Расширяемость SQL Server 2005 Integration Services позволяет решать необычные задачи
В версии SQL Server 2005 самым существенным изменениям подверглись службы Data Transformation Services (DTS), ныне переименованные в SQL Server 2005 Integration Services (SSIS). Как мощное средство извлечения, преобразования и загрузки данных, SSIS обладает высокой производительностью, большим каталогом динамических компонентов, продуманной моделью развертывания, а также гибкостью и расширяемостью. Расширяемость является отличительной чертой продуктов Microsoft, и компания остается верна стратегии построения надежных платформ, отвечающих основным потребностям пользователей, с возможностью расширения для решения более специализированных задач. Если вы вплотную подошли к оценке перспектив развертывания SQL Server 2005, и в частности SSIS, на своем предприятии, то вам следует знать, о какой расширяемости платформы здесь идет речь.
В этой статье мы на конкретном примере рассмотрим процесс создания, установки и тестирования нестандартного соединения для работы с исходными данными в SSIS, который может осуществлять разбор данных файлов журнала Internet Information Server (IIS). Благодаря нестандартному компоненту пакет SSIS рассматривает файл журнала IIS в качестве источника данных, поэтому преобразует, а затем перенаправляет его содержимое в место назначения. Причем этот нестандартный компонент для работы с исходными данными создать на удивление легко.
Нужно иметь в виду, что, когда мы разрабатывали и тестировали приведенный в статье пример, последней версией SQL Server 2005 была Beta 2 October Community Technology Preview (IDW 9). Эта стадия разработки характеризуется почти полной готовностью продукта, за исключением некоторых деталей, таких как объекты со старыми именами DTS, которые к моменту выпуска финальной версии еще могут измениться. И хотя наш пример будет компилироваться и исполняться на последующих бета-версиях и в финальном продукте, скорее всего, некоторые существенные изменения, вносимые Microsoft, могут проявить себя неожиданным образом, как это было в SSIS между Beta 1 и Beta 2.
Нестандартный источник данных
Источник данных — это адаптер SSIS, который загружает информацию в процесс обработки данных. SSIS позволяет разработать нестандартный компонент, который можно подключить к уникальному источнику или целевому файлу, а также использовать для выполнения специфических задач по преобразованию данных. Можно разработать нестандартный компонент для подсоединения к источнику данных, к которому нельзя получить доступ посредством существующих адаптеров данных или выполнить разбор данных и реализовать логику в сценарии на этапе извлечения данных.
В последнее время Microsoft придерживается такой тактики совершенствования продуктов, при которой сами пользователи и независимые разработчики имеют возможность расширять базовый продукт за счет собственных новаций. Несмотря на то что нестандартные компоненты можно было создавать и в DTS, это было непросто. Более того, большинство пакетов основывалось на объемных сценариях, выполняющих сложные операции. При наличии SSIS создавать нестандартные компоненты становится проще, необходимость написания сценариев сокращается радикально, а производительность и надежность построенных решений возрастают.
Создаем компонент
Наш пример нестандартного соединения выполняет разбор по столбцам содержимого журнала IIS по умолчанию, с использованием выходного буфера SSIS, что дает пакету возможность отправить журнал в базу данных, Excel или любой другой целевой компонент. Согласно настройкам по умолчанию, в журнале IIS фигурируют имена различных полей — время запроса, искомый IP-адрес, метод, единый индикатор ресурса (Uniform Resource Indicator, URI) и код статуса — в четвертой строке файла. Те, кто пытался разобраться в журнале, используя стандартный текстовый адаптер, знают, насколько неуклюжим может быть форматирование, поскольку информация разделена пробелами, а данные в строке URI непредсказуемы. Хотя осуществить разбор данных в журнале можно с помощью других средств, этот тип файлов подходит для нашего примера.
Нестандартный компонент создается в виде сборки .NET, которая является дочерней по отношению к базовому классу Microsoft. SqlServer.DTS.Pipeline.PipelineComponent. Этот базовый класс определяет методы, к которым будет обращаться SSIS для управления задачей Data Flow. В дополнительном компоненте предусмотрена безопасная замена (и игнорирование) любых методов, необходимых для выполнения задачи. Базовый класс PipelineComponent устроен так, что при отсутствии замены метода вызовы обрабатываются его механизмами по умолчанию.
В интерфейсе PipelineComponent создаются компонент источника, компонент преобразования и компонент назначения. Несмотря на то что компоненты играют разные роли в Data Flow, они выглядят одинаково; отличие заключается в функциях, выбираемых для реализации. У компонента источника (компонента для работы с исходными данными) есть выходные данные, у компонента назначения есть входные данные, а у компонента преобразования есть и то и другое плюс логика преобразования данных между вводом и выводом. Нужно только указать SSIS, к какому этапу обработки относится компонент.
Этап подготовки мы начнем с создания в Visual Studio 2005 нового проекта Class Library. Поскольку имя проекта будет именем по умолчанию для создаваемой сборки, следует выбрать имя, которое отражает сущность компонента. По неписаному правилу в конец имени компонента добавляется Src (исходный) или Dest (целевой), в зависимости от функции компонента. В нашем примере создается проект с именем IisLogFileSrc.
Следующий шаг — добавление в проект ссылок, указывающих Visual Studio, где искать объекты SQL Server, с которыми мы будем работать. На вкладке .NET результирующего диалогового окна следует выбрать четыре компонента: Microsoft.SqlServer.DTSPipelineWrap, Microsoft.SQLServer.DTSRuntimeWrap, Microsoft.SQLServer.ManagedDTS и Microsoft.SqlServer.PipelineHost.
Когда запускается проект, Visual Studio автоматически создает начальный класс (возможно, с именем Class1 — имя класса не имеет значения). Сначала, чтобы указать компилятору, какие будут использоваться ссылки, мы задействуем простое для запоминания предложение using, как показано в коде на C# в листинге 1. Необходимо применить предложение using для вышеназванных компонентов Pipeline и Runtime, и, поскольку мы будем считывать данные из файла, следует добавить System.IO.
Также мы должны немного изменить файл AssemblyInfo. Этот файл, как можно догадаться по его имени, дает компилятору дополнительную информацию о сборке через атрибуты. По умолчанию каждый раз, когда мы строим компонент, Visual Studio создает его новую версию. Но нам это не нужно, так как компонент регистрируется в SSIS с конкретной версией, поэтому мы заменяем значение по умолчанию атрибута AssemblyVersion (1.0.?) на конкретную версию, например 1.0.0.0.
Наконец, желательно добавить наш нестандартный компонент для работы с исходными данными в глобальный кэш сборок (Global Assembly Cache, GAC), для чего необходимо присвоить ему полноценное имя. Проще всего это сделать с помощью утилиты .NET Framework 2.0 SDK Strong Name Utility (sn.exe). Переключатель -k позволяет создать ключевой файл, который становится частью проекта и должен быть помещен в папку проекта. Чтобы передать компилятору имя ключевого файла, следует использовать атрибут AssemblyKeyFile.
Возвращаясь к классу Class1, мы должны создать атрибут класса, который сообщает Business Intelligence Development Studio о нашем компоненте. В листинге 1 атрибут содержит минимальную информацию: имя компонента и тип компонента. Эту информацию можно пополнить, в том числе добавив пиктограмму, которая будет появляться в панели инструментов Development Studio.
В заключительных строках кода листинга 1 объявляется о том, что наш класс является дочерним для класса PipelineComponent. Это избавляет нас от необходимости реализовывать каждый метод, как того требует интерфейс, и все вызовы, которые мы не обрабатываем, будет получать базовый класс. Базовый класс также позволяет нам воспользоваться IntelliSense, которая автоматически создает сигнатуры для выбираемых нами методов.
На старт! Теперь мы начинаем добавлять в наш класс методы, которые будут перехватывать вызовы от SSIS Data Flow. Первый метод, ProvideComponentProperties (см. листинг 2), описывает наш компонент дизайнеру пакетов SSIS. В листинге 2 показан вызов от дизайнера, в котором запрашивается, какие входные данные, выходные данные, соединения и другие свойства необходимы компоненту для выполнения работы. Дизайнер пакетов SSIS добавляет поля на страницы свойств компонента, предоставляя пользователю возможность вводить эту информацию. Ввиду простоты нашего компонента нам понадобятся только данные о соединении и данные, относящиеся к выводу.
В соответствии с кодом листинга 2 SSIS не сохраняет предыдущую информацию о компоненте. В целях предосторожности на этом шаге стирается вся предыдущая информация, относящаяся к выводу и соединениям, а также предотвращается дублирование данных, если компонент уже инициализировался. Далее в набор данных, относящихся к выводу, добавляется выходной объект. Поскольку в нашем примере только один выходной объект, мы можем назвать его Output. Чтобы определить в SSIS внешний вид выходного объекта, код добавляет в объект столбцы, представляющие столбцы по умолчанию файла журнала IIS, который мы будем разбирать. Для простоты все поля в примере имеют строковый тип.
В заключительной части кода в SSIS передается информация о том, что компоненту необходимо соединение. Компоненту требуется файловое соединение с журналом, который мы будем читать, однако, как ни странно, в SSIS не предусмотрен способ задания типа соединения, необходимого компоненту. Мы назовем его File Connection. При желании получить более надежную реализацию проекта мы должны были бы убедиться, что соединение, которое компонент устанавливает в процессе работы, имеет подходящий тип.
Внимание! Второй этап в создании компонента состоит в формировании запросов SSIS на установление соединения перед исполнением пакета и на освобождение соединения в процессе очистки после исполнения. Как показано в листинге 3, запрос на установление соединения и получение запрошенного файлового соединения осуществляется путем обращения к менеджеру соединений. В коде содержится пара строк, которые позволяют ему найти нужный объект, поэтому мы получаем простое имя файла, которое пользователь указал в дизайнере пакетов. Для открытия файла используется метод AcquireConnections, а для закрытия — метод ReleaseConnections, при этом мы сохраняем в частной переменной дескриптор файла, чтобы тот был доступен на этапе исполнения.
Марш! На третьем и заключительном этапе мы обеспечиваем все, что связано с выводом данных, применяя метод PrimeOutput, как показано в листинге 4. К этому моменту SSIS создает буфер для каждого канала вывода, который мы установили ранее, и теперь передает эти буферы в PrimeOutput в виде массива. Поскольку в нашем примере выходные данные генерируются только по одному каналу, в массиве имеется только один буферный элемент. Метод PrimeOutput заполняет буфер данными и закрывает его.
Поскольку на предыдущем этапе мы воспользовались дескриптором файла, компоненту остается только считать каждую строку файла и произвести разбор нужной информации. Вверху файла журнала IIS предусмотрена секция заголовков, поэтому мы пропускаем все строки, начинающиеся с символа #, который обозначает заголовок. Поля данных в строках, которые являются записями в журнале, разделены пробелами, что способствует более легкому разбору. Если пробелы отсутствуют, разбор данных невозможен, но с тестовыми файлами, которые мы использовали в этом примере, затруднений не возникло.
Как только компонент разобрал данные и готов добавить их в буфер, он вызывает метод AddRow и задает каждое значение. В листинге 4 показана мера предосторожности, состоящая в обрезании данных поля по определенной ширине столбца выходных данных. Таким образом предотвращается переполнение, которое может привести к ошибке во время исполнения пакета. Ввиду того что администраторы иногда заполняют журналы дополнительной информацией (а строка URI может быть очень длинной), этот прием повышает надежность проекта даже тогда, когда вы абсолютно уверены в форматах своих файлов.
Наконец, когда код листинга 4 достигает конца файла журнала и все данные записаны в буфер, код применяет к буферу метод SetEndOfRowset, сообщая SSIS, что работа закончена. Теперь код может закрыть компонент и очистить буфер.
Скрытые препятствия. Несмотря на простоту нашего примера, чтобы привести его в рабочее состояние, потребуются еще некоторые усилия. По сведениям Microsoft, на этапе метода PrimeOutput нельзя быть уверенным, что столбцы идут в том же порядке, в каком вы расположили их на этапе использования ProvideComponentProperties. Дело в том, что у менеджера буфера есть право вставлять заполнители вместо лишних столбцов, которые в процессе преобразования данных могут сливаться. Созданный компонент может и «не знать» об этих дополнительных заполнителях. Кроме того, менеджер буфера в состоянии изменить порядок столбцов для лучшей компоновки страниц памяти. Microsoft предлагает не надеяться на то, что порядок столбцов будет таким, каким вы его определили, а применить метод PreExecute и использовать метод менеджера буфера FindColumnByLineageID для уточнения местонахождения столбцов, построив массив, который можно применять в методе PrimeOutput для поиска индекса столбца по имени. Мы так и делали, но в целях простоты и экономии места в примере этого не приводим.
Устанавливаем компонент
Компонент легко устанавливается для дальнейшего использования Business Intelligence Development Studio. Сначала требуется скопировать созданную сборку в ту папку, где хранятся конвейерные компоненты SSIS. Затем нужно добавить сборку в глобальный кэш GAC. Напоследок можно добавить компонент в панель инструментов Development Studio, где его сможет выбирать пользователь. Каждый раз, когда в компонент вносятся изменения, следует скопировать файл, удалить предыдущую версию из GAC и установить в GAC новую версию компонента, поэтому мы рекомендуем для всех этих действий создать пакетный файл. В листинге 5 показан пример такого пакетного файла, который использовался в процессе работы.
|
| Экран 1. Расположение в меню пункта Choose Toolbox Items |
Чтобы добавить компонент в панель инструментов, нужно открыть меню Tools и выделить пункт Choose Toolbox Items. Откроется диалоговое окно, изображенное на экране 1. Компонент должен появиться на вкладке Data Flow Items, как показано на экране 2. Необходимо выделить компонент и щелкнуть OK, после чего он появится в списке инструментов в секции Data Flow Sources.
|
| Экран 2. Отображение компонента с именем IisLogFileSrc на вкладке Data Flow Items |
Для обновления компонента после модернизации нужно закрыть все использующие его приложения, снова запустить установочный пакетный файл и открыть то же приложение. Данное приложение должно автоматически получить новую версию компонента. Сбой при выполнении этой процедуры у нас возник только однажды — когда мы изменили имя класса компонента. В силу этого изменения Business Intelligence Development Studio воспринял наш компонент как совершенно другой (хотя и с тем же именем). Нам пришлось удалить старый компонент из панели инструментов и добавить новый. Кроме того, потребовалось удалить компонент из всех проектов и добавить его заново.
Создаем тестовый пакет
Для того чтобы протестировать образец, нужно создать новый проект типа Data Transformation Project в Business Intelligence Development Studio. Сначала на экране появляется чистый лист Control Flow, в который требуется добавить задачу Data Flow Task. Нужно дважды щелкнуть на этой задаче — откроется чистый лист Data Flow. Теперь следует захватить новый компонент для работы с исходными данными в панели инструментов и перенести его на пустое место.
Затем File Connection должен сообщить компоненту, где искать файл журнала, который предстоит импортировать. Нужно дважды щелкнуть на секции Connections внизу листа Data Flow и выделить New File Connection. Будьте внимательны, чтобы невзначай не воспользоваться пунктом New Flat File Connection: это соединение другого типа, предназначенное для компонента Flat File Source. Для файлового соединения в нашем примере тип использования следует установить в значение Existing File. После этого можно добавить импортируемый файл журнала IIS. Обычно журнальные файлы IIS расположены в папке C:WINDOWSsystem32Logfiles на той системе, где установлен IIS. Ясно, что Web-сервер должен иметь какой-то контент и трафик, чтобы сгенерировать журналы. Если ничего такого нет, можно сформировать несколько файлов на основе описанного выше формата.
Теперь требуется добавить в компонент новое соединение. Нужно щелкнуть правой кнопкой на компоненте и выделить Edit в контекстном меню. На экране появится редактор, и первая вкладка должна называться Connection Managers. Соединение, которое компонент запросил в методе ProvideComponentProperties, должно на ней отобразиться, а в поле со списком можно будет выбрать вновь созданное файловое соединение.
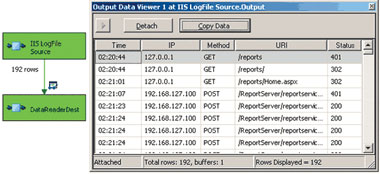
Последний шаг — объект назначения. Тестируя компоненты с исходными данными, мы пользовались DataReader Destination, средством аккумулирования выходных данных, которое позволяет легко протестировать компонент. Конечно, можно было бы направить выходные данные в SQL Server, Excel или в какое-нибудь другое целевое приложение, но нужно иметь в виду, что, как правило, другие целевые приложения требуют дополнительной настройки. Чтобы воспользоваться DataReader Destination, необходимо просто захватить выходной объект источника и перенести его на целевой объект. Затем нужно отредактировать целевой объект и выбрать столбцы, соответствующие имеющимся выходным данным, чтобы не вызвать ошибок SSIS из-за неиспользуемых столбцов. Рекомендуется также добавить к соединению средство просмотра данных Data Viewer, как показано на экране 3, чтобы иметь возможность убедиться, что источник данных работает. Для этого следует щелкнуть правой кнопкой на соединении, выделить Data Viewers и добавить источник данных.
|
| Экран 3. Добавленное к компоненту средство просмотра данных показывает, что все работает |
Теперь пакет должен быть полностью готов к исполнению. После того как мы щелкнем зеленую стрелку для компиляции и исполнения в отладчике, должен появиться Data Viewer и отобразить данные файла журнала IIS в виде таблицы с сеткой. Более подробную информацию о разработке дополнительных компонентов для работы с исходными данными можно найти в разделе «Creating a Source Component» в SQL Server 2005 Books Online.
Дуглас Макдауэлл - Преподаватель, менеджер проектов по Business Intelligence в Solid Quality Learning. Имеет звания MCSE, MCDBA и MCT. douglas@SolidQualityLearning.com
Джей Хэкни - Старший консультант в Intellinet, занимается проектированием решений BI на базе технологий SQL Server 2005 и Microsoft .NET. Имеет сертификаты MCDBA и MCSD. jayh@intellinet.co
Первый нестандартный компонент для работы с источником данных
На этапе начального бета-тестирования SQL Server 2005 команда разработчиков SQL Server 2005 Integration Services (SSIS) подыскивала сложные проблемы, с помощью которых можно было бы протестировать SSIS. И вот вместе с нашим коллегой Эриком Веерманом мы предоставили команде в качестве источника данных чрезвычайно мудреный текстовый файл. Это был журнальный файл телефонного узла размером около 5 Мбайт, имевший более пяти форматов многострочной записи. В нашем приложении, построенном на основе SQL Server 2000 Data Transformation Services (DTS), эти журнальные файлы импортировались в одну консолидированную таблицу, которая содержала более 100 столбцов и использовала для разбора записей сценарий ActiveX, состоящий из 500 строк. Три механизма разбивали данные на выделенные таблицы, в зависимости от типа записей. Обработка одного файла и отправка его в базу данных занимала 40 секунд, и мы применяли нестандартный процесс, чтобы справиться с количеством текстовых файлов в исходной папке. Рабочая нагрузка доходила до 1000 файлов в день.
Специалисты команды SSIS тщательно исследовали файловый формат телефонного узла и пришли к выводу, что он не подходит ни к одному из существующих адаптеров данных. Таким образом, мы познакомились с концепцией нестандартного соединения для работы с исходными данными. Команда работала над этой проблемой в отсутствие документации, поэтому одному из главных членов команды, Джиму Хоуи, пришлось повозиться с идеями и деталями компонента, и со своей задачей он успешно справился. В результате появилось превосходное решение для импорта и разбора журнальных файлов. Более того, команда разработчиков SSIS предусмотрела возможность использования встроенного цикла ForEach для массовой обработки журнальных файлов, содержащихся в папке, без утомительного написания сценариев.
Мы переместили сложную логику разбора данных из ActiveX в готовый .NET-компонент и таким образом сохранили вложенные при декодировании файла усилия, обеспечив их использование на более высоком уровне. Применяя логику разбора, компонент для работы с исходными данными различал три типа записей и создавал три выходных потока, так что данные могли непосредственно вставляться в три целевые таблицы, минуя дорогостоящий промежуточный шаг, необходимый в DTS. В итоге число операций импорта сократилось в 12 раз на один файл и в 17 раз при одновременном импорте многих файлов. Это впечатляющее достижение имело место до выпуска первой бета-версии SSIS и до того, как команда закончила все настройки производительности продукта.
Поначалу мы были даже несколько ошеломлены таким ростом производительности, но позже, оглядываясь назад, поняли, в чем дело. В дополнительном компоненте для работы с исходными данными произошел существенный сдвиг в архитектуре, при котором логика преобразования данных переместилась в скомпилированный компонент, не имеющий дополнительных издержек, связанных с созданием сценариев ActiveX. Кроме того, сближение преобразования данных с источником данных сократило количество обращений к данным. Сочетание высокой производительности с гибкостью решения делает нестандартный компонент для работы с исходными данными весьма эффективным средством.