

Процессорная архитектура SPARC (Scalable Processor Architecture) компании Sun Microsystems является одной из распространенных среди RISC-систем. Процессоры с архитектурой SPARC лицензированы и изготавливаются несколькими производителями: Texas Instruments, Fujitsu, LSI Logic, Bipolar International Technology, Philips, Cypress Semiconductor и Ross Technologies. Эти компании осуществляют поставки процессоров SPARC не только самой Sun Microsystems, но и другим известным производителям вычислительных систем, например Solbourne, Toshiba, Matsushita и Tatung.
Экскурс в историю
Первоначально архитектура SPARC была разработана с целью упрощения реализации 32-битового процессора. Впоследствии, по мере улучшения технологии изготовления интегральных схем, она постепенно развивалась, и сегодня существует 64-битовая версия этой архитектуры (SPARC-V9), которая положена в основу семейства новых микропроцессоров, получивших название UltraSPARC.
Первый процессор SPARC был изготовлен компанией Fujitsu на базе вентильной матрицы, работающей на частоте 16.67 МГц. На основе этого процессора была разработана первая рабочая станция Sun-4 с производительностью 10 MIPS, объявленная осенью 1987 года. До этого времени компания Sun использовала в своих изделиях микропроцессоры Motorola 680X0. В марте 1988 года Fujitsu увеличила тактовую частоту до 25 МГц, создав процессор с производительностью 15 MIPS.
Позднее компания Sun умело использовала конкуренцию среди компаний-поставщиков интегральных схем, выбирая наиболее удачные разработки для реализации своих изделий SPARCstation 1, 1+, IPC, ELC, IPX, 2 и серверов серий 4xx и 6xx. Тактовая частота процессоров SPARC была повышена до 40 МГц, а производительность С до 28 MIPS. Дальнейшее увеличение производительности процессоров с архитектурой SPARC было достигнуто за счет реализации в кристаллах принципов суперскалярной обработки компаниями Texas Instruments и Cypress. Процессор SuperSPARC компании Texas Instruments стал основой серии рабочих станций и серверов SPARCstation/SPARCserver 10 и 20. В зависимости от смеси команд он обеспечивает выдачу до трех команд за один машинный такт. Процессор SuperSPARC имеет сбалансированную производительность на операциях с фиксированной и плавающей точкой. Он имеет внутренний кэш емкостью 36 Кбайт (20 С кэш команд и 16 С кэш данных), раздельные конвейеры целочисленной и вещественной арифметики и при тактовой частоте 75 МГц обеспечивает производительность около 205 MIPS.
Компания Texas Instruments разработала также 50 МГц процессор MicroSPARC с встроенным кэшем емкостью 6 Кбайт, который ранее широко использовался в дешевых моделях рабочих станций SPARCclassic и LX. Затем Sun совместно с Fujitsu создали новую версию кристалла MicroSPARC II с встроенным кэшем емкостью 24 Кбайт. На его основе построены рабочие станции и серверы SPARCstation/SPARCserver 4 и 5, работающие на частоте 70, 85 и 110 МГц.
Хотя архитектура SPARC в течение длительного времени оставалась одной из наиболее заметной на рынке процессоров RISC, особенно в секторе рабочих станций, повышение тактовой частоты процессоров в 1992-1994 годах происходило более медленными темпами по сравнению с повышением тактовой частоты конкурирующих архитектур. Чтобы ликвидировать это отставание, а также в ответ на появление 64-битовых процессоров компания Sun разработала и начала проводить в жизнь пятилетнюю программу модернизации. В соответствии с этой программой Sun планировала довести тактовую частоту процессоров MicroSPARC до 100 МГц в 1994 году (процессор MicroSPARC II с тактовой частотой 110 МГц используется в рабочих станциях и серверах SPARCstation 4 и 5). В конце 1994 и в течение 1995 года на рынке появились микропроцессоры hyperSPARC и однопроцессорные и многопроцессорные рабочие станции SPARCstation 20 с тактовой частотой процессора 100, 125 и 150 МГц. К середине 1995 года тактовая частота процессоров SuperSPARC была доведена до 85 МГц (60, 75 и 85 МГц версии этого процессора применяются сегодня в рабочих станциях и серверах SPARCstation 20, SPARCserver 1000, SPARCcenter 2000 и 64-процессорном сервере компании Cray Research). Наконец, в конце 1995 года появились 64-битовые процессоры UltraSPARC-I с тактовой частотой 143, 167 и 200 МГц, и были объявлены процессоры UltraSPARC-II с тактовой частотой от 250 до 300 МГц, серийное производство которых должно начаться в середине 1996 года. В дальнейшем планируется выпуск процессоров UltraSPARC-III с частотой до 500 МГц.
Таким образом, компания Sun Microsystems имеет сегодня широкий спектр процессоров, способных, теоретически, удовлетворить нужды любого пользователя, как с точки зрения производительности выпускаемых ею рабочих станций и серверов, так и в отношении их стоимости, и судя по всему не собирается уступать своих позиций на быстро меняющемся компьютерном рынке.
Архитектура UltraSPARC
Основные критерии разработки
Как известно, производительность любого процессора при выполнении заданной программы зависит от трех параметров: такта (или частоты) синхронизации, среднего количества команд, выполняемых за один такт, и общего количества выполняемых в программе команд. Невозможно изменить ни один из указанных параметров независимо от других, поскольку соответствующие базовые технологии взаимосвязаны: частота синхронизации определяется достигнутым уровнем технологии интегральных схем и функциональной организацией процессора, среднее количество тактов на команду зависит от функциональной организации и архитектуры системы команд, а количество выполняемых в программе команд определяется архитектурой системы команд и технологией компиляторов.
Из этого видно, что создание нового высокопроизводительного процессора требует решения сложных вопросов во всех трех направлениях разработки. При этом эффективная с точки зрения стоимости конструкция не может полагаться только на увеличение тактовой частоты. Экономические соображения заставляют разработчиков принимать решения, основой которых является массовая технология. Системы UltraSPARC-1 обеспечивают высокую производительность при достаточно умеренной тактовой частоте (до 200 МГц) путем оптимизации среднего количества команд, выполняемых за один такт. Однако при таком подходе естественно возникают вопросы эффективного управления конвейером команд и иерархией памяти системы. Для увеличения производительности необходимо по возможности уменьшить среднее время доступа к памяти и увеличить среднее количество команд, выдаваемых для выполнения в каждом такте, не превышая при этом разумного уровня сложности процессора.
При разработке суперскалярного процессора практически сразу необходимо "расшить" целый ряд узких мест, ограничивающих выдачу для выполнения нескольких команд в каждом такте. Таким узким местом является наличие в программном коде зависимостей по управлению и данным, аппаратные ограничения на количество портов в регистровых файлах процессора и устройствах, реализующих иерархию памяти, а также количество целочисленных конвейеров и конвейеров выполнения операций с плавающей точкой.
При создании своего нового процессора UltraSPARC-1 конструкторы из Sun решили добиться увеличения производительности процессора в тех направлениях, где это не противоречило экономическим соображениям. Чтобы сократить число потенциальных проблем, было принято несколько принципиальных решений, которые определили основные характеристики UltraSPARC-1:
- Реализация на кристалле раздельной кэш-памяти команд и данных;
- Организация широкой выборки команд (128 бит);
- Создание эффективных средств динамического прогнозирования направления переходов;
- Реализация девятиступенчатого конвейера, обеспечивающего выдачу для выполнения до четырех команд в каждом такте;
- Оптимизация конвейерных операций обращения к памяти;
- Реализация команд обмена данными между памятью и регистрами плавающей точки, позволяющая не приостанавливать диспетчеризацию команд обработки;
- Реализация на кристалле устройства управления памятью (MMU);
- Расширение набора команд для поддержки графики и обработки изображений;
- Реализация новой архитектуры шины UPA.
Структура процессора UltraSPARC-I
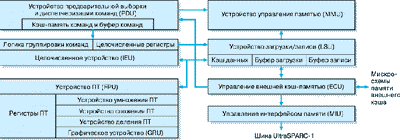
Процессор UltraSPARC-1 представляет собой производительный, высокоинтегрированный суперскалярный процессор, реализующий 64-битовую архитектуру SPARC-V9. В его состав входят: устройство предварительной выборки и диспетчеризации команд, целочисленное исполнительное устройство, устройство работы с вещественной арифметикой и модуль графики, устройства управления памятью, загрузки/записи и управления внешней кэш-памятью, модули управления интерфейсом памяти и кэш-памяти команд и данных (рис. 1).
 (1x1)
(1x1)
Рис. 1. Блок-схема процессора UltraSPARC-1
Устройство предварительной выборки и диспетчеризации команд
Устройство предварительной выборки и диспетчеризации команд процессора UltraSPARC-1 (PDU) обеспечивает выборку команд в буфер команд, окончательную их дешифрацию, группировку и распределение для параллельного выполнения в конвейерных функциональных устройствах процессора. Буфер команд емкостью 12 инструкций позволяет согласовать скорость работы памяти со скоростью обработки исполнительных устройств процессора. Команды могут быть предварительно выбраны из любого уровня иерархии памяти, например, из кэш-памяти команд (I-кэша), внешней кэш-памяти (Е-кэша) или из основной памяти системы.
В процессоре реализована схема динамического прогнозирования направления ветвлений программы, основанная на двухбитовой истории переходов и обеспечивающая ускоренную обработку команд условного перехода. Для реализации этой схемы с каждыми двумя командами в I-кэше связано специальное поле, хранящее двухбитовое значение прогноза. Таким образом, UltraSPARC-1 позволяет хранить информацию о направлении 2048 переходов, что на сегодняшний день превышает потребности многих современных прикладных программ. Поскольку направление перехода может меняться каждый раз, когда обрабатывается соответствующая команда, состояние двух бит прогноза должно каждый раз модифицироваться для отражения реального исхода перехода. Эта схема особенно эффективна при обработке циклов.
Кроме того, в процессоре UltraSPARC-1 с каждыми четырьмя командами в I-кэше связано специальное поле, указывающее на следующую строку кэш-памяти, которая должна выбираться вслед за данной. Использование этого поля позволяет осуществлять выборку командных строк в соответствии с выполняемыми переходами, что обеспечивает для программ с большим числом ветвлений практически ту же самую пропускную способность команд, что и на линейном участке программы. Способность быстро выбрать команды по прогнозируемому целевому адресу команды перехода является очень важной для оптимизации производительности суперскалярного процессора и позволяет UltraSPARC-1 эффективно выполнять "по предположению" (speculative) достаточно хитроумные последовательности условных переходов.
Используемые в UltraSPARC-1 механизмы динамического прогнозирования направления и свертки переходов сравнительно просты в реализации и обеспечивают высокую производительность. По результатам контрольных испытаний UltraSPARC-1 88% переходов по условиям целочисленных операций и 94% переходов по условиям операций с плавающей точкой предсказываются успешно.
Кэш-память команд
Кэш-память команд (I-кэш) представляет собой двухканальную множественно-ассоциативную кэш-память емкостью 16 Кбайт. Она организована в виде 512 строк, содержащих по 32 байта данных. С каждой строкой связан соответствующий адресный тег. Команды, поступающие для записи в I-кэш проходят предварительное декодирование и записываются в кэш-память вместе с соответствующими признаками, облегчающими их последующую обработку. Окончательное декодирование команд происходит перед их записью в буфер команд.
Организация конвейера
В процессоре UltraSPARC-1 реализован девятиступенчатый конвейер. Это означает, что задержка (время от начала до конца выполнения) большинства команд составляет девять тактов. Однако в любой данный момент времени в процессе обработки могут одновременно находиться до девяти команд, обеспечивая во многих случаях завершение выполнения команд в каждом такте. В действительности эта скорость может быть ниже в связи с природой самих команд, промахами кэш-памяти или другими конфликтами по ресурсам. Первая ступень конвейера С выборка из кэш-памяти команд. На второй ступени команды декодируются и помещаются в буфер команд. Третья ступень осуществляет группировку и распределение команд по функциональным исполнительным устройствам. В каждом такте на выполнение в исполнительные устройства процессора могут выдаваться по 4 команды: не более двух целочисленных команд или команд плавающей точки/графических команд, одной команды загрузки/записи и одной команды перехода. На следующей ступени происходит выполнение целочисленных команд или вычисляется виртуальный адрес для обращения к памяти, а также осуществляются окончательное декодирование команд плавающей точки (ПТ) и обращение к регистрам ПТ. На пятой ступени происходит обращение к кэш-памяти данных. Определяются попадания и промахи кэш-памяти и разрешаются переходы. При обнаружении промаха кэш-памяти, соответствующая команда загрузки поступает в буфер загрузки. С этого момента целочисленный конвейер ожидает завершения работы конвейеров плавающей точки/графики, которые начинают выполнение соответствующих команд. Затем производится анализ возникновения исключительных ситуаций. На последней ступени все результаты записываются в регистровые файлы и команды изымаются из обработки.
Целочисленное исполнительное устройство Главной задачей при разработке целочисленного исполнительного устройства (IEU) является обеспечение максимальной производительности при поддержке программной совместимости с существующим системным и прикладным программным обеспечением. Целочисленное исполнительное устройство UltraSPARC-1 объединяет в себе несколько важных особенностей:
- 2 АЛУ для выполнения арифметических и логических операций, а также операций сдвига;
- Многократные целочисленные устройства умножения и деления;
- регистровый файл с восемью окнами и четырьмя наборами глобальных регистров;
- реализация цепей ускоренной пересылки результатов;
- еализация устройства завершения команд, которое обеспечивает минимальное количество цепей обхода (ускоренной пересылки данных) при построении девятиступенчатого конвейера.
Устройство загрузки/записи (LSU)
LSU отвечает за формирование виртуального адреса для всех команд загрузки и записи (включая атомарные операции), за доступ к кэш-памяти данных, а также за буферизацию команд загрузки в случае промаха D-кэша (в буфере загрузки) и буферизацию команд записи (в буфере записи). В каждом такте может выдаваться для выполнения одна команда загрузки и одна команда записи.
Устройство плавающей точки (FPU)
Конвейерное устройство плавающей точки построено в соответствии со спецификациями архитектуры SPARC-V9 и стандарта IEEE 754. Оно состоит из пяти отдельных функциональных устройств и обеспечивает выполнение операций с плавающей точкой и графических операций. Реализация раздельных исполнительных устройств позволяет UltraSPARC-1 выдавать и выполнять две вещественных операции в каждом такте. Операнды-источники и результаты операций хранятся в регистровом файле емкостью 32 регистра. Большинство команд полностью конвейеризованы С имеют пропускную способность 1 такт, задержку в 3 такта и не зависят от точности операндов, имея одну и ту же задержку для одинарной и двойной точности. Команды деления и вычисления квадратного корня не конвейеризованы и без остановки процессора выполняются за 12/22 такта (одинарная/двойная точность). Команды, следующие за командами деления/вычисления квадратного корня, могут выдаваться, выполняться и изыматься из обработки для фиксации результата в регистровом файле до момента завершения команд деления/вычисления квадратного корня. Процессор поддерживает модель точных прерываний путем синхронизации конвейера плавающей точки с целочисленным конвейером, а также с помощью средств прогнозирования исключительных ситуаций для операций с большим временем выполнения. FPU может работать с нормализованными и ненормализованными числами с одинарной (32 бит) и двойной точностью (64 бит), а также поддерживает операции над числами с учетверенной точностью (128 бит).
Устройство FPU тесно взаимодействует с целочисленным конвейером и способно без каких-либо дополнительных задержек выполнять чтение вещественного операнда из памяти и следующую за ней операцию. IEU и FPU имеют выделенный интерфейс управления, который обеспечивает диспетчеризацию операций, выбранных PDU в FPU. Устройство предварительной выборки и диспетчеризации команд выполняет распределение находящихся в очереди команд в FPU. IEU управляет частью операций, связанных с D-кэшем, а FPU выполняет собственно операции обработки данных. При выполнении команд вещественной арифметики целочисленное устройство и FPU совместно определяют наличие зависимостей по данным. Существующий между ними интерфейс включает также взаимную синхронизацию при появлении исключительных ситуаций FPU. Для снижения взаимного влияния и увеличения общей производительности в FPU обеспечивается дополнительная буферизация команд, реализованная с помощью очереди размером в три команды.
Графическое устройство (GRU)
В процессоре UltraSPARC-1 реализован исчерпывающий набор графических команд, которые обеспечивают аппаратную поддержку высокоскоростной обработки плоских и трехмерных изображений, а также обработку видеоданных. GRU выполняет операции сложения, сравнения и логические операции над 16-битовыми и 32-битовыми целыми числами, а также операции умножения над 8-битовыми и 16-битовыми целыми. В GRU поддерживаются однотактные операции определения расстояния между пикселями, операции выравнивания данных, операции упаковки и слияния.
Устройство управления памятью (MMU)
Высокая суперскалярная производительность процессора поддерживается соответствующей скоростью поступления для обработки команд и данных. Обычно эта задача ложится на иерархию памяти системы. Устройство управления памятью процессора UltraSPARC-1 выполняет все операции обращения к памяти, реализуя необходимые средства поддержки виртуальной памяти. Виртуальное адресное пространство задачи определяется 64-битовым виртуальным адресом, однако процессор UltraSPARC-1 поддерживает только 44-битовое виртуальное адресное пространство. Соответствующее преобразование является функцией операционной системы.
В свою очередь, MMU обеспечивает отображение 44-битового виртуального адреса в 41-битовый физический адрес памяти. Это преобразование выполняется с помощью полностью ассоциативных 64-строчных буферов: iTLB С для команд и dTLB С для данных. Каждый из этих буферов по существу представляет собой полностью ассоциативную кэш-память дескрипторов страниц. В каждой строке TLB хранится информация о виртуальном адресе страницы, соответствующем физическом адресе страницы, а также о допустимом режиме доступа к странице и ее использовании. Процесс преобразования виртуального адреса в физический заканчивается сразу, если при поиске в кэш-памяти TLB происходит попадание (соответствующая строка находится в TLB). В противном случае замещение строки TLB осуществляется специальным аппаратно-программным механизмом. MMU поддерживает четыре размера страниц: 8Кбайт, 64Кбайт, 512Кбайт и 4Мбайт.
Как уже было отмечено, MMU реализует также механизмы защиты и контроля доступа к памяти. В результате выполняющийся процесс не может обращаться к адресному пространству других процессов, и, кроме того, гарантируется заданный режим доступа процесса к определенным областям памяти С на базе информации о допустимом режиме доступа к страницам памяти. Например, процесс не может модифицировать страницы памяти, доступ к которым разрешен только по чтению или которые зарезервированы для размещения системных программ.
Наконец, MMU выполняет функции определения порядка (приоритета) обращений к памяти со стороны ввода/вывода, D-кэша, I-кэша и схем преобразования виртуального адреса в физический.
Управление интерфейсом памяти (MIU)
В процессоре UltraSPARC-1 применяется специальная подсистема ввода/вывода (MIU), которая обеспечивает управление всеми операциями ввода и вывода, осуществляемыми между локальными ресурсами: процессором, основной памятью, схемами управления и всеми внешними ресурсами системы. В частности, все транзакции, связанные с обработкой промахов кэш-памяти, прерываниями, наблюдением за когерентным состоянием кэш-памяти, операциями обратной записи и т.д., обрабатываются MIU. MIU взаимодействует с системой на частоте меньшей, чем частота UltraSPARC-1 в соотношении 1/2 или 1/3.
Кэш-память данных
В процессоре UltraSPARC-1 используется кэш-память данных D-кэш с прямым отображением емкостью 16 Кбайт, реализующая алгоритм сквозной записи. D-кэш организован в виде 512 строк, в каждой строке размещаются два 16-байтных подблока данных. С каждой строкой связан соответствующий адресный тег. D-кэш индексируется с помощью виртуального адреса, при этом теги также хранят соответствующую часть виртуального адреса. При возникновении промаха при обращении к кэшируемой ячейке памяти происходит загрузка 16-байтного подблока из основной памяти.
Поиск слова в D-кэше осуществляется с помощью виртуального адреса, младшие разряды которого обеспечивают доступ к строке кэш-памяти, содержащей требуемое слово (прямое отображение). Старшие разряды виртуального адреса сравниваются затем с битами соответствующего тега для определения попадания или промаха. Подобная схема гарантирует быстрое обнаружение промаха и обеспечивает преобразование виртуального адреса в физический только при наличии промаха.
Управление внешней кэш-памятью
Одной из важнейших проблем построения системы является согласование производительности процессора со скоростью основной памяти. Основными методами решения этой проблемы, помимо различных способов организации основной памяти и системы межсоединений являются увеличение размеров и многоуровневая организация кэш-памяти. Устройство управления внешней кэш-памятью (ECU С E-кэш) процессора UltraSPARC-1 позволяет эффективно обрабатывать промахи кэш-памяти данных (D-кэша) и команд (Е-кэша). Все обращения к внешней кэш-памяти (E-кэшу) конвейеризованы, выполняются за 3 такта и осуществляют пересылку 16 байт команд или данных в каждом такте. Такая организация дает возможность эффективно планировать конвейерное выполнение программного кода, содержащего большой объем обрабатываемых данных, и минимизировать потери производительности, связанные с обработкой промахов в D-кэше. ECU позволяет наращивать объем внешней кэш-памяти от 512 Кбайт до 4 Мбайт.
ECU обеспечивает совмещенную во времени обработку промахов обращений по чтению данных из Е-кэша с операциями записи. Например, во время обработки промаха по загрузке ECU разрешает поступление запросов по записи данных в E-кэш. Кроме того, ECU поддерживает операции наблюдения (snoops), связанные с обеспечением когерентного состояния памяти системы.
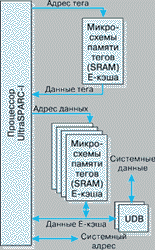
Типовой процессорный модуль UltraSPARC-1
Типовой процессорный модуль (рис. 2) UltraSPARC-1 состоит из собственно процессора UltraSPARC-1, микросхем синхронной статической памяти (SRAM), используемых для построения памяти тегов и данных внешнего кэша и двух кристаллов буферов системных данных (UDB). UDB изолируют внешний кэш процессора от остальной части системы и обеспечивают буферизацию данных для приходящих и исходящих системных транзакций, а также формирование, проверку контрольных разрядов и автоматическую коррекцию данных (с помощью ECC-кодов). Таким образом, UDB позволяет интерфейсу работать на тактовой частоте процессора (за счет снижения емкостной нагрузки).
 (1x1)
(1x1)
Рис. 2. Типовой процессорный модуль
Буфер данных обеспечивает также совмещение во времени системных транзакций с локальными транзакциями E-кэша. В состав процессора UltraSPARC-1 включена логика управления буферными кристаллами, которая обеспечивает быструю пересылку данных между процессором или внешним кэшем и системой. Для поддержки системных транзакций используется отдельная адресная шина и отдельный набор управляющих сигналов.
Архитектура системной шины UPA
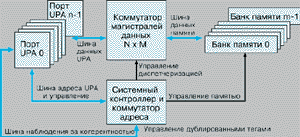
Обеспечение высокой производительности процессора UltraSPARC-1 потребовало создания гибкой масштабируемой архитектуры межсоединений, позволяющей достаточно просто строить системы для широкого круга приложений от небольших настольных систем индивидуального пользования до больших многопроцессорных корпоративных серверов. Новая архитектура UPA (Ultra Port Architecture) определяет возможности построения целого семейства тесно связанных многопроцессорных систем с общей памятью.
UPA представляет собой спецификацию, описывающую логические и физические интерфейсы порта системной шины, и требования, накладываемые на организацию межсоединений. К этим портам подключаются все устройства системы. Спецификация UPA включает также описание поведения системного контроллера и интерфейс ввода/вывода системы межсоединений.
UPA может поддерживать большое количество (рис. 3) системных портов (32, 64, 128 и т.д.) и включает четыре типа интерфейса. Интерфейс главного устройства выдает в систему межсоединений транзакции чтения/записи по физическому адресу, используя распределенный протокол арбитража для управления адресной шиной. Главное устройство UPA, например процессорный модуль UltraSPARC-1, может включать физически адресуемую когерентную кэш-память, на размер которой в общем случае не накладывается никаких ограничений. Интерфейс подчиненного устройства получает транзакции чтения/записи от главных устройств UPA, поддерживая строгое упорядочивание транзакций одного и того же класса главных устройств, а также транзакций, направляемых по одному и тому же адресу устройства. Порт UPA может быть только подчиненным, например, для подключения графического буфера кадров. Двумя другими дополнительными интерфейсами порта UPA являются источник и обработчик прерываний. Источники прерывания UPA генерируют пакеты прерывания, направляемые к обработчикам прерываний UPA.
 (1x1)
(1x1)
Рис. 3. Масштабируемая архитектура UPA
В отличие от традиционных мультипроцессорных систем, поддерживающих когерентное состояние кэш-памяти и разделяющих глобально наблюдаемую адресную шину, архитектура межсоединений UPA основана на пакетной коммутации сообщений по принципу точка-точка. Поддержка когерентного состояния кэш-памяти системы для настольных рабочих станций, включающих от 1 до 4 процессоров, осуществляется централизованным системным контроллером, а для больших серверов С распределенным системным контроллером. UPA может поддерживать дублирование наборов тегов всех кэшей системы и позволяет для каждой когерентной транзакции выполнять параллельно просмотр дублированных тегов и обращение к основной памяти.
Отход от традиционных методов построения мультипроцессорных систем, основанных на наблюдаемой шине или на справочнике, позволяет существенно минимизировать задержки доступа к данным благодаря сокращению потерь на обработку промахов кэш-памяти. В итоге архитектура межсоединений UPA позволяет более эффективно использовать высокую пропускную способность процессора UltraSPARC-1. Максимальная скорость передачи данных составляет 1.3 Гбайт/с при работе UPA на тактовой частоте 83 МГц.
Разработчики архитектуры UPA многое сделали для минимизации задержек доступа к данным. Например, UPA поддерживает раздельные шины адреса и данных. Именно эти широкие шины С адресная шина имеет 64 бит, а шина данных С 144 бит (128 бит данных и 16 бит для контроля ошибок)) обеспечивают пиковую пропускную способность системы. Наличие отдельных шин позволяет устранить задержки, возникающие при переключении разделяемой шины между данными и адресом, а также возможные конфликты доступа к общей шине.
UPA не только поддерживает отдельные шины адреса и данных, но и позволяет иметь несколько шин с организацией соединений точка-точка. Обычно в большинстве систем имеются несколько интерфейсов для обеспечения работы подсистемы ввода/вывода, графической подсистемы и процессора. В мультипроцессорных системах требуются также дополнительные интерфейсы для организации связи между несколькими ЦП. Вместо одного набора шин данных и адреса для всех этих интерфейсов UPA допускает создание неограниченного количества шин.
Подобная организация имеет ряд достоинств. Наличие нескольких наборов шин позволяет минимизировать количество циклов арбитража и уменьшает вероятность конфликтов. Системный контроллер несет ответственность за работу и взаимодействие различных шин и может параллельно обрабатывать запросы нескольких шин. Он позволяет также уменьшить задержки, связанные с захватом шины. По существу, наличие нескольких шин адреса и данных означает меньшее число потенциальных главных устройств на каждом наборе шин. Для обеспечения наименьшей возможной задержки захвата шины используется распределенный конвейеризованный протокол арбитража. Каждый порт UPA имеет собственные схемы арбитража, при этом каждый порт в системе видит запросы шины всех других портов. Такая схема также позволяет уменьшить задержку доступа и обеспечивает увеличение общей производительности системы.
Архитектура UPA легко адаптируется для работы почти с любой конфигурацией системы С от однопроцессорной до массивно-параллельной. Разработчиками были предусмотрены специальные меры с целью ее оптимизации для систем, содержащих от 1 до 4 процессоров. В результате до четырех тесно связанных процессоров и системный контроллер могут разделять доступ к одной и той же системной адресной шине. Однако на базе богатого набора транзакций и протокола когерентности, которые поддерживаются устройством интерфейса памяти процессора UltraSPARC-1, могут быть построены мультипроцессорные системы с большим количеством процессоров. В архитектуре UPA применяется протокол когерентности, построенный на основе операций записи с аннулированием соответствующих копий блока в кэш-памяти других процессоров системы и использующий для наблюдения дублированные теги. Процессор UltraSPARC поддерживает переходы состояний блоков кэш-памяти, соответствующие протоколам MOESI, MOSI и MSI.
Следует отметить, что в основу архитектуры UPA положены принципы, позволяющие иметь в системе не только несколько мультиплексированных или раздельных шин, но и в широких пределах варьировать разрядность шины данных для удовлетворения различных требований к отношению стоимость/производительность. При этом в различных частях системы в зависимости от конкретных требований может использоваться разная скорость передачи данных. Например, разрядность шины данных системы ввода/вывода вполне может быть ограничена 64 битами, но для согласования с интерфейсом процессора более предпочтительна разрядность в 128 бит. С другой стороны, разрядность шины данных оперативной памяти системы может быть еще более увеличена для обеспечения высокой пропускной способности при использовании более медленных, но более дешевых микросхем памяти С в младших моделях компьютеров на базе микропроцессора UltraSPARC-1 используется 256-битовая шина данных памяти, а в старших моделях С 512-битовая.
Набор графических команд
UltraSPARC является первым универсальным процессором с 64-битовой архитектурой, обеспечивающий высокую пропускную способность, необходимую для реализации высокоскоростной графики и обработки видеоизображений в реальном масштабе времени. Расширенный набор команд UltraSPARC позволяет за один такт выполнять сложные графические операции, для реализации которых обычно затрачивается несколько десятков тактов. При этом только три процента реальной площади кристалла используется для реализации графических команд. Высокая производительность UltraSPARC и его способность выполнять декомпрессию и обработку видеоданных в реальном времени позволяют в ряде случае при построении системы обойтись без специальных дорогостоящих видеопроцессоров.
Высокоскоростная обработка графики и видеоизображений базируется на суперскалярной архитектуре процессора UltraSPARC. При этом для вычисления адресов команд загрузки и записи широко используются целочисленные регистры, а для манипуляций с данными С регистры плавающей точки. Такое функциональное разделение регистров существенно увеличивает пропускную способность процессора, обеспечивая приложению максимальное количество доступных регистров и параллельное выполнение команд.
Специальный набор видеокоманд UltraSPARC (VIS С Video Instruction Set) предоставляет широкие возможности обработки графических данных: команды упаковки и распаковки пикселей, команды параллельного сложения, умножения и сравнения данных, представленных в нескольких целочисленных форматах, команды выравнивания и слияния, обработки контуров изображений и адресации массивов. Эти графические команды оптимизированы для работы с малоразрядной целочисленной арифметикой, при использовании которой обычно возникают значительные накладные расходы, вызванные необходимостью многократного преобразования из целочисленного формата в формат с плавающей точкой и обратно. Возможность увеличения разрядности промежуточных результатов обеспечивает дополнительную точность, необходимую для получения качественных графических изображений. Все операнды графических команд находятся в регистрах вещественной арифметики, что обеспечивает максимальное количество регистров для хранения промежуточных результатов вычислений и параллельное выполнение команд.
UltraSPARC поддерживает различные алгоритмы компрессии, используемые для видеоприложений и обработки неподвижных изображений, включая H.261, MPEG-1, MPEG-2 и JPEG. Кроме этого, процессор может обеспечивать скорости кодирования и декодирования, необходимые для организации видеоконференций в реальном времени.
Первые системы на базе процессора
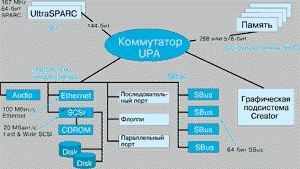
Сегодня компания Sun выпускает два типа настольных рабочих станций и серверов, оснащенных процессорами UltraSPARC: Ultra 1 и Ultra 2, архитектура которых представлена на рис. 4.
 (1x1)
(1x1)
Рис. 4. Архитектура станций Ultra1 и Ultra 2
В моделях Ultra 1 используются процессоры с тактовой частотой 143 и 167 МГц. При этом они комплектуются как стандартными видеоадаптерами TurboGX и TurboGXplus (модели 140 и 170), так и новыми видеоподсистемами Creator и Creator3D (модель 170Е). Объем оперативной памяти может наращиваться до 512 Мбайт, внутренних дисков до 4.2 Гбайт, можно устанавливать также накопители на магнитной ленте, флоппи-дисководы и считывающие устройства с компакт-дисков. Эти системы обеспечивают уровень производительности в 252 SPECint92 и 351 SPECfp92 при тактовой частоте 167 МГц. Модели 170Е оснащаются контроллерами Fast&Wide SCSI-2 и 100Base-T Ethernet.
Модели Ultra 2 С это однопроцессорные и двухпроцессорные системы на базе 200 МГц процессора UltraSPARC (332 SPECint92 и 505 SPECfp92), имеющие максимальный объем оперативной памяти 1 Гбайт. Появление следующих моделей, построенных на процессорах UltraSPARC II (420 SPECint92 и 660 SPECfp92), ожидается в середине 1996 года.
Заключение Выпуск 64-разрядного процессора UltraSPARC и первых компьютеров на его основе ознаменовал собой новый этап в развитии компании Sun Microsystems, которая планирует постепенно перевести на эти процессоры все свои изделия, включая рабочие станции и серверы начального уровня. Конечно для широкого внедрения новой концепции обработки данных, получившей название UltraComputing, понадобится некоторое время, но уже сейчас очевидно, что ориентация Sun на обеспечение высокой сбалансированной производительности для широкого класса прикладных систем, пропускной способности передачи данных для сетевых приложений и построение эффективных средств визуализации и обработки видеоданных в реальном времени позволяет компании сохранять свои позиции на современном рынке научно-технических и бизнес-приложений.
Литература
1. "UltraSPARC-1. High-Performance 64-Bit RISC Processor", SPARC Technology Business, May 1995.
2. "UltraSPARC(TM). Universal Port Architecture: The New Media System Architecture", Whitepaper #95-023, SPARC Technology Business, 1995.
3. "UltraSPARC?. The Visual Instruction Set (VIS): On-Chip Support for New-Media Processing", Whitepaper #95-022, SPARC Technology Business, 1995.
Виктор Шнитман (vzs@ispras.ru) -- сотрудник Института системного программирования PAH, (Москва).
