Стабилизация экономики ведет к росту конкуренции и повышению важности принятия правильных решений для успешной работы предприятий.
Стабилизация экономики ведет к росту конкуренции и повышению важности принятия правильных решений для успешной работы предприятий. А управление предприятием требует знания истории клиентов и продаж, анализа спроса и других факторов, что невозможно осуществить без использования больших объемов разнообразных данных, которые так или иначе порождались на предприятии или были ему доступны. Этот факт сейчас признается не только ИТ-специалистами, но и руководителями предприятий. Однако создание хранилищ таких данных требует и особых подходов. Это должны учитывать и специалисты и руководители.
Из статьи читатель узнает:
- об отличиях хранилищ данных от традиционных баз данных информационных систем;
- о различных архитектурах систем поддержки принятия решений;
- о приемах моделирования хранилищ и витрин данных;
- о критериях, которыми можно руководствоваться при выборе инструмента для проектирования моделей хранилищ и витрин данных.
Хранилища данных нужны не сами по себе. В первую очередь они служат основой для создания и применения систем поддержки принятия решений (СППР). Поэтому, прежде чем начинать разговор об особенностях архитектуры хранилищ данных или способов их построения, приведем три простых примера из этой области. СППР на основе технологии хранилищ данных позволяют эффективно решать такие задачи, как анализ клиентской базы, анализ продаж и анализ доходов предприятия.

|
| Константин Борисович Лисянский, архитектор хранилищ данных, компания «Диасофт». Ему можно написать по электронной почте klissianski@diasoft.ru |
Анализ клиентской базы нацелен на измерение эффективности работы с клиентами и позволяет определить целевые сегменты клиентов для предложения им определенных продуктов и услуг. Целевые сегменты формируются на основе различной информации о клиентах финансового и нефинансового характера (обороты, принадлежность к определенной отрасли, форма собственности и т. д.). Консолидация данных о клиентах позволяет подразделениям маркетинга лучше понимать потребности клиентов и использовать эти данные при проведении маркетинговых кампаний.
Анализ продаж позволяет определять тенденции и зависимости в продажах, планировать продажи и проводить анализ выполнения плана по продажам в разрезе продуктов, клиентов, подразделений, а также исходя из результатов сбыта стимулировать работу клиентских и продуктовых подразделений. Использование хранилища данных позволяет получить интегрированное представление о результатах продаж и формировать планы продаж на основе этой информации.
Анализ доходов актуален для любого предприятия и позволяет формировать «уникальные» продукты для каждого «уникального» клиента исходя из максимизации прибыли в долгосрочной перспективе, правильно выстраивать ценовую политику предприятия, делать клиентам специальные предложения, выделять сегменты, продукты и услуги, которые стратегически важны для предприятия.
В табл. 1 сравниваются способы решения описанных выше задач. Из таблицы видно, что использование хранилища данных может существенно повысить эффективность их решения.
Комплекс задач по созданию хранилища данных
Некоторые компании предлагают типовые отраслевые решения на основе хранилищ данных, однако хранилища данных имеют свою специфику — они не являются коробочным продуктом. В силу постоянного изменения характера работы организаций и требований к анализу информации хранилища данных строятся и развиваются вместе с развитием организаций. Поэтому, как правило, проекты по построению хранилища данных имеют характер итеративной разработки и состоят из нескольких этапов.
- Предпроектное обследование организации (поиск приоритетных задач управления бизнесом, исследование информационных источников).
- Логическое моделирование (построение логических моделей хранилищ и витрин данных).
- Разработка архитектуры (выбор аппаратного и программного обеспечения, выбор способов взаимодействия компонентов архитектуры).
- Физический дизайн баз данных хранилища и витрин данных (написание или автоматическая генерация программ для создания объектов баз данных: таблиц, представлений, учетных записей пользователей, и др.).
- Разработка процедур наполнения хранилища и витрин данных (настройка специализированных инструментов или разработка процедур с помощью традиционных средств разработки приложений).
- Разработка пользовательских приложений (настройка специализированных инструментов или разработка приложений с использованием традиционных средств разработки приложений).
- Поддержка и развитие системы (текущее администрирование, периодическая загрузка данных, регулирование прав доступа, итеративное расширение хранилища).
При составлении проектного плана необходимо учитывать специфику каждого этапа, следить за рамками проекта, подбирать специалистов соответствующей квалификации. Наполнение хранилища данных — один из ответственных этапов, занимающий, по различным оценкам, до 70% ресурсов проекта. На это также следует обратить внимание при планировании.
Далее в статье мы уделим внимание выбору архитектуры хранилища данных, а также моделированию хранилищ и витрин данных.
Основные отличия систем поддержки принятия решений от традиционных оперативных систем
Ввиду того что приемы проектирования систем поддержки принятия решений на основе хранилищ данных и приемы проектирования традиционных систем различны, следует упомянуть о причинах этого, кроющихся в отличиях между двумя видами информационных систем. Основные отличия между традиционными оперативными информационными системами и системами поддержки принятия решений (СППР) обусловлены задачами, для решения которых создаются системы: обеспечение ежедневной работы предприятия одной системой и поддержка принятия решений — другой. На данный момент существует масса публикаций, в которых эти отличия рассматриваются весьма подробно [4, 6, 8, 15].
Мы же в данной статье сконцентрируемся на аспекте проектирования совокупности баз данных на предприятии — операционных («традиционных»), исторических (хранилищ) и приспособленных к решению специфических задач («витрин»; см. табл. 2).
В силу различной природы систем требуются различные приемы моделирования данных. Мы рассмотрим эти приемы ниже, предварительно уделив внимание архитектуре систем поддержки принятия решений.
Архитектура СППР
Известно несколько способов построения СППР, и большинство из них основано на технологиях хранилищ и витрин данных.
На сегодняшний день можно выделить четыре наиболее популярных типа архитектур систем поддержки принятия решений:
- Функциональная СППР.
- Независимые витрины данных.
- Двухуровневое хранилище данных.
- Трехуровневое хранилище данных.
Функциональная СППР
Функциональная СППР (рис. 1) является наиболее простой с архитектурной точки зрения. Такие системы часто встречаются на практике, особенно в организациях с невысоким уровнем аналитической культуры и недостаточно развитой информационной инфраструктурой.
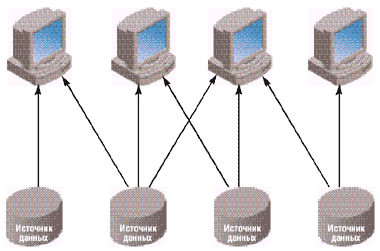
|
| Рис. 1. Функциональная СППР |
Функциональная СППР характерна тем, что при анализе данных система использует данные из оперативных систем.
Преимущества:
- быстрое внедрение за счет отсутствия этапа перегрузки данных в специализированную систему;
- минимальные затраты за счет использования одной платформы.
Недостатки:
- единственный источник данных, потенциально сужающий круг вопросов, на которые может ответить система;
- оперативные системы характеризуются очень низким качеством данных с точки зрения их роли в поддержке принятия стратегических решений; в силу отсутствия этапа очистки данных данные функциональной СППР, как правило, также обладают невысоким качеством;
- большая нагрузка на оперативную систему — сложные запросы могут привести к остановке работы оперативной системы, что весьма нежелательно.
СППР с использованием независимых витрин данных
Независимые витрины данных (рис. 2) часто появляются ?исторически? и встречаются в крупных организациях с большим количеством независимых подразделений, зачастую имеющих свои собственные отделы информационных технологий.
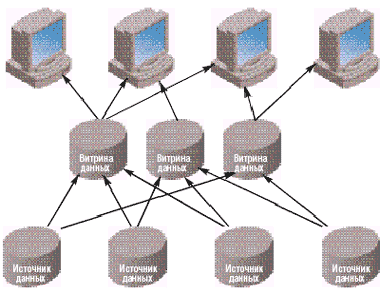
|
| Рис. 2. Независимые витрины данных |
Преимущества:
- витрины данных можно внедрять достаточно быстро;
- витрины проектируются для ответов на конкретный ряд вопросов;
- данные в витрине оптимизированы для определенных групп пользователей, что облегчает процедуры их наполнения, а также способствует повышению производительности.
Недостатки:
- данные хранятся многократно в различных витринах данных, что приводит к дублированию информации и, как следствие, к увеличению расходов на хранение и возможным проблемам, связанным с необходимостью поддержания непротиворечивости данных;
- потенциально очень сложный процесс наполнения витрин данных при большом количестве источников данных;
- данные не консолидируются на уровне предприятия и, следовательно, отсутствует единая картина бизнеса.
СППР на основе двухуровневого хранилища данных
Двухуровневое хранилище данных (рис. 3) строится централизованно для предоставления информации в рамках компании. Для поддержки такой архитектуры необходима выделенная команда профессионалов в области хранилищ данных. Это означает, что вся организация должна согласовать все определения и процессы преобразования данных.

|
| Рис. 3. Двухуровневое хранилище данных |
Преимущества:
- данные хранятся в единственном экземпляре;
- минимальные затраты на хранение данных;
- отсутствуют проблемы, связанные с синхронизацией нескольких копий данных;
- данные консолидируются на уровне предприятия, что позволяет иметь единую картину бизнеса.
Недостатки:
- данные не структурируются для поддержки потребностей отдельных пользователей или групп пользователей;
- возможны проблемы с производительностью системы;
- возможны трудности с разграничением прав пользователей на доступ к данным.
СППР на основе трехуровневого хранилища данных
Хранилище данных представляет собой единый централизованный источник информации для всего предприятия. Витрины данных отражают подмножества данных из хранилища, организованные для решения задач отдельных подразделений компании. Конечные пользователи имеют возможность доступа к детальным данным хранилища, в случае если данных в витрине недостаточно, а также для получения более полной картины состояния бизнеса.

|
| Рис. 4. Трехуровневое хранилище данных |
Преимущества:
- создание и наполнение витрин данных упрощено, поскольку наполнение происходит из единого стандартизованного надежного источника очищенных нормализованных данных;
- имеется (построена) общая структура данных предприятия;
- витрины данных синхронизированы и совместимы с общей структурой данных предприятия;
- существует возможность сравнительно легкого расширения хранилища и добавления новых витрин данных;
- гарантированная производительность.
Недостатки:
- избыточность данных, ведущая к росту объема хранилища;
- требуется согласованность с принятой архитектурой многих областей с потенциально различными требованиями (например, скорость внедрения иногда конкурирует с требованиями следовать архитектурному подходу).
Мы рассмотрели основные варианты типов архитектур систем поддержки принятия решений. Выбор конкретного варианта зависит от условий, в которые поставлена проектная группа. Нужен ли быстрый возврат от инвестиций или можно потратить больше времени и построить надежную инфраструктуру? Является ли проектная группа профессиональной или состоит из новичков? Существует ли формализованная методология или механизмы работы еще не отлажены? Ответы на эти и ряд других вопросов могут повлиять на ваш выбор.
Подробное описание преимуществ и недостатков каждого варианта архитектуры можно найти в [2, 3].
Моделирование хранилищ данных
В силу коренных отличий хранилищ данных от оперативных систем приемы моделирования также отличаются. Все описанные ниже особенности и приемы относятся к моделированию реляционных баз данных, поскольку последние наиболее часто используются для хранения и обработки данных хранилища. Приемы моделирования для многомерных баз данных выходят за рамки данной статьи.
Особенности моделирования времени в хранилищах данных
Традиционные подходы к моделированию оперативных систем основываются, как правило, на статическом представлении реального мира. При этом если время и учитывается, то только в виде временных отметок создания записей и их модификации. С точки зрения моделирования времени хранилища данных принципиально отличаются от оперативных систем, и модели хранилищ данных более интенсивно используют временные отметки. Подробно об этом пишут Саймон [14] и Девлин [2].
Можно выделить три основных подхода к моделированию времени в хранилищах данных.
1) Модель снимков данных.
Снимок данных — это представление данных в определенный момент времени. Данная модель характерна для оперативных систем (OLTP). Обновления данных носят деструктивный характер (т. е. предыдущие значения атрибутов замещаются новыми) (рис. 5).
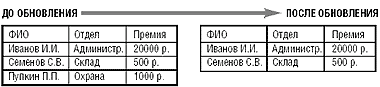
|
| Рис. 5. Модель снимков данных |
Поскольку модель не обеспечивает хранения истории изменений, ее применение в хранилищах данных ограниченно.
2) Событийная модель.
Событийная модель используется для моделирования данных о наступлении событий в определенные моменты времени (рис. 6). Эта модель хорошо подходит для моделирования транзакций, таких как продажи, финансовые транзакции, складские операции и т. д.

|
| Рис. 6. Событийная модель |
3) Статусная модель.
Статусная модель используется для моделирования состояния объектов во времени. Она хорошо подходит для представления данных, имеющих нетранзакционный характер.
Существует три способа моделирования изменяющихся во времени статусов:
- непрерывная модель — для хранения промежутков времени используется одно поле даты, при этом дата начала следующего периода совпадает с датой окончания предыдущего;
- начало и окончание — для хранения промежутков времени используется два поля — дата начала и дата окончания периода действия статуса;
- начало и длительность — для хранения промежутков времени используется одно поле даты (дата начала) и поле длительности периода.
Наибольшее распространение при создании статусных моделей получил способ «начало и окончание» (рис. 7).

|
| Рис. 7. Статусная модель |
Статусная и событийная модели являются взаимно дополняющими. Путем преобразований из одной можно получить другую. Например, зная остаток на счете на определенный момент и историю транзакций в событийной модели, можно восстановить все статусы счета (остатки на счете) в периоды между транзакциями. И наоборот, имея статусную модель остатков на счете, можно вычислить события (т. е. транзакции), которые происходили со счетом в начале (конце) каждого периода.
Выбор ключей
Выбор ключей для таблиц хранилища данных является непростой задачей и может существенно повлиять на дальнейшее развитие схемы данных, производительность системы и ее надежность.
Существуют разные способы решения этой задачи, каждый — со своими плюсами и минусами. Упрощенный же подход к ее решению может привести к ухудшению качества хранилища вплоть до потери логической целостности данных.
Перед разработчиком модели хранилища встает вопрос: использовать ли в хранилище данных ключи из оперативных систем, и если нет, то как их сформировать? Рассмотрим варианты решения этой задачи.
Использование ключей из оперативных систем
Данное решение представляется очевидным, однако практика показывает, что оно далеко не самое удачное. Одна из проблем при использовании ключей из оперативных систем заключается в том, что некоторые приложения могут использовать одно и то же значение ключа для идентификации новых объектов после удаления из базы данных объектов, идентифицировавшихся этим значением ключа ранее.
А поскольку данные из хранилища, как правило, не удаляются, повторное использование ключевых значений в оперативной системе может очень сильно затруднить поддержку хранилища.
При большом количестве источников данных есть вероятность совпадения ключей в записях из разных источников.
Генерация ключей
одно из решений заключается в генерации новых ключей для записей, загружаемых из систем-источников. Существует несколько подходов к генерации ключей.
- Новый ключ генерируется путем конкатенации ключа из системы-источника с уникальным идентификатором этой системы. Данный подход исключает возможность совпадения ключей из различных источников, позволяет проследить, из какого источника данные попали в хранилище, но не решает проблемы повторного использования ключей в оперативных системах.
- Новый ключ генерируется путем конкатенации ключа из системы-источника с меткой времени загрузки записи в хранилище. Данный подход позволяет сделать ключ действительно уникальным за счет уникальности метки времени. Однако длина ключевого поля может оказаться достаточно ощутимой для системы, в результате чего возможно снижение производительности при выполнении операции соединения таблиц по ключевым полям.
- Новый ключ генерируется с помощью специального алгоритма (простейший случай — генерация возрастающей последовательности целых чисел). Преимущество такого подхода заключается в том, что ключи можно сделать минимально короткими. Это позволит решить проблемы с производительностью и сэкономить дисковое пространство, необходимое для хранения записей. Однако в этом случае необходимо иметь специальную структуру метаданных (таблица или несколько таблиц) для хранения соответствий между ключами оперативных систем и суррогатными ключами хранилища данных, а также процедуры для управления данной структурой.
Выбор конкретного способа генерации ключей зависит от масштаба проекта, количества и качества систем-источников, требований к производительности и поддержке хранилища данных и полностью определяется проектной группой.
При проектировании хранилища следует учитывать, что генерация ключей — задача, требующая хорошей проработки. От того, как она решена, будет зависеть эффективность хранилища. Специалист, ответственный за создание модели хранилища, должен хорошо разбираться в тонкостях генерации суррогатных ключей.
Вопросы целостности данных
Ввиду историчности данных их целостность в хранилище носит характер, отличный от целостности данных в оперативных системах. Если при построении транзакционных систем речь идет о целостности транзакций и соблюдении ссылочной целостности, то в хранилищах данных кроме этого очень важно обеспечивать историческую целостность данных и соблюдение бизнес-правил, которые могут выражаться механизмами, отличными от ссылочной целостности.
Соответственно, ссылочная целостность и непротиворечивость данных в хранилище данных обеспечиваются иначе. Как правило, при проектировании хранилищ данных не используются триггеры и встроенные в СУБД механизмы контроля целостности. Они способны очень сильно снизить производительность системы и увеличить окно загрузки (что, как правило, крайне нежелательно). Вместо этого целостность данных контролируется на этапе их загрузки путем выполнения различных проверок. При этом задачи контроля целостности данных полностью ложатся на разработчиков хранилища данных.
Моделирование витрин данных
Приемы моделирования витрин данных отличаются от приемов моделирования хранилищ данных в силу различных требований к структурам данных. Если основной задачей хранилища данных является хранение консолидированной исторической информации, то витрина данных строится с учетом требований по доступу к данным и представления информации.
Как правило, для моделирования витрин данных используются схемы типа «звезда» и «снежинка». Популяризатор данного подхода моделирования Ральф Кимбал разработал основные концепции схемы «звезда» [7, 8, 9]. Некоторые исследователи даже попытались подвести под практические подходы Кимбала теоретическую базу [10]. Давайте познакомимся с этими подходами немного поближе.
Схема «звезда»
Схема «звезда» — популярный тип модели базы данных для витрин данных. Данная структура характеризуется наличием таблицы фактов, окруженной связанными с ней таблицами измерений. Запросы к ней включают простые соединения таблицы фактов с каждой из таблиц измерений. Схема «звезда» характеризуется небольшой избыточностью данных и высокой по сравнению с нормализованными структурами производительностью. Некоторые промышленные СУБД и инструменты класса OLAP/Reporting умеют использовать преимущества схемы «звезда» для сокращения времени выполнения запросов.
На рис. 8 изображен пример использования схемы «звезда» для анализа остатков на счетах банка и количества транзакций в разрезе времени, клиентов, счетов, продуктов, отделений, статусов счетов. Модель выполнена с использованием нотации IDEF1X. Данная модель позволяет ответить на широкий спектр аналитических вопросов. Например: «Посчитать средний остаток и количество операций на депозитных счетах, открытых более года назад клиентами отделения «Тверское», проживающими в городе Зеленоград». Специалисты, знакомые с автоматизированными банковскими системами, могут убедиться в том, что на подобный запрос очень нелегко ответить с их помощью.
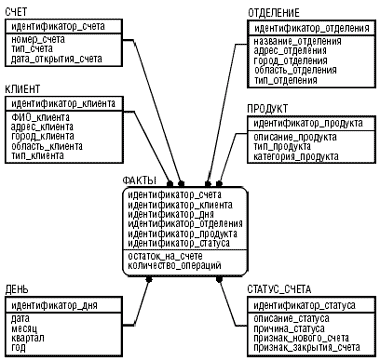
|
| Рис. 8. Схема «звезда» для анализа остатков на счетах банка |
Рассмотрим компоненты схемы «звезда».
Измерения
В технологии многомерного моделирования измерение (dimension) — это аспект, в разрезе которого можно получать, фильтровать, группировать и отображать информацию о фактах.
Типичные измерения, встречающиеся практически в любой модели:
- клиент;
- продукт;
- время;
- география;
- сотрудник.
Измерения, как правило, имеют многоуровневую иерархическую структуру. Например, измерение ВРЕМЯ может иметь следующую структуру: ГОД—КВАРТАЛ — МЕСЯЦ — ДЕНЬ.
Факты
Факты — это величины, обычно числовые, хранящиеся в таблице фактов и являющиеся предметом анализа. Примеры фактов: объем операций, количество проданных единиц товара и т. д.
Факты могут обладать различными свойствами, на которых мы вкратце остановимся.
Аддитивные факты
Аддитивность определяет возможность суммирования факта вдоль определенного измерения. Аддитивные факты можно суммировать и группировать вдоль всех измерений на любых уровнях иерархии. Аддитивными, как правило, являются величины, характеризующие обороты (потоки, объемы операций).
Полуаддитивные факты
Полуаддитивный факт — это факт, который можно суммировать вдоль определенных измерений, и нельзя — вдоль других. Примером может служить остаток на счете (или остаток товара на складе).
Данную величину нельзя суммировать вдоль измерения ВРЕМЯ. Однако сумма остатков на счетах вдоль измерения КЛИЕНТЫ имеет вполне реальный смысл для анализа.
Неаддитивные факты
Неаддитивные факты вообще нельзя суммировать. Любое отношение двух величин (выраженное в процентах) является примером неаддитивного факта.
Специалисты рекомендуют моделировать неаддитивные факты таким образом, чтобы сделать их более аддитивными. Например, представить процент составляющими его величинами [1].
Более подробное описание фактов и их свойств можно найти в [1, 8, 9].
Таблицы покрытия
Таблицы покрытия используются с целью моделирования сочетания измерений, для которых отсутствуют факты. Например, нужно найти количество категорий продуктов, которые сегодня ни разу не продавались. Таблица фактов продаж не может ответить на данный вопрос, поскольку она регистрирует только факты продаж. Для того чтобы модель позволяла отвечать на подобные вопросы, нужна дополнительная таблица фактов (по сути дела, не содержащая фактов), которая и называется таблицей покрытия.
Схема «снежинка»
Данная схема (рис. 9) используется для нормализации схемы «звезда», при этом несколько сокращается избыточность в таблицах измерений.
Одним из достоинств данной схемы является более быстрое выполнение запросов о структуре измерений (например, «выбрать все строки из таблицы измерения на определенном уровне»), которые очень часто выполняются при анализе данных и могут задерживать ход анализа.
Однако основным достоинством схемы «снежинка» является не экономия дискового пространства, а возможность иметь таблицы фактов с разным уровнем детализации, например фактические данные — на уровне дня, а плановые — на уровне месяца.
Моделирование времени в витринах данных
Витрины данных, как правило, характеризуются наличием явного измерения ВРЕМЯ. При этом структура данного измерения может меняться в зависимости от моделируемой предметной области и требований, предъявляемых пользователями к представлению времени.
Помимо стандартных атрибутов времени, как правило, возникает необходимость моделирования специальных атрибутов времени, таких как:
- недели;
- времена года;
- сезоны;
- выходные и праздники;
- рабочие смены.
Моделирование времени в витринах данных — достаточно сложный момент, освещение которого заслуживает отдельной статьи, мы же перейдем к обсуждению проблемы выбора инструментов для моделирования.
Выбор инструментов
Для создания и поддержки успешных моделей хранилищ и витрин данных необходимы соответствующие средства моделирования. В настоящее время на рынке представлено достаточно большое количество продуктов, предназначенных для проектирования традиционных баз данных, и специализированных средств, предназначенных для создания хранилищ и витрин данных. Приведем названия некоторых из них:
- CAST AppViewer (www.castsoftware.com)
- Computer Associates ERwin (www.ca.com)
- Embarcadero ER/Studio (www.embarcadero.com)
- Microsoft VisioModeler (www.microsoft.com)
- Oracle Designer (www.oracle.com)
- Popkin System Architect (www.popkin.com)
- Sybase PowerDesigner WarehouseArchitect (www.sybase.com)
- Visible Systems Visible Advantage Data Warehouse Edition (www.visible.com)
Несмотря на то что многие из этих продуктов считаются универсальными, необходимо помнить о том, что моделирование хранилищ данных имеет свои особенности и, соответственно, выдвигает свои требования к инструментам данного класса.
Поэтому при выборе инструмента рекомендуется руководствоваться следующими критериями. Список их достаточно обширен и поэтому разбит на несколько категорий.
Поддержка методологий проектирования моделей
- Поддержка традиционного ER-моделирования (для моделирования хранилищ данных) и многомерного моделирования (для моделирования витрин данных).
- Поддержка различных методологий проектирования и нотаций (нотации Чена, Мартина, Баркера, IDEF1X, IE, ORM, UML, DFD и др.).
- Корректное преобразование моделей из одной нотации в другую.
Управление метаданными
- Открытый репозиторий метаданных (возможность обмена метаданными с приложениями класса ETL, OLAP/Reporting, data mining, репозиториями метаданных, инструментами контроля качества данных).
- Поддержка стандартов на хранение и обмен метаданными (ISO 11179, CWM, MDIS, CWMI, CDIF).
- Поддержка свойств, определяемых пользователем (UDP), — для расширения круга метаданных, поддерживаемых моделью.
Поддержка жизненного цикла моделей
Поддержка коллективной разработки моделей данных (контроль версий, check-in, check-out, разграничение доступа на уровне моделей и их отдельных объектов). Гибкая система отчетности (отчеты обо всех объектах модели данных на всех уровнях, отчеты об изменениях и другие отчеты, возможность публикации отчетов в сети intranet). Поддержка возможности проверки качества моделей (стандарты именования объектов моделей данных, проверка полноты описания объектов, автоматическая генерация запросов на проверку качества). Многоплатформенность (поддержка генерации объектов для различных промышленных СУБД). Поддержка повторного использования компонентов моделей (экономия ресурсов при разработке однотипных фрагментов). Наличие встроенных средств разработки (макроязык, API) для тонкой настройки инструмента и автоматизации рутинных операций. Поддержка обратного проектирования (reverse engineering) для обеспечения возможности восстановления моделей оперативных систем в случае их отсутствия.Удобство использования
- Удобный интерфейс пользователя.
- Возможность ввода информации об объектах модели как через графический интерфейс, так и через упрощенный списочный интерфейс с дальнейшей генерацией графического представления.
- Возможность качественной печати моделей.
- Качественная документация на систему. Удобная справочная система.
- Качественная техническая поддержка от производителя (желательно локальная).
Заключение
Проектирование хранилищ и витрин данных — интересный, сложный и достаточно трудоемкий процесс, требующий использования приемов и методик, отличных от применяемых при проектировании традиционных систем. Руководителям подразделений информационных технологий следует учитывать эти особенности при организации проектов по созданию хранилищ данных.
Литература
- Adamson C., Venerable M. Data Warehouse Design Solutions. John Wiley & Sons, Inc (1998). ISBN 0-471-25195-X.
- Devlin B. Data warehouse: from architecture to implementation. Addison Wesley Longman, Inc. (1997). ISBN 0-201-96425-2.
- IBM. «Business Intelligence Architecture on S/390. Presentation Guide». SG24-5747-00, IBM Corporation (2000).
- IBM. «Business Intelligence Certification Guide». SG24-5747-00, IBM Corporation (2000).
- IBM. «Data Modeling Techniques for Data Warehousing». SG24-2238-00, IBM Corporation (1998).
- Inmon W. What is a data warehouse?//White Paper. http://www.billinmon.com//library/whiteprs/ earlywp/ttdw.pdf
- Kimball R. A Dimensional Modeling Manifesto//DBMS Magazine. August 1997.
- Kimball R. The Data Warehouse Toolkit. Practical Techniques for Building Dimensional Data Warehouses. John Wiley & Sons, Inc (1996). ISBN 0-471-15337-0.
- Kimball R. et al. The Data Warehouse Lifecycle Toolkit: Expert Methods for Designing, Developing and Deploying Data Warehouses. John Wiley & Sons, Inc (1998). ISBN 0-471-25547-5.
- McGuff F. Hitchhiker?s Guide to Decision Support (http://members.aol.com/fmcguff/dwmodel/).
- Silverston, L. Inmon W., Graziano K. The Data Model Resource Book. A Library of Logical Data Models and Data Warehouse Designs. John Wiley & Sons, Inc (1997). ISBN 0-471-15367-2.
- Winsberg, P. Modeling the Data Warehouse and Data Mart// InfoDB, 10, № 3, 1-10.
- Львов В. Создание систем поддержки принятия решений на основе хранилищ данных//Системы управления базами данных. 1997. № 3.
- Саймон А. Стратегические технологии баз данных. Глава 4. Склады данных//Системы управления базами данных. 1997. № 3.
- Спирли Э. Корпоративные хранилища данных. Планирование, разработка и реализация. Т. 1. «Вильямс» (2001). ISBN 5-8459-0191-X.
- Щавелев Л. В. Способы аналитической обработки данных для поддержки принятия решений//Системы управления базами данных. 1998. № 4-5.
Термины, использованные в статье:
Витрина данных — предметно-ориентированное подмножество данных из хранилища данных, проектируемое для удовлетворения потребностей определенной группы пользователей и требований безопасности. Витрины данных позволяют решить проблемы с производительностью, так как содержат меньший объем данных, агрегируют данные заранее и используются ограниченным кругом пользователей.
Измерение в технологии многомерного моделирования — это аспект, в разрезе которого можно получать, фильтровать, группировать и отображать информацию о фактах. Измерение, как правило, имеет иерархическую структуру и состоит из нескольких уровней.
Метаданные — любые данные, необходимые для поддержки процессов создания и использования хранилища данных. Метаданные включают информацию о физических данных, технических и бизнес-процессах, правилах и структуре данных организации.
Таблица измерения — таблица, хранящая информацию об измерении. Как правило, это таблица схемы «звезда» или «снежинка», имеющая первичный ключ, состоящий из одного атрибута.
Таблица покрытия — таблица, хранящая информацию об отсутствии фактов для определенных сочетаний измерений (например, отсутствие продаж определенных продуктов в определенные дни).
Таблица фактов — таблица в схеме «звезда» или «снежинка», использующаяся для хранения данных об анализируемых показателях.
Факт — величина, обычно числовая и аддитивная, хранящаяся в таблице фактов и являющаяся предметом анализа.
Хранилище данных — предметно-ориентированный, интегрированный, зависимый от времени набор данных, предназначенный для поддержки принятия решений различными группами пользователей организации.