

Как сберечь память, пользуясь функциями сжатия в SQLCLR
Реляционные базы данных подразумевают наличие специального хранилища для данных, и большинство типов данных сохраняется без проблем, хотя бывают и исключения. Например, одна из таких ситуаций возникает, когда приходится часто сжимать бинарные данные, чтобы значительно сократить их объем. Если требуется хранить очень много бинарных данных, их компрессия может существенно уменьшить расходы на запоминающие устройства.
Несмотря на то что SQL Server не предоставляет встроенных возможностей компрессии, их можно добавить в SQL Server 2005, опираясь на Common Language Runtime (CLR). Рассмотрим способы сжатия данных в SQL Server 2005 и то, какую пользу можно извлечь из нового типа данных — varbinary(max), который приходит на смену весьма неудобному типу данных image. Ознакомившись с приведенными в этой статье примерами, вы научитесь сжимать данные SQL Server и узнаете, как применить код Windows .NET Framework для усиления влияния SQL Server 2005.
Обзор возможностей и первые шаги
Для того чтобы сжать данные перед сохранением в базу и привести в первоначальный вид после извлечения из базы, разработчикам годами приходилось изобретать собственные хитроумные решения. Некоторые сведения по этому вопросу приведены во врезке «Основы компрессии». Сильно упрощает решение подобных задач .NET Framework 1.1. В этой платформе предусмотрено пространство имен java.util.zip, с которым связаны методы архивирования и разархивирования данных. Например, в этой версии Framework можно создавать интерфейсные классы для непрямого вызова java.util.zip из языков .NET, таких как VB.NET и C#. Но инфраструктура .NET Framework 2.0, являющаяся частью SQL Server 2005 и Visual Studio (VS) 2005, уже содержит пространство имен System.IO.Compression. Использование методов этого пространства имен делает процесс компрессии и декомпрессии данных очень удобным.
Пространство имен System.IO.Compression, доступное во всех языках .NET, предоставляет два класса для компрессии и декомпрессии данных: DeflateStream и GzipStream. В DeflateStream применен алгоритм DEFLATE (в том виде, в каком он определен в документе RFC 1951). В GzipStream реализован формат gzip (определенный в RFC 1952), предназначенный для сжатия единичного файла и также основанный на алгоритме DEFLATE. DeflateStream и GzipStream, как следует из названия, работают с потоками данных. А потоки — это не просто серии байтов, это объекты, дополненные методами для манипулирования другими объектами.
Кратко остановимся на тех действиях, которые необходимо выполнить при создании любой программы компрессии, а затем перейдем к конкретным примерам. Сначала нужно добавить операторы Visual Basic (VB) Imports или using в C# для пространства имен System.IO и System.IO.Compression:
' VB Imports statements
Imports System.IO _
' for Stream object
Imports System.IO.Compression _
' for DeflateStream and _
GZipStream
// C# code
using System.IO;
// for Stream object
using System.IO.Compression;
// for DeflateStream and
GZipStream
Текст кода разбит на несколько строк из-за особенностей форматирования статьи в журнале.
Кроме того, для значений параметров и выходных значений функций нужно использовать собственный для SQL Server тип данных SqlBytes. SqlBytes является частью пространства имен System.Data.SqlType, которое для собственных типов данных SQL Server 2005 предоставляет соответствующие классы. Согласно документации по .NET, эти классы «являются более защищенной и быстрой альтернативой типам данных, имеющимся в .NET [CLR]». Дополнительное удобство предоставляет реализованный в пространствах имен SqlType интерфейс Inullable, который поддерживает актуальное «пустое значение». Использование собственных типов данных SQL Server, помимо прочего, избавляет от проблем преобразования типов. Внутри функций SQL CLR, конечно, можно использовать общие типы данных .NET, такие как массив Byte, например, но среда исполнения все равно будет конвертировать типы данных .NET в соответствующие типы SqlType. Преобразование типов означает как бы небольшой штраф в терминах производительности и не позволяет исключить возможные ошибки перевода. Так, при первом написании функции CompressBytes мы использовали массивы Byte. Работая с готовым кодом в SQL Server 2005, мы обнаружили, что среда исполнения конвертирует массивы Byte в varbinary(8000). Этот неудачный перевод одного типа данных в другой препятствовал работе с документами размером более 8 Кбайт.
Для компрессии данных нужно написать не занимающую много места пользовательскую функцию (UDF) типа SqlBytes:
Public Shared Function _
CompressBytes(ByVal _
UncompressedBytes As _
SqlBytes) As SqlBytes
В процессе сжатия используется как объект MemoryStream,
так и объект GzipStream, например следующим образом:
Dim outputStream As New _
MemoryStream ' Contains the _
compressed data
Dim zipStream As Stream _
' The zip stream used for _
compression
zipStream = New GZipStream_
(outputStream, _
CompressionMode.Compress) _
' instantiate
Эта функция выполняет компрессию, вызывая метод Write объекта GzipStream — метод, который записывает сжатые байты в объект MemoryStream (выходной поток). В следующем фрагменте кода видно, что метод Write требует указания количества несжатых байтов (чуть позже мы объясним, почему это важно):
zipStream.Write _
(UncompressedBytes.Value, _
0, CInt(UncompressedBytes. _
Length))
Теперь, когда сжатые данные находятся в выходном потоке, остается лишь получить данные из функции:
Return New SqlBytes _
(outputStream.ToArray)
Вот так легко данные сжимаются. Обратный процесс декомпрессии почти так же прост. Для декомпрессии данных используется метод Read объекта GzipStream. Метод Read, по асимметричному сходству с методом Write, требует указания количества сжатых байтов, которое будет обрабатывать. Мы пришли к выводу, что, создавая универсальный интерфейсный класс компрессии и декомпрессии, отслеживать количество сжатых и несжатых байтов неудобно. Поэтому мы решили, что применение подхода, в котором данные подвергаются компрессии и декомпрессии порциями и нет необходимости отслеживать излишние детали, вполне обоснованно.
Компрессия в примерах
Чтобы понять, как использовать в стандартном приложении Windows Forms пространства имен System.IO.Compression для компрессии и декомпрессии данных из SQL Server 2005 или из другого источника, можно использовать три .NET-проекта из поставки продукта. Для примера была выбрана база данных AdventureWorks, поскольку содержащиеся в ней данные хорошо подходят для теста компрессии. Тип данных varbinary(max), о котором говорилось выше, имеет столбец Document таблицы Document в схеме Production, где хранятся несжатые документы Word.
Для простоты в первом проекте мы отказались от каких бы то ни было обращений к базе данных. Программа представляет собой простое приложение Windows Forms и позволяет выбрать файл, задать метод компрессии и узнать процент сжатия. Также приложение показывает время сжатия и время, которое потребуется для декомпрессии, как показано на экране 1.
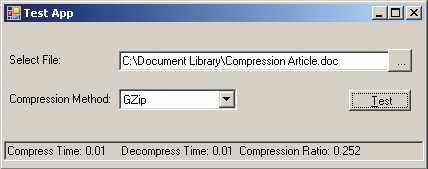
|
| Экран 1. Пример проекта приложения компрессии |
Поскольку процессы компрессии и декомпрессии данных посредством DeflateStream и GzipStream одинаковы, логику обоих алгоритмов компрессии можно встроить в одну и ту же подпрограмму или функцию. Поэтому в листинге 1 видно, что интерфейсный класс CompressWrapper содержит методы Compress и Decompress, каждый из которых имеет параметр для выбора и указания алгоритма. Код, отвечающий за компрессию, должен копировать несжатый поток в сжатый. Код, отвечающий за декомпрессию, наоборот, должен копировать сжатый поток в несжатый. Эти две операции копирования потоков можно объединить внутри одной универсальной функции. C#-версия CompressWrapper показана в листинге 2.
Заметим, что в коде под меткой A в листинге 1 объекты Stream являются параметрами метода CopyStream. Поскольку классы DeflateStream и GzipStream являются дочерними по отношению к классу Stream, оба они имеют тип Stream. Когда объекты потоков DeflateStream и GzipStream реализуются, второй параметр конструктора показывает, какие данные — сжатые или несжатые — будет содержать поток. Когда приложение передает в какой-то метод объекты Stream как значения параметров, из этого метода можно вызвать методы Read и Write объектов Stream, что и делает функция CopyStream. Если, например, объект несжатого потока передан во входной параметр, а объект GzipStream является выходным параметром, CopyStream, используя метод Read несжатого потока, берет порцию несжатых данных из входного потока. Затем приложение использует метод Write сжимаемого потока для сжатия порции и передачи сжатых данных в выходной поток GzipStream. Аналогично, если сжатый объект GzipStream — входной параметр, а объект несжатого потока — выходной параметр, CopyStream использует метод Read сжатого потока, чтобы взять порцию сжатых данных и подвергнуть их декомпрессии. Затем приложение использует метод Write сжатого потока для передачи порции после декомпрессии в несжатый выходной поток. Нет необходимости указывать полное количество байтов компрессии или декомпрессии, так как CopyStream обрабатывает порции, циклически вызывая методы Read и Write.
Теперь, после ознакомления с базовым подходом к компрессии и декомпрессии, перейдем ко второму примеру, который посвящен созданию проекта SQL Server и активации класса CompressWrapper в SQLCLR. Более подробно о том, как писать и использовать код CLR в SQL Server 2005, рассказано в статье «Как получить максимум от CLR», опубликованной в № 8 нашего журнала за 2005 год. Вызовите правой кнопкой мыши в Solution Explorer проект SQL Server и выберите в контекстном меню Add, New Item. На экране появится несколько доступных шаблонов объектов баз данных. Щелкните User-Defined Function. VS создаст класс с необходимыми предложениями Imports и образцом скалярной функции. Не меняйте этот класс, а сначала добавьте в проект наш интерфейсный класс компрессии (CompressWrapper.vb), нажимая Add, Existing Item. Ранее уже упоминалось, что в этом классе реализована логика компрессии и декомпрессии с целью обеспечения возможности многократного применения. И конечно, для большего удобства использования этот класс следует откомпилировать в отдельный модуль. Но нужно иметь в виду, что применение дополнительных модулей в проекте SQL Server требует и дополнительных настроек. Краткие указания по настройке ссылок на дополнительные модули .NET приведены во врезке «Как правильно настроить ссылку». Так что ограничимся пока многократным использованием на уровне класса. Импортируйте CompressWrapper.vb в файл классов функций и добавьте два вызова функций SQL, как показано в листинге 2. C#-версии этих UDF приведены в листинге 4. Выполните развертывание проекта с использованием функции VS 2005 Deploy.
Varbinary(max) спешит на помощь
Довольно часто бывает легко определить тип данных SQL Server по названию класса в SqlType (например, SqlMoney, SqlInt32). Поскольку компрессии подвергаются бинарные данные, они хранятся в новом типе данных varbinary(max), что соответствует типу данных SqlBytes.
Разработчики Microsoft, как было отмечено, забраковали тип данных image. Критически важной для нас заменой этому типу данных служит varbinary(max). Кто пытался работать с типом данных image в хранимых процедурах SQL Server 2000, тот знает, что эти типы данных для локальных переменных недопустимы. Более того, хотя переменную image можно передать в хранимую процедуру, изменить или выбрать значение переменной в другой переменной внутри той же процедуры нельзя. Благодаря varbinary(max) работа с большими объемами бинарных данных становится такой же простой, как работа с числовыми данными.
Соединяем в целое
От основ создания в .NET пользовательских функций перейдем к следующему примеру. Из файлов проектов следует открыть файл WindowsAppTestCompression.sln, где находятся проекты приложений Windows, которые могут вставлять и извлекать документы из базы данных AdventureWorks. Чтобы сделать пример более наглядным (и в то же время не менять оригинальной схемы AdventureWorks), в нем использована модифицированная копия таблицы Production.Document. Таблица называется Document-CompressEg; она имеет три дополнительных столбца для контроля размера документа (до и после сжатия), а также использованного метода компрессии.
Чтобы создать такую таблицу (и хранимые процедуры, которые использует Windows-приложение), нужно выполнить сценарий файла CreateTableAndSps.sql, который хранится в папке проекта Test Scripts. После этого можно будет вставлять и извлекать как сжатые, так и несжатые документы, и видеть достигнутый уровень сжатия по каждому из них (см. экран 2).
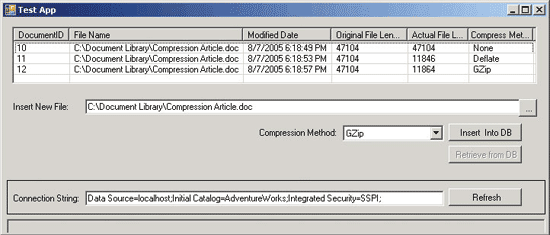
|
| Экран 2. Приложение Windows для компрессии данных |
Выбор пути
SQL Server 2005 характеризуется большой гибкостью и предоставляет широкий выбор вариантов развертывания, хранения и программирования. На примере описанного проекта мы показали, что наличие в SQL Server 2005 такого компонента, как CLR, позволяет применять и развертывать сложную логику компрессии на сервере базы данных, используя неэлементарный язык программирования. Попутно мы рассказали о том, что новый тип данных varbinary(max) упрощает манипулирование, хранение и воссоздание больших бинарных объектов. Это, конечно, не означает, что нужно все бросить и с ходу начать переносить всю сложную бизнес-логику и логику технических приемов на сервер базы данных. Но с такими усовершенствованиями у нас появляется намного больше возможностей в отношении планирования и проектирования систем.
Джон Пол Кук (johnpaulcook@email.com) — архитектор систем и баз данных из Хьюстона, Техас. Специализируется на помощи крупным компаниям и пользователям в работе с SQL Server, Oracle и .NET Framework. Имеет несколько сертификатов Microsoft и Oracle.
Тайлер Чесман (tylerc@microsoft.com) — специалист по технологиям в South Central District компании Microsoft, отвечает за адаптацию у клиентов платформ Database и Business Intelligence. До перехода в Microsoft несколько лет работал консультантом по вопросам развертывания финансовых, аналитических и торговых приложений.
Основы компрессии
Работа программы сжатия состоит в поиске фрагментов файлов с повторяющимися разрядами и последующей замене найденных фрагментов более короткими, которые называются токенами. Чем больше повторяющихся разрядов содержит файл, тем лучше он сжимается. Например, за счет компрессии можно существенно уменьшить размер большинства растровых файлов и документов Word. А вот JPEG-файлы являются уже сжатыми, поэтому попытки еще больше уменьшить размер этих файлов малоэффективны.
Выбор алгоритмов компрессии велик. И Gzip, и популярный формат Zip основаны на широко используемом алгоритме DEFLATE. Известно, что чем выше степень компрессии данных, тем больше времени занимает компрессия и декомпрессия. Поэтому компрессия и декомпрессия часто используемых данных может требовать слишком много времени.
Компрессию и декомпрессию можно выполнять на сервере, на клиенте и на промежуточном уровне. Если компрессия выполняется преимущественно на сервере, она может значительно уменьшить расходы на поддержку запоминающих устройств. Но когда есть избыток свободного пространства на клиентах, имеет смысл выполнять компрессию и декомпрессию именно на клиентах, особенно если клиент и сервер работают в медленной сети или в сети с ограниченной пропускной способностью.
Как правильно настроить ссылку
Разработчики постоянно группируют и компилируют общие функции, создавая единый компонент (например, DLL), к которому неоднократно могут обращаться различные приложения. Собственно Windows .NET Framework может рассматриваться как большая библиотека компонентов многократного использования. Интерфейсный класс компрессии из нашего примера также обладает мощным потенциалом многократного использования либо сам по себе, либо как часть набора пользовательских утилит.
Многократное применение какого-либо компонента в Visual Studio 2005 (VS) достигается путем добавления ссылки в проект. Достаточно просто щелкнуть правой кнопкой мыши на проекте и выбрать в меню команду Add Reference. Возможными ссылками могут быть встроенные компоненты .NET, пользовательские .NET-компоненты, .NET-компоненты независимых разработчиков и даже традиционные COM-компоненты. Сложнее обстоит дело с проектами SQL Server, где существует много ограничений на применение ссылок: только модули .NET, которые уже были созданы в SQL Server 2005, могут быть добавлены в качестве ссылок. Более того, лишь несколько модулей с точки зрения встроенной функциональности .NET являются «заранее созданными» (например, System, System.Data, System.Security, System.Transactions, System.Web.Services, System.XML). Если вы попытаетесь создать в SQL Server 2005 модуль, который ссылается на другой встроенный модуль .NET (например, System.Windows. Forms.dll), система выдаст сообщение об ошибке.
Это не означает, однако, что нельзя создавать и ссылаться на дополнительные модули .NET в проектах SQL Server. Но ограничения на пользовательские модули есть, и они устанавливаются рамками .NET Framework. Эти ограничения заставляют нас более осторожно относиться как к планированию порядка развертывания, так и к выбору логики .NET, которой хотелось бы воспользоваться.