

Сравнительный анализ производительности
По окончании обработки получаем две базы данных, содержащие массу полезной информации. Одна из них включает результаты разбора трассировок, полученных при воспроизведении тестовой нагрузки на SQL Server 2000, вторая — для SQL 2008.
В первую очередь интересно, кто стал работать хуже. Судить об этом мы будем на основании количества операций чтения, выполненных запросами. Почему? По следующим причинам.
- Использовать длительность исполнения запроса (Duration в терминах Profiler) не имеет смысла. Откройте транзакцию в одном соединении, откройте такую же транзакцию на другом соединении, отойдите на полчасика и сделайте отмену действий в обоих соединениях. Если при этом у вас будет активный Profiler, то Duration для второго соединения он покажет 30 минут или более, тогда как реально команда просто ждала завершения транзакции.
- Использовать показатели загрузки процессора? Уже теплее, но процессор показывает реальное время исполнения запроса и ничего не сообщает от качестве его выполнения.
- Использовать количество операций записи (Writes)? Снова холодно. Во-первых, большинство систем пишет на порядки меньше, чем читает, а во-вторых, торможение обычно возникает на выборках или в условиях, ограничивающих критерии модификации.
Отсюда следует, что для анализа производительности имеет смысл взять значение Reads.
Одна из особенностей утилиты Readtrace заключается в том, что при разборе файлов трассировки она все тексты команд преобразует к некоей нормальной форме. На основе этой нормальной формы строится хеш строки. Имея два одинаковых хеш-значения, мы можем уверенно говорить, что это две одинаковые команды, отличающиеся, возможно, только параметрами.
В базе данных с разобранными трассировками нас в первую очередь интересуют следующие четыре таблицы:
- tblUniqueBatches — содержит список первичных вызовов типа EXEC с исходным и нормализованным текстом команды;
- tblUniqueStatements — содержит список команд в теле хранимых процедур, триггеров и т. д. с исходным и нормализованным текстом команды;
- tblBatches — содержит все вызовы с указанием расхода ресурсов на каждый вызов;
- tblStatements — содержит все команды с указанием расхода ресурсов на каждый вызов.
Таблицы tblUniqueBatches и tblBatches — парные, как и таблицы tblUniqueStatements и tblStatements. Между собой таблицы в паре связаны значением хешированной величины текста запроса HashId. Таблицы tblBatches и tblStatements связаны между собой через последовательность исполнения команд — поле BatchSeq. В результате у нас появляется замечательная возможность сравнить поведение одних и тех же команд в разных тестах.
Выбираем из наших баз данных информацию о воспроизведении теста с указанием, какой тест и где проходил, чтобы можно было сделать вывод о производительности. Надо иметь в виду, что, когда Profiler записывает TRC-файл, параметр Duration записывается для SQL Server 2000 в миллисекундах, тогда как для SQL 2005/2008 — в микросекундах. Соответственно, при анализе мы используем (duration/1000).
Сравнивать имеет смысл не только по абсолютной разнице операций чтения, но и по процентному соотношению. И в первую очередь следует обратить внимание на запросы, у которых имеются высокие расхождения в процентах. Для начала нас интересуют запросы, которые сильно «уехали» с точки зрения числа операций чтения. Отсортировав таблицу по степени расхождений, получаем набор значений HashId. Если в системе есть процедуры или функции, вполне возможно, что их команды будут видны в результатах анализа. Поэтому стоит не только отсортировать по разнице в операциях чтения, но и по HashId, чтобы сгруппировать часто повторяющиеся команды.
Для полученного набора HashId необходимо найти исходный вызов с параметрами. Это может быть самостоятельная команда, полученная из Web-интерфейса или от клиента, либо вызов хранимой процедуры.
Возможные проблемы и работа с ними
До сих пор во всех проектах по переходу на SQL 2008/2005 для системы, основной объем запросов которой составляют команды, характерные для приложения OLTP и разбавленные некоторым количеством аналитики или отчетности, статистика поведения запросов выглядела примерно одинаково: около 90% запросов отрабатывались почти без изменений, из оставшихся 10 порядка 5–6% показывали гораздо лучшие результаты, а около 4–5% — значительно худшие.
Основная причина ухудшения работы — изменение плана исполнения запроса. У меня нет внятного объяснения такому поведению, равно как и универсального подхода к решению проблем. Могу только поделиться опытом, как я выбирался из трудных ситуаций.
Скорее всего, основной целью проекта перехода на новую версию является не академическое исследование, а повышение производительности до уровня «не хуже, чем было». Поэтому я предлагаю начать борьбу с проблемным запросом с помощью мастера Database Tuning Advisor. Проверку его рекомендаций стоит начать со статистики. Она обходится дешево и можно себе позволить большое число проверок, которые следует выполнять с тем же самым сценарием, который был передан мастеру, добавив в него набор команд для получения данных о характере выполнения запросов:
SET STATISTICS IO ON —
выдает информацию о чтении
GO
SET STATISTICS PROFILE ON —
выдает фактический план исполнения
GO
SET STATISTICS TIME ON —
выдает данные о загрузке процессора
GO
Сначала запускаем сценарий без рекомендаций, средствами указанных выше команд собираем характеристики исполнения, создаем статистику и еще раз запускаем. Если снижения числа операций чтения добиться не удалось, строим индекс. Или же смотрим на результат, и если он удовлетворительный, двигаемся дальше.
Если и построение индекса ничего не дает, тогда смотрим на информацию по операциям чтения, которую выдает SET STATISTICS IO. Следует обратить внимание на расхождение оценки и фактического числа записей на отдельных элементах плана. Оптимизатор строит план, исходя из оценочной выдачи записей на каждом из элементов плана. Это не единственный критерий, но при выборе того или иного типа соединения он учитывается. Если по обеим сторонам соединения расположены крупные таблицы, выдающие по критериям запроса много записей, оптимизатор вполне может выбрать HASH JOIN, так как он требует однократного прохода по таблицам. Если размеры таблиц или размеры выдачи сильно отличаются, то будет выбран LOOP JOIN. Если оценка сильно расходится с фактами, сервер вынужден выполнять гораздо больше операций чтения, чем нужно, например, на организацию поиска посредством меток Bookmark. Если мы не можем изменить ситуацию путем обновления и построения новой статистики, придется указать на правильное решение с помощью оператора HASH JOIN. В результате мы получаем существенное сокращение числа операций чтения. Кроме того, мы знаем, что HASH JOIN использует, как следует из названия, хеш значений полей соединения, что требует значительных затрат ресурсов процессора. Чтобы помочь серверу в расчетах, мы можем добавить дополнительное указание OPTION (MAXDOP N), что приведет к созданию параллельного плана исполнения.
Я редко рекомендую использовать значение параметра Max degree of parallelism больше 1; как правило, использование значения по умолчанию 0 приводит к существенным задержкам в работе, но для конкретного запроса это может быть оправданно. Попробуем MAXDOP 2 или 4. Проверяем еще раз, видим, что ситуация изменилась к лучшему, и двигаемся дальше.
Следующая остановка — команда UPDATE. Неожиданно обнаруживается, что эта простая команда сильно «проседает» при выполнении условий, по которым сервер отбирает записи, подлежащие обновлению. Снова видим использование меток.
Избежать этого поможет применение кластерного индекса. Создаем его и видим, что действительно число операций чтения сократилось очень сильно, но при этом выросла загрузка процессора.
В чем дело? К таблице, которую мы обновляли, было применено динамическое сжатие (еще одно нововведение в SQL Server 2008). Оно позволяет уменьшить размер хранения самой базы данных в несколько раз, сократить требования к памяти, так как страницы, как на диске, так и в памяти, хранятся в сжатом виде, но все это оборачивается повышением нагрузки процессор. При непосредственной обработке страницы (а, как мы знаем, SQL Server все модификации и поиск выполняет только в буферах памяти) необходимо восстановить страницу, а это «стоит» процессорных циклов. В результате мы получили следующее: до тех пор, пока сжатой была только таблица, поиск по индексам не вызывал увеличения загрузки процессора, а сама модификация была незначительной и тоже обходилась дешево. Как только мы создали кластерный индекс, который, по сути, является отсортированной таблицей, все обращения к нему, будь то поиск или модификация, стали вызывать загрузку процессора.
Оставив кластерный индекс и убрав сжатие, мы получили почти идеальный вариант. Число операций чтения увеличилось незначительно, а загрузка процессора почти исчезла. Но ощущение неудовлетворенности осталось. Таблица большая, хочется получить еще высокую скорость обновления и малый объем хранения. Чтобы этого добиться, можно применить секционирование. Если модификации распространяются только на незначительную часть данных (наиболее свежие), использование секционирования, которое дает возможность сжимать отдельные секции данных и индексы, обеспечивает оптимальный вариант.
Кроме того, пришло время еще одной хранимой процедуры. Она также исполнялась хуже в среде SQL Server 2008. После того как мы развернули ее код, по описанному выше способу процедура исполнилась за 30 секунд, тогда как вызов EXECUTE проходил за 9 минут. Код не менялся, следовательно, мы можем заключить, что дело в применении параметров (то, что называется parameter sniffing). Когда мы исполняем набор команд, предварительно объявив переменные, оптимизатор строит план, зная значения параметров. При вызове процедуры оптимизатор сначала строит план, и только на этапе фактического исполнения применяет реальные значения параметров. Иногда это приводит к падению производительности. Мы отследили исполнение процедуры и обнаружили, что два запроса при вызове через EXECUTE исполняются гораздо медленнее и создают гораздо больше операций чтения, чем при выполнении развернутого кода. При первой попытке оптимизации использовалось указание OPTION (RECOMPILE), вставленное в код процедуры для первого запроса. Если не помогло, значит, дело не только в отложенном применении параметров. Мы передали развернутый текст процедуры на анализ Tuning Advisor, и он предложил создать индекс. После создания индекса скорость исполнения уменьшилась втрое, но все же была слишком низкой. Тогда мы применили принудительную рекомпиляцию ко второму запросу, и время исполнения упало до 27 секунд.
Некоторые дополнения
Когда проводится анализ производительности при переходе на новую версию, следует выделить некоторое время на «переосмысление» кода. Я не призываю заниматься корректировкой архитектуры, слишком большое число изменений резко повышает риски, но посмотреть свежим взглядом на текст запросов может быть полезно. Во-первых, учитывая описанные выше проблемы с выбором типа соединения, стоит переписать запросы, использующие критерии, соединенные условием OR. Такое соединение критериев обычно сильно усложняет задачу оптимизатору.
Попробуем разбить запрос на две части, получим два варианта максимального значения и выберем из них «наибольший». Это дает сокращение операций чтения почти в 800 раз и загрузку процессора в две тысячи раз — неплохой результат, особенно если речь идет о запросе, который выполняется очень часто.
Почти универсальные рекомендации
Все универсальные рекомендации можно разделить на три группы: оптимизация аппаратной платформы, оптимизация операционной системы и оптимизация собственно SQL Server. Последнюю группу при желании можно дополнительно разделить на оптимизацию настроек самого сервера и оптимизацию программного кода. Давайте начнем с железа.
В первую очередь стоит сказать, что я не рекомендую рассматривать серверы на базе процессоров x86. Даже если у вас сейчас стоит 32-разрядная версия SQL Server 2000/2005 и вы собираетесь обновить аппаратную часть, то она должна быть только 64-разрядной (x64). Хотя бы потому, что в режиме Windows on Windows (WOW) 32-разрядное приложение получает полноценные 4 Гбайт памяти по сравнению с 1,7 Гбайт, если вы не используете переключатель 3 Гбайт.
Дисковая подсистема. На дисковую подсистему приходится существенная часть производительности. Даже если вся база данных умещается в памяти, SQL Server обязан записывать журнал транзакций. Когда скорость записи недостаточно велика, сервер начинает приостанавливать основную работу для обеспечения гарантированной записи изменений в журнал транзакций. Поэтому система хранения должна отвечать самым высоким требованиям. Рекомендуемое время отклика для дисковой группы, на которой расположены файлы баз данных, составляет в идеале 10 мс. 20 мс считается неважным, но все же приемлемым результатом. Для журнала транзакций требования еще более жесткие, 1–5 мс. Рекомендуется форматировать систему хранения с размером блока 64 Кбайт, и перед форматированием обязательно выполнить выравнивание секторов средствами DISKPART.EXE. Кроме того, имеет смысл проанализировать схему разбиения с точки зрения выделения физических дисков серверам и взаимосвязь между набором дисков и логическими дисками (в нашем случае точками монтирования).
Учитывая высокую нагрузку на все файлы данных (особенно Tempdb) и практически непредсказуемый характер интенсивности вызовов, оптимальной может быть конфигурация, когда все доступные диски используются для размещения всех файлов данных и журналов.
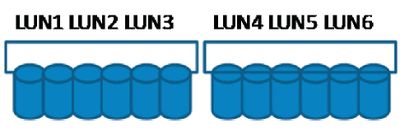
Так, конфигурация, представленная на рисунке 1, может оказаться не самой удачной, так как мы искусственно ограничиваем LUN 1–3 работой на 6 дисках.
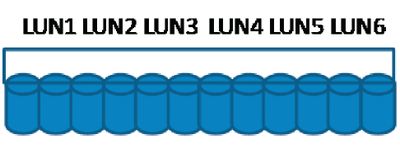
Конфигурация, представленная на рисунке 2, использует все физические диски и лучше балансирует нагрузку. Чего не стоит делать, так это разбивать диски таким образом, чтобы кусок одного физического диска предназначался различным задачам. Если необходима производительность, физические диски должны быть выделены только под работу SQL Server.
Настройка SQL Server и Windows. Настройки самого SQL Server устанавливаются либо через графический интерфейс, либо с помощью процедуры sp_configure. Наиболее отчетливо на производительность влияют выделенная серверу память max server memory/min server memory. Для сервера памяти чем больше, тем лучше, но не следует забывать о том, что он работает в среде Windows, у которой может быть также немало потребностей. Рекомендуется на каждые 16 Гбайт физической памяти оставлять оперативной системе не менее 1 Гбайт, то есть если на сервере стоит 32 Гбайт, SQL Server надо отвести не более 30 Гбайт.
Еще одна настройка, вокруг которой только что война не идет, — это установка, определяющая уровень параллелизма при обработке запросов. Я считаю, что ее лучше всего сделать равной 1 или 2, а потом смотреть на индивидуальные запросы для определения эффективности увеличения. Чего совершенно точно не стоит делать, так это оставлять ее в значении по умолчанию — 0.
При написании запросов следует принимать во внимание, что интенсивное использование табличных функций может существенно понизить производительность, и, если есть возможность задействовать встроенные в текст запроса функции, это стоит сделать. Не всегда разумно идти по пути создания универсальных функций, например таких, которые выполняют преобразование даты или мелких строковых операций. С точки зрения инкапсуляции это выглядит красиво, но с точки зрения производительности — не всегда оправданно. Хороший пример — упомянутое выше вычисление максимума с OR-критерием в запросе. Не стоит слишком усложнять предложения SELECT. Запрос, занимающий три экрана (я видел такие), конечно, наполняет душу программиста гордостью, но вызывает судороги у оптимизатора. Иногда разбить запрос на части с промежуточными временными таблицами оказывается гораздо более эффективно с точки зрения производительности. Не следует использовать табличные переменные для больших объемов данных. У них нет статистики, а SQL 2008 умеет перекомпилировать индивидуальные запросы, так что неоптимальный план хуже, чем пара рекомпиляций из-за временных таблиц.
Возможно, кто-то разочарован отсутствием универсального решения, которое, как по мановению волшебной палочки, снимает все проблемы производительности. Но, увы, SQL Server — не тот случай. Тем не менее некоторые универсальные подходы все же существуют. Но они достаточно общие и не позволяют выработать набор правил, уточненных до уровня индивидуальных конструкций кода, кроме того, в некоторых случаях и они могут не сработать. Поэтому я основное внимание уделил не программированию, а методам поиска неисправностей.
Дмитрий Артемов (dimaa@MICROSOFT.com) — старший консультант серверной практики Microsoft Россия