

Cитуация, когда случайно удаляется какой-нибудь важный файл, унося с собой в небытие все свои биты и байты, — настоящий кошмар для любого системного администратора. В большинстве случаев это скорее неудобство, чем трагедия, поскольку файлы можно восстановить с помощью регулярно обновляемой резервной копии.
Однако если системный администратор или разработчик со времени последнего резервного копирования файла успел-таки внести в него значительные изменения, то изрядное количество данных может оказаться потеряно. Неприятные ситуации этим не ограничиваются: неверно сконфигурированные сценарии резервного копирования, сбои в аппаратном обеспечении или, наконец, простое невезение. Ничто не заменит правильной стратегии резервного копирования. Нисколько не подвергая этот тезис сомнению, в данной статье мы акцентируем внимание на методах полного или частичного восстановления файлов в файловой системе UNIX.
ФАЙЛОВАЯ СИСТЕМА UNIX
Файлы в UNIX представляют собой логические контейнеры данных. С каждым файлом связана так называемая структура индексного дескриптора (inode, index-node structure), где содержатся метаданные (дисковые блоки, на которых физически размещен файл), информация о владельце файла, правах доступа, размере и т. д. При удалении файла индексные дескрипторы физически не стираются с диска, а отмечаются как свободные. Данные, содержащиеся в таких файлах, все еще хранятся на диске и потенциально могут быть восстановлены, если на их место еще не успели записать новую информацию.
ВОЗВРАЩЕНИЕ ИЗ БЕЗДНЫ
Некоторое время назад молодому коллеге одного из авторов предложили разработать на языке Perl интерфейс на основе CGI для предварительной настройки и поддержки некоего разрабатываемого продукта. Ранее ей показали, как можно использовать программные каналы UNIX (pipes) и переназначение (redirection) для отладки написанного ею сценария на языке Perl с помощью командного процессора, а не только посредством сервера Web. К сожалению, однажды она по ошибке случайно напечатала следующее:
$ ./nph-www.pl > nph-www.pl
Эта команда превратила ее файл с кодом Perl в файл размером в нуль байт. Ситуация усугублялась еще и тем, что изменения, производимые в течение недели, не вносились сотрудницей в базу данных системы контроля версий (Concurrent Versions System, CVS), что означало потерю приблизительно около 600 строк кода. Когда она сообщила, что случилось, ее успокоили, объяснив, что на самом деле большой беды нет, так как этот файл можно извлечь из резервной копии, которая была сделана прошлой ночью, и что ей придется восстановить лишь код, написанный сегодня.
Я позвонил нашему системному администратору и попросил его восстановить интересующий нас файл. Однако я не получил ответа, на который рассчитывал, — системный администратор признался, что он ни разу не слышал о сервере разработки, и поэтому данный сервер не резервировался.
Сотрудница, смирившись с тем, что в файловой системе UNIX невозможно восстановить удаленный ранее файл, приготовилась потратить все свои выходные на повторное написание этого кода. Ее уверили, что восстановление файла возможно, но для этого потребуется несколько часов. Заметим, что такие неприятные истории случаются не только с неопытными администраторами. Несколько лет назад, работая в Linux, один из нас случайно напечатал crontab -d вместо crontab -e. Много ли среди читателей найдется пользователей, которые делают резервные копии /var/spool/cron/crontabs?
ВОССТАНОВЛЕНИЕ ФАЙЛОВ UNIX
Как только какой-либо файл был по ошибке удален, необходимо тут же прекратить на данном разделе жесткого диска любые операции ввода/вывода. Раздел следует демонтировать или немедленно после случившегося перевести систему в однопользовательский режим. Если это сделать невозможно (в частности, корневая файловая система не может быть демонтирована), то всем работающим в системе пользователям следует прекратить свою работу, а остальным необходимо запретить вход в систему (например, с помощью файла /etc/nologin). В некоторых версиях UNIX существует возможность повторного монтирования раздела только для чтения.
# mount -o ro, remount -n /home
Главное — не допустить перезапись другими процессами дисковых блоков или индексных дескрипторов, ранее востребованных удаленным файлом. Это особенно актуально, если данный раздел почти заполнен, поскольку именно тогда вероятность повторного использования удаленных индексных дескрипторов существенно возрастает. Если степень заполнения раздела невелика, процедуру восстановления можно осуществить непосредственно на смонтированном с возможностью чтения/записи разделе диска, хотя, как было отмечено выше, шансы на восстановление при этом неизбежно уменьшаются.
Далее описываются процедуры восстановления файлов в системах UNIX. Первый раздел посвящен способу восстановления файлов с известным содержимым, который применим практически для всех разновидностей файловых систем UNIX. Второй рассматривает специфику восстановления файлов в файловой системе Linux ext2.
ПРОЦЕСС ВОССТАНОВЛЕНИЯ ФАЙЛОВ С ИЗВЕСТНЫМ СОДЕРЖИМЫМ
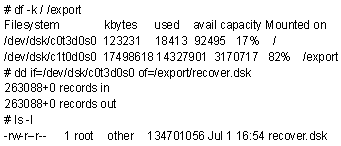
После того как система переведена в безопасное состояние, необходимо с помощью команды dd(1) сделать копию исходных данных раздела, содержащего удаленный файл. Предположим, что по ошибке удален файл /etc/passwd. Следующий пример иллюстрирует процедуру создания копии корневого раздела с последующим помещением ее в файл из раздела /export:
|
Целевой раздел должен быть достаточно большим, чтобы вместить в себя весь раздел-источник (в данном случае около 128 Мбайт). Если в системе нет необходимого места на диске, нужно подумать об альтернативных действиях, таких, как монтирование удаленного раздела средствами NFS или выполнение действий непосредственно над файлом устройства раздела.
После того как копия файловой системы сделана, систему можно вернуть в многопользовательский режим и продолжить работу с ней в обычном режиме. Если копию сделать не удается, систему следует оставить в безопасном состоянии, а имя устройства заменить на имя файла (в примерах, приводимых ниже, /dev/dsk/c0t3d0s0 заменятся на /export/recover.dsk).
Описываемая далее процедура больше похожа на искусство, чем на науку. Пусть удален файл с именем passwd. В левой части приведенной ниже инструкции команда cat(1) отражает все «строки» диска (опция -n предусматривает вывод номеров строк). Далее вывод перенаправляется утилите fgrep(1), а та по указанному ей регулярному выражению осуществляет «быстрый» поиск записи root в файле passwd:
# cat -n recover.dsk | fgrep "root:x:0:1" 200600 root:x:0:1:Super-User:/:/sbin/sh 202098 root:x:0:1:Super-User:/:/sbin/sh 332802 Ё1 root:x:0:1:Super-User:/:/sbin/sh
Утилита fgrep может не найти строки, соответствующие указанному шаблону. Вероятнее всего, это означает, что содержание файла было перезаписано и восстановлению не подлежит. В противном случае имеет смысл обобщить шаблон, расширив область поиска.
В нашем примере версии файла /etc/passwd хранились на диске в трех местах. Версия GNU утилиты grep(1) предоставляет опции -A и -B, позволяющие выводить на печать несколько строк, расположенных до и после найденной по шаблону строки. Это облегчает извлечение содержимого всего удаленного файла. Если grep(1) версии GNU не установлена на вашем компьютере, то вы можете воспользоваться программой на Сu под названием seekcat, приведенной в Листинге 1. Она выводит на печать весь файл, начиная с определенного смещения в байтах или строках. В программе seekcat предусмотрены два независимых параметра: первый указывается с помощью флага -b или -l, за ним следует целое число, означающее смещение в байтах или строках, с которого должен начинаться листинг. Второй параметр задается в виде флага -f, а затем указывается имя файла, представляющее собой в данном случае «образ диска» исходных данных. Например:

|
Такого же результата можно добиться и путем указания утилите seekcat начальной строки. Этот номер берется из распечатки, полученной в результате выполнения команды cat -n, описанной ранее в текущем разделе. Программа seekcat выведет содержимое файла, начиная с того места, где былa найдена соответствующая шаблону строка. В следующем примере выводятся 10 строк «образа диска», начиная с самой первой найденной строки (строка за номером 200 600). При необходимости можно повторить процесс, задав номер следующей найденной строки (в нашем примере ее номер 202 098):

|
К сожалению, иногда отдельные части файла могут занимать несмежные области и размещаться вразброс по всему разделу. В этом случае для получения содержимого всего файла следует повторить вышеописанную процедуру, используя подходящие шаблоны. Чаще всего (включая удаленный по ошибке код на Perl) файлы все-таки располагаются в смежных областях, что облегчает их восстановление. Труднее всего понять, какая из версий файла, хранящихся на диске, самая последняя. Это можно определить, лишь просмотрев все содержимое. К счастью, заголовки CVS или RCS, содержащие номера версий, даты, а также другую известную информацию, оказываются достаточно полезными при выяснении этого вопроса.
ПРОЦЕСС ВОССТАНОВЛЕНИЯ ФАЙЛОВ В LINUX
Речь пойдет о процессе восстановления файлов в системе Linux в случае, если они были удалены командой rm(1). Описываемая здесь методика, как правило, гарантирует восстановление файлов и не опирается на принцип проб и ошибок. Дополнительное ее преимущество заключается в том, что она позволяет легко восстанавливать двоичные файлы, а также файлы с неизвестным содержимым.
Средство, используемое в процессе восстановления, известно как отладчик файловой системы debugfs(8), применяемый обычно для ее проверки и изменения состояния. Хотя приведенные ниже примеры написаны для Linux, теоретически они должны быть справедливы для файловой системы любого типа UNIX при условии, что в ней имеется средство с функциональностью debugfs(8). Если же такого средства не будет, то придется пользоваться методикой восстановления файлов с известным содержимым.
Здесь стоит сказать, что debugfs — это мощное, но в то же время чрезвычайно опасное средство. Оно предоставляет непосредственный доступ к файловой системе, так что на протяжении сеанса работы с ним необходимо соблюдать осторожность.
Утилита debugfs(8) обеспечивает интерфейс по типу интерфейса командного процессора. Нас будут интересовать три команды: lsdel, cat и dump. Запустить debugfs(8) в требуемом разделе можно следующим образом:
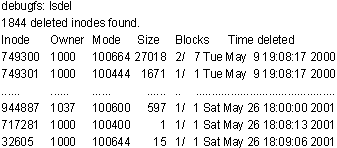
Ввод в строке приглашения команды lsdel приведет к распечатке на экране списка всех удаленных индексных дескрипторов в данной файловой системе. Это займет некоторое время, так как системе необходимо просмотреть все дескрипторы указанного раздела:
|
Поскольку такой список обычно достаточно велик, весь вывод имеет смысл перенаправить в файл, который затем можно просмотреть в редакторе или с помощью программы постраничного вывода:
По информации из вывода lsdel можно выяснить, какие из удаленных индексных дескрипторов представляют для нас интерес. Наиболее важны колонки из листинга — Owner (Владелец), Size (Размер), Mode (Состояние) и Time deleted (Время удаления). Если с момента удаления файла(ов) не было последующих операций с диском, то интересующие нас дескрипторы окажутся в конце списка. В поле Owner (Владелец) содержится идентификатор пользователя — владельца файла, значение которого можно найти в третьем поле файла /etc/passwd. В нашем примере имя владельца johnf (идентификатор 1000) и файл содержит единственную строку important_data.
В приведенном выше листинге дескриптор (inode) с номером 32605 находится в конце списка и, следовательно, является первым кандидатом на проверку. Содержимое, соответствующее данному дескриптору, можно вывести следующим образом:
debugfs: cat <32605> important_data
Итак, удаленный файл найден. Команда dump «воскрешает» файл, записывая его на диск:
debugfs: dump -p <32605> /tmp/recovered_file
Ключ -p гарантирует, что у файла останутся прежними владелец, группа и права доступа.
Данный подход удобен, когда удален единственный файл, но может оказаться достаточно утомительным, если необходимо восстановить большое количество файлов. К счастью, Том Пайк написал утилиту recover, которая автоматизирует процедуру восстановления. Самую последнюю версию программы recover можно получить по адресу: http://recover.sourceforge.net/ linux/recover/download.php3
Установка recover достаточно проста:
# tar zxf recover-1.3.tar.gz # cd recover-1.3 # make # make install
По умолчанию утилита устанавливается в систему каталогов с корнем /usr. Пожалуйста, прочтите файл README с описанием того, как установить ее в другую систему каталогов. Во время сеанса работы программа recover задает несколько простых вопросов, например:
- кто является владельцем файлов?
- когда эти файлы были удалены?
- каков приблизительный размер этих файлов?
Используя полученную информацию, recover запускает debugfs, восстанавливает соответствующие данному критерию индексные дескрипторы и помещает их в каталог, указанный пользователем.
К сожалению, в отличие от содержимого файлов, их имена восстановить нельзя. Восстановленные файлы получают имена, состоящие из префикса dump и номера последующего индексного дескриптора. При удалении такого каталога, как /etc, могут быть потеряны сотни файлов. Для сортировки восстановленных файлов можно использовать простые утилиты UNIX, среди которых наиболее полезны strings(1) и file(1).
Программа strings(1) отображает последовательность символов ASCII, извлекая ее из указанного файла. Данная утилита обычно применяется для «вытаскивания» текста из двоичных файлов, не поддающихся расшифровке другими способами.
Утилита file(1) помогает выяснить тип файла (например, является ли он изображением JPEG или файлом PostScript) путем выполнения ряда тестов с использованием неких «магических» чисел.
Так выглядит результат работы программы file(1) для каталога с восстановленными файлами:

|
Классифицировать файлы разных типов, добавив к именам файлов соответствующие расширения, можно с помощью простого сценария командного процессора. Например:
После сортировки самое время попытаться идентифицировать каждый файл. Для тех, что содержат текст, код на Сu, звук или изображение, сделать это несложно, поскольку каждый такой файл можно просмотреть соответствующим программным средством и догадаться о его первоначальном имени. Двоичные файлы, например исполняемые файлы, библиотеки или файлы баз данных, идентифицировать гораздо труднее.
В этом случае можно применить утилиту strings(1), выведя на экран все текстовые строки ASCII, содержащиеся в двоичном файле. Например:

|
По этому тексту можно догадаться, что данный файл является исполняемым файлом groff(1). Его запуск на исполнение с параметром --help подтверждает это. С библиотеками несколько труднее, поскольку их нельзя запустить. Здесь нам на выручку приходит команда objdump(1). Например:
# objdump -p dump34756.lib | grep SONAME SONAME libmenu.so.4
Вышеописанный метод годится в том случае, когда файл был удален командой rm(1) или функцией unlink(2). Если же он был перезаписан, то индексные дескрипторы, которые содержали первоначальные данные, возможно были перезаписаны также. Правда, сохраняется вероятность того, что некоторые фрагменты данных все еще находятся где-либо на диске. К примеру, многие редакторы создают временные копии файлов, или, возможно, еще не все дескрипторы перезаписаны. Если индексные дескрипторы потеряны, то следует применить уже описанный нами метод восстановления файлов с известным содержимым.
ЗАКЛЮЧЕНИЕ
Никакие методы восстановления не заменят резервные копии данных, создаваемые регулярно и в полном объеме на надежных носителях. Процедуры, описанные выше, — это помощь системным администраторам, оказавшимся на краю пропасти.
Лайэм Уиддоусон — консультант в компании Hewlett-Packard. С ним можно связаться по адресу: lbw@telstra.com. Джон Ферлито — старший инженер в компании Bulletproof Networks. С ним можно связаться по адресу: johnf@bulletproof.net.au.