
Беспрецедентный рост сетей Internet и intranet привел к тому, что традиционных средств полнотекстового поиска, а также традиционных методов поиска в базах данных оказалось уже недостаточно. Громадный объем и разнообразие информации, доступной сегодня в глобальных и корпоративных сетях, создали устойчивый спрос на интеллектуальные и простые в использовании средства поиска, обеспечивающие понятные, гибкие и эффективные возможности для получения искомой информации. Одним из таких решений стал Excalibur RetrievalWare, предназначенный для поиска неструктурированной информации в информационных массивах практически неограниченного объема.
Компания Excalibur Technologies предложила недавно программный продукт RetrievalWare Web Server, в котором используется весьма интересный подход к поиску неструктурированной информации, сочетающий технологию адаптивного распознавания образов (APRP - Adaptive Pattern Recognition Processing) и технологию семантических сетей доступа к данным через серверы HTTP. Данный пакет предоставляет широкий спектр простых в использовании средств поиска информации для приложений World Wide Web и позволяет создавать решения на основе Internet и intranet. В качестве отличительных особенностей RetrievalWare можно назвать следующие:
Основой RetrievalWare является универсальная технология индексирования и поиска информации (APRP), которая позволяет создавать приложения для поиска по содержанию не только текстовых документов, но и изображений, звука, видео и других видов оцифрованных данных. Способность работать с различными типами информации наряду с высокой скоростью индексации и возможностью быстрого нечеткого поиска делают эту технологию достаточно перспективной для разработки поисковых решений в глобальных и корпоративных сетях, поддерживающих широкий спектр мультимедиа данных.
Архитектура RetrievalWare
RetrievalWare строится на основе гибкой, модульной и масштабируемой архитектуры, позволяющей проводить параллельную обработку на серверах, распределенных в локальных сетях, частных корпоративных сетях и Internet.
На рис.1 представлен набор средств разработки RetrievalWare. В состав этого набора входит сервер ввода и поиска текстов, сервер Web, а также произвольное число дополнительных компонентов, разрабатываемых третьими фирмами. Среда разработки приложений RetrievalWare SDK состоит из API на уровне ядра системы, высоуровневого интерфейса программирования и инструментария для работы в среде клиент/сервер. Кроме этого в состав поставки входит серия примеров графических интерфейсов пользователя, поставляемых в исходных кодах. Инструментальные средства соответствуют промышленным стандартам Visual Basic Custom Controls (VBX) и DLL. Поддерживаются интерфейсы к наиболее распространенным реляционным базам данных: Oracle, Informix, Sybase и Microsoft SQL Server.
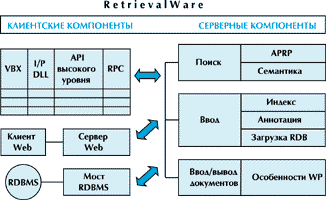
Рисунок 1.
Набор средств разработки RetrievalWare.
Ядро RetrievalWare состоит из набора независимых серверных процессов, что дает возможность достигать необходимой эффективности и надежности при загрузке документов, индексировании и обработке запросов. Одновременно осуществляется поддержка безопасности и шифрация данных. В ядро включены также специальные процессы, позволяющие интегрировать полнотекстовый поиск и возможности поиска реляционных баз данных через открытый шлюз.
RetrievalWare Web Server
RetrievalWare Web Server (рис. 2) обеспечивает интерфейс пользователя на основе шаблонов HTML, что необходимо для взаимодействия с серверами HTTP на базе интерфейса CGI. В отличие от других серверов поиска Web, RetrievalWare Web Server поддерживает идеологию выделенного сервера приложения, обеспечивая одновременную обработку большого количества параллельно поступающих запросов.
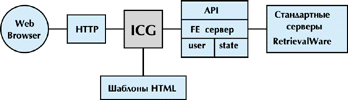
Рисунок 2.
Состав и взаимодействие компонентов RetrievalWare Web Server.
RetrievalWare Web Server поддерживает NT и основные UNIX-платформы. Он имеет несколько режимов поиска и серверных компонентов, обеспечивающих возможности полнотекстового поиска. Текстовые серверы RetrievalWare представляют собой открытый расширяемый конвейер из модулей индексирования, обработки запросов и отображения результатов, который настраивается для работы на нескольких процессорах одного сервера или на любых машинах в сети серверов. Возможности системы RetrievalWare Semantic & Pattern Server объединяет технологии семантических сетей и APRP компании Excalibur с набором традиционных методов текстового поиска. Разнообразные возможности поиска текста предуматривают, в частности, поиск по смысловому значению слов; поиск на основе адаптивного распознавания образов; обычный поиск слов; нечеткий поиск; статистический поиск, а также поиск с использованием булевой логики.
RetrievalWare Pattern Server сочетает технологии APRP, статистического и логического поиска. Он оптимизирован для приложений, требующих высокого уровня нечувствительности к ошибкам, таких, как приложения для управления документами, в которых сканируются и распознаются средствами OCR большие объемы бумажных документов. Он не зависит от конкретного языка, что обеспечивает быструю разработку систем поиска многоязычных текстов.
RetrievalWare Profiling Server - отвечает за фильтрацию и сортировку в реальном времени сообщений, получаемых по каналам новостей и электронной почте, а также других динамических информационных потоков. Архитектура сервера оптимизирована по производительности с производительностью остальных серверов RetrievalWare (Semantic, Pattern и Web) для обеспечения работы в реальном времени. Это средство облегчает разработку приложений, использующих ретроспективный поиск и классификацию по содержанию.
Базы знаний RetrievalWare содержат семантические ресурсы по конкретным предметным областям, которые могут быть интегрированны в семантические сети RetrievalWare в виде многоуровневых словарей. Сегодня в качестве дополнительной базы знаний доступен правовой тезаурус McMillan, на очереди - тезаурус Национальной медицинской библиотеки.
Фильтры текстовых процессоров поставляются в качестве дополнительных средств RetrievalWare.
Особенности RetrievalWare Web Server
RetrievalWare Web Server предоставляет множество средств разработки приложений Internet, поиска и выборки информации:
Технология шаблонов HTML RetrievalWare Web Server использует макропеременные для быстрой и гибкой настройки интерфейсов пользователя при поиске и просмотре результатов. Вместо создания скриптов CGI на языке PERL или Си, разработчики могут использовать обычный текстовый редактор для модификации шаблонов HTML со специальными маркерами макропеременных, определяющими характеристики интерфейса пользователя. Формы автоматически подстраиваются под различные конфигурации библиотек и полей.
Корпоративная система управления документами
Система Excalibur EFS предназначена для сбора всех типов электронных текстов и изображений, поступающих из многочисленных источников. Документы автоматически индексируются и архивируются с использованием графического интерфейса пользователя, использующего аналогию с физическим архивом, с его шкафами, ящиками и папками, входящими документами и мусорной корзиной. Такая интуитивно понятная организация позволяет быстро изучить и легко использовать Excalibur EFS, одновременно предоставляя мощные средства организации, хранения, поиска и просмотра документов. Устойчивая к ошибкам технология адаптивного распознавания образов APRP дает возможность архивации и поиска электронных документов вне зависимости от наличия каких-либо ошибок при вводе, наиболее типичными из которых являются ошибки оптического распознавания символов (OCR) при вводе сканированных документов. Excalibur EFS имееет ряд важных особенностей, которые выделяют его из ряда других продуктов управления образами документов.
Автоматическая индексация подного текста документа
Каждый раз, когда новый документ или страница вносится в архив EFS, просходит автоматическая индексация всего текста. Таким образом, становятся ненужными трудоемкие и дорогостоящие операции по выбору ключевых слов экспертами или другие сложные операции по каталогизации.
Нечеткий полнотекстовый поиск
Возможности нечеткого поиска Excalibur EFS, основаные на технологии адаптивного распознавания образов, позволяют свободно формулировать произвольные запросы по полному тексту, названиям документов и полям контрольной карточки. Нечеткий поиск повышает производительность работы, позволяя с высокой степенью вероятности найти документ, даже если он или запрос содержат ошибки. Нечеткий поиск Excalibur игнорирует ошибки оптического распознавания символов, что позволяет избежать дорогостоящего исправления текста сканированных документов.
Архитектура клиент-сервер
Excalibur EFS полностью использует преимущества архитектуры клиент/сервер и предоставляет масштабируемое решение для управления образами документов, которое может быть интегрировано в действующую на предприятии информационную инфраструктуру. EFS WebFile предоставляет пользователям корпоративных сетей доступ к Excalibur EFS с помощью RetrievalWare Web Server.
EFS WebFile
EFS WebFile предоставляет возможности Excalibur EFS пользователям Internet и сетей intranet при помощи стандартных программ просмотра Web. Авторизованные пользователи могут использовать любой браузер Web для поиска и просмотра документов, хранящихся в архивах Excalibur EFS. EFS WebFile поддерживает многие платформы при использовании стандартных браузеров Web EFS. WebFile независим от платформы и позволяет работать с электронными образами документов в пределах предприятия или по всему миру. При этом не требуется установка программного обеспечения для клиента EFS.
Простота настройки интерфейсов архивов EFS WebFile позволяет быстро изменять внешний вид и поведение интерфейса архивов EFS. Изменения вносятся также легко, как создаются страницы Web, без необходимости программировать или писать скрипты CGI.
Локализация интерфейса архивов для многоязычного доступа
EFS WebFile обеспечивает доступ к архивам EFS, а шаблоны WebFile позволяют создавать экраны регистрации, окна поиска и просмотра архивов на любом языке, поддерживаемом браузером Web.
Одновременный доступ к нескольким архивам в нескольких окнах браузера
Пользователи могут проводить поиск в различных архивах одновременно, используя дополнительные программы просмотра и подключаясь к различным серверам EFS.
Компоненты Excalibur EFS WebFile
Excalibur EFS WebFile имеет модульную архитектуру. HTML EFS WebFile предоставляет шаблоны на HTML вместе со файлами изображений в стандартном формате GIF для создания пиктограмм интерфейса, позволяя непрограммистам настраивать интерфейсы клиентов архивов EFS. Файлы шаблонов используют специальный набор макросов для обмена данными с серверами Excalibur EFS.
Сервер Excalibur EFS и RetrievalWare Web Server
EFS WebFile включает в себя Excalibur RetrievalWare Web Server и специализированный сервер приложений (Front-End Server) для Excalibur EFS. В ходе работы сервер Web получает информацию, переданную из браузера Web клиента и пересылает серверу приложений EFS. Запрос регистрируется и передается поисковому серверу Excalibur EFS для исполнения, а затем результаты возвращаются серверу Web. RetrievalWare Web Server определяет, какой из файлов шаблонов на HTML следует обработать, включает в него соответствующую информацию и пересылает измененный файл HTML программе просмотра Web клиента.
Дополнительные компоненты
Для работы с Excalibur EFS WebFile пользователю необходимо иметь следующие компоненты:
Заключение
Экспоненциальный рост Internet вызвал повышенный спрос на новые решения по поиску информации. Возможности традиционных систем уже исчерпаны и оказываются недостаточными для работы с массивами данных больших объемов, доступных сегодня в Internet. Ежедневный рост объема текстовых ресурсов привел к необходимости в поисковом решении, обеспечивающем точный и легкий доступ к информации. Стремительная эволюция World Wide Web с возрастанием объема и разнообразия мультимедийной информации показывает, что успешные решения по поиску информации в лабиринтах Internet, потребуют значительно большей сложности и необходимой функциональности. Решения компании Excalibur в технологии распознавания образов и семантических сетей предоставлюет возможность справляться с проблемами поиска информации в Internet и World Wide Web при помощи RetrievalWare. Кроме того, способность RetrievalWare адаптироваться к различным типам данных является важной для построения нового поколения решений, в частности поиска в мультимедийных массивах.
