

Инструментарий доступа к функциям бизнес-аналитики SQL Server 2005
Признаюсь, я был одним из тех специалистов по реляционным базам данных, которые не придавали большого значения Analysis Services. Я думал, что куб O. LAP — это место пребывания Оливера Лапа, сотрудника финансового отдела, с 8:00 до 17:00. Размерности (dimension), как мне казалось, могут интересовать только физиков и поклонников «Сумеречной зоны».
Мое отношение изменилось несколько лет назад, когда я узнал, каким образом компонент Analysis Services может пригодиться мне и моим клиентам. Взгляды сторонников традиционных реляционных баз данных тоже могут измениться после знакомства с документами SQL Server 2005 June Community Technical Preview (CTP), который можно загрузить по адресу http://www.microsoft.com/sql/2005/ productinfo/ctp.mspx. Цель этой статьи не в том, чтобы превратить всех приверженцев реляционных баз данных в «кубистов». Я просто хочу обратить внимание читателей на несколько чрезвычайно удобных функций бизнес-аналитики (business intelligence, BI) в SQL Server Integration Services (SSIS), которые можно использовать в реляционных приложениях. Две новые операции трансформации упрощают работу с неупорядоченными данными, а операция извлечения данных позволит построить модель данных, адаптируемую к изменениям в бизнесе. Для этих операций не требуется больших хранилищ данных или кубической инфраструктуры OLAP. Нужны лишь SQL Server 2005 и готовность осваивать новые технологии.
Трансформации SSIS
Сначала рассмотрим две задачи трансформации SSIS. Служба SSIS пришла на смену DTS (Data Transformation Services — служба преобразования данных). Она выполняет ту же функцию, что и DTS, а именно — переносит данные из одного места в другое. Однако возможности SSIS шире, она проще в использовании, требует меньше усилий в плане программирования и отличается очень высоким быстродействием.
В первую очередь мы поговорим о таких задачах трансформации, как Fuzzy Lookup (нечеткий поиск) и Fuzzy Grouping (нечеткая группировка). Как видно из названий, с помощью этих операций можно группировать и выполнять поиск без точного совпадения данных. Эти функции могут быть полезны при импорте информации из унаследованных систем или полей ввода данных произвольного формата.
Fuzzy Lookup. Функция Fuzzy Lookup считывает столбцы данных и отыскивает значения в таблице ссылок потока данных SSIS. Полного совпадения не требуется. Fuzzy Lookup напоминает снисходительного учителя: выставляет баллы по криволинейной шкале и дает частичный кредит доверия. Fuzzy Lookup ведет поиск близких совпадений между значениями в столбце и элементами таблицы.
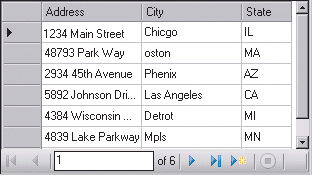
|
| Экран 1. Унаследованные данные из текстового файла |
Рассмотрим ситуацию, в которой нужно загрузить текстовый файл (экран 1) из адресной таблицы унаследованной системы. Части адреса, представляющие город и штат, в целевой системе нормализованы, а комбинации города и штата сохранены в отдельной просмотровой таблице. К сожалению, в унаследованной системе отсутствует контроль точности информации о городах, поэтому сопоставить город и штат с записью в просмотровой таблице будет трудно.
Выйти из положения поможет SSIS и трансформация Fuzzy Lookup. На экране 2 показан поток данных базового пакета SSIS. Пакет программируется с использованием метода drag-and-drop. Достаточно перенести элементы в панель инструментов, расположить их в потоке данных и назначить свойства. Самостоятельно составлять исходный текст не требуется. Пакет принимает данные из текстового файла, выполняет операцию Fuzzy Lookup в поисках внешнего ключа (foreign key) для комбинации города и штата, а затем сохраняет эту информацию в таблице Address в SQL Server. Как показано на экране 3, с помощью Fuzzy Lookup удалось успешно сопоставить неупорядоченные данные из текстового файла с соответствующими городами в просмотровой таблице.
В процессе работы Fuzzy Lookup генерирует две оценки. Первая из них — уровень совпадения (similarity score). Это число характеризует близость между элементами. Уровень совпадения вычисляется на основе количества изменений (edit distance) между значением и потенциальным совпадением. Другими словами, сколько раз необходимо вставить, удалить или заменить символы, чтобы получить слово в просмотровом списке? Второй показатель — уровень достоверности, вычисленная алгоритмом Fuzzy Lookup вероятность того, что совпадение обнаружено верно. Ориентируясь на этот показатель, пользователь может принять элемент, обнаруженный алгоритмом, или проверить его вручную.
Важная особенность Fuzzy Lookup: предполагается, что слова, целиком состоящие из прописных букв, представляют собой акронимы. Значимость каждой буквы акронима выше, чем у отдельных букв в обычном слове; FCC и FTC — две разные вещи. Хотя количество изменений этих акронимов равно единице, Fuzzy Lookup не делает попытки сопоставить их. Если унаследованные данные введены исключительно прописными буквами, то их следует перед запуском Fuzzy Lookup преобразовать в строчные.
Fuzzy Grouping — еще одна замечательная операция трансформации данных. Fuzzy Grouping работает аналогично Fuzzy Lookup, но отыскивает совпадения в одном наборе данных, а не использует просмотровую таблицу. Например, предположим, что данные импортируются из журнала обращений в службу технической поддержки (экран 4). Потребители не всегда одинаково называют свои имена при обращении за консультацией, и сотрудники службы могут записывать их по-разному. Cathy Jones, Kathryn Jones и Kathy Jones — вероятно, разные варианты записи имени одного человека (экран 4), но каким образом компьютер сможет выяснить это? Как раз с помощью трансформации Fuzzy Grouping.
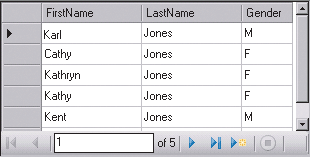
|
| Экран 4. Просмотр журнала обращений в службу поддержки |
На экране 5 показан пакет SSIS, который использует трансформацию Fuzzy Grouping для поиска потенциальных дубликатов в процессе импорта. На экране 6 показаны результаты импорта и отмечены потенциальные дубликаты. Операция Fuzzy Grouping не удаляет дубликаты автоматически; это делается в ходе отдельной операции.
Значение в столбце Key_In, генерируемое в процессе операции Fuzzy Grouping, представляет собой уникальный идентификатор для каждой записи в потоке данных. В процессе нечеткого сопоставления значение в столбце Key_Out, наряду с чистым значением для каждого столбца, обрабатываемого SSIS, показывает группы обнаруженных потенциально дублированных записей. В данном примере были сгруппированы строки со значениями Key_In 2, 3 и 4, а строка 4 идентифицирована как Model Row (строка, в которой следует объединить дублированные записи). Как и в операции Fuzzy Lookup, столбец Similarity/Score показывает уровень совпадения на основе величины редактирования. Уровень совпадения 1 указывает на точное соответствие. Уровни совпадения менее 1 указывают на нечеткое соответствие.
В данном примере пакет SSIS выполняет сопоставление имени и фамилии на основе методов нечеткой логики и точное сопоставление по полу. Предполагается, что люди знают свой пол, а сотрудник службы поддержки может ввести с клавиатуры M (для мужчины) или F (для женщины). Если увеличить число критериев операции Fuzzy Grouping, то уверенность в том, что две строки действительно дублируются, повысится. Например, можно ввести четкое или нечеткое сравнение по адресу, городу, штату, почтовому индексу или номеру телефона, чтобы с уверенностью определять дубликаты.
Добываем золото
Задача трансформации Data Mining Prediction Query — еще одна операция SSIS, которая поможет прогнозировать значения неизвестных данных в процессе загрузки информации. Иногда меня спрашивают: «Извлечение данных — это такой метод, в котором используются сложные математические алгоритмы и замысловатый язык запросов?» Это действительно так. Однако, прежде чем в глазах читателя появится скука и он перейдет к следующей статье, хочу отметить, что пользователю совсем не обязательно вникать в математические тонкости. Кроме того, язык запросов Data Mining Extensions (DMX) представляет собой расширение T-SQL. Поэтому многие элементы запроса DMX выглядят очень знакомыми.
Методы извлечения данных позволяют отыскивать закономерности и строить прогнозы внутри набора данных. Например, с помощью алгоритма извлечения данных можно исследовать тенденции в поведении покупателей и определить, какие товары и услуги тот или иной клиент может приобрести в следующий раз или кто из потребителей может обратиться к другому поставщику. В данной статье инструментарий извлечения данных используется для выбора продуктов, которые могут иметь спрос в розничном магазине.
Каждую неделю электронный книжный магазин получает от дистрибьютора список книг. Магазин платит за каждую книгу, которая публикуется на сайте, поэтому он заинтересован в том, чтобы в списке были только книги, которые наверняка будут проданы. Аналитик по продажам ежемесячно просматривает информацию о продажах и определяет, какие книги следует разместить на сайте. Руководство книжного магазина желает организовать автоматизированный процесс выбора книг, аналогичных текущим бестселлерам в национальных списках. Это можно сделать с помощью трансформации Data Mining Prediction Query.
Для трансформации Data Mining Prediction Query необходима модель извлечения данных. Модели извлечения данных размещаются в базе данных Analysis Services, поэтому необходимо иметь доступ к серверу Analysis Services. Использование Analysis Services входит в лицензию SQL Server 2005, и службу нетрудно добавить к существующему экземпляру SQL Server 2005.
Во-первых, необходимо построить модель извлечения данных на составление прогнозов для книжного магазина. SQL Server 2005 располагает несколькими алгоритмами извлечения данных. В нашем примере используется алгоритм извлечения данных Decision Trees, который успешно применяется для прогнозов, необходимых книжному магазину. Для прогнозирования используются следующие атрибуты: автор, издатель, формат (бумажный или твердый переплет либо аудиокнига) и жанр (например, приключения, детектив, научная фантастика). Уровень прогнозируемых продаж 1 указывает на потенциальный бестселлер.
После того как будет определена модель извлечения данных, необходимо оценить картину текущих продаж, чтобы иметь возможность предугадать будущие бестселлеры. Информация о продажах книжного магазина за прошлый месяц используется в модели извлечения данных в качестве обучающего набора данных. Таким образом можно определить критерий (автор, издатель, формат и жанр) для идентификации бестселлера и научиться прогнозировать продажи.
Mining Model Viewer (экран 7) показывает закономерности, обнаруженные обученной моделью извлечения данных. Затенение обозначает концентрацию бестселлеров в определенном узле дерева: чем темнее фон, тем выше концентрация. Заметна высокая концентрация бестселлеров среди книг издательства Random House. Еще выше концентрация лидеров продаж среди детективов, выпущенных этим издательством. Следовательно, в данный период времени целесообразно представлять на книжном сайте больше детективов Random House. Конечно, популярность книг меняется от месяца к месяцу, поэтому рекомендуется чаще переобучать модель данных, чтобы точнее отслеживать тенденции покупательского спроса.

|
| Экран 8. Переобучение модели данных |
Обученную модель извлечения данных можно использовать в составе пакета SSIS, который импортирует список книг дистрибьютора. Как показано на экране 8, управляющая логика процесса получает текстовый файл из FTP-узла дистрибьютора, переобучает модель извлечения данных с использованием информации о текущих продажах и, наконец, запускает процесс обработки данных, в ходе которого выполняется собственно импорт.
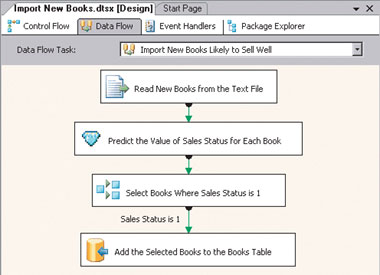
|
| Экран 9. Процесс обработки данных для выяснения количества продаж книги |
Процесс обработки данных (экран 9) считывает список имеющихся книг из текстового файла, а затем использует задачу трансформации Data Mining Prediction Query для прогнозирования статуса продаж каждой новой книги. Книги, отвечающие критерию бестселлеров (со статусом продаж 1), вносятся в таблицу Books и предлагаются в электронном магазине.

|
| Экран 10. Запрос DMX при транформации в Data Mining Query |
На экране 10 показан запрос DMX, используемый в трансформации Data Mining Prediction Query. Запрос выглядит очень похоже на предложение SELECT, которое выполняет слияние двух таблиц. Различие заключается в использовании PREDICTION JOIN вместо INNER или LEFT OUTER JOIN в типичных предложениях T-SQL. В данном случае PREDICTION JOIN получает критерий из потока данных @InputRowset пакета SSIS и посылает его в модель извлечения данных Books-DecisionTrees. Оператор JOIN устанавливает соответствие между полями таблицы данных и входами модели извлечения данных. Ключевое слово FLATTENED настраивает запрос DMX на генерацию набора данных со столбцами и строками вместо обычного иерархического набора данных. Функция Predict() со списком полей выдает прогнозируемый уровень продаж.
На экране 11 приведены результаты прогностического запроса: бестселлеры, добавленные в онлайновый магазин на этой неделе. Неудивительно, что все пополнения этой недели — детективы издательства Random House. Но на следующей неделе бестселлеры могут отвечать иному набору критериев и оказаться совершенно другими. В этом и заключается преимущество алгоритмов извлечения данных и автоматизации процессов в SSIS — в удобстве адаптации к изменяющейся ситуации путем постоянного переобучения модели.
Награда за смелость
Для специалистов, привыкших к реляционным компонентам SQL Server, инструментарий BI может показаться сложным, неприступным или просто ненужным. Однако функциональность SQL Server 2005 должна понравиться разработчикам как BI, так и реляционных моделей. Просто не надо бояться экспериментировать с адаптивными возможностями функций Fuzzy Lookup и Fuzzy Grouping, а также трансформацией Data Mining Prediction Query. С помощью нового инструментария можно быстро автоматизировать сложный процесс анализа существующих данных и добыть из них актуальные сведения. Хороший пример применения этих инструментов приведен в Web-презентации Джеймса Макленнана «Technology Overview: Business Technology Data Mining» на диске SQL Server 2005 Beta Resource Kit DVD. BI, безусловно, заслуживает внимания — загрузите новый CTP, и ваше мужество будет достойно вознаграждено.
Брайан Ларсон - Директор по технологиям в Superior Consulting Services, шт. Миннесота. В течение 13 лет занимался разработкой приложений для баз данных. Помогает консультантам и группе разработчиков Reporting Services в Microsoft. larson@teamscs.com