Компьютеры MPP-архитектуры на базе x86-совместимых микропроцессоров – если, конечно, не считать таковыми Itanium 2 – сегодня предлагает только Cray. И микропроцессоры эти – не от Intel. В Cray выбрали процессоры AMD Opteron. В чем причины такого выбора? Проанализируем архитектуру суперкомпьютеров Cray XD1 и XT3 на базе Opteron, сопоставив эти системы с массовым параллелизмом с альтернативными платформами, в первую очередь, с кластерными системами на базе аналогичных процессоров, которые сегодня захватили главенствующие высоты на рынке многопроцессорных вычислительных систем с распределенной памятью.

Все больше ведущих производителей компьютерных систем признает: 64-разрядные процессоры AMD, оказавшиеся очень удачными, являются привлекательной платформой для многопроцессорных серверов, как, впрочем, и высокопроизводительных рабочих станций. Использование процессоров Opteron в подобных системах позволяет достичь высокой производительности при умеренной цене.
В числе таких производителей можно упомянуть компании IBM и Hewlett-Packard. Но, пожалуй, самыми яркими примерами служат компания Sun Microsystems, которая выпускает серверы Fire V20z/V40z на базе процессоров Opteron (будущее линейки собственных высокопроизводительных микропроцессоров UltraSPARC остается туманным), а также операционная система Solaris для этой платформы [1], и, как это ни покажется кому-то странным, Cray, специализирующаяся на суперкомпьютерах. Cray выпускает вычислительные системы разной архитектуры – и векторные (Cray X1), и многопоточные (MTA-1), и с массовым параллелизмом (ранее это были Cray T3E на базе процессоров Alpha). Системы Сray T3E, похоже, стали даже популярнее векторных систем этой компании.
Что же касается собственных векторных систем Cray, то они уступают по своим возможностям суперкомпьютерам NEC. Сегодня Cray – уже не тот флагман векторных суперкомпьютеров, как в прежние годы, и успехи компании на рынке во многом могут зависеть от привлекательности МРР-систем на базе Opteron. (Будущие векторные системы Cray X1E, вероятно, также будут уступать последнему поколению векторных компьютеров NEC SX-8.)
Почему Opteron?
Выбор микропроцессоров, пригодных для построения высокопроизводительных вычислительных систем, к сегодняшнему дню весьма сузился. HP Alpha уже снимаются с производства, PA-RISC, UltraSPARC и SGI R1x000 не отличаются столь уж высокой производительностью, и, вероятно, уже никогда не вернутся в верхние строчки рейтингов.
Остается IBM Power5, мировой лидер по производительности с плавающей запятой. Он очень дорогой, в том числе и из-за огромного внешнего кэша. Остается PowerPC 970fx; у него тактовая частота повыше, чем у Power5, но на частоте 2,5 ГГц процессорам PowerPC требуется уже жидкостное охлаждение, и неясно, насколько снижается его производительность из-за уменьшения емкости кэша по сравнению с «прототипом» Power 4.
Остается Itanium 2, однако он тоже имеет высокое тепловыделение. Кстати, тот факт, что RISC-процессор Power5 опередил по производительности с плавающей запятой (по пиковой производительности, на тестах SPECfp2000) пост-RISC архитектуру в лице Itanium 2, отражает новые реалии микропроцессорного мира. Сейчас уже некоторые специалисты – в том числе представители Intel – заявляют, что важна не архитектура как таковая (CISC, RISC или пост-RISC), а микроархитектурная реализация.
Наметившееся в последнее время в силу известных технологических проблем существенное замедление скорости роста тактовой частоты процессоров Pentium 4/Xeon может привести к увеличению разрыва в производительности Itanium 2 и Pentium 4/Xeon. Рост производительности процессоров семейства Itanium может осуществляться не столько за счет роста тактовой частоты, сколько за счет развития микроархитектуры (в том числе за счет увеличения емкости кэш-памяти). Кроме того, почти все ведущие производители – в частности, Intel, AMD, IBM и Sun Microsystems – предлагают или намереваются предложить в будущем многоядерные процессоры.
Intel под давлением успехов Opteron и Athlon64 ускорила выпуск собственных процессоров Xeon Nocona с архитектурой EM64T, практически совпадающей с предложенной ранее в Opteron. Однако Nocona также обладает высоким тепловыделением. Кроме того, хотя Nocona и может работать с эффективной частотой шины FSB в 800 МГц, во всех двухпроцессорных системах на базе Xeon процессоры разделяют FSB, вследствие чего на ней возникают конфликты по доступу в оперативную память, и производительность падает.
Процессоры Opteron, напротив, имеют собственный независимый доступ в оперативную память, контроллер памяти интегрирован в процессор. Поэтому Opteron идеально подходит для многопроцессорных серверов – не только с двумя, но и с четырьмя и восемью процессорами [2].
Учитывая традиционно более низкую стоимость продукции AMD, процессоры Opteron привлекательны и по отношению стоимость/производительность. Конечно, 32-разрядные процессоры Xeon дешевле 64-разрядных Nocona, но 32 разрядов для сложных вычислительных задач сегодня зачастую оказывается недостаточно. Поэтому выбор Cray вполне понятен.
Основным недостатком Opteron является, по всей видимости, низкая пиковая производительность по сравнению с конкурентами – 4,8 GFLOPS для Opteron/2,4 ГГц против 7,2 GFLOPS для Nocona/3,6 ГГц, 6 GFLOPS для Itanium 2/1,5 ГГц и 10 GFLOPS у PowerPC 970fx/2,5 ГГц. Приложения, способные достигнуть производительности, близкой к пиковой, – например, Linpack на длинных векторах, – выполняются на альтернативных платформах существенно быстрее. (Отметим, что приведенные данные о пиковой производительности относятся, как это принято, к 64-разрядному представлению чисел с плавающей запятой.)
Конечно, сказанное является лишь неким усреднением, и конкретные приложения могут показать совершенно иную картину. Так, на приложениях NASTRAN процессоры Itanium 2 существенно опережают Opteron (www.mscsoftware.com/support/ prod_support/nastran/performance/v04_sngl.cfm).
Компьютеры на базе Nocona уже поддерживают шину PCI Express, позволяя достигать более высокой скорости и более низких задержек при вводе и выводе, в том числе, при соединении узлов кластеров. Компьютеры на базе Opteron также будут поддерживать PCI Express, как только появятся наборы микросхем, содержащих мосты PCI Express с каналами HyperTransport. Пример набора микросхем SiS756 для Athlon64 говорит о том, что это может быть делом уже ближайшего будущего.
C другой стороны, применение HyperTransport в Opteron позволило Cray предложить более эффективное с точки зрения производительности решение без использования PCI. Действительно, пропускная способность HyperTransport равна 3,2 Гбайт/с, а PCI-X – не превосходит 1 Гбайт/с, что ограничивает скорость передачи данных между узлами кластеров. PCI Express х4 имеет пропускную способность 2 Гбайт/с, но PCI Express x8 – уже 4 Гбайт/с. Кроме того, в PCI Express задержки ниже, чем в PCI-X, поэтому PCI Express в состоянии конкурировать с HyperTransport с точки зрения эффективности при соединении узлов кластера. Однако HyperTransport также продолжает развиваться; планируются новые ее версии с более высокой производительностью.
Cray в [3] для демонстрации преимуществ Opteron проводит сопоставление микропроцессоров Xeon/3,2 ГГц (с шиной FSB 533 МГц), Itanium 2/1,3 ГГц и Opteron 248/2,2 ГГц по данным на январь 2004 года. Приводятся, в частности, рейтинги SPECint_2000_rate, SPECfp_2000_rate и задержки по обращению в память. Opteron почти во всем оказался лучше, только на SPECfp_2000_rate процессор Itanium 2 побыстрее (36,9 против 32,8). Пожалуй, показатели SPECfp_2000/SPECint_2000 все-таки «первичнее». В то же время задержки по обращению к оперативной памяти важнее для приложений, характеризующихся случайным обращением в память; для обюемных вычислений обычно важнее пропускная способность памяти.
Power5 сумел превзойти своих конкурентов на задачах с плавающей запятой, но 64-разрядный процессор Opteron даже на плавающей запятой отстает от него не слишком много, а на целочисленных приложениях – опережает, и при этом имеет более низкое тепловыделение.
Сбалансированные компьютеры
Компания OctigaBay разработала новое межсоединение RapidArray и основанные на нем компьютеры МРР-архитектуры OctigaBay 12K. Их представление состоялось на международной конференции Supercomputing 2003 в конце 2003 года; позднее Сray приобрела эту компанию, и теперь предлагает OctigaBay 12K под маркой Cray XD1.
Характеризуя архитектуру XD1, в Cray подчеркивают ее сбалансированность, сравнивая с кластерами на базе небольших серверов и крупными SMP-системами. Для обозначения архитектуры кластеров в Cray используют выражение I/O connected («связанные через ввод/вывод»), подчеркивая наличие каналов связи между узлами кластеров, работающих через шины PCI. Большие SMP-системы при этом называют «связанными через память» (memory connected), а архитектуру XD1 – «связанной напрямую» (direct connected), поскольку межсоединение Rapid Array подсоединяется напрямую к шинам HyperTransport, минуя PCI.
Сравнительные характеристики этих архитектур представлены в таблице, которая основана на [3]. В таблице приведены данные для кластеров с узлами на базе Xeon/3,2 ГГц, связанными каналами Gigabit Ethernet, для SMP-cерверов IBM pSeries на базе Power4/1,7 ГГц, а также для Cray XD1. (Однако, в качестве пиковой величины производительности Xeon с двойной точностью в таблице приводится удвоенный показатель – 6,4 GFLOPS; хотя умножение в Xeon с ядром Pentium 4 не было не полностью конвейеризовано – т.е. результат получался не на каждом такте, – в первом приближении этим обычно пренебрегают.)
Для сравнения архитектур с точки зрения их сбалансированности Cray предлагает использовать следующие показатели:
- производительность в расчете на один процессор, GFLOPS;
- пропускная способность памяти (Гбайт/с) в расчете на 1 GFLOPS;
- пропускная способность межсоединения (Гбайт/с) в расчете на 1 GFLOPS;
- задержка межсоединения;
- пропускная способность ввода-вывода (Гбайт/с) в расчете на 1 GFLOPS;
- наличие средств поддержки синхронизации.
По этим показателям кластеры в Cray считают несбалансированными, а SMP-системы и XD1 – сбалансированными. SMP-системы масштабируют обычно не более чем до 64 процессоров, а их стоимость в пять-десять раз превосходит стоимость кластеров. Однако на реальных сложных вычислительных задачах производительность SMP-систем может оказаться выше вследствие более «слабых» межсоединений узлов кластеров и с точки зрения пропускной способности, и с точки зрения задержек по сравнению с коммуникациями через общую память в SMP-серверах. Cray XD1 является, с одной стороны, масштабируемым (до тысяч процессоров), с другой стороны, его стоимость относительно невелика из-за широкого применения дешевых массовых компонентов.
К этому анализу «от Cray» представляется необходимым сделать два замечания. Во-первых, можно рассмотреть не SMP, а ccNUMA. Такие архитектуры обладают гораздо более высокой масштабируемостью – до 512 процессоров для сегодняшних лидеров «движения ccNUMA» SGI Altix [4]. Впрочем, в MPP-системах и в кластерах процессоров может быть гораздо больше. Во-вторых, следовало бы рассматривать кластеры с современными межсоединениями (например, Infiniband), имеющими на порядок более высокую пропускную способность и на порядок более низкие задержки. Выводы Cray с учетом этих замечаний не утратят своей силы, но соотношения рассматриваемых параметров будут иными.
Архитектура Cray XD1
Основу архитектуры Cray XD1 формируют двухпроцессорные SMP-лезвия (рис. 1). Межсоединение RapidArray подключается к процессорам Opteron, имеющим тактовую частоту не менее 2 ГГц, напрямую через шину HyperTransport, а не через PCI. Собственно, подобные специально сконструированные схемы соединения и отличают «уникальные» МРР-системы от кластеров, базирующихся на «общеупотребительных» (т.е. доступных на рынке) межсоединений наподобие Infiniband, Quadrics QsNet, Myrinet и т.п.
К шине HyperTransport подсоединяются коммуникационные процессоры RapidArray, которые имеют два канала с пропускной способностью по 2 Гбайт/с в каждом направлении к «коммутирующей фабрике» и от нее, а также канал с пропускной способностью 3,2 Гбайт/с к специализированной программируемой логической матрице (FPGA), служащей для ускорения некоторых специализированных приложений. В качестве FPGA-сопроцессора используется Xilinx Virtex II Pro (шесть матриц на сопроцессор).
Процессоры RapidArray не являются узким местом для пропускной способности передачи данных к Opteron: ее ограничивают возможности HyperTransport. Межсоединение RapidArray обеспечивает коммутацию с высокой суммарной пропускной способностью и задержками на уровне 1 микросекунды; применение коммутатора дает вклад в задержку всего в 200 наносекунд.
Каждое лезвие имеет четыре канала к межсоединению RapidArray с суммарной пропускной способностью 8 Гбайт/с. В конструктиве шасси размещается шесть SMP-лезвий и встроенный внутренний коммутатор. Всего в шасси 24 канала RapidArray подсоединены к 12 процессорам, и еще 24 канала используются для связи между шасси, а пропускная способность внутренней коммутирующей фабрики равна соответственно 96 Гбайт/с.
Основные функции ввода-вывода поддерживаются, по имеющимся у нас данным, на уровне SMP-лезвий, имеющих четыре слота PCI-X и поддерживающих жесткие диски с протоколом Serial ATA. Шасси могут также иметь порты Gigabit Ethernet или Fibre Channel. В архитектуре представлен еще и канал High-Speed
I/O, однако о соответствующем слоте на момент подготовки статьи в Cray никаких комментариев не давали.
Конструктивом предусмотрены многопортовые коннекторы, соединяющие шасси между собой. Это позволяет строить МРР-конфигурации, содержащие до 300 процессоров при связывании 25 шасси напрямую, без внешнего коммутатора; при использовании внешних коммутаторов теоретически можно построить систему, содержащую тысячи процессоров (www.cray.com/media/articles/HPCWireNov18.pdf).
В Сray XD1 возможно построение различных топологий. Для приложений, выполнение которых характеризуется обменами данными с соседними узлами, эффективными могут оказаться топологии трехмерного тора или решетки. Наивысшую пропускную способность обеспечивает топология «толстого дерева» (т.е. дерева с несколькими корнями); схожая топология реализована в SGI Altix.
Производительность приложений, связанных с большим обюемом вычислений, принципиальным образом зависит от средств разработки. В Cray XD1/RAP имеется аппаратная поддержка средств MPI, shmem, Global Array, операций gather/scatter, broadcast/multicast, одностороннего асинхронного доступа в память. Наконец, имеется адаптивная обработка коротких и длинных сообщений: для коротких сообщений оптимизация уменьшает задержку, для длинных сообщений – увеличивает пропускную способность. Процессоры RapidArray имеют прямой доступ в память, с которой работают процессоры Opteron. Это разгружает центральные процессоры от нагрузки при передаче MPI-сообщений и способствует достижению высокой пропускной способности на уровне MPI.
В [3] Cray приводит графики зависимости пропускной способности от размера сообщений, демонстрирующие преимущества реализаций shmem и MPI в Cray XD1 по сравнению с пользующимися популярностью у создателей кластеров межсоединениями Infiniband, Myrinet и QsNet. Компания приводит и пример реального приложения – моделирование столкновения автомобиля с использованием известного пакета LS-DYNA: достигаемое на Cray XD1 ускорение при разном числе процессоров превосходит достигаемое в кластере на базе микропроцессоров Intel Xeon с межсоединениями Myrinet, Gigabit Ethernet и Fast Ethernet.
Во всех экземплярах ОС Linux, работающих в Cray XD1, используются единые на всю систему часы; точнее говоря, аппаратура осуществляет синхронизацию часов с точностью до 1 микросекунды.
В Cray обратили особое внимание на модернизацию планировщика Linux c целью реализации иного алгоритма синхронизации. Обычный планировщик оптимизирован для работы с интерактивными задачами (например, обработка транзакций). Между тем, при распараллеливании сложных вычислительных задач возникает много синхронизирующихся процессов, каждый из которых делает, грубо говоря, примерно один и тот же обюем работ на «своем» процессоре. Операция наподобие MPI_Barrier может при этом привести к задержкам на всех процессорах в случае, если один из них, получивший запрос на барьер, занят в это время выполнением служебных функций (Cray в качестве оценки подобной задержки приводит значение в 10 миллисекунд).
Этот недостаток в Cray XD1 устранен благодаря синхронизации всех часов: все процессы MPI теперь выполняются в одно и то же время, и служебные функции Linux также выполняются в скоординированные слоты времени. В результате на 64-процессорной системе, если задание генерирует 200 операций MPI_Barrier в секунду, возможно до 50% увеличения производительности. Надо, однако, отметить, что подобная частота выполнения MPI_Barrier представляется весьма высокой.
Реальная тактовая частота используемых процессоров Opteron составляет 2,4 ГГц, чему отвечает пиковая производительность 12-процессорного шасси в 58 GFLOPS. Cray обещает возможности модернизации процессоров в будущем, в том числе с переходом в 2005 году к двухядерным процессорам Opteron, что фактически позволит удвоить число устройств обработки данных.
Вопреки первоначальной информации об использовании в XD1 микропроцессоров Opteron с емкостью кэша в 1,5 Мбайт реальная емкость кэша составила, как и следовало ожидать, «стандартную величину» 1 Мбайт.
По оценкам компании, MPI-задержка вчетверо меньше, чем при использовании Infiniband, и в 30 раз меньше, чем при работе с Gigabit Ethernet. Достигаемая пропускная способность на сообщениях размером от 1 Кбайт оказалась вдвое выше, чем для Infiniband 4х, а на длинных сообщениях – на 60% выше.
Реально достигаемая величина задержки на уровне MPI внутри шасси декларируется на уровне 1,8 микросекунд, а наихудшая величина MPI-задержки в конфигурации, содержащей 324 процессора, и с топологией трехмерного тора, не превосходит 2,5 микросекунд. Автору известно всего три межсоединения, дающие задержку ниже 2 микросекунд – Quadrics QsNet, SGI Altix и Cray RapidArray. Хотя QsNet используется при построении кластеров Beowulf, оно является самым дорогостоящим; сопоставление цен с XD1 еще только предстоит.
Для иллюстрации приведем еще несколько характеристик конфигураций XD1. Шасси XD1, кроме 12 процессоров, может вмещать до 84 Гбайт памяти и 1,5 Тбайт дискового пространства. Стойка XD1 вмещает до 12 шасси, т.е. до 144 вычислительных процессоров с суммарной пиковой производительностью 691 GFLOPS.
«Красный шторм» и «морская звезда»
Интересно, что Cray вела собственные разработки MPP-систем на базе Opteron параллельно с работами, проводившимися в OctigaBay. Соответствующий проект был назван ASCI RedStorm, а разрабатывавшиеся в его рамках компьютеры имели кодовое название Strider. Реализация проекта была разбита на два этапа. Первый этап должен был завершиться в конце 2003 года созданием экспериментальной кластерной системы Strider0 из двухпроцессорных узлов на базе Opteron/2 ГГц.
Второй этап должен был ознаменоваться появлением Strider1 – собственно суперкомпьютера RedStorm, который и был анонсирован в октябре под именем Cray XT3. Эта MPP-система ориентирована на однопроцессорные узлы с применением Opteron с тактовой частотой более 2 ГГц (в настоящее время она равняется 2,4 ГГц) и трехмерное межсоединение SeaStar, так же, как и RapidArray, подсоединяющееся к каналам HyperTransport [6]. Финансирование проекта со стороны Министерства энергетики США должно было составить 93 млн. долл.
Очевидно, проект RedStorm направлен на достижение рекордно высоких показателей производительности. Вряд ли в компании OctigaBay ставили перед собой эту задачу; но так или иначе, разработки двух разных межсоединений, работающих с каналами HyperTransport процессоров Opteron, могут начать конкурировать друг с другом.
Судя по всему, это и заставило Cray приобрести компанию OctigaBay. Однако теперь в распоряжении Cray оказались два близких продукта. При этом Cray XD1 и XT3 выходят на рынок почти одновременно, и если межсоединение SeaStar не будет очень дорогим, как раз и может возникнуть конкуренция, но уже «внутри» Cray. Можно предположить, что системы XT3 ориентированы на наиболее масштабные задачи, поскольку могут содержать от 200 до 30 тыс. процессоров с суммарной производительностью до 144 TFLOPS и межсоединение с суммарной пропускной способностью свыше 100 Тбайт/с. Для конфигураций поменьше можно использовать XD1. Впрочем, диапазоны допустимого числа процессоров у различных конфигураций XT3 и XD1 пересекаются.
Масштабы проекта RedStorm может описать следующее сравнение: МРР-система со сравнимыми характеристиками должна включать 11 тыс. процессоров Opteron с суммарной пиковой производительностью свыше 40 TFLOPS (примерно столько же, сколько у суперкомпьютера NEC Earth Simulator, до последнего времени в течение двух лет возглавлявшего рейтинг Top500). В знаменитой лаборатории Sandia National Lab. уже установлена система с производительностью 10 TFLOPS. Другая известная американская лаборатория, Oak Ridge National Lab., хочет приобрести Cray XT3 с производительностью 20 TFLOPS плюс векторную систему X1E той же производительности, в 2006 году – компьютерную систему Cray производительностью 100 TFLOPS, а в 2007-м – еще один компьютер Cray с пиковой производительностью 250 TFLOPS при 100 TFLOPS на реальных задачах.
Суммарная емкость оперативной памяти в RedStorm должна достигнуть 10 Тбайт, а емкость дискового пространства – 240 Тбайт. Площадь, занимаемая МРР-системой вместе с дисковыми устройствами, составляет около 300 квадратных метров.
Суммарно RedStorm включает 10368 процессоров Opteron, расположенных в 108 стойках вычислительных узлов. Кроме того, имеется 16 стоек для узлов ввода/вывода и сервисных функций, и 16 стоек коммутаторов, разделенных на две группы – «черные» и «красные». 512 процессоров ввода/вывода и сервиса также разбиты на две группы – «черные» и «красные» – по 256 процессоров на группу.
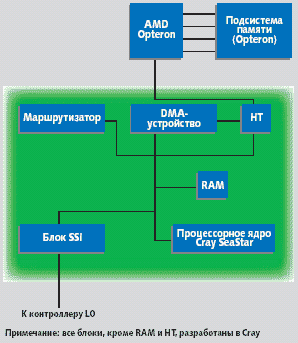
|
| Рис. 2. Структура узла RedStorm |
Общая архитектура узлов RedStorm/XT3 (в терминологии разработчиков XT3 – процессорных элементов) представлена на рис. 2. В межсоединении применяется топология трехмерного тора (ее Cray считает более эффективной, чем «толстое дерево») с двунаправленными каналами, имеющими пиковую пропускную способность по 7,6 Гбайт/с (поддерживаемое значение – свыше 4 Гбайт/с). Для обеспечения этой топологии в XT3 используются разработанные в Сray шестипортовые коммутаторы SeaStar, с суммарной пропускной способностью 45,6 Гбайт/с.
Коммутаторы являются частью микросхем SeaStar, включающих также канал HyperTransport, сервисный порт SSI (подсоединяется к отдельной сети управления), устройство прямого доступа в память DMA и процессор, отвечающий за управление и коммуникации. Для повышения эффективности работы таблицы маршрутизации могут динамически изменяться. В протоколе каналов связи используются схемы CRC и аппаратная поддержка повторных передач при сбоях. DMA работает совместно с процессором PowerPC 440 и позволяет разгрузить процессоры Opteron от задач передачи данных. XT3 включает в себя вычислительные серверы-лезвия (по 4 процессорных элемента на лезвие, с одним процессором Opteron и оперативной памятью емкостью до 8 Гбайт на процессорный элемент, с поддержкой ECC и технологии Chipkill) и сервисные лезвия (по два сервисных процессорных элемента, с поддержкой PCI-X/133 МГц).
В подсистеме ввода/вывода применяются дисковые массивы, подсоединяемые к соответствующим процессорным элементам по каналам Fibre Channel. Лезвия, в свою очередь, помещаются в конструктиве стойки до 96 процессоров на стойку, имеющую производительность 460 GFLOPS и потребляющую 14,5 КВт электроэнергии.
В отличие от XD1, в XT3 используется операционная система UNICOS/lc, основанная на микроядре, которое загружается в вычислительные процессорные элементы. Однако и здесь не обошлось без ОС Linux, которая применяется в сервисных процессорных элементах и в элементах, предназначенных для интерактивной работы пользователей. MPI-задержка между процессорными элементами в XT3 составляет 3 микросекунды.
Промежуточная победа
Из проведенного выше обсуждения мы можем прийти к очевидному выводу об определенной победе AMD Opteron на рынке высокопроизводительных вычислений – конечно, победе и небезоговорочной, и небезвозвратной. Менее очевидным представляется рыночное будущее Cray XD1 и XT3: наиболее опасными их конкурентами представляются все-таки кластеры. Доказывать преимущество перед ними по производительности или отношению стоимость/производительность понадобится на практике – хотя бы потому, что цены на XD1 пока неизвестны (известно, что стоимость RedStorm составляет 2 млн. долл.).
Литература
- Sun Fire V20z and V40z server architectures, A Technical White Paper, Jul. 2004, SunWIN Token#407582.
- Михаил Кузьминский, «64-разрядные микропроцессоры AMD». Открытые системы, б№ 4, 2002, с. 10-15.
- Cray XD1 High Performance Computer. White paper, WP-0020404. Cray, 2004.
- Михаил Кузьминский, «Реинкарнация Origin». Открытые системы, б№ 7/8, 2003, с. 12-15.
- B. Buckley, HPC with Cray. May 2004, cs.anu.edu/Student/comp4300/lectures/cray04.pdf.
- M. Resh, HPC-Center Stuttgart, Univ. Stuttgart, T-Systems, HPCN Workshop, 2004, www.t-systems-sfr.com/download/3hlrs_resh.pdf.
