
изменения должны выполняться в соответствии с определенными требованиями, которые я сам перед собой поставил (они перечислены ниже).
Предполагается, что исходный текстовый файл обладает следующими свойствами:
- текст состоит из абзацев, начинающихся с абзацного отступа;
- не используются специальные типографские символы (т.е. вместо тире — дефис, вместо типографских кавычек — обычные).
К преобразованию текста предъявляются следующие требования:
- абзацы исходного текста должны быть заключены в теги
,
, причем если перед абзацем пустая строка, то он должен начинаться не просто с, а с
(в моей таблице стилей по умолчанию не предусмотрены отступы сверху и снизу от абзацев, а описанный в ней же стиль «up» как раз и обеспечивает отступ сверху от того абзаца, к которому применен);
- в получаемом HTML-тексте абзацы должны быть разделены пустыми строками — при редактировании сразу будет видно деление на абзацы, а на его вид в браузере эти строки не повлияют;
- встречающиеся в тексте http- и ftp-адреса должны быть оформлены как гиперссылки.
Также текст должен быть приведен в соответствие с основными нормами русской типографики¹; [4, 7]:
- используемые в тексте обычные кавычки должны быть заменены на «елочки» (««», «»»);
- вместо многоточия из трех отдельных символов-точек должен быть подставлен символ многоточия «…»;
- значок «©» должен быть заменен на «©», а «®» — на «®»;
- дефисы, используемые вместо тире, должны быть заменены на тире и привязаны неразрывным пробелом к предыдущему или следующему слову в зависимости от ситуации;
- сокращенное наименование единицы измерения, стоящее после числа, должно быть привязано к числу неразрывным пробелом;
- последовательности букв и/или цифр, содержащие дефис, должны быть заключены в теги
, , чтобы предотвратить перенос в месте дефиса.
Довольно долго я решал эту задачу вручную, но потом решил автоматизировать данный процесс. О программах, преобразующих текст в соответствии с такими требованиями, я не слышал. Единственное — в «Студии Лебедева» создан онлайновый сервис «Типограф» (http://www.artlebedev.ru/tools/typograf). Там предлагается ввести HTML-текст в форму, и он будет приведен в соответствие с нормами типографики. Но это средство решает лишь часть моей проблемы, к тому же мне была нужна автономная программа.
Итак, надо было действовать самому. Какое же средство выбрать для достижения подобной цели? Процесс преобразования текста может быть разбит на отдельные операции поиска-замены с использованием регулярных выражений. А для выполнения таких операций хорошо подходит программа для обработки текста, так называемый текстовый фильтр sed (Stream EDitor). Ее разработал в 1973 или 1974 г. Ли Макмагон; впоследствии различные авторы создали множество версий sed для разных компьютерных платформ [1].
Я выбрал современную свободно распространяемую версию ssed 3.62 (super-sed) и переписал исполняемый файл этой программы для Windows, а также исходные тексты вместе с документацией со страницы http://sed.sourceforge.net/grabbag/ssed.
Кратко работу sed можно представить так. Данное приложение получает строки текста со стандартного ввода (или из файла), обрабатывает их в соответствии с указанной пользователем программой (иначе называемой скриптом или сценарием), представляющей собой последовательность команд sed, и выдает результат на стандартный вывод (он может быть перенаправлен в файл). Более подробные сведения о работе sed приведены в [1], а конкретно о ssed — в [2].
Синтаксис команды sed, осуществляющей поиск-замену с использованием регулярных выражений, таков: s/<регулярное выражение для поиска>/<выражение для замены>/<опции>. (Если вы программируете на Perl, это должно быть вам знакомо.)
Например, команда, заменяющая каждую последовательность пробелов и/или табуляций на один пробел, будет выглядеть так:
s/[ ]+/ /g
Здесь регулярное выражение для поиска «[ ]+» соответствует последовательности пробелов и табуляций: «[ ]» обозначает «пробел или табуляция» (иначе говоря, это класс символов, состоящий из пробела и табуляции), а «+» — повтор один раз или более. Выражение для замены — это пробел. Опция «g» означает, что замена должна быть глобальной, т.е. во всем обрабатываемом тексте (при отсутствии этой опции замена произошла бы только для первой встреченной последовательности пробелов и/или табуляций).
Из команд поиска-замены и состоит написанный мной скрипт для ssed, решающий поставленную задачу (за исключением его начала, где расположены команды, загружающие в память весь обрабатываемый текст).
При написании сценария также было учтено пожелание редакции «Мира ПК» — он может обрабатывать и такие тексты, где вместо тире используются два дефиса подряд, а не один. Получившийся текст см. на «Мир ПК-диске».
Комментарии
В процессе создания скрипта при составлении списка сокращенных наименований единиц измерения информации использовались данные из [5], для списка доменов первого уровня — из [9, 10]. При написании регулярного выражения, распознающего адреса для последующего оформления их в виде гиперссылок, были взяты данные из [3].
Если хотите разобраться в функционировании скрипта, читайте подробные комментарии в нем самом. Ну и, конечно, вы должны понимать, как работает ssed, — об этом подробно рассказывается в [2].
Скрипт рассчитан на преобразование только абзацев текста; заголовки, списки, таблицы и т.п. не будут преобразованы в их HTML-аналоги — это вам придется делать cамостоятельно. По поводу преобразования таблиц рекомендую посмотреть статью [6]. А для преобразования листингов программ можно использовать вот такой простейший сценарий:
s/&/&/g
s/"/"/g
s/>/>/g
s/1 s/^/
//
$ s/$/
Руководство пользователя
Предположим, что скрипт содержится в файле с именем txt2html.sed, имя обрабатываемого текстового файла — source.txt, а результат надо получить в файле destiny.txt (и все эти три файла — в текущем каталоге). Тогда командная строка для запуска «ssed» будет такой:
ssed -R -f txt2html.sed source.txt >destiny.txt
Когда необходимо, то могут быть указаны и пути к файлам. Так, если предположить, что скрипт находится в каталоге «c:», обрабатываемый файл — в каталоге «e:work», а результат надо получить в каталоге «f:», то командная строка будет следующей:
ssed -R -f c: xt2html.sed e:worksource.txt >f:destiny.txt
Кстати, сразу замечу, что кодировка скрипта должна совпадать с кодировкой обрабатываемого текста.
Обработанный текст, полученный в результате работы сценария, еще не является готовым HTML-документом. Чтобы получить HTML-документ, надо поместить этот обработанный текст в специальную «заготовку» (шаблон).
Transitional//EN"
"http://www.w3.org/TR/html4/loose.dtd">
Сюда помещаем обработанный текст:
В содержимом атрибута «charset», конечно, должна быть указана фактическая кодировка документа, не обязательно Windows-1251, как в шаблоне.
Замечу, что иногда бывает так, что при публикации HTML-документа требуется «закачивать» его на сервер в заранее определенной кодировке, которая в самом документе не должна указываться (т.е. метатега «» вообще не должно быть). Дело в том, что сервер может отдавать посетителю HTML-документ, при необходимости переводя его в другую кодировку, но не изменяя в этом документе содержимое атрибута «charset», из-за чего у посетителя порой возникают проблемы с просмотром документа.
Пример
Здесь я продемонстрирую на конкретном примере, как скрипт преобразует обрабатываемый текст. Для этого возьмем фрагмент из романа Л.Н. Толстого «Анна Каренина» [8].
"Да! Она не простит и не может простить.
И всего ужаснее то, что виной всему я, -
виной я, а не виноват. В этом-то вся драма, -
думал он. - Ах, ах, ах!" - приговаривал он с
отчаянием, вспоминая самые тяжелые для себя
впечатления из этой ссоры.
Неприятнее всего была та первая минута,
когда он, вернувшись из театра, веселый и
довольный, с огромною грушей для жены в руке,
не нашел жены в гостиной; к удивлению, не
нашел ее и в кабинете и, наконец, увидал ее в
спальне с несчастною, открывшею все запиской
в руке.
Она, эта вечно озабоченная, и
хлопотливая, и недалекая, какою он считал ее,
Долли, неподвижно сидела с запиской в руке и
с выражением ужаса, отчаяния и гнева смотрела
на него.
- Что это? Это? - спрашивала она,
указывая на записку.
И при этом воспоминании, как это часто
бывает, мучало Степана Аркадьича не столько
самое событие, сколько то, как он ответил на
эти слова жены.
После обработки этого текста скриптом получается вот что:
«Да! Она не простит и не может простить.
И всего ужаснее то, что виной всему я,
—
виной я, а не виноват. Вэтом-то
вся драма, — думал он.
— Ах, ах, ах!» —
приговаривал он с отчаянием, вспоминая самые
тяжелые для себя
впечатления из этой ссоры.
Неприятнее всего была та первая минута,
когда он, вернувшись из театра, веселый и
довольный, с огромною грушей для жены в руке,
не нашел жены в гостиной; к удивлению, не
нашел ее и в кабинете и, наконец, увидал ее в
спальне с несчастною, открывшею все запиской
в руке.
Она, эта вечно озабоченная, и
хлопотливая, и недалекая, какою он считал ее,
Долли, неподвижно сидела с запиской в руке и
с выражением ужаса, отчаяния и гнева смотрела
на него.
— Что это? Это? —
спрашивала она,
указывая на записку.
И при этом воспоминании, как это часто
бывает, мучало Степана Аркадьича не столько
самое событие, сколько то, как он ответил на
эти слова жены.
Полученный на основе этого обработанного текста HTML-документ отображается в браузере Opera 5.12 так:
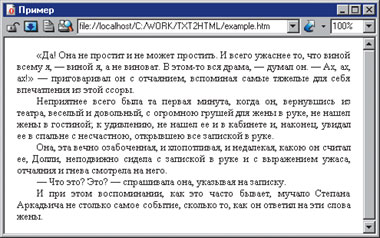
Если вы программируете на Perl...
...и хотите перенести в свою программу скрипт, описанный в этой статье, или его фрагменты, то этот раздел будет полезен для вас — в нем речь пойдет о переносе в программу на Perl команд поиска-замены.
Как уже упоминалось, синтаксис этих команд в ssed аналогичен синтаксису оператора поиска-замены в Perl. Вдобавок рассмотренный скрипт написан в режиме совместимости регулярных выражений с этим языком (потому-то при его запуске и требуется указывать в командной строке опцию «-R»). Но различия есть, и их надо иметь в виду. Возьмем для примера одну команду данного сценария. Вот эта команда (на самом деле она большая, и для экономии места группа строк из ее середины заменена многоточием):
s/ # 1-й вариант адреса.
(? # не должен быть сразу перед адресом.
(ht|f)tp:// # Начальная часть адреса.
[0-9a-z_[x5d;/?:@&=+$,.!~*'()%#-]+
# Окончание
# адреса.
# 2-й вариант адреса.
|(? # не должен быть сразу перед адресом.
[0-9a-z.-]+.(biz|com|edu|gov|info|int|mil|
name|
net|org|pro|aero|coop|jobs|museum|travel|arpa|
...
us|uy|uz|va|vc|ve|vg|vi|vn|vu|wf|ws|ye|yt|
yu|za|
zm|zw) # Начальная часть адреса.
(?![0-9a-z_-]) # Ни один из этих символов
# не должен быть сразу после начальной части
# адреса.
[0-9a-z_;/?:@&=+$,.!~*'()%#-]*
# Необязательное
# окончание адреса.
/&/gix # На что заменяем.
Правила преобразования команд поиска-замены при помещении этих команд в программу на Perl.
- Указанная в команде поиска-замены опция «x» позволяет и в ssed, и в Perl разбивать искомое регулярное выражение на несколько строк, в которых могут быть комментарии. Но при этом в ssed надо ставить в конце строки «», если выражение продолжается на следующей строке, а в Perl они не требуются и должны быть убраны.
- Как в регулярном выражении для поиска, так и в выражении для замены перед символами «$» надо поставить «» (кроме случаев, когда «$» обозначает конец строки или уже предварен относящимся к нему символом «»), и тогда Perl не будет считать, что с «$» начинается имя скалярной переменной. А чтобы у него не создавалось впечатление, что с «@» начинается имя массива, перед этими символами также надо поставить «». В выражении для замены необходимо заменить символы «&», используемые в ssed для обозначения всей найденной строки, на последовательности «$&», служащие для той же цели в Perl. Естественно, если «&» предварен относящимся к нему символом «» (и, таким образом, обозначает просто символ «&»), то заменять его не нужно. (В примере выражение для замены в последней строке команды как раз содержит символ «&», подлежащий замене.)
- В ssed обязательно должны разделяться точками с запятой лишь команды, расположенные по нескольку в одной строке. Но если вы перенесете группу команд поиска-замены в программу на Perl, то в конце каждой (возможно, кроме последней) надо будет поставить «;».
Вот как будет выглядеть взятая для примера команда после применения к ней вышеприведенных правил:
s/ # 1-й вариант адреса.
(? # не должен быть сразу перед адресом.
(ht|f)tp:// # Начальная часть адреса.
[0-9a-z_[x5d;/?:@&=+$,.!~*'()%#-]+
# Окончание
# адреса.
# 2-й вариант адреса.
|(? # не должен быть сразу перед адресом.
[0-9a-z.-]+.(biz|com|edu|gov|info|int|mil|name|
net|org|pro|aero|coop|jobs|museum|travel|arpa|
...
us|uy|uz|va|vc|ve|vg|vi|vn|vu|wf|ws|ye|yt|yu|za|
zm|zw) # Начальная часть адреса.
(?![0-9a-z_-]) # Ни один из этих символов
# не должен быть сразу после начальной части
# адреса.
[0-9a-z_;/?:@&=+$,.!~*'()%#-]*
# Необязательное
# окончание адреса.
/$&/gix; # На что заменяем.
* * *
Вот и подошел к концу рассказ о моей разработке, уважаемые читатели. Надеюсь, что благодаря рассмотренному скрипту облегчится ваша работа по преобразованию текстовых файлов в формат HTML, а в Рунете увеличится доля HTML-документов, оформленных в соответствии с нормами русской типографики.
Источники
- SED FAQ. http://sed.sourceforge.net/sedfaq.txt.
- Документация к ssed (файл «sed.info» из комплекта поставки ssed 3.62). http://sed.sourceforge.net/grabbag/ssed (документация находится в том же архиве, где и исходные тексты).
- Berners-Lee T., Fielding R., Masinter L. Uniform Resource Identifier (URI): Generic Syntax (RFC 3986). http://www.ietf.org/rfc/rfc3986.txt.
- Лебедев А. «Ководство». 62. «Экранная типографика». http://www. artlebedev.ru/kovodstvo2/sections/62.
- Лебедев А. «Ководство». 84. «Не подскажете, сколько байт в килобайте?». http://www.artlebedev.ru/kovodstvo2/sections/84.
- Рощин И. Преобразование псевдографических таблиц в формат HTML // Радиомир. Ваш компьютер. 2003. №5—7. http://ivr.webzone.ru/articles/tab2html.
- Былинский К.И., Никольский Н.Н. Справочник по орфографии и пунктуации для работников печати. М.: Изд-во Московского университета, 1970.
- Толстой Л.Н. Анна Каренина. М.: Правда, 1962. Т. 1. с. 6.
- Общий домен верхнего уровня. «Википедия». Версия от 10 апреля 2006 г. 15:19 UTC. http://ru.wikipedia.org/w/index.php?title=Общий_домен_ верхнего_уровня&oldid=1018346.
- Национальный домен верхнего уровня. «Википедия». Версия от 4 мая 2006 г. 13:16 UTC. http://ru.wikipedia.org/w/index.php? title=Национальный_ домен_верхнего_уровня&oldid=1119821.
ОБ АВТОРЕ
Иван Рощин — автор более 80 статей и ряда свободно распространяемых программ для ZX Spectrum и PC, веб-страница: http://www.ivr.da.ru.
¹Графическое оформление печатного текста посредством набора и верстки с использованием норм и правил, специфических для данного языка (http://ru.wikipedia.org/index.php?title=Типографика&oldid=1303578).