

Microsoft переработала свой продукт от А до Я
 |
SQL Server 7.0 в корне меняет ситуацию. Microsoft полностью переработала свой продукт. Благодаря усовершенствованиям архитектуры новая версия сделать уверенный шаг на рынок СУБД масштаба предприятия. Многие производители систем управления предприятием с готовностью поддержали SQL Server 7.0. В данной статье я расскажу об усовершенствованиях новой версии, сосредоточившись на вопросах масштабирования.
Наперегонки с «железом»В последние годы аппаратура постоянно опережала в своем развитии программное обеспечение. Например, к концу 1999 года будут выпущены 8-процессорные системы на базе нового набора микросхем Intel Profusion. Однако главным препятствием на пути к масштабированию остается способность программных продуктов в полной мере использовать возможности аппаратных платформ. Одно из важнейших нововведений в SQL Server 7.0 — механизм динамического выделения ресурсов. |
В сочетании с NT Server, Enterprise Edition (NTS/E), СУБД SQL Server 7.0 Enterprise Edition увеличивает общий объем физической памяти, доступной серверу баз данных. NT Server 4.0, Standard Edition позволяет адресовать максимум 4 Гбайт памяти: при этом NT резервирует 2 Гбайт памяти, а приложениям, в том числе SQL Server, достаются оставшиеся 2 Гбайт. Работая же под управлением NTS/E, СУБД SQL Server 7.0 Enterprise Edition может напрямую обращаться к 3 Гбайт физической памяти. Благодаря этому SQL Server 7.0 Enterprise Edition лучше поддерживает работу с большими базами данных и обеспечивает более высокий уровень производительности.
Базы данных SQL Server 7.0 размещаются в стандартных файлах ОС, а не в «сырых» устройствах фиксированного размера, которые использовались в SQL Server 6.5. Это новое свойство позволяет расширять базы данных SQL Server 7.0 динамически, по мере того, как увеличиваются таблицы базы. В результате администратору не приходится вмешиваться в процесс и, соответственно, простоев системы не возникает. При создании базы данных администратору остается лишь указать приращение и предполагаемый максимальный размер базы. По мере заполнения базы данных SQL Server 7.0 расширяются до тех пор, пока не будет достигнута означенная граница, или не переполнится диск.
Еще одно преимущество SQL Server 7.0 состоит в том, что эта СУБД теперь поддерживает работу с очень большими базами данных (very large database — VLDB), размером до 1048516 Тбайт (сравните с ограничением в 1 Тбайт, действовавшим для версии 6.5). База данных TerraServer (http://terraserver.microsoft.com) является самой объемной (1,4 Тбайт) из доступных сверхбольших баз данных SQL Server; к тому же ею можно пользоваться через Internet. В TerraServer собраны сделанные со спутников фотографии вместе с соответствующими географическими координатами.
Еще один важный аспект, напрямую связанный с масштабированием и использованием современных аппаратных платформ, — это усовершенствованная поддержка симметричной многопроцессорной обработки (Symmetric Multiprocessing — SMP) в корпоративной редакции SQL Server 7.0 Enterprise Edition. Версия 6.5 имеет определенные ограничения в отношении работы на многопроцессорных системах и, в частности, не используется на серверах с числом процессоров более четырех. Значительно переработанное ядро SQL Server 7.0 Enterprise Edition позволяет в полной мере задействовать все возможности четырехпроцессорных систем и, более того, может работать на новых серверах с 8 процессорами. Встроенный механизм распараллеливания запросов позволяет ядру SQL Server 7.0 распределять составляющие запроса по всем имеющимся процессорам.
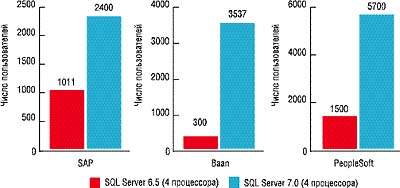 |
| РИСУНОК 1. Тестирование производительности симметричной многопроцессорной обработки для систем управления предприятием. (Графики представляют результаты тестов, выполненных производителями ПО; их результаты нельзя сопоставить из-за различий в методиках те |
Проведенное Microsoft тестирование SQL Server 7.0 Enterprise Edition с применением процедур измерения производительности нескольких ERP-систем показало значительный прирост производительности по сравнению с предыдущей версией при работе на 4-процессорных системах. Результаты представлены на Рисунке 1. Несомненно, новая архитектура проявит себя и на системах с большим числом процессоров; на новых 8-процессорных серверах показатели, приведенные на Рисунке 1, наверняка будут многократно перекрыты.
Масштабируемая архитектура
Помимо усовершенствованной поддержки новейшего оборудования, в SQL Server 7.0 появились и другие архитектурные нововведения, направленные на достижение максимальной масштабируемости. Переработке подверглись практически все базовые компоненты ядра SQL Server 7.0. Самые значительные изменения затронули размер страницы и подсистемы ввода-вывода. Размер страницы по умолчанию в SQL Server 7.0 увеличен с 2 до 8 Кбайт, а размер экстентов — с 16 до 64 Кбайт. Емкость буфера при вводе-выводе также выросла до 64 Кбайт, что позволяет обрабатывать больше данных за одну операцию ввода-вывода и, соответственно, повысить производительность системы.
Процессор запросов SQL Server 7.0 также подвергся фундаментальной переработке, и теперь он может лучше оперировать сложными запросами, свойственными системам управления предприятием и системам поддержки принятия решений. Чтобы более эффективно справляться с неструктурированными запросами, процессор запросов SQL Server 7.0 выполняет операции опережающего чтения и параллельного ввода-вывода для ускорения просмотра таблиц.
В новом процессоре запросов SQL Server 7.0 реализовано несколько высокопроизводительных алгоритмов обработки запросов для поддержки больших баз данных и повышения производительности при выполнении сложных запросов при работе таких приложений, как, например, информационные хранилища. Можно назвать такие новые алгоритмы, как пересечение индексов, поглощающее слияние и хеш-слияние. Первый из них позволяет при выполнении запроса использовать значения сразу нескольких индексов и тем самым сократить число операций ввода-вывода — если информация, необходимая для выполнения запроса, уже содержится в индексах, то к таблице с данными обращаться не нужно. Поглощающее слияние позволяет применять несколько индексов для ускорения выполнения сложных запросов. Хеш-слияние применяется, когда ни один из индексов не содержит запрошенных данных. Сначала процессор запросов выполняет частичное сканирование данных (хеширование) и группирует их по подмножествам. Теперь прежде чем выполнять выборку из основной таблицы, процессор просматривает хешированные подмножества, что требует гораздо меньше времени. Цель новых методов — сократить число операций ввода-вывода, которые в СУБД выполняются медленнее всех остальных.
Для выбора оптимального метода выполнения запроса SQL Server вычисляет его стоимость. Стоимость запроса зависит от его типа, наличия индексов, оценки затрат процессорного времени на выполнение запроса и числа операций ввода-вывода. Для вычисления стоимости запросов применяется и статистика, которую собирает SQL Server.
Кластеры — чем больше, тем лучше
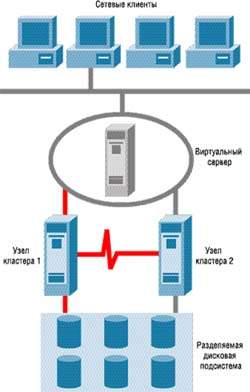 |
| РИСУНОК 2. Схема организации кластера на базе SQL Server 7.0 Enterprise Edition и MSCS. |
SQL Server 7.0 Enterprise Edition и кластер MSCS можно установить в двух вариантах: с одним или с двумя постоянно активными узлами. В первом случае постоянно активен только один из узлов кластера, а второй находится в резерве. Если первый сервер выходит из строя, вся обработка переносится на SQL Server второго узла. Когда резервный сервер становится активным, установленный на нем SQL Server выполняет обычную процедуру восстановления после сбоя, отменяя все незавершенные транзакции и тем самым обеспечивая целостность данных.
Во втором варианте оба узла активны одновременно, однако они не дополняют друг друга, то есть пользователь имеет дело с двумя отдельными серверами SQL Server 7.0. Обе системы доступны одновременно, и приложения можно запускать на обоих узлах кластера, работающего в этом режиме. Если один из серверов такого кластера выходит из строя, оставшийся узел принимает на себя обязанности первого. Как и для кластера с одним активным сервером, после отказа одного из узлов SQL Server на втором выполняется процедура восстановления состояния с отменой всех незавершенных транзакций.
Резервное копирование
Поначалу кажется, что масштабирование не имеет прямого отношения к резервному копированию и восстановлению, однако возможность по мере роста базы данных создавать ее резервные копии становится критически важной. Создание резервной копии базы данных масштаба предприятия — задача не из легких. Например, для базы данных терабайтного размера резервное копирование по расписанию попросту не имеет смысла. Кроме того, проблему усложняет и широко распространенное требование доступности базы данных в течение 99,9% времени.
Масштабирование операций восстановления и резервного копирования в SQL Server 7.0 реализуется двумя способами. Во-первых, метод параллельного создания копий позволяет ускорить процесс копирования и восстановления данных при увеличении скорости работы устройства резервного копирования. При параллельном копировании данные пишутся на несколько таких устройств одновременно, что позволяет увеличить скорость операции копирования/восстановления пропорционально количеству устройств, подключенных к серверу. Например, если для резервного копирования используется один ленточный накопитель и время его работы составляет 2 часа, то добавление второго сократит это время почти вдвое. Для баз данных масштаба предприятия поддержка параллельного резервного копирования экономит время при создании копий.
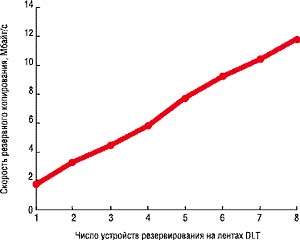 |
| РИСУНОК 3. Зависимость скорости резервного копирования SQL Server 7.0 от числа устройств. |
В основе Рисунка 3 лежат результаты тестирования, проведенного Microsoft, Legato Systems и Compaq. Тесты выполнялись для базы данных размером 263 Гбайт на 8-процессорном сервере Compaq AlphaServer оперативной памятью объемом с 8 Гбайт, 2,2 Тбайт дискового пространства и 32 ленточными накопителями Compaq AIT. Как показывает Рисунок 3, скорость копирования растет пропорционально количеству ленточных накопителей.
Кроме того, SQL Server 7.0 может создавать резервные копии в оперативном режиме, т.е. в процессе обычной работы. Такой режим — обязательный атрибут систем, где необходима доступность базы данных в режиме 24х7 — 24 часа в сутки 7 дней в неделю. В ходе тестирования оценивалась и производительность создания резервных копий в оперативном режиме при средней, большой и очень большой нагрузке на систему. В первом случае до начала выполнения операции резервного копирования имитировалась средняя нагрузка в 170 транзакций в секунду (transaction per second — tps). После начала резервного копирования в оперативном режиме производительность сервера упала до 133 tps, то есть SQL Server обеспечивал производительность на уровне 78% от производительности без резервного копирования. Второй тест проводился при большей нагрузке — 197 tps. После начала копирования сервер смог обеспечить лишь 150 tps или 76% производительности без резервного копирования. При очень большой нагрузке в 278 tps запуск резервного копирования в оперативном режиме снизил эту цифру до 188 tps (68%). Подробнее c результатами этих тестов можно ознакомиться по адресу http://www.microsoft.com/sql/productinfo/backup.htm.
Хранилища данных и системы поддержки принятия решения
Хранилища данных предъявляют очень высокие требования к системам хранения и, кроме того, к производительности выполнения аналитических запросов. Для поддержки хранилищ данных и систем принятия решений служат OLAP-службы SQL Server 7.0. При выполнении запроса в обычной реляционной базе данных просматриваются все соответствующие записи. Для хранилищ данных этот подход не годится, и поэтому службы OLAP используют кубы и агрегирование данных. Куб — это набор измерений и мер, обеспечивающих навигацию по многомерным данным. В большинстве случаев данные, хранящиеся в ячейке куба, являются агрегированными, т. е. представляют собой сводку данных из множества строк и столбцов. OLAP-приложения используют агрегирование данных для обеспечения высокой скорости обработки запросов.
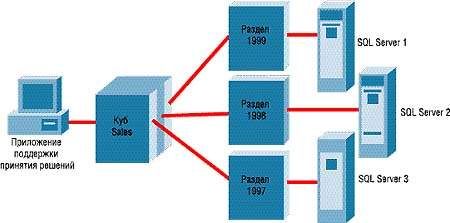 |
| РИСУНОК 4. OLAP-разделы, реализованные на нескольких источниках данных. |
Куб реализует логическую структуру данных, размещенных в хранилище, однако сами данные хранятся в разделах. Каждый куб должен иметь хотя бы один раздел. В SQL Server 7.0 Enterprise Edition можно создавать дополнительные разделы, позволяющие распределять куб между несколькими источникам данных на разных серверах. Этот подход значительно улучшает масштабируемость, поскольку в результате OLAP-служба могут работать на кластере. На Рисунке 4 показано, как можно распределить разделы по нескольким источникам данных. Для системы поддержки принятия решений такой куб OLAP представляет собой единое целое, но на самом деле он размещен в трех разделах.
Высота 2000
В Microsoft надеются, что усовершенствования поднимут SQL Server еще выше по лестнице систем масштаба предприятия. Windows 2000 и SQL Server 7.5 расширят способность SQL Server поддерживать сверхбольшие базы данных. На платформе Win2K Advanced Server, SQL Server 7.5 сможет адресовать до 8 Гбайт оперативной памяти. Windows 2000 Datacenter Server (Datacenter) поднимает планку еще выше: он позволяет SQL Server 7.5 задействовать ни много ни мало 64 Гбайт памяти посредством механизма расширения физической адресации (Physical Address Extension — PAE). Усовершенствованная поддержка аппаратных платформ позволяет Datacenter работать на 16-процессорных SMP-системах; специализированные версии будут поддерживать и 32-процессорные системы. Кроме того, Datacenter дает возможность создавать отказоустойчивые кластеры на базе 4 серверов. К числу новых функций SQL Server 7.5 относятся: поддержка Active Directory Service, расширенный параллелизм, поддержка каскадной ссылочной целостности, дополнительные средства кластеризации и хранение представлений.
Приступая к модернизации SQL Server 7.0 разработчики Microsoft рассчитывали тем самым вывести СУБД на орбиту систем уровня предприятия. И хотя SQL Server 7.0 еще не может в полной мере заменить системы класса мэйнфрейма, новая версия СУБД отвечает требованиям современного бизнеса как минимум на 98%.