
О чем нельзя забывать при переводе ресурсов сети с одного сервера на другой.
Bсякий, кому приходилось когда-нибудь переезжать с квартиры на квартиру, легко согласится с тем, что два переезда равны одному пожару. А если это «переезд» файловых и принтерных ресурсов предприятия? Ведь администратору сети придется четко сформулировать возникшие в этой связи задачи, аргументированно представить руководству необходимость «переезда» и реализации комплекса мер, разработанных для его осуществления, получить поддержку у службы сопровождения рабочих мест и многое другое. По своему опыту могу сказать следующее: ни руководство, ни коллеги из службы поддержки клиентов, ни сами клиенты вас на деле не поддержат. И не столько из-за технического непонимания проблемы, сколько в силу общей инертности поведения. Ну да ладно - только бы не мешали. Все, что остается, - утешать себя мыслью, что ценой вашей премии оплачена техническая живучесть организации. А еще тем, что накопленный опыт будет опубликован и кому-нибудь да пригодится.
Kонкретная ситуация в нашей организации: за пять лет эксплуатации двух серверов из состава центральной группы (кластер от компании Digital, тогда еще здравствовавшей) объективные и субъективные показатели работы кластера перестали удовлетворять требованиям нормального функционирования. На данной паре серверов были реализованы следующие задачи:
- основные службы регистрации пользователей (серверы служили контроллерами домена) - около тысячи активно работающих пользователей ежедневно;
- весь сетевой сервис печати организации;
- основной файловый сервис (до 95%);
- почтовый сервер MS Exchange банка (на сервере MS Exchange объем оперативной памяти составлял менее 200 Мбайт).
Поясню, что я имел в виду, говоря об объективных и субъективных показателях.
Когда-то в вычислительных центрах в основном работали ЕС-ЭВМ и СМ, и субъективный интегральный показатель нормального функционирования всего комплекса эмпирически оценивался так: время реакции системы при работе в интерактивном режиме не должно было превышать 7 с. Знатоки утверждали, что это время вычислялось на основе законов эргономики и подтверждалось исследованиями зарубежных специалистов.
В нашем случае показатель «7 с», как утверждали и сами пользователи, и сотрудники службы технической поддержки, обслуживающей рабочие места, превышался не только в пиковое время (утренние часы - массовая регистрация в сети, биржевые торги, подготовка перекрестных отчетов подразделений и т. п.), но и в самые «безобидные» часы работы - скажем, в обед. Стал нормой ручной сброс на печать заданий, зависших по тем или иным причинам (в противном случае вклад службы принт-сервера в общую загрузку процессора составлял около 95%), и перезапуск служб MS Exchange. В конечном итоге было решено не реже одного раза в неделю в плановом режиме просто-напросто перезагружать узлы кластера.
Объективные показатели перегрузки в работе узлов кластера определялись по данным счетчиков Performance Monitor: средний уровень очередей к дисковой подсистеме - 4 (в течение суток (!), что уж говорить о часах пик…), загрузка процессорной подсистемы (по два 133-мегагерцевых процессора на каждом узле) - 70% непрерывно свопируемой памяти, - все это явно свидетельствовало о наличии в системе узких мест.
Кроме того, объем данных на общей дисковой стойке возрос настолько, что практически вся информация была сжата средствами NT, и все равно приходилось ежедневно скрупулезно выискивать крохи, которые можно было бы удалить или вынести на магнитную ленту.
Очевидно, что в таких условиях продолжать эксплуатацию серверов было очень и очень рискованно. Всесторонне рассмотрев пути выхода из сложившейся ситуации, мы решили перенести задачи, выполняемые на двухузловом кластере в реализации Digital, на более мощный кластер, но уже производства Microsoft. В этом и состояла суть «переезда».
Перечислю вкратце задачи, которые стоят перед администратором сети в период «переезда» ресурсов организации с одной группы серверов на другую. Понятно, что все эти задачи в равной степени важны, и решать их придется одновременно.
1. Создание процедуры Generic Application для синхронизации сценариев регистрации на контроллерах домена. Одно из отличий программных реализаций кластеров производства Digital и Microsoft состоит в том, что в кластере от Digital для каждого ресурса существует понятие Pre- и Post-задания - другими словами, что делать до и после перемещения ресурса с места на место. Оформить эту своеобразную «окантовку» можно, например, с помощью BAT-файла. В продукте Microsoft такое понятие отсутствует, но зато есть его аналог - процедура Generic Application. С ее помощью можно не только оформлять фактически Pre- и Post-задания для любого ресурса, но и составлять куда более сложные процедуры.
Новое месторасположение перемещаемых ресурсов - кластер Microsoft Cluster Server for Windows NT. С появлением MSCS существующую синхронизацию каталогов регистрации необходимо дополнить еще одним источником синхронизации - кластером от Microsoft. Для этого и требуется написать отдельную процедуру синхронизации файлов сценариев, т. е. создать Generic Application.
Официально Generic Application - тип ресурса, который может быть создан в среде кластера Microsoft. По сути же - это самое обычное приложение. Значение данного типа ресурса поясню на примере.
Допустим, пользователь собирается ежедневно в час ночи запускать программу антивирусного сканирования. При этом программа-сканер действует независимо от кластера. Все, что ей необходимо, - наличие диска для проверки. В то же время диск может быть перемещен после сбоя на другой узел кластера. Т. е., если не принять никаких дополнительных мер, программа-сканер просто-напросто аварийно завершится, не найдя диска на своем «родном» месте.
Как быть? Устанавливать антивирусный сканер на обоих узлах и не обращать внимания на то, что одна из программ сканирования всегда будет завершаться аварийно? Поискать кластерную реализацию сканера? Как всегда, решений может быть несколько. Одно из них - использование ресурса типа Generic Application.
Суть решения в следующем: пишется командный файл (возможностей BAT-файла в данном случае вполне достаточно), в котором вначале проверяете наличие сканируемого диска. Если оказывается, что диск «на месте», нужно инициировать запуск программы-сканера. Если же нет - запустить программу сканирования на удаленном диске (т. е. на диске соседнего узла). Все, остается только разместить данную BAT-процедуру в списке задач планировщика на одном из узлов кластера.
А теперь предположим, что у нас имеется сервер, который как бы «переезжает» вслед за диском, если тот по каким-либо причинам переместился на соседний узел. Другими словами, для такого сервера сканируемый диск всегда «под рукой». В этом случае в BAT-процедуре можно смело указать сканируемый диск и не задумываться о том, есть ли он в данный момент на сервере. (Периодичность запуска программы-сканера при этом нужно организовать внутри самой BAT-процедуры.)
По кластерной терминологии такой сервер называется виртуальным, а BAT-процедура - Generic Application. Другими словами, Generic Application - это приложение, запускаемое на виртуальном сервере.
2. Сохранение на ленту всей критически важной информации. Надеюсь, что хотя бы из чувства самосохранения администраторы систем, на которых, собственно, и рассчитана данная статья, давно позаботились об организации системы резервирования данных. На момент «переезда» накопленный опыт пригодится как никогда.
А опыт у каждого свой. За несколько лет эксплуатации программного обеспечения ARCserve от Computer Associates и технического консультирования специалистов из филиалов нашей организации всякий раз приходилось решать одни и те же вопросы. Поэтому специальная статья о разработке системы резервирования будет посвящена в первую очередь таким нетривиальным ситуациям (с учетом специфики «переезда»).
3. Перенос файловой системы и мониторинг использования файл-сервера. Для «переезда» файловой службы решающее значение имеют следующие факторы:
- объем переносимых данных;
- допустимое время простоя сервера;
- способ соединения клиентов с файловым сервером.
Нам «повезло» - ни по одному из перечисленных факторов никаких послаблений не предвидилось. Объем данных - десятки гигабайт, характер работы - 24Х7, способ соединения - самый разный (сценарии с использованием букв, индивидуальное соединение с клиентской станции - и через UNC, и с использованием собственных букв).
4. Перенос очередей принт-сервера и мониторинг использования принт-сервера. При переводе принт-сервера предприятия с одного сервера на другой очень важно грамотно и оперативно организовать службу мониторинга используемых очередей.
Так или иначе, но решать перечисленные задачи, связанные с «переездом» сервера, придется почти одновременно. Я расскажу о них в том порядке, в каком они были перечислены.
Создание Generic Application для синхронизации сценариев регистрации контроллеров домена
В нижней части рисунка условно изображена та часть аппаратных ресурсов организации, которые обеспечивают работу служб файлов и печати, а также регистрации пользователей - всех тех служб, которые переводятся на более мощную группу серверов (верхняя часть рисунка). Не вникая в технические детали, скажу лишь, что по объему памяти, емкости дисковой подсистемы и производительности процессоров Кластер А в несколько раз мощнее Кластера В.
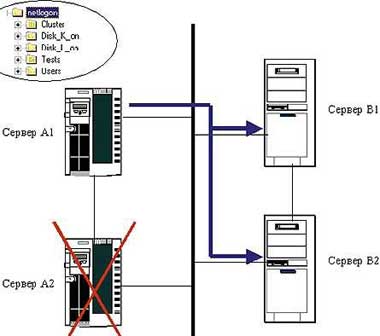
Означенные ресурсы именно перемещаются, а не перераспределяются между серверами, представленными на Рисунке 1. Это означает, что Кластер В прекращает свое существование и как кластер, и как Сервер В1 плюс Сервер В2.
До появления в структуре домена кластера производства Microsoft схема синхронизации сценариев регистрации пользователей выглядела так.
Исходное состояние. Сервер В1 и Сервер В2 являются контроллерами домена, файлы сценариев синхронизированы на всех контроллерах (на рисунке представлены не все имеющиеся в домене контроллеры, а лишь те, что участвуют в «переезде»).
Внесение изменений в каталог регистрации одного из контроллеров. Вручную запускается BAT-файл, который реплицирует изменения на все контроллеры домена.
На одном из узлов кластера Digital Cluster Server возникает ошибка. В случае сбоя ресурсы перемещаются с неисправного узла на оставшийся работоспособный.
Итак, один из узлов кластера от Digital дает сбой. Ресурс «переезжает» и запускается Post-задача, синхронизирующая файлы сценариев на всех контроллерах домена.
Общие положения технологии создания сценариев
В тот момент, когда мы осознали «встроенные» в Windows NT Server трудности работы со сценариями с точки зрения их исполнения на клиентских станциях (что было особенно заметно после работы с Novell NetWare), нам стало понятно: содержимое сценария пользователя должно быть легко «вычисляемо». Мы решили, что в имени файла сценария должны присутствовать буквы необходимых пользователю сетевых каталогов. Это было сделано следующим образом.
Все сценарии подразделялись на базовые и производные. Наиболее важным разделяемым каталогам присваивались буквы английского алфавита. Им соответствовали базовые сценарии. Чтобы отделить имена этих сценариев от всех остальных, нужен был своеобразный символ - идентификатор типа сценария. Мы выбрали символ подчеркивания. Таким образом, имя _Q.bat означало, что разделяемому каталогу присваивается буква Q. (Разделяемый каталог представлял для пользователя определенный интерес - например, в нем могли располагаться файлы базы данных расчета заработной платы.) Пример базового файла сценария _Q.bat:
net use q: s33disk_k
Производные сценарии именовались буквами сетевых каталогов, которые были нужны пользователю сети NT. Так, например, за именем производного сценария IKLS.bat скрывалось подсоединение пользователя к сетевым дискам I, K, L и S, естественно, при успешной регистрации в домене.
Выяснялось, какие сетевые диски требовались пользователю. Предположим, что нужны диски I, S, J, K, L, Q, M, P и N. Тогда из этих букв (и имен базовых сценариев) в алфавитном порядке составлялось имя производного сценария: IJKLMNPQS.bat, которое и связывалось с учетной записью пользователя.
При этом в тексте производного сценария указывалась последовательность инструкций:
set dr=%0... call %dr%_i.bat call %dr%_j.bat call %dr%_k.bat call %dr%_l.bat call %dr%_m.bat call %dr%_n.bat call %dr%_p.bat call %dr%_q.bat call %dr%_s.bat
Очевидно, что базовые файлы-сценарии должны присутствовать в каталоге регистрации пользователей домена.
Рассмотрим содержимое пользовательского (производного) сценария IKLS.bat и его выполнение на станции клиента Windows 9x; см. Таблица 1.
Ну, а теперь арифметика. Если базовых сценариев 12, сколько от них можно образовать уникальных производных, с учетом ограничений, описанных выше? Сотни! На деле все не так страшно, хотя тоже впечатляет - стоит только взглянуть на содержимое каталога регистрации одного из контроллеров домена - каталога Users (см. Листинг 1). Представлено около 450 производных файлов сценариев. Это не абстрактный пример, а реальная ситуация со сценариями в нашей организации. Но при всей видимой неразберихе ориентироваться в них на удивление легко и удобно - с одного взгляда на название сценария понятно, «кто где живет».
Технология сценариев. Кластерная реализация MSCS
На самом деле, вся история со сценариями регистрации и процедурой Generic Application возникла из-за того, что в больших организациях - с сотнями клиентов, с необходимостью согласовывать все решения, пусть даже технически грамотные, но требующие дополнительной проработки со стороны самых разных служб - не так-то просто было осуществить внедрение протокола TCP/IP. Именно из-за того, что далеко не на всех компьютерах в организации поддерживался этот протокол, невозможно было повсеместно использовать «родной» клиент для MSCS - кластерный клиент на базе протокола TCP/IP. Вот и пришлось взять на вооружение старую технологию сценариев со всеми ее недостатками.
На Рисунке 2 схематично представлено разбиение дискового пространства кластерной стойки на кластерные группы:
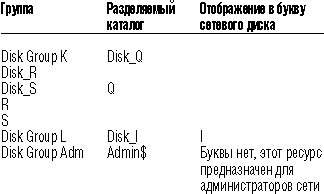 |
| Рисунок 2. |
В случае выхода из строя одного из узлов кластера MSCS синхронизация сценариев с оставшегося сервера кластера будет производиться так, как это изображено на Рисунке 3.
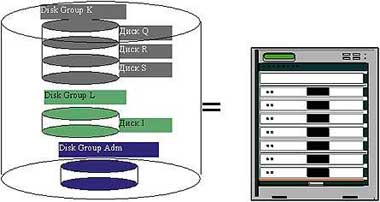 |
| Рисунок 2. Кластерные группы и отображение дисков. |
Вверху слева показан фрагмент каталога регистрации Netlogon. Та его часть, которая содержится в подкаталоге Users, включает базовые и производные сценарии. Как видно из предыдущего рассуждения, производные сценарии не меняются, на каком бы сервере в действительности ни располагался тот или иной сетевой каталог. Вопрос в том, в какой момент и как в подкаталог Users «подложить» правильно адресованные базовые сценарии?
 |
| Рисунок 3. Синхронизация сценариев в кластере MSCS при выходе из строя одного из узлов. |
Проблема эта решается следующим образом.
Для каждого узла кластера - контроллера домена - в сетевом каталоге Netlogon создается подкаталог, соответствующий имеющейся кластерной группе. Например, для данного случая это - подкаталоги Disk_K_on и Disk_L_on. В них располагаются базовые сценарии, наописанные так, как если бы кластерная группа принадлежала данному узлу. Например, если базовый скрипт _Q.bat расположен на сервере кластера S33 в подкаталоге Disk_K_on, то содержимое сценария будет выглядеть следующим образом:
net use q: s33disk_k
Если же базовый сценарий _Q.bat расположен на сервере S44 кластера в подкаталоге Disk_K_on, то содержимое сценария будет выглядеть иначе:
net use q: s44disk_k
В каталоге Cluster, собственно, и размещается процедура Generic Application. Активизировавшись в нужный момент (при аварийной остановке одного из узлов кластера, ручном перемещении кластерной группы или при потере «видимости» узла из-за повреждения сетевого соединения), она копирует с неисправного узла группу с принадлежащими ей ресурсами, после чего реплицирует содержимое своего каталога с базовыми сценариями (скажем, Disk_K_on) в каталог регистрации Users.
Вот, собственно, и все
А теперь - процедура Generic Application (см. Листинг 2).
Комментарии
1…4 Блок-заголовок процедуры. С помощью утилиты Logtime из пакета Resource Kit в файле Logtime.log регистрируется начало выполнения процедуры Generic Application.
5…10 Описание переменных среды. Имена серверов - узлов кластера - соответственно S33 и S44. Для того что процедура не была привязана к именам серверов, вводятся две переменные - Host (имя узла, на котором исполняется данная процедура Generic Application) и Reserve (другой узел кластера).
В последней строке задается арифметическая переменная - это пригодится для организации цикла локального копирования сценариев.
11…16 Цикл локального копирования сценариев. Цикл начинается с метки цикла - LOOP_LOCAL_ COPY - и заканчивается проверкой кода возврата команды копирования. Как видно из описания команд, попытка скопировать сценарии предпринимается трижды. Если все три раза она была неудачной, то кластерная процедура завершается блоком команд оповещения операторов и администраторов сети об ошибке копирования. Факт успешного завершения цикла регистрируется.
17…18 Блок удаленного копирования сценариев. Для всех контроллеров домена, помимо тех, что присутствуют в самом кластере, копирование сценариев выполняется всякий раз при возникновении сбоя.
Можно было бы поместить в тело процедуры содержимое файла sooncopy.bat, но основное тело процедуры следует изменять как можно реже. Поэтому изменяемая часть Generic Application была вынесена в отдельный файл.
Важное замечание. Если отказаться от использования Call при вызове sooncopy.bat, то результат будет на первый взгляд несколько неожиданным: процедура Generic Application окажется в состоянии Offline, и ее выполнение дойдет лишь до точки вызова программы sooncopy.bat.
На самом деле все просто. Вообще говоря, полезно время от времени вспоминать, что было написано по поводу тех или иных инструкций MS-DOS самими разработчиками Microsoft:
CALL Calls one batch program from another without causing the first batch program to stop.
CALL Вызов одной BAT-процедуры из другой BAT-процедуры без остановки вызывающей процедуры.
Если вы организуете вызов BAT-процедуры без указания инструкции CALL, то факт остановки вызывающей процедуры будет истолкован кластерной службой как исключительная ситуация (все равно, что остановка одной из автоматически стартующих служб NT, например Server service), и Generic Application перейдет в состояние Offline.
19…22 Блок оповещения администраторов и операторов об успешном завершении копирования сценариев. Помимо своего основного назначения, оповещение всех заинтересованных лиц несет еще одну, дополнительную нагрузку: само появлениe такого рода сообщения говорит администратору и оператору о том, что в кластерной системе только что произошел сбой. А это лишний повод обратить внимание на обслуживаемые серверы.
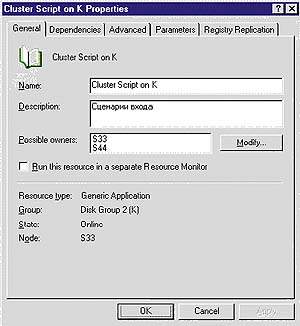 |
| Экран 1. Общее описание кластерного ресурса. Возможными владельцами процедуры Generic Application могут быть оба узла кластера. При этом предпочтительный владелец определяется на уровне группы, в состав которой входит данный кластерный ресурс. |
23…27 Копирование локальных сценариев на другой узел кластера В нормальной ситуации описываемая процедура Generic Application начинает выполняться в тот момент, когда узел кластера, которому изначально принадлежал ресурс Generic Application, по каким-то причинам выходит из строя (аварийная остановка узла-сервера, потеря сетевого соединения и др.). Предположим, это был узел В. Далее происходит следующее: группа целиком перемещается на работоспособный узел (узел А) и процедура Generic Application запускается с самого начала на этом узле. Важное замечание: как только неисправный узел - узел В - начнет «откликаться» на обращения работающего узла (узла А), версии сценариев должны быть синхронизованы на всех контроллерах домена, в том числе и на узле, только что начавшем нормальное функционирование (узел В).
Именно это реализовано в данном блоке команд: с интервалом в 15 с (утилита Sleep из пакета Resource Kit) предпринимаются попытки скопировать текущую версию сценариев с узла А на узел В. Попытки продолжаются до тех пор, пока операция копирования не будет успешно выполнена.
Интересный нюанс: если при описании группы, в которой расположен ресурс Generic Application, указано, что один из узлов (скажем, узел В) является предпочтительным собственником группы, то при восстановлении работоспособности этого узла происходит обычное перемещение всей группы с узла А на узел B. Сразу же вслед за окончанием цикла LOOP_RESERV_COPY и перемещением группы на исходный узел - узел B, процедура Generic Application вновь запускается, и сценарии опять-таки синхронизируются на всех контроллерах домена, но уже относительно версий сценариев на вновь заработавшем узле В.
28…30 Штатное завершение процедуры Generic Application. Если бы процедура не имела команды паузы (или ее аналога), то выполнение Generic Application завершилось бы нормально, и состояние ресурса Generic Application стало бы Offline. Но при этом группа, в состав которой входит описываемая процедура, в приложении Cluster Administrator будет «светить» красным фонарем, что конечно же не самое лучшее решение с точки зрения мониторинга.
Кроме того, ресурс, состояние которого Offline, при перемещении группы с узла на узел остается в состоянии Offline, что уже совсем никуда не годится: процедура Generic Application тем и хороша, что позволяет администратору кластерной системы не заботиться о выполнении рутинных операций вручную.
 |
| Экран 2. Описание зависимостей кластерного ресурса. Не стоит злоупотреблять установлением большого числа зависимостей при создании ресурса. Если обратиться к журналу регистрации кластерных событий, то можно увидеть, что в случае сбоя каждая зависимость отрабатывается отдельно. Зачем перегружать работу MSCS избыточной логикой? "Отсеките все лишнее", и останется то, без чего в самом деле бессмысленно запускать данный ресурс - Generic Application. |
По здравом размышлении вопрос с последней «боевой» командой Generic Application - pause - вроде бы логичен. Но это после того, как известен «ответ» в поставленной задаче - написать работающую процедуру Generic Application. Сам факт - неработающая процедура, необходимость ее ручного запуска - все это подталкивает к мысли о pause. Но попробуйте-ка «вычислить» эту завершающую pause заранее…
31…36 Блок оповещения об ошибке. Если цикл локального копирования LOOP_LOCAL_COPY завершен неудачно, администраторы и операторы системы оповещаются, а сам факт неудачи регистрируется в файле Logtime.log
37…38 Аварийное завершение процедуры. Как и раньше, последней командой Generic Application следует поставить pause.
Описание Sooncopy.bat 1 @echo off 2 copy %SystemRoot%system32ReplImportScripts Disk_K_on*.bat s3 etlogonusers 3 copy %SystemRoot%system32ReplImportScripts Disk_K_on*.bat s4 etlogonusers
 |
| Экран 3. Дополнительные настройки кластерного ресурса. Обратите особое внимание на флажок Affect the group. По умолчанию он установлен. Это означает, что если в процедуру Generic Application закралась ошибка, то вся группа целиком, со всеми находящимися в ней ресурсами, начнет непрерывно перебрасываться с одного узла на другой и обратно, пока не будет превышен лимит числа файловеров за установленный период времени. |
1…3 Копирование сценариев с активного узла кластера на все контроллеры домена Поскольку базовых сценариев не так много, задержки при копировании (а значит, возможное рассогласование версий файлов регистрации на различных контроллерах) очень незначительны.
После внесения изменений в пользовательский или кластерный каталог регистрации на одном из контроллеров домена (добавление, удаление или изменение пользовательского или базового сценария) для синхронизации регистрационных каталогов всех контроллеров домена можно воспользоваться следующим алгоритмом:
- процедуры Generic Application на каждом узле кластера переводятся в Offline;
- процедуры Generic Application на каждом узле кластера переводятся в Online.
|
| Экран 4. Параметрические настройки ресурса Generic Application. Собственно путь и имя процедуры задаются в параметре Command Line. Расширение CMD не должно смущать: на этом месте может быть любой исполняемый файл. Что касается текущего каталога, задаваемого в Current directory, то я бы не стал особенно на него полагаться. Возможно, он нужен для каких-то других целей, но рассчитывать на значение этого параметра как на текущий каталог исполнения процедуры почему-то не приходится. Может быть, кто-то из читателей знает ответ? Я просто в самой процедуре явно задаю текущй каталог выполнения процедуры. |
Описание Generic Application. Generic Application - один из штатных ресурсов MSCS. Его описание выполняется в приложении Cluster Administrator. На Экране 1, 2, 3 и 4 представлены некоторые особенности описания процедуры синхронизации каталогов Generic Application.
Еще раз подчеркну, что данная задача - создание процедуры Generic Application для синхронизации каталогов регистрации пользователей - становится неактуальной, если на клиентах сети установлена поддержка протокола TCP/IP. В этом случае пользователи работают с так называемыми виртуальными серверами и виртуальными сетевыми каталогами. Но это уже совсем другая история.
Сценарии готовы. Что дальше?
Пора позаботиться о защите данных. Иначе и сценарии, как и сами администраторы систем, станут не нужны.
ЛОХИН ОЛЕГ
Администратор, занимается сетями на базе Windows NT c 1994 года.
| Последовательность инструкций командного файла | Исполнение сценария на станции клиента |
| 1. set dr=%0... | C:WINDOWS>set dr=Z:usersIKLS!.bat... |
| 2. call %dr%_i.bat | C:WINDOWS>call Z:usersIKLS!.bat...\_i.bat C:WINDOWS>net use i: s44Disk_L Команда выполнена успешно. |
| 3. call %dr%_k.bat | C:WINDOWS>call Z:usersIKLS!.bat...\_k.bat C:WINDOWS>net use k: s1disk_d Команда выполнена успешно. |
| 4. call %dr%_l.bat | C:WINDOWS>call Z:usersIKLS!.bat...\_l.bat C:WINDOWS>net use L: s5sbrf-L Команда выполнена успешно. |
| 5. call %dr%_s.bat | C:WINDOWS>call Z:usersIKLS!.bat...\_s.bat C:WINDOWS>net use s: s33infobase Команда выполнена успешно. |
ПРИМЕЧАНИЯ
К позиции 1. Установка переменной Dr. Переменная %0 редко используется в командных файлах. А напрасно: конструкция %0... передает в переменную Dr путь к каталогу, из которого запущена команда IKLS.bat. Очень интересная особенность, которая наверняка покажется знакомой администраторам сети NetWare: нигде явно не указывается отображение буквы Z: в совместный каталог <Имя_сервера_регистрации>Netlogon, но происходит именно так. Благодаря такой возможности, во-первых, отпадает необходимость в явном присоединении к каталогу Netlogon одного из контроллеров домена (а это означает независимость сценария от какого-либо конкретного сервера-контроллера). Во-вторых, резко возрастает скорость исполнения самого сценария. И, наконец, нагрузка на контроллеры распределяется в соответствии с алгоритмами операционной системы и не зависит от администратора сервера. (В сети NetWare за аналогичный процесс отвечала клиентская часть NetWare, когда по умолчанию еще до момента регистрации клиента на сервере NetWare пользователю назначались буквы Z: и Y: - каталоги Login и Public, соответственно.)
К позиции 2. Далее выполняется последовательный вызов базовых сценариев. Обратите внимание на пути вызова всех BAT файлов.