Начнем с наивного вопроса: что есть персональный компьютер?
Нет, речь идет не о точно выверенном энциклопедическом определении: «ПК — это...», а о том, является ли он сложным техническим устройством, работа с которым требует если не обряда посвящения, то, как минимум, «корочек» наподобие водительских. Или это обычный бытовой прибор (типа телевизора), для пользования которым достаточно (заметьте, достаточно, а не требуется!) один раз прочитать инструкцию?
Сей непритязательный вопрос оказался не таким уж простым. Свидетельство тому — многочисленные дискуссии, не затихающие на рунетовском пространстве (отслеживать иноязычные форумы нам, право же, лень). Одни из их участников аргументированно доказывают, что, не ведая о таких понятиях, как файл, файловая система, каталог (папка) или командная строка, вы можете идти выпить «йаду». Другие не менее аргументированно вопрошают: «А зачем козе баян?»
Самое смешное, что правы и те, и эти. Все зависит от того, под каким углом зрения это рассматривать. В общем, как с тем самым стаканом, который для одних полупуст, для других — наполовину полон... Особо дотошные не хотят усредненных решений и потому все настраивают своими руками. В результате программы на компьютерах начинают просто летать на зависть окружающим, имеющим в ПК и процессор помощнее, и «оперативки» побольше, вот только работают их машины с настройками от производителя. Для прочих же ПК лишь инструмент, помогающий выполнять основную задачу, будь то работа или развлечение. Так, журналисту требуется «умная пишмашинка», на которой можно не просто комфортно набивать текст, но и проверять его на соответствие правилам русского языка. Бухгалтеру нужен «продвинутый калькулятор», позволяющий рассчитать баланс и оформить его в виде, приемлемом для вышестоящей инстанции. А кто-то хочет просто сунуть диск в накопитель и получать удовольствие от имеющегося на нем контента. Для него компьютер, требующий изучения либо настройки, считай неисправный.
В общем, определенной категории пользователей (назовем их администраторами) абсолютно необходимо знакомство с внутренним устройством системы, а остальным (потребителям) требуется лишь возможность выполнять свою работу наиболее удобным способом. Впрочем, неразумно отнимать у администраторов право на высокоуровневые инструменты и еще неразумней запирать потребителя в тесных рамках дружественного интерфейса, ведь расширение компьютерного кругозора — лучший путь повышения эффективности труда любого пользователя.
Однако если просвещение не входит в планы пользователя, а потребность в ПК таки присутствует, обязательно ли получать немалый объем лишних знаний? Развитие технологий индексации, организации и контекстного поиска документов различных видов позволяет возвести над внутренностями системы высокоуровневую объектную надстройку. Такой подход делает диалог с машиной более естественным и существенно повышает продуктивность труда, а в минуты досуга направляет развлечения в русло, далекое от заветов Захера Мазоха.
Файлы и их содержимое
Файлы — зло! Не спешите хвататься за пистолет. Всегда успеете. Пока же ответьте на вопрос: с чем работает пользователь-потребитель — с файлами или с их содержимым?
Согласитесь, куда естественнее воспринимается фраза «Реквием» Моцарта в исполнении бобруйского симфонического оркестра», чем запись c:Мои документыМоя музыкаМоцартИсполнителиБобруйский симфонический equiem. mp3. А теперь представьте, что хотите послушать все, что исполняет этот оркестр. Если бы речь шла о всех наличествующих у вас творениях Моцарта, то нет ничего проще: достаточно воспроизвести содержимое папки c:Мои документыМоя музыкаМоцарт. Но ведь бобруйский симфонический исполняет не только Моцарта, может быть, он еще и Мендельсона на свадьбах играет, тогда как? В том-то все и дело, что приведенная для примера коллекция отсортирована лишь по единственному признаку — по автору. И дабы отбор не осуществлять вручную, требуется, чтобы искомые файлы и папки присутствовали во всевозможных сочетаниях (файлы с Моцартом в папках с «бобруйским симфоническим», Мендельсон в папке со «свадьбой» и он же в папке с «бобруйским симфоническим»).
А если критериев отбора несколько и, не дай бог, один из них с исключением: скажем, все записи, кроме Моцарта, в исполнении упомянутого оркестра? В этом случае мы получаем работу вручную в несколько этапов: сначала «набросать» в плей-лист необходимые композиции, а затем удалить ненужные.
О музыке мы заговорили лишь для того, чтобы приступить к рассмотрению проблемы, поскольку критериев отбора у музыкальных композиций традиционно меньше, чем у фотографий или текстовых документов. Представьте себе, например, снимки с выпускного вечера. Под какие критерии они могут попасть при сортировке и поиске? Навскидку: события (выпускной), групповые портреты, дата, личное и каждый присутствующий выпускник как отдельный критерий со всеми вытекающими условиями. В случае с иерархической системой максимум, что мы получим при отборе, — дата создания файла и одна-единственная категория. Этого явно недостаточно, если вы хотите разом отобрать все фотографии Маши Ивановой, Вани Петрова и себя, любимого. О текстовых документах пока вообще помолчим, ибо здесь критерием может выступать каждое входящее в них слово.
Впрочем, нам могут возразить, что столкнуться с проблемой эффективного поиска рискует лишь пользователь со стажем, обладатель обширной библиотеки разнообразных данных. Но разве новичку, имеющему два десятка MP3-шек, гневное письмо в техподдержку и набор картинок для Рабочего стола, предложенный поставщиком ОС, в рамках иерархической файловой системы вполне вольготно? Как бы не так! Чтобы относительно свободно манипулировать собственными документами на ПК, он должен разобраться с основами файловой системы. В противном случае неизбежны ярлыки, скопированные на сменные носители вместо самих файлов, надежно потерянные в дебрях файловой системы (ФС) документы и хранение всех новых данных прямо на Рабочем столе, дабы не лишиться ненароком. А ведь современные технологии позволяют подобных неприятностей избежать. Оказавшись в умелых руках профессионала, такие средства способны расширить привычный функционал и открыть массу новых возможностей.
Для примера рассмотрим музыкальные композиции, графику, веб-страницы, письма и рабочие материалы. Общим для них является то, что все это в достатке водится на обычном ПК, невелико по размерам и активно переносится посредством внешних устройств и электронной почты. Можно ли работать с такими данными, особо не задумываясь о сущности файла и его точном расположении, и насколько это удобно?
Свойства и критерии
Необходимое условие для эффективных сортировки и поиска — возможность присвоения каждому документу произвольного количества атрибутов. В случае с песней, например, такими атрибутами могут быть исполнитель, альбом, год, жанр, а в случае текстового материала — автор, тема, ключевые слова, заметки. Во всех случаях, разумеется, в число атрибутов входит и тип файла: музыкальный, видеоролик, графика или что угодно еще. Такие атрибуты называются метаданными, а их наличие служит основным отличием документа определенного вида от «просто файла». Метаданные хранятся непосредственно в искомом файле и стандартизированы для файлов именно такого типа. Следовательно, любая программа способна извлечь сведения о файле, даже если их внесла какая-то другая.
Самый распространенный пример метаданных — теги MP3-файлов, способные хранить все перечисленные выше атрибуты музыкальной композиции. На примере музыкальных файлов мы и рассмотрим кардинальное различие между «файловым» подходом и современными средствами более высокого уровня.
iTunes, amaroK и другие
Как обычно составляется плей-лист в проигрывателях с отсутствующей или неудобной библиотекой? Либо добавляются файлы прямо из соответствующего менеджера вроде Проводника Windows, либо точно так же вносятся средствами самой программы. Следовательно, возможность выбора представлена лишь упорядочением/фильтрацией по имени файла и дате его создания, его местоположением и хорошей памятью владельца файла.
Насколько ограничен такой подход при сортировке, мы разъяснили выше. Однако даже элементарный выбор нужной композиции может быть весьма затруднителен тогда, когда пользователь не помнит, какая песня скрыта под личиной track012345678. mp3, а файловый менеджер об этом и вовсе представления не имеет.
На таком фоне возможности полноценной музыкальной библиотеки воспринимаются просто как дар Божий. Программы, названия которых мы вынесли в заголовок, а также Novell banshee, Windows media player 10 и прочие способны превратить будни меломана в праздники.
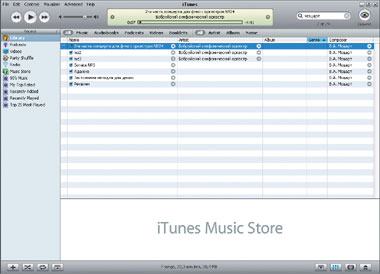
Судите сами. Проигрыватель автоматически отыскивает все музыкальные файлы на жестком диске и позволяет сортировать их по любым атрибутам из метаданных и ряду своих, в частности по личному пользовательскому рейтингу. Большинство таких программ группируют музыку без тегов в отдельной категории «неопознанных», что позволяет быстро восполнить пробелы вручную либо посредством различной автоматики. Пользователь получает всю наличествующую музыку, сгруппированную в одной базе, и богатейшие возможности выбора. На рис. 1 показано, как iTunes находит все произведения Моцарта по первым введенным буквам. Выступления же «бобруйского симфонического» отмечены в отдельной колонке.
|
| Рис. 1. Строка быстрого поиска и сортировка композиций в iTunes |
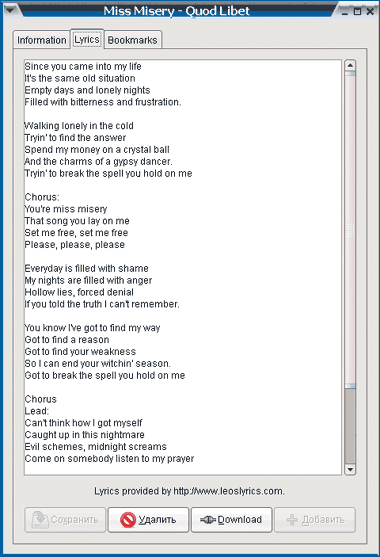
Вполне естественно, что при таком подходе, в отличие от «файлового», обложка альбома или текст требуемой песни будут просто одним из доступных свойств нужного объекта (рис. 2). Так же легко добавляются и новые композиции в ПК.
|
| Рис. 2. Операции с текстом песни в Quod Libet |
Все перечисленные выше плееры способны захватывать дорожки с CD, автоматически заполнять теги с помощью интернет-базы и добавлять информацию в библиотеку, а banshee (для Linux) и iTunes (для Windows и Mac OS) — еще и приобретать композиции в iTunes Music Store компании Apple. Как видите, никакого общения с файлами при выполнении этих действий у пользователя не происходит, а работа с большой медиатекой становится несравненно удобней. Разумеется, и перенос музыки обратно на CD, iPod либо другой плеер происходит подобным же образом — никаких файлов, только понятные и удобные в обращении музыкальные композиции со всеми их атрибутами.
Пользователь со стажем также найдет массу применений своим навыкам и существенно облегчит себе жизнь. Ваша медиатека насчитывает несколько тысяч композиций? Тогда мы идем к вам!
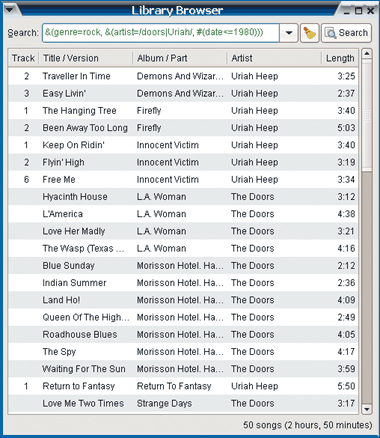
Прекрасным примером здесь будет новационный медиаплеер Quod Libet для ОС Linux. Рассчитанная на работу с очень большими коллекциями, программа позволяет сортировать композиции по всем атрибутам разом, причем с применением регулярных выражений и прямого обращения к тегам. Например, можно задать шаблон названия песни, жанр и диапазон дат в одной поисковой строке (рис. 3). Это придется по душе тем, кто любит UNIX Shell, программы SED и язык Perl (как и один из авторов этой статьи).
|
| Рис. 3. Использование в строке поиска регулярных выражений и прямого обращения к тегам в Quod Libet |
Более сложные задачи и самые наглядные примеры последуют дальше.
Графика
Итак, критериев для сортировки фотографий и прочих изображений существенно больше, чем для музыкальных композиций. Действительно, помимо общих категорий вроде «Мероприятия» или «Семья» может быть и несколько подгрупп, например «Презентация» или «Первые шаги Васи». Вариантов настолько много, что подогнать их под определенные рамки просто невозможно. Именно поэтому метаданные графических файлов (EXIF, XMP) содержат массу произвольной информации, начиная с модели фотокамеры и заканчивая автором, тематикой или комментариями.
Следовательно, и от программы-органайзера требуется больше, чем от медиаплеера. В первую очередь нужны сортировка по любым существующим критериям, создание новых критериев (групп) и пользовательских комментариев, запись всей информации в графические файлы. Кроме того, совершенно необходима функция импорта изображений с внешних устройств (например, с цифровой камеры или iPod photo) и передачи данных по электронной почте.

|
| Рис. 4. Библиотека изображений в программе F-Spot |
При наличии подобных средств пользователь может на всех этапах — от импорта с камеры до отправки по почте или печати, свободно манипулировать объектами, а не файлами. Рассмотрим такой подход на примере программы F-Spot компании Novell. На рис. 4 представлены эскизы изображений в библиотеке и список категорий (групп), по которым можно проводить сортировку. Допустим, мы добавим несколько фотографий с диска «Санкт-Петербург и пригороды. Фотоколлекция» компании «Новый Диск». В группе «Места» создадим подгруппу «Питер» и отнесем к ней все новые фотографии. Точно так же в категории «Авторы» организуем подгруппу «К. Ренжин» (разработчик диска) и пристроим туда новые снимки. Теперь снабдим отдельные изображения комментариями, скажем «Закат на реке Неве», и полюбуемся результатом.
Классификация фотографий по месту (Питер) и автору (Ренжин) позволяет легко выбирать нужные снимки буквально одним щелчком, например все питерские фотографии и/или работы К. Ренжина (рис. 5). Количество критериев, разумеется, может быть и большим, а комментарии могут носить не только пояснительный характер.

|
| Рис. 5. Сортировка изображений в программе F-Spot |
Отметим, что возможность отнести каждое изображение к нескольким категориям вкупе с хронологической шкалой (timeline) и функцией сортировки по дате позволяет сузить круг поиска хоть до одной картинки из десятка тысяч в считанные секунды. Даже самая кропотливая организация сложной структуры папок на диске не способна на такое!
Фотоорганайзеров для различных ОС существует достаточно много. В среде Linux помимо рассмотренного F-Spot достаточно широко распространено KDE-приложение Digikam. Рассчитанный на новичков органайзер Picasa компании Google существует как для Windows, так и для Linux. Во врезке приведены ссылки на наиболее популярные программы подобного профиля.
Сеть
Проблема сохранения интернет-страниц решается множеством путей. Кто-то желает сэкономить и запускает офлайновый браузер во время действия льготного тарифа. Кому-то просто нужно скопировать заинтересовавшие страницы на жесткий диск для последующего автономного просмотра. Однако самое элегантное решение поджидает пользователя в браузере Firefox и его расширении ScrapBook (веб-альбом). Подробное описание ScrapBook см. в «Мире ПК», №8/05, с. 64, а здесь мы ограничимся лишь теми возможностями, которые напрямую связаны с темой статьи.
Для начала вспомним, какие муки способно принести массовое сохранение веб-страниц по старинке. Во-первых, крайне часто совпадают имена файлов (классика жанра — index.html). Во-вторых, страницы, как правило, состоят из множества файлов, копирующихся в отдельную папку и быстро превращающих диск в помойку. Ну а сохранение страниц в формате веб-архива (*.mht) несет в себе все те же прелести, что и организация любой объемной подборки из документов, если невозможна многогранная классификация.
В противовес всему перечисленному ScrapBook предлагает виртуальную файловую систему прямо в браузере, где название каждого «файла» соответствует заголовку сохраненной страницы. Все без исключения тексты перекодируются в универсальную кодировку UTF8, что помогает избежать еще и «зоопарка» из вариантов кириллицы. Структура ФС ScrapBook, естественно, иерархическая, древовидная. Однако в ней присутствуют «файлы» лишь одного вида, и потому заблудиться весьма трудно. Но когда количество записей в базе перевалит за несколько сотен, то неминуемо встанет вопрос сортировки и поиска. И здесь пришло самое время поговорить об инструментах, объединяющих приведенные подборки документов и предоставляющих возможности поиска во всех коллекциях одновременно, а также и многие другие.
Настольные поисковые системы
Нетрудно заметить, что все перечисленные программы позволяют работать лишь с одним видом данных, скажем с музыкой или изображениями. Когда речь идет просто о просмотре/прослушивании домашней коллекции, то такой подход более чем достаточен, однако в работе нередко требуются документы самых разных типов, причем одновременно и без задержек на поиск. И здесь на помощь приходят средства универсального поиска.
Цель всех таких программ — предоставить пользователю перечень документов, соответствующих введенному критерию. Точно так же работает любая система онлайнового поиска, будь то «Яндекс» или Google. Неслучайно одна из самых популярных поисковых систем для локальных нужд выпущена последней компанией. Рассмотрим принцип ее работы.
Первым и главным источником информации о документах являются все те же метаданные. Например, наши питерские фотографии получили метку «Питер» в органайзере F-Spot. Как помним, метаданные, записанные одной программой, обязаны читаться в любой другой. Поэтому поисковая система beagle компании Novell по запросу «Питер» выводит в числе прочих и эти фотографии (рис. 6). Здесь самое время вспомнить наш комментарий «Закат на реке Неве». В нашем случае других документов, соответствующих данному критерию, в компьютере не обнаружилось. В результате beagle выдала лишь один вариант — верный!

|
| Рис. 6. Beagle: поиск документов по метаданным |
Вторым и наиболее эффектным механизмом является индексация текстовых документов по содержанию. Системы, подобные Google Desktop Search или той же beagle, скрупулезно изучают каждый документ на жестком диске и составляют объемный индекс полнотекстового поиска. Благодаря ему запросы обрабатываются практически мгновенно. Новые же документы добавляются в индекс по мере возникновения или при модификации точно так же, как и в случае с поиском по метаданным.
Какие же возможности предоставляет система настольного поиска? Предлагаем несколько типовых ситуаций.
Случай первый и самый простой — большой массив текстов
Как мы заметили в описании ScrapBook, при увеличении базы сохраненных страниц до некоего критического объема иерархическая система неминуемо покажет себя во всей красе. И тогда пользователю останется либо снова городить огород из вложенных подпапок, либо воспользоваться полнотекстовым поиском. Последний, кстати, присутствует и в ScrapBook, но не обладает должной скоростью, функциональностью и, главное, не работает глобально в рамках всех данных ПК. Использование же программ, подобных beagle, позволяет по единственному запросу получить список таких документов, в метаданных или тексте которых встречаются искомые слова.
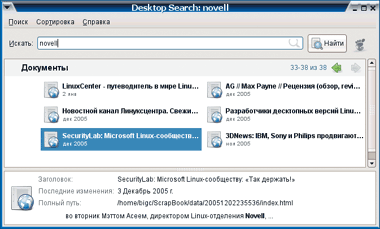
Проиндексированная база ScrapBook в значительной степени напоминает эдакий автономный «мини-интернет», где моментально находится информация, сохраненная бог весть когда и находящаяся на самой неожиданной странице (рис. 7).
|
| Рис. 7. Beagle: полнотекстовый поиск |
Поисковая система также окажется отличным помощником программиста или веб-дизайнера. Достаточно включить в исходный текст комментарии с ключевыми словами, и эффективный поиск займет считанные секунды, даже если вы напрочь позабыли, где находится ваш файл двухлетней давности.
Случай второй и самый распространенный — поиск документов разных типов в контексте запроса
Вернемся к городу на Неве. Допустим, ваша нынешняя работа каким-то образом связана с С.-Петербургом. У вас присутствуют сохраненные веб-страницы по теме, некоторое количество документов в форматах .doc, .odt и просто .txt, специально отобранные фотографии, снимки позапрошлогоднего отпуска в этом городе, переписка с работодателем и собственные текстовые наработки. Что же объединяет эти данные? Явно не имена файлов, так как получены они в разное время из различных источников. Может быть, общая папка? Также нерационально, ведь эти документы изначально относятся к разным категориям и неизбежно дублирование.
Зато и в тексте, и в метаданных встречаются одинаковые ключевые слова, и поиск по этим словам неминуемо выведет нужные ссылки в одном окне поисковой системы!
Случай третий и самый наглядный — поиск по множеству критериев разом
Допустим, у вас в подчинении находятся четыре сотрудника: Иванов, Петров, Сидоров и Рабинович. Если бы все они просто занимались отдельными проектами, то разнести их работы по папкам иерархической ФС не составило бы чрезмерного труда. Однако в вашем случае все куда запутанней. Иванов и Рабинович работают над совместным проектом. Аналогичный проект у Иванова с Сидоровым. Петров же работает в одиночку, однако базируется на работах Рабиновича и Сидорова. Документы сотрудников, будучи рассортированы в «классическом» стиле по принципу «если имеет отношение, должно находиться в соответствующей папке», образуют воистину жуткий клубок продублированных файлов.
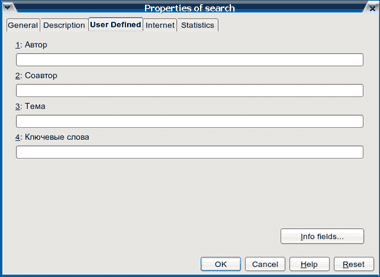
|
| Рис. 8. Теги офисных документов |
Казалось бы, ничто не спасет от путаницы, кроме разума и памяти руководителя. Однако для последних есть отличные помощники в виде тегов офисных документов .doc, .odt, .ods и прочих «офисных» форматов. В нашем случае достаточно будет указать автора, соавтора и название проекта. Проблему же цитируемых работ решит полнотекстовый поиск. На рис. 8 представлены варианты заполнения метаданных, а на рис. 9 — результаты поиска с логическими операторами и/или/нет. Как видите, все документы можно хранить хоть в одном каталоге, а сортировку без труда выполнит система поиска. Например, запрос «Сидоров и Рабинович» выведет как раз результаты работы данных сотрудников, а заодно и ссылающиеся на них труды господина Петрова.
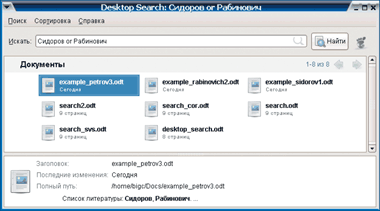
|
| Рис. 9. Beagle: поиск с применением логических операторов |
Еще неразумная, но уже сила
Разумеется, для полноценного функционирования системы настольного поиска требуются «костыли» в виде метаданных. И расставлять их приходится человеку. Пока искусственный интеллект не научится оперировать содержанием документа самостоятельно, такой подход неизбежен. Однако уже сейчас подобные программы выводят пользовательский интерфейс на принципиально новый уровень.
Документы, фотографии, музыка, переписка — все, что способно иметь смысловую нагрузку, группируется в едином контекстном пространстве. Порог вхождения для новичков существенно снижается, а профессионалы обретают массу новых возможностей.
В настоящее время подобные решения работают «из коробки» в Novell SUSE Linux 10 и Mac OS X, очень многое ожидается и в новой Windows Vista. Пользователям же прочих дистрибутивов Linux, версий Windows 2000/XP и других современных ОС мы рекомендуем с помощью приведенных во врезке ссылок обустроить свое рабочее пространство самостоятельно.
Ссылки
http://desktop.google.com/ru/?pr=mp-gd-ru-v3-1
Google Desktop для Windows
http://picasa.google.com
http://picasa.google.com/linux
Google Picasa для Windows и Linux
http://www.apple.com/itunes/download
Apple iTunes для Windows и Mac OS
http://banshee-project.org
Banshee
http://beagle-project.org
Beagle
http://f-spot-project.org
F-Spot