
Мы продолжаем знакомить читателей с книгой Криса Дейта и Хью Дарвена «Foundation for Object/Relational Databases: The Third Manifesto» (начальные главы книги обсуждались в предыдущем выпуске журнала – прим. ред.). В этот раз мы рассмотрим третью и четвертую главы книги – «Третий манифест» и «Новая реляционная алгебра». Третья глава читается не очень легко; она написана в очень формальном стиле и не содержит пояснений. Но без этого материала трудно понять следующие, неформальные и дискуссионные главы. Мне самому очень нравится четвертая глава, где вводится новая, минимизированная версия реляционной алгебры. По-моему, создание этой алгебры относится к главным достижениям авторов книги.
Положительные RM-утверждения
1. Cкалярный тип данных (домен) – это именованное множество скалярных значений. Скалярные типы T1 и T2 одинаковы в том и только в том случае, когда являются одним и тем же типом. Пользователи языка D должны иметь возможность определения собственных скалярных типов; другие скалярные типы должны обеспечиваться системой. Должна иметься возможность отмены определения пользовательских скалярных типов. Значениями скалярных типов и соответствующими переменными можно оперировать только с помощью операций, определенных для этого типа. Для каждого скалярного типа и каждого обюявленного возможного представления его значений в состав этих операций должны входить:
a) операция selector, служащая для выборки произвольного значения этого скалярного типа (см. RM-утверждение 4);
b) набор операций для раскрытия возможного представления (см. RM-утверждение 5).
В состав системных скалярных типов должен входить тип truth value с двумя значениями (true и false); для этого типа должны поддерживаться все требуемые логические операции.
2. Все скалярные значения должны быть типизированы, т.е., по крайней мере, концептуально должны позволять идентифицировать тип, к которому относятся.
3. Пользователи языка D должны иметь возможность определения собственных скалярных операций; другие скалярные операции должны обеспечиваться системой. Должна быть предусмотрена возможность отмены определения пользовательских скалярных операций (с оговорками, содержащимися в RM-утверждении 5):
a) определение скалярной операции должно включать спецификацию типа каждого параметра (обюявленный тип параметра). Если операция Op имеет параметр P обюявленного типа T, то аргумент A, соответствующий P, в каждом вызове Op должен иметь тот же тип T;
b) каждая скалярная операция – либо операция обновления, либо операция только чтения. Операцией обновления является такая скалярная операция, по меньшей мере один аргумент которой специфицирован как ссылка на скалярную переменную, и вызов операции приводит к присваиванию значения таким аргументам (по крайней мере, потенциально); параметры, соответствующие подобным аргументам, являются предметом обновления. Прочие скалярные операции – операции только чтения;
c) скалярные операции только чтения возвращают результат, операции обновления – нет;
d) в определении скалярной операции только чтения должна содержаться спецификация типа результата (обюявленного типа);
e) в определении скалярного типа должна включаться спецификация аргументов, являющихся предметом обновления. Параметры, соответствующие таким аргументам, должны передаваться по ссылке. Все остальные аргументы операций обновления и все параметры операций только чтения должны передаваться по значению;
f) результат вычисления скалярного выражения SX имеет обюявленный тип, рекурсивно порождаемый из обюявленных типов операндов SX и обюявленных типов результатов подвыражений, содержащихся в SX.
4. Если T – это скалярный тип, а v – появление (в некотором контексте) значения этого типа, то по определению у v имеется в точности одно реальное представление и одно или более возможных представлений. Реальное представление, связанное с типом T, должно определяться средствами некоторого языка определения структуры хранения и не должно быть видимо в языке D (см. RM-утверждение 6). То же касается возможных представлений. Для каждого обюявленного возможного представления PR типа T должна автоматически определяться операция selector S со следующими свойствами:
a) если представить, что компоненты PR (см. RM-утверждение 5) и параметры S представлены в виде упорядоченных списков, то эти два списка должны содержать одно и то же число элементов n, и обюявленные типы i-тых элементов списков (i = 1, 2, ..., n) должны быть одинаковы;
b) каждое значение типа T должно производиться путем некоторого вызова S;
c) каждый (успешный) вызов S должен производить некоторое значение типа T.
5. Если некоторое обюявленное возможное представление PR для скалярного типа T определено в терминах компонентов C1, C2, ..., Cn (у каждого компонента имеются имя и обюявленный тип), v – значение типа T, а PR(v) – его возможное представление, то PV(v) должно демонстрироваться (иначе говоря, должен быть автоматически определен набор операций только чтения и обновления, такой что:
a) для всех значений v и для всех i (i = 1, 2, ..., n) можно «выбрать» (прочитать значение) компонента Ci PR(v);
b) для любой переменной V типа T и для всех i (i = 1, 2, ..., n) можно обновить V таким образом, что если значениями V до и после обновления являются v и v’ соответственно, то возможные представления PR(v) и PR(v’) отличаются самое большее в их компонентах Ci.
Такой набор операций должен обеспечиваться для каждого возможного представления, обюявленного в определении T.
6. Должен поддерживаться генератор типов TUPLE, т.е. при наличии некоторого заголовка кортежа H (см. RM-утверждение 9) должно быть возможно использовать генерируемый тип TUPLE {H} как основу определения (или, в случае значений, выбора):
a) значений и переменных этого генерируемого типа (см. RM-утверждения 9 и 12);
b) значений атрибутов кортежей и атрибутов заголовка кортежей этого генерируемого типа (RM-утверждение 9);
c) компонентов обюявленных возможных представлений этого генерируемого типа (RM-утверждение 5).
Генерируемый тип TUPLE {H} называется типом кортежей; имя этого типа – TUPLE {H}. К этому типу, его значениям и переменным применима терминология степени, атрибутов и заголовков (RM-утверждение 12), вводимая в RM-утверждении 9. Типы кортежей TUPLE {H1} и TUPLE {H2} совпадают в том и только в том случае, когда H1 = H2. Применимые операции должны включать аналоги операций реляционной алгебры
RENAME, project, EXTEND и JOIN (RM-утверждение 18), а также операции присваивания кортежей (RM-утверждение 21) и сравнения кортежей (RM-утверждение 22); кроме того, должна иметься (a) операция выбора кортежей (RM-утверждение 9), (b) операция извлечения из указанного кортежа значения указанного атрибута (этот кортеж должен иметь степень один – см. RM-утверждение 9) и (c) операции «nesting» и «unnesting» для кортежей.
7. Должен поддерживаться генератор типов RELATION, т.е. при наличии некоторого заголовка отношения H (см. RM-утверждение 10) должна иметься возможность использования генерируемого типа RELATION {H} для определения (или, в случае значений, для выбора):
a) значений и переменных этого генерируемого типа (RM-утверждения 10 и 13);
b) значений атрибутов кортежей и атрибутов заголовка кортежей этого генерируемого типа (RM-утверждение 9);
c) компонентов обюявленных возможных представлений этого генерируемого типа (RM-утверждение 5).
Генерируемый тип RELATION {H} называется типом отношения, и имя этого типа – TUPLE {H}. К этому типу, его значениям и переменным применима терминология степени, атрибутов и заголовков (RM-утверждение 13), вводимая в RM-утверждении 10. Типы отношения RELATION {H1} и RELATION {H2} совпадают в том и только в том случае, когда H1 = H2. Применимые операции должны включать операции реляционной алгебры (RM-утверждение 18), а также операции реляционного присваивания (RM-утверждение 21) и реляционного сравнения (RM-утверждение 22); кроме того, должна иметься (a) операция выбора отношения (RM-утверждение 10), (b) операция извлечения из указанного отношения указанного кортежа (это отношение должно иметь мощность один – см. RM-утверждение 10) и (c) операции «nesting» и «unnesting» для отношений.
8. Для каждого типа должна быть определена операция сравнения по равенству. Если выражения X1 и X2 вырабатывают значения одного и того же типа T v1 и v2 соответственно, то операция X1 = X2 вырабатывает значение true в том и только в том случае, если v1 и v2 в действительности являются одним элементом T. Если Op – это операция с параметром P типа T, то для всех таких операций при условии, что X1 = X2, то эффект двух успешных вызовов Op, в одном из которых аргументом, соответствующим P, является X1, а в другом – X2, должен быть одним и тем же. Наоборот, если эффект двух таких вызовов Op различается, то значением сравнения X1 = X2 должно быть false.
9. Значение кортежа t (или для краткости кортеж) – это множество упорядоченных триплетов , где:
a) A – имя атрибута кортежа t. Никакие два различных триплета t не должны содержать одно и то же имя атрибута;
b) T – имя типа атрибута кортежа t.
c.v – значение типа T, называемое значением атрибута A кортежа t. Мощность множества триплетов в t, или число атрибутов t называется степенью t. Множество упорядоченных пар , получающихся путем удаления компонента v из каждого триплета, является заголовком t. Кортеж t называется соответствующим этому заголовку (принадлежит к соответствующему типу кортежа – см. RM-утверждение 6). Степень заголовка – это степень кортежа, а атрибуты и соответствующие типы заголовка – это атрибуты и соответствующие типы кортежа t. При заданном заголовке H должна быть доступна операция selector для выбора произвольного кортежа, соответствующего H.
10. Значение отношения r (для краткости – отношение) состоит из заголовка и тела, где:
a) заголовком r является заголовок кортежа H (RM-утверждение 9). Отношение r называется соответствующим этому заголовку (принадлежит к соответствующему типу отношения – RM-утверждение 7), а степенью r является степень этого заголовка. Атрибуты и соответствующие типы r – это атрибуты и соответствующие типы H;
b) тело r – это множество B кортежей, каждый из которых имеет заголовок H; мощность тела называется мощностью r.
При заданном заголовке отношения H должна быть доступна операция selector для выбора произвольного отношения, соответствующего H.
11. Скалярная переменная типа T – это переменная, допустимыми значениями которой являются скаляры указанного скалярного типа T, обюявленного типа этой переменной. В языке D должны иметься доступные для пользователей средства определения скалярных переменных. При определении скалярной переменной должна производиться инициализация переменной некоторым значениям – явно указанным в операции определения переменной или не указываемым явно, определенным в реализации.
12. Переменная кортежа типа TUPLE {H} – это переменная, допустимыми значениями которой являются кортежи, соответствующие указанному заголовку кортежа H. Обюявленный тип этой переменной кортежа есть TUPLE {H}. Атрибутами переменной кортежа являются атрибуты H, соответствующие типы – обюявленные типы этих атрибутов, степень переменной кортежа – степень H. В языке D должны иметься доступные для пользователей средства определения переменных кортежей. При определении переменной кортежа должна производиться инициализация переменной некоторым значением – явно указанным в операции определения переменной или не указываемым явно, определенным в реализации.
13. Переменная отношения (для краткости – relvar) типа RELATION {H} – это переменная, допустимыми значениями которой являются отношения, соответствующие указанному заголовку отношения H. Обюявленный тип relvar есть RELATION {H}. Атрибутами relvar являются атрибуты H, соответствующие типы – обюявленные типы этих атрибутов, степень relvar – степень H. В языке D должны иметься доступные для пользователей средства определения и уничтожения переменных relvar базы данных (для тех relvar, которые принадлежат базе данных, а не приложению – см. RM-утверждение 16). Должны также поддерживаться возможности определять relvar на уровне приложений.
14. Переменные relvar базы данных могут быть реальными или виртуальными. Виртуальная relvar – это relvar базы данных, значением которой в любой момент времени является результат вычисления некоторого реляционного выражения, указываемого при определении relvar. Реальная relvar – это НЕ виртуальная relvar базы данных. При определении реальной relvar должна производиться ее инициализация пустым отношением (отношением мощности нуль).
15. По определению у каждой relvar имеется по меньшей мере один возможный ключ. По меньшей мере один такой ключ должен быть определен при определении relvar, и не должно быть возможно ликвидировать все возможные ключи данной relvar (кроме как ликвидировав саму relvar).
16. База данных – это именованный контейнер переменных relvar; содержимой базы данных в любой момент времени – это набор переменных relvar базы данных. Требуемые операции для определения и ликвидации баз данных не должны являться частью языка D.
17. Каждая транзакция должна взаимодействовать в точности с одной базой данных. Однако разные транзакции должны иметь возможность взаимодействия с разными базами данных, и разные базы данных не обязательно должны быть разюединенными. Кроме того, транзакции должны иметь возможность определять новые и уничтожать существующие relvar внутри соответствующей базы данных (см. RM-утверждение 13).
18. В языке D должны поддерживаться обычные операции реляционной алгебры (или их некоторые логические эквиваленты). Конкретно, должны прямо или косвенно поддерживаться по меньшей мере операции RENAME, restrict (WHERE), project, EXTEND, JOIN, UNION, INTERSECT, MINUS, (обобщенная) DIVIDEBY PER и (обобщенная) SUMMIRIZE PER. Все такие операции должны выражаться без чрезмерного многословия. В языке D должен также поддерживаться механизм наследования типов отношения, благодаря чему заголовок результата вычисления реляционного выражения должен быть правильно определенным и известным как системе, так и пользователю (см. RM-утверждение 7).
19. Имена relvar и вызовы селектора отношений должны быть допустимыми реляционными выражениями. В реляционных выражениях должна допускаться рекурсия.
20. В языке D должны поддерживаться средства для определения и уничтожения операций только чтения со значениями-отношениями. Отношение, являющееся результатом вызова такой операции, должно определяться некоторым реляционным выражением, указываемым при определении операции. В этом выражении должно допускаться наличие параметров; такие параметры должны представлять скалярные значения, и их наличие должно допускаться в любом месте, где допускаются вызовы скалярных селекторов. Вызовы таких операций внутри реляционных выражений должны допускаться в любом месте, где разрешаются вызовы селекторов отношений.
21. В языке D должно допускаться:
a) присваивание (значения) скалярного выражения скалярной переменной;
b) присваивание (значения) кортежного выражения переменной кортежа;
c) присваивание (значения) выражения над отношениями relvar.
В каждом случае типы источника и цели должны совпадать. В дополнение к этому в языке D должна поддерживаться множественная форма операции присваивания, в которой несколько отдельных присваиваний выполняются в некоторой указанной последовательности как часть одной логической операции.
22. В языке D должны поддерживаться некоторые операции сравнения, а именно:
a) операции сравнения скаляров должны включать «=» и, возможно, «<», «>» и т.д. (в зависимости от данного скалярного типа);
b) операции сравнения кортежей должны включать «=» и «» (и только);
c) операции сравнения отношений должны включать «=», «», «является подмножеством» и т.д.;
d) должна поддерживаться операция «[» для проверки вхождения кортежа в отношение.
Во всех случаях, кроме «[», операнды должны быть одного типа, а в случае «[» кортеж и отношение должны иметь одинаковые заголовки.
23. Выражение, при вычислении которого вырабатывается истинностное значение, называется логическим выражением (также называемым истинностным, условным или булевским выражением). Ограничением целостности является логическое выражение, которое: a) именовано; b) является замкнутой WFF (Well Formed Formula – правильно построенной формулой) или ее логическим эквивалентом реляционного исчисления; с) при вычислении дает значение true. В языке D должны обеспечиваться средства для определения и уничтожения ограничений целостности. Такие ограничения классифицируются на ограничения домена (т.е. типа), атрибута, relvar и базы данных, и в языке D должен поддерживаться механизм наследования ограничений (насколько это возможно).
24. Для каждой relvar имеется соответствующий предикат relvar, и для каждой базы данных имеется соответствующий предикат базы данных.
Предикаты relvar должны удовлетворяться в границах оператора. Предикаты базы данных должны удовлетворяться в границах транзакции.
25. Каждая база данных должна включать набор relvar, составляющих каталог этой базы данных. Должна существовать возможность производить присваивания relvar каталога.
26. Язык D должен конструироваться в соответствии с установившимися принципами правильной разработки языка.
Отрицательные RM-утверждения
1. Язык D не должен содержать конструкции, зависящие от определения какой бы то ни было упорядоченности атрибутов отношений. Для каждого отношения r, выражаемого средствами D, атрибуты r должны различаться своими именами.
2. Язык D не должен содержать конструкции, зависящие от определения какого бы то ни было порядка кортежей отношения.
3. Для каждого отношения r, если t1 и t2 являются разными кортежами этого отношения, должен существовать такой атрибут A отношения, что сравнение «A FROM t1 = A FROM t2» принимает значение false (выражения A FROM t1 и A FROM t2 означают значения атрибута A в кортежах t1 и t2 соответственно).
4. Каждый атрибут каждого кортежа должен иметь значение, причем соответствующего типа.
Это один из первых намеков Дейта и Дарвена на то, что не должны поддерживаться неопределенные значения (NULL). С моей точки зрения, при всех отрицательных явлениях, порождаемых неопределенными значениями, пока Дейту и Дарвену не удалось предложить альтернативный работающий подход.
5. В языке D должно учитываться, что отношения без атрибутов приемлемы и интересны и что то же относится к возможным ключам без компонентов.
6. Язык D не должен содержать конструкции, которые связаны с «физическими» уровнями системы (уровнями хранения, внутренними уровнями) или образованы под логическим влиянием этих уровней.
7. Не должно быть покортежных операций на relvar или отношениями.
8. В языке D не должны поддерживаться «составные домены» или «составные атрибуты», поскольку подобной функциональности можно достичь, если это желательно, на основе описанной выше поддержки типов.
9. Операции, в которых требуется нарушение ограничений доменов, являются нештатными и необязательными, и они не должны поддерживаться.
10. Язык D не должен называться SQL.
Положительные OO-утверждения
Этот раздел явно подчеркивает трактовку Дейта и Дарвена аббревиатуры OO как «Other Orthogonal», а не как «Object-Oriented». По сути дела, ни одно из положительных OO-утверждений не имеет прямого отношения к обюектной ориентации.
1. В языке D должна допускаться проверка типов во время компиляции.
2. Если в языке D допускается определение некоторого типа T’ как подтипа некоторого супертипа T, то такая возможность должна соответствовать некоторой четко определенной и общепризнанной модели.
3. Если в языке D допускается определение типа T’ как подтипа некоторого другого типа T, то это не противоречит тому, чтобы T’ определялся как подтип и некоторого иного типа, который не является типом T или каким-либо супертипом T (если требования Утверждения 2 не запрещают такую возможность).
4. Язык D должен быть вычислительно полным. В языке D может иметься (но не должна требоваться) поддержка вызова из так называемых «основных программ», написанных на языках, отличных от D. Аналогично, в языке D может иметься (но не должна требоваться) поддержка использования других языков программирования для реализации определяемых пользователями операций.
5. Инициация транзакций должны производиться только средствами явного выполнения операции «begin transaction». Завершение транзакции должно производиться только средствами выполнения операций «commit» или «rollback»; фиксация всегда должна быть явной, а откат может быть неявным (если транзакция завершается неуспешно не по своей вине). Если транзакция TX завершается выполнением операции commit («нормальное завершение»), то изменения, произведенные TX в соответствующей базе данных, должны быть зафиксированы. Если транзакция TX завершается выполнением операции rollback («ненормальное завершение»), то изменения, произведенные транзакцией TX в соответствующей базе данных, должны быть аннулированы.
6. В языке D должны поддерживаться вложенные транзакции, т.е. должно допускаться образование транзакцией-предком TX транзакции-потомка TX’ до завершения транзакции TX. При этом:
a) TX и TX’ должны взаимодействовать с одной и той же базой данных (что в действительности требуется RM-требованием 17);
b) не требуется задержка выполнения TX на время выполнения TX’ (хотя это и допускается). Однако TX не должна завершаться до завершения TX’; другими словами, TX’ должна полностью содержаться в TX.
c) откат TX должен включать откат TX’, даже если TX’ завершилась фиксацией. Другими словами, «фиксация» всегда интерпретируется в контексте предка (если он существует) и может быть отменена транзакцией-предком.
7. Пусть AggOp – агрегатная операция, такая как SUM. Если аргумент AggOp является пустым, то:
a) если AggOp является сокращенной формой некоторой итеративной бинарной операции Op (в случае SUM это операция «+») и если для Op существует начальное значение (0 в случае SUM), то результатом вызова AggOp должно быть это начальное значение;
b) в противном случае результат вызова AggOp должен быть неопределенным.
Последнее OO-утверждение вновь явно направлено на избавление от неопределенных значений. Но для меня совершенно неочевидно, что при сложении пустого набора чисел должно получиться значение 0. Кроме того, во-вторых, во второй части этого утверждения появляется словосочетание «неопределенный результат», но что это значит, формально не поясняется.
Отрицательные OO-утверждения
1. Переменные Relvar – это не домены.
2. Никакое значение не должно обладать каким-либо идентификатором ID, отличным от самого этого значения.
Как видно, это очередной «наезд» на обюектно-ориентированный мир. Но утверждение не слишком корректное, поскольку в обюектном мире никто и никогда не утверждал, что у значений должны существовать идентификаторы. Говорится про «object identity», то есть про существование уникальной идентификации обюектов. Но Дейт и Дарвен, похоже, вообще не хотят соглашаться с наличием понятия обюекта.
Очень строгие RM-суждения
1. В языке D следует обеспечить механизм, в соответствии с которым значения некоторого определенного возможного ключа (или его компонентов) для некоторой указанной relvar поставляются системой. Следует также обеспечить механизм, в соответствии с которым произвольное отношение может быть расширено атрибутом, значения которого: a) уникальны внутри этого отношения (или внутри некоторых разделов этого отношения); b) поставляются системой.
2. В язык D следует включить некоторую декларативную сокращенную форму для выражения ссылочных ограничений (называемых также ограничениями внешнего ключа).
3. Если RX – реляционное выражение, то по определению RX можно считать обозначением relvar R – либо определенной пользователем (если RX состоит только из имени relvar), либо определяемой системой (в противном случае). Желательно, хотя и не всегда возможно, чтобы система была в состоянии выводить возможные ключи R таким образом, что:
a) если RX предназначено для определения выражения для некоторой виртуальной relvar R’, то эти выводимые возможные ключи можно проверить на соответствие возможным ключам, явно определяемым для R’. Если конфликт не обнаруживается, то выводимые ключи становятся возможными ключами R’;
b) сведения о выводимых ключах могут быть включены в информацию об R, доступную пользователям языка D.
В языке D следует поддерживать такие возможности, но без какой-либо гарантии того, что: a) эти выводимые ключи не составляют точного надмножества множества реальных возможных ключей; b) выводимый возможный ключ обнаружен для каждого реального возможного ключа.
4. В языке D следует поддерживать ограничения переходов, т.е. ограничения на допустимые изменения значений данных relvar или базы данных.
5. В языке D следует поддерживать некоторую сокращенную форму для выражения запросов с квотами. Для формулировки подобных запросов не должно требоваться преобразование соответствующего отношения, например, в массив.
6. В языке D следует поддерживать некоторую сокращенную форму для выражения операции обобщенного транзитивного замыкания, включая возможность определения обобщенных операций конкатенации и агрегации.
7. В языке D следует допустить, чтобы параметры определяемых пользователями операций (включая операции над значениями-отношениями, см. RM-утверждение 20) могли быть кортежами, отношениями или скалярами.
8. Для работы с «отсутствующей информацией» в языке D следует обеспечить некоторый механизм специальных значений.
9. Следует обеспечить возможность реализации языка SQL средствами языка D – не потому, что такая реализация желательна сама по себе, а в связи с тем, что это обеспечит безболезненный переход к D для пользователей SQL. С той же целью следует обеспечить возможность преобразования существующих баз данных SQL в такую форму, с которой D-программы могли бы работать без ошибок.
У меня есть сильные сомнения относительно реальности последнего суждения. В прошлом предпринимались многочисленные попытки реализации SQL с использованием реляционной алгебры, и они приводили к необходимости очень сильных расширений алгебры. При той реляционной чистоте, которую Дейт и Дарвен требуют от языка D, его возможностей, скорее всего, не хватит для реализации огромного и разнородного языка SQL.
Очень строгие OO-суждения
1. В языке D следует поддерживать некоторую форму наследования типов (см. OO-утверждения 2 и 3). В соответствии с этим суждением в языке D не следует поддерживать неявные преобразования типов.
2. Следует поддерживать логическое различие между определениями операций и определениями типов их параметров и/или результатов, не связывая эти определения в один узел (хотя селекторы и операции, требуемые в RM-утверждении 5 можно рассматривать как исключения по отношению к этому суждению).
3. Следует поддерживать генераторы типов коллекций, такие как LIST, ARRAY и SET, распространенные в языках с развитыми системами типов.
4. Для любого генератора типа коллекции С, отличного от RELATION, следует обеспечить операцию преобразования (скажем, C2R) для преобразования значений типа C в отношения и обратную операцию (скажем, R2C) таким образом, что:
a) C2R(R2C(r)) = r для любого выразимого r;
b) R2C(C2R(c)) = c для любого выразимого значения c типа C.
5. Следует основывать язык D на одноуровневой модели хранения.
Новая реляционная алгебра
В четвертой главе книги предлагается новая реляционная алгебра, которую Дейт и Дарвен называют A – двойной рекурсивный акроним от ALGEBRA, что, в свою очередь, раскрывается в «A Logical Genesis
Explains Basic Relational Algebra». Основная цель, которая преследовалась при разработке алгебры A, состояла в том, чтобы более четко показать связь этой дисциплины с логикой первого порядка.
Алгебра A отличается от оригинальной алгебры Кодда четырьмя основными аспектами.
Операция декартова произведения (TIMES) заменена операцией естественного соединения, которую, подчеркивая наличие двойника этой операции в логике предикатов, Дейт и Дарвен называют просто >AND<. TIMES становится частным случаем >AND<. [Замечание: имена операций алгебры A обрамляются символами «>» и «<», чтобы отличать их от соответствующих имен операций логики предикатов из Tutorial D. Имя >AND< не должно вводить в заблуждение, конечно, оно обозначает реляционную операцию (ее результатом является отношение), в то время как ее двойник из логики предикатов and является логической операцией (возвращает истинностное значение). Аналогичные замечания относятся и к операциям >OR< и >NOT<.]
Операция UNION заменена более общей операцией >OR<, для применения которой не требуется совпадение заголовков отношений-операндов. UNION становится частным случаем >OR<.
В алгебру включена операция реляционного дополнения >NOT<. Наличие этой операции позволяет исключить операцию вычитания (MINUS), которая становится частным случаем комбинации >AND< и >NOT<.
Дейт и Дарвен обходятся без операций restrict (WHERE), EXTEND и SUMMARIZE, поскольку эти операции являются частным случаем >AND<.
Кроме перечисленных трех операций в состав алгебры A входят операции >RENAME<, >REMOTE< и >COMPOSE<, а также операция транзитивного замыкания >TCLOSE<.
Мотивация и обоснование
Для простоты в этом разделе используется не слишком формальный подход. В частности, вместо введенного в третьей главе формального определения кортежа здесь под кортежем понимается разделяемый запятыми список значений. Поскольку в этой главе активно используются идеи логики предикатов, требуется ряд комментариев по поводу терминологии.
Переменные, появляющиеся в предикатах, называются заменителями (placeholder). Заменители являются логическими переменными, а не переменными в смысле языка программирования, поэтому Дейт и Дарвен предпочитают использовать другой термин.
Для обозначения числа заменителей в предикате используются слова с греческим суффиксом -adic, а для обозначения степени отношения – слова с латинским суффиксом -ary. Например, предикат «Служащий E работает в отделе D» является диадным, а отношение, соответствующее этому предикату (см. RM-утверждение 10), – бинарным.
Необходимость разработки алгебры A авторы обюясняют следующими целями:
По психологическим соображениям Дейт и Дарвен искали набор операций, для которых существуют непосредственные двойники в логике, и в меньшей степени опирались на теорию множеств. По мнению авторов, этот подход позволяет лучше осмыслять и понимать реляционную теорию.
В предшествовавших алгебрах имелось более одной операции, соответствующей логической операции and. Эта избыточность казалась Дейту и Дарвену неправильной, и они ее устранили.
Дейт и Дарвен хотели, чтобы реляционные операции Tutorial D отображались в выражения алгебры A. Детали этого отображения содержатся в пятой главе книги.
Ниже приведено более подробное обсуждение четырех принципиальных отличий A от предшествовавших алгебр.
Отсутствие TIMES
Когда в логике два предиката соединяются связкой and, нужно обращать внимание на имена заменителей. Любое имя заменителя, которое появляется в обоих предикатах, должно пониматься как обозначающее одно и то же в новообразованном предикате. Например, рассмотрим два предиката, выраженные на естественном языке: «Служащий E работает в отделе D» и «Служащий E работает над проектом J». Связка этих двух предикатов с использованием and порождает триадный, а не тетрадный предикат: «Служащий E работает в отделе D и служащий E работает над проектом J». Этот предикат можно представить в сокращенной форме «Служащий E работает в отделе D над проектом J», чтобы подчеркнуть тот факт, что мы не можем подставить некоторого конкретного служащего для E, который работает в отделе D, не подставив того же служащего для E, работающего над проектом J. Это наблюдение позволяет заметить, что заменители тесно связаны с хорошо известной операцией естественного соединения и, конечно, с операцией >AND< алгебры A.
Что касается операции TIMES, она, конечно, является частным случаем соединения (>AND< в алгебре A). Более точно, TIMES соответствует связке через and двух предикатов без общих заменителей, например, «Служащий E работает в отделе D, и у проекта J имеется бюджет B».
Кстати, приведенная выше сокращенная формулировка предиката может привести к ошибочному заключению, что проект J каким-то образом связан с отделом D. Кодд называл этот вид ошибок «ловушкой связи», а позже его иногда называли «ловушкой соединений», что не очень удачно, поскольку ситуация не уникальна для соединений и реляционных операций вообще.
Отсутствие UNION
Предикаты естественного языка могут комбинироваться не только с помощью and, но и с помощью or. Триадному предикату «Служащий E работает в отделе D или служащий E работает над проектом J» соответствует тернарное отношение. Если служащий EX работает в отделе DX, то кортеж (EX, DX, J) входит в тело этого отношения для всех возможных проектов J независимо от того, работает ли реально служащий EX над проектом J (и даже независимо от того, выполняется ли проект J в это время в компании). Аналогично, если служащий EX работает над проектом JX, то кортеж (EX, D, JX) входит в тело отношения для всех возможных отделов D независимо от того, работает ли реально служащий EX в отделе D (и даже независимо от того, существует ли отдел D в это время в компании).
Операция >OR< вводится в алгебру A как двойник операции or. Классическая операция UNION является частным случаем >OR< и соответствует связыванию через or двух предикатов, которые содержат в точности один и тот же набор заменителей, например, «Служащий E работает в отделе D или служащий E прикомандирован к отделу D».
Здесь и далее Дейт и Дарвен умышленно оставляют в стороне вычислительные проблемы выполнения операции.
Отсутствие MINUS
Пусть WORKS_IN – это отношение с атрибутами E (служащий) и D (отдел), а соответствующий предикат – «Служащий E работает в отделе D».
Тело логического дополнения (>NOT<) этого отношения состоит из всех возможных кортежей в форме (E, D), для которых неверно, что служащий E работает в отделе D.
Для того чтобы продемонстрировать возможность устранения операции MINUS, рассмотрим следующий пример. Предположим, что в придачу к отношению WORKS_IN имеется отношение WORKS_ON с атрибутами E и J (проект), а соответствующий предикат – «Служащий E работает над проектом J». Рассмотрим теперь унарное отношение, соответствующее монадному предикату «Служащий E работает в некотором отделе, но не работает ни над каким проектом». К алгебре Кодда это отношение можно было бы получить, спроецировав отношения WORKS_IN и WORKS_ON на атрибут E и взяв затем соответствующую разность. В алгебре A мы сначала проецируем WORKS_ON на E, а затем берем >NOT< от этой проекции; соответствующим предикатом будет «Не существует такого проекта, над которым бы работал служащий E». Потом это отношение можно соединить (>AND<) с отношением WORKS_IN, и проекция этого соединения на E даст искомый результат.
Отсутствие restrict (WHERE), EXTEND и SUMMARIZE
При выполнении restrict (WHERE), EXTEND и SUMMARIZE требуются вызовы некоторых операций. В случае restrict эти операции возвращают значения (инстинностные значения), используемые для предотвращения появления некоторых кортежей в результирующем отношении; в случае EXTEND и SUMMARIZE операции возвращают значения, на основе которых определяются некоторые атрибуты результирующего отношения.
Для целей, которыми руководствуются Дейт и Дарвен, имеет смысл и может быть полезно рассматривать такие операции как отношения. Рассмотрим операцию Op, являющуюся скалярной функции (операцию, возвращающую в точности один результат, являющийся скалярным значением). Предположим, что у Op имеется n параметров. Тогда можно трактовать Op как отношение с n+1 атрибутами, по одному на каждый параметр и один на результат.
Конечно, атрибуты, соответствующие параметрам, образуют возможный ключ этого отношения; однако это возможный ключ может не быть единственным. Например, если PLUS – это отношение с атрибутами X, Y и Z, тип каждого из которых INTEGER, и это отношение соответствует скалярной функции «+» целой арифметики и предикату «X + Y = Z», то возможными ключами отношения являются комбинации {X, Y}, {X, Z} и {Y, Z}, а в тело отношения входит по одному кортежу (X, Y, Z) для всех возможных комбинаций X, Y, Z, удовлетворяющих предикату.
[Замечание. По аналогии с relvar можно относиться к отношениям типа PLUS как к relcon, или как к реляционным константам: они именованы, но их значения не изменяются во времени. И, конечно, упоминавшиеся возможные ключи – это ключи реляционной константы, а не реляционной переменной.]
Итак, скалярная функция является частным случаем отношения. Более точно, любое отношение можно рассматривать как операцию, отображающую некоторое подмножество его атрибутов на оставшиеся атрибуты; если это отображение является функциональным (много-к-одному), то отношение можно считать функцией. Поскольку у множества из n элементов имеется 2n подмножеств, отношение степени n можно считать представлением 2n различных операций, некоторые из которых функции, а некоторые – нет (в общем случае). Например, если рассматривать PLUS как операцию, отображающую Z в X и Y, то это отображение не функционально (не поддерживаются функциональные зависимости Z->X и Z->Y), и соответствующая операция не является функцией.
В следующем разделе показывается, что при подобной трактовке операций и наличии операций алгебры A >AND<, >REMOVE< и >RENAME< можно отказаться от непосредственной поддержки операций restrict, EXTEND и SUMMARIZE.
>REMOVE<, >RENAME< и >COMPOSE<
Операция >REMOVE< является двойником в алгебре A квантора существования логики предикатов. Она соответствует операции project Кодда. Отличие состоит в том, что в >REMOVE< указываются не атрибуты, которые должны сохраниться в результате, а атрибуты, которые следует удалить. Мотивация Дейта и Дарвена является психологической: проекция отношения с атрибутами X и Y на X эквивалентна квантификации существования по Y. Например, проекция WORKS_IN на E эквивалентна предикату на естественном языке «Существует некоторый отдел D такой, что служащий E работает в отделе D».
>RENAME< («переименовать некоторый атрибут некоторого отношения») – это еще одна примитивная операция алгебры A. Такая операция существенна для любого конкретного синтаксиса реляционных выражений, в котором атрибуты различаются по именам.
«Макро»-операция >COMPOSE< является комбинацией >AND< и >REMOTE<. При выполнении операции к общим атрибутам отношений, для которых выполняется >AND<, затем применяется >REMOTE<. Имя операции >COMPOSE< отражает то суждение, что такая реляционная композиция является естественным обобщением функциональной композии (композицией двух функций f (...) и g (...) – в таком порядке – является функция f (g (...) )). Операция реляционной композиции упоминалась в ранних статьях Кодда, но в последствии по некоторым причинам он ее устранил; Д&Д сочли эту операцию полезной для поддержки их намерения трактовать операции как отношения.
Заключительные замечания
Должно быть ясно, что алгебра A реляционно полна. В предыдущих алгебрах для этого требовалось шесть операций (обычно RENAME, restrict, project, TIMES, UNION и MINUS); Дейту и Дарвену удалось сократить их число до пяти. Благодаря тому, что операции трактуются как отношения, удалось обойтись без операций EXTEND и SUMMARIZE.
На самом деле алгебра A «более чем» реляционно полна: неограниченные операции и >OR< и >NOT< позволяют определить отношения, которые было невозможно определить в предыдущих алгебрах. Это замечание является чисто академическим, поскольку на практике операции >OR< и >NOT< не будут полностью неограниченными, поскольку в противном смысле возникают определенные вычислительные проблемы.
В соответствии с законами Де Моргана для достижения реляционной полноты не обязательно поддерживать обе операции >AND< и >OR<. Например, A>ANDNOT<((>NOTOR<(>NOTNOT< и >OR< можно было бы отказаться от >AND<. Можно было бы даже свернуть >NOT< и >OR< в одну операцию >NOR< («neither A nor B», что эквивалентно «not A and not B»). Аналогичным образом можно было отказаться от >OR< и свернуть >AND< и >NOT< в одну операцию >NAND< («not A or not B»). В результате при желании можно сократить алгебру A всего лишь до трех операций: >RENAME<, >REMOVE< и либо >NOR<, либо >NAND< (плюс операция >TCLOSE<, обсуждаемая ниже).
Конечно, Дейт и Дарвен не считают, что все эти операции можно действительно удалить из конкретного синтаксиса языка D, поскольку они являются полезными и удобными сокращенными формами. Но их следует явно определить как сокращенные формы.
Обращение с операциями как с отношениями
Обратимся вновь к отношению PLUS с целочисленными атрибутами X, Y и Z, соответствующему предикату «X + Y = Z». Пусть TWO_AND_TWO – это (уникальное) отношение, тело которого состоит из единственного кортежа
{ < X, INTEGER, 2 >,
}
Тогда выражение
TWO_AND_TWO >COMPOSE< PLUS
произведет отношение, тело которого состоит из единственного кортежа
{ < Z, INTEGER, 4> }
Тем самым фактически была вызвана операция «+» с аргументами X = 2 и Y = 2, и был получен результат Z = 4 (заметим, что у результата имеется имя Z; Дейт и Дарвен изучают возможные последствия этого для языка D). Конечно, этот результат является встроенным как значение атрибута внутри кортежа отношения. Чтобы извлечь результат в виде чистого скалярного значения, необходимо выйти за пределы алгебры A и применить операции (требуемые RM-утверждениями 7 и 6 соответственно) для: a) извлечения указанного кортежа из указанного отношения; b) для извлечения значения указанного атрибута из указанного кортежа. В терминах языка TUTORIAL D эти извлечения можно выполнить следующим образом:
Z FROM ( TUPLE FROM ( result ) )
где result обозначает результат вычисления A-выражения TWO_AND_TWO >COMPOSE< PLUS.
Однако для целей этого раздела Дейт и Дарвен интересуются обхождением с операциями как с отношениями в чисто реляционном контексте. В частности, этот подход позволяет обюяснить суть классической реляционной операции EXTEND чисто реляционным образом.
Рассмотрим выражение TWO_AND_ TWO >AND< PLUS. Результатом этого выражения является отношение, тело которого состоит в точности из одного кортежа
{ < X, INTEGER, 2 >, < Y,
INTEGER, 2 >, < Z, INTEGER, 2 > }
Следует понимать, что это выражение A логически эквивалентно следующему расширению на языке Tuturial D:
EXTEND TWO_AND_TWO ADD X + Y AS Z
Этого примера достаточно, чтобы показать, каким образом можно отказаться от операции EXTEND. Более того, то же самое выражение логически эквивалентно следующем ограничению на языке Tutorial D:
PLUS WHERE X = 2 AND Y = 2
Этого примера достаточно, чтобы показать, каким образом можно отказаться от restrict.
Что касается операции SUMMARIZE, то хорошо известно, что любое суммирование можно выразить в терминах EXTEND, а не самой SUMMARIZE. Из этого следует, что можно отказаться и от SUMMARIZE.
В конце раздела Дейт и Дарвен отмечают, что не только со скалярными функциями можно обращаться как с отношениями. Вот примеры.
Пример скалярной операции, не являющейся функцией, представляет SQRT («квадратный корень»). Для заданного положительного аргумента эта операция вырабатывает два различных значения. Например, SQRT(4.0) возвращает +2.0 и -2.0.
Пример операции, являющейся функцией, но не скалярной, представляет ADDR_OF («адрес»). Эта операция для заданного служащего возвращает адрес этого служащего в виде коллекции из четырех значений (STREET, CITY, STATE, ZIP).
Рассмотрим эти примеры немного детальнее. Очевидно, что SORT можно воспринимать как отношение с атрибутами, например, X и Y типа RATIONAL. Но это отношение не является функцией, поскольку отсутствует функциональная зависимость YаX (например, одновременно присутствуют кортежи (4.0, +2.0) и (4.0, -2.0)). (С другой стороны, функциональная зависимость XаY поддерживается.) Это отношение содержит:
Для x = 0 ровно один кортеж с X = x
Для x > 0 ровно два кортежа с X = x
Для x < 0 ни одного кортежа с X = x
Из этого следует, что выражение
SQRT >COMPOSE< { { < X, RATIONAL, 4.0 > } }
по сути дела представляет вызов операции SQRT, но при вызове образуются два результата. Более точно, производится унарное отношение со следующим телом:
{ { < Y, RATIONAL, +2.0 > },
< Y, RATIONAL, -2.0 > } }
(При желании теперь можно по отдельности выбрать из результата каждый из этих кортежей, а потом по отдельности извлечь из этих кортежей каждое из двух скалярных значений.) Один из выводов авторов состоит в том, что в реляционном языке D может оказаться разумным поддерживать расширенную форму EXTEND, не обязательно гарантирующую появление ровно одного выходного кортежа для каждого входного кортежа.
Очевидно, что можно обращаться как с отношением и с операцией ADDR_OF. Это отношение имело бы атрибуты E, STREET, CITY, STATE и ZIP, а атрибут E был бы возможным ключом. Поэтому выражение
{ { < E, EMPLOYEE, e > } } >COMPOSE< ADDR_OF
(e обозначает некоторого служащего) на самом деле представляет вызов операции ADDR_OF, возвращающий не скалярное значение. Дейт и Дарвен делают из этого следующий вывод: в языке D может оказаться разумным поддерживать расширенную форму EXTEND, не обязательно гарантирующую. появление ровно одного дополнительного атрибута.
Формальные определения
Поскольку этот раздел носит весьма формальный характер, авторы начинают его с повтора некоторых необходимых определений. Пусть r – отношение, A – имя атрибута r, T – тип атрибута A, v – значение типа T. Тогда.
Заголовок Hr отношения r – это множество упорядоченных пар вида , по одной такой паре для каждого атрибута A r. По определению никакие две пары в этом множестве не могут содержать одно и то же имя атрибута A.
Пусть tr – это кортеж, соответствующий Hr; т.е. tr – это множество упорядоченных кортежей вида по одному такому кортежу для каждого атрибута A Hr.
Тело Br отношения r – это множество таких кортежей tr. Заметим, что в общем случае могут существовать такие кортежи tr, соответствующие Hr, но не появляющиеся в Br.
Заметим, что заголовок – это множество, тело – это множество, и кортеж – это множество. Элемент заголовка – это упорядоченная пара вида ; элемент тела – это кортеж; элемент кортежа – это упорядоченный триплет вида . Любое подмножество заголовка – это заголовок, любое подмножество тела – это тело, и любое подмножество кортежа – это кортеж.
Теперь можно определить операции. Каждое из определений состоит из: формальной спецификации ограничений (если они имеются), применимых к операндам соответствующей операции; формальной спецификации заголовка результата операции; формальной спецификации тела результата; неформального обсуждения формальных спецификаций.
Пусть s есть >NOT< r.
Hs = Hr
Bs = { ts : exists tr ( tr П Br and ts = tr ) }
Операция >NOT< производит дополнение s заданного отношения r. Заголовком s является заголовок r. Тело s включает все кортежи с этим заголовком, не входящие в тело r.
Пусть s есть r >REMOVE< A. Требуется, чтобы существовал некоторый тип T такой, что ‰? Hr.
Hs = Hr minus { }
Ds = { ts : exists tr exists v
( tr ‰?Br and v ‰? T and ‰? tr
and ts = tr minus { } ) }
Операция >REMOVE< производит отношение s, формируемое путем удаления указанного атрибута A из данного отношения r. Операция эквивалентна взятию проекции r на все атрибуты, кроме A. Заголовок s получается вычитанием из заголовка r пары . Тело s состоит из таких кортежей, которые соответствуют заголовку и каждый из которых является подмножеством некоторого кортежа r.
Пусть s есть r >RENAME< (A, B). Требуется, чтобы существовал некоторый тип T такой, что ‰? Hr и чтобы не существовал какой-либо тип T такой, что
‰? Hr.
Hs = ( Hr minus { } ) union {
}
Bs = { ts : exists tr exists v
( tr ‰? Br and v ‰? T and ‰? tr
and
ts = ( tr minus { } )
union { } )
Операция >RENAME< производит отношение s, которое отличается от заданного отношения r только именем одного атрибута, которое изменяется с A на B. Заголовок s такой же, как заголовок r за исключением того, что пара заменяется на пару . Тело s включает все кортежи тела r, но в каждом из этих кортежей триплет заменяется на триплет .
Пусть s есть r1 >AND< r2. Требуется, что если ‰? Hr1 и ‰? Bs = { ts : exists tr1 exists tr2 ( ( tr1 ‰? Br1 and tr2 ‰? Br2 ) and ts = tr1 union tr2 ) }
Операция >AND< является реляционной конююнкцией, производящей результат, называвшийся ранее в литературе естественным соединением заданных отношений r1 и r2. Заголовок s является обюединением заголовков r1 и r2. Тело s состоит из всех кортежей, соответствующих заголовку s и являющихся надмножеством некоторого кортежа из тела r1 и некоторого кортежа из тела r2. Операцию >AND< можно было бы логически назвать conjoin (конююнктивным соединением).
Пусть s есть r1 >OR< r2. Требуется, что если ‰? Hr1 и ‰? Hr2, то должно быть T1 = T2.
Hs = Hr1 union Hr2
Bs = { ts : exists tr1 exists tr2
( ( tr1 ‰? Br1 or tr2 ‰? Br2 ) and
ts = tr1 union tr2 ) }
Операция >OR< является реляционной дизююнкцией, являясь обобщением того, что ранее в литературе называлось обюединением (в этом частном случае заданные отношения r1 и r2 имеют одинаковые заголовки, и результат s является обюединением этих двух отношений в традиционном смысле). Заголовок s есть обюединение заголовков r1 и r2. Тело s состоит из всех кортежей, соответствующих заголовку s и являющихся надмножеством либо некоторого кортежа из тела r1, либо некоторого кортежа из тела r2. Операцию >OR< можно было бы логически назвать disjoin (дизююнктивным соединением).
Наконец, определим «макро»-операцию >COMPOSE<. Пусть s есть r1 >COMPOSE< r2 (r1 и r2 должны удовлетворять тем же требованиям, что и для >AND<). Пусть общими атрибутами для r1 и r2 являются A1, A2, ..., An (n ? 0). Тогда s определяется как результат выражения
( r1 >AND< r2 ) >REMOVE< An ... >REMOVE< A2 >REMOVE< A1
При n = 0 r1 >COMPOSE< r2 – это то же самое, что r1 >AND< r2, что, в свою очередь, то же самое, что r1 TIMES r2 в алгебре Кодда.
Транзитивное замыкание
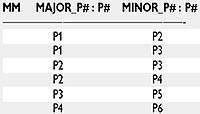 |
| Рис. 1. Отношение MM |
Алгебра A отходит от оригинальной алгебры Кодда еще в одном отношении: она включает явную операцию транзитивного замыкания >TCLOSE<. Чтобы обюяснить, как работает операция, рассмотрим отношение MM (рис. 1). Это отношение является примером того, что иногда называют диграфовым отношением, поскольку его можно представить как направленный граф.
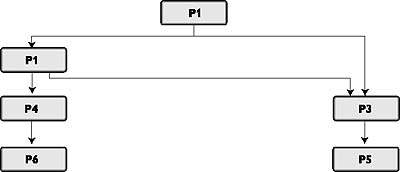 |
| Рис. 2. Граф отношения MM |
Из интуитивных соображений иногда удобнее преобразовать направленный граф (рис. 2) в виде числовой иерархии с возможно повторяющимися узлами (рис. 3). Конечно, эти два графа информационно эквивалентны.
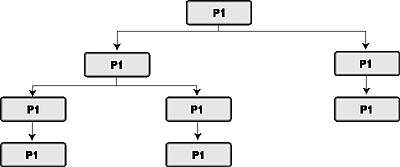 |
| Рис. 3. Граф отношения MM в виде иерархии |
Поскольку MM является бинарным отношением, к нему можно применить операцию транзитивного замыкания. Операция описывается следующим образом:
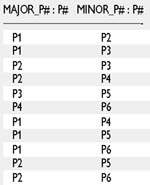 |
| Рис. 4. Транзитивное замыкание MM |
Пусть r – это бинарное отношение с атрибутами X и Y одного и того же типа T. Тогда транзитивное замыкание r (>TCLOSE< r) – это отношение r+ с тем же заголовком, что у r, и телом, являющимся надмножеством тела r, определяемым следующим образом: Кортеж
{ < X, T, x >, }
входит в r+ том и только в том случае, когда он входит в r или существует последовательность значений z1, z2, ..., zn (все типа T) таких, что кортежи
{ < X, T, x >, < Y, T, z1 > }
{ < X, T, z1 >, < Y, T, z2 > }
........................
{ < X, T, zn >, < Y, T, y > }
все входят в r. Другими словами кортеж «(x, y)» входит в результат, только если существует путь в графе из узла x в узел y. Вот результат транзитивного замыкания отношения MM (рис. 4).
Содержание обозреваемых глав книги
Глава 3. Третий манифест
Положительные RM-утверждения
Отрицательные RM-утверждения
Положительные OO-утверждения
Отрицательные OO-утверждения
Очень строгие RM-суждения
Очень строгие OO-суждения
Глава 4. Новая реляционная алгебра
Введение
Мотивация и обоснование
>REMOVE<, >RENAME< и >COMPOSE<
Заключительные замечания
Обращение с операциями как с отношениями
Формальные определения
Транзитивное замыкание
