

При загрузке браузера подспудно ощущаешь, что необходимая информация в Сети есть, но до нее никак не удается добраться и очевидным выходом из этого тупика является создание информационной службы поиска с использованием ключевых слов и фраз. И такие службы в Internet есть — перед пользователем стоит только одна проблема: какую службу или механизм поиска выбрать. Главное, хорошо представлять себе, что ты хочешь найти и где искать.
Internet, подобно спруту, опутала своими щупальцами почти весь земной шар. Он охватывает все области человеческой деятельности. Включая в себя огромное количество отдельных сетей, и Internet имеет свыше 20 млн. пользователей. К тому же, это - быстро развивающаяся структура: число серверов Web удваивается каждые 53 дня. В такой ситуации первопроходец может сутками продираться сквозь постоянно разрастающиеся щупальца, достигая, в конечном итоге, нулевого результата. Как же быть? Отдаться на волю случая? Конечно, нет. На выручку приходят информационные службы, помогающие не только первопроходцу, но и искушенному пользователю ориентироваться в бесчисленной паутине информации. По существу, информационная служба должна работать для отдельного конкретного пользователя, а последний оценивает ее деятельность по уже полученным результатам, принимая во внимание такие факторы, как:
- полнота информационных ресурсов;
- средства поиска;
- обновляемость (расширяемость);
- дизайн.
Заглянем в самые популярные зарубежные информационные службы (каталоги). Сразу надо отметить, что они демонстрируют великолепный дизайн и расширенные средства поиска.
LYCOS
Lycos основана в Мальборо (Массачусетс) и имеет свои представительства в Питсбурге (Пенсильвания). Будучи абсолютно бесплатной службой для пользователей (нет платы на подписку, поиск и ответные справки), LYCOS обслуживает более 30 млн. запросов в месяц, что делает ее одной из самых популярных служб на WWW. LYCOS поддерживается на средства Carnegie Mellon University.
Point, дочерняя компания LYCOS, является издателем первого обзора on-line и руководства оценки для Internet, Point Survey. В настоящее время Point располагает наиболее полной коллекцией последних Web-обзоров, доступных в режиме on-line, и обрабатывает 6 млн. ответных справок (на запрос) в месяц. Кроме того, недавно образованная и бесплатная служба Point Now обеспечивает в режиме реального времени обновление новостей и статей со всего мира, представляющих общий интерес, наряду с обновлениями по множеству специализированных предметных областей. LYCOS и Point получают денежные средства от продажи объявлений. LYCOS дополнительно получает доходы от лицензий на использование своей технологии и каталога Internet таким компаниям, как Microsoft и Frontier Technologies.
Полнота информационных ресурсов LYCOS поражает воображение. LYCOS заиндексировала свыше 10,75 млн. страниц по всему миру. Это составляет свыше 91% содержания World Wide Web. Никакой другой каталог, средство поиска или справочник даже не приближается к такой цифре. На рисунке 1 отражены размеры каталогов ведущих служб.
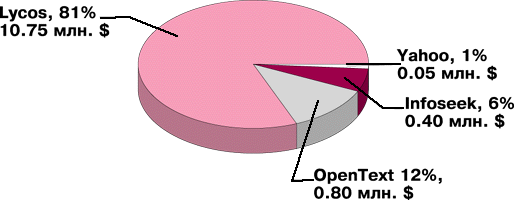
Рис. 1. Размеры каталогов ведущих служб.
Купите ли вы только первый том энциклопедии вместо семнадцати или словарь, включающий всего лишь буквы A и B? А это сравнение хорошо соответствует тому, что вы можете получить от возможностей других каталогов. LYCOS обладает самой быстрой и наиболее мощной технологией поиска и индексирования. Используя технологию сделанных заявок на патент, "паук" LYCOS постоянно производит выборки на Web и сливает результаты поиска в каталог LYCOS, который еженедельно "вырастает" на 300000 страниц. LYCOS ищет не только по узлам http, но и по адресам FTP и gopher. В отличие от других Web-каталогов, LYCOS индексирует и нетекстовые ресурсы Internet, включая графику, звуки, фильм и исполняемые программы, не индексируя, однако, недолговечные или изменяющиеся данные или бесконечные виртуальные пространства. Следовательно, базы данных WAIS, новости USENET, услуги telnet, электронная почта не попадают в сферу деятельности LYCOS.
Кроме того, LYCOS игнорирует файлы, начинающиеся на "/dev/tty/" и заканчивающиеся следующими расширениями: AU, AVI, BIN, DAT, DVI, EXE, FLI, GIF, GZ, HDF, HQX, JPEG, LHA, MAC, MPEG, PS, TAR, TGA, TIFF, UU, UUE, WAV, Z или ZIP.
В период с 21 ноября 1994 года по 4 апреля 1995 года LYCOS загрузила по крайней мере, по одному файлу из 23550 уникальных HTTP-серверов. Таблица 1, отражающая распределение по типам файлов, наглядно иллюстрирует, что загрузила LYCOS в этот период. При этом средний размер загруженного текстового файла равнялся 7920 символам.
Таблица 1.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
LYCOS предоставляет пользователю не только список всех узлов, выданных по запросу, но и их ранжировку, основываясь на оценке "популярности" каждого из узлов. Эта оценка для определенного узла вычисляется на основании общего количества других узлов, имеющих связи с ним. Используя свою технологию, LYCOS опять-таки автоматически создает аннотации с наиболее популярных узлов, позволяя быстро и эффективно определить, какие узлы наиболее релевантны пользовательским запросам.
Получается, что LYCOS растет быстрее, чем сам Web, т.е. очень скоро в каталогах LYCOS окажется свыше 99% содержания Web. Механизм поиска LYCOS, PURSUIT, является программой на Си, использующей поисковую систему с инвертированными файлами и простую сумму весов для подсчета документов. Уникальная особенность заключается в том, что PURSUIT оценивает, насколько близко к началу файла встречаются в документе слова. Таким образом, ответные справки в названии или первом параграфе оцениваются выше.
Планируется модернизировать язык механизма поиска, включая больше стандартных булевых операторов. Кроме того, будут добавлены коррекция орфографии и семантические средства.
Open Text
Посмотрим, чем хороша эта информационная служба, какие продукты и услуги предоставляет своим пользователям. Корпорация Open Text является пионером и одним из лидеров технологии поиска с развитой логикой. Программные средства Open Text хорошо понимают структуру документов на Internet и быстро выдают релевантные результаты по запросам пользователя, позволяют искать любое слово на любой странице, доступной на Internet, - и в локальной, и в глобальной сети - в соответствии с критерием, определенным пользователем.
Основанная в 1991 году, корпорация Open Text является частной компанией, штаб-квартира которой расположена в Ватерлоо (Канада). Ее основной высокопроизводительный инструмент поиска по тексту, Open Text 5, основан на технологии Центра разработок текстовой информации в университете Ватерлоо. Технология используется как академическими и правительственными учреждениями, так и компаниями, связанными с такими отраслями деятельности, как автопромышленность, финансовые услуги, здравоохранение, страхование, библиотеки, издательская деятельность.
Корпорация Open Text разработала технологию и рыночную стратегию, с целью занять ведущее место на быстрорастущем рынке продуктов и услуг по интерактивному поиску, который оценивался в 1994 году в 400 млн. долл., а годовой рост приблизительно был равен 30-35%.
Для того чтобы извлечь максимальную выгоду из этих благоприятных возможностей, Open Text в последние двенадцать месяцев заметно увеличила свой штат и вкладывает значительные средства в деятельность по сбыту и маркетингу. Компания работает с такими партнерами как Yahoo!, которая интегрирует продукты Open Text в свои собственные продукты и услуги, а также с другими фирмами, поддерживающими и продающими продукты компании в различных отраслях.
Компания начала свою деятельность с создания механизма поиска по полному тексту для Оксфордского английского словаря. Появление Open Text Index(TM), наиболее объемлющего мощного средства по поиску в Internet, с его способностью обрабатывать огромные массивы текста наряду с пониманием его структуры, выполненной в формате SGML, стала возможным благодаря языку SGML. Создание Open Text Latitude(TM), системы распределения документов, позволяющей целым предприятиям искать и использовать все документы, было естественным результатом прежних усилий. Технология Web Search Server(TM) предоставляет средства для расширения возможностей поиска текста в Internet и приложений по поиску, открывая доступ пользователям ко всем поисковым данным на Internet. С помощью "ползунов", Open Text программ-посредников по индексированию, Web Search Server индексирует каждое слово, каждую страницу в Internet. Кроме постоянного индексирования, "ползуны" регулярно посещают различные узлы, пополняя раздел "что нового" в основном индексе. Web Search Server "подпитывается" Open Text(TM), то есть основан на разработке Open Text Index, гарантирующей следующие возможности: индексирование "слово за словом" и гибкие эффективные поисковые запросы, в том числе многоуровневые булевы, структурированные поиски, ранжированные и простые поиски для определенных слов и фраз.
Open Text 5 сердце индексирования Open Text INDEX на WWW. Это высокопроизводительный механизм поиска с развитыми логическими возможностями, разработанный для переработки огромных объемов информации.
Перечислим преимущества Open Text 5:
- высокая производительность;
- способность индексирования свыше 40 различных типов файлов, включая систему подготовки текстов, SGML, HTML и PDF;
- индексирование каждого слова, каждой страницы, включая "stop"-слова;
- осведомленность о структуре, то есть наличие информации об элементах документа (основные заголовки и сноски), в которых встречаются слова;
- многоязычность, т.е. возможность индексировать европейские и неевропейские языки (например японский и арабский)
- монитор параллельного выполнения, способный обрабатывать запросы на многих серверах одновременно;
- "ползуны", автоматически ведущие поиск на узлах для построения и пополнения индекса.
Open Text 5 разработан, чтобы стать магистралью приложений промышленного масштаба, и утвердил себя на часто посещаемых узлах. Продукты корпорации Open Text первоначально были разработаны для индексирования сложных SGML-документов. Путем стандартизации Internet-документов на HTML, подмножестве SGML, Open Text смогла начать индексирование Internet. Многие клиенты компании используют WWW в качестве "виртуальной внутренней сети" для совместного использования данных, связи и сотрудничества по всему предприятию.
Корпорация Open Text предлагает завершенное решение для организации баз данных на World Wide Web - Latitude Web Server, программное обеспечение, усиливающее Open Text Index на WWW. Этот сервер многим отличается от стандартных систем:
- Open Text 5;
- HTTP-демон для обработки "деталей" ответа на вход пользователя в Web. (Возможен и иной выбор - Latitude Web Server прекрасно работает с программными средствами Web-сервера из Netscape, Open Market и другие);
- программы-"ползуны";
- фильтры данных, автоматически переводящие форматы обработки текстов в HTML "на лету" (пользователи имеют доступ к документам, написанным в Microsoft Word, WordPerfect и в других текстовых редакторах; другими словами, дублировать множество документов, которое должно быть переведено в HTML, не придется);
- программные средства по администрированию и выписыванию счетов, которые отслеживают доступы к вашим данным, время центрального процессора и др. Это позволяет пользователям эффективно управлять своим узлом и даже выписывать счета за использование.
Несмотря на то, что большой объем и динамическая природа Internet не позволяют организовать полное индексирование, а некоторые узлы не предоставляют доступа для любого механизма индексирования, средства компании Open Text по индексированию и поиску работают в пределах этих ограничений, создавая достаточно объемлющий и точный каталог Internet, включая WWW, Archie, Gopher и Usenet News (LYCOS, как мы уже знаем, не предоставляет такой возможности).
Остановимся поподробнее на уникальной возможности Open Text - поиске по полному тексту. Когда перед вами открываются огромные массивы информации (скажем, WWW), и вы хотите что-то найти, то необходимо использовать каждый ключ и "дактилоскопический отпечаток", какими вы располагаете. Одним из способов поиска информации является ее организация по категориям, логическим подкатегориям и т.д. Так устроено содержание. То же мы наблюдаем в Yahoo.
Но бывает, что вы хотите найти информацию, рассеянную по нескольким категориям, или она не входит ни в одну категорию, или вы просто не знаете, какой каталог просматривать, или, наконец, в выбранной вами категории содержится слишком много документов. Вот почему у книг есть индексы. Стандартный индекс по полному тексту (каким не является Open Text Index) во многом напоминает индекс в конце книге. Программные средства по индексированию пропускают весь материал, который необходимо проиндексировать, и строят гигантский список. Существуют разные способы организации списка. Выбор определяется несколькими соображениями:
- Количество данных. Многие индексные разработки достаточно быстро ищут данные, пока вы не дошли до 1 Гбайт данных. Тогда очень быстро возрастает время ожидания и т.д.
- Точность и воспроизведение. Критерий точности заключается в определении "ошибочных утверждений", выданных вашим индексом пользователю. Критерием воспроизведения является количество "истинных утверждений", найденных индексом.
- Контекст. Какое количество информации вы записываете? Где появляется слово? Какое слово стоит следующим? Где в структуре документа встречается слово? Большинство индексов основано на модели "инвертированного слова", в которой за каждым уникальным словом следует множество указателей (электронный эквивалент номеров страниц) на документы, в которых слово найдено.
Хотя во многих случаях это приемлемо, подход имеет ряд слабых мест. Работа индексов по инвертированному слову быстро ухудшается после преодоления гигабайтной отметки. По этой причине (наряду с другими) в индексах по инвертированному слову стараются избегать использования "стоп"-слов (и, а, или, др.), то есть слов, встречающихся на большинстве страниц. Они не схватывают контекст, ограничивая тем самым пользователя выполнением производительных поисков.
Open Text не использует индекс по инвертированному слову, а использует архитектуру "построчного" индекса: индексируется каждое слово, даже "стоп"-слова, а также слова в контексте. Вот почему с помощью Open Text Index вы можете искать полные фразы и вот почему вы можете искать в пределах заглавий и других структурных элементов.
Другие механизмы поиска
Вы можете выбрать уже рассмотренные службы или какой-либо другой механизм поиска. Ниже мы представим их краткий перечень других механизмов поиска.
CUSI. CUSI (Configurable Unified Search Engine) - это настраиваемый поисковый интерфейс для многих WWW-ресурсов, доступных для поиска. Он позволяет быстро проверить связанные ресурсы, не настраиваясь на каждый из них и не перебивая ключевые слова. Механизм разработан и представлен как личная инициатива М. Костера в 1993 году. Теперь он является частью программы "NEXOR - профессиональная служба WEB".
GlOSS. GlOSS представляет собой систему, разработанную в Стенфордском университете, которая помогает найти источники данных, наилучшим образом соответствующие вашим запросам. Только представьте GlOSS перечень ключевых слов, и система отобразит ранжированный перечень источников, содержащих документы, какие вы ищете.
IS WORKGROUP, SEARCH PAGE. Прежде всего, этот механизм характерен наличием связи с собственным перечнем мест, представляющих интерес, который содержит ряд соединений с серверами, признанные членами рабочей группы интересными. Оставшаяся часть этого документа представляет некоторые наиболее полезные механизмы поиска, доступные на WWW. Вводите ваш запрос, выбираете механизм поиска и нажимаете "submit".
INFOSEEK. InfoSeek является одним из популярных механизмов поиска на Web. Поиск с его помощью очень легок и увлекателен. InfoSeek содержит достаточно большой индекс WWW-страниц на Internet и наиболее полный в мире полнотекстовый индекс UseNet новостей (свыше 10,000 групп новостей охватывают почти любую тему, какую только можно вообразить). Вы можете ввести запрос на английском языке или ключевые слова и фразы, и высокоточный механизм поиска найдет информацию, какую вы ищите, за секунды.
INTERNET SEARCH ENGINES. Internet огромен и продолжает разрастаться, поэтому поиск необходимого вам ресурса может показаться просто устрашающим. Эта страница включает связи к достаточно продвинутым механизмам поиска для тех пользователей, кто более или менее точно знает, что он ищет. Если такого понимания нет, тот имеется в наличии перечень более дружественных для пользователя механизмов поиска. Эти механизмы позволяют вам искать информацию разными способами: одни ищут названия документов, другие - сами документы и третьи - другие индексы и каталоги.
JUMPSTATION FRONT PAGE. Это способ поиска ссылок на информацию, доступную на WWW. Пользователи получают множество ссылок на другие страницы Web, соответствующих их запросу. Для сбора данных JumpStation использует Robot, обеспечивающий средства поиска для темы, на которую есть ссылка в названии документа.
MUSCAT. Muscat - механизм поиска на естественном языке, который намного быстрее, чем другие статистические поисковые системы. Muscat помогает пользователям, предлагая родственные слова на лету: нет необходимости вручную создавать "темы" или тезаурус.
YAHOO. Yahoo считается одной из популярных и объемлющих каталогов на WWW. Yahoo предлагает поиск по ключевым словам и каталог "что на Web". Но использование категорий каталога может быть бесполезным, если вы точно не знаете, что хотите.
Национальная служба технической информации
Приведем пример информационной службы, совершенно отличной от выше рассмотренных как по источникам информации, так по поисковым возможностям.
National Technical Information Service (Национальная служба технической информации) представляет информацию, субсидируемую правительством США. NTIS, агентство Министерства торговли, по праву считается центральным национальным ресурсом информации, касающейся научно-технических и инженерных работ, а также бизнеса. Служба предоставляет широкий спектр информации, которую трудно найти где-либо еще. NTIS обеспечивает доступ к более чем 2,7 млн. названий, представляющих собой доклады, описывающие исследования, ведущиеся или спонсирующиеся федеральными агентствами; статистическую и деловую информации; аудио-визуальные продукты; программные средства и базы данных, разработанные федеральными агентствами; и технические доклады, подготовленные международными исследовательскими организациями. Около 85000 новых документов индексируется и добавляется ежегодно.
Информация поступает от многочисленных участников: правительства США, источников, распространенных по всему миру, и совместных предприятий. В соответствии со специальным законом, касающимся американских технологий, сотни федеральных агентств регулярно направляют в NTIS копию своих информационных продуктов для общедоступного распределения.
Только NTIS предоставляет следующие информационные услуги:
- FEDWORLD. Электронное окно в NTIS. FedWorld стартовала в ноябре 1992 года, когда NTIS организовала небольшую систему доступа с установлением связи по телефонному номеру, которая позволяла связываться с 50 другими правительственными "досками объявлений", а также получить информацию о различных информационных продуктах правительства, доступных из NTIS. Целью NTIS FedWorld является обеспечение доступа пользователей по централизованному размещению и заказу информации правительства США. Доступ к FedWorld осуществляется через модем или telnet-команды на Internet (fedworld.gov) и обеспечивает связь с правительственными WWW-серверами, NTIS-файлами, документами и базами данных. Узел FedWorld Telnet обеспечивает свободный межсетевой интерфейс со 140 правительственными интерактивными системами, многие из которых иными путями недоступны в Internet. Все правительственные WWW-серверы отсортированы по предметным категориям - по таким же, как в NTIS, сортируются более 700 новых информационных продуктов, получаемых каждую неделю, - таким образом, пользователь может легко настроиться на сервер, соответствующий его интересам. В ближайшем будущем ожидается, что в перечень правительственных серверов США войдут правительственные Gopher и FTP-серверы.
- NTIS Preview Database. База данных содержит библиографические ссылки на тысячи новых информационных продуктов, поступивших в коллекцию NTIS в последние 30 дней и доступных для продажи.
- Библиографическая база данных NTIS. Не имеющий себе равных ресурс, обеспечивающий глубокий охват исследований в научной, технической, конструкторской и др. областях, спонсируемых правительством США и международными источниками. Полная база данных содержит более чем двух миллионов записей. Многие из них являются уникальными, поэтому недоступны из других источников.
- NTIS ALERT. Обеспечивает эффективный и своевременный способ находиться в контакте с последними исследованиями, технологиями и разработками, доступными из NTIS. Эта служба два раза в месяц знакомит с новыми документами, добавленными в NTIS, которые могут представлять интерес. Более чем 1600 новых названий добавляются в NTIS каждую неделю.
- FEDRIP (база данных текущих федеральных исследований). Необходимый ресурс для тех, кому необходима информация о ведущихся исследованиях, инвестируемых федеральным правительством. Вы можете получить доступ к информации, содержащейся в 150000 ведущих исследовательских проектах в различных предметных областях.
- Foreign Broadcast Information Service Daily Reports (Широковещательная информационная служба по ежедневным отчетам). Эти популярные отчеты, составленные правительством США, содержат политические, военные, экономические, экологические, социологические новости, комментарии и другую информацию.
- World News Connection. Служба в режиме on-line, обеспечивающая информацией, включающей выдержки международных политических речей, телевизионных и радиопрограмм, газетных статей, периодики и книг - все переведены на английский.
- Published Search (общедоступный поиск). На основании кратких рефератов для каждого общедоступного поиска вы можете быстро и недорого определить, какие из тысячи документов из базы данных релевантны для вас.
- Free Catalogs. Предоставление бесплатных каталогов NTIS, которые можно посмотреть, загрузить или заказать в on-line (текстовые и PDF-файлы). PDF-файлы требуют программные средства Acrobat Reader для просмотра и печати документов.
***
Информационные службы, взявшие на вооружение механизмы поиска, занимают лидирующее положение в Internet. Перед пользователем стоит только одна проблема - какую службу или механизм поиска выбрать. Главное хорошо представлять себе, что хочешь найти и где искать. Чтобы помочь вам легче ориентироваться в море информационных ресурсов, мы представили этот краткий перечень механизмов поиска. Если один механизм не поможет, попробуйте другой. Надеемся, что они помогут вам найти что-то полезное для себя.
РОССИЙСКИЕ ИНФОРМАЦИОННЫЕ СЛУЖБЫДо осени 1995 года российские поставщики IP-услуг не обращали особого внимания на организацию специализированных информационных служб для абонентов своих сетей. Серьезный шаг в этом направлении был предпринят в конце года компанией Sovam Teleport, которая объявила об организации системы Россия Он Лайн. В заявлении о создании этой службы было сказано, что она строится по примеру крупной коммерческой службы типа America On Line. Не вдаваясь в организационную сторону вопроса, попробуем оценить существующий уровень этого информационного ресурса в сравнении с такими службами как Lycos или Yahoo. Web-страница РОЛ строится по образцу и подобию указанных выше служб. Если бы не русские буквы в графическом меню, то можно было бы и не заметить различий. Такое решение достаточно удобно с точки зрения выбора пользователем одной из страниц кодировки русских букв, т.к. не требует показа на полэкрана непонятной тарабарщины, в которой нужно разглядеть что-то осмысленное. К сожалению, пока у системы много недостатков. Отсутствие поиска информации по ключевым словам, заставляет пользователя блуждать по системе меню, что само по себе достаточно утомительно. Большинство страниц, объявленных в гипертекстовых ссылках, находятся в стадии разработки и не содержат информации, зато уже есть коммерческий вход, требующий регистрации. По всей видимости, нет и сколь-либо большой базы данных индекса информационных ресурсов Internet, без которой не обходится ни одна западная служба. При регистрации управляющие файлы (scripts) системы не проверяют наличие данного пользователя в базе данных зарегистрированных пользователей системы. При входе в зарегистрированную часть необходимо указывать пароль, но во время регистрации это не требуется, а, следовательно, есть проблемы с зарегистрированным входом (правда это можно объяснить бестолковостью пользователя, но в западных системах таких проблем не было). При реализации системы SovamTeleport выбрал технологию Netscape. Такое решение оправданно и закономерно. В страницах применяется большое количество тегов из спецификации Netscape Extensions, что не мешает просматривать их с помощью других программ просмотра. Дизайн системы полностью соответствует решениям принятым другими службами. Интересна и организационная структура группы, которая занимается разработкой этого сервера. Общая численность сотрудников, согласно информации с сервера ROL, составляет 11 человек, из которых собственно созданием документов HTML занимаются только двое. Однако при сравнении с другими аналогичными отечественными службами - это довольно большой штат. Ясно и другое - все перечисленные выше недостатки возможны из-за того, что за два-три месяца нельзя развернуть полноценную информационную службу при таком количестве занятых в ней сотрудников. Будем надеяться, что через год РОЛ действительно станет реальным информационным ресурсом не только российского сектора Сети, но и всего Internet в целом. В конце прошлого года к созданию своей информационной службы приступила компания Demos. Эта служба получила название Russia on Net. Важной ее особенностью стало наличие электронного журнала Crazy Web и обращений к поисковым машинам удаленных информационных систем. Журнал представляет из себя набор страниц Web, которые не связаны между собой какой-либо тематической иерархией. При их реализации часто используются таблицы для форматирования текста. Поисковый механизм системы реализован путем обращений к таким поисковым машинам информационных служб, как Yahoo, DejaNews, Infoseek, OpenText Search Engine, Lycos, DejaNews (поиск в архивах Usenet) и Intermap (почтовые адреса, Россия). Правда, при загруженности отечественных каналов такой поиск не дает никаких преимуществ перед прямым обращением к данным системам. Судя по дизайну страниц и их реализации, система опирается на возможности Netscape и совместима с этой программой серверов. Relcom также начал преобразование своих информационных служб, которое вылилось в систему Infoline. Она не такая красивая, как перечисленные выше, но зато в ней реализована масса сервисных возможностей, которые скрыты от пользователей системы. Это и автоматическая перекодировка по типу клиента, и дополнительные деревья, и поддержка СУБД, и многое другое. В системе не реализован поиск по ключевым словам ни в World Wide Web, ни в GopherSpace. Отчасти это объясняется нехваткой дискового пространства поскольку на одну только базу данных Veronica требуется около 2 Гбайт памяти.Однако в настоящее время изыскиваются гораздо большие возможности. В целом информационные службы Relcom следует признать как одни из самых консервативных, продолжающих ориентироваться на алфавитно-цифровое описание и одновременное распространение информации в одном и том же виде как по электронной почте, так и по IP-соединениям, в частности по HTTP. В отличие от SovamTeleport, где есть группа разработчиков, или Demos, в Relcom за информационную службу никто персонально не отвечает. Обязанности размазаны по большому кругу сотрудников, которые занимаются еще и другими не менее ответственными делами: администрируют сеть, программируют, ведут базы данных и т.п. Пока не ясно как велика должна быть информационная служба, но опыт наших западных коллег говорит о том, что ее сотрудники должны заниматься только этим, и ни чем иным, только в этом случае служба будет эффективной. Последняя служба, о которой хочется рассказать, служба RoSprint. Информационная служба этой сети не выделяется из общей череды других систем подобного рода, но при отсутствии достаточно полного объема информации о Sprint появление Web-сервера, который рассказал в общих чертах о сети и ее технологии - уже довольно знаменательное событие. Кроме того, информационная служба RoSprint выпускает электронный бюллетень размещает на своем сервере в открытом доступе. При этом стоит принять во внимание, что выпуски бюллетеня носят скорее рекламный характер, но это тоже пока интересно. Завершая описание отечественных служб, обратим еще раз внимание на то, что они только зарождаются, информация на них практически отсутствует, и знакомство с ними носит скорее исследовательский характер, чем реальное использование в своей повсеместной практике. Но следует помнить, что развитие аналогичного спектра услуг на западе произошло в течение года-полутора, буквально на наших глазах, и наши специалисты в этом плане не уступают своим зарубежным коллегам. Будем надеяться, что в конце 1996 года можно будет уже перейти к содержательному анализу информационных служб российского сектора Internet. |
Наталья Сергеева -- сотрудник РНЦ "Курчатовский Институт" (Москва).
