы использовать взвешивание следует иметь насыщенный словарь.
-
термины индексирования находятся в окрестностях максимума частотного распределения терминов
Насыщение словаря - очень важное свойство систем со свободным словарем. Дело в том, что говорить вообще о векторной модели информационного потока и ее применимости для информационных систем можно только в том случае, когда мощность словаря (число представленных в нем терминов) фиксирована. Пока речь шла о локальных информационных системах, то вопрос о размере словаря не стоял. За время эксплуатации системы (с момента загрузки документов и до момента актуализации) информационный массив и словарь системы не менялись, и, следовательно были фиксированными. В Internet дело обстоит совсем иначе. Во-первых, нет единого информационного массива, который можно было бы одним махом загрузить, построив долгоживущий индекс. Поэтому система постоянно осуществляет сканирование сети и коррекцию своего поискового аппарата - словарь, который определяется индексом постоянно изменяется. Во-вторых, из-за отсутствия единой информационной службы нельзя организовать систему с контролируемым словарем, как это было сделано для INIS или INSPEC. Таким образом в Internet происходят два процесса: постоянный рост информационного массива, с одной стороны, и постоянное увеличение словаря системы, с другой. По данным информационной службы Lycos ее поисковый массив (индекс) на начало 1996 года составлял уже 4 Тбайта.
Но и Lycos, и OpenText, и Altavista, и другие системы Internet применяют линейную модель индексирования и поиска, используя различительную силу термина в алгоритмах автоматического индексирования и поиска. Следовательно, применяемые алгоритмы ограничивают словарь, допуская его незначительный рост.
Именно это и осуществляют все реально функционирующие системы, ограничивая размер поискового образа документа 20-40 наиболее "тяжелыми" терминами из содержания. При этом в словарь попадают только термины поисковых образов. Следует также отметить, что источником терминов индексирования, в большинстве случаев выступает не весь документ, а только отдельные его части: заголовок, гипертекстовые ссылки, подзаголовки, специальные поля. Таким образом удается контролировать размер словаря и оставаться в рамках линейной модели индексирования и поиска.
В итоге выполняется второе предположение из приведенного списка -использование различительной силы терминов в качестве веса терминов позволяет выбирать термины из окрестности максимума частотного распределения.
От информационного поиска к навигации
В предыдущих разделах была приведена теоретическая основа современных информационно-поисковых систем в их классической реализации. Надеюсь, теперь понятно: от системы можно получить только то, что в ней имеется. Если ваши информационные потребности лежат в плоскости ортогональной тематической плоскости системы, то можно вообще на свой запрос ничего путного не получить или получить столько "шума", что полезная информация в нем просто потеряется.
Но кроме проблемы информационного поиска в WWW существует еще и проблема администрирования страниц и гипертекстовых навигационных документов. Собственно, задача любого навигационного средства - сократить путь просмотра гипертекстового графа от его начала до полезной информационной страницы.
Остановимся на двух основных аспектах, касающихся управления навигацией:
-
жизненный цикл страницы World Wide Web;
-
детектирование структурных изменений в запросах пользователей.
Обе проблемы важны как с точки зрения коммерческго использования WWW, когда сеть применяется с целью глобализации бизнеса, так и с точки зрения повышения качества информационного обслуживания.
Цель анализа любой статистики обращений к информационной системе - повышение эффективности ее работы. Однако само понятие эффективности может быть истолковано по разному. Для коммерческих систем - эффективность будет исчисляться в терминах прибыли от эксплуатации этой системы, в то время, как эффективность информационной системы бюджетной организации может складываться на основании числа реальных пользователей, количества запросов и, опосредованно, на основе доли бюджетных средств, которые расходуются на систему.
Жизненный цикл страницы Web
Рассмотрим жизненный цикл страницы на примере не одной, а нескольких, образующих небольшую группу, одновременно размещенных страниц, что больше соответствует реальной практике использования Web. Тематика страниц- авария на Чернобыльской атомной электростанции. Конечно, это далеко не рекламная страница какой-нибудь компании, но жизненный цикл, а точнее основные периоды этого цикла, у всех страниц на WWW во многом схожи.
На рисунке 1 видно, что примерно через 150 суток начинает проявляться определенный интерес со стороны пользователей к информации, расположенной на сервере. Приблизительно те же данные можно получить и на других серверах сети. При этом интересно отметить, что включение сервера в так называемые Top-списки на задержку практически никак не влияет. Такой эффект легко объясним. Дело в том, что ссылка попадает в список после внесения ее в список популярного коммерческого сервера. Но в этот список ссылка попадает либо после сканирования сети роботом, либо из сообщения в телеконференции, либо после ее регистрации вручную администратором системы. При этом необходимо время для индексирования ссылки и задержки ее в кэширующем сервере коммерческой системы для того, чтобы администрация системы обратила внимание на существование такого ресурса и уже вручную внесла изменения в классификацию ресурсов Internet на домашней странице сервера коммерческой службы. Если анонс был сделан летом, то приходится сделать еще и скидку на сезон. В результате получаем задержку, приблизительно в 150 дней. Особенно это характерно для специализированных систем, имеющих относительно узкий круг пользователей. Попадание в индекс поисковой системы дает рост обращений только в том случае, если данная тема становится "горячей", как, например, после заявления Украины о том, что Чернобыльская станция снова взорвется в начале осени 1996 года. Существенный прирост посещений можно зарегистрировать только после попадания в классификации информационных систем, но этот процесс носит характер ручного индексирования и предполагает предварительный анализ предметной области экспертом.
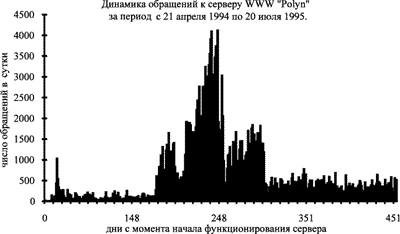
Рис. 1. Статистика посещений за год
Теперь обратим внимание на пик в начале графика. Точно такой же пик отмечается на всех серверах - это обращения администратора системы к файлам базы данных. До тех пор, пока система не выйдет на стабильный режим работы, администратор системы является самым частым гостем на ее страницах.
Пик посещений приходится на 230-250 сутки после начала функционирования сервера. С отметки 300 сервер устойчиво посещают только около 700 пользователей в сутки. Это число отличается от того, которое было до начала роста популярности (150 суток с начала функционирования за вычетом активности администратора).
Чтобы убедится в том, что это различие статистически значимо, проверим следующую гипотезу: распределения частоты посещения страниц базы данных в начальный период работы сервера и после пика посещений одинаковы. Для этого выберем два периода наблюдений: июль 1994 и май 1995 года. В качестве статистического теста используем тест Колмогорова-Смирнова. Такой выбор объясняется тем, что ни форма, ни параметры обоих распределений априори не определены. На рисунке 2 приведены графики этих распределений.
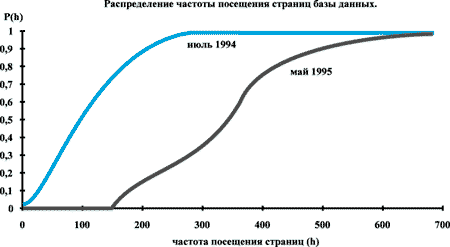
Рис. 2. Графики распределений посещений страниц базы данных в начальный и в стационарный период работы сервера
Для данного примера значение статистики равно:
D = max |F1(x) - F2(x)|; где
F1(x) и F2(x) - сравниваемые функции распределения.
D* = 0.83 > D = 0.39;
где D* - эксперимент, а D - таблица.
Табличное значение получено для уровня значимости, который равен 0.05, а при условии, что табличное значение меньше экспериментального, гипотеза о равенстве распределений отвергается.
Для того, чтобы еще раз убедиться в полученном результате, сравним два распределения стационарного периода работы сервера: май и апрель 1995 года (рисунок 3). На этом рисунке видно, что распределения тоже имеют различия, но гораздо меньшие чем в первом случае. Это подтверждает и статистический тест:
D = max |F1(x) - F2(x)|; где
F1(x) и F2(x) - сравниваемые функции распределения.
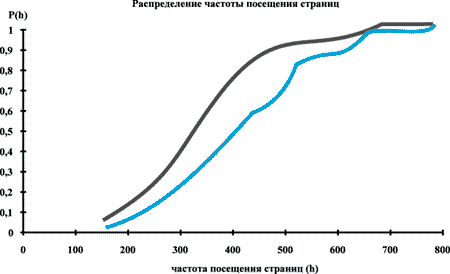
Рис. 3. Распределения частоты посещения страниц в стационарный период работы сервера.
D* = 0.28 < D = 0.39;
где D* - эксперимент, а D - таблица.
Табличное значение больше расчетного, и, следовательно, нет оснований для того, чтобы отвергать гипотезу о равенстве распределений.
Учет распределения частоты посещений важен с двух точек зрения. Во-первых с чисто коммерческой. Наибольший процент использования технологии WWW дает реклама товаров и услуг - 80% всей информации. Чрезвычайно важно знать когда реально пользователь получит реакцию на информацию о товаре и услуге, размещенной в Internet. Как показывает статистика обращений, это происходит не мгновенно. При этом следует четко представлять когда реклама становится неэффективной, т. е. после того , как большинство потенциальных покупателей ее уже посмотрели. Как видно из графика (рис. 1), этот период составляет примерно 200 суток, причем данный показатель одинаков для всех серверов. На коммерческих серверах трудно определить этот порог, в то время как специализированные серверы дают ясное представление о максимальном наплыве пользователей всех категорий. Дело в том, что большинство пользователей, обратившихся на сервер в самый пик - это случайные люди, а их процент во всех системах один и тот же. Таким образом выставлять рекламу на срок больший, чем начальный период плюс 200 суток нецелесообразно. Для специализированных систем - это период проведения опросов, манифестов и других мероприятий информационного характера. Кроме того очевидно, что простое обращение в телеконференции Usenet не дает гарантии максимального оповещения пользователей - сообщение Usenet хранится около 5 суток, а этого, как видно из графика совсем недостаточно. Поэтому размещение сообщения в архиве телеконференции или в поисковой системе типа Lycos является оправданным даже с коммерческой точки зрения.
Последнее замечание хотелось бы пояснить. Еще год назад, до широкого внедрения Dial-IP (доступ к Internet по коммутируемой телефонной линии с получением от провайдера постоянного или выделенного IP-адреса) это замечание было верно только частично. Многие пользователи подписывались на телеконференции, что означало их принудительное оповещение о поступивших материалах. С внедрением Dial-IP ситуация меняется. Теперь пользователи просматривают материалы конференций в том же режиме, что и страницы Web, а это значит, что закономерности Web можно ассоциировать и с Usenet - контингент пользователей один и тот же. Более того даже средство просмотра списков новостей и страниц Web одно и то же - программы класса Nescape Navigator.
Второй аспект проблемы - это отделение шума случайных посещений от запросов действительно заинтересованных в информации пользователей. Совершенно ясно, что изменять структуру базы данных первые 300 суток после ее установки в сети нельзя. В этот период число случайных посещений превосходит число тематических, что приводит к искажению представлений о тематических потребностях реальных пользователей. Чтобы подтвердить этот вывод, рассмотрим еще один график (рисунок 4).
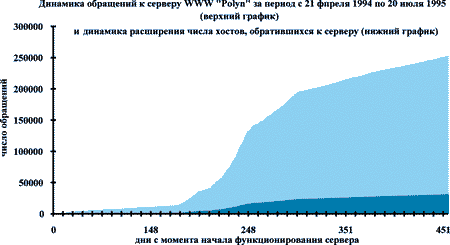
Рис. 4. Рост числа машин, с которых обращаются к базе данных "Полынь"
Через 300 суток после начала функционирования сервера рост числа новых машин, с которых обращаются к данным Website существенно замедляется при постоянном числе обращений в сутки к страницам базы данных. Что еще раз подтверждает вывод о стабилизации круга пользователей системы.
Вот еще один интересный график (рисунок 5).
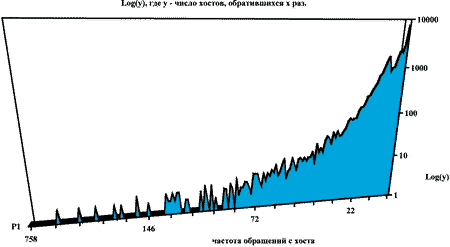
Рис. 5. Распределение частоты обращений пользователей к страницам базы данных "Полынь" к середине лета 1995 года
Во-первых он показывает, что существует несколько сотен пользователей, которые просмотрели все навигационные страницы базы данных - около сотни пользователей работают с базой данных регулярно. Если учесть, что проблемами моделирования загрязнения окружающей среды в результате аварии на Чернобыльской станции в мире занимаются только около десяти исследовательских групп, из которых не все имелют доступ к WWW, то такой показатель можно считать достаточно хорошим.
Любопытно и то, что большинство случайных пользователей предприняло только одно посещение страниц базы данных. Дело в том, что корневая страница имела встроенную графическую картинку, загружаемую по отдельному запросу к серверу. Если пользователь работает с графической программой просмотра страниц World Wide Web, то при случайном обращении к базе данных пользователь должен осуществить два посещения (файл HTML и файл GIF). Тогда максимум должен приходится на 2, а не на 1. Казалось бы большинство пользователей работает с алфавитно-цифровыми программами просмотра, но этому противоречит статистика программ-клиентов - первое место сегодня занимает графическая программа Netscape Navigator. Следовательно остается только одно - пользователи отключают режим автоматической подкачки графики, и берут иллюстрации только по специальному запросу.
Анализ структуры обращений
Основная идея анализа статистики посещений страниц базы данных состоит в том, чтобы найти такие характеристики и свойства компонентов системы, которые можно было бы использовать для классификации пользователей по группам интересов, а через них и корректировать структуру навигационного графа системы. Данный подход хорошо коррелирует с тенденцией применения технологий WWW для организации корпоративных информационных систем, которые часто рассматриваются в рамках концепции построения сетей intranet.
Сегодня статистика посещений баз данных Web сводится к выявлению наиболее посещаемой страницы и к поиску наиболее активного пользователя. Однако, это только малая толика того, что можно извлечь из анализа статистики.
Главное назначение любого навигационного аппарата - предоставить удобные и быстрые средства доступа к информации. Задачей систем иерархических меню, каковыми в большинстве случаев являются навигационные страницы Web, является построение не очень разветвленных и достаточно коротких меню, которые бы при относительно небольшом числе шагов приводили бы пользователя к искомому материалу.
Вычислять профиль системы, особенно, когда число страниц превышает сотню, а число пользователей переваливает за десятки тысяч, довольно трудная задача с точки зрения ресурсов вычислительной установки. Учитывая, что большинство серверов в нашей стране - обычные ПК (к слову, такая задача может оказаться "не по зубам" и для более серьезных систем), необходимо найти такое решение, которое с одной стороны отражало бы профиль системы, а с другой не требовало бы большого количества ресурсов для его расчетов.
Как показано на рис. 1, существует, по крайней мере, три периода функционирования системы: начальный, пиковый и стационарный. Прежде чем оценивать влияние различных типов пользователей на статистику посещений, следует определить зависимость структуры системы от периода, в который проводятся измерения.
Одним из решений является разбиение всех страниц базы данных (или их части) на две группы, и построение графиков посещения страниц в координатах этих групп. Для иллюстрации идеи структурного анализа обращений пользователей к страницам корпоративного сервера снова возьмем базу "Полынь". При анализе посещений базы данных каждому пользователю ставится в соответствие частота посещения графических и текстовых страниц базы данных. Такое разбиение основано на следующих предположениях:
-
При эксплуатации системы было обнаружено большое количество дотошных пользователей, которые посетили все страницы базы данных. Такого числа интересующихся техническими подробностями аварии в мире быть не должно. Следовательно, пользователей сети главным образом интересует нечто, отличающее их от специалистов по авариям на атомных станциях. Скорее всего это иллюстрации, что косвенно подтверждается обращениями со стороны школьников, студентов и редакторов различных популярных и специальных изданий.
-
Кроме того, в различные периоды функционирования системы число таких пользователей должно быть разным. На первом этапе систему посещают те, кто опирается на нестандартные средства поиска. В эту категорию могут входить пользователи любого типа, но при этом их всех объединяет хорошее знание сетевых информационных ресурсов, а по сему это все-таки своеобразная тематическая группа. В период пика должны преобладать пользователи, которых больше интересуют красивые картинки, а не тематическое содержание, что должно отражаться на пользовательском профиле системы. В стационарный период основную массу составляют пользователи, для которых тематика базы данных является главным, но при этом следует учитывать, что чтение текста с экрана гораздо хуже воспринимается, чем представление информации в виде графиков и гистограмм.
Рассмотрим выдвинутые предположения с различных углов зрения и попробуем найти им подтверждения. Кроме этого, оценим эффективность используемой в системе структуры базы данных.
Начальный этап функционирования системы характеризуют данные на июль 1994 года. Этот период выбран из тех соображений, что влияние администрации на статистику посещений системы уже мало (все поправки и тесты, касающиеся ошибок разметки и размещения страниц к этому моменту были выполнены). Характерная для этого периода картина посещений представлена на рисунке 6.
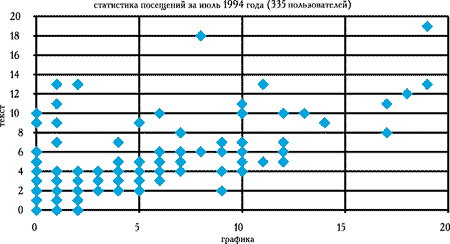
Рису. 6. Статистика посещений графических и текстовых страниц в начальный период функционирования сервера
Как видно из графика (рисунок 6), основная масса точек лежит в прямоугольнике 15х10, что соответствует среднему соотношению числа графических страниц на одну текстовую страницу в базе данных. Все точки, выше уровня 7 текстовых страниц, говорят о более углубленном интересе к проблематике базы - ко всей графической информации можно добраться с первых 5-7 страниц, если не использовать прямые адреса файлов. Наличие точек с нулевым посещением графических страниц говорит о том, что в Internet существует группа лиц, которая использует только текстовые программы просмотра. Вообще превышение количества текстовых страниц над графическими говорит о пользователях, которые ищут тематическую информацию, а графику заказывают только в случае острой необходимости.
Пиковый период функционирования системы рассмотрен на примере статистики обращений в ноябре и декабре 1994 года. На рисунке 7 приведен декабрьский график.
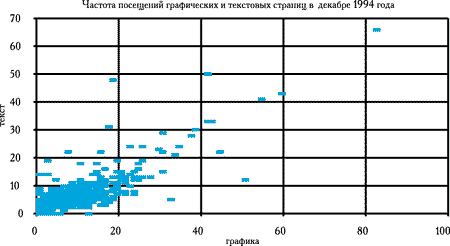
Рис. 7. Статистика обращений в пиковый период (декабрь 1994 года, 10106 пользователей)
Как видно из рисунка 7, основная масса пользователей находится в прямоугольнике 20х10, что близко к показателям начального периода функционирования сервера, однако здесь уже гораздо лучше выражена тенденция соотношения страниц графики на одну страницу текста, характерная для базы данных "Полынь". Следует при этом отметить, что она проходит несколько круче, чем диагональ прямоугольника 20х10.
Приведем теперь аналогичную картинку для стационарного периода функционирования сервера - июнь, июль 1995 года (рисунок 8).
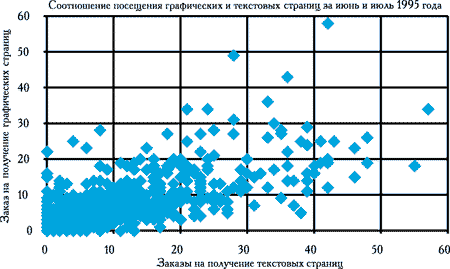
Рис. 8. Статистика обращений к графическим и текстовым страницам в стационарный период функционирования сервера
На рисунке 8 можно уже выделить три тенденции: точки в начале графика, точки ниже прямой y = x и точки выше прямой y = x. Говорить о трех группах, а не о двух последних приходится по следующей причине: график (рисунок 8) - это только проекция двухмерной плотности распределения частоты посещения страниц базы данных. Это означает, что за каждой точкой на этой плоскости стоит разное число пользователей, которые могут быть охарактеризованы парой: число посещений текстовых страниц, число посещений графических страниц. Точки за пределами квадрата 20х10 расположены вдоль осей, характеризующих различные фрагменты базы данных. Точки внутри указанного квадрата характеризуют скорее пользователей, занятых поиском иллюстраций, нежели специалистов, заинтересованных в получении описательной информации и данных.
Убедимся в этом следующим образом: проведем статистический тест на долю посещения графических страниц в различные периоды функционирования сервера. При этом будем подсчитывать число посещений графических страниц на общее число посещений страниц в те же периоды времени. В качестве периодов сравнения выберем июль, ноябрь и декабрь 1994, апрель, май и июнь 1995. Проверим гипотезу о том, что две выборки относятся к одной и той же генеральной совокупности на том основании, что разность долей признака в выборках из одной генеральной совокупности при числе точек более 30 подчиняется нормальному закону распределения [13].
Гипотеза проверялась для уровня значимости 0.01 для пар выборок составленных на основе месячных интервалов наблюдений, которые соответствовали различным периодам функционирования сервера. При этом в качестве доли признака рассматривалось число посещения графических страниц к общему числу посещений. Результаты получились следующие.
Таблица 1. Доля графических страниц в общем объеме посещения страниц базы данных "Полынь"
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
- В начальный период число обращений было сбалансировано, а в период пика стал наблюдаться рост интереса к графической информации. Для того, чтобы усилить это различие, в главное меню системы (домашняя страница всей базы данных - та, на которую пользователи попадают в первую очередь) была введена строчка список иллюстраций (разница между ноябрем и декабрем). В стационарный период эта разница увеличилась, но больше уже не менялась. Основное внимание пользователи уделяли графикам выброса радионуклидов из шахты реактора (в пиковоый период, основной спрос наблюдался на фотографии разрушенного реактора).
После проведения расчетов получены следующие результаты: существуют значительные расхождения по условию посещения графических страниц между начальным периодом эксплуатации и остальными этапами, а пик посещений существенно отличается от стационарного периода эксплуатации сервера. В то же время внутри периодов эксплуатации особых расхождений не наблюдается. Однако, в эти результаты могли не войти более тонкие различия в структуре посещения страниц базы. В частности, если построить графики распределений посуточного посещения всевозможных страниц за исследуемые интервалы времени, то можно заметить некоторое различие в этих распределениях (рисунок 9).
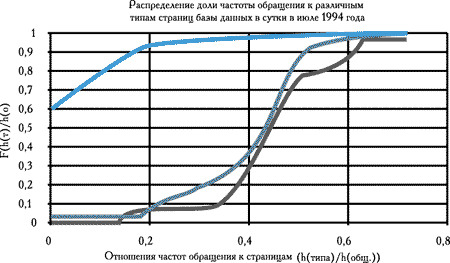
Рис. 9. Распределение доли признака (типа страниц) в ежедневной статистике посещений за июль 1994 года. Средний график - обращение к графическим страницам, нижний график - обращение к текстовым страницам, верхний график - обращение к скриптам
Кроме текстовых и графических страниц было рассмотрено также и количество обращений к численным данным, хранящимся в базе данных "Проба". Такой доступ осуществлялся через скрипты и специальные формы доступа. Включение в рассматриваемые типы документов скриптов определено тем, что при их помощи обычно организуют доступ к таким ресурсам, которые ориентированы на пользователей, действительно заинтересованных в получении информации из базы данных системы. При помощи скриптов может осуществляться идентификация пользователей, доступ к коммерческим ресурсам, доступ к данным из хранилищ средствами СУБД и т.п.
Как видно из графика на (рисунок 9) в начальный период функционирования нашего сервера распределения доли обращений к текстовым и графическим страницам были примерно одинаковые. При этом вероятность обращения к численным данным отличалась от вероятности обращения к информационным страницам (графика и текст) примерно в 4 раза. При пиковом режиме картина изменяется (рисунок 10).
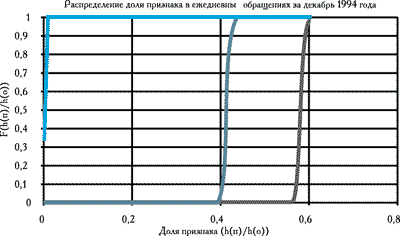
Рис. 10. Графики распределений доли признака (текст, графика, скрипты) в объеме посещений страниц базы данных за сутки в декабре 1994 года. Правая кривая - графика, средняя - текст, левая - скрипты
Доля посещения графических страниц растет и перекрывает долю посещения текстовых страниц. При этом график распределения становится круче, что говорит об уменьшении дисперсии, т. е. о том, что пользователи системы имеют схожие интересы. При этом, если в ноябре еще заметны обращения к численным данным, то в декабре их практически не видно, поскольку их доля чрезвычайно мала. Введение раздела иллюстраций в главное меню системы в декабре еще больше уменьшает различия в поведении пользователей при просмотре базы данных.
При стационарном режиме снова наблюдается изменение картины посещений страниц базы данных (рисунок 11).
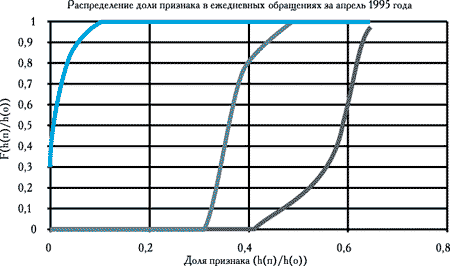
Рис. 11. Графики распределений доли признака (текст, графика, скрипты) в объеме посещений страниц базы данных за сутки в апреле 1995 года. Правый график - графика, средний график - текст, левый график - скрипты
В апреле опять увеличивается дисперсия посещения графических страниц и проявляются обращения к численным данным. Увеличение дисперсии посещений вызвано тем, что графика просматривается не в контексте списка иллюстраций, а порой просто с использованием прямых адресов, которые пользователи выбирают из списков закладок. При просмотре через список иллюстраций на страницу текста приходится примерно равное количество страниц и все пользователи придерживаются примерно одинаковой стратегии просмотра, что уменьшает дисперсию в пиковый период. В стационарный период эти факторы теряют свое значение.
Эти соображения подтверждают и результаты анализа данных за май и июнь 1995 года - первый месяц имеет более гладкие формы кривых чем апрель и июнь. В июне 1995 года было зафиксировано самое большое число обращений в сутки к скриптам, что привело к появлению доли признака, равной почти четверти суточных обращений. И хотя вероятность такого события все еще продолжает оставаться относительно небольшой, тем не менее появление этого типа обращений довольно симптоматично.
Для того, чтобы проверить насколько значимы все эти эффекты, были проведены тесты, которые основывались на суточном посещении страниц базы данных за исследуемые периоды. Анализировалась однородность выборочных коэффициентов корреляции посещений различных типов страниц за те же шесть периодов эксплуатации сервера. В рамках данной статьи приведем только одну таблицу для парного сравнения выборочных коэффициентов корреляции соотношения "графика-текст" за исследуемые периоды.
Таблица 2. Значимость различий между выборочными коэффициентами корреляции. Графика-Текст (U1-0.05/2 = 1.96)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
- Из таблицы 2 следует, что существенные отличия в степени зависимости числа обращений к текстовым и графическим страницам имеют место только в пиковый период функционирования базы данных. Структура обращений в начальный и в стационарный периоды в значительной мере совпадают. Нет оснований говорить о различной степени связи для июля 1994 года и апреля - июля 1995 года.
В то же время апрель 1995 года отличается от других месяцев стационарного периода функционирования сервера. Таким образом по критерию сравнения выборочных коэффициентов корреляции можно выделить как периоды работы сервера, так и различия внутри периодов.
Проведение такого рода тестов для других пар показателей ("графика-CGI", "текст-CGI") позволяет выявить еще ряд интересных зависимостей. Так, например, обращения к тексту и CGI-скриптам коррелируют гораздо лучше, чем обращения к графике и скриптам. Конечно, все эти зависимости определяются характером базы данных и ее тематическим профилем, а также средствами, которые использует администрация системы для размещения материалов в WWW. Зная все эти особенности администрация сервера может легко построить тесты для проверки своих представлений о поведении пользователей системы, и если эти представления не совпадают с реальностью, скорректировать архитектуру гипертекстовых графов и, может быть, изменить средства доступа к данным.
Коррекция структуры навигационных страниц
Поведение пользователей не всегда приводит к изменению профилей информационной системы. Так например, если рассматривать лишь пользователей, которые случайно заглянули на наши страницы, то профили системы, описывающие ее структуру не меняются от числа этих пользователей. Если пользователи аккуратно просматривают все страницы базы данных, то это также не приводит к изменению профилей. Увеличение доли "случайных" или "дотошных" пользователей среди всех пользователей системы в стационарный период работы сервера - дурной признак. Это означает, что либо существует терминологические несоответствия между узлами графа системы и информационными запросами пользователей, либо сама предметная область в данной системе плохо структурирована. Кроме того, информационные потребности пользователей постоянно изменяются, что приводит к изменению в статистике обращений к базе данных. Это в свою очередь должно вызывать изменения в структуре гипертекстового графа системы.
Если рассматривать Website "Полынь", то пользователи по мере эксплуатации все меньше внимания стали уделять фотографиям укрытия разрушенного блока ЧАЭС, а больше начали интересоваться информацией о динамике выброса радионуклидов и загрязнении местности. Простая статистика разбиения страниц на графику и текст существенных изменений при этом не фиксировала и разбиение на иллюстрации и содержательную часть оставалось без изменения до весны 1996 года. Однако, после проведения тематического разбиения страниц на общее описание аварии и специальные вопросы загрязнения окружающей среды было обнаружено изменение тематического профиля запросов, что заставило скорректировать структуру навигационных страниц в сторону сокращения числа иерархий от домашней страницы до страниц с описанием выброса активности.
Другой результат дополнительного разбиения связан с анализом уменьшающегося потока запросов к фотографиям. Здесь было обнаружено, что число обращений собственно к фотографиям укрытия и внутренних помещений остается постоянным, а относительная доля таких обращений даже увеличивается. Для описания состояния блока реактора была введена дополнительная ссылка в содержание системы, что еще сильнее изменило соотношение обращений к фотографиям в сторону увеличения доли обращений к изображениям внутренних помещений. На основе этого было принято решение разместить тестовый Website "Inside" как самостоятельную базу данных со своим адресом. В ответ на этот шаг администрация сервера стала получать почту с вопросами о возможности размещения полного описания внутренних помещений блока и информации о наличии в них радиоактивных материалов.
Следует также отметить, что из всех пользователей нами были выбраны те кто известен как специалист в области радиационных аварий. Интересы этих групп достаточно хорошо совпадали с первоначальным тематическим разбиением навигационных страниц. Часть пользователей, которые до обращения к нашей базе данных не были нам известны, но по тематике своих обращений совпадали с выбранными группами участвовали в опросе, и их интересы также принимались во внимание при формировании тематического графа Website.
По мере эксплуатации стало очевидным, что ряд страниц, которые ранее пользовались популярностью у профессионалов и были включены в верхние уровни иерархии, стали менее посещаемыми. Пользователи часто использовали их просто как проходной двор для продвижения внутрь системы. Определить это можно было по отсутствию интереса к графике, которая на этих страницах была размещена. Такое наблюдение заставило поменять местами ряд страниц в иерархии доступа. Однако, полное удаление страниц из Website было бы неправильным - всегда существуют пользователи, которые возвращаются к первоначальной информации. Кроме этого имеется еще и феномен запоминания места расположения информации и ее гипертекстового окружения. Этот феномен заставляет вести историю, сохраняя старые копии Website как целое. Это общая для Web практика и мы здесь не являемся пионерами.
Другое интересное наблюдение связано с эффективностью иконизации иллюстраций. Данный прием рекомендуется в руководствах по созданию "хороших" Website. Он заключается в том, что встроенная картинка приводится на странице в виде своей уменьшенной копии, а если пользователь хочет рассмотреть детали, он вызывает гипертекстовую ссылку на оригинал и работает с ним. К сожалению оценки с точки зрения различительной силы этого метода по отношению к тематическому разделению пользователей получить пока не удалось. На одной странице не были размещены разные тематические фотографии. Однако следует отметить, что в ряде случаев пользователи действительно смотрели не все фотографии или схемы со страницы. Все-таки этот прием носит скорее эстетический, нежели тематический характер и определен особенностями технологии просмотра данных на ограниченном пространстве экрана монитора.
От навигации к intranet
Приводя такое обилие математической терминологии, не свойственное для статей об Internet вообще и WWW в частности, хотелось бы еще раз подчеркнуть две основные идеи, ради которых задумывалась данная статья.
Во-первых, Internet и WWW становятся повсеместно используемыми информационными технологиями, а это означает, что время "хакеров" и простых решений прошло. Как любая "высокая" технология Internet для своего развития и применения требует соответствующих методов повышения эффективности использования.
Во-вторых, внедрение WWW в качестве основы корпоративных информационных систем - это не только и не столько реклама и вопросы безопасности. Читая статьи на эту тему, создается впечатление, что обсуждаются главным образом две темы: как о себе можно заявить в "Сети сетей" и как спрятаться от всего мира за бастионами брандмауэров и хитрыми механизмами шифрования. Использование ресурсов Сети для нужд корпорации отходит на второй план. Собственно, intranet - это три равноправных компонента, функциональные особенности, которых можно было бы сформулировать в виде девизов:
-
Что мы можем дать Сети.
-
Что технология Сети может дать нам.
-
Что Сеть, как информационный ресурс, может дать нам.
В статье сосредоточено внимание на последнем из этих трех тезисов, который в практическом плане сводится к организации корпоративной информационной службы, где кроме доступных всему миру "домашних" страниц компании проводилось бы детальное изучение ресурсов самой сети, создавались бы поисковые страницы для каждого из подразделений, проводился бы анализ информационных потребностей сотрудников с целью коррекции страниц. Современные кэширующие proxy-серверы позволяют такую работу организовать.
Вообще, проблема эта гораздо шире. Ведь надо организовывать и анализ информационных запросов конкурентов и анализ информационных потребностей клиентов, и систему защиты от анализа своих информационных запросов, что должно быть частью системы информационной безопасности.
Если заменить слова "компания" или "корпорация" на слова "бюджетная организации", "университет" или "научно-исследовательский центр", то суть вопроса от этого не изменится, а он только приобретает еще большую остроту, учитывая трудности с информационным обеспечением работ из-за вечной нехватки средств и "случайность" связей в рамках международного сотрудничества.
Литература
1. Паук - Описание системы. RASER Company. 1995.
2. Kahle, B., and Medlar, A., "An Information System for Corporate Users: Wide Area Information Servers," Technical Report TMC-199, Thinking Machines, Inc., April 1991.
3. Budi Yuwono, Dik L.Lee. Search and Ranking Algorithms for Locating Resources on the World Wide Web. In Proceedings of the Forth International Conference on the World Wide Web, New York, November, 1995.
4. Koster, M., "ALIWEB: Archie-like Indexing in the Web," Computer Networks and ISDN Systems, 27(2), pp. 175-182, 1994.
5. Martin Bartschi. An Overview of Information Retrieval Subjects. IEEE Computer, # 5, 1985, p. 67-84
6. Дж. Солтон. Динамические библиотечно-информационные системы. Мир, Москва, 1979.
7. Попов И.И. Оценка и оптимизация информационных систем. - М: МИФИ,. 1981.
8. Решетников В.Н. Алгебраическая теория информационного поиска. Программирование, # 3, 1979, стр. 68-73.
9. Yu C.T., Salton G. Effective Information Retrieval Using Term Accuracy. Communication ACM, V.20, # 3, p. 135-142.
10. T.Norault, M. McGill, and M.B. Koll. "A performance Evaluation of Similarity Measures, Document Term Weighing Schemes and Representations in Boolean Environment, Information Retrieval Search," R.N. Oddy et al., eds., Butterworth, London, 1981, p. 57-76.
11. Yu C.T., Lam K., Salton G. "Term Weighting in Information Retrieval Using the Term Precession Model. Communication ACM, V.29, 1982, p. 152-170.
12. И.И. Попов, П.Б. Храмцов. Распределение частоты встречаемости терминов для линейной модели информационного потока. НТИ, Сер.2, # 2, стр. 23-26, 1991.
13. С.А. Айвазян, И.С. Енюков, Л.Д. Мешалкин. Прикладная статистика. Исследование Зависимостей. Москва, ФиС 1985.
Павел Храмцов (paulkh@yandex.ru) -- РНЦ, Курчатовский институт, (Москва).
