
Сегодня все еще используются миллиарды строк, написанных на Коболе, PL/I и других языках программирования. Многие пытались переписать унаследованные программы на более современные языки, но немногим это удавалось. Данная статья проливает свет на некоторые трудности языковых преобразований и разбирает возможности и ограничения автоматизированных языковых конвертеров.
Как правило, стоимость программного обеспечения определяется менеджментом, кадровым составом сотрудников и уровнем организации процесса разработки, а не применяемыми инструментами. Однако и коммерческие разработчики, и академические исследователи придают особое значение именно программным средствам. В результате, многие становятся жертвами шарлатанских продуктов и услуг по модификации программ. Этот эффект иногда обозначают термином «волшебство слова». Достаточно произнести заклинание — «преобразование Кобола в Java», и вас уже охватил экстаз. Для подтверждения ваших притязаний не требуется никаких доказательств: люди, отчаянно нуждающиеся в решениях и так безоговорочно поверят вашим утверждениям [1].
Многие руководители рано или поздно обнаруживают, что они погребены под ворохом устаревших программ, нуждающихся в модификации. В то же время обучение программированию ориентировано исключительно на новые разработки, а не на улучшение существующих, не говоря уже о сопровождении унаследованных приложений. Эта проблема настолько серьезна, что Каперс Джонс упоминает ее как один из 60 главных рисков процесса разработки программного обеспечения [2]. Языковый конвертер помог бы решить ваши проблемы с персоналом: преобразование языков ликвидирует разрыв между знаниями обычного программиста и знаниями, необходимыми для решения проблем унаследованных систем. Но насколько это просто?
Насколько сложны преобразования языков?
В рекламном заявлении одной из компаний, разрабатывающей конвертер из Кобола в Visual Basic, говорилось: «Конвертер работает в режиме простого мастера, и с ним может работать любая секретарша». Более того, на международной конференции по сопровождению программ в докладе, посвященном задачам нового столетия, утверждалось, что автоматизированные преобразования языков давно перестали быть проблемой, а трудности связаны только с преобразованиями, изменяющими парадигму программирования. Это означает не только безболезненный перевод кода из Кобола в Си++, но и его преобразование в объектно-ориентированные программы на Си++, работающие в Сети. Складывается впечатление, что автоматизированные преобразования языков — несложная задача. И действительно, перевод, например, операции присваивания «ADD 1.005 TO A» из Кобола в эквивалентную форму для VB, «A = A + 1.005», не вызывает проблем. Даже очень простой конвертер может справиться с этим.
С другой стороны, преобразование языков — почему-то очень рискованный бизнес. Нам известно несколько случаев, когда провалившиеся проекты по преобразованию языков приводили компании к банкротству. Том Холмс из компании Reasoning утверждает, что если критерием успеха считать получение прибыли, большинство подобных проектов неуспешны. Один из читателей предварительной версии этой статьи сообщил нам, что его компания потратила более 50 млн. долл. на неудачные проекты по преобразованию языков. Роберт Гласс в своей книге о катастрофах программирования упоминает о провале системы, которая должна была транслировать программы из старого в новое окружение. Менеджеры считали, что задача имеет очень ограниченный масштаб, и программистам надо перевести только небольшой набор конструкций исходной системы. Предположение оказалось неверным. Анализ по окончании проекта показал, что конвертер должен быть в 10 раз сложнее, чем показывали исходные оценки. Из-за этого задача, казавшаяся технически возможной, стала экономически и технически невыполнимой [3].
C. Спронг, работавший над переносом программ из Фортрана в Си, высказал в дискуссионной группе alt.folklore.computers следующее мнение: «Низкоуровневый перенос программ, даже при наличии документации, является одной из самых темных разновидностей программистского колдовства; знание о том, как это правильно делать, гарантирует вам прямое попадание в ад».
Итак, мнения о том, насколько трудны языковые преобразования, сильно разнятся. Возможно, автоматическое изменение структуры системы с изменением парадигмы программирования, — например, введение объектно-ориентированных концепций, — теоретически возможно. Однако этот процесс очень трудно автоматизировать, в нем подразумевается активное участие человека [4]. Вместе с тем отдача от таких вложений значительно превышает затраты, особенно для систем с длительным временем жизни. Большинство предлагаемых средств автоматизации ограничивается синтаксическими преобразованиями. Но даже при этом, казалось бы, простом и низкоуровневом подходе, возникает множество трудностей, масштаб которых еще не окончательно осознан.
Несмотря на немногочисленность содержательных публикаций на тему языковых преобразований [5-13], рынок программных продуктов и услуг по переносу приложений переполнен. Многие компании утверждают, что они могут перевести ваши системы на любой язык программирования по вашему усмотрению. В большинстве случаев такие заявления оказываются необоснованными. Например, одна компания, рекламировавшая свои продукты в Internet, приводила в качестве примеров программы, которые даже не компилировались! Другая заявляла, что может конвертировать приложения из PowerBuilder в Java, но в ответ на наши запросы сотрудники этой компании признались, что у них нет ни опыта подобных работ, ни соответствующих средств. Зато, по их утверждениям, им был понятен процесс выполнения данной работы. Следующая цитата из книги Гарри Снида, посвященной преобразованиям программ в объектно-ориентированную форму [12], резюмирует текущее состояние дел на рынке трансформации приложений: «В действительности все обстоит по-другому. Те, кто умеет читать между строк, знают, что проблемы сильно упрощены и рекламируемые продукты далеки от того, чтобы их можно было использовать на практике».
Требования к средствам преобразования языков
Постановка задачи для языковых преобразований очень проста: перевести данную систему на другой язык программирования, оставив неизменным ее внешнее поведение. С абстрактной точки зрения, проект по переносу приложения на новый язык кажется обманчиво простым, поэтому требования к языковым конвертерам очень часто не формулируются явным образом.
Обычно, легкость формулирования проблемы перевода зависит от наличия в целевом языке соответствующих встроенных языковых конструкций. Например, если необходимо выбрать один из вариантов в зависимости от какого-то условия, то язык, поддерживающий условные предложения, будет наиболее удобен. Если же придется использовать язык, в котором конструкция if-then-else отсутствует, ее придется эмулировать. Подобные фрагменты кода будем называть эмулированными языковыми конструкциями. Например, можно эмулировать объекты в языке, не имеющем поддержки объектной ориентации.
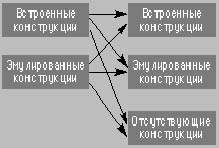 |
| Рис. 1. Отображение языковых конструкций |
Проблема языковых преобразований сводится к отображению встроенных и эмулированных конструкций исходного языка во встроенные (по возможности) конструкции целевого языка. Существует как минимум шесть различных категорий подобного отображения; они продемонстрированы на рис. 1. Мы встречали примеры всех шести типов подобного отображения. К сожалению, спецификации конвертеров обычно упоминают только ту часть отображения, которая касается перевода встроенных конструкций исходного языка во встроенные конструкции целевого. Это связано со стремлением людей вначале концентрироваться на самых легких частях задачи. Один из авторов статьи, Крис Верхуф выступал внешним аудитором нескольких крупных проектов по преобразованию языков. Большинство из них провалилось, так как сложная часть проблемы не была упомянута в требованиях. В одном из этих проектов 80% текста спецификаций было посвящено графическому интерфейсу, а сам языковый конвертер был представлен одной-единственной стрелкой.
Недооценка проблем очень часто ведет к потере управляемости проектов. Первые же трудности ведут к задержке выполнения преобразования, что, в свою очередь, увеличивает давление на команду разработчиков конвертера (возможно, уже новую). В результате, разработчики вообще перестают уделять внимание высказываемым требованиям. После нескольких проходов по этому замкнутому кругу проект полностью разваливается.
Приведем минимальный набор требований, необходимый для разработки конвертера из одного языка программирования в другой.
- Следует составить перечень всех встроенных и эмулированных языковых конструкций, подлежащих преобразованиям.
- Должна быть определена стратегия перевода для каждой языковой конструкции. В частности, следует создать набор фрагментов на исходном и целевом языках, показывающий желаемое поведение конвертера.
- Необходимо явно сформулировать, требуется ли функциональная эквивалентность конвертированной системы исходной. На первый взгляд, это требование выглядит непременным, однако, на практике изощренные автоматизированные системы преобразования зачастую выявляют ошибки и опасные места в исходной системе. Чаще всего, заказчик впоследствии требует исправления и этих проблем, так что возникает опасность незаметного разрастания требований. Кроме того, это вредит тестированию новой системы, поскольку регрессионное тестирование основано на эквивалентности систем.
- Необходимо понять, будут ли конвертироваться тестовые наборы исходной системы. Кроме того, следует сформулировать политику модификации в случае обнаружения ошибок в исходных тестах.
- Необходимо поставить целью достижение максимальной автоматизации процесса перевода.
- Если планируется дальнейшее сопровождение конвертированной системы, при переводе надо учитывать критерии сопровождаемости, а результирующий объем не должен существенно превосходить объем исходного приложения. Например, если сопровождать новую систему будет та же команда программистов, что сопровождает старую, необходимо добиться максимальной схожести текстов целевой системы с текстами исходной; благодаря этому им будет легче находить «знакомые» фрагменты кода. С другой стороны, если планируется передать систему на сопровождение новой группе, то значительно важнее, чтобы конвертированная система использовала стиль целевого языка, тогда программисты будут ориентироваться на знакомые языковые конструкции. Есть и другие ситуации, когда, например, исходные тексты программы используются для ее модификации даже после успешного преобразования (скажем, из Кобола в Java), так как процесс трансляции может быть настолько автоматизирован, что проще заново сгенерировать целевой код, чем пытаться внести изменения непосредственно в него. Такой подход в состоянии помочь и в тех случаях, когда инженеры сопровождения хорошо знакомы с исходным языком, но не знакомы с целевым.
- Необходимо добиваться приемлемой скорости компиляции и выполнения сгенерированных текстов.
- В случаях, когда планируется многократное использование конвертера, важной характеристикой становится время работы. Оптимизация конвертера не всегда тривиальна и иногда требует распределения вычислений по нескольким компьютерам.
Помимо явных требований, существуют еще и подразумеваемые ожидания заказчика, отражающие его представления о том, какие преимущества должны появиться в результате переноса системы в современное окружение. Очень часто именно эти воображаемые преимущества и служат толчком для проекта по трансформации приложения, однако в большинстве случаев эти ожидания не оправдываются. Например, распространено заблуждение, что после преобразования будет проще вносить изменения в систему, а потому появится возможность наделить ее абсолютно новой функциональностью. Проблема усугубляется тем, что большинство компаний, продающих промышленные средства преобразования, не спешат разубеждать потенциальных клиентов в этих ожиданиях. Между тем, качество предлагаемых инструментов чаще всего оставляет желать лучшего, а порою и просто никуда не годится.
Автоматически конвертированные программы обычно существенно хуже, чем разработанные в рамках целевого языка от начала до конца. Понятно, что в идеале результат преобразований должен выглядеть так, как будто он был написан на целевом языке с использованием всех его средств и особенностей, однако реальные результаты конвертации зачастую сохраняют идеологию исходного языка. Многие ожидают, что структура программы после автоматизированных преобразований может только улучшиться, но концептуальные изменения приложений практически всегда связаны с большим объемом ручной работы [5, 13]. Например, вообразите себе перевод программ, работающих на мэйнфрейме и использующих CICS, на Си++ с использованием Microsoft Transaction Server.
Технические проблемы
При переводе программ с одного языка на другой полезно составить набор входных и выходных образцов кода (паттернов), что составляет, собственно говоря, основную сложность языковых преобразований.
Преобразование типов данных
Одна из первых задач — это преобразование типов данных. Мы не всегда осознаем, что практически все языки программирования имеют свой уникальный набор типов данных. Даже в таких похожих языках как Си++ и Java легко найти различия: например, в Си++ есть указатели, а в Java они отсутствуют; в Си++ размеры типов данных варьируются от платформы к платформе, а в Java они зафиксированы, и т.д.
Когда же речь заходит о различиях между такими языками, как Кобол или PL/I, и современными языками, такими как Java, Visual Basic или Си++, то иногда найти эквиваленты попросту невозможно. Действительно, рассмотрим следующий тип данных в PL/I:
DECLARE C FIXED DECIMAL (4, -1);
Переменная С занимает три байта, причем подразумевается, что десятичная точка находится на одну позицию правее, чем само число. Таким образом, С может содержать значения 123450 и 123460, но не 123456 и принимать значения в диапазоне от - 9999910 до 9999910, а у всех присваиваемых С значений будет урезана последняя цифра, так что присваивание С = 123456 будет эквивалентно С = 123450. Так как последняя цифра всегда равна нулю, она вообще нигде не хранится. Очевидно, что ни приведенный тип данных, ни соответствующий ему оператор присваивания не соответствуют никакому стандартному типу данных Си++ и стандартному оператору присваивания (отметим, что в статье [4] данный вопрос не был затронут, так как в отличие от общепринятого стандарта на язык PL/I, типы данных PL/IX в основном совпадают с типами данных языка Cи).
Преобразование Кобола в Visual Basic
При преобразовании Кобола в VB одним из возможных вариантов является перевод только тех типов данных, для которых удается найти эквивалентные в целевом языке. Согласно схеме на рис. 1 это соответствует переводу встроенных конструкций во встроенные. В этом случае конвертер будет игнорировать переменные всех остальных типов и предлагать пользователю переписать те части кода, в которых эти переменные используются. Следующий простой фрагмент на Коболе иллюстрирует проблемы, связанные с таким подходом к преобразованию данных:
DATA DIVISION. 01 A PIC S9V9999 VALUE -1. PROCEDURE DIVISION. ADD 1.005 TO A. DISPLAY A.
Переменная А может содержать такие значения, как -3,1415 и в данном примере она инициализируется значением «-1». В процедурной части кода, мы прибавляем к А число 1.005 и выводим результат на экран. Конвертер может перевести эту простую программу на Коболе в следующий фрагмент на VB:
Dim A As Double A = -1 A = A + 1.005 MsgBox A
В этом фрагменте переменная A объявлена с типом Double, инициализируется и получает значение «-1». Команда ADD из Кобола представлена в VB оператором «+». Однако запуск программы на VB дает иной результат — «+0.0049», что свидетельствует об ошибке округления. Эта небольшая разница возникает из-за того, что программа на Коболе использует тип данных с фиксированной точкой, а фрагмент на VB — с плавающей. Неточность вычислений переменных с плавающей точкой около нуля не является ошибкой и документирована в справочниках по Visual Basic.
В приведенном примере проблему округления можно решить путем использования встроенного типа данных Currency. Но рассмотрим несколько измененный пример:
DATA DIVISION. 01 A PIC S9V99999 VALUE -1. PROCEDURE DIVISION. ADD 1.00005 TO A. DISPLAY A.
Преобразуем его с использованием типа данных Currency:
Dim A As Currency A = -1 A = A + 1.00005 MsgBox A
Программа на Коболе проводит вычисления с большей точностью, чем в предыдущем примере, и выдает ожидаемый результат. Однако программа на VB печатает 0.0001, что в два раза больше, чем во втором примере на Коболе. Дело в том, что тип Currency использует четыре знака после десятичной точки и округляет результаты для меньших значений. Итак, Currency тоже плохо ведет себя в некоторых контекстах.
Таким образом, ни один тип данных VB не соответствует структурам Кобола с фиксированной точкой. Поэтому любая простая стратегия перевода этих типов обречена на провал и даже в примитивных случаях необходим нетривиальный анализ типов данных.
Преобразование Кобола в Java
Любая языковая конструкция, которая может быть неправильно употреблена, будет употреблена неправильно. Так называемые «хитроумные» использования языковых конструкций могут вести к неожиданным различиям во внешнем поведении исходной и конвертированной программ. Возможны проблемы переполнения, приведением типов и прочими сложными манипуляциями с типами данных. Рассмотрим программу на Коболе:
DATA DIVISION. 01 A PIC 99. PROCEDURE DIVISION. MOVE 100 TO A. DISPLAY A.
Во фрагменте объявлена переменная А, которая может содержать двузначные числа. В процедурной части этой переменной присваивается трехзначная константа и затем печатается результат. Конвертер мог бы преобразовать эту программу в следующий код на Java:
public class Test {
public static void main(String
arg[]) {
short A = 100;
System.out.println (A);
}
}Мы объявляем целочисленную переменную типа short, присваиваем ей значение 100 и печатаем результат. Однако результат этот вовсе не тот же самый: программа на Коболе печатает 00, а на Java — 100.
Решение проблем, связанных с неожиданными побочными эффектами типов данных, — это одна из трудностей языковых преобразований. Для борьбы с ними необходим другой подход, который называют эмуляцией типов данных [7]. Для каждого типа данных исходного языка, который не имеет точного эквивалента в целевом языке, создается специальная поддержка, эмулирующая поведение переменных данного типа. Удобно считать, что в целевой язык добавляются некоторые конструкции, так чтобы стрелка из «встроенных конструкций» на рис. 1 стала указывать в «эмулированные конструкции» вместо «отсутствующих конструкций». Например, следующие описания переменных на Коболе
01 A PIC 9V9999. 01 B PIC X(15).
не имеют подходящего эквивалента в Java. Поэтому преобразованные элементы должны иметь следующий синтаксис:
Picture A = new Picture («9V9999»); Picture B = new Picture («X(15)»);
где класс Picture эмулирует все подробности поведения исходного типа данных, включая обработку присваиваний, преобразование в другие типы данных и обработку переполнения. Конечно, теперь конвертированная программа стала очень похожей на Кобол, хотя это все же программа на Java.
Как только мы начинаем эмулировать типы данных, возникает вопрос о композиционности: если использовать эмулированные типы данных во встроенной арифметической конструкции конвертированной программы, то будет ли результат корректным? Если нет, потребуется создать специальную функцию типа Add(Pic, Pic) или специальные методы, корректно реализующие арифметические операции для эмулированных типов данных, например, a.Add(b). В Си++ можно перегрузить операторы +, -, * и =. Однако в этом случае может возникнуть ошибка, если программист, дописывающий полученную программу на Си++, воспользуется неправильным эмулированным и перегруженным оператором + вместо обычного.
Учитывая все перечисленные проблемы, трудно поверить, что конвертированные программы проще в сопровождении или изменении, более современны, модульны или лучше в каком-либо другом аспекте, упоминающемся в качестве причины для языковых преобразований.
Преобразование OS/VS Cobol в VS Cobol II
Итак, преобразование данных из одного языка в другой является достаточно сложной задачей. Не менее простым оказывается и преобразование процедурной части программ. В качестве примера рассмотрим преобразование одного из диалекта стандарта Кобол 74 под названием OS/VS Cobol в современный диалект Кобола 85, VS Cobol II. Многие полагают, что преобразования такого рода — не проблема. Но рассмотрим следующий фрагмент, печатающий слово «IEEE»:
PIC A X(5) RIGHT JUSTIFIED VALUE ?IEEE?. DISPLAY A.
Данный синтаксис допустим в обоих диалектах, поэтому кажется, что нет никакой нужды в преобразованиях. Однако в данном случае одинаковый синтаксис имеет разное поведение. Например, после компиляции с помощью OS/VS Cobol программа напечатает ожидаемый результат — строку ? IEEE? с выравниванием по правому краю, но использование Cobol/370 даст строку ?IEEE ? с выравниванием по левому краю. Аналогичные примеры можно найти в [14-17]. Мы называем это проблемой омонимов.
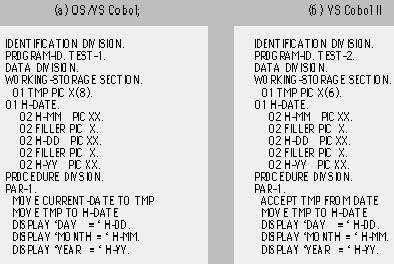 |
| Рис. 2. Две похожие программы: |
В другом примере данную проблему не так просто обнаружить (см. рис. 2а). По существу, программа на OS/VS Cobol определяет переменную TMP, рассчитанную на хранение восьми позиций, и затем переменную H-DATE для работы с датами, такими как 13/01/99. В процедурной части значение специального регистра CURRENT-DATE присваивается переменной TMP. Программа записывает это значение в специальную переменную и затем печатает день, месяц и год. Чтобы преобразовать эту программу в новый диалект Кобола, необходимо заменить использование специального регистра CURRENT-DATE на системный вызов DATE, который возвращает значение YYMMDD, не совпадающее с типом DD/MM/YY, используемым CURRENT-DATE. В руководстве по миграции программ на Коболе [18], написанном специалистами IBM, предлагается изменить тип переменной TMP из PIC X(8) в X(6) и преобразовать MOVE CURRENT-DATE в оператор ACCEPT. Это приводит нас к программе на VS Cobol II (рис. 2б).
Однако в данном контексте такое решение, поскольку при выполнении оператора MOVE неявно предполагается, что тип переменной TMP совпадает с типом переменной H-DATE. Но это предположение не выполняется, и потому результат работы программы ошибочен. Выполнение конвертированной программы 15 сентября 1999 года дало следующие результаты:
DAY = 91 MONTH = 99 YEAR =
Программа присвоила строку «990915» структурной переменной H-DATE: в поле H-MM попали первые две цифры — «99», а в FILLER попал следующий за этим «0». Полю H-DD достались следующие две цифры — «91», а еще один FILLER забирает последнюю пятерку. Поэтому H-YY не получает ничего, и результат оказывается плачевным.
Как исправить данную ошибку? Одним из вариантов решения является преобразование типа переменной H-DATE и всего кода, использующего данную переменную. Эти изменения могут затронуть всю программу (а возможно, и другие: переменная может использоваться в базе данных или передаваться в качестве параметра в другую программу). Таким образом, преобразование процедурного кода тесно связано с преобразованием типов данных, используемых в процедурном коде. Если воспользоваться решением, предложенным в руководстве IBM, нам придется модифицировать всю систему в целом. Тотальных изменений можно избежать благодаря эмуляции типов данных, как в следующем примере:
IDENTIFICATION DIVISION.
PROGRAM-ID. TEST-3.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 F-DATE.
02 F-YY PIC XX.
02 F-MM PIC XX.
02 F-DD PIC XX.
01 TMP PIC X(8).
01 H-DATE.
02 H-MM PIC XX.
02 FILLER PIC X.
02 H-DD PIC XX.
02 FILLER PIC X.
02 H-YY PIC XX.
PROCEDURE DIVISION.
PAR-1.
ACCEPT F-DATE FROM DATE
STRING F-MM ?/? F-DD ?/? F-YY
DELIMITED SIZE INTO TMP
END-STRING.
MOVE TMP TO H-DATE
DISPLAY ?DAY = ? H-DD.
DISPLAY ?MONTH = ? H-MM.
DISPLAY ?YEAR = ? H-YY.Вначале мы определяем новую переменную F-DATE с тем же типом, что и новый системный вызов DATE в процедурной части кода. Сохраняем результат системного вызова в этой переменной, а затем эмулируем старый специальный регистр путем записи в него значения в соответствующем формате. После этого весь код, использующий старый формат даты, работает, как если бы он по-прежнему использовал специальный регистр. Глобальное изменение программы предотвращено, а решение можно полностью автоматизировать, хотя результат и не столь красив, как хотелось бы. (В новых версиях руководства IBM эта ошибка исправлена.)
Из Turbo Pascal в Java
Еще один пример основан на преобразовании следующей программы на язык Java.
Program StringTest;
var s: string;
a: integer;
begin
s := ?abc?;
a := pos (?d?, s);
writeln (a);
s [pos (?a?, s)] := ?d?;
writeln (s);
end;Вначале строковой переменной присваивается значение abc, затем переменной «a» — значение, равное позиции первого появления буквы «d» в строке «s». Поскольку эта буква ни разу не встречается, переменная «a» получает значение «0». Результат выдается на экран. Затем ищется первое вхождение буквы «a» в строке «abc», заменяется на «d», а полученная строка выдается на экран. Итак, программа печатает «0» и «dbc». Следующая программа на Java могла бы стать результатом работы «наивного» автоматического конвертера:
public class StringTest {
public static void main (String
args[]) {
StringBuffer s = new StringBuffer
(«abc»);
int a;
a = s.toString().indexOf(?d?);
System.out.println (a);
s.setCharAt (s.toString().indexOf
(?a?), ?d?);
System.out.println (s);
}
}В ней объявляется переменная «s» со значением «abc», а переменной «a» присваивается значение, равное позиции первого вхождения буквы «d» в строке «s». Однако согласно соглашениям, принятым в Java, в тех случаях, когда подстрока не найдена, возвращается значение «-1». Итак, семантика первой части программы при переводе изменилась. К счастью, вторая часть переведена правильно. Поэтому, учтя изменение возвращаемого значения, переписываем вручную конечную программу следующим образом:
public class StringTest {
public static void main (String
args[]) {
StringBuffer s = new StringBuffer
(«abc»);
int a;
a = s.toString().indexOf(?d?) + 1;
System.out.println (a);
s.setCharAt (s.toString().indexOf
(?a?) + 1, ?d?);
System.out.println (s);
}
}Для решения проблемы с кодом возврата прибавляем единицу, эмулируя поведение программы на Turbo Pascal. Теперь переменная «a» получает правильное значение. Однако это ведет к тому, что вторая часть программы становится некорректной; вместо «dbc» печатается «adc». Данный эффект возникает из-за другого побочного эффекта: элементы массивов в Java нумеруются с нуля, а не с единицы, как в Turbo Pascal. Если учесть и этот факт, получим следующий код:
public class StringTest {
public static void main (String
args[]) {
StringBuffer s = new StringBuffer
(«abc»);
int a;
a = s.toString().indexOf(?d?) + 1;
System.out.println (a);
s.setCharAt ((s.toString().
indexOf(?a?)
+ 1) — 1, ?d?);
System.out.println (s);
}
}Мы добавили единицу к результату работы функции indexOf, чтобы скомпенсировать разницу в значениях кода возврата. При использовании массивов в Java, 1 из индекса массива вычитается, чтобы скорректировать разницу с Turbo Pascal. На этапе реструктуризации конвертированного кода проведение константных вычислений преобразуют выражение
s.setCharAt ((s.toString().indexOf (?a?) + 1) — 1, ?d?);
в следующее
s.setCharAt (s.toString().indexOf (?a?), ?d?);
Вот почему первая попытка преобразования давала правильный результат во второй части программы: по чистой случайности две ошибки наложились, взаимоуничтожив друг друга. Скотт Адамс описал этот эффект в своей книге «Принцип Дилберта» так: «Две ошибки дают правильный ответ — почти» (Two wrongs make a right, almost).
Обсуждение
Приведенные примеры показывают, что сложность преобразования языков существенно недооценивается, в том числе и известными специалистами [19]. С проблемами можно столкнуться даже в тех случаях, если ограничиться преобразованиями между двумя диалектами языка от одного производителя. Похоже, даже в IBM недооценили сложность преобразования собственных диалектов.
Приведенные примеры со всей очевидностью демонстрируют, что автоматизированное преобразование языков значительно труднее, чем принято полагать. Возможно, недооценка сложности проблемы связана с тем, что синтаксис преобразованной арифметики внешне выглядит обманчиво похожим на оригинал. В примерах наподобие «ADD 1.005 TO A» и «A = A + 1.005», нас подводит наше собственное восприятие арифметических действий. Функции вывода на экран в Коболе (DISPLAY), VB (MsgBox) и Си (printf) тоже относительно похожи, но их семантика расходится с интуитивными ожиданиями. Наконец, если ограничиться преобразованием диалектов, проблема становится даже сложнее: несмотря на то, что программы могут успешно компилироваться, семантика одного и того же синтаксиса может меняться от компилятора к компилятору. Как следствие, семантика конвертированного кода обычно отличается от исходной, если только не предпринять специальных усилий.
Рассмотренные примеры также иллюстрируют опасности, поджидающие при отображении типов данных одного языка на похожие типы данных другого языка (рис. 1, стрелка из «Встроенные конструкции» в «Отсутствующие конструкции»). Использование встроенных или эмулированных типов данных зависит от требований к результатам преобразований. Встроенные типы данных не всегда гарантируют корректность кода, но и с эмулированными типами связан ряд проблем. Применение встроенных типов данных целевого языка может упростить сопровождение (в связи с уменьшением объема чужеродного кода), но одновременно уменьшает уровень автоматизации или влияет на семантическую корректность результата. Использование эмулированных типов ведет к большей автоматизации и более корректным программам, но требует дополнительных работ по написанию библиотек динамической поддержки, увеличивает затраты на сопровождение и снижает производительность целевой системы.
В принципе, обе методики могут использоваться одновременно. Например, можно вначале проанализировать, безопасна ли исходная программа с точки зрения типов (т.е. в ней отсутствуют проблемы, подобные перечисленным). Если это требование выполняется, можно воспользоваться встроенными типами целевого языка, а в проблематичных случаях — применить эмуляцию типов данных.
Далее, проблема омонимов вскрывает распространенное заблуждение о том, что синтаксическая схожесть различных языков является признаком уровня сложности проектов по переводу: чем более похожи языки, тем проще преобразование между ними. На самом деле, данная мера сложности только запутывает, поскольку чем ближе языки программирования, тем сложнее обнаружить различия между ними. Помимо всех обычных проблем с языковыми преобразованиями, дополнительно приходится иметь дело с семантическими различиями, которые нет возможности обнаружить синтаксически.
Любой менеджер проекта, подумывающий о преобразованиях языков как о средстве решения своих проблем, должен понимать, что вместо проблем, которые хотелось бы решить с помощью преобразований, появятся иные, возможно, менее очевидные проблемы. При этом чем больше объем кода, подлежащего переводу, тем больше потребность в автоматизации, что, в свою очередь, ведет к увеличению объема чужеродного кода. При некотором везении, единственным проявлением объектной ориентации в результате большого проекта по преобразованию станет наследование тех проблем сопровождения, которые у вас уже были.
Процесс преобразования языков
Преобразование приложений из одного языка программирования в другой обычно предпринимается для упрощения сопровождения. Следовательно, тексты сгенерированных программ должны быть хорошо структурированы, содержать минимум глобальных данных и т.п. Увы, очень немногие исходные программы удовлетворяют подобным требованиям, и потому любое осмысленное преобразование языков должно начинаться с всесторонней реструктуризации, — несмотря на все проблемы, возникающие при использовании классических средств реструктуризации [9].
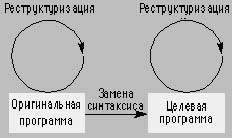 |
| Рис. 3. Процесс языковых преобразований |
Некоторые шаги при преобразовании языков следует считать обязательными. Рассмотрим пример, основанный на работе, выполненной для одного швейцарского банка [11]. На рис. 3 изображена схема процесса преобразования, которой мы пользовались.
Реструктуризация исходного приложения выполняется с целью уменьшения числа проблематичных преобразований (рис. 1). Например, программы на Коболе не обязаны содержать main, в отличие от программ на Си, поэтому при конвертации из Кобола в Си, в процессе реструктуризации исходных программ надо создать искусственный параграф main. Процедуры в Коболе не используются, но широко распространены в других языках. Извлечь процедуры из исходных текстов достаточно трудно, особенно в случае слабо структурированных программ. Например, во время преобразования из Кобола в Аду [4], обилие операторов GO TO в исходном тексте (один оператор на 225 строк) весьма затруднило идентификацию процедур.
В подавляющем большинстве преобразований реструктуризация является обязательным предварительным этапом для того, что мы называем заменой синтаксиса. На этом шаге синтаксис специально подготовленного и реструктуризированного исходного текста заменяется на целевой синтаксис. Это относительно несложный шаг. Преобразованные программы обычно выглядят уродливо, поэтому необходима еще одна реструктуризация (теперь уже в терминах целевого текста), чтобы максимально приблизить полученный код к целевому языку. В качестве иллюстрации рассмотрим небольшую программу из реального приложения, использовавшегося в банке и преобразуем ее из Кобола в Си. (Мы адаптировали исходную программу и превратили ее в задачу о путешествиях, чтобы упростить отслеживание ее логики.) Качество программы именно такое, какого следует ожидать от унаследованного приложения: один GO TO на каждые четыре строки (рис. 4а, сильно реструктуризированный вариант на Коболе — рис. 4б [11]).
 |
| Рис. 4. Пример программы на Коболе: |
Обе программы печатают на выходе следующие строки:
S.E.I. Univ. of Waterloo Univ. of Victoria WCRE & ASE
Программа описывает поездку, начинающуюся в Амстердаме в определенный день. Согласно программе, мы отправимся через Атланту в Питтсбург, чтобы поработать в Институте разработки программного обеспечения, затем через некоторое время путешествуем из Питтсбурга в университет Ватерлоо через Торонто, далее летим в университет Виктории через Торонто и Ванкувер, затем в Гонолулу через Ванкувер, чтобы посетить две конференции, а через некоторое время летим в Амстердам через Нью-Йорк. Обратите внимание на неиспользуемый код: мы не летим через Детройт. Такие призрачные пункты назначения иногда возникают в сложных поездках просто потому, что билет в обе стороны порою бывает дешевле билета в одну сторону. Неявный код, представленный в данной программе стыковочными рейсами, и неиспользуемый код («призрачные пункты назначения») весьма характерны для устаревших систем. Кроме того, характерно массовое использование операторов безусловного перехода, ухудшающих качество исходной программы. Легко убедиться, что у реструктурированной программы та же семантика, что и у исходной. Однако неиспользуемый и неявный код, а также операторы GO TO исчезли, появилась секция «кандидатов в процедуры» и т.д. Таким образом, значительная работа по приближению исходного Кобола к целевому языку Си уже проделана. Теперь мы готовы к замене синтаксиса. Нетрудно видеть, что это не самая сложная часть преобразований:
#include
long D = 980912;
int X = 1 ;
void PITTSBURGH ( ) {
printf(«S.E.I.
»);
D += 14;
}
void VICTORIA ( ) {
printf(«Univ. of Victoria
»);
D += 4; X = 1;
}
void WATERLOO ( ) {
printf(«Univ. of Waterloo
»);
D += 6; X = 0;
}
void TORONTO ( ) {
while ( X == 1 ) {
WATERLOO ( );
};
while ( X == 0 ) {
VICTORIA ( );
};
printf(«WCRE & ASE
»);
D += 14;
}
void main ( ) {
while ( D == 980912 ) {
PITTSBURGH ( ); TORONTO ( );
};
exit ( );
}Полученный код нуждается в дальнейшей реструктуризации. Во-первых, исходный диалект Кобола не имел встроенной поддержки функций, которая есть в Си, поэтому похожие участки целевого кода можно свернуть в функции с параметрами. Во-вторых, необходимо сделать глобальные переменные локальными в тех или иных процедурах. Наконец, имеет смысл переписать неявный код, т.е. вызовы функций, состоящих только из вызова другой функции. Выполнение всех этих типичных шагов по реструктуризации приложений на Си дает следующую программу:
;#include
void f(long dD, int newX,long
*D,int *X, char *s) {
printf(s); *D += dD; *X = newX;}
void TORONTO (long *D, int *X ) {
while ( *X == 1 ) {
f(6,0,D,X,»Univ. of
Waterloo
»); };
while ( *X == 0 ) {
f(4,1,D,X,»Univ. of
Victoria
»);};
f(14,*X,D,X,»WCRE & ASE
»);}
void main ( ) {
long D = 980912; int X =1;
while ( D == 980912 ) {
f(14,X,&D,&X,»S.E.I.
»);
TORONTO (&D,&X ); };
exit ( ) ;
}Итак, получился некий код на Си, но даже это не означает, что выполнение языковых преобразований сводится к наличию соответствующих инструментов. Дело в том, что приведенный пример не дотягивает до реальной программы: в нем нет ввода данных, вывод тривиален, типы данных элементарны и потому потенциально опасные преобразования отсутствуют, внешнее поведение программы тривиально, программа имеет небольшие размеры, процедуры печати очень просты и т.д. Этот пример лишь иллюстрирует процесс преобразования языков. Серьезные технологии трансформации (например, систолические алгоритмы структуризации [11]) еще только зарождаются. Одной из основных задач подобных технологий должны быть разделение операторов управления и конкретных вычислений с целью выявления процедур.
Обобщить трудности преобразований языков и диалектов можно в пяти простых правилах.
- Преобразования обычно сложны.
- Преобразования всегда сложнее, чем вы думаете.
- Чем больше требуемая степень семантической эквивалентности, тем невозможнее достижение результата.
- Переход от богатого выразительными средствами языка к простому невозможен.
- Несложное преобразование — это оксюморон, сочетание несочетаемых слов.
Надеемся, что люди станут лучше понимать все сложности языковых преобразований, а менеджеры проектов несколько умерят свои требования к качеству и семантической эквивалентности конвертированного кода. Мы также надеемся, что разработчики воспользуются нашими примерами в качестве противоядия шарлатанским обещаниям продавцов инструментов языковых преобразований.
Для того чтобы автоматизированные средства начали давать удовлетворительные результаты на реальных приложениях, необходимо еще очень много работы. На данном этапе преобразовать один язык программирования в другой не проще, чем превратить сосиску в свинью.
Авторы выражают признательность Алексу Селлинку (Quack.com), а также Эдмунду Арранга (Object-Z Systems), Эгги ван Бьютен (ASB), Бобу Диртенсу (Университет Амстредама), Хайко де Йонгу и Юргену Винджу (CWI), Тиму Бикмуру (МТИ), Роберту Филману (НАСА), Тому Холмсу и Джасперу Камперману (Reasoning), Карлу Геру (Edge Information Group), Костасу Контогианису (Университет Ватерлоо), Стиву Макконеллу (Construx Software), Борису Казанскому и Михаилу Попову («ЛАНИТ-Терком»), Карине Тереховой (Оксфордский университет), Gert Veltink (RogueWave Software).
Литература
[1] T. DeMarco and T. Lister, Peopleware-Productive Projects and Teams, Dorset House, New York, 1987, p. 30
[2] C. Jones, Assessment and Control of Software Risks, Prentice Hall, Englewood Cliffs, N.J., 1994
[3] R.L. Glass, Computing Calamities-Lessons Learned from Products, Projects, and Companies That Failed, Prentice Hall, Englewood Cliffs, N.J., 1999, pp. 190-191
[4] K. Kontogiannis et al., «Code Migration through Transformations: An Experience Report», Proc. IBM Center for Advanced Studies Conf. (CASCON ?98), IBM, Armonk, NY, 1998, pp. 1-12
[5] R. Gray, T. Bickmore, and S. Williams, «Reengineering Cobol Systems to Ada», Proc. Seventh Annual Air Force/Army/Navy Software Technology Conf., US Dept. of Defense, Hill Air Force Base, 1995
[6] W. Polak, L.D. Nelson, and T.W. Bickmore, «Reengineering IMS Databases to Relational Systems,» Proc. Seventh Annual Air Force/Army/Navy Software Technology Conf., US Dept. of Defense, Hill Air Force Base, 1995
[7] K. Yasumatsu and N. Doi, «SPiCE: A System for Translating Smalltalk Programs Into a C Environment,» IEEE Trans. Software Eng., Vol. 21, No. 11, 1995, pp. 902-912
[8] R.C. Waters, «Program Translation via Abstraction and Reimplementation», IEEE Trans. Software Eng., Vol. 14, No. 8, 1988, pp. 1207-1228
[9] F.W. Calliss, «Problems with Automatic Restructurer», ACM SIGPLAN Notices, Vol. 23, No. 3, Mar. 1988, pp. 13-23
[10] J.C. Miller and B.M. Strauss, «Implications of Automated Restructuring of COBOL», ACM SIGPLAN Notices, Vol. 22, No. 6, June 1987, pp. 76-82
[11] M.P.A. Sellink, H.M. Sneed, and C. Verhoef, «Restructuring of COBOL/CICS Legacy Systems», Proc. Third European Conf. Maintenance and Reengineering, IEEE Computer Soc. Press, Los Alamitos, Calif., 1999, pp. 72-82
[12] H.M. Sneed, Objektorientierte Softwaremigration [Object-Oriented Software Migration], Addison Wesley Longman, Bonn, Germany, 1998
[13] I. Jacobson and F. Lindstrom, «Re-engineering of Old Systems to an Object-Oriented Architecture», Proc. Conf. Object-Oriented Programming Systems, Languages, and Applications (OOPSLA ?91), ACM, New York, 1991, pp. 340-350
[14] W.M. Klein, OldBOL to NewBOL: A COBOL Migration Tutorial for IBM, Merant Publishing, 1998
[15] Y. Chae and S. Rogers, Successful COBOL Upgrades: Highlights and Programming Techniques, John Wiley and Sons, New York, 1999
[16] R. Widmer, COBOL Migration Planning, Edge Information Group, 1998.
[17] M.G.J. van den Brand, M.P.A. Sellink, and C. Verhoef, «Generation of Components for Software Renovation Factories from Context-Free Grammars», Science of Computer Programming, Vol. 36, No. 2-3, Mar. 2000, pp. 209-266
[18] COBOL/370 Migration Guide, release 1, IBM Corp., Armonk, N.Y., 1992
[19] C. Cerf and V. Navasky, The Experts Speak — The Definitive Compendium of Authoritative Misinformation, Villard Books, New York, 1998
Андрей Терехов (ddt@tepkom.ru) — аспирант Санкт-Петербургского государственного университета, менеджер проекта компании «ЛАНИТ-Терком». В сферу его интересов входят технологии компиляции, преобразование ПО и криптография. Крис Верхуф (x@cs.vu.nl) — профессор Свободного университета Амстердама, сотрудник Института разработки программного обеспечения и Университета Карнеги-Меллон, член исполнительного комитета технического комитета по программированию IEEE CS. Область его интересов составляют разработка и сопровождение программ, преобразование, программная архитектура и теоретические основы программирования.
