
Александр Крейнес
ОСНОВНЫЕ ФУНКЦИИ КОМПЬЮТЕРНОЙ ТЕЛЕФОНИИ
Аппаратура или программа?
Семейство плат для компьютерной телефонии
Конкретный пример
Литература
Голосовые компьютерные технологии становятся сегодня все более популярными. Задача обучения компьютера навыкам общения с человеком при помощи обычной речи привлекает внимание как известных гигантов компьютерной индустрии, так и относительно небольших компаний, специализирующихся исключительно на этой области индустрии телекоммуникаций. Компьютеры уже научились понимать команды человека и озвучивать текстовые файлы. Впрочем, голосовые технологии для настольных систем выглядят чем-то вроде забавы - удобно, но при необходимости можно обойтись и без них. А вот для развивающейся необычайно быстрыми темпами компьютерной телефонии голосовые технологии - это насущная необходимость.
Основная идея компьютерной телефонии - сочетание мощи компьютерного интеллекта с простотой и доступностью телефонной связи. Благодаря этой технологии, можно связываться с удаленными компьютерами, и, ответив на несколько вопросов голосового меню, выполнить достаточно широкий набор действий: получить телефонное соединение с любым сотрудником компании-пользователя или оставить голосовое сообщение, осуществить доступ к базе данных и получить информацию либо в голосовом виде, либо по факсу. Помимо этого, компьютерная телефония позволяет производить интеллектуальную коммутацию входящего или исходящего звонка, переключать звонок с одного номера телефона на другой, как в пределах организации, так и "наружу" и производить большое количество других действий. Некоторые возможные приложения компьютерной телефонии описаны в работе [1].
ОСНОВНЫЕ ФУНКЦИИ КОМПЬЮТЕРНОЙ ТЕЛЕФОНИИ
Сложные приложения компьютерной телефонии формируются из ограниченного числа относительно простых вызовов функций, реализующих достаточно сложные реальные алгоритмы, базирующиеся на ряде следующих аппаратных и программных средств.
Запись и воспроизведение голоса. Чтобы общаться с человеком по телефону, голосовая система должна уметь записывать и воспроизводить человеческую речь. Простейшим примером такой системы является обыкновенный автоответчик, где голос записывается на магнитную ленту, а потом воспроизводится. В современных системах компьютерной телефонии голос записывается в цифровом виде на диск, обычно по методу PCM (Pulse Code Modulation). Аналоговый электрический сигнал, передающий голос, подвергается цифровому преобразованию через определенные промежутки времени. Согласно известной теореме Найквиста, частота оцифровки или частота выборки должна быть вдвое выше максимальной частоты, присутствующей в спектре оцифровываемого сигнала. Общепринятым стандартом при передаче голоса является сохранение в его спектре частот до 4 кГц - при этом голос, с одной стороны, сохраняет узнаваемость, а с другой - не требует для своей передачи высококачественных линий. Отсюда получается, что частота выборки должна составлять 8 кГц, а общепринятое разрешение аналого-цифрового преобразования составляет 256 уровней. Для кодировки такого преобразования необходимо 8 бит информации. Таким образом, для кодирования голосового сигнала требуется скорость 64 Кбит/с.
Распознавание набранных абонентом цифр. Системы компьютерной телефонии должны воспринимать команды абонента, которые в простейшем случае вводятся путем набора цифры на телефонном аппарате. Отсюда следует, что аппаратура для компьютерной телефонии должна распознавать, какую цифру набрал абонент. Здесь следует отметить, что сегодня существуют две основные принципиально различные системы набора номера - DTMF (Dual-Tone Multifrequency) и импульсный набор. Система DTMF принята в США, Израиле и ряде других стран, импульсный набор - в большинстве европейских стран, России и Японии. В системе DTMF (или тоновом наборе) каждая цифра кодируется звуковым сигналом, представляющим собой сочетание двух частот, отвечающих координатам соответствующей цифры на наборной клавиатуре телефона. Обычно на такой клавиатуре имеется четыре горизонтальных и три вертикальных ряда клавиш, соответственно, в системе DTMF имеется двенадцать сочетаний частот, передаваемых по телефонным линиям в виде обычных звуковых сигналов. Существуют стандартные схемные решения для распознавания этих частот, поэтому обработка тонового набора никаких затруднений не представляет.
С импульсным набором дело обстоит сложнее - каждая цифра кодируется серией разрывов в цепи между телефонным аппаратом и коммутирующим оборудованием на станции. Число разрывов в линии соответствует набранной цифре (ноль кодируется десятью разрывами); разрывы, относящиеся к одной и той же цифре, разделены короткими интервалами, более длинные интервалы разделяют разрывы, относящиеся к разным цифрам. Основная проблема состоит в том, что разрывы цепи не передаются дальше по линии, и на другом конце соединения прослушиваются только характерные щелчки. Эти щелчки приходится распознавать, что при наличии помех в линии сделать затруднительно.
Преобразование текст-речь. Любая компьютерно-телефонная система должна обладать способностью озвучить для абонента то или иное сообщение. Такое преобразование может выполняться в одном из двух режимов: путем сборки из заранее записанных речевых фрагментов и прямым формированием речевого сообщения по текстовому файлу. Сборка из заранее записанных речевых фрагментов позволяет решать только самые простые задачи, например синтез числительных. Достаточно записать речевые фрагменты, содержащие простейшие элементы, из которых состоят наименования чисел: цифры, десятки, сотни, тысячи и т.д. и из них можно будет набрать любое число. А поскольку работа многих информационных систем связана именно с передачей чисел, то такого синтеза будет вполне достаточно для работы очень многих приложений. Несмотря на внешнюю простоту такой системы, с ней связан целый ряд существенных проблем. Для того, чтобы синтезируемое сообщение звучало плавно, без разрывов, подставляемые слова должны быть интонационно встроены в общую фразу, достичь чего не так просто. В русском языке к этой проблеме добавляется еще проблема изменяемости слов - приходится для каждого контекста, где встречается числительное в определенном падеже, делать отдельную запись. Кроме того, в зависимости от числительного меняются и окружающие его слова, например: "триста тридцать один рубль", "триста тридцать три рубля", что еще больше осложняет ситуацию. Тем не менее, существуют стандартные методы подготовки речевых фрагментов для этого метода синтеза сообщений. Данный способ формирования речевых сообщений годится для подавляющего большинства голосовых систем.
Значительно более гибким, хотя и более сложным алгоритмически является прямой синтез речевых сообщений по тексту. Сегодня существуют алгоритмы синтеза речи по текстам на английском, немецком, испанском, японском и ряде других языков. Недавно появились сообщения о том, что разработана и система для русского языка, однако прямого подтверждения этому найти пока не удалось. Лидером в области разработки коммерческих систем текст-речь является сегодня компания Berkeley Speech Technologies (BeST). Основная проблема, до настоящего времени пока не имеющая полного решения, состоит в том, чтобы синтезированная по тексту речь звучала "по-человечески" - пока компьютерная речь практически не имеет интонаций и ударений, а кроме того, имеются трудности с озвучиванием имен собственных и адресов.
Распознавание голоса. Абонент может подавать команды машине не только набирая определенные комбинации цифр на своем телефонном аппарате, но и более обычным способом - проговаривая команды, что предполагает применение технологий распознавания речи. На сегодняшний день это, пожалуй, одна из самых сложных проблем в области интерфейса человека и компьютера. Несмотря на то, что недавно в этой области были достигнуты большие успехи, до полного решения еще далеко. Все алгоритмы распознавания работают на базе словарей, содержащих определенное количество слов; количество и характер слов для разных языков и режимов распознавания речи отличаются друг от друга. Алгоритмы распознавания речи занимаются выделением соответствующих слов в голосовом сигнале и преобразованием их в текст. Существует несколько режимов распознавания речи: с настройкой на голос конкретного пользователя и без настройки. В первом случае объем словаря может достигать нескольких десятков тысяч слов, которые распознаются при слитном произнесении. Данный режим распознавания применяется, когда у системы компьютерной телефонии имеется только один конкретный пользователь, который может по телефону давать команды системе и даже диктовать письма. Для систем общего пользования необходим режим распознавания без настройки на голос конкретного пользователя. Такие системы также работают на основе словаря, который, однако, может содержать гораздо меньшее число слов. Словари для распознавания речи без настройки на конкретного пользователя создаются на основе образцов речи, полученных от многих сотен или даже тысяч носителей языка.
Словари для работы без настройки на голос конкретного пользователя могут обеспечивать распознавание цифр от нуля до девяти и простейших команд типа "да" и "нет" при их раздельном произнесении, либо обеспечивать распознавание цифр и несколько более узкого набора команд при их слитном произнесении, либо обеспечивать распознавание цифр и наименований всех букв алфавита. Словари для распознавания речи без настройки на голос пользователя созданы для нескольких десятков языков и диалектов - для русского языка пока существует лишь простейший словарь, обеспечивающий распознавание цифр и простейших команд, произносимых раздельно.
Осуществление исходящего звонка. Системы компьютерной телефонии должны обеспечивать набор номера и мониторинг линии, который и представляет наибольший интерес. Речь идет о распознавании сигналов, свидетельствующих о состоянии соединения: редкие гудки - осуществление соединения; снятие трубки на противоположном конце; частые гудки - занятость линии; отсутствие гудков - соединение не установилось; гудки, обозначающие ошибку при наборе номера (как правило, это три последовательных гудка с возрастающей высотой тона). Кроме того, многие системы компьютерной телефонии в состоянии отличить, отвечает ли им человек, автоответчик или факсимильный аппарат. Для распознавания сигналов в линии и ответа абонента часто используется так называемая каденция - порядок чередования периодов молчания и наличия звука в линии и их продолжительность. Каденция распознается существенно проще, чем речь, хотя и здесь имеются свои проблемы, связанные с тем, что в разных странах состояние линии обозначается разными сигналами, поэтому системы компьютерной телефонии должны допускать настройку на сигналы, которые принято использовать в данной стране. Распознавание "сущности" отвечающего абонента осуществляется довольно просто. Факсимильный аппарат отвечает длинным сигналом готовности, который легко отличить по каденции от редких гудков и от человеческой речи. Человек, снимая трубку, коротко отвечает "Алло!" или в крайнем случае представляется. Автоответчик же начинает долго рассказывать, куда вы позвонили и что надо сделать, чтобы оставить сообщение.
Генерация факсимильных сообщений. Чтобы обеспечить полную поддержку всех необходимых человеку функций, система компьютерной телефонии должна уметь осуществлять генерацию факсимильных сообщений по текстовым файлам, результатам запросов баз данных и так далее. Данная функция мало чем отличается от работы обычного факс-модема.
 (1x1)
(1x1)
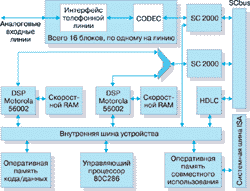
Рисунок 1.
Функциональная схема многоканальной голосовой платы Dialogic D/160SC-LS.
Аппаратура или программа?
Реализовать перечисленные функции или хотя бы часть из них можно различными способами. В простейшем случае, для телефонного соединения можно использовать обыкновенный факс-модем, а все функции, связанные с обработкой голоса, осуществлять при помощи платы Sound Blaster. При этом вся интеллектуальная нагрузка, связанная с осуществлением телефонного соединения и голосовой поддержкой, ложится на компьютер. Это, во-первых, означает, что для этой цели можно использовать лишь достаточно мощные машины, а во-вторых, при таком подходе компьютер превращается в интеллектуальный телефонный аппарат, что означает не слишком рациональное использование его вычислительных ресурсов. Впрочем, для решения простых задач такой подход может вполне сгодиться. Его преимущество - идейная простота и относительная дешевизна используемого оборудования.
Более основательный подход предполагает использование простых и относительно дешевых голосовых плат, представляющих собой интегрированные устройства, поддерживающие ряд функций, необходимых для установления телефонного соединения. В частности, такие платы набирают номер (как по системе DTMF, так и импульсом), озвучивают приветствие, задают абоненту вопросы голосового меню, распознают ответы абонента в виде сигналов DTMF, а также оцифровывают речь абонента и готовят соответствующие данные к записи на диск. Такое решение имеет одно несомненное преимущество - все функции поддержки телефонного соединения выполняются автономным процессором DSP (digital signal processor), находящимся на плате.
DSP представляет собой мощный процессор, разработанный специально для работы с аудиосигналами. Сегодня такие процессоры широко доступны на рынке за весьма умеренную плату. Широко распространено также загружаемое программное обеспечение для этих процессоров, которое, собственно, и обеспечивает выполнение всех необходимых функций. Главный недостаток, помимо малой пропускной способности - данные платы рассчитаны на работу в одноканальном режиме, состоит в том, что эти голосовые платы представляют собой закрытую систему, как с точки зрения аппаратного, так и программного обеспечения. Установив однажды такую плату и программное обеспечение к ней, ее нельзя расширить и очень трудно модифицировать. Кроме того, данные платы не выполняют интеллектуальных функций, таких как распознавание речи или преобразование текст-речь. Производятся такие одноканальные платы большим числом компаний: American Megatrends (Норкросс, шт. Джорджия), Boca Research (БокаРейтон, шт. Флорида), Objix Multimedia (Уолтем, шт. Массачусетс).
Наиболее гибкими и разветвленными являются модульные системы плат расширения для компьютерной телефонии. Основным производителем таких плат является компания Dialogic (Парсипанни, шт. Нью-Джерси), которая выпускает широкий набор разнообразных плат расширения, различающихся как по функциям, так и по масштабу. Все они основаны на применении технологии DSP, в который загружено фирменное программное обеспечение, обеспечивающее выполнение необходимых функций. Прежде всего, следует отметить программное обеспечение поддержки телефонного соединения SpringWare, в котором реализованы следующие функции: оцифровка и воспроизведение речи, распознавание сигналов состояния линии, распознавание отсутствия звука в линии, распознавание сигналов тонового набора, набор номера в соответствии с заданным стандартом. Помимо этого, SpringWare может отличать речь человека от сигналов в линии, распознавать ответ автоответчика, изменять скорость воспроизведения сообщения без изменения звучания голоса, регулировать громкость и автоматически подстраивать коэффициент усиления при записи речи со входящего звонка.
Семейство плат для компьютерной телефонии
Опишем несколько более подробно, какие платы входят в семейство, выпускаемое компанией Dialogic - именно это семейство представляет собой индустриальный стандарт в области модульных систем для компьютерной телефонии. Среди других производителей аппаратного обеспечения следует отметить компанию Natural MicroSystems (Нэтик, шт. Массачусетс), а также Brooktrout (Нидэм, шт. Массачусетс) и Pika (Канада, Онтарио).
Главным компонентом систем компьютерной телефонии являются многоканальные голосовые платы. Именно они выполняют основной набор функций, связанных с поддержкой диалога с пользователем и именно на них в первую очередь рассчитано программное обеспечение SpringWare. Число каналов в одной плате меняется от двух до тридцати; имеются платы, рассчитанные на работу с отдельными аналоговыми линиями и способные "принять" на себя цифровой канал T-1 или E-1 целиком. Некоторые платы могут быть напрямую подключены к линии, другим требуются специальные интерфейсные платы, также выпускаемые Dialogic.
Следующий член семейства Dialogic-платы коммутации и распределения ресурсов. Данные платы обеспечивают внутреннюю коммутацию ресурсов в пределах систем и коммутацию внешних линий, например, подключение любого из операторов к любой из внешних линий, организацию конференций и т.д.
Платы распознавания речи и преобразования текст-речь. Данные платы также работают на основе программного обеспечения, загружаемого в DSP-процессор.
Помимо этих плат, в семейство Dialogic входят еще платы поддержки факсимильного обмена, выполняемые в качестве плат-приставок для голосовых плат.
Модульность семейства плат расширения предполагает, что в одном компьютере могут быть установлены несколько плат, выполняющих разные функции. Кроме того, представляется разумным организовать распределение, скажем, ресурсов распознавания голоса между большим числом голосовых каналов. Отсюда следует, что платы должны обмениваться информацией между собой. Использование для этой цели системной шины вызовет ее перегрузку и приведет к непроизводительным затратам ресурсов. Поэтому с самого начала системы компьютерной телефонии были ориентированы на использование собственной шины для обмена информацией между платами.
Вначале для этой цели применялась аналоговая шина AEB, Analog Expansion Bus, представляющая собой просто четыре параллельные аналоговые линии, объединенные в один кабель. Данная шина обладает невысокой пропускной способностью и используется только в системах низшего класса. Следующим шагом на этом пути было использование цифровых шин - сначала это PEB (PCM Expansion Bus), а потом и MVIP (Multi-Vendor Integration Protocol), компании Natural MicroSystems. Данные шины можно представлять как внутримашинные линии T-1 (E-1). MVIP - это сочетание восьми цифровых линий, обеспечивающих 256 независимых голосовых каналов пропускной способностью 64 кбит/с каждый. Индивидуальная шина PEB представляет собой один цифровой канал, однако, используя специальную коммутационную плату, можно обеспечить использование до четырех индивидуальных PEB в одной системе с возможностью обмена информацией как в пределах одной шины, так и между шинами. Суммарная пропускная способность системы на базе PEB может составлять до 128 голосовых каналов на 64 кбит/с.
Следующим шагом в этом направлении стала предложенная Dialogic шина SCbus - составная часть аппаратно-программного стандарта компьютерной телефонии SCSA (Signal Computing System Architecture). Переход от PEB к SCbus носит не только чисто количественный - суммарная пропускная способность новой шины составляет 2048 голосовых каналов, но и качественный характер. Во-первых, отдельные каналы шины могут быть объединены в магистрали для передачи высококачественного звука или видеоинформации. Служебная информация в SCbus передается по отдельной линии, в то время как в PEB применялось заимствование битов у полезного сигнала. Кроме того, SCbus может управляться любым из устройств, подключенных к шине, что повышает отказоустойчивость системы в целом. Наконец, очень важно, что в стандарте SCbus предусмотрена поддержка передачи информации между отдельными машинами, благодаря чему оказывается возможной организация многомашинных систем.
Конкретный пример
В качестве примера рассмотрим, функциональную схему многоканальной голосовой платы D/160SC-LS, входящей в состав семейства Dialogic/HD, объединяющего аппаратуру с высокой плотностью информации - к ней можно подключать до 16 аналоговых линий. Структура платы основана на стандарте SCSA. Плата поддерживает все функции, характерные для голосовых плат.
Входные линии подключаются к телефонному интерфейсу, обеспечивающему защиту аппаратуры от перегрузок, вызванных переходными процессами. Здесь же происходит распознавание входящего звонка. Пройдя интерфейсные цепи, входной сигнал попадает на вход устройства кодировки/декодировки (CODEC), где происходит его оцифровка. Оцифрованная информация попадает на микросхему SC2000, где определяется, будет ли данная информация передана по шине SCSA для дальнейшей обработки на другие устройства или ее предполагается обрабатывать в пределах самой платы. Именно здесь и обеспечивается использование, например, внешних плат распознавания речи. Обработка оцифрованного звукового сигнала происходит в DSP- процессорах Motorola 56002 на основе программного обеспечения SpringWare. Здесь выполняются такие функции, как сжатие/восстановление звукового сигнала для передачи его по системной шине компьютера, подстройка уровня громкости и коэффициента усиления, распознавание сигналов тонового набора, распознавание молчания в линии, а также мониторинг соединения. Контроллер HDLC (High-level Data Link Controller) осуществляет доступ к управляющей линии шины SCbus и обеспечивает передачу управляющих сигналов и распознавание коллизий. Расположенный на плате процессор 80C286 управляет ее работой и обеспечивает правильную интерпретацию и выполнение команд от центрального процессора, тем самым поддерживая взаимодействие голосовой платы с прикладной программой. Процессор работает с системной шиной через оперативную память совместного использования, играющую также роль буфера при передаче файлов. Работа платы управляется программным обеспечением, хранящимся в оперативной памяти кода/данных и памяти DSP. Данное программное обеспечение загружается при инициализации системы с жесткого диска.
Литература
[1]. А.Крейнес. Компьютерная телефония в приложениях. Открытые системы, N 2, 1996 г., с. 43-47.
