
RCO Fact Extractor — наделенная интеллектуальными возможностями программа, предназначенная для анализа текста на русском языке. Она позволяет отыскивать описания фактов заданного типа, например относящиеся к «встречам», «договоренностям», «приобретению собственности», причем производятся их классификация и упорядочивание. Основная область применения программы — аналитические задачи, возникающие при проведении компьютерной разведки и требующие высокоточного поиска информации, в том числе автоматического подбора материала к досье на целевой объект или мониторинга определенных сторон его активности, освещаемых в СМИ. В программе Fact Extractor воплощены наиболее продвинутые технологии искусственного интеллекта, разработанные компанией «Гарант-Парк-Интернет», известной своими решениями в области компьютерной лингвистики (www.rco.ru).
Помимо Fact Extractor с графическим интерфейсом для Windows компания выпустила динамическую библиотеку для разработчиков (SDK). На ее базе и построена программа, позволяющая включать возможности анализа текста в собственные приложения, в частности обрабатывать документы в популярных текстовых форматах и из таких источников, как файловая система, база данных, оговоренные веб-сайты.
Результатом работы программы является таблица, содержащая информацию о найденных фактах, связанных с объектами мониторинга, которая может экспортироваться в файл html-формата для формирования отчета или загрузки в стороннее приложение, работающее с уже структурированными данными.
Как работать с программой?
Основные логические сущности, которыми оперирует Fact Extractor, следующие:
- факты, описания которых ищут в тексте;
- объекты мониторинга для сбора фактов;
- атрибуты объектов, к которым относятся факты;
- досье, где собирается информация обо всех найденных фактах.
Фактом называется некоторая ситуация (событие), представляющая интерес для пользователя программы. Ее описание следует искать в тексте. Каждый факт имеет свой тип — название ситуации (например, «покупка акций») — и список ролей возможных участников-фигурантов («покупатель», «продавец», «эмитент акций»). Лингвистические описания фактов требуемого типа — шаблоны для поиска в тексте — либо создаются пользователем с помощью дополнительной программы-настройщика, либо приобретаются у производителя. В стандартный пакет поставки Fact Extractor входят готовые описания для нескольких типов фактов общего характера, позволяющие выделить без детальной классификации все события, в которых участвует объект, и всех участников этих событий.

|
| Рис. 1. Настройка атрибута объекта «владеет предприятиями» — объединение фактов различных типов (список в окне слева) |
К объектам мониторинга, по которым ведется сбор фактов, относятся персоны и организации. Описание объекта включает в себя целый ряд полей, значения которых задаются пользователем, например для персоны обязательные поля «Фамилия» и «Имя», желательное — «Отчество». А если есть возможность, то полезно задавать такие поля, как «Синонимы», «Контекстные синонимы», «Референтный контекст», «Эквивалентные по смыслу». Не вдаваясь в содержание этих полей, заметим, что более полное описание объекта позволяет правильно выделять большее количество упоминаний в тексте, включая полные и краткие наименования, косвенные обозначения, а также различать объекты с одинаковыми фамилиями, именами, должностями и пр.
Атрибут — комплексная характеристика определенной стороны объекта или его деятельности, представляющая конечный интерес для пользователя-аналитика. Экспертное суждение об атрибуте объекта будет складываться на основе фактов различного типа. Например, атрибут «политический профиль персоны» может формироваться из множества фактов типа «кого поддержал на выборах», «за что критикует власть» и т.п. В то же время один и тот же факт может интерпретироваться по-разному и отражать разные стороны объекта, т.е. относиться к нескольким его атрибутам. Поэтому каждый атрибут определяется пользователем, задающим способ объединения и интерпретации фактов.
Для каждого типа фактов указывается роль, в которой должен стоять целевой объект мониторинга, для того чтобы факт относился к данному атрибуту объекта (выбирается в группе «участники факта» в столбце «целевой»). Как видно, в атрибут дважды включен факт типа «купля-продажа акций», причем в первом случае целевой участник выступает в роли «продавца», а во втором — в роли «покупателя». Это имеет смысл при ретроспективном анализе информации, так как покупатель и продавец являлись владельцами предприятия. При анализе новостей, когда интерес представляет появление новых владельцев, целесообразно включать целевого участника только в роли «покупателя». Дополнительно в группе «участники факта» в столбце «значение» помечаются роли других участников, интересующих аналитика, которые формируют значение атрибута и отображаются на экране. В данном случае это роль «эмитента» — выпускающего акции предприятия, которым владеет покупающий или продающий их объект мониторинга. Факты с одинаковым значением группируются вместе и образуют одну запись в досье (рис. 2).
|
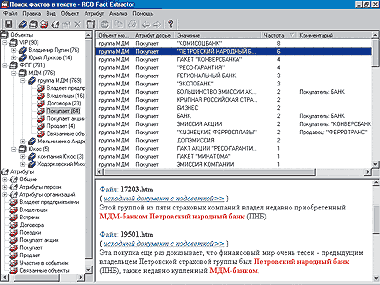
| Рис. 2. Общий вид интерфейса пользователя Fact Extractor |
В итоге все найденные факты объединяются по атрибутам объектов и собираются в таблицу, называемую досье. Каждая запись досье содержит информацию об одном найденном факте или о множестве похожих: объект мониторинга и его атрибут, к которым относится факт; значение атрибута — фигурант факта, извлеченный из текста; количество упоминаний о факте в обработанных документах и др.
В окне слева — объекты и атрибуты, для удобства объединенные в логические группы. С каждым объектом можно связать свои атрибуты, перетащив их мышью. В окне справа — список найденных фактов, связанных с атрибутом «покупает» выбранной группы объектов МДМ. Атрибут настроен так, что факты сгруппированы по значению фигуранта «предмет покупки». В окне снизу приведены найденные описания факта покупки «Петровского народного банка» — шесть цитат из документов с возможностью просмотра их полного текста. Упорядочив записи досье по столбцу «значение», можно найти все факты других типов, связывающие группу МДМ и «Петровский народный банк», например заключение договоров. Упорядочив записи по столбцу «частота», можно отобрать факты, оказавшиеся в фокусе внимания журналистов.
Как работает программа?
Для поиска описаний фактов текст представляется в форме семантической сети, строящейся лингвистическим процессором — интеллектуальным ядром программы. Семантическая сеть содержит все полнозначные слова и словосочетания, упоминавшиеся в тексте: наименования предметов, персон, организаций, событий и признаков, связанные различными типами связей.
Представление текста в форме семантической сети позволяет абстрагироваться от многих его особенностей, не существенных для описания фактов. Такая сеть инвариантна к форме предложения и порядку слов с точностью до логической структуры, выбранной автором для описания ситуации, — пропозиции. Например, конструкциям «Иванов купил акции» и «об акциях, которые были куплены Ивановым», как разным способам выражения одной пропозиции, будут соответствовать одинаковые сети. В то же время пропозициям вида «Иванов становится покупателем акций» и «покупка акций — дело рук Иванова» будут соответствовать иные сети.
Шаблон факта задается множеством лингвистических описаний (ЛО), и каждое из них соответствует своему типу пропозиции и позволяет распознать целое множество семантических сетей близкой структуры. Лингвистическое описание представляет собой сеть, подобную искомой, но в ее узлах и связях с помощью логических выражений задаются условия, которым должны удовлетворять узлы и связи искомой сети. Как правило, в некоторых узлах ЛО содержатся конкретные слова и их синонимы, включаемые в описание искомой ситуации. Часть узлов, соответствующих искомым фигурантам факта, содержат не слова, а метки, обозначающие роли участников ситуации. Слова, стоящие в этих узлах и неизвестные заранее, будут выданы при нахождении факта. Для хорошего распознавания фактов обычно требуется 5—10 лингвистических описаний на каждый тип факта.
Поиск факта есть поиск в семантической сети текста подсети, изоморфной одному из ЛО. Если подсеть найдена, то факт считается установленным, после чего производятся извлечение фигурантов факта и их отнесение к заданным ролям.
Три узла, обозначенные метками BUYER, ISSUER и SELLER, представляют возможных фигурантов факта «покупка акций» в ролях «покупатель», «эмитент» и «продавец» соответственно. Наличие узла SELLER вместе с идущей к нему связью не является обязательным при поиске, так как продавец может быть и не указан в тексте, и именно пара «покупатель—эмитент» представляет интерес для факта покупки акций.
Для настройки шаблонов фактов используется модуль с графическим интерфейсом, позволяющим строить ЛО на основе типовых фраз русского языка, т.е. обучать программу на примерах. Основа ЛО — узлы и связи сети — строится программой автоматически, после чего остается лишь проставить ограничения в узлы в виде списков синонимов, указать роли искомых фигурантов факта, пометить обязательных и факультативных фигурантов. Эта процедура не требует специальных лингвистических знаний, однако предполагает хорошее владение русским языком для понимания тех способов, которыми факт может быть описан в тексте, и для учета возможных синонимов. Если вы приобретете определенную сноровку после нескольких дней работы с программой, то создание и тестирование шаблона факта, содержащего десяток ЛО, будет занимать у вас около часа.
ОБ АВТОРЕ
А. Е. Ермаков — канд. техн. наук, руководитель отдела компьютерной лингвистики ООО «Гарант-Парк-Интернет», ermakov@metric.ru