О соотношении частоты синхронизации памяти и FSB
Если у современного человека спросить, из каких основных частей состоит компьютер, то, пожалуй, он приведет довольно длинный список, в первых строках которого окажутся системный блок, клавиатура и монитор. Нетрудно догадаться, что подобный перечень вряд ли годится для характеристики компьютера, управляющего микроволновой печью, системой зажигания автомобиля или космическим аппаратом. В общем, в нем не больше общего с реальностью, чем в утверждении о том, будто малиновый пиджак - отличительная черта всех позвоночных.
Любой компьютер, вне зависимости от его архитектурных особенностей и предназначения, состоит из центрального процессора и оперативной памяти, которые при необходимости могут быть дополнены периферийными устройствами. Последние применяются в основном для того, чтобы компьютер мог обмениваться информацией с внешним миром. Но в общем его производительность определяется согласованной работой именно процессора и памяти. И как раз здесь последнее время наметилось узкое место.
В IBM PC, первом массовом 16-разрядном персональном компьютере, появившемся немногим более 20 лет назад, был использован процессор Intel 8088 - младший брат Intel 8086, отличающийся от него вдвое более узкой внешней шиной данных. Такое решение было экономически оправданным, так как позволяло использовать восьмиразрядную периферию, благодаря чему новый компьютер не слишком сильно отличался по цене от своих восьмиразрядных собратьев. Но если предыдущий процессор Intel 8086 осуществлял синхронную выборку и исполнение команд, то у нового процессора эти действия выполнялись асинхронно - появилась очередь команд, заполнявшаяся тогда, когда не было интенсивного обмена процессора с областью данных. Это позволило более эффективно использовать пропускную способность шины данных, и уменьшение ее ширины вдвое не привело к существенному падению производительности.
В то время память практически не задерживала исполнение команд: процессор работал на тактовой частоте 4,77 МГц и даже адрес он вычислял гораздо дольше, чем память выдавала необходимые данные. Однако скорость процессора характеризуется тактовой частотой, а скорость памяти - временем доступа, которое не подвержено столь головокружительному прогрессу: тактовая частота выросла почти в 500 раз, а время доступа сократилось лишь примерно на порядок. Но если время доступа, скажем, 100 нс, то при 10 МГц это соответствует одному такту процессора, при 40 МГц - четырем тактам, а при 100 МГц - уже десяти. Кроме того, совершенствовалась архитектура процессоров, так что одни и те же команды стали выполняться за гораздо меньшее количество тактов (см. табл. 1).
Разработчики учитывали возникающие тенденции. IBM PC AT вышел уже с полной 16-разрядной шиной данных, а IBM AT-386 - с полной 32-разрядной. Такова же была разрядность компьютеров и на 486 процессоре. Дальше - больше. Ширина внешней шины данных Pentium составляла 64 разряда, т. е. вдвое превышала разрядность процессора. А для графических процессоров (часто называемых 3D-акселераторами) она составляет уже 128-256 разрядов.
Увеличение ширины шины - не единственный способ обойти низкую скорость работы памяти. Начиная со старших моделей 386 в компьютерах стали применять кэш-память - небольшой объем быстродействующей памяти, являющейся как бы буфером между медленной основной памятью и процессором.
Современные модули памяти предназначены для работы в узком диапазоне частот, поэтому временные диаграммы их работы оптимизируются лишь для одной, номинальной, частоты. Следовательно, при использовании более низких частот производительность памяти будет пропорционально снижаться.
До недавнего времени частота внешней шины процессора Front Side Bus (FSB) должна была совпадать с частотой тактирования оперативной памяти. Низкая частота шины у процессоров Celeron (66 МГц) при этом ограничивала производительность данного класса процессоров. Последние же чипсеты позволяют тактировать память более высокой частотой, что может довольно существенно сказаться на общей производительности. Для исследования этого вопроса была использована системная плата Gigabyte GA-6VTX на чипсете VIA Apollo Pro 133T, позволяющем независимо устанавливать как внешнюю частоту процессора, так и частоту тактирования оперативной памяти. На нее по очереди устанавливались два процессора, различающиеся частотой внешней шины: Celeron-566 (FSB 66 МГц) и Celeron-1000 (FSB 100 МГц). Набор тестов - традиционный для нашего журнала. Все тесты проводились в однозадачной ОС (DOS Mode Windows 98 SE). Естественно, кэш-память при проведении измерений не отключалась, что также оказало немалое влияние (иногда определяющее, но об этом ниже) на результаты.
При чтении, записи и пересылке 4-Мбайт массива выявились вполне определенные закономерности (см. табл. 2).
Во-первых, увеличение частоты тактирования памяти со 100 до 133 МГц при FSB 66 МГц не привело к какому-либо изменению результатов. Это справедливо не только для последовательного доступа, но и вообще для всех проведенных экспериментов. В чем тут дело: то ли FSB не способна "переварить" более чем полуторакратное увеличение частоты памяти, то ли реальная частота тактирования "замораживается" на 100, когда BIOS Setup показывает 133, - сказать трудно.
Во-вторых, скорость выполнения значительной части операций зависит лишь от частоты памяти, а не от частоты процессора.
В-третьих, реально замеренные скорости доступа к памяти зачастую оказываются существенно ниже того, что можно было бы ожидать, исходя из простейших оценок.
В качестве альтернативы последовательному доступу можно применить произвольный. Внутри 32-Мбайт области случайным образом вычислялся адрес, а затем по этому адресу производилось чтение или запись одного байта (рис. 1).
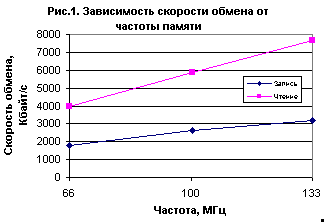
Чрезвычайно низкая скорость обмена объясняется двумя факторами. Во-первых, для первоначального задания адреса требуется довольно много времени (см. врезку "Как работает динамическая память"). Во-вторых, операции чтения/записи буферизованы кэшем, а обмен с ним осуществляется только порциями по 32 байта. Другими словами, чтобы считать из памяти 1 байт, необходимо перенести в кэш 32. В заключение отмечу, что процедура вычисления случайного адреса конечно же тоже занимает некоторое время, тем не менее примененный алгоритм позволяет при уменьшении объема данных до объема кэша L2 производить выборку со скоростью более 70 Мбайт/с для применяемого процессора 1 ГГц.
Различный характер зависимости производительности от частоты процессора и памяти для разных типов приложений можно видеть на рис. 2.
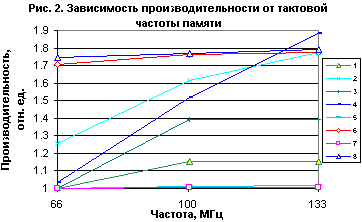
Для единообразия за единицу производительности принят процессор с частотой 566 МГц и памятью, работающей на 66 МГц. Кривыми обозначены следующие тестовые программы:
- Решение системы дифференциальных уравнений в частных производных (СДУЧП) на процессоре 566 МГц при объеме данных 40 Мбайт.
- Решение СДУЧП на процессоре 1000 МГц при тех же условиях.
- Нахождение простых чисел методом "решета Эратосфена" (РЭ) на процессоре 566 МГц при объеме массивов 40 Мбайт .
- РЭ на процессоре 1000 МГц при том же объеме массивов.
- Быстрая сортировка 16-Мбайт массива на процессоре 566 МГц.
- Быстрая сортировка 16-Мбайт массива на процессоре 1 ГГц.
- Нахождение кратчайшего пути в графе методом Дейкстры на 566-МГц процессоре. Объем массивов 300 Кбайт (более удвоенного объема кэш-памяти).
- Нахождение кратчайшего пути в графе на 1-ГГц процессоре при тех же условиях.
Из приведенных данных видно, что большая часть приложений наиболее чувствительна к частоте процессора. На рис.2 им соответствуют горизонтальные кривые вблизи единицы для частоты 566 МГц и вблизи 1,7-1,8 для 1000 МГц. Наиболее чувствительным к частоте памяти оказалось "решето Эратосфена", при этом с 66-МГц памятью производительность практически не зависела от частоты процессора. Графики для таких приложений имеют вид наклонных линий, для которых увеличение частоты вдвое соответствует такому же увеличению производительности, при этом зависимость от частоты процессора отсутствует. Некоторый компромисс наблюдается при решении системы дифференциальных уравнений. Производительность зависит от частоты памяти, но не прямо пропорционально, а гораздо слабее, кроме того, при частоте памяти 66 МГц процессор Celeron 1 ГГц демонстрирует всего на четверть более высокую производительность по сравнению с 566 МГц.
Хочется провести сравнение на примере еще одной задачи, а также исследовать влияние кэш-памяти.
В те далекие времена, когда компьютеры занимали несколько этажей здания и использовались исключительно для научных расчетов, оценке производительности уже уделялось немало внимания. Правда, задержек, связанных с памятью, тогда не было, а самыми сложными считались вычисления с плавающей запятой. Вот для таких вычислений и был написан тест Донгарра - решение системы линейных уравнений. Результаты некоторого обобщения этого теста приведены на рис. 3. Теперь уже оказалось, что сами вычисления с плавающей запятой можно выполнить гораздо быстрее, чем записать результаты этих вычислений в память.
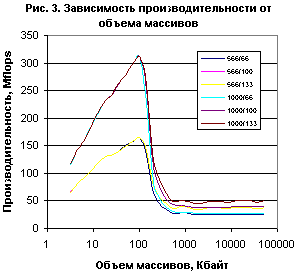
Невысокая производительность при небольших массивах объясняется тем, что современные суперскалярные процессоры с конвейерной архитектурой хорошо выполняют непрерывную последовательность команд, циклы же и вызовы процедур - несколько хуже, а накладные расходы именно на эти операции растут с уменьшением размеров массивов. До достижения объемом данных объема кэш-памяти производительность растет, причем определяется исключительно частотой процессора. При переполнении кэша мы видим резкое падение производительности, достигающее десятикратного. При этом кривые в переходной области сначала расходятся, а затем вновь сходятся, но уже совсем по иному признаку - по частоте памяти. Тактовая частота процессора утрачивает свою роль, на первый план выходит частота памяти.
К счастью, значительная часть реальных приложений не достигает таких объемов одновременно обрабатываемых данных, при которых тактовая частота процессора уже перестает играть роль. Обработку текстур, необходимую на каждом кадре, берет на себя графический процессор, а там совсем другие и частоты, и ширина шины. А остальные объемные данные, будь то видеофильм, архив или многостраничный документ, как правило, обрабатываются небольшими порциями, умещающимися в кэш-память. Но с другой стороны, кэш-память ведь тоже надо заполнять. Да и снижение производительности "всего" вдвое-втрое или даже на десятки процентов вместо десятикратного вряд ли может утешить.
Из проведенных измерений следует и еще один вывод: если чипсет допускает асинхронную работу процессора и памяти, это нивелирует разницу в производительности из-за различия в FSB, которая имеется, например, у Celeron и Pentium !!!.
От редакции: хотя полученные выводы с уверенностью можно отнести только к платам на основе набора микросхем VIA Apollo 133T, но в целом этот подход может быть применен и для оценки эффективности перехода на 533-МГц шину в современных платах.
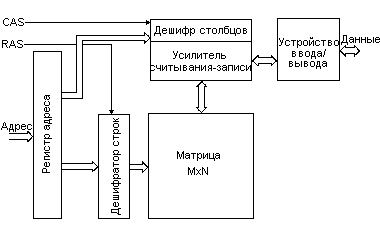
Как работает динамическая память
Центральной частью микросхемы динамической памяти является матрица конденсаторов размером MxN, где M и N обычно равны двум в какой-либо степени. Каждый конденсатор может находиться в одном из двух состояний: заряженном или разряженном, таким образом он хранит 1 бит информации.
Адрес в микросхему памяти передается в два этапа: сначала младшая половина адреса фиксируется в регистре адреса сигналом RAS (строб адреса строки), а затем старшая - сигналом CAS (строб адреса столбца). При считывании данных из памяти после фиксации младшая часть адреса подается на дешифратор строк, а с него - на матрицу, в результате чего строка конденсаторов матрицы целиком подключается к входу усилителей считывания. В процессе считывания конденсаторы разряжаются, а значит, информация в матрице теряется. Чтобы не допустить этого, только что считанная строка данных вновь записывается в строку конденсаторов матрицы - происходит регенерация памяти. К тому моменту, когда строка из матрицы попала в буфер усилителя считывания, на дешифратор адреса столбца уже подана старшая половина адреса и при помощи этого дешифратора выбирается один-единственный бит информации, хранящейся по адресу, зафиксированному в регистре адреса. После этого считанные данные можно подать на выход микросхемы. При записи информации сначала строка также считывается целиком, затем в ней изменяется нужный бит и строка записывается на прежнее место. Увеличение разрядности до 1, 2, 4 или 8 байт достигается параллельной работой нескольких микросхем памяти или нескольких матриц в одной микросхеме.
Как видим, для доступа к ячейке динамической памяти нужно проделать много последовательных операций, а потому время доступа оказывается довольно большим - сегодня это 35-50 нс, что соответствует 5-7 тактам внешней шины.
Память, работающая, как описано выше (DRAM - динамическая память произвольного доступа), применялась в первых персональных компьютерах. В одном корпусе при этом хранился объем информации до 64 кбит. Но если операции с адресом неизбежно занимают много времени, то нельзя ли как-нибудь обойти это ограничение? Ведь процессору зачастую нужны длинные цепочки байтов, хранящиеся в памяти подряд, например при выполнении последовательности команд или при обработке строк и массивов данных. И решение было найдено: после передачи микросхеме адреса первого элемента несколько последующих считывалось лишь при помощи сигналов шины управления, без передачи нового адреса, что оказалось примерно вдвое быстрее. Такая память получила название FPM RAM (память с быстрой страничной организацией) и надолго стала единственным типом оперативной памяти, используемым в персональных компьютерах. Для обозначения временных характеристик такой памяти применялись последовательности цифр: например, "7-3-3-3" означало, что на получение первой порции данных нужно затратить 7 тактов системной шины, а на последующие - по 3. Однако отрыв тактовой частоты процессора от частоты системной шины, с одной стороны, и прогресс технологии, позволивший сократить количество тактов, расходуемое вычислительным блоком на одну операцию, с другой, поставили вопрос о дальнейшем усовершенствовании технологии работы оперативной памяти.
Следующим этапом была разработка EDO RAM - памяти с увеличенным временем вывода данных, когда стало возможным совместить получение очередного блока данных с передачей "заявки" на получение следующего. Это позволило на такт уменьшить время доступа: "6-2-2-2". Однако EDO RAM очень скоро была вытеснена памятью типа SD RAM (синхронная), за счет чередования блоков время доступа оказалось возможным уменьшить до "5-1-1-1-1-1-1-1". Одновременно был применен некоторый маркетинговый ход: если при обозначении времени доступа к памяти типа FPM и EDO RAM принято было указывать время первого обращения, которое составляло 60-80 нс, то для SD RAM стали указывать время второго и последующих, что составляло уже 10-12 нс для тех же тактовых частот и, следовательно, близкого времени первого обращения. Производительность подсистемы памяти при этом выросла на десятки процентов, тогда как числа, обозначающие время доступа к памяти, уменьшились в несколько раз.
SDRAM до сих пор является основным типом памяти для процессоров Intel Pentium !!! и Celeron. Наряду с ней могут использоваться и более новые разработки: DDR RAM (точнее, DDR SDRAM, но мы будем пользоваться указанным обозначением), применяемая в основном с процессорами AMD Athlon и Duron, работающая на тех же частотах (100-133 МГц), но позволяющая передавать данные до двух раз за такт: по переднему и заднему фронту (поэтому появилось такое понятие, как эффективная частота, в данном случае 200-266 МГц), и ориентированная на применение в системах с Pentium-4 RDR RAM (Rambus RAM), работающая на частотах 300-533 МГц (эффективная частота 600-1066 МГц).
Если для SDRAM (теперь часто называемой SDR DRAM) были приняты обозначения PC-100 и PC-133, означающие возможность работы на 100 и 133 МГц соответственно, то для новых типов памяти, скажем PC-2100, цифры обозначают уже не частоту более 2 ГГц, а лишь "пиковую" скорость передачи данных. Слово "пиковая" взято в кавычки потому, что в каких бы идеальных условиях мы ни проводили измерения, полученное отношение количества переданной информации к затраченному на это времени не только не будет равно указанным числам, но даже не будет стремиться к ним асимптотически. Дело в том, что эта скорость приведена для части пакета с отрезанной первой порцией данных, т. е., как и для SDRAM, только для "второго и последующих". Для DDR RAM время первого обращения такое же, как и для SDRAM, а последующих - в два раза меньше. Поэтому при последовательном доступе выигрыш в производительности составляет десятки процентов, а при произвольном - вообще отсутствует.