Для тестирования системных плат использовались программы, позволяющие оценить производительность ПК или какой-либо из его подсистем. Эти тесты можно разбить на две группы: синтетические, для определения максимальной производительности отдельных узлов на специально для этого разработанных алгоритмах, и тесты, использующие реальные приложения. Первые позволяют получить конкретные числовые характеристики и составить представление об особенностях той или иной подсистемы. Они также позволяют прогнозировать поведение системы на том или ином классе приложений, а также выбрать приоритеты при подборе конфигурации для решения конкретных задач. Тесты, использующие реальные приложения, мало что могут сказать о том, как будет вести себя данная система на другом приложении. Все получаемые с их помощью результаты имеют ценность только при сравнении с аналогичными результатами (т. е. с использованием той же версии той же программы и в той же операционной и файловой системах) другой машины. Однако только они позволяют сказать, насколько эта система будет работать быстрее другой на конкретном приложении.
Первая серия тестов создана для исследования взаимодействия между ЦП и ОЗУ. С одной стороны, операций здесь не так уж много: чтение, запись и копирование из одного места памяти в другое. Но современная динамическая память характеризуется тем, что если надо получить доступ к двум последовательным элементам, то на получение первого тратится в десятки раз больше времени, чем на доступ к последующему. А применение многоуровневой кэш-памяти еще более усугубляет ситуацию, в результате чего различие может достигать сотен раз¹. При обращении к оперативной памяти в кэш-память считывается не только запрошенный элемент, но и несколько последующих. Чем длиннее эта цепочка, тем выше скорость последовательного доступа и ниже — произвольного. Поэтому каждый из этих двух режимов был исследован отдельно.
С другой стороны, разрядность слова процессора (32 разряда) не совпадает с разрядностью внешней шины (64 разряда), поэтому в ряде случаев быстрее оказывается обмен с использованием регистров ММХ (64 разряда). Кроме того, если данные в памяти размещены без учета выравнивания на длину элемента данных, то возникают дополнительные задержки. Результаты теста, осуществляющего последовательный доступ к области памяти объемом 4 Мбайт (существенно больше размера кэш-памяти), приведены на диаграмме 3. Зависимость скорости пересылки данных от объема данных показана на рис. 1. С точки зрения тестирования системных плат интерес представляет только та часть графика, которая соответствует обмену между ЦП и ОЗУ, т. е. при объемах данных, превосходящих размер процессорной кэш-памяти.
Дополнительные инструкции управления кэш-памятью, введенные в расширении набора команд SSE в Pentium III (и присутствующие в Athlon XP), позволяют еще несколько увеличить скорость обмена при последовательном доступе. Результаты этого теста с использованием массива данных объемом 16 Мбайт приведены на диаграмме 1.
Отдельным вопросом является исследование скорости обмена с внешними устройствами, в первую очередь — видеопамятью и жестким диском. Следует сказать, что для повышения точности измерений большая часть синтетических тестов проводилась в однозадачной среде при загрузке с системной дискеты. В этих условиях работают драйверы, «прошитые» в BIOS, поэтому данные тесты также в какой-то степени характеризуют системную плату, а именно входящее в ее состав ПО. Не всегда драйверы BIOS обеспечивают наивысшую производительность системы. Иногда они ориентированы на работу в 16-разрядном реальном режиме. При этом шина AGP работает в режиме PCI, а контроллер жесткого диска — в режиме PIO вместо UDMA. На диаграмме 1 показаны скорости пересылки из оперативной памяти в видеопамять в трех различных режимах: в режиме «окна» (banked), когда фрагмент видеопамяти проецируется в адресное пространство реального режима (для программ DOS), в режиме линейного буфера (LFB), который доступен только из защищенного режима, а также в режиме линейного буфера, но с использованием инструкций ММХ.
В дополнение приведен еще один режим, который, строго говоря, является не пересылкой, а перекодировкой. Экранный буфер, расположенный в ОЗУ, содержащий изображение в режиме 800х600 True Color 32 бита конвертируется в режим Hi Color 16 бит и в таком виде записывается в видеопамять (диаграмма 1). Для контроля приведены данные по скорости аналогичного преобразования, выполняемого целиком в оперативной памяти. Скорость приведена применительно к объему данных в приемнике, чтение из источника осуществляется вдвое быстрее.
Заключительный тест, результаты которого приведены на диаграмме 1, - на скорость чтения данных с жесткого диска. Эта величина меньше той, с которой способен работать используемый накопитель, и не коррелирует с установленным набором микросхем; другими словами, цифры характеризуют качество драйверов BIOS.
Следующая серия тестов определяет производительность вычислительной подсистемы компьютера на основе выполнения конкретных задач. Первая из них — нахождение простых чисел методом «решета Эратосфена», при котором интенсивно используется оперативная память. Результаты выполнения этого теста в относительных единицах времени для различных диапазонов чисел приведены на диаграмме 5. Следующий тест — компрессия и декомпрессия тестового файла объемом 5,45 Мбайт методом LZW. Результат также указан в относительных единицах.
Быстрая сортировка — один из самых эффективных алгоритмов упорядочивания данных. Он чрезвычайно широко используется в самых разнообразных областях, от обработки баз данных и электронных таблиц до компьютерных игр и научных вычислений. Время сортировки в секундах массива целых двухбайтовых чисел объемом 16 Мбайт приведено на диаграмме 5.
Исторически традиционный способ оценки быстродействия компьютеров — решение системы линейных уравнений. Производительность ЭВМ принято указывать во флопах (Flop), т. е. В количестве операций с плавающей точкой в секунду. Достигнутый сегодня пик производительности составляет примерно 36 терафлоп (т. е. 36 триллионов операций в секунду). Для современного персонального компьютера этот показатель составляет порядка одного гигафлопа, что примерно в миллион раз превосходит производительность тех суперкомпьютеров, для которых этот тест был изначально написан. В те времена задача состояла в решении 100 уравнений со 100 неизвестными, т. е. обработку матрицы чисел с плавающей точкой 100х100. При использовании ставших стандартом де-факто для научных расчетов чисел с двойной точностью (double) объем массива составляет менее 80 Кбайт. По нынешним меркам даже для ПК это уже несерьезно. Сегодня акценты сместились, и теперь операция с плавающей точкой выполняется гораздо быстрее, чем результат этой операции можно записать в ОЗУ. Кроме того, 80 Кбайт — это меньше размера кэш-памяти, поэтому все действия выполняются внутри процессора и для тестирования системных плат данная задача никакого интереса не представляет. Все это побудило написать обобщение классического теста — построение профиля производительности в зависимости от объема обрабатываемых массивов. Для тестирования системных плат представляет интерес «хвост» этого профиля, приходящийся на большие объемы данных, когда происходит интенсивный обмен с оперативной памятью. Фрагмент такого профиля представлен на рис. 2.
Еще один тест в однозадачной среде — микширование звука средствами MMX. Применение технологии ММХ в данном случае существенно ускоряет вычисления и предъявляет повышенные требования к оперативной памяти. Приведенное время соответствует микшированию одной минуты стереофонического звука из восьми каналов с независимой регулировкой громкости и панорамы по каждому из них.
Последний тест, представленный на диаграмме 5, — Performance Test компании PassMark (www.passmark.com). Помимо множества частных характеристик он выдает и две интегральные: общий индекс производительности и производительность при вычислении с плавающей точкой. В общем индексе учитываются характеристики как основы компьютера (ЦП и ОЗУ), так и периферийных устройств (видеосистемы и дисковых накопителей).
Одной из наиболее известных компаний, выпускающих тесты производительности ПК, является FutureMark (www.futuremark.com). При испытаниях системных плат были использованы две программы этой фирмы: PCMark2002 Pro и 3DMark03 Pro. Первая определяет три индекса производительности: для ЦП, памяти и жесткого диска (см. диаграмму 4). В аспекте тестирования системных плат наибольший интерес представляет вторая характеристика. Правда, в ней учитываются также свойства встроенной в процессор кэш-памяти. Дисковый индекс, в свою очередь, в отличие от данных, представленных на диаграмме 1, характеризует работу дисковой подсистемы с драйверами ОС, т. е. только свойства самого «железа», так как драйверы в этом случае используются одни и те же (во всяком случае, для одного и того же набора микросхем). Второй тест оценивает компьютерную мощь в игровых приложениях, использующих DirectX. Правда, основной упор в нем сделан не столько на производительность, сколько на поддержку наиболее новых технологий, реализованных в графическом ускорителе. В наших измерениях мы использовали разрешения 640х480, 1024х768 и 1600х1200 точек. Выбранная сетка разрешений была использована и при проведении игровых тестов.
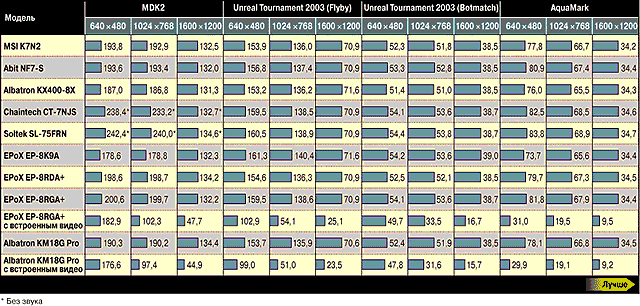
Одним из основных, если не единственным стимулом к совершенствованию элементной базы персональных компьютеров являются 3D-игры. Под этим термином подразумеваются компьютерные игры, использующие полигональные текстурированные модели. Но «истинному» игроку абсолютно неинтересен вычисляемый тестовой программой индекс, его волнует лишь скорость обновления изображения, измеряемая кадрами в секунду (fps). Благо, сегодня разработчики игр культивируют в игроке эту склонность, предусматривая в своих творениях механизмы определения пресловутых fps. Этим мы и воспользуемся (см. диаграмму 7). Так как при работе с полигональной графикой нашли применение две различные платформы — DirectX и OpenGL, мы взяли по одной игре для каждой. Производительность для OpenGL определялась на игре MDK2 компании BioWare (www.vie.co.uk), а для DirectX — на Unreal Tournament 2003 разработки Digital Extremes & Epic Games (www.unrealtournament2003.com). В последнем случае применялись две различные карты. В качестве еще одного не совсем игрового, но чрезвычайно красивого теста, использующего DirectX, была выбрана программа AquaMark, разработанная фирмой Massive Development (www.massive.de). Как индекс производительности этот тест также использует столь любимые игроманами fps.
Другое ресурсоемкое применение ПК — набирающее все большую популярность компьютерное видео, связанное с кодированием и декодированием видеоданных. Поэтому следующим тестом была выбрана перекодировка фрагмента файла в формате MPEG-1 (352х240 точек) длительностью 10 мин в формат DivX v4.12 со скоростью потока 780 кбит/с с помощью программы VirualDub. Абсолютные значения времени здесь, конечно, не показатель, но для сравнения системных плат между собой этого вполне достаточно (см. диаграмму 2).
Не менее популярно среди владельцев ПК и сжатие звука, в первую очередь музыки. В принципе, о сжатии аудио в некоторой степени можно судить по результатам предыдущего теста, однако было решено посвятить ему и отдельный тест — сжатие 227-Мбайт звукового файла продолжительностью 22 мин 34 с с переменной и постоянной скоростью потока 192 кбит/с.
Последний из использованных нами тестов — набор контрольных задач PC WorldBench 4 журнала PC World. В нем с помощью языка макросов измеряется время выполнения заданной последовательности операций в наиболее распространенных офисных и профессиональных программах (диаграмма 6). Поскольку приложений довольно много и состав их разнообразен, суммарный индекс производительности можно считать достаточно адекватной оценкой быстродействия ПК. Однако тут следует учитывать недостаток данного теста — довольно высокий разброс результатов из-за интенсивного использования многочисленных систем ПК, и в первую очередь жесткого диска.
¹ Слово «усугубляет» здесь означает лишь «увеличивает разницу». При этом с учетом кэширования задержка в считывании первого элемента данных увеличивается, как правило, не более чем вдвое, зато последующих — снижается в несколько, вплоть до десятка раз.
|