К официальной статистике люди всегда относились с недоверием. Достаточно вспомнить высказывание Марка Твена: "Существует три вида лжи - невинная ложь, наглая ложь и статистика". В застойные времена в нашей стране статистические методы в основном применялись в научных исследованиях для обработки результатов экспериментов. Но по-настоящему широкий интерес к ней возник в послеперестроечное время. Статистика вдруг понадобилась всем - от политиков, желающих предсказать исход выборов, до предпринимателей, стремящихся оптимизировать прибыль при тех или иных вложениях капитала.
На Западе статистику используют широко и давно, так что эта наука интенсивно развивалась. Было создано множество программ, в том числе и для персональных компьютеров, позволяющих применять самые современные методы математической статистики для обработки данных.
Стандартные статистические методы обработки данных включены в состав электронных таблиц, таких как Excel, Lotus 1-2-3, QuattroPro и др.; в математические пакеты общего назначения - Mathсad, Maple и т. д. Но, конечно, гораздо большими возможностями обладают такие специализированные пакеты как SPSS фирмы SPSS Inc., SAS фирмы SAS Institute, и среди них особого внимания заслуживает Statistica 5.1.
Пакет Statistica разработан фирмой StatSoft (США), основанной в 1984 г. Первоначально он входил в качестве модуля в состав самых популярных в то время электронных таблиц Lotus 1-2-3. Как самостоятельный продукт пакет впервые заявил о себе в 1991 г. и с тех пор занимает лидирующее положение среди специализированных статистических программ. Последняя версия продукта - Statistica 5.1 - совместима не только с Windows 3.1, но и с Windows 95, в ней поддерживается графический интерфейс пользователя (GUI) и динамический обмен данными (DDE). Благодаря этому пакет может работать в сочетании с другими Windows-приложениями. В новую версию включен также язык программирования Statistica-BASIC, позволяющий расширять возможности пакета в соответствии с потребностями пользователя.
Благодаря профессионализму исполнения, простоте освоения и удобству использования пакет приобрел большую популярность (зарегистрировано свыше 300 тыс. пользователей). Statistica 5.1 позволяет проводить исчерпывающий, всесторонний анализ данных для научного, коммерческого и инженерного применения. Программа обладает превосходными средствами представления результатов анализа в виде таблиц и графиков, позволяет автоматически создавать отчеты по проделанной работе. Система подсказок составлена настолько продуманно и так удобна в обращении, что с ее помощью можно обучаться не только работе с самим пакетом, но и современным методам статистического анализа.
Statistica - начинающему пользователю
Допустим, вы предприниматель и вам нужно собрать информацию о финансовых результатах деятельности фирмы. Эти данные могут быть использованы не только для представления отчета в налоговые органы. Пользуясь пакетом Statistica, можно проанализировать деятельность как фирмы в целом, так и отдельных ее подразделений, принять решения, направленные на улучшение результатов.
Однако хорошая иллюстрация нагляднее абстрактных рассуждений, поэтому мы продемонстрируем основные возможности пакета на двух конкретных примерах.
Пример 1
Представим такую ситуацию (пример взят из книги: Кимбл Г. Как правильно пользоваться статистикой, М.: Финансы и статистика, 1982. 294 с.). Вы поручили реализацию одинаковых партий продукции нескольким сотрудникам и по результатам их работы за некоторый период времени хотите определить, случайна ли разница в полученной выручке. Если не случайна, значит, необходимо принять соответствующие меры для увеличения объема продаж. В таблицу внесены данные о продажах продукции четырьмя сотрудниками фирмы в течение десяти месяцев. Общее число продаж n=40. Каждому сотруднику соответствует группа из десяти случайных величин - объемов продаж (число групп N=4). Таблица состоит из четырех столбцов, в заголовках которых указан номер группы, в десяти строках - выручка за каждый месяц, а в последней строке - средняя выручка за весь рассматриваемый период (см. таблицу).
Очевидно, что у каждого сотрудника объемы продаж варьируются от месяца к месяцу, т. е. cуществует некоторый разброс результатов. Количественная характеристика этого разброса (дисперсия) вычисляется по формуле
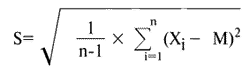
|
(1) |
где: Xi - значения случайной величины X (в нашем случае - объема продаж), M - среднее значение случайной величины X в n событиях:
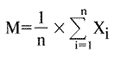
|
(2) |
В нашем случае n=10, в нижней строке приведены средние значения для каждого сотрудника, вычисленные по этой формуле. Из таблицы видно, что существует разброс и между средними показателями отдельных сотрудников, который также можно оценить по формулам (1), (2); здесь, однако, случайными величинами будут средние показатели для отдельных сотрудников, а n=4. Интуитивно ясно, что чем больше дисперсия (разброс) средних показателей продаж сотрудников по отношению к дисперсии продаж каждого отдельного сотрудника, тем более вероятен такой вывод: либо сотрудники работают в разных условиях, либо представленные данные неверны.
Для количественного решения этой задачи в статистике применяется метод дисперсионного анализа (Analysis of variations - ANOVA). В этом методе для ответа на заданный выше вопрос используется так называемый F-критерий, величина которого равна отношению дисперсии средних показателей групп к средней дисперсии внутри отдельных групп. Программа Statistica может рассчитать F по данным Xi, числу групп N и числу событий n. При этом предполагается, что все случайные величины подчинены одному и тому же закону распределения (для нашего случая это означает, что все сотрудники работают в одинаковых условиях). Вероятность полученного значения величины F, вычисляемого с помощью этого метода, показывает, насколько справедливо сделанное предположение.
Давайте посмотрим, как решает подобные задачи программа Statistica.
Запустим программ и выберем метод анализа ANCOVA/MANCOVA. Загрузится соответствующий модуль. Можно получить более подробную информацию о методе, выбрав в меню Help/Index раздел "ANCOVA/MANCOVA - Вводный обзор основных понятий". При запуске модуля по умолчанию будет загружен также файл данных, использовавшийся в предыдущем сеансе работы программы. Файл данных представляет собой обычную электронную таблицу. Пользователи Excel и других аналогичных электронных таблиц без труда освоят методы работы с данными в ней. В пакете Statistica все операции, включая копирование, перетаскивание и автоматическое заполнение ячеек, производятся так же, как в популярных электронных таблицах. При нажатии правой кнопки мыши появляется всплывающее меню, где точно так же предлагается перечень операций, которые можно выполнить над выделенным объектом.
Кроме того, данные можно скопировать из других Windows-приложений или импортировать из файлов. Кнопки на Панели инструментов позволяют вводить наименования переменных.
В нашем случае данные, приведенные в таблице, удобно занести в столбцы, соответствующие двум переменным (в каждом столбце по 40 строк). В первый столбец (независимая переменная "ГРУППА") заносятся номера групп, во второй (зависимая переменная "ВЫРУЧКА") - соответствующие объемы продаж.
Наконец файл данных готов. Теперь из раздела Analysis главного меню программы можно вызвать исходное окно (Startup Panel). В нем представлено много элементов, но если вы не знаете, что делать дальше, можно нажать знак ? в правом верхнем углу этого окна и получить подробную информацию обо всех его элементах. Впрочем, лучше нажать кнопку OK, и программа сама подскажет, что делать. Первым делом Statistica предложит ввести зависимую и независимую переменные для анализа. Щелчком правой кнопки мыши обозначим независимую ("Группа") и зависимую ("Выручка") переменные и нажмем на кнопку OK. Вновь появится исходное окно, где следует опять нажать кнопку ОК.
После нажатия кнопки ОК появляется окно ANOVA-results с описанием условий задачи. В верхней строке указан метод анализа, а в следующих перечисляются зависимая ("ВЫРУЧКА") и независимая ("ГРУППА") переменные.
Осталось, нажав на кнопку All effects, получить информацию о результатах анализа. Программа выводит окно, в котором указаны параметры для вычисления F-фактора: df Effect=3 (N-1), MS Effect=1333 (межгрупповая дисперсия), df Error=36 (n-N), MS Error=66,66 (внутригрупповая дисперсия), значение самого F-фактора (F=20) и вероятность получения данного значения F-фактора при случайном разбросе средних (p-level). В нашем случае эта вероятность равна нулю с точностью до шести знаков. Вывод: полученная разница между объемами продаж с очень большой вероятностью (близкой к 100%) неслучайна, так что необходимо устранять причину неудовлетворительной работы двух сотрудников.
Другие кнопки в окне просмотра результатов анализа предназначены главным образом для всестороннего изучения (в том числе с использованием графиков распределений) исходных данных с точки зрения применимости нормального распределения случайных величин, которое предполагается в этом методе анализа. Например, если мы нажмем на кнопку Descriptive stats & graphs (Описательная статистика и графики), а в появившемся после этого окне - на кнопку Categorized normal probability plot, то получим матричный график распределения вероятностей для всех четырех серий, причем масштаб вертикальной оси выбирается так, чтобы нормальному распределению соответствовали прямые линии (вероятностная шкала). На графике нанесены прямые линии, соответствующие нормальному распределению, и видно, что наши случайные величины (объемы продаж) очень хорошо ложатся на прямые нормального распределения.
Прежде чем распечатывать результаты анализа, было бы удобно сформировать отчет.
Для этого в меню File/Page/Output setup в разделе Output активизируем Off (чтобы отключить принтер) включаем опцию Window, позволяющую сразу просмотреть полученный результат.
После нажатия кнопки OK появится новое текстовое окно Output, в которое можно внести информацию о проделанном анализе. При активизации любого окна с данными и результатами анализа и последующем выводе на принтер (кнопка принтера слева на основной панели инструментов) информация продублируется в окне Output. Для распечатки полученного таким образом отчета достаточно активизировать окно Output и нажать кнопку Printer на основной панели инструментов. Отчет можно также сохранить в текстовом файле в формате .RTF.
Пример 2
Рассмотрим еще один пример из реальной практики производственной фирмы, выпускающей продукцию, пользующуюся большим спросом.
За прошедшее время прибыль неуклонно падала. Необходимо определить, с чем связано это падение, - с усилением конкуренции или с общей депрессией в экономике. Для этого в таблицу данных вводятся данные об инфляции за тот же период времени; инфляция вычисляется как отношение приращения курса доллара за месяц к его величине на начало месяца. Сначала поясним, как строится график временной зависимости прибыли и инфляции. Для этого нажмем верхнюю кнопку на левой панели инструментов (Custom 2D graphs) и в появившемся окне в разделе Plot1 в качестве X введем "ДАТА", а в качестве Y - "ПРИБЫЛЬ", в разделе Plot2 в качестве X введем "ДАТА", а в качестве Y - "ИНФЛЯЦИЯ". Для разделов Plot1 и Plot2 выберем вид графика Line Plot, а для разделов Plot3 и Plot4 - Ignore. Нажав ОК, мы увидим в окне, что графики инфляции и прибыли ведут себя очень похоже: как правило, если прибыль падает, падает и инфляция. Поведение инфляции никак не связано с деятельностью фирмы и определяется общими экономическими процессами в государстве, поэтому очень важно определить, насколько существенна связь между прибылью и инфляцией. Для этого в статистике существует метод корреляционного анализа. В программе этот метод можно найти, переключившись на модуль Basic statistic/Tables, что мы и сделаем. Теперь вызовем исходное окно, щелчком правой кнопки мыши в окне данных выделим переменные, которые хотим анализировать ("ПРИБЫЛЬ", "ИНФЛЯЦИЯ"), в исходном окне выберем раздел Correlation matrices и нажмем ОК.
На экране появится окно корреляционного анализа. Поскольку мы предварительно обозначили переменные, то в списке переменных в левом углу будет напечатано "First List: ПРИБЫЛЬ - ИНФЛЯЦИЯ". Теперь нажмем кнопку Correlations.
В появившейся таблице указан коэффициент корреляции, для переменных "ПРИБЫЛЬ" и "ИНФЛЯЦИЯ" равный 0,78.
Если теперь нажать кнопку 2D scatterp., а затем в качестве переменной X выбрать "ИНФЛЯЦИЯ", а в качестве переменной Y - "ПРИБЫЛЬ", то после нажатия ОК получим график, на котором изображены все точки данных и прямая линия, являющаяся наилучшим линейным приближением отражающим зависимость между переменными. Соответствующая этой прямой формула автоматически выписывается под заголовком графика:
ПРИБЫЛЬ = 7.0060 + .99166 3 3 ИНФЛЯЦИЯ
На этом же графике указан коэффициент корреляции между переменными (0,77548), штриховыми линиями обозначен доверительный интервал (область, в которой с вероятностью 95% лежат значения переменных).
В общем случае математическим коэффициентом корреляции между случайными величинами X и Y является величина
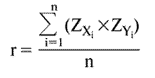
|
(3) |
при
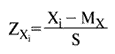
|
(4) |
где Z - оценка (разница между значением данного наблюдения величины Xi и средним этой величины MX, отнесенная к упомянутой выше дисперсии случайной величины S). Коэффициент корреляции может принимать значения в интервале от -1 до 1, и чем ближе его абсолютная величина к 1, тем сильнее взаимосвязь между переменными (знак коэффициента r указывает на направление взаимосвязи - прямое или обратное). Значение r = +1 или r = -1 указывает на наличие строгой функциональной зависимости, значение r = 0 указывает на отсутствие какой-либо взаимосвязи. Таким образом, значение r = 0,78 между переменными "ПРИБЫЛЬ" и "ИНФЛЯЦИЯ" указывает на прямую взаимосвязь между этими величинами, и можно предположить, что падение прибыли и падение инфляции с высокой степенью вероятности связаны с одними и теми же отрицательными процессами в экономике.
Используя полученные данные, можно сделать и другие выводы. Например, о периодическом падении и возрастании спроса, что связано с сезонным фактором. Зависимость прибыли от времени можно аппроксимировать различными кривыми.
Для этого на левой панели инструментов нажмем кнопку Graphs Gallery и, выбрав Stats 2D Graphs - Scatterplots, нажмем ОК. В появившемся окне в качестве переменной X выберем "НОМЕР", а в качестве переменной Y - "ПРИБЫЛЬ". Теперь из списка можно выбрать различные варианты подгонки кривой "ПРИБЫЛЬ=f(НОМЕР)".
ПРИБЫЛЬ=23.523 3 exp(-0.06 3 НОМЕР),
где "НОМЕР" - номер месяца от начала работы фирмы. По этой формуле мы можем предсказать прибыль фирмы в недалеком будущем. Например, на 35-м месяце (N = 35) получим ПРИБЫЛЬ = 2,88, что в девять раз меньше прибыли в первом месяце.
Рассмотренные примеры достаточно просты, но они показывают, что на освоение методов анализа и обучение работе с программой Statistica не придется тратить много времени, а важность полученных результатов трудно переоценить.
Программа способна решать и гораздо более сложные задачи, она также помогает незнакомому с предметом пользователю повышать свой уровень.
Но и искушенный пользователь найдет программу Statistica не менее полезной.
Statistica - профессионалу
Во-первых, своими техническими возможностями.
- Программа способна обрабатывать огромные массивы данных - таблицы с числом переменных (столбцов) до 32 000 и практически неограниченным числом строк (случаев); в ней имеется специальный модуль - менеджер файлов, который может создавать мегафайлы и манипулировать ими.
- Повышенная (quadruple) точность математических операций позволяет проводить анализ данных даже с очень малым разбросом величин.
- Расчеты и построение графиков выполняются с очень высокой скоростью (за счет оптимизации программного кода и механизмов управления памятью).
- Программа предлагает множество вариантов научных и технических графиков и диаграмм при великолепном качестве и поразительной точности отображения информации.
Во-вторых, Statistica предлагает пользователю широкий выбор методов анализа. Достаточно перечислить основные ее модули:
- Quick Basic Statistics (быстрый анализ) - модуль, позволяющий быстро провести анализ наиболее употребительными методами;
- Basic Statistics/Tables (основные статистические методы и таблицы) - описательные методы статистики, таблицы частот и корреляций, регрессии и другие базовые статистические методы;
- Nonparametrics/Distribution - внутригрупповые и межгрупповые непараметрические тесты, сравнение различных дискретных и непрерывных теоретических распределений с распределением наблюдаемых величин;
- ANCOVA/MANCOVA - однофакторный и многофакторный дисперсионный и ковариационный анализ;
- Multiple Regression - различные методы множественной линейной и фиксированной нелинейной регрессии (в частности, полиномиальной, экспоненциальной, логарифмической и др.);
- Nonlinear Estimation - методы подгонки к нелинейным зависимостям данных различных функций, в том числе заданных пользователем;
- Time Series/Forecasting - анализ при помощи временны'х рядов (рядов Фурье и др.) и прогнозирование временны'х зависимостей, в том числе анализ сезонных колебаний;
- Cluster Analysis - различные методы кластерного анализа и классификации;
- Factor Analysis - выделение наиболее существенных факторов сложного объекта методами повторных главных компонент, минимальных остатков, максимального правдоподобия;
- Canonical Analysis - метод канонического анализа корреляции между двумя группами переменных;
- Multidimensional Scaling - многомерное шкалирование;
- SEPATH - многомерный анализ с помощью моделирования причинных связей между переменными линейными структурными уравнениями, в том числе оценка достоверности результатов методом статистического моделирования Монте-Карло;
- Reliability/Item Analysis - анализ надежности сложного объекта на основе результатов диагностики его элементов;
- Discriminant Analysis - дискриминантный анализ, позволяющий на основе определенного критерия отнести объект к некоторому классу;
- Log-linear Analysis - логарифмический линейный анализ сложных многоуровневых таблиц частот;
- Survival Analysis - анализ долговечности (выживания) для задач социологии (особенно необходим страховым компаниям), биологии, инженерных задач (долговечность машин, сооружений) и др.
- Еще три модуля программы объединены в общий класс "Промышленная статистика".
- Quality Control - широкий набор методов контроля качества;
- Process Analysis - набор методов анализа производственных процессов, в том числе калибровочный анализ повторяющихся партий продукции;
- Experimental Design - модуль планирования эксперимента в промышленных и прикладных областях.
Модули программы не являются независимыми друг от друга и часто используют одни и те же процедуры. В процессе работы легко переключиться с одного модуля на другой. Более того, пользуясь встроенным в систему командным языком (Statistica Command Language - SCL), вы можете запустить программу в так называемом пакетном режиме.В этом случае Statistica шаг за шагом, переключаясь с одного модуля на другой, обработает ваши данные и выведет результат на печать или в файл. При частом использовании SCL-режима в интерфейс можно добавить специальную кнопку, которая будет автоматически запускать нужную последовательность действий.
Включенный в новую версию Statistica 5.1 эффективный, легко усваиваемый язык программирования Statistica-BASIC позволяет пользователю создавать собственные программы обработки и преобразования данных. В состав пакета входят несколько программ, написанных на языке Statistica-BASIC, которые можно использовать в качестве примеров или заготовок.
Пользователь, занимающийся сбором данных - будь то экспериментальные данные, полученные в научных исследованиях, данные инженерных измерений, экономические данные, характеризующие деятельность предприятия, или данные, собранные в ходе социологических опросов, - знает, насколько неблагодарен этот труд, зависящий от многих обстоятельств и требующий больших затрат времени и сил. Однако не меньшие усилия подчас требуются и для того, чтобы полученные результаты грамотно обработать и извлечь из них максимум информации. Программа Statistica 5.1 станет надежным помощником и консультантом в этой работе, подскажет, какие методы анализа существуют и какие из них лучше всего подходят для тех или иных задач, избавит пользователя от рутинных вычислений, наглядно продемонстрирует результаты анализа, поможет оптимально спланировать будущие эксперименты и высококачественно оформить выполненную работу, оставив специалисту удовольствие обобщить результаты и сделать соответствующие выводы.
Хотелось бы поблагодарить директора корпорации SoftLine Игоря Боровикова за любезно предоставленную возможность ознакомиться с программой Statistica 5.1.
Statistica 5.1
Программа поставляется на CD-ROM. В поставку входят четыре тома с подробным описанием пакета.
Платформа: Macintosh, Windows. Поддерживаются сетевые стандарты Windows for Workgroups.
Системные требования для Windows-версии: процессор 386 и выше, 4-Мбайт ОЗУ (рекомендуется 8-Мбайт), операционная система Windows 3.1 и выше, дисковое пространство - 18Мбайт.
Цена: 1782 долл., для учебных заведений - скидки.
Тел. поставщика в Москве: (095) 232-00-23, e-mail: root@softline.msk.su
Борис Михайлович Манзон - к.ф.-м.н., тел.: (095) 498-45-16.