
Как только приложения таких разработчиков начинают обрабатывать большое количество данных, проблемы производительности всплывают наружу. Это обычно случается через несколько дней после того, как приложение запущено в промышленную эксплуатацию. В этот момент обычно и происходит обращение к администратору базы данных.
После некоторых предварительных исследований и выполнения нескольких трассировок администратор базы данных, возможно, решит выполнить полный анализ индексов. Здесь может быть полезен Database Engine Tuning Advisor, но я предпочитаю узнавать лично все о моих индексах, а не доверять мастеру. И для этого я написал две хранимые процедуры на T-SQL: sp_GenerateIndexes и sp_ListAllIndexes, которые работают на SQL Server 2005 и SQL Server 2000.
Хранимая процедура sp_GenerateIndexes генерирует предложения SQL, которые могут удалять и создавать индексы для указанной таблицы. При наличии кода SQL, удаляющего и создающего индексы, можно поставить несколько экспериментов, добавляя или удаляя столбцы, в зависимости от того, подходят ли они. В случае неудачи можно просто снова использовать процедуру sp_GenerateIndexes, чтобы удалить новые индексы и пересоздать исходные индексы, выполняя код SQL, который был предварительно создан. Следует, конечно, делать это только в тестовом окружении, а не на промышленном сервере.
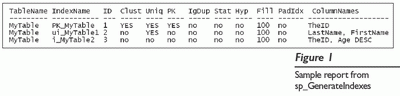
Хранимая процедура sp_GenerateIndexes также создает очень полезный отчет, который детализирует различные свойства каждого индекса (кластеризован ли индекс, порядок сортировки и фактор заполнения). На рисунке 1 показан пример отчета отредактированного ради экономии места. Я пробовал использовать короткие названия полей, чтобы можно было включать столько информации, сколько возможно в отчете. Приведу краткое описание каждого поля:
- TableName - определяет имя таблицы;
- IndexName - определяет имя индекса;
- ID - определяет идентификационный номер индекса из таблицы sysindex. Обратите внимание, что 0 и 255 не используются, потому что они имеют специальные значения;
- Clust - определяет, является ли индекс кластерным;
- Uniq - определяет, является ли индекс уникальным;
- PK - определяет, является ли индекс первичным ключом;
- IgDup - определяет, игнорирует ли индекс двойные записи;
- Stat - определяет, является ли индекс действительно сгенерированным статистически и не истинным индексом;
- Hyp - определяет, является ли индекс действительно гипотетическим индексом, созданным мастером Index Tuning Wizard и не истинным индексом;
- Fill - учитывает оригинальный коэффициент заполнения, который был указан, когда индекс был создан;
- PadIdx - определяет, включен ли индекс заполнения для индекса;
- ColumnNames - обеспечивает связанный список всех полей в индексе.
Как видно из примера отчета на Рисунке 1, таблица MyTable имеет кластеризованный первичный ключ, уникальный индекс и некластеризованный составной индекс с убывающим порядком сортировки относительно его второго поля. Оригинальный коэффициент заполнения был определен как 100 для каждого индекса. В этом отчете третий индекс является составным индексом, который включает то же самое поле, что и кластерный индекс (то есть TheID). Это расточительно, потому что каждая строка в нескластеризованном индексе уже содержит строку-определитель, который в этом случае есть кластеризованный ключ индекса (то есть TheID).
Вторая хранимая процедура, которую я создал - это sp_ListAllIndexes, она выполняет итерацию по всем таблицам в текущей базе данных, вызывая процедуру sp_GenerateIndexes для каждой найденной таблицы. Вывод от работы процедуры sp_GenerateIndexes фиксируется и сохраняется на рабочем столе, а затем отображается в конце как один большой главный отчет.
После выполнения процедуры sp_ListAllIndexes читатель получит основной отчет, в котором перечислены все индексы на всех таблицах текущей базы данных. Если в отчете никаких индексов нет, можно отнести пустой отчет к разработчикам и вежливо объяснить им, что база данных без индексов столь же полезна, как мышь без кнопок.