

Кластерная архитектура предусматривает объединение нескольких вычислительных узлов с помощью высокоскоростных каналов. В настоящее время это один из наиболее перспективных подходов к реализации высокопроизводительных вычислительных систем.

Концепция высокопроизводительных кластерных систем отмечает свое десятилетие: она получила широкое распространение в 1994 г., с появлением кластеров Beowulf. За прошедшее время накоплен немалый опыт в области параллельных вычислений. Рабочая группа IEEE по кластерным вычислениям (Task Force on Cluster Computing, TFCC) регулярно выпускает официальные документы, освещающие состояние дел в сфере кластерных архитектур. Мировой рынок таких решений стал достаточно зрелым и сложившимся, что, впрочем, не мешает появлению новых компаний. Сегодня он активно формируется и в России. Главный рычаг этого процесса — короткие сроки окупаемости подобных комплексов.
В отличие от кластерных систем высокой готовности (High Availability, HA), важнейшим свойством которых является обеспечение надежности за счет дублирования компонентов, кластеры для высокопроизводительных вычислений (High Perfomance Computing, HPC) реализуются с целью достижения максимальной вычислительной мощности, что, естественно, делается не только в расчете на рекорды. Они применяются для решения вполне реальных задач расчета прочности, гидродинамики, метеорологии, моделирования термоядерного синтеза, автомобилестроения, фармацевтики, авиации, геофизических исследований, государственного управления.
ЦЕНА УНИВЕРСАЛЬНОСТИ
Некоторые задачи, включая моделирование ядерного взрыва или расшифровку генома, не могли бы быть выполнены без применения систем HPC. По стоимости капитальных и эксплуатационных затрат кластеры HPC в несколько раз дешевле, чем системы MPP и суперкомпьютеры аналогичной мощности, в основе которых нередко лежат уникальные программные и аппаратные средства, а потому способны составить им реальную конкуренцию. Например, система IBM eServer x335 (34 двухпроцессорных узла, процессор Intel Xeon, ОС Linux) в шесть раз превосходит по производительности 80-процессорную систему MPP от SGI и при этом стоит в полтора-два раза дешевле.
В прошлом году в число самых мощных суперкомпьютеров (Top500) вошла система Terascale Cluster (Big Mac) с производительностью 9,6 TFLOPS, состоящая из 1100 компьютеров Apple Mac. В ней используются 2200 процессоров IBM PowerPC. Кластер применяется для научных исследований в таких областях, как наноэлектроника, аэродинамика и молекулярное моделирование белковых структур. Кластер с высокоскоростной сетью Infiniband работает под управлением операционной системы Mac OS X и объединяет 1100 компьютеров G5. При производительности в 10,3 TFLOPS он в 30 раз дешевле суперкомпьютеров NEC и HP, лидирующих в Top500, а по быстродействию лишь немногим уступает системе HP. Совместно с техническим колледжем шт. Вирджиния Apple строит еще одну систему, где будут установлены 64-разрядные компьютеры Xserve G5 на базе тех же процессоров PowerPC 970.
В Top500 прослеживается тенденция увеличения числа кластеров из недорогих узлов, они занимают примерно половину списка. Например, на основе процессоров Intel Xeon в сочетании с технологиями Infiniband и PCI Express можно создавать доступные для широкого круга пользователей готовые кластерные системы с производительностью более 1 TFLOPS и хорошими стоимостными показателями. На последней конференции Supercomputing такая система из 192 двухпроцессорных узлов, объединенных в единую инфраструктуру посредством Infiniband, была развернута менее чем за два дня, а ее стоимость составила менее 1 млн долларов.
Привлекательное соотношение цена/производительность является наиболее важным преимуществом кластеров HPC. К сожалению, далеко не всегда вертикальное масштабирование (многопроцессорные системы) можно заменить горизонтальным (кластеры). Несмотря на применимость кластеров HPC для целого ряда приложений, в отличие от значительно более универсальных систем с симметричной многопроцессорной архитектурой (SMP) и суперкомпьютеров, они пригодны для существенно более узкого класса приложений с хорошо распараллеливаемыми операциями. Нередко многоузловые кластеры конструируются и оптимизируются для решений одной конкретной задачи.
Многое определяется не только архитектурой кластерной системы, но и программным обеспечением. Инструментальные средства для «универсализации» вычислений в кластерных системах долгое время отсутствовали или были недостаточно развитыми. Сегодня крупные поставщики предлагают программные среды разработки приложений для параллельных вычислений, ПО промежуточного слоя и инструменты для оптимизации кластерных систем.
Современные коммерческие компиляторы могут в какой-то мере обеспечить распараллеливание в пределах одного узла, однако на уровне кластера задача оказывается гораздо более сложной. Поэтому много усилий направлено на облегчение прикладного программирования для кластеров HPC, для чего применяются функциональные модели программирования (чтобы программа могла без изменений выполняться на разном количестве процессоров), распределенная общая память, специальные инструменты анализа для выявления потенциально распараллеливаемых блоков программ и т. д. Универсализации кластерных решений способствует и увеличение вычислительной мощности узлов.
СТАНДАРТИЗАЦИЯ HPC
В 80-х гг. системы HPC были полностью закрытыми решениями, в 90-х производители обычно применяли в них стандартные процессоры и подсистемы памяти, а теперь кластеры HPC нередко строятся исключительно из стандартных компонентов. Эта тенденция распространяется на технологию межузлового соединения, ОС и программные инструментальные средства. Из научно-исследовательской сферы высокопроизводительные вычисления постепенно проникают в сферу бизнеса, находят применение в автомобильной и авиакосмической промышленности, производстве электроники, энергетике, нефтегазовой отрасли. Более трети самых мощных компьютеров платформы Intel используются в коммерческих целях.
Несмотря на «стандартизацию», каждый кластерный проект HPC сегодня уникален и требует большого объема работ по оптимизации под приложения заказчика. Именно поэтому и зарубежные, и российские производители предлагают высокопроизводительные кластеры в основном как проектное решение с услугами по проектированию, развертыванию, внедрению и сопровождению системы, хотя крупные производители — HP, IBM и Sun Microsystems — имеют в своем арсенале разнообразные типовые варианты кластерных решений на базе различных платформ (см. Таблицу 1). Обычно клиентам оказывается помощь в оптимизации ПО, предоставляется возможность опробовать приложения в центре кластерных решений (см. статью автора «Кластеры на пробу» в сентябрьском номере «Журнала сетевых решений/ LAN» за 2003 г.).
Между тем, учитывая стремление производителей предлагать быстро развертываемые кластерные решения, кластеры HPC постепенно превращаются из уникальных проектов во все более стандартные, готовые к использованию решения. Оценка пригодности конфигурации для конкретной задачи выполняется при помощи специально разрабатываемых для этого инструментов, однако внедрение кластеров HPC может занимать многие месяцы. Поставщики видят свою задачу в том, чтобы не допустить ошибок заказчиков в выборе решения и сокращать сроки внедрения.
Еще один аспект касается эффективности инвестиций. По словам Олега Кукушкина, управляющего директора группы компаний Arbyte, суммы, затрачиваемые на подобные комплексы, весьма существенны, а стоимость лицензий ПО, как правило, значительно превышает стоимость оборудования. С этой точки зрения использование стандартного, типового кластерного решения может оказаться экономически неэффективным. Настройка аппаратной части иногда в несколько раз сокращает время решения задачи, что влияет на сроки окупаемости комплекса. Исследуя конкретное ПО, его реакцию на конфигурирование аппаратной части и настройки ОС, разработчики создают типовые решения и могут рекомендовать заказчикам использование универсального кластера под весь набор задач либо решение некоторых типов задач на специализированных вычислителях. Коммерческие кластеры рассматриваются отечественными производителями как проектные решения, начиная от постановки задачи для проектирования кластера и заканчивая системами охлаждения и электропитания. Потребителями же «коробочных» систем, наборов модулей для построения кластера обычно являются университеты или научные организации.
Как отмечает Андрей Слепухин, руководитель центра кластерных технологий компании «Т-Платформы», для разных задач необходимы кластеры с разной архитектурой и разным набором ПО, и сегодня, когда рынок высокопроизводительных решений в России только формируется, а число кластерных инсталляций невелико, затраты на создание «коробочных» решений слишком высоки. Тем не менее компания «Т-Платформы» ведет работы в этой области, готовит решения для базовых средств администрирования кластеров.
ЛУЧШЕ МЕНЬШЕ, ДА ЛУЧШЕ
От чего же зависит конечный результат создания системы HPC — ее производительность? Скорость решения задачи зависит не только от применения быстродействующих узлов и высокоскоростного межузлового соединения (Cluster Interconnect, CI). На быстродействие системы и ее масштабируемость значительное влияние оказывает характер самих задач. Далеко не всегда они хорошо поддаются распараллеливанию, поэтому объединение систем не обязательно повышает эффективность вычислений. Определенные типы задач (например, рендеринг независимых сюжетов в видеофрагменте) могут быть разбиты на независимые блоки, результаты вычислений которых практически не зависят друг от друга. В этом случае производительность межсоединения CI мало влияет на быстродействие системы в целом.
С другой стороны, для целей гидро- и аэродинамики, моделирования крэш-тестов типичен иной характер расчетов: для вычисления следующего блока нужно иметь результат вычисления предыдущего. Подобные приложения сильно зависят от межузлового соединения, и при его недостаточной производительности увеличение числа узлов в кластере будет мало влиять на скорость решения задачи — возникает проблема масштабируемости. Таким образом, соединение множества низкопроизводительных узлов вовсе не обязательно увеличивает суммарное быстродействие системы HPC.
Поскольку «насыщение межсоединения» характерно для широкого класса задач, эффективность их решения обусловлена степенью производительности узлов в кластере HPC. Применение узлов с более мощными процессорами помогает решить проблему масштабируемости системы HPC, сэкономить на дорогостоящих межузловых соединениях (идеальный вариант — вычисление на одном высокопрозводительном процессоре без распараллеливания).
Появление процессоров Itanium 2 привело к активизации производителей в области HPC, включая компании, ранее не продвигавшие свои решения на данном рынке. В настоящее время разработку наборов микросхем для Itanium 2, обеспечивающих распараллеливание и синхронизацию работы процессоров, ведет целый ряд производителей, в числе которых — Hitachi, IBM, HP, NEC, Bull, SGI, Unisys и Fujitsu Siemens Computers. Такие решения позволяют увеличить мощность узлов кластера, нередко представляющих собой системы SMP.
К 2007 г. Intel обещает повысить производительность Itanium на 50—100%. Применяемая в Itanium архитектура параллельного выполнения команд (Explicitly Parallel Instruction Computing, EPIC) изначально обладает преимуществами «многоядерной» и многопоточной обработки. Кроме того, EPIC позволяет быстрее обрабатывать сложные команды и операции с плавающей точкой, что важно для решения научно-технических и конструкторских задач.

|
| Рисунок 1. Кластер серии hpcLine компании Fujitsu Siemens Computers. |
Сегодня решения HPC на базе процессоров Intel выпускают большое число компаний (см. Рисунок 1), для которых доступно различное прикладное ПО (NPACI Rocks, Boeing SOCS, Paradigm, Schlumberger ECLIPSE), однако и архитектуру RISC рано сбрасывать со счетов. Если HP держит курс на Itanium 2, то IBM и Sun планируют серьезное обновление микропроцессорной архитектуры POWER и UltraSPARC. Уже этой весной Sun Microsystems намерена представить образцы многопоточного процессора Niagara с восемью ядрами, вчетверо превосходящего по производительности UltraSPARC IV. Такие архитектуры позволяют создавать мощные 64-разрядные системы с десятками процессоров, обладающие хорошей вертикальной масштабируемостью и пригодные для выполнения широкого круга задач.
Как сообщается, наряду с технологическими усовершенствованиями будущий процессор архитектуры RISC POWER5 компании IBM позволит объединять до восьми процессоров в «виртуальный векторный процессор» (Virtual Vector Architecture, ViVA) с пиковой производительностью 60—80 GFLOPS. Созданию новых мощных кластеров должна способствовать диверсификация процессоров, совершенствование технологий «очень длинных команд» (Very Long Instruction Word, VLIW) и вычислительных устройств с операциями на более высоком уровне.
Что касается увеличения мощности узлов за счет архитектуры SMP, то, как отмечают специалисты компании Arbyte, кластер из восьми двухпроцессорных узлов дешевле кластера из четырех четырехпроцессорных, а тот, в свою очередь, дешевле одного 16-процессорного сервера (при одинаковом объеме памяти). Между тем соотношение стоимости и производительности существенно зависит от гранулярности приложения — возможности его разбиения на независимые параллельно выполняемые фрагменты. Плохо распараллеливаемые задачи требуют систем с небольшим числом процессоров и высокопроизводительной памятью.
В общем случае наличие мощных узлов делает кластерную систему более универсальной, расширяет спектр задач, которые она способна решать. Однако свою роль играет и возможность адаптации приложения к большому количеству процессоров в сервере SMP, масштабируемость узла. Если не углубляться в детали закона Амдала, то можно сказать, что многое зависит от эффективности математического решения и размерности задачи. Одни приложения хорошо функционируют и на кластерах с четырехпроцессорными узлами, другие — только на однопроцессорных узлах. И еще один важный момент. Для прикладных пакетов стоимостью в сотни тысяч долларов, лицензируемых по числу процессоров, применение в кластерах меньшего числа более мощных процессоров дает существенный выигрыш в цене.
По словам Андрея Слепухина, использование большого числа процессоров в узле кластера нецелесообразно из-за нелинейного роста стоимости узла и увеличения межузлового обмена: межсоединения CI становятся «узким местом», не позволяя достичь хорошей масштабируемости приложений. Решение же этой проблемы повышает стоимость системы и ограничено возможностями архитектуры ввода/вывода.
Традиционными недостатками кластеров HPC считаются высокое энергопотребление, сложности запуска и остановки системы, содержащей большое число узлов. Для крупных систем (порядка 100 узлов) приходится решать проблемы управляемости, к тому же в них возрастает вероятность отказов. При мощности узла 500 Вт система из 1000 узлов потребляет 500 кВт/ч. Это выливается в огромные счета на оплату электроэнергии и существенно влияет на стоимость владения кластером (TCO). Привлекательный вариант — использование в системах HPC тонких серверов на процессорах с пониженным энергопотреблением, к примеру Intel Pentium M. Подобные процессоры с мощностью около 45 Вт отличаются хорошим соотношением производительности к тепловыделению.
НЕ ТОЛЬКО «ЖЕЛЕЗО»
Для практических расчетов (трехмерная анимация, крэш-тесты, разведка нефтяных и газовых месторождений, прогнозирование погоды) коммерческие организации, как правило, используют кластеры из 10—200 узлов. В этом случае основной задачей является обеспечение работы кластера с конкретным приложением. Чтобы архитектура HPC могла продемонстрировать все свои достоинства, необходима оптимизация программного кода. И наоборот, кластерная конфигурация обычно оптимизируется (технически и по соотношению цена/производительность) для решения конкретного приложения. В качестве примера можно привести кластерный комплекс для инженерного анализа MSC.Nastran — Arbyte Zeeger/64MN, созданный в центре высокопроизводительных решений Arbyte на базе процессора Intel Itanium 2 и ПО MSC.Nastran (см. Рисунок 2).

|
| Рисунок 2. Кластер компании Arbyte на платформе Itanium 2. |
К сожалению, перенести существующее «некластерное» ПО на кластер не всегда возможно (и по стоимости это подчас сравнимо с ценой самого оборудования), а разработка нового приложения требует внесения серьезных изменений в математические модели, что обычно также непросто. Разработчики прикладного ПО (ANSYS, LS-DYNA или STAR-CD) используют специальные алгоритмы и библиотеки, позволяющие распараллелить процесс обсчета задачи.
При построении кластера HPC приходится оптимизировать настройки ОС, переменные операционной среды, конфигурацию оборудования, решать проблемы, связанные с выбором настроек прикладного ПО. Очень многое зависит и от компилятора. Именно он позволяет достичь максимальной производительности процессоров. Повышение эффективности компилятора даже на 10% дает возможность соответственно уменьшить число узлов, что в дорогостоящих системах HPC выливается в достаточно существенные суммы.
В Росгидромете после оптимизации задачи расчета погоды за счет настройки параметров компилятора без изменения исходного кода был получен двукратный рост производительности, в результате небольших изменений ПО (оптимизация для работы с кэш-памятью) производительность выросла вчетверо, а после включения опции распараллеливания — еще в два с половиной раза. Отсюда видно, насколько важен процесс оптимизации. Кроме того, для написания эффективных приложений нужно глубокое понимание способов взаимодействия пользовательских библиотек (таких, как MPI) с ПО низкого уровня и оборудованием.
Переносимость ПО и вопросы управления остаются наиболее острыми проблемами кластеров HPC. Например, в кластере, содержащем 1000 процессоров, локализовать причину отказа программы часто бывает крайне трудно. При разных запусках программы совокупная последовательность действий неодинакова. Из-за такой недетерминированности приложение приходится запускать десятки раз, чтобы обнаружить ошибку.
Основная трудность при построении кластеров с большим количеством узлов состоит в масштабируемости ПО для обеспечения адекватного прироста производительности. Для этого важно правильно выбрать конфигурацию кластера в зависимости от обмена данными между экземплярами программы, запущенными на разных узлах. Оптимизация ПО возможна только в том случае, если оно распространяется с исходными текстами. Коммерческие же программные продукты, как правило, рассчитаны на использование с определенными версиями системного ПО, поэтому зачастую приходится решать проблемы совместимости.
ИСКУССТВО СВЯЗЫВАНИЯ УЗЛОВ
Тип применяемого в кластере межузлового соединения определяется как решаемыми задачами, так и выделенным бюджетом. Недорогое соединение Gigabit Ethernet из-за присущей ему высокой латентности (больших задержек при передаче) обычно используют в кластерах HPC с малым числом узлов, в недорогих кластерных системах и для решения задач, где не предполагается интенсивный обмен данными (например, задачи рендеринга). В Gigabit Ethernet задержка составляет 50—100 мкс (внутренние задержки в коммутаторе 35—45 мкс), максимальная теоретическая пропускная способность достигает 125 Мбайт/с, а для стандартных реализаций MPI (MPICH, LAM) — около 70 Мбайт/с.
Многообещающая технология межсоединения — Infiniband. Эта спецификация была принята в июне 2001 г. и является стандартом коммуникационной среды с пропускной способностью 2,5—30 Гбит/с (в зависимости от ширины шины). Она может использоваться в качестве межузлового соединения (по меди или оптике) в кластере и служить основой для интерфейса передачи сообщений MPI. В системах HPC применяются коммутаторы Infiniband с 8—128 портами и скоростью 1,25 Гбайт/с. При реализации MPI поверх Infiniband скорость несколько снижается. В кластере на базе Infiniband пропускная способность CI достигает 850 Мбайт/с, а задержка при применении MPI не превышает 7 мкс (для коротких сообщений).
В феврале разработчики соединений на базе Infiniband провели встречу в Сан-Франциско и представили планы удвоения скорости передачи данных с 2,5 Гбит/с (312,5 Мбайт/с) до 5 или 6,25 Гбит/с. Ожидается, что до конца года рабочая группа при Infiniband Trade Association (IBTA) примет окончательную спецификацию новой версии, что впервые позволит реализовать межсоединение со скоростью более 100 Гбит/с.
В прошлом году появился целый ряд продуктов Infiniband для применения в системах HPC: платы хост-адаптеров, коммутаторы, драйверы устройств и реализации MPI. Несмотря на свою перспективность, Infiniband пока дороже более распространенной технологии Myrinet от компании Myricom с пропускной способностью около 100 Mбайт/с и задержкой 10—15 мкс. Как и в Infiniband, в Myrinet используется сквозная маршрутизация, а в последних реализациях обычно применяется оптическое волокно. Для Myrinet освоен выпуск коммутаторов на 8—128 портов. Новые коммутаторы Myrinet2000 обладают пропускной способностью 230 Мбайт/с и задержкой около 10 мкс при передаче коротких сообщений MPI.
Технологию QsNet компании Quadrics активно использовала Compaq в серверах серии AlphaServer SC. Подобно Infiniband и Myrinet, сеть QsNet включает в себя интерфейсные платы и коммутатор с 16 или 128 портами. Каждая пара портов обеспечивает теоретическую пропускную способность 400 Мбайт/с в дуплексном режиме. QsNet обычно применяется в крупных кластерах, насчитывающих от 50—60 до 1500 узлов. В отличие от Myrinet, коммутатор QsNet поддерживает два уровня приоритетов пакетов сообщений (Infiniband предусматривает 16 уровней). Задержка в коммутаторе составляет около 35 нс. В конце прошлого года Quadrics выпустила версию QsNet с пиковой пропускной способностью 1 Гбайт/с и задержкой менее 3 мкс. В настоящее время на реальных текстах QsNet показывает пропускную способность 160 Мбайт/с для MPI и более 300 Мбайт/с в симплексном режиме. При этом для MPI задержка не превышает 9 и 5 мкс.
Если число узлов не больше десяти, то многие производители применяют технологию межсоединения Scalable Coherent Interface (SCI). При пропускной способности 300 Мбайт/с технология SCI с протоколом ScaMPI имеет задержку 5 мкс. Эта стандартизированная в 1992 г. технология (ANSI/IEEE l596-1992) поддерживается в ОС Linux, Windows NT/2000 и Solaris.
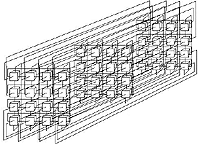
|
| Рисунок 3. Топология трехмерного тора в межузловом соединении SCI. |
SCI была разработана, чтобы преодолеть присущие шине ограничения и по сути представляет собой соединяющую узлы кольцевую структуру. Пара колец используется для передачи сигналов в прямом и обратном направлении. Такая топология имеет вид одно-, двух- или трехмерных торов (см. Рисунок 3). Информация передается в пакетах размером до 256 байт. Одной из специальных функций SCI является обеспечение когерентности кэш-памяти процессоров (предполагалось, что SCI заменит шины в многопроцессорных системах ccNUMA). Подобно QsNet, она позволяет реализовать общую виртуальную память.
Топология тора налагает определенные ограничения при добавлении/удалении узлов, но не требует применения коммутатора. Некоторые поставщики SCI, в частности Dolphin, предлагают для масштабирования системы ПО реконфигурации межсоединения. Пропускная способность в кластерах на базе SCI составляет около 320 Мбайт/с (для MPI) при задержке 1-2 мкс.
Выше перечислены лишь наиболее распространенные технологии межсоединения. Многие производители используют и иные варианты: Giganet cLAN или собственные нестандартные решения.
КЛАСТЕРЫ HPC В РОССИИ
Рынок высокопроизводительных систем HPC в России только формируется, и российские производители, создающие собственные кластерные конфигурации и центры кластерных решений, в значительной степени рассчитывают на будущее. В большинстве случаев реализация таких кластеров осуществляется как проектное решение с тщательным выбором аппаратных и программных компонентов, а также с их последующей оптимизацией.
Компания Arbyte концентрирует свои усилия на отраслевых решениях — кластерных системах для инженерных и геофизических расчетов. На базе процессора Intel Itanium 2 она создала мощный инструмент инженерного анализа — кластер MSC.Nastran-Arbyte Zeeger/64MN. Mосковский офис MSC Software совместно с Arbyte протестировал систему MSC.Nastran на данном кластере, проверив различные модели реальных изделий, результаты которых представляют интерес для предприятий разных отраслей. Кроме того, центр высокопроизводительных решений Arbyte оптимизировал кластер Zeeger/32 TCF на базе Intel Xeon под программный комплекс CFX-5. При содействии представительства компании Paradigm Geophysical разработан кластер, оптимизированный для ПО GeoDepth Power. Комплекс на платформе Xeon предназначен для обработки результатов сейсморазведки месторождений нефти и газа.
Один из крупнейших заказчиков кластерных решений HPC в России — нефтегазовая отрасль. В стране растет спрос на услуги обработки трехмерных сейсмических данных, получаемых в процессе геологоразведки. Кластеры HPC могут обеспечить решение геофизических задач, ранее недоступных по цене, а нефтяные компании получают возможность повысить точность поиска и оценки месторождений. В прошлом году было реализовано несколько кластерных проектов для этой сферы.
Так, компания Paradigm, специализирующаяся в области обработки геофизических данных для нефтегазовой отрасли, модернизировала свой ВЦ в Москве, установив серверный кластер IBM eServer x335, содержащий 68 процессоров Intel Xeon 2,4 ГГц. Установленные в стойку 34 узла кластера IBM соединены управляющей сетью Ethernet и сетью Gigabit Ethernet для обмена данными. В стандартной конфигурации система может включать до 512 кластерных узлов и до 32 дополнительных узлов хранения данных, а в более мощных версиях для обмена данными используется сеть Myrinet2000. За счет создания специальной технологии кабельных соединений C2T Interconnect разработчикам удалось уменьшить количество необходимых кабелей, упростить расширение системы и замену серверов. Кластер обеспечивает выполнение оптимизированного для данной платформы ПО Paradigm GeoDepth, предназначенного для построения трехмерных моделей месторождений по данным геологоразведки.
Схожее отраслевое решение создано группой компаний R-Style: кластерные системы на основе двухпроцессорных серверов платформы Intel Xeon собственного производства были поставлены в ГРЦ ФГУП «Южморгеология» Министерства природных ресурсов РФ для сложного анализа данных сейсморазведки при поиске месторождений нефти и газа, моделирования залежей сырья и мониторинга добычи. Кластер состоит из 34 стандартных серверов R-Style Marshall под управлением ОС Red Hat Linux с межсоединением по Gigabit Ethernet (один резервируемый сервер играет роль управляющей машины). Для обработки данных сейсморазведки 2D/3D применяется ПО CGG GeoCluster 1100.
В январе компания «Дата Технологии», партнер AMD по кластерным решениям на российском рынке, модернизировала кластер на базе 24 процессоров AMD Athlon MP, установленный в прошлом году в Институте биоорганической химии (ИБХ РАН) для изучения белковых структур. Новый 32-процессорный кластер состоит из 16 узлов R42100 производства компании «Т-Платформы». Каждый узел в корпусе 4U имеет плату TYAN Tiger DUAL с двумя процессорами Athlon 2800+. Для управления используется внутрикластерная сеть Ethernet, а для взаимодействия узлов — Myrinet. Кластер с расчетной производительностью 65 GFLOPS работает под управлением ОС Red Hat Linux. По информации компании, «Дата Технология» остановила свой выбор на процессорах AMD, исходя из соотношения цена/производительность. В этом году компания планирует реализовать еще несколько кластерных проектов, включая кластеры HPC на базе процессоров AMD Opteron.
Компания «Т-Платформы» специализируется на «промышленных» кластерных решениях и постоянно наращивает их мощность. Пиковая производительность ее кластеров T-Forge на базе процессоров Opteron — от 28,8 до 230,4 GFLOPS (на базе модулей T-Forge можно строить кластеры с производительностью, соответствующей нескольким TFLOPS). «Т-Платформы» уже осуществила ряд инсталляций T-Forge, и несколько проектов находятся в работе. Заказчиками пока выступают научные организации, проявляющие наибольший интерес к модели T-Forge8/16.

|
| Рисунок 4. Пиковая производительность кластера СКИФ К-500 — 716,8 GFLOPS (в тесте Linpack — 423,6 GFLOPS, 59% от пиковой). |
В сентябре 2003 г. ОИПИ НАН Белоруссии, НИИ ЭВМ (Минск), ИПС РАН в сотрудничестве с компанией «Т-Платформы» объявили о разработке программно-аппаратного комплекса СКИФ К-500 (см. Рисунок 4). Это второй по производительности суперкомпьютер, произведенный в СНГ и вошедший в список Top500. Создание системы со 128 процессорами Intel Xeon заняло всего четыре месяца. СКИФ К-500 позволяет решать достаточно широкий спектр задач при относительно невысокой стоимости: соотношение цена/производительность составляет менее 1 млн долларов на 1 TFLOPS. В нем использованы адаптеры 3D SCI (их будет производить ОАО НИЦЭВТ) и сервисная сеть разработки ИПС РАН (производства минского НИИ ЭВМ), применение которой позволило удешевить систему управления кластером и расширить ее возможности, а также специализированное шасси от компании «Т-Платформы» в целях обеспечения интеграции компонентов узла в корпусе 1U. Созданные в рамках проекта программные средства упрощают установку и настройку ПО на СКИФ К-500, обеспечивают мониторинг и управление компонентами.
Можно привести немало других примеров изготовленных в России кластерных систем. Кластеры HPC с узлами на Intel Xeon с межсоединением по Gigabit Ethernet или SCI предлагает компания Team Computers. Все больше производителей поставляют кластеры на базе Itanium 2. Например, компания «К-Системс» позиционирует свои двухпроцессорные серверы Patriot Titan 2200 на базе Intel Itanium 2 Low Voltage в корпусе 2U как основу кластеров HPC для решения задач в области САПР, дифференциальных уравнений, математического анализа, виртуального моделирования и инженерного анализа, а также для расчетных задач в области автомобилестроения и судостроения, метеорологических и т. п. Kraftway Computers использует в вычислительных кластерах большой мощности тонкие серверы GEG Express 6203 на базе процессоров Intel Itanium 2, оснащенные модулем управления и специальной системой охлаждения повышенной эффективности, а также новые четырехпроцессорные модульные серверы GEG Express Blade на базе Xeon MP. «Клондайк Компьютерс» строит кластеры HPC для решения инженерных задач на базе однопроцессорных серверов KLONDIKE President 1000A (Intel Xeon) и KLONDIKE President 64K2 (Intel Itanium).
В нашей стране накоплен обширный опыт создания высокопроизводительных кластерных систем. В частности, один из первых в России проектов с межузловым соединением SCI на базе процессоров Pentium III (а позднее Xeon) был реализован в НИВЦ МГУ. В настоящее время кластер загружен решением различных научных задач, в частности химии и биологии (молекулярная генетика и молекулярная динамика).
ЗАКЛЮЧЕНИЕ
Практически все ведущие производители серверов предлагают услуги по проектированию, планированию и реализации своих кластерных решений HPC, используя для достижения желаемых результатов и адаптации их под задачи клиента свой опыт и имеющиеся инструментальные средства.
По мнению экспертов Intel, архитектура Itanium сегодня одна из наиболее совершенных и позволяет «выжать» из процессора максимум производительности. Согласно информации Intel, на долю корпорации в настоящее время приходится 85% российского рынка процессоров, однако с ростом спроса на серверы с процессором AMD Opteron производители все чаще обращают внимание на эту альтернативную платформу. Впрочем, выбор определяется не только особенностями платформы и стоимостью, но и доступным ПО. Многое зависит и от самой задачи. В частности, применяемая в Intel Xeon технология Hyper-Threading улучшает производительность далеко не всех приложений MPI (в некоторых случаях она даже снижается).
Экономичность платформы Opteron не столь очевидна, как кажется. При построении системы с производительностью 1 TFLOPS потребуется около 100 узлов с Itanium или 152 узла с Opteron 246. В результате система на базе Itanium (Deerfield) может оказаться дешевле за счет меньшего числа узлов кластера и интерфейсных модулей. Существенный выигрыш дает к тому же экономия на электроэнергии и охлаждении. Впрочем, соотношение цен постоянно меняется, а AMD проводит агрессивную ценовую политику. Так, в феврале снижены цены на серверные процессоры, причем старшие модели Opteron 848 подешевели более чем вдвое. Линейка Opteron пополнилась и продуктами с низким энергопотреблением. В марте появятся процессоры AMD Opteron HE (55 Вт) и EE (30 Вт). Процессоры Opteron рассматриваются как конкуренты Intel Xeon. Очевидно, объявленная Intel технология 64-разрядного расширения памяти для архитектуры IA-32 будет способствовать еще большему разнообразию кластерных решений. Именно HPC — одна из тех областей, где 64-разрядные вычисления дают реальный выигрыш. В частности, эта архитектура позволяет работать с большими объемами памяти (> 4 Гбайт).
Процессоры Opteron применяют в своих серверах ведущие производители, желающие расширить свою долю на этом рынке. Вслед за IBM такое решение приняли HP и Sun Microsystems. Даже Cray, известная своими мощными системами MPP, рассматривает Opteron как перспективную платформу для будущей линейки продуктов, поскольку процессоры AMD позволяют одновременно выполнять 32- и 64-разрядное ПО.
В списке Top500 наиболее весомо представлены HP и IBM, причем HP лидирует по числу систем (165), а IBM — по их суммарной производительности (530 TFLOPS). Общая производительность систем Top500 каждые четыре года увеличивается примерно на порядок. В ноябрьском Top500 Intel Xeon обогнал HP PA-RISC — он используется в наибольшем числе систем.
По прогнозам IDC, среднегодовые темпы роста рынка HPC превысят 6%, и к 2007 г. его объем достигнет 6,3 млрд долларов. Судя по растущему спросу на серверы, неплохая перспектива ожидает и кластеры HPC. Увеличению производительности узлов кластеров будет способствовать не только совершенствование технологий микропроцессоров, но и широкое внедрение технологии PCI Express, выпуск сопрягаемой с хост-адаптерами шины PCI Express спецификации HyperTransport 2.0.
Отечественный рынок HPC в самом начале своего становления. Если раньше пользователями систем HPC были в основном научные организации, то сейчас все большее количество систем внедряется в отечественную экономику. Интерес к кластерным решениям проявляют ведущие предприятия машиностроения и нефтехимии. В настоящее время большинство систем HPC имеет кластерную архитектуру, и доля кластеров будет расти за счет более выгодного соотношения цена/производительность, использования недорогих компонентов, простоты в обслуживании и лучших возможностей расширения. Как считает Андрей Слепухин, доля отечественных кластерных решений (см. Таблицу 2) на российском рынке HPC также будет увеличиваться, поскольку по многим параметрам они не уступают зарубежным, стоят дешевле, проще в поддержке и обслуживании.
Сергей Орлов — обозреватель «Журнала сетевых решений/LAN». С ним можно связаться по адресу: sorlov@lanmag.ru.
Упоминаемые компании
Arbyte — http://www.arbyte.ru
Bull — http://www.bull.ru
Dell — http://www.dell.ru
Fujitsu Siemens Computers — http://www.fujitsu-siemens.ru
HP — http://www.hp.ru
IBM —http://www.ibm.com/ru
Kraftway Computers — http://www.kraftway.ru
R-Style Computers — http://www.r-style-computers.ru
Sun Microsystems — http://www.sun.ru
Team Computers — http://www.team.ru
«Дата Технологии» — http://www.datatec.ru
«К-Системс» — http://www.k-systems.ru
«Клондайк Компьютерс» — http://www.klondike.ru
«Т-Платформы» — http://www.t-platforms.ru