Успешное управление уровнем сервиса в сетях требует применения упреждающих мер, в то время как большинство отделов ИТ работает в режиме реагирования. Предотвратить проблему проще, чем устранять ее последствия. В статье рассказывается, как не тратя времени даром перейти от устранения проблем к планированию работы сети с помощью соответствующих инструментов.
Управление уровнем сервиса (Service Level Management, SLM) получило широкое распространение как метод рационального использования ресурсов ИТ в соответствии с потребностями конкретного бизнеса. Основная его идея — постоянный контроль качества предоставляемых информационных услуг в целях удовлетворения требований клиентов к сети и повышения эффективности работы. Применяя такой подход, заказчик получает средство оценки ИТ в соответствии с отдачей от инвестиций, а не общей стоимости владения.
Традиционное управление уровнем сервиса основано исключительно на мониторинге доступности ресурсов. Сервис (сеть, сервер или приложение) должен оставаться работоспособным в продолжение 99,999% времени. Такую оценку просто получить, и она дает определенную информацию конечному пользователю. Однако подобный подход не позволяет достичь ключевых целей SLM, удовлетворить требования клиентских приложений и обеспечить постоянное улучшение характеристик. Причина проста: реально предоставляемый сервис может иметь столь низкие рабочие характеристики, что использовать его окажется невозможно.
Кроме того, такой подход не только не способствует росту эффективности, но и приводит к обратному результату — ведь он фокусирует внимание команды администраторов на редко происходящих событиях, а не на типичном поведении системы. Для достижения максимальной эффективности необходимо, чтобы управление основывалось не только на факте доступности или недоступности ресурсов, но и жестко привязывалось к конкретным рабочим характеристикам, при этом оно должно учитывать как текущий статус оборудования и инфраструктуры, так и реальную практику работы пользователя. Главное — применяемый способ должен обеспечивать экономию времени, а не его расходование.
К счастью, инструментарий SLM уже достиг надлежащего уровня развития. Современные методы SLM активно поддерживают переход от политики реагирования к превентивному управлению за счет применения четырех ключевых средств: многоуровневых отчетов, раннего обнаружения проблем, быстрого их разрешения и подбора других вариантов. Очень важно, чтобы эти функции были просты в освоении, управлении и применении.
Для эффективного управления SLM необходимо точно определить целевые параметры уровня сервиса (Service Level Objectives, SLO) и прежде всего оценить три ключевые переменные: время отклика для конечного пользователя, время реакции сервера и величину задержки сигнала в сети. Однако способ измерения может быть разным (пассивным или активным), а от этого во многом зависит достижение желаемого результата. Параметры SLO основываются на средних значениях времени, на процентном соотношении средних значений или на процентном соотношении транзакций. Многие имеющиеся инструментальные средства позволяют отслеживать параметры SLO по усредненным по времени значениям, однако это не всегда позволяет в полной мере оценить работу приложений, как она воспринимается пользователями. Отслеживание SLO на базе процентного соотношения транзакций — более совершенный метод с технической точки зрения, причем он точно отражает реальную ситуацию. Однако решений, с помощью которых этот подход мог бы быть реализован в масштабах всего предприятия, предлагается совсем немного.
Настройка пороговых значений в параметрах SLO должна опираться на реальные потребности пользователей. Варианты могут быть разными — как по приложениям, так и по методам доступа к сети. Первое пороговое значение — нижнее — определяет границу, когда появляются трудности при работе с сетью. Второе — верхнее — показывает, в какой момент недостаточная эффективность системы начинает приводить к существенным издержкам. Процентные соотношения (если система параметров SLO их поддерживает) следует регулярно уточнять, тогда результативность постоянно улучшается, а временные задержки всегда находятся под контролем.
ПРЕВЕНТИВНОЕ УПРАВЛЕНИЕ ПОСРЕДСТВОМ SLM
Для достижения целей SLM специалистам ИТ приходится менять свои привычки и отношение к работе. Подавляющее большинство решает проблемы по мере возникновения, причем почти всегда в пожарном порядке. Применяя же подходы SLM, отделы ИТ в состоянии предвидеть проблемы заранее, быстро находить их источники и устранять еще не случившиеся сбои, переходя от реагирования к упреждению. Подобное изменение поведенческой модели, конечно, требует обучения персонала, зато специалисты получают нужный стартовый импульс для оценки рабочих характеристик сети по-новому.
Инструментарий SLM — это не просто методы мониторинга и анализа. Он гарантирует, что необходимые ресурсы будут соответствовать нуждам пользователей и целям бизнеса. Первое требование для внедрения системы — она должна высвободить время для стратегических действий. Некоторые средства настолько громоздки в установке, управлении и использовании, что их применение не дает никакой экономии времени. Продукты SLM должны быть легко управляемы и предоставлять функциональные возможности, которыми действительно удобно пользоваться.
Простота использования инструментария SLM зависит от того, насколько быстро система устанавливается, удобна ли она в работе и ежедневном управлении. Все это определяется архитектурой средств SLM и особенностями той среды, в которой они применяются. Инструментарий, слишком дорогой и сложный для малого предприятия, может оказаться приемлемым в крупной корпоративной сети. Если же он требует постоянной координации между несколькими группами ИТ (например, одни отвечают за настольные приложения, другие — за приложения глобальной сети), то иногда это вызывает напряженность между отделами, и в результате попытки повысить эффективность окажутся бесплодными...
Средства управления SLM должны активно поддерживать, а точнее, стимулировать переход от реагирующего управления к превентивному.
ЗНАЧИМЫЕ ПЕРЕМЕННЫЕ
Один из начальных этапов реализации SLA — выбор ключевых переменных. На каких переменных будет основана система соглашений об уровнях сервиса? В реальной жизни конфликт часто возникает между желаниями пользователя и возможностями отдела ИТ: первые обычно трудно охарактеризовать численно, хотя они так или иначе связаны со временем отклика системы; между тем как специалисты ИТ всегда хотят иметь четкие параметры, которые они могли бы контролировать. Так, при отсутствии контроля за группой серверов никто не возьмет на себя ответственность за проблемы с ними. Компромиссное решение — проведение более широких измерений при четком разделении обязанностей: все важные переменные должны отслеживаться, но при этом штрафные санкции должны соответствовать мере ответственности.
ПРОИЗВОДИТЕЛЬНОСТЬ ДЛЯ КОНЕЧНОГО ПОЛЬЗОВАТЕЛЯ
Время отклика на запрос конечного пользователя нужно отслеживать независимо от того, применяются ли в системе соглашения SLA. Это облегчает нахождение общего языка между пользователем и специалистами ИТ, ведь самый простой способ выразить в цифрах ощущения от работы сети — измерить время транзакций и ее составляющих.
Для численной оценки решающее значение имеет выбор транзакций для измерения и способ его проведения. Нужно ли отслеживать все типы операций или достаточно ограничиться несколькими? В последнем случае для масштабирования требуется агрегирование, что несколько ухудшает детализацию. При отслеживании части операций потребуется потратить определенное время и силы на проверку репрезентативности, чтобы убедиться, что полученные данные правильно характеризуют происходящее. Комбинация этих двух вариантов часто дает удовлетворительные результаты, причем оба метода вовсе не всегда исключают друг друга.
Надо ли отслеживать работу реально имеющихся пользователей в пассивном режиме или следует создавать агентов специально? Первый вариант абсолютно необходим для достижения целей SLM, поскольку именно ради реальных пользователей все и делается. Зато второй дает детерминированную базовую характеристику системы, что полезно для задач диагностирования сети. Наилучшим подходом является комбинация пассивного мониторинга реальных пользователей и нескольких искусственно созданных агентов.
ПРОИЗВОДИТЕЛЬНОСТЬ РАБОТЫ СЕРВЕРА
За временем отклика сервера нужно следить независимо от применения соглашений SLA. Очень важно уметь быстро определить, серверы ли виноваты в том, что этот параметр ухудшается. Его же можно использовать и для наблюдения за качеством сервиса, предоставляемого информационным центром, и для оптимизации и планирования загруженности сети.
При оценке времени отклика сервера нередко возникают проблемы. Если для повторного выполнения одних и тех же транзакций применяются искусственно созданные агенты, то в этом случае результаты могут кэшироваться клиентом и сервером. Это, по сути, обесценивает результаты, поскольку они не отражают реальную ситуацию. Когда сервер выполняет кэширование информации, то ее нельзя обрабатывать и блокировать избирательно, а при выполнении транзакций в случайном порядке теряется главное преимущество искусственно созданных агентов — их детерминизм. Избирательное кэширование в сочетании с наличием искусственных агентов чревато неточной оценкой времени отклика сервера. Проблема устраняется путем пассивного мониторинга характеристик сервера по всем транзакциям и всем пользователям, заодно это дает необходимые предпосылки к обеспечению производительности в будущем.
ХАРАКТЕРИСТИКИ РАБОТЫ СЕТИ
Задержка сигнала в сети — еще один параметр, нуждающийся в постоянном внимании независимо от того, используются ли в системе соглашения SLA. Он позволяет быстро определить, в чем причина ухудшения времени отклика на запрос конечного пользователя. Показатели эффективности работы сети, например время подтверждения приема, могут пригодиться для оценки качества сервиса, полученного от сетевого провайдера. Кроме того, непрерывный мониторинг задержки сигнала необходим для оптимизации и планирования работы сети.
Есть несколько общих методов оценки задержки сигнала в сети. К активным относится регулярная отправка пакетов ICMP (ICMP ping) или установление сеансовых соединений TCP. Пассивные включают в себя измерение характеристики сеансовых соединений TCP или пакетов приложений более общего назначения. Измерение задержки сигнала путем отслеживания обычных пакетов приложений дает наиболее точные данные о производительности сети. Чтобы оценить достоинства и ограничения каждого метода, важно учесть все составляющие задержки сигнала в сети. Она состоит из пяти компонентов: сериализации (преобразование в последовательную форму), нахождения в очередях, задержки распространения сигнала в среде передачи, задержки обработки данных и задержки протокола.
ДОСТУПНОСТЬ СЕРВИСОВ
Доступность сервиса нужно контролировать в явном виде — это часть стратегии управления SLM. При традиционном подходе к управлению отслеживается доступность сети и сервера. Его можно дополнить активными агентами или программными зондами, которые периодически будут пытаться выполнить выбранные транзакции. Если такие средства настроены на запуск каждые 15 мин, то в среднем уже через 7,5 мин длительный простой будет обнаружен. Однако промежуточные кратковременные сбои нередко остаются незамеченными и не находят отражения в параметрах SLO. Более частый опрос, конечно, поможет выявить и такие кратковременные неполадки, но за счет дополнительной нагрузки на систему.
СОМНИТЕЛЬНАЯ СТАТИСТИКА
Следующее важное решение при реализации системы SLM касается статистики. Должны ли соглашения SLA базироваться на средних значениях по времени или на процентном отношении транзакций? В SLA нa основе усредненных характеристик может требоваться, в частности, чтобы среднее время отклика было менее 3 с. А в SLA на базе процентных соотношений — чтобы время отклика было меньше 3 с в 95 случаях из 100.
Преимуществом выбора SLA на базе временных средних значений является то, что почти каждый производитель систем SLM поддерживает их определение, чем обеспечивается широкий выбор инструментария. Но усреднение по времени не дает точного представления о том, что испытывают пользователи при работе в сети. Например, пусть для девяти пользователей время отклика составляет 0,5 с, а для десятого — 90,0 с. Среднее время отклика равняется 9,5 с, и это отличается на целый порядок от того, с чем в действительности сталкивается любой из них. По этой причине управление на основе средних значений — задача слишком сложная. Если для десятого пользователя время отклика 180,0 с, а не 90,0, при том что у остальных показатель останется по-прежнему 0,5 с, среднее значение почти удвоится, хотя только один из всех столкнулся с ухудшением характеристик.
Некоторые производители опираются на усеченное среднее значение, чтобы уменьшить чувствительность к отдельным значениям (выбегам) — они отбрасывают любое измерение, превышающее предварительно установленное пороговое значение. В предыдущем примере пороговое значение в 2 с приведет к тому, что усеченное среднее составит 0,5 с, без учета значения 90-секундного выбега. Однако при таком подходе возникает серьезная опасность, что из-за отсечек существующие проблемы с производительностью могут оказаться скрытыми. Если время отклика для семи пользователей увеличивается с 0,5 до 2,5 с, то усеченное среднее значение по-прежнему останется равным 0,5 с, пусть даже 80% пользователей столкнулись с ухудшением характеристик! Из-за неоднородной природы большинства сред правильно выбрать пороговое значение для отсечки почти невозможно. В реальной жизни были случаи, когда из-за такого усечения участки с наихудшей производительностью выдавали отчеты, согласно которому они выглядели чуть ли не лучшими во всей сети по эффективности.
Соглашения SLA на основе процентного соотношения транзакций не подвержены таким перекосам и напрямую связаны с тем, что испытывает пользователь. Если для 95% транзакций время отклика составляет менее 3 с, то его значение для остальных 5% несущественно. Соглашения SLA на базе усеченных средних значений игнорируют все значения времени отклика, которые превышают предварительно установленный порог; когда же все значения превышают порог, то измерения как такового и нет вовсе. Соглашения SLA на основе процентного соотношения транзакций игнорируют только заранее заданную долю (в нашем примере — это 5%) значений времени отклика.
При этом выбор производителя системы SLM оказывается более узким. С технической точки зрения составление отчетов о процентном соотношении — более сложная задача, а потому этот вариант поддерживается меньшим числом производителей. Некоторые производители выбирают гибридный метод составления отчетов на основе процентного соотношения средних значений вместо транзакций. Соглашения SLA нa базе такого гибридного метода требуют, например, чтобы в течение месяца 95% из средних значений за 5 мин составляли менее 5 с.
ВАЖНЫЕ ПАРАМЕТРЫ
Другое решение касается точного описания целей. Сколько целевых значений мы получим для каждой переменной? Какие временные интервалы должны быть заданы для нее? Какие пороговые значения и процентные соотношения следует принять? Эти важные параметры должны основываться на потребностях пользователя и отображать реальное положение дел.
Интерес представляют как минимум два пороговых значения: приемлемый и критический порог. Все задержки меньше приемлемого порога незаметны пользователю; это не значит, что они малы — просто величина задержек попадает в диапазон ожиданий, который не вызывают раздражения. Задержки, превышающие критический порог, приводят к тому, что пользователь фактически лишается сервиса и не в состоянии работать должным образом. Для бизнеса они обходятся дорого, поскольку приводят к финансовым потерям и снижению производительности труда. Задержки, величина которых оказывается между двумя описанными пороговыми значениями, обычно воспринимаются как «подтормаживание» приложения и сети.
Два указанных пороговых значения в численном виде обычно заранее неизвестны, однако их можно оценить экспериментально с помощью специально привлекаемых или невольно участвующих в оценке пользователей. Например, типичные пороговые значения при загрузке страниц Web часто составляют 3 с и 8 с. Однако пороговые значения практически всегда существенно зависят от метода сетевого доступа и от типа самого приложения. Так, имеющие доступ к развлекательному порталу через спутник более спокойно относятся к задержкам, чем те, кто обращается с запросом в службу технической поддержки по наземному каналу DS3. Для каждого приложения и группы доступа следует составить отдельное соглашение SLA.
Пороговые значения всегда следует устанавливать с учетом требований пользователей. Процентные соотношения, если соглашение SLA их поддерживает, должны быть такими, чтобы работа системы постоянно улучшалась. Пользователи чувствительны не только к абсолютным значениям задержек, но и к их изменениям. Увеличение процентного соотношения позволяет эффективно контролировать колебания. Например, пусть сначала в соглашении SLA определяется, что в 95% случаев вре-мя отклика при транзакции должно быть менее 3 с, а в 98% — менее 8 с. Задача в том, чтобы за определенный период увеличить эти отношения, скажем, до 96 и 99%. Уменьшение трехсекундного порога мало повлияет на деловые операции — это и так вполне приемлемое значение.
Некоторые перерывы на обслуживание или даже отдельных пользователей, может быть, понадобится намеренно исключить из соглашения SLA. Это следует предусмотреть еще на стадии описания, а не после того, как соглашение SLA окажется невыполненным. Заметим, однако, что далеко не все производители поддерживают такие функции. Если выбранный продукт не в состоянии обеспечить исключение требуемых «окон», то заданное процентное отношение придется скорректировать вручную в меньшую сторону.
МНОГОУРОВНЕВЫЕ ОТЧЕТЫ
Многие производители заявляют, что их инструментарий реализует SLM, а интерпретация результатов и настройка остаются на усмотрение пользователя. Конечно, отслеживание пакетов позволяет реализовать SLM, но, если время ограничено, такой подход не всегда удобен. Инструментарий не приносит особой пользы и в случае обеспечения только высокоуровневого «управления», без каких-либо технических подробностей, необходимых для выбора корректирующих действий. Он должен предоставлять как высокоуровневую информацию о статусе, так и технические детали — просто и понятно. Эту функцию на-зывают навигацией, именно она обеспечивает предоставление иерархических отчетов. Высокоуровневые сводки полезны, но в основном нужны для общения с нетехнической аудиторией. Цель же навигации — быстро отыскать нужный технический параметр специалисту, принимающему решение.
ВЫСОКОУРОВНЕВЫЕ ОТЧЕТЫ SLA
На Рисунке 1 в сводном высокоуровневом отчете SLA представлена информация о выполнении различных соглашений SLA. Если необходимо просмотреть более подробные данные, нужно щелкнуть на названии приложения, после чего будет открыт детальный отчет именно для этого приложения.
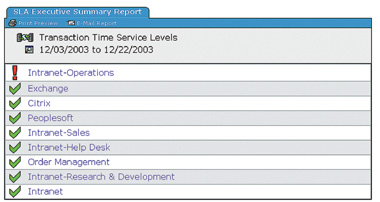
|
| Рисунок 1. Высокоуровневый отчет SLA. |
На Рисунке 2 представлены данные по приложению Peoplesoft. Для него соглашение SLA требует, чтобы 95% всех транзакций имело время отклика менее 2 с (Критерий 1) и 99% — время отклика менее 4 с (Критерий 2). Сервис Peoplesoft полностью соответствует SLA, поскольку 99,9% транзакций длится менее 4 с, а 99,8% — менее 2 с.
Форма другого отчета (см. Рисунок 3) более удобна для руководителей отделов ИТ или технических пользователей. Она позволяет окинуть взглядом общую картину и посмотреть счетчики нарушений; при необходимости способ представления информации можно изменить. Высокоуровневые отчеты очень по-лезны для общей интерпретации результатов и идентификации нарушений, но они не дают достаточной информации для принятия решения и выбора конкретных корректирующих действий.
ОТЧЕТЫ SLA СРЕДНЕГО УРОВНЯ
Отчеты среднего уровня дают различные временные, пространственные или логические сводки относительно соответствия соглашениям SLA. На Рисунке 4 показана реальная статистика по соглашениям SLA в виде функции от времени. Это позволяет быстро установить периодичность возникновения проблемы или выделить временные интервалы для более глубокого исследования.
Чтобы определить, кто виновник чрезмерного количества нарушений — отдельный сервер или какая-то группа пользователей, — нужны иные варианты отчетов. Так, если нарушения соглашения SLA вызваны несколькими клиентскими сайтами, это удается выявить благодаря специальному отчету (по отдельным площадкам). Подобные представления помогут специалистам по ИТ понять, как привести приложение в соответствие с соглашениями SLA.
НИЗКОУРОВНЕВЫЕ ОТЧЕТЫ
Отчеты такого рода нужны для быстрого решения проблем с производительностью и как вспомогательное средство для эффективного распределения ресурсов. Они предоставляют необходимые технические данные для понимания масштаба и причины проблемы, что позволяет отделу ИТ принять меры для устранения возникших затруднений. Низкоуровневые отчеты включают в себя результаты автоматизированного анализа (см. Рисунок 5), а также подробные показатели производительности (см. Рисунок 6).
ИНТЕЛЛЕКТУАЛЬНЫЕ ОТЧЕТЫ О БАЗОВЫХ ХАРАКТЕРИСТИКАХ
Мало отслеживать производительность с помощью заданных пороговых значений SLA, важно также понять, каким образом текущая производительность меняется с течением времени. Ожидания пользователей основаны на их опыте работы с приложением — функционирования системы вполне может соответствовать принятым соглашениям SLA, и при этом люди все равно будут проявлять недовольство, поскольку время отклика оказалось больше того, к которому они привыкли. Интеллектуальный отчет может быть сгенерирован при условии, что для приложения уже вычислена его базовая производительность. Статистика должна принимать в расчет производительность системы в недавнем прошлом и за длительный период.
На Рисунке 7 показан высокоуровневый отчет по производительности приложения в сравнении с его исторической базовой статистикой.
РАННЕЕ ОБНАРУЖЕНИЕ ПРОБЛЕМ
Всем хорошо знакомы обычные методы обнаружения проблем на предприятии: пользователи донимают администраторов телефонными звонками и срочными сообщениями по электронной почте, а то и приходят в отдел ИТ. Как правило, сотрудникам этих отделов физически не хватает времени на то, чтобы уделить внимание каждой жалобе. Если источники проблем не выявить на ранней стадии, то они всегда будут чрезмерно заняты срочным решением проблем, а планированием развития системы и долговременным прогнозированием будет заняться просто некогда.
Инструментарий SLM должен автоматически выявлять проблему еще в зародыше — до того, как она станет заметна невооруженным глазом. Такой механизм автоматического обнаружения в сочетании с отчетностью по приоритетам очень важен для принятия правильных превентивных мер. Разработки предыдущих поколений полагаются на предварительно сконфигурированные статистические пороговые значения, современный же инструментарий использует самообучающийся алгоритм. Новые средства изучают «стандартное» поведение приложений, серверов и клиентов, собирая и накапливая ежедневные, еженедельные и ежемесячные статистические данные. Такой алгоритм, в частности, в состоянии «понять», что для последней пятницы в месяце характерна более медленная работа, чем в другие временные периоды, поэтому сигнал тревоги генерироваться не будет, если только режим работы не окажется совсем уж неприемлемым в сравнении с «выученной» нормой.
Настраиваемая базовая статистика позволяет автоматизировать обнаружение назревающих проблем. Отдел ИТ получит предупреждение о потенциальных опасностях до того, как они станут заметны пользователям. Подобное раннее обнаружение сокращает среднее время восстановления (MTTR), увеличивает производительность работы и поднимает репутацию специалистов ИТ. Новые средства могут выполнять поиск в масштабах всего предприятия, обнаруживая аномалии, выявляя неэффективно работающие участки и другие области, нуждающиеся в улучшении. Они обеспечивают мониторинг и анализ данных о производительности все 24 ч в сутки и семь дней в неделю.
Альтернативный высокоуровневый отчет по производительности, с данными по самым серьезным сбоям за последние две недели, показан на Рисунке 8.
Очень важно уметь выявлять проблемы с доступностью и производительностью. Для этого обычно применяют средства активного мониторинга, но им свойственны некоторые недостатки (см. раздел «Доступность сервисов»). Поэтому обычно тестируются только отдельные транзакции из отдельных точек сети. К тому же слишком часто агенты своей работой провоцируют возникновение проблем.
Лучшим методом представляется пассивный мониторинг в сочетании с периодически запускаемым активным исследованием. Например, активное зондирование сети или сервера следует проводить, только если будет обнаружено необычное отсутствие трафика — это сведет к минимуму нагрузку на сеть. Таким образом, можно легко обнаруживать потенциальные сбои, не загружая сеть и серверы сверх минимально необходимого уровня.
Независимо от того, каким методом диагностируются сбои, раннее определение проблем с доступностью и производительностью сети — основа правильного управления SLM.
БЫСТРОЕ УСТРАНЕНИЕ ПРОБЛЕМ
Выбранный инструментарий SLM должен не только позволять оперативно выявлять возникающие проблемы, но и оказывать помощь в их устранении. Многоуровневая отчетность значительно облегчает задачу, особенно в сочетании с навигационным интерфейсом «щелкни и посмотри». Настраиваемые при помощи конструктора форм отчеты — средство очень гибкое, но пользовательский интерфейс оказывается сложным, а работа — утомительной. Это, скорее, — вспомогательное, а не ключевое средство.
Автоматизированные исследования значительно экономят время, если для них требуется лишь небольшая настройка вручную. При обнаружении неполадок в работе сервера необходимо собрать дополнительную информацию — уровень загрузки центрального процессора, использование памяти, данные по наиболее активным процессам — на момент возникновения проблемы. Когда в сети выявлена назревающая неприятность, следует запустить средства трассировки или собрать дополнительные статистические данные из баз MIB. Подобные исследования могут уменьшить объем последующей диагностической работы.
ПОСТОЯННОЕ СОВЕРШЕНСТВОВАНИЕ
Одна из основных целей управления SLM — постоянное улучшение работы сети. Раннее обнаружение проблем и их быстрое устранение, несомненно, увеличивают эффективность работы. Но все это относится к мерам реагирования, а не профилактики. Обычно необходимые меры принимаются, когда сервис оказывается совершенно неприемлемым (на основании порогового значения SLA) или его качество ухудшилось (в сравнении с базовыми характеристиками). Если же он постоянно находится в устойчивом, но неэффективном состоянии, то подобное положение дел может остаться незамеченным. Инструментарий SLM должен обеспечивать механизм быстрого выявления всех неэффективно работающих компонентов сети и предлагать варианты улучшения.
Пример реализации такой функции показан в отчетах на Рисунках 9-12. Диаграммы производительности необычайно полезны для улучшения производительности, они позволяют сделать выбор из некоторого числа вариантов, включая приложение (приложения), клиента (клиентов), сервер (группу серверов), представляющие интерес показатели, порядок сортировки и период времени.
Ниже мы рассмотрим примеры использования диаграмм производительности.
НЕЭФФЕКТИВНОСТЬ ПРИЛОЖЕНИЙ И ВОЗМОЖНОСТИ УЛУЧШЕНИЯ
На Рисунке 9 показана диаграмма производительности с указанием «времени транзакций по приложениям» для популярного сейчас многоуровневого приложения ERP — системы планирования ресурсов предприятия. Каждый его уровень отслеживается агентом: графический пользовательский интерфейс Web (система ERP), идентификация пользователя (служба каталогов LDAP), обмен документами (NetBIOS/TCP) и сервер баз данных (Oracle 9i DB). Естественно, приложение графического интерфейса имеет самое большое среднее время транзакции (1,51 с), сервер баз данных — самое малое (0,04 с), а идентификация пользователя сопряжена с задержкой в 0,53 с.
Такая диаграмма производительности дает моментальный снимок поведения каждого уровня приложения и показывает, как они влияют друг на друга. Если бы оба значения времени — и для графического интерфейса, и для сервера баз данных — были высоки, то и вероятность того, что один уровень влияет на другой, оказалась бы очень большой.
В этом случае пользователю необходимо щелкнуть на названии приложения, чтобы посмотреть подробный низкоуровневый отчет, определить зависимость между двумя уровнями и установить истинный источник проблемы.
НЕЭФФЕКТИВНОСТЬ РАБОТЫ СЕТИ И ВОЗМОЖНОСТИ УЛУЧШЕНИЯ
Диаграммы производительности можно использовать для характеристики задержки и потерь в сети. На Рисунке 10 приведена гистограмма времени отклика сети по каждой площадке, иллюстрирующая ее производительность в масштабах всего предприятия. Для визуального определения «горячих» точек в схему включены все узлы сети, отсортированные по описанию. Например, пользователям виртуальной сети VPN пришлось довольствоваться низкой производительностью, в то время как пользователи, находившиеся в штаб-квартире корпорации, наслаждались высокой пропускной способностью.
Диаграмма «Коэффициент потерь байтов по площадкам» на Рисунке 11 показывает 15 клиентских областей с наихудшими коэффициентами потерь. Сортировка производится по показателю, а не по описанию или адресу. Высокая степень потерь может быть вызвана ошибками или перегрузкой. В любом случае потери — результат неэффективной работы сети, а значит, есть что улучшать. Эффективность работы пользователей в Питтсбурге и Эль-Пасо серьезно ограничена характеристиками сети.
НЕЭФФЕКТИВНОСТЬ РАБОТЫ СЕРВЕРОВ И ВОЗМОЖНОСТИ УЛУЧШЕНИЯ
Диаграммы производительности применяются и для идентификации проблемных серверов путем сравнения их производительности. Диаграмма производительности по несостоявшимся сеансам (см. Рисунок 12) указывает на то, что сервер ERP1 перегружен или неисправен. На диаграмме производительности по времени отклика сервера (см. Рисунок 13) видно, что серверы Web предоставляют неадекватные уровни сервиса, поскольку показатель самого быстрого отклика в семь раз меньше значения самого медленного. Возможно, система просто устарела и требует модернизации или необходимо оптимально распределить нагрузку. Диаграммы производительности помогают оценить эффективность средств распределения нагрузки, позволяя сравнить количество активных сеансов, объемы трафика, время отклика. Разные инструменты используют различные показатели оптимальности распределения нагрузки. Посредством диаграмм производительности можно оптимизировать работу серверной фермы на основании данных об объеме трафика между системами.
ЗАКЛЮЧЕНИЕ
Управление уровнем сервиса SLM — это управление качеством предоставляемого сервиса в целях удовлетворения требований клиентов и улучшения рабочих характеристик системы. Клиентами ИТ являются конечные пользователи. Работа отдела информационных технологий в том и заключается, чтобы облегчить ведение бизнеса, следовательно, SLM можно рассматривать как еще одно подтверждение того, что информационные технологии способствуют успешности предпринимательской деятельности.
При внедрении программы SLM следует учесть два требования: во-первых, технические цели нуждаются в точном определении; во-вторых, отделу ИТ необходимо научиться действовать стратегически. При определении технических целей следует учесть все подлежащие мониторингу сервисы и выбрать показатели для измерений, методы измерения и инструментарий для контроля соглашений SLA. Выбранные средства SLM должны поддерживать упреждающее, превентивное управление за счет использования четырех ключевых факторов: многоуровневых отчетов, раннего обнаружения проблем, быстрого их разрешения и подбора других вариантов. Переход отдела ИТ от экстренной работы по устранению лавины проблем к стратегическому планированию возможен лишь в случае успешного решения поставленных технических задач и введения SLM в ежедневную практику.
Управление SLM позволяет специалистам ИТ перейти на цикли-ческую работу по постоянному улучшению сервисов, поддерживаемых ими для успешной работы предприятия. Анализ производительности и статистики соответствия сети предъявляемым требованиям помогает идентифицировать проблемные области, реорганизация которых обеспечивает наилучшие результаты. Достигнутое оптимальное распределение ресурсов и соответствие информационных технологий потребностям бизнеса — именно то, в чем сильнее всего нуждается сейчас любая организация.
Дмитрий Дундуков — руководитель отдела измерительно-контрольного оборудования компании Landata. С ним можно связаться по адресу: fluke@landata.ru.