
Как устроены распределенные прикладные системы? Каковы наиболее важные их компоненты? Какую роль играет промежуточное программное обеспечение в разработке распределенных систем? Наконец, каковы типичные проблемы, которые могут возникнуть в процессе разработки и интеграции систем? Попытаемся ответить на эти вопросы.
В составе прикладной системы удобно выделить прикладное программное обеспечение и платформу. Формирующие (наряду с аппаратурой) платформу операционную систему, СУБД и программное обеспечение промежуточного слоя [1-4] вместе называют системным ПО.
Большинство прикладных программ можно разделить на три части: логику (алгоритмы) представления, бизнес-логику (расчетные алгоритмы и правила) и логику (алгоритмы) доступа к данным. Каждая часть вовсе не должна полностью соответствовать отдельному модулю, типу отдельной программы, нити, функции или процедуре — такое разделение весьма полезно, но не необходимо. Очень простые приложения часто способны собрать все три части в единственную программу, и подобное разделение соответствует функциональным границам.
Пользователи взаимодействуют с частью, называемой логикой представления, которая управляет доступом к приложению. Независимо от конкретных характеристик этой части системы (интерфейс командной строки, сложные графические пользовательские интерфейсы, интерфейсы через посредника) ее задача состоит в том, чтобы обеспечить средства для наиболее эффективного обмена информацией между пользователем и системой. Вот почему на стадии проектирования приложения так много внимания уделяют этому компоненту, видимому со стороны внешнего мира.
Бизнес-логика определяет, для чего, собственно, предназначено приложение. В зависимости от конкретных функциональных требований и сложности задач может быть полезным подразделить эту часть на несколько компонентов. В этом случае конкретная реализация каждого компонента может быть представлена в виде набора процедур (библиотеки), класса или классов объектов, отдельных программ. Разделение приложения по границам между программами обеспечивает естественную основу для распределения приложения на нескольких компьютерах.
Алгоритмы доступа к данным исторически рассматривались как специфический для конкретного приложения интерфейс к механизму постоянного хранения данных наподобие файловой системы или СУБД. Так, при помощи этой части программы приложение управляет соединениями с базой данных и запросами к ней (перевод специфических для конкретного приложения запросов на язык SQL, получение результатов и перевод этих результатов обратно в специфические для конкретного приложения структуры данных). К этой части относят только специфический для приложения интерфейс к СУБД, но не ее саму.
Иногда три указанные части называют слоями — от теоретической модели, которая рассматривает каждую часть приложения в терминах ее положения относительно пользователя, от «переднего слоя» (front-end, логика представления) до «заднего слоя» — (back-end, логика доступа к данным). Одна из функций «среднего слоя» (бизнес-логика) состоит в обеспечении двунаправленного преобразования между структурами данных высокого уровня переднего слоя и низкоуровневыми структурами заднего слоя. В этой модели положение каждого слоя (относительно пользователя) непосредственно связано с различными уровнями абстракции.
Рассмотрим приложение, которое производит поиск в базе данных согласно определенным пользователем критериям (рис. 1). Пользователь заполняет формы и нажимает кнопку «Поиск». Эта информация передается блоку бизнес-логики для формирования одного или более запросов. Эти запросы один за другим передаются блоку логики доступа к данным, который преобразует данные и запросы в формат, совместимый с СУБД, выполняет каждый запрос, получает результат и преобразует его в формат приложения. Наконец, он возвращает результат блоку бизнес-логики, который объединяет результаты нескольких запросов в порцию информации, передаваемую блоку логики представления; тот помещает эти данные в удобочитаемую форму и показывает ее пользователю.
Как правило, преобразования данных выполняются несколько раз. В некоторых приложениях избегают этого, используя структуры, подобные структурам СУБД, в качестве внутреннего формата представления данных. Тогда в рассматриваемом примере блок бизнес-логики может сразу же брать данные пользователя по мере получения их от блока логики представления и преобразовывать в SQL-запросы. После этого блок бизнес-логики может обращаться к базе данных непосредственно, без вовлечения специфической для приложения логики доступа к данным.
Проблема такого подхода состоит в том, что он привязывает приложение к определенному формату данных. Если приложение необходимо перенести на другую СУБД, внутренние структуры данных придется изменить. (Эта зависимость находится вне связи со специфической моделью базы данных, например, с различиями между иерархической и реляционной базами.)
Проблема обостряется еще, когда используется несколько различных по структуре представлений. В этом случае блок бизнес-логики вынужден поддерживать несколько внутренних представлений для, возможно, одних и тех же данных. Поэтому разумнее иметь один «родной» для приложения формат внутреннего представления данных. Преобразование в другой формат может выполняться, когда оно становится неизбежным (в блоке логики доступа к данным при взаимодействии с конкретной базой данных, в слое представления при взаимодействии с пользователем и т.д.).
Разделение функциональных алгоритмов на логику представления, бизнес-логику и логику доступа к данным предполагает разные уровни абстракции в различных частях приложения. Разложение же приложения на части согласно различным уровням абстракции представляет иерархию, которую можно использовать, чтобы разделить одну программу на несколько одновременно исполняемых модулей. Процесс, реализующий один или несколько уровней в этой иерархии, не должен ничего знать об уровнях, расположенных выше или ниже. Поэтому за исключением обмена информацией между процессами в различных слоях (рис. 1) каждый процесс независим и самодостаточен. Процесс на одном уровне не нуждается в прямом доступе к структурам данных, расположенным на другом уровне; следовательно, он может быть легко выделен в отдельно исполняемую программу.
Такое разделение минимизирует взаимодействие между составными элементами, уменьшая объем передаваемой информации и упрощая алгоритмы, отвечающие за связь между процессами, и потому служит основой для выделения компонентов, которые могут быть распределены на нескольких компьютерах.
Архитектуры прикладных систем
В таблице 1 перечислены наиболее часто встречающиеся архитектуры прикладных систем. Колонка «максимальное число пользователей» может рассматриваться как некоторая мера масштабируемости. Все архитектуры, кроме первой, являются архитектурами распределенных систем.
Как можно заметить, самая «древняя», централизованная архитектура обеспечивает намного более масштабируемое решение, чем две следующих. Потребовалось три поколения, прежде чем эти распределенные архитектуры смогли эффективно конкурировать с решением, ориентированным на универсальный компьютер: построить распределенную систему гораздо труднее.
Централизованная архитектура
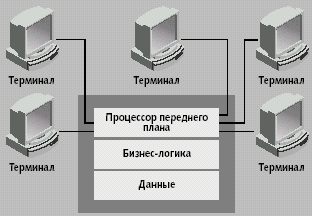
|
| Рис. 2. Централизованная архитектура. Блок «Данные» включает алгоритмы доступа к данным, СУБД и саму базу данных |
Одна мощная универсальная ЭВМ была единственной платформой, выполняющей все алгоритмы логики приложения (рис. 2). У централизованной архитектуры множество достоинств: простая разработка приложений, легкость обслуживания и управления. Именно они и обеспечили столь долгую жизнь «унаследованных» систем. Смерть универсальных ЭВМ неоднократно провозглашалась после появления четырех- и восьмиразрядных ПК в начале 80-х годов (компьютеры PET и VIC-20 компании Commodore, TRS-80 компании Radio Shack и множество других машин на базе процессоров Z-80, а также 6502 и 6800 производства Motorola). Однако они продолжали работать, переваривая десятки миллионов транзакций в день, приспосабливаясь к постоянно увеличивающимся нагрузкам.
Разделение файлов
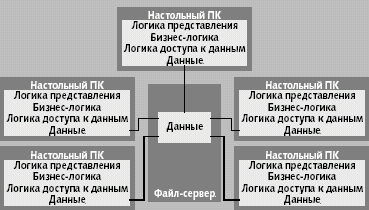
|
| Рис. 3. Архитектура разделения файлов |
Едва появившись, ПК принесли ожидание того, что большое число маленьких машин может заменить, а, в некоторых случаях, и превзойти по производительности универсальную ЭВМ. Архитектура разделения файлов, ставшая первым шагом к реализации этого притязания, включает множество настольных ПК и файловый сервер, связанных сетью (рис. 3). Файловый сервер загружает файлы из разделяемого местоположения, а прикладные программы исполняются полностью на настольных ПК.
Подобная архитектура была особенно популярна при использовании продуктов наподобие dBASE, FoxPro и Clipper. Первоначально сети персональных компьютеров были основаны на метафоре совместного использования файлов, потому что это было просто. Однако она хорошо работала лишь в некоторых случаях. Во-первых, все приложения должны вписаться в единственный ПК. Во-вторых, совместное использование и конфликты обновления чрезвычайно снижают производительность. Наконец, учитывая пропускную способность сети, объем данных, которые могут передаваться, также невелик. Все эти факторы крайне ограничивают число параллельных пользователей, которое способна поддерживать архитектура разделения файлов [6-8].
Клиент-сервер
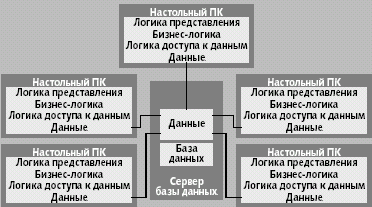
|
| Рис. 4. Ранние архитектуры клиент-сервер |
Стремление исправить архитектуру разделения файлов привело к замене файлового сервера сервером баз данных (рис. 4). Вместо передачи файлов целиком он пересылает только ответы на запросы клиентов, уменьшая нагрузку на сеть. Эта стратегия вызвала появление архитектуры клиент-сервер. Появившись в 80-х годах, она ввела понятие «клиента» (сторона, запрашивающая функции/обслуживание) и «сервера» (сторона, предоставляющая функции/обслуживание). На уровне программного обеспечения разделение на клиента и сервер является логическим: процессы клиента и сервера могут физически размещаться как на одной, так и на разных машинах. Под общим концептуальным названием скрываются три варианта архитектуры: двухзвенная, трехзвенная и многозвенная.
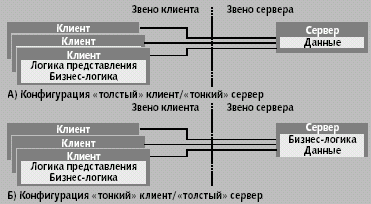
|
| Рис. 5. Двухзвенная архитектура |
Самая старая — двухзвенная (рис. 5). Она разделяет приложение на две части, клиентскую и серверную. Сторона клиента содержит логику представления, а логика доступа к данным, СУБД и сама база находятся на стороне сервера.
Остаются алгоритмы бизнес-логики, которые могут быть размещены как на машине клиента вместе с логикой представления (конфигурация «толстый клиент»), так и на стороне сервера (конфигурация «тонкий клиент»), или даже могут быть разделены между ними. Конфигурация «толстый клиент» более распространена: суммарная вычислительная мощность клиентов, по крайней мере, в теории, предполагается большей, чем мощность единственного сервера. Подобный ход рассуждений привел некоторых из разработчиков к созданию приложений, где даже логика доступа к данным размещается на клиенте, оставляя серверу только поддержание самой базы данных.
Двухзвенная архитектура, особенно конфигурация «толстый клиент», имеет ряд недостатков. Например, как и в архитектуре разделения файлов, — это ограничение, вытекающее из вычислительной мощности отдельных машин клиентов. Но еще хуже имеющее фундаментальный характер ограничения на число одновременных соединений с сервером. Сервер поддерживает открытое соединение со всеми активными клиентами, даже если никакой работы нет. Это необходимо, чтобы сервер мог получать сигналы тактового импульса, что не так страшно, когда клиентов менее 100 [9-12]; однако сверх этого числа производительность начинает быстро деградировать до недопустимо низкого уровня. Хорошим примером возникновения подобной проблемы может служить работа прокси-сервера.
В некоторых прикладных системах бизнес-логику пытаются реализовать, используя хранимые процедуры. Идея состоит в том, чтобы в соответствии с «тонкой» конфигурацией клиента переместить алгоритмы бизнес-логики на серверную машину, ближе к данным, которые требуются им постоянно. Это выглядит как хорошая идея, однако только усугубляет главную проблему. Так как осуществляющие бизнес-правила процессы теперь управляются СУБД, число пользователей, которых может поддерживать такая система, ограничено максимумом возможных активных соединений с СУБД. Кроме того, от СУБД к СУБД механизмы хранимых процедур разнятся. Тем не менее, двухзвенная архитектура хорошо работает в маленьких рабочих группах [9-12]. С начала 90-х годов появилась масса инструментальных средств, упрощающих создание систем в такой архитектуре, в том числе Delphi и PowerBuilder.

|
| Рис. 6. Трехзвенная архитектура |
С середины 90-х годов признание специалистов получила трехзвенная архитектура, которая, как и двухзвенная, поддерживала концепцию клиент-сервер, но разделила систему по функциональным границам между тремя слоями: логикой представления, бизнес-логикой и логикой доступа к данным (рис. 6). В отличие от двухзвенной архитектуры появляется дополнительное звено — «сервер приложений», целиком предназначенное для осуществления бизнес-логики.
Именно выделение бизнес-логики в отдельное звено позволяет преодолеть фундаментальные ограничения двухзвенной архитектуры. Клиенты не поддерживают постоянного соединения с базой данных, а обмениваются информацией со средним звеном только тогда, когда это необходимо. В то же время процесс среднего звена поддерживает всего несколько активных соединений с базой данных, но использует их многократно; поэтому процессы в среднем звене могут предоставлять обслуживание теоретически неограниченному числу клиентов. В сравнении со всеми другими моделями трехзвенная архитектура обладает столь многими преимуществами. Но преимущества не даются даром. Разработка прикладных программ, основанных на трехзвенной архитектуре, — более трудное дело, чем для двухзвенной архитектуры или при использовании централизованного подхода. Преодолеть возникающие проблемы помогает программное обеспечение промежуточного слоя [5-9].
Трехзвенная архитектура
Рассмотрим четыре варианта распределенных систем, основанных на трехзвенной архитектуре: с сервером приложений, с монитором обработки транзакций, с сервером передачи сообщений и с брокером объектных запросов.
Сервер приложений
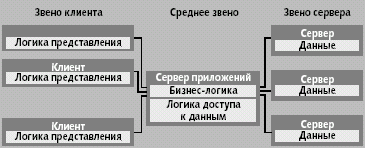
|
| Рис. 7. Трехзвенная архитектура с сервером приложений |
Клиенты (рис. 7) содержат только слой логики представления прикладного ПО, а алгоритмы бизнес-логики и логики доступа к данным перемещены в среднее звено. В этом случае сервер приложений обеспечивает «общее хранилище» бизнес-правил и процедур. Клиенты соединяются с сервером приложений и предоставляют ему данные для обработки. Совместное использование алгоритмов бизнес-логики, общих для всего приложения, обладает важными достоинствами. Помимо «утоньшения» клиента, эта стратегия ведет к созданию системы, в которой будущие обновления прикладного ПО будут производиться, главным образом, на сервере приложений, что упрощает процесс модификаций.
Обычно сервер приложений поддерживает пул ограниченного числа открытых подключений к базам данных и вместо того чтобы делать каждое подключение к базе данных выделенным для определенного клиента (как в двухзвенной архитектуре), подключения многократно используются для выполнения запросов различных клиентов.
Есть и другие преимущества. Во-первых, так как вся «важная» часть прикладной логики теперь централизована в среднем звене, нет необходимости поддерживать сложные механизмы аутентификации на стороне клиентов.
Во-вторых, аппаратная платформа, на которой выполняется сервер приложений, может быть достаточно мощной; это дает дополнительную степень масштабируемости всей прикладной системы.
В-третьих, централизованный доступ к данным в серверах приложений делает всю прикладную систему менее зависящей от конкретной СУБД.
Наконец, сервер приложений обеспечивает эффективную стратегию для интеграции. Придерживаясь того же протокола коммуникации, что и клиент, другое «внешнее» приложение может легко взаимодействовать с «чужим» сервером приложений. Эта конфигурация допускает интеграцию приложений не только на уровне данных, но и на уровне правил бизнес-логики. Это чрезвычайно важно, потому что совместное использование данных разными прикладными программами может вести к логическим противоречиям в базе данных. Типичное решение состоит в том, чтобы копировать одни и те же правила и алгоритмы в несколько прикладных программ. Но тогда очень затрудняются их поддержка и обновление — любое изменение кода должно проводиться во всех прикладных программах, которые его используют. Если же бизнес-правила сосредоточены на сервере приложений и используются совместно, то такой проблемы нет.
Мониторы обработки транзакций
Мониторы обработки транзакций (transaction processing monitor, TPM) — самый старый тип технологии распределенных систем, которая появилась в 70-х годах в среде больших универсальных ЭВМ [9-12]. Одной из первых прикладных систем была интерактивная среда поддержки, созданная компанией Atlantic Power and Light для совместного использования прикладных служб и информационных ресурсов в режимах пакетной обработки и с применением среды с разделением времени. TPM (например, IBM CICS) стали главным инструментом построения высоко масштабируемых решений для сетевых прикладных систем. Однако в начале 90-х популярность TPM начала падать; причиной стало появление продуктов категории TPM «Lite» — мониторов обработки транзакций внутри СУБД. Их функциональные возможности были близки к обычным TPM, и с возрастающей тогда популярностью двухзвенной архитектуры они первоначально обеспечили хорошее решение для создания распределенных прикладных систем.
К концу десятилетия ситуация изменилась. Оказалось, что в то время как обычный монитор транзакций может легко поддерживать тысячи пользователей, их производительность становится недопустимо низкой, когда совокупность пользователей превышает 100. Сегодня TPM снова вернулись, но теперь это технология, которая воплощает среднее звено в трехзвенной архитектуре.
Клиенты связываются с мониторами, посылая запросы на транзакции. Так как коммуникации асинхронны, после того, как запрос послан, клиент может выполнять другие задачи. Каждый запрос ставится в очередь, и монитор может обработать его позднее. Поддерживая различные схемы приоритетов, можно определить, в каком порядке запросы принимаются из очереди на обработку. Мониторы постоянно поддерживают установленное число подключений к базам данных, поэтому непосредственного соответствия между клиентами и подключениями к базе данных нет. Вместо этого мониторы мультиплексируют запросы от различных клиентов по одному и тому же подключению — точно так же, как и серверы приложений.
Одно из достоинств процессора транзакций — способность обращаться к гетерогенным источникам данных (реляционные и сетевые базы данных, плоские файлы и т.д.). Поэтому каждый TPM содержит логику доступа к данным, которая выполняет соответствующее преобразование, связанное с различными источниками.
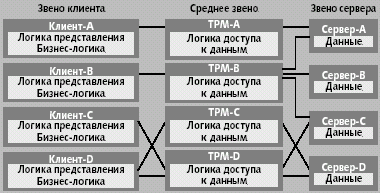
|
| Рис. 8. Трехзвенная архитектура с монитором обработки транзакций |
Самая простая конфигурация — клиент-A взаимодействует только с одним монитором TPM-A (рис. 8), который обеспечивает доступ к данным, расположенным на одном компьютере (Сервер Данных A). При помощи двухфазного протокола фиксации монитор может обеспечивать семантику транзакций и с несколькими базами данных. Таким образом, транзакция одного клиента будет фактически разбита между несколькими базами данных; эта ситуация показана в случае с TPM-B, который взаимодействует с источниками данных на нескольких машинах (Сервер Данных A, Сервер Данных B и Сервер Данных C). В этом случае, если подтранзакция терпит неудачу на одном из серверов, все другие подтранзакции также откатываются назад, а Клиент-B получает сообщение о таком событии.
Отношения между клиентами и мониторами, так же как и между мониторами и источниками данных, фактически являются отношениями «многие-ко-многим». Эта конфигурация часто используется, чтобы обеспечить балансировку нагрузки. Когда число пользователей увеличивается, система может запускать дополнительные экземпляры мониторов, обеспечивающих доступ к одним и тем же источникам данных.
В этой конфигурации мониторы могут также обеспечить инфраструктуру для разработки систем, способных обрабатывать ошибки. Например, как видно из рис. 8, Клиент-C и Клиент-D могут обращаться к одним и тем же источникам данных (Сервер Данных C и Сервер Данных D) либо через TPM-C, либо через TPM-D, причем каждый монитор выполняется на своем собственном компьютере. Если один из мониторов выходит из строя, то все клиенты могут переключаться на все еще работающий монитор. Система в этом случае замедлится, но будет способна обеспечить исходный набор функций.
Сервер сообщений
Вместо монитора транзакций приложение может использовать сервер сообщений. Он обладает большинством существенных преимуществ монитора транзакций. Клиенты взаимодействуют с сервером сообщения асинхронно, помещая в очередь сообщения, которые обрабатываются позднее. В свою очередь, сервер сообщений поддерживает пул доступных подключений к базе данных, которые он может использовать многократно. Но вместо предопределенных запросов, с которыми должен работать монитор, само сообщение содержит достаточно информации относительно того, что нужно с ним делать.
У каждого сообщения есть заголовок и тело. Заголовок определяет, что должно быть сделано с сообщением (скажем, выполнить бизнес-правило или хранимую процедуру, послать его в базу данных или передать его другому серверу сообщений). Последнее позволяет осуществлять коммуникации не только между клиентом и базой данных, но и между клиентами или между клиентом и базами данных, доступными через различные серверы сообщений (рис. 9).
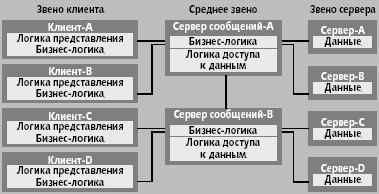
|
| Рис. 9. Трехзвенная архитектура с сервером сообщений |
Используя механизмы передачи с промежуточным хранением, сообщения могут обходить точки отказов по альтернативным маршрутам и дополнительным серверам сообщений. Это похоже на использование нескольких мониторов, обслуживающих одних и тех же клиентов и связанных с одними и теми же источниками данных. Но в отличие от мониторов, сообщение может быть пропущено через несколько серверов сообщений прежде чем оно, наконец, достигнет своего адресата. Более того, «интеллект», который направляет сообщение по дополнительному пути, находится не на клиенте, а на сервере сообщений. Таким образом, отказы могут оставаться полностью скрытыми от клиента.
Большинство серверов сообщений поддерживает несколько протоколов связи и выполняется на различных платформах. В результате прикладная система, построенная с серверами сообщений, может охватывать весьма сложные гетерогенные среды, состоящие из компьютеров разных платформ, различных операционных систем, сетей и протоколов коммуникаций. Ясно, что помимо создания таких переносимых приложений, серверы сообщений играют очень важную роль в интеграции, позволяя совместно использовать сообщения, данные и бизнес-правила.
Брокер объектных запросов
Брокер объектных запросов (object request broker, ORB) обеспечивает инфраструктуру, поддерживающую распределенные объекты, которыми можно управлять как и объектами, расположенными «рядом» с процессом, работающим с ними. По вызову метода (в смысле объектно-ориентированного программирования) на одном компьютере может фактически выполняться некоторый программный код другого, притом что доступ к данным в пределах распределенного объекта может потребовать получения соответствующей информации из удаленной базы данных. Все эти детали остаются скрытыми от прикладной программы [15].
Использование брокера объектных запросов в трехзвенной архитектуре очень похоже на использование сервера сообщений. Единственное различие состоит в том, что взаимодействие осуществляется на объектном уровне, а не на уровне отдельных сообщений. Эта парадигма, объединенная с мощью объектно-ориентированного программирования, делает распределенные объекты очень привлекательной стратегией для разработки распределенных систем.
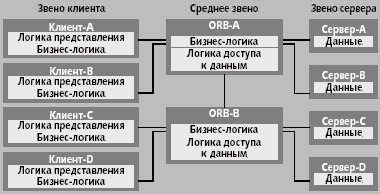
|
| Рис. 10. Трехзвенная архитектура с брокером объектных запросов |
Пример использования двух брокеров объектных запросов показан на рис. 10. Как и в случае сервера сообщения, бизнес-логика разделена между клиентами и ORB. Однако доступ к процедурам, физически расположенным на брокере, остается скрытым от клиентов при помощи распределенных объектов. Через конкретное выполнение распределенных объектов в среднем звене можно мультиплексировать запросы клиентов на одном и том же пуле подключений к базам данных. В качестве источника данных можно использовать объектно-ориентированную СУБД, однако разного рода «упаковщики» могут обеспечивать доступ к другим источникам (базы данных других типов, плоские файлы и т. п.).
Точно так же распределенные объекты могут «упаковывать» другие прикладные программы. Поэтому интеграция приложений может осуществляться не просто на уровне бизнес-правил, но на уровне объектов. Эти два подхода, однако очень похожи. Так как бизнес-правила скрыты в методах объекта, совместное использование объекта подразумевает совместное использование бизнес-правил. Но объект также содержит информацию о состоянии, поэтому он допускает интеграцию и на уровне данных.
Архитектура с пятью звеньями
Нетрудно заметить, что функция среднего звена как части архитектуры клиент-сервер в интегрированной системе должна быть значительно расширена. Во-первых, слой доступа к данным должен управлять не только данными, связанными с «родной» постоянной памятью системы (ее базой данных), но и быть способным обрабатывать информацию из внешних источников, которые представляют данные от других прикладных программ. Кроме того, рассматривая три различных уровня, на которых может проходить интеграция, и соответствующие способы, при помощи которых извлекаются эти данные, можно заключить, что сложность слоя доступа к данным непомерно велика.
Другие факторы, наподобие «упаковки» внешних прикладных программ, могут также требовать разработки локального слоя бизнес-логики. Кроме работы с бизнес-правилами, локальными для текущего приложения, он должен также знать внешние бизнес-правила, которые могут применяться к внешним (и, иногда, к локальным) данным. Вместе с расширенным (продленным) слоем доступа к данным, мы можем теперь получить чересчур «толстое» среднее звено.
Одно из возможных решений состоит в том, чтобы ввести в рассмотрение дополнительные звенья, которые помогли бы ему стать более «тонким». На рис. 11 представлено расширение трехзвенной архитектуры с сервером приложений в среднем звене. Здесь слой доступа к данным управляется звеном Универсального Доступа к данным (universal data access, UDA), показанным как четвертое звено. Он обеспечивает стандартное представление локальных данных, как и данных, постоянно находящихся в удаленных «унаследованных» системах (специализированный механизм доступа к данным унаследованных систем в четвертом звене, иногда называют legacyware — программное обеспечение доступа к унаследованным системам) или в других внешних системах (они доступны через звено бизнес-правил — businessware).
Цель состоит не просто в том, чтобы обеспечить коммуникацию между программами вообще (это задача промежуточного программного обеспечения), а в том, чтобы установить связь между прикладными программами, что включает совместное использование данных и логики. Передача данных при этом осуществляется через звено UDA (связь D), в то время как совместное использование логики реализуется связью между звеном серверов приложений и звеном бизнес-правил (связь P).
Литература
- А. Кононов, Е. Кузнецов, Онтология промежуточного ПО. // Открытые системы, 2002, № 3
- Н. Дубова, Все про промежуточное ПО. // Открытые системы, 1999, № 7-8
- Ф. Бернштейн, Middleware модель сервисов распределенной системы. // Системы управления базами данных, 1997, № 2
- Л. Розенкранц, Промежуточное ПО. // Computerworld Россия, 2000, № 39
- Е. Карташева, Средства интеграции приложений. // Открытые системы, 2000, № 1-2
- G. Schussel, Client-Server Past, Present and Future. http://news.dci.com/geos/dbsejava.htm, 1995
- S. Guengerich, G. Schussel, Rightsizing Information Systems, SAMS Publishing, 1994
- H. Edelstein, Unraveling Client-Server Architecture. DBMS, 1994, № 5: 34 (7)
- David S. Linthcum, Enterprise Application Integration, Addison-Wesley, 2000
- R. Orfali et. al., Client-Server Survival Guide, 3rd edition, Wiley Computer Publishing, 1999
- A. Berson, Client-Server Architecture, New York: McGraw-Hill, 1992
- R. M. Adler, Distributed Coordination Models for Client-Server Computing, Computer, 28, 1995, № 4
- A. Dickman, Two-Tier Versus Three-Tier Apps. Informationweek 553, 13, 1995
- J. Gallaugher, S. Ramanathan, Choosing a Client-Server Architecture. A Comparison of Two-Tier and Three-Tier Systems. Information Systems Management Magazine 13, 1996, 2
- Evans, Lacey, Harvey, Gibbons, Client-Server: A Handbook of Modern Computer Design. Prentice Hall, 1996
- Martin and Leben, Client-Server Databases: Enterprise Computing, Prentice Hall, 1996
Алексей Кононов (aik762@hotmail.com) — независимый консультант. Евгений Кузнецов (eugene.kuznetsov@hotmail.ru) — сотрудник Института проблем управления РАН (Москва).
