

Случаи катастрофических разрушений баз данных — явление нечастое, но уж если такие события происходят, то и последствия они имеют самые неприятные. В этой статье речь пойдет не о том, как уберечься от потерь данных и поддержать производительность на должном уровне после разрушения базы данных, а о восстановлении базы данных после изолированного катастрофического сбоя — в частности, после сбоя, который затрагивает только определенную часть базы данных. Например, может так сложиться, что будет утеряно некоторое подмножество данных — одна таблица или ее часть. Хотя полное восстановление базы данных — это возможность (иногда единственная), которая всегда под рукой, ряд стратегий резервного копирования и программное обеспечение от независимых разработчиков позволяют обрабатывать описанный тип сбоев более рационально.
Прежде чем перейти к обсуждению этих стратегий, давайте посмотрим, что именно может стать причиной изолированного сбоя. Один из возможных источников сбоя — отказ в аппаратном обеспечении. Но чаще всего причина потерь данных и, как следствие, простоев в работе — это человеческий фактор. Возможно, DBA случайно очистил содержимое таблицы или по ошибке удалил или обновил записи таблицы из-за некорректно составленного оператора WHERE. Может быть, разработчик базы неправильно протестировал приложение, в результате чего пользователи могли оперировать неверными данными. Восстановление после изолированного сбоя, вызванного ошибками сотрудников, может оказаться более сложной задачей, чем восстановление после аппаратного сбоя, поскольку точно неизвестно, что именно оказалось разрушенным, когда разрушено, или в чем причина и каковы масштабы разрушений. Если мы не располагаем полной информацией, мероприятия по восстановлению могут оказаться нерациональными, занять слишком много времени, привести к возникновению дополнительных ошибок и дальнейшей потере данных. Причина сбоя определяет и методику восстановления данных, поэтому давайте рассмотрим способы восстановления после аппаратного сбоя и после сбоя, обусловленного человеческим фактором.
Восстановление после аппаратного сбоя
Если в системе произошел аппаратный сбой, такой, например, как сбой на диске, база данных автоматически становится недоступной и выставляется атрибут suspect. Когда возникает сбой носителя информации, разрушенные данные легче восстановить, поскольку можно сделать только одно: найти другое подходящее место для размещения искаженного фрагмента базы данных. Это может быть место как для постоянного хранения данных, так и для временного размещения — до тех пор, пока неисправное оборудование не будет заменено или перенастроено. Заметим, что процесс восстановления данных после сбоя носителя протекает гораздо быстрее, когда под рукой имеются дополнительные жесткие диски или свободное дисковое пространство, которое сразу же после сбоя может быть задействовано для восстановления данных с помощью команды WITH MOVE. В противном случае, возможно, нужно будет заказать и какое-то время ждать получения новых дисков. После того как решен вопрос, куда восстанавливать данные, необходимо определить, как и когда лучше всего это сделать. Решение зависит от стратегии резервного копирования, модели восстановления и осведомленности относительно причины сбоя.
Когда утерян только один файл данных, все можно восстановить на момент сбоя — без каких-либо потерь. Такое восстановление с точностью до минуты возможно, поскольку SQL Server хранит в журнале транзакций подробную информацию об изменениях в данных. Чтобы обеспечить возможность восстановления с точностью до минуты, необходимо получить доступ к детализированной информации журнала транзакций разрушенной базы данных и просто восстановить данные журнала транзакций. Но восстановление данных с точностью до минуты возможно не всегда, и данные могут быть потеряны при следующих сценариях:
- часть или весь журнал транзакций утерян;
- в разрушенной базе данных использовалась модель восстановления Simple и только периодически выполнялась процедура полного резервирования Full Database Backup;
- используется модель восстановления с протоколированием массовых операций Bulk_Logged в разрушенной базе данных, и со времени последнего резервного копирования журнала транзакций выполнялась массовая операция.
Во всех этих случаях изменения, отраженные в журнале транзакций к моменту сбоя (так называемые «остатки» журнала транзакций), не могут быть зарезервированы, и, следовательно, данные можно восстановить только на время выполнения последнего резервного копирования. Как результат — все изменения, произошедшие с момента резервного копирования, придется выполнить заново.
Можно минимизировать потери данных, выполняя резервное копирование журнала транзакций чаще (скажем, каждые 5 минут). Также можно установить ограничения на время, в течение которого режим резервирования базы данных может оставаться в состоянии bulk-logged, используя для этих целей пакетные задания, в которых программным путем будут меняться модели восстановления. Однако потребуется некоторое время, чтобы определиться с оптимальным планом резервирования журнала транзакций и моделью восстановления.
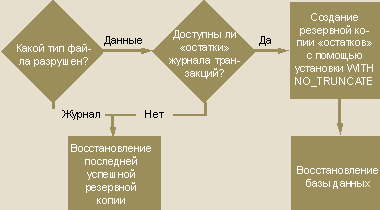
|
| Рисунок 1. Начальные шаги принятия решения о восстановлении данных после сбоя |
Когда база данных оказывается в состоянии suspect, необходимо решить, как лучше начать восстанавливать данные. На рис. 1 изображена диаграмма, на которой показаны самые первые шаги, предпринимаемые после того, как база данных оказалась в состоянии suspect. Если удалось установить, что «остаток» журнала транзакций доступен и может быть создана резервная копия журнала, в первую очередь необходимо создать резервную копию журнала транзакций с помощью режима NO_TRUNCATE. Этот ключ специально разрабатывался для ситуаций, когда некоторая порция данных в базе оказывается недоступной, но журнал транзакций все еще может быть зарезервирован. Следующий шаг — определиться с планом восстановления работоспособности базы данных. В зависимости от использовавшихся ранее типов резервного копирования, общее время, необходимое для восстановления, может быть сильно сокращено, если правильно выбрать порядок и тип резервных копий. SQL Server поддерживает две основные стратегии восстановления: на основе Full Database Backup и на базе пофайлового или группового резервирования файлов. Обе стратегии дают возможность восстановить только непосредственно разрушенный файл или группу файлов. Полное резервное копирование (Full Database Backup) базы данных означает, что на регулярной основе выполняется полное копирование как самой базы данных, так и журнала транзакций (например, еженедельное полное копирование базы и ежечасное копирование журнала). Дифференциальное копирование (Differential Backup) базы данных предоставляется как дополнение; однако этот тип резервного копирования может и не дать никакого преимущества с точки зрения времени восстановления. Нужно помнить о том, что Differential Backup — это тот же Full Backup, но с включением только тех экстентов, которые были изменены со времени последнего полного копирования базы. Во время процесса реанимации базы данных необходимо восстанавливать лишь самую последнюю дифференциальную копию вместо всей последовательности журнальных копий, созданных за тот же самый интервал времени.
Если используется стратегия резервирования File/Filegroup, то непосредственное полное резервирование не выполняется. Вместо этого приходится более тщательно разбираться с созданием резервных копий отдельных файлов и файловых групп. Применение стратегии File/Filegroup — задача более сложная, нежели проведение полного копирования, поскольку выполняется большее число заданий резервного копирования и каждое занимается какой-то своей частью базы данных. Но при этом восстановить недоступное подмножество базы данных можно быстрее, чем при работе с полной копией. Подробнее об этом рассказано в статье «Пока не грянул гром», опубликованной на сайте Windows & .NET Magazine/RE. Читая врезку «Восстановление данных после изолированного сбоя на диске» в этой статье, обратите внимание на существование проблем при работе с файловой группой, у которой установлен атрибут read-only. Описанная в статье проблема по-прежнему присутствует в версии SQL Server 2000 Service Pack 3 (SP3) и SP3a.
Ниже перечислены шаги, важные для определения самой быстрой процедуры восстановления, если отталкиваться от выбранной стратегии резервирования.
- Установите, доступен ли "остаток" журнала транзакций. Если да, создайте его резервную копию.
- Установите, сколько файлов повреждено.
- Восстановите разрушенную часть базы данных. Если используется стратегия Full Database Backup и разрушено небольшое число файлов, следует воспользоваться синтаксисом FILE = или FILEGROUP = в команде RESTORE для восстановления только испорченного файла или группы файлов. Нет нужды восстанавливать всю базу целиком. Если используется стратегия File/Filegroup, то потребуется восстановить только соответствующие файлы или файловые группы.
- Как вариант можно задействовать дифференциальные копии, чтобы "подвести" поврежденные файлы/группы максимально близко к моменту возникновения сбоя.
- С помощью журнала транзакций повторите транзакции в базе данных.
- Повторите транзакции и восстановите базу данных, используя "остаток" журнала. Необходимо убедиться, что используется конструкция RESTORE LOG...WITH RECOVERY. Если задействовать RESTORE WITH NORECOVERY, то базы данных можно попытаться разбить, используя RESTORE DATABASE dbname WITH RECOVERY, не восстанавливая резервных копий.
- Как вариант, если база данных или ее часть восстановлена по временному адресу, базу данных можно будет перенести в новое место (потом это можно проделать в любой момент). Сначала надо базу отсоединить, затем переместить файлы и снова их подсоединить. Дополнительную информацию о перемещении баз данных можно найти в статье Microsoft "Moving SQL Server Databases to a New Location with Detach/Attach" по адресу http://support.microsoft.com/default.aspx?scid=kb;en-us;224071.
Восстановление после ошибки оператора
Если ошибка человека привела к изолированному искажению данных, при восстановлении данных возникают более серьезные проблемы, чем это было в предыдущем случае из-за сбоя оборудования. Как уже отмечалось ранее, можно не знать, когда или как возникло разрушение данных и каковы его масштабы. Во врезке «Защита никогда не помешает» рассказано, как можно минимизировать человеческие ошибки или полностью защититься от них. Когда о разрушении данных становится известно, прежде всего нужно определить, не распространились ли разрушения и на другие серверы, — от этого зависит, что предпринимать дальше. Если используются такие системы высокой готовности, как SQL Server, то после некоторого технологического тайм-аута можно будет настроить вспомогательный сервер для поддержки журналов транзакций. А если задействовать два резервных сервера, их можно настроить так, чтобы один из них получал данные в реальном времени для использования после сбоя на сайте, а другой — для получения данных на период ликвидации последствий изолированного сбоя. Однако если резервный сервер поддерживает и журналы транзакций, причем получает их от основного сервера, то в этом случае данные на обоих серверах — и основном, и резервном — окажутся искаженными.
Как только выясняется, разрушены ли данные на вспомогательном сервере, использование имеющихся в распоряжении DBA инструментов становится более осмысленным. Вот несколько действий, которые можно безотлагательно предпринять.
- Решите, нужно ли переводить базу данных в автономный режим и нужно ли переключать пользователей базы данных на вторичную базу (сервер).
- Определите, нужно ли оставить пользователям доступ к производственной базе данных (если решено не переключать пользователей на вторичный сервер).
- Установите границы проблемы.
- Определитесь, чем вы располагаете для восстановления данных.
- Приступайте к восстановлению.
Каждый из перечисленных шагов будет сопровождаться необходимостью выбора из большого числа сопутствующих параметров, со своими аргументами за и против. Требуется найти время на рассмотрение всех перечисленных ниже вариантов и выбрать лучший план реанимации производственной базы данных.
Предоставление пользователям доступа к базе данных. Этот шаг чрезвычайно важен, поскольку на данном этапе можно предотвратить дальнейшее разрушение базы и при удачном стечении обстоятельств сохранить пользователям доступ к данным, и, таким образом, простоя не будет. Если имела место ошибка оператора, SQL Server не выставит флаг suspect и не закроет пользователям доступ к базе данных, что произошло бы в случае аппаратного сбоя, например разрушения диска. Но узнать о разрушении базы можно будет только в том случае, если станет известно о некорректности, отсутствии или разрушении данных.
Если нет вспомогательной базы данных, на которую можно было бы переключить пользователей, можно попробовать начать процесс восстановления либо с ограничения доступа к базе, либо выставив флажок read-only для поврежденной базы данных. Доступ к базе нужно ограничить следующим образом:
ALTER DATABASE dbname SET RESTRICTED_USER
Базы данных, маркированные как RESTRICTED_USER, разрешают доступ только владельцам роли db_owner или системным администраторам. Чтобы перевести базу в состояние read-only, что дает возможность пользователям видеть данные, но не модифицировать их, применяется следующая команда:
ALTER DATABASE dbname SET READ_ONLY
Решение, должны ли пользователи иметь доступ к базе после ее повреждения, зависит от ее наполнения, приложения и степени разрушения базы данных. После того как решение принято и есть уверенность, что пользователи разрушат базу еще больше, можно двигаться дальше и приступать собственно к восстановлению базы данных.
Границы проблемы. Вероятно, самое сложное в процессе восстановления — установить масштабы проблемы. Если известно, как именно произошло разрушение данных, вероятно, и объем разрушений установлен. Но если ничего не известно ни о причинах происшедшего, ни о механизме разрушений, потребуется провести анализ поврежденной базы данных, чтобы установить степень разрушений. Нужные сведения можно получить при помощи команды SQL Server RESTORE WITH STANDBY или инструментальных средств независимых разработчиков программного обеспечения.
К примеру, для того чтобы разобраться в проблеме, сначала следует восстановить предыдущую версию базы данных в надежное место (на оригинальный сервер или куда-либо еще) и начать методично проверять, не содержит ли предыдущая версия базы уже поврежденные данные. Небольшой «трюк» — можно использовать различные варианты восстановления для перевода базы в состояние read-only, после чего продолжать восстановление дополнительных журналов транзакций или частей журналов. В такой дублирующей системе можно просмотреть данные между каждым использованием журнала. Но перед тем как повторять транзакции, и это еще одна хитрость, следует скопировать чистую версию данных в третью базу. Это действие чрезвычайно важно, поскольку тем самым мы сохраняем корректную версию данных, прежде чем восстанавливать очередной журнал, что, вполне вероятно, приведет к разрушению данных. После того как будут применены разрушающие транзакции, мы уже не сможем вернуться назад к более ранней версии данных без того, чтобы начать заново всю пройденную последовательность восстановления вплоть до последнего неискаженного журнала транзакций. Для поиска источника разрушений данных можно применить такую последовательность действий.
- Восстановите самый последний вариант резервной копии Full Backup, в котором, по вашему мнению, содержатся только неискаженные данные. Если для создания резервных копий базы данных используется стратегия Full Backup, всегда есть возможность восстановить целиком всю базу данных, или же только разрушенные файлы, или файловые группы с помощью RESTORE WITH STANDBY. Если применяется стратегия Differential Backup, придется восстанавливать всю базу данных целиком, так как SQL Server не поддерживает возможность RESTORE WITH PARTIAL для резервных копий файла или файловой группы.
- Если вы предпочитаете работать с Differential Backup, восстановите самый последний вариант резервной копии Differential Backup, в котором, по вашему убеждению, содержатся только корректные данные. И снова, если используется стратегия Full Backup, нужно убедиться, что, применив RESTORE WITH STANDBY, можно будет продолжить восстанавливать транзакционные журналы. Необходимо считать из восстановленной версии данные и определить, искажены они или еще нет. Следует использовать INSERT/SELECT для копирования восстановленных и неискаженных данных в третью базу данных (временное хранилище), чтобы в случае необходимости всегда была возможность извлечь эти данные заново.
- Воспользуйтесь оператором WITH STANDBY для восстановления каждого транзакционного журнала либо целиком, либо применив WITH STOPAT, восстановив некоторую часть журнала транзакций, после чего тщательно просмотрите табличные данные - не разрушены ли они. Убедившись, что данные не разрушены, следует применить функцию TRUNCATE для временного хранилища, а затем INSERT/SELECT для размещения неповрежденных данных во временном хранилище. Цель всех усилий - сохранить самую последнюю версию неискаженных данных, чтобы затем перенести их в производственную базу, если решено будет сделать именно так. При восстановлении придется работать с большим числом параметров, однако "чистая" версия данных всегда может пригодиться. Описанный процесс нужно повторить для каждого транзакционного журнала, чтобы максимально близко подойти к тому моменту, когда произошло разрушение данных. Следует использовать STOPAT для указания внутри журнала времени, к которому процесс восстановления должен остановиться, вместо восстановления всего журнала транзакций целиком. Продвигаясь "вдоль" журнала такими короткими шагами и просматривая данные, можно будет осуществить верификацию данных в различные моменты времени. Я использовал в своем примере специально написанные сценарии и всевозможные команды восстановления, чтобы показать все тонкости процедуры анализа проблемы.
Выбор варианта восстановления. После того как масштабы проблемы установлены, предстоит выбрать наиболее подходящий способ восстановления базы данных. По большому счету существует две возможности: восстановить всю базу данных целиком на некоторый момент времени в прошлом или же восстановить поврежденные данные в другое место, чтобы затем вручную, с помощью более ранних и неповрежденных версий данных, возвратить их в производственную базу. Оба подхода имеют свои плюсы и минусы. Если восстановить всю базу целиком, не будет никаких проблем с точки зрения целостности данных, поскольку база данных будет восстановлена на момент времени в прошлом, когда она находилась в непротиворечивом состоянии. Однако в зависимости от того, сколько прошло времени с момента нарушения целостности данных, может оказаться, что потери важных для бизнеса данных слишком велики, если «откатывать» назад всю базу целиком.
Вторая возможность — «склеивание» данных вручную — это очень длительный процесс, с высокой вероятностью возникновения ошибок, все зависит от характера разрушения и типа поврежденных данных. При ручном «склеивании» данных в базе может понадобиться изменить большое число зависимостей. Например, если некоторая таблица имеет внешние ключи с каскадными ограничениями (cascading constraint), данные, не расположенные непосредственно в разрушенных таблицах, также могут оказаться поврежденными. Здесь открывается целый круг тем, которые могут быть отнесены к нашей проблеме. Если принято решение восстанавливать разрушенные данные в какое-то другое место и переносить данные вручную в производственную базу, следует помнить, что всем разработчикам базы данных, всем DBA — иными словами, всем заинтересованным лицам — необходимо выделить время для ручной верификации данных до того, как отдавать базу данных в распоряжение пользователей.
Реанимация базы данных. Руководящее правило для восстановления базы данных — использовать самый эффективный метод. Прежде чем начинать действовать, нужно запомнить несколько простых правил. Не следует пользоваться оператором RECOVERY в команде RESTORE до тех пор, пока самый последний журнал транзакций не будет подготовлен для восстановления данных. Если начать реанимировать базу данных раньше времени, придется заново проделать всю процедуру восстановления. Использование NORECOVERY для каждого восстановления, даже для самого последнего — более надежная техника работы, поскольку она позволяет выполнить реанимацию базы, не запуская процедуру восстановления. Если все backup-наборы уже восстановлены и если NORECOVERY использовался для каждого шага восстановления, можно с помощью команды RESTORE DATABASE dbname WITH RECOVERY реанимировать базу данных — т. е. отменить все незавершенные транзакции. Нужно помнить, что без специального задания параметров в команде RESTORE работает режим по умолчанию, а именно — RECOVERY.
Еще одно правило — необходимо восстанавливать только поврежденные файлы и файловые группы. Не следует запускать процедуры восстановления всей базы данных до тех пор, пока это не станет абсолютно необходимым. И наконец, если принято решение о восстановлении производственной базы данных на некоторый момент времени, нужно использовать WITH STOPAT для определения, когда следует остановить реанимацию. Если решено вручную переместить данные между временной базой данных и производственной базой, можно задействовать INSERT/SELECT для выполнения копирования данных — это самый эффективный способ.
Анализ разрушений
Теперь рассмотрим процесс анализа разрушенной базы с применением режима RESTORE WITH STANDBY. На рис. 2 показан пример такого анализа. База данных состоит из семи файлов: одна основная (primary) файловая группа, три файловые группы read/write (RWFG), две — read-only (ROFG), а также один журнал транзакций. Предположим, что в момент времени time-point 1 была создана полная резервная копия базы данных, Full Backup, в момент времени time-point 2 — резервная копия журнала транзакций, в момент времени time-point 3 — Differential Backup базы данных и в момент времени time-point 4 — очередная резервная копия журнала транзакций. Между каждыми двумя заданиями резервного копирования тот же самый сценарий модифицирует данные в базе, так что всякий раз резервные копии отличаются одна от другой.
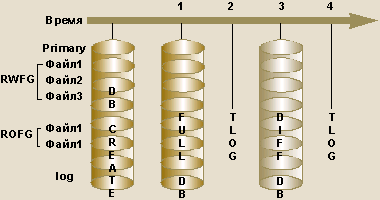
|
| Рисунок 2. Пример установки с использованием WITH PARTIAL и STOPAT |
В момент времени time-point 4 выясняется, что в таблице RWFG произошло искажение данных. Невозможно точно сказать, когда произошло повреждение данных, и с помощью серии восстановительных процедур требуется это выяснить. На сервере достаточно свободного места, и принято решение восстановить RWFG (а также основную файловую группу и журнал транзакций) на том же сервере, где размещается оригинальная база, но в другую базу данных и другие файлы. Очевидно, что для этого потребуется использовать команду RESTORE с указанием многочисленных параметров.
Чтобы восстановить базу данных в новое место, в команде RESTORE применяется режим WITH MOVE. Для восстановления только одной группы RWFG в операторе RESTORE следует указать имя файловой группы и параметр PARTIAL в операторе WITH. Чтобы быть уверенным, что можно будет продолжать восстанавливать дополнительные резервные копии на частично восстановленную базу данных, необходимо использовать оператор STANDBY в RESTORE и указать UNDO-файл. Файл UNDO — это то место, в котором SQL Server размещает транзакционную информацию для открытых — следовательно, незавершенных — транзакций. Незавершенные транзакции помещаются в файл UNDO в самом конце процесса восстановления, с тем чтобы SQL Server мог применить (повторить) транзакционную информацию из следующего журнала транзакций. В листинге показан полный синтаксис процедуры восстановления.
После того как описанная процедура восстановления успешно завершена и известно, что разрушение данных произошло после проведения Differential Backup, можно приступать к восстановлению резервной копии Differential Backup. Но если нельзя точно сказать, когда произошло разрушение базы, использование индивидуальных копий журнала транзакций предоставит более детальное восстановление — можно будет продвигаться вперед по временной шкале более мелкими шагами. В приведенном примере я выбрал восстановление с шагом 1 минута. В таблице показано, когда выполнялось восстановление и что изменялось в выходных данных команды RESTORE HEADERONLY. Эта команда очень удобна для отображения номера, времени и типа резервных копий, которые присутствуют на устройстве резервирования или наборе носителей.
В нашем случае Full Backup финишировал очень быстро, поскольку база данных была только что создана и не содержала большого количества данных. Самая первая копия журнала транзакций была создана ровно через 3 минуты, а Differential Backup — еще тремя минутами позже. Последняя копия журнала транзакций сформировалась через 3 минуты после Differential Backup. Самый лучший способ отработать с использованием всех резервных копий — выбрать время и от этого момента двигаться вперед маленькими шажками. Поскольку нет точного представления о том, когда произошло разрушение данных, продвижение через копии журналов транзакций будет происходить с помощью параметров STANDBY и STOPAT в команде RESTORE. Чтобы восстановить самую первую минуту первого журнала, следует указать время. Журнал транзакций был зарезервирован в 13:40:30, и в него вошли все изменения со времени завершения последнего Log Backup. Но поскольку это самый первый Log Backup после создания базы данных (и ее резервной копии), реально в нем будет находиться только информация со времени выполнения последнего Full Backup, завершенного в 13:37:09. Следующий Log Backup будет содержать изменения с момента завершения первого Log Backup. При восстановлении можно будет выбрать любой момент времени в диапазоне с 13:40:30.000 по 13:47:12.000 и, если нужно, восстановить некоторые данные или же весь журнал транзакций. Если надо восстановить только часть журнала транзакций, можно будет восстановить каждую минуту или каждые 30 секунд ценной информации. Хотя подобный пошаговый метод восстановления занимает немало времени, в некоторых ситуациях это может оказаться очень полезным. В каждом варианте восстановления следует специфицировать STOPAT, STANDBY и файл UNDO, что позволит исследовать состояние данных в каждый момент времени. Следующий фрагмент кода демонстрирует восстановление первого Log Backup, в котором используются STOPAT, STANDBY и даны инструкции для указания файла UNDO в STANDBY =:
RESTORE LOG NewPubsTest FROM WITH FILE = 2, - The backup - number by position. STOPAT = '2003-06-20 13:38:00', STANDBY =
Хотя пошаговый процесс прохождения по копиям Log Backup может показаться несколько утомительным, в каждом случае всегда можно будет определить, насколько тщательно следует обрабатывать копии журналов транзакций того или иного приложения. В каждом случае выбираются нужные для проверки данные, которые затем анализируются, и делается вывод о наличии либо отсутствии проблемы. Сохранение данных в другую базу между отдельными загрузками данных также помогает провести окончательную реанимацию базы более быстрыми темпами, если решено переносить данные в производственную базу данных вручную, а не восстанавливать всю производственную базу целиком с возвращением к какому-то моменту времени в прошлом.
До тех пор пока выполняется резервное копирование журналов транзакций, можно задействовать RESTORE WITH STANDBY, чтобы иметь возможность отрабатывать резервные копии более детально, и не имеет значения, какой тип стратегии резервирования применяется. Но если в конкретной ситуации выполняются все три перечисленных ниже критерия, можно будет восстановить только ту часть базы, которая действительно повреждена, в другое место и провести анализ ситуации с использованием режима WITH PARTIAL в команде RESTORE.
- Применяется стратегия резервирования Full Backup, т. е. выполняется полное резервное копирование самой базы и журналов транзакций. Выполнять Differential Backup необязательно.
- База данных разделена на множество файлов и файловых групп.
- Необходимо восстановить только отдельно взятый файл или файловую группу.
Следует отметить, что, если решено восстанавливать некоторое подмножество базы данных с помощью RESTORE WITH PARTIAL, SQL Server потребует предварительного восстановления основной файловой группы.
Использование программного обеспечения независимых разработчиков
Для исследования состояния разрушенной базы данных можно воспользоваться программными средствами независимых разработчиков. Некоторые из пакетов предлагают функции реинжиниринга (reverse-engineer) транзакционного журнала и генерацию для этой цели соответствующих операторов T-SQL. Во время работы такие утилиты сообщают, какие пользователи какие операции выполняют в настоящий момент. Можно с помощью скрипта реинжиниринга «изменить историю», используя сгенерированные сценарии как форму реанимации базы данных вместо восстановления журналов транзакций. Однако при этом существует риск потерять целостность данных — особенно если история базы изменена. Если удалить некоторые команды сценария, но при этом запускать остальные команды, работа оставшихся операторов может привести к появлению совершенно иных результатов и других данных. Мало того, пользователи могут начать выполнять свою повседневную работу, опираясь на информацию, полученную в результате работы модифицированных сценариев. Вместе с тем такие программные средства могут оказать помощь, когда необходимо быстро отыскать искаженные данные и получить информацию о том, как избежать в будущем повторения изолированного разрушения данных. Например, в результате работы такого программного обеспечения можно обнаружить некое вредоносное приложение, которое после решения всех проблем можно попросту закрыть.
Но самое большое преимущество от использования таких программ состоит в том, что их можно применять для чтения журналов транзакций после фиксации изменений. В отличие от таких продуктов, SQL Server не предоставляет механизм для чтения журналов транзакций. Когда используется встроенный инструментарий SQL Server, можно выполнить некоторые представления аудита реального времени, чтобы выяснить, кто стал виновником проблем, когда произошло повреждение данных. Но для этих целей разрешается использовать только триггеры, специально написанные приложения или такие инструменты, как SQL Server Profiler. Если опираться на возможности восстановления SQL Server, необходимо примерно знать, что было повреждено и что следует искать. А при работе с программным обеспечением независимых разработчиков предоставляется возможность непосредственной работы с журналом транзакций — что, конечно, более эффективно.
Вот два основных программных инструмента для исследования журнала транзакций: Log Explorer (разработка компании Lumigent Technologies, http://www.lumigent.com) и разработка SQL-BackTrack фирмы BMC Software, о которой можно прочитать в http://www.bmc.com/products/proddocview/ 0,2832,19052_19429_23365_1058,00.html.
Оценка проведенного восстановления
После того как поврежденные вследствие изолированного сбоя данные восстановлены, необходимо провести анализ происшедшего. В чем была проблема — в системе безопасности приложения или в заложенной в приложении функциональности? Так ли выполнялся процесс восстановления работоспособности, как было запланировано? Что пошло не так, как надо? Что можно сделать, чтобы в будущем осуществить восстановление было проще? И, что самое главное, необходимо проанализировать, какие действия следует предпринять, чтобы в будущем такие печальные события больше не повторялись.
Реализуя стратегии предотвращения аппаратных сбоев, целесообразно рассмотреть построение избыточных с точки зрения установленного оборудования систем для минимизации возможных проблем из-за сбоев «железа». Кроме того, потребуется разработать мероприятия по предотвращению, насколько это вообще возможно, проблем из-за ошибок оператора. Надо, однако, признать, что абсолютно надежных и не подверженных ошибкам систем не существует. Знание своих возможностей при восстановлении базы данных тем не менее поможет минимизировать время простоя и вернуть систему в стабильное и работоспособное состояние. Имеет смысл уже сейчас разработать несколько сценариев восстановления данных после отказа применительно к условиям работы конкретной сети. Следует провести тестовые испытания, составить документацию на все мероприятия и процедуры, а также учесть особенности своих данных, используемые модели восстановления и прочие факторы, так или иначе относящиеся к описанной в данной статье проблеме.
Кимберли Трипп — президент компании SYSolutions. Она имеет сертификат MCT и 10-летний опыт решения реальных проблем с помощью SQL Server. С ней можно связаться по адресу: Kimberly@SolidQualityLearning.com
Защита никогда не помешает
Если тщательно разработать план действий в случае потери данных и разрушения базы, то вам, несомненно, удастся уменьшить масштабы ущерба, нанесенного изолированным сбоем. Тем не менее основные усилия следует сосредоточить на базовом проектировании, реализации и тестировании мероприятий, направленных на предотвращение или минимизацию последствий человеческих ошибок. Например, если дать пользователям возможность работать с данными только через хранимые процедуры, представления и функции вместо прямого доступа к таблицам базы данных, вы сможете свести к минимуму вероятность случайного удаления и обновления данных в результате некорректного использования WHERE. Просто, прежде чем отдавать хранимую процедуру своим пользователям, нужно убедиться, что она тщательно протестирована.
Изначально у вас всегда есть возможность помешать пользователю удалить содержимое таблицы. Во-первых, право «сбросить» таблицу имеют владелец таблицы, члены роли db_ddladmin или db_owner или системный администратор (sa). Во-вторых, можно предотвратить сброс содержимого, даже если это действие выполняется с полным на то правом. Если внешний ключ ссылался на таблицу или она находилась в цепочке жесткой зависимости, SQL Server не позволит сбросить содержимое такого объекта, пока сохраняется ссылка на объект (зависимость). Зависимости вынуждают зависимые объекты оставаться в целости и сохранности без модификации или удаления. Однако не для каждого объекта существует внешний ключ зависимости. Для такого объекта можно использовать привязанное к схеме представление — schemabound view — для создания зависимой цепочки исключительно в целях защиты от случайного сброса таблицы. О том, как данное представление препятствует удалению таблиц, рассказано в статье «Полезные советы при работе с T-SQL», опубликованной на нашем сайте.
Код для выполнения самого первого восстановления базы данных
RESTORE DATABASE NewPubsTest FILEGROUP = ?RWFG? FROM WITH PARTIAL, MOVE ?pubs? TO , MOVE ?pubs_log? TO , MOVE ?PubsTestRWFile1? TO , MOVE ?PubsTestRWFile2? TO , MOVE ?PubsTestRWFile3? TO , MOVE ?PubsTestROFile1? TO , MOVE ?PubsTestROFile2? TO , FILE = 1, — This is the backup number by position. STANDBY =
Пример затрат времени на различные типы резервного копирования
| Тип резервирования | BackupStartTime | BackupFinishTime |
| Full Database Backup | 2003-06-20 13:37:08.000 | 2003-06-20 13:37:09.000 |
| Transaction Log Backup | 2003-06-20 13:40:30.000 | 2003-06-20 13:40:30.000 |
| Differential DB Backup | 2003-06-20 13:43:51.000 | 2003-06-20 13:43:51.000 |
| Transaction Log Backup | 2003-06-20 13:47:12.000 | 2003-06-20 13:47:12.000 |