
- 8.1. Конфигурация памяти NUMA-Q
- 8.2. Кэш-когерентность в NUMA-Q
- 8.3. Нужно ли оптимизировать программы для NUMA-Q?
- 8.4. Задержки доступа к памяти в системе NUMA-Q
- 8.5. Пропускная способность шины IQ-Link
В течение второй половины прошедшего года в области архитектур для высокопроизводительных многопроцессорных систем многое изменилось. Сразу несколько компаний (Hewlett-Packard/Convex, Pyramid Technology, Sun и Silicon Graphics) выпустили платформы с принципиально новой архитектурой CC-NUMA. Отличительная черта этого класса архитектур - поддержка неоднородного доступа к памяти - NUMA (Non-Uniform Memory Access). В данный класс можно также включить хорошо известные кластерные системы, архитектуры с массовым параллелизмом (MPP) и их современные модификации RMC (Reflective Memory Clusters), COMA (Cache-Only Memory Architecture). Среди разработок архитектура CC-NUMA выделяется принципиально. Это архитектура симметричного мультипроцессирования (SMP), обладающая множеством достоинств: простая модель программирования, переносимость приложений и т. д. У истоков создания архитектуры CC-NUMA стояла компания Sequent, реализовавшая собственную версию - NUMA-Q. В данной статье приводятся некоторые детали реализации NUMA-Q и данные о рабочих характеристиках конкретных компьютерных систем, построенных на базе этой архитектуры. По мнению аналитиков, данная архитектура позволяет на порядок повысить производительность вычислений и увеличить возможности масштабирования всех ресурсов.
Проще всего понять цели и мотивы разработки архитектуры NUMA-Q, рассмотрев их в контексте традиционных подходов к организации многопроцессорных систем.
1. Симметричная многопроцессорная архитектура
Ключевым понятием многопроцессорных архитектур является узел - вычислительная система, состоящая из одного или нескольких процессоров, имеющая оперативную память и систему ввода-вывода. Узел характеризуется тем, что на нем работает единственная копия операционной системы (ОС).
Симметричный многопроцессорный (SMP) узел содержит два или более одинаковых процессора, используемых равноправно. Все процессоры имеют одинаковый доступ к вычислительным ресурсам узла. Поскольку процессоры одновременно работают с данными, хранящимися в единой памяти узла, в SMP-архитектурах обязательно должен быть механизм, поддержки когерентности данных. Когерентность данных означает, что в любой момент времени для каждого элемента данных во всей памяти узла существует только одно его значение несмотря на то, что одновременно могут существовать несколько копий элемента данных, расположенных в разных видах памяти и обрабатываемых разными процессорами. Механизм когерентности должен следить за тем, чтобы операции с одним и тем же элементом данных выполнялись на разных процессорах последовательно, удаляя, в частности, устаревшие копии. В современных SMP-архитектурах когерентность реализуется аппаратными средствами.
Механизм когерентности является критичным для эффективной параллельной работы узла SMP и должен иметь малое время задержки. До сегодняшнего дня самые крупные SMP-системы содержали максимум 32 процессора на узел, что объяснялось требованием малых задержек когерентных связей, приводящим к архитектуре с одной объединительной платой, а это физически ограничивает возможное число подсоединенных процессоров и плат памяти. Поэтому для дальнейшего увеличения числа процессоров в узле приходится вместо аппаратно реализованной техники когерентности применять более медленную программную реализацию, что очень существенно сказывается на программируемости систем и их производительности.
SMP-узлы очень удобны для разработчиков приложений: операционная система почти автоматически масштабирует приложения, давая им возможность использовать наращиваемые ресурсы. Само приложение не должно меняться при добавлении процессоров и не обязано следить за тем, на каких ЦПУ оно работает. Временная задержка доступа от любого ЦПУ до всех частей памяти и системы ввода-вывода одна и та же. Разработчик оперирует с однородным адресным пространством. Все это приводит к тому, что SMP-архитектуры разных производителей выглядят в основном одинаково: упрощается переносимость программного обеспечения между SMP-системами. Переносимость программ - одно из основных достоинств SMP-платформ.
Типичные SMP-архитектуры в качестве аппаратной реализации механизма поддержки когерентности используют шину слежения (snoopy bus). Каждый процессор имеет свой собственный локальный кэш, где он хранит копию небольшой части основной памяти, доступ к которой наиболее вероятен. Для того чтобы все кэши оставались когерентными, каждый процессор "подглядывает" за шиной, осуществляя поиск тех операций считывания и записи между другими процессорами и основной памятью, которые влияют на содержимое их собственных кэшей. Если процессор "В" запрашивает ту часть памяти, которая обрабатывается процессором "А", то процессор "А" перехватывает этот запрос и помещает свои значения области памяти на шину, где "В" их считывает. Когда процессор "А" записывает измененное значение обратно из своего кэша в память, то все другие процессоры видят, как эта запись проходит по шине и удаляют устаревшие значения из своих кэшей.
Существует несколько вариантов SMP-узла с одной и несколькими системными шинами, однако последний вариант приводит к усложнению архитектуры и повышению ее стоимости. Одним из примеров может служить структура, реализованная компанией NCR, - две шины и общая разделяемая ими память. Когерентность в такой структуре реализуется путем хранения записей о состоянии и местонахождении каждого блока данных из оперативной памяти. Такой тип работы с кэш-памятью называется кэшированием на основе каталога и обладает тем достоинством, что удваивает пропускную способность шины. Недостатками такого подхода являются необходимость более сложных аппаратных средств и дополнительные задержки при пересылке данных между памятью и обеими шинами.
В архитектуре Cray SuperServer 6400 SMP используются четыре шины. Все ЦПУ подсоединяются к каждой из четырех шин и реализуют протокол следящей шины для поддержки когерентности. Каждое ЦПУ отслеживает только те операции, которые влияют на содержимое своего кэша. Этот подход отличается от протоколов кэширования на основе каталога, так как здесь каталога нет. В системе Cray 6400 пропускная способность шины потенциально увеличивается в 4 раза, однако очевидным недостатком является то, что на каждом ЦПУ устанавливается четыре экземпляра аппаратных средств поддержки когерентности.
Новая система Sun Ultra Enterprise 6000 для подсоединения всех ЦПУ, памяти и систем ввода-вывода использует коммутатор, который заменяет традиционную объединительную плату, но по существу выполняет ту же функцию. Соответственно, сохраняются те же недостатки, поскольку весь трафик между памятью, ЦПУ и системой ввода-вывода должен проходить через коммутатор. Система имеет только 16 слотов для плат ЦПУ/память и ввода-вывода. Хотя такой новый коммутатор несколько увеличивает пропускную способность шины, проблема "большой шины" остается: требование малых задержек ограничивает в этих архитектурах число присоединенных ЦПУ, а увеличение скорости в шинах или коммутаторах не соответствует росту производительности ЦПУ.
2. Массовый параллелизм (МРР)
Узлы в архитектуре MPP обычно состоят из одного ЦПУ, небольшой памяти и нескольких устройств ввода-вывода. В каждом узле работает своя копия OC, а узлы объединяются между собой специализированным соединением. Взаимосвязи между узлами (и между копиями ОС, принадлежащими каждому узлу) не требуют аппаратно поддерживаемой когерентности, так как каждый узел имеет собственную ОС и, следовательно, свое уникальное адресное пространство физической памяти. Когерентность реализуется программными средствами, с использованием техники передачи сообщений.
Задержки, которые присущи программной поддержке когерентности на основе сообщений, обычно в сотни и тысячи раз больше, чем те, которые получаются в системах с аппаратными средствами. С другой стороны, их реализация значительно менее дорогая. В некотором смысле в МРР-узлах задержкой приходится жертвовать, чтобы подсоединить большее число процессоров - сотни и даже тысячи узлов.
Известно, что производительность МРР-систем весьма чувствительна к задержкам, определяемым программной реализацией протоколов и аппаратной реализацией среды передачи сообщений (будь то коммутатор, или сеть). Вообще говоря, настройка производительности МРР-систем включает распределение данных для того, чтобы минимизировать трафик между узлами. Приложения, которые имеют естественное разбиение данных, хорошо работают на больших МРР-системах - такие, например, как видео-по-запросу (video-on-demand). На рисунке 1 приведена структура МРР-системы из четырех узлов.
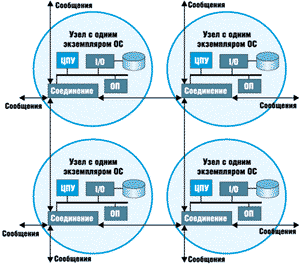
Рисунок 1.
МРР система с четырьмя узлами.
Современное направление развития МРР-систем заключается в увеличении мощности узла путем подсоединения дополнительных процессоров и, по существу, превращения его в SMP-узел. Именно это делают компании NCR, предлагая соединение Bynet, и Tandem с ServerNet. Компания Pyramid также реализовала собственное соединение - Meshine, которое может использоваться для объединения как SMP-платформ, так и однопроцессорных узлов.
МРР-архитектуры привлекательны в первую очередь для разработчиков аппаратных средств, так как в этом случае возникает меньше проблем и ниже стоимость аппаратуры. Из-за того, что нет аппаратной поддержки ни для разделенной памяти, ни для когерентности кэшей, подсоединить большое число процессоров очень просто. Такие системы обеспечивают высокий уровень производительности для приложений с большой интенсивностью вычислений, со статистически разделяемыми данными и с минимальным обменом данными между узлами. Для большинства коммерческих приложений МРР-системы подходят плохо из-за того, что структура базы данных меняется со временем и слишком велики затраты на перераспределение данных.
Ключевым различием между одиночным SMP-узлом и МРР-системой является то, что внутри SMP-узла когерентность данных поддерживается исключительно аппаратными средствами. Это действительно быстро, но и дорого. В МРР-системе с таким же числом процессоров когерентность между узлами реализуется программными средствами. Поэтому происходит это более медленно, однако и цена значительно ниже.
3. Кластер
Кластер состоит из двух или более узлов, удовлетворяющих следующим требованиям:
- каждый узел работает со своей копией ОС;
- каждый узел работает со своей копией приложения;
- узлы делят общий пул других ресурсов, таких как накопители на дисках и, возможно, накопители на лентах.
В отличие от кластеров, в МРР-системах узлы не делят ресурсы для хранения. Это главное отличие между кластерными SMP-системами и традиционными МРР-системами.
Важно отметить, что в кластере отдельные экземпляры приложения должны быть осведомлены о работе друг друга: они должны выполнять блокировку доступа к данным, чтобы поддерживать когерентность внутри базы данных. Механизм блокировок делает кластеры более трудными для управления и масштабирования, чем узел SMP. Однако кластеры имеют и некоторые достоинства: высокую доступность приложений и очень большую производительность.
Добиться дополнительного повышения производительности в кластере тяжелее, чем произвести масштабирование внутри узла. Основным барьером является трудность организации эффективных межузловых связей. Коммуникации, которые происходят между узлами, должны быть устойчивы к большим задержкам программно поддерживаемой когерентности. Приложения с большим количеством взаимодействующих процессов работают лучше на основе SMP-узлов, в которых коммуникационные связи более быстрые. В кластерах, как и в МРР системах, масштабирование приложений более эффективно при уменьшении объема коммуникаций между процессами, работающими в разных узлах. Это обычно достигается путем разбиения данных. Именно такой подход используется в наиболее известном приложении на основе кластеров - OPS (Oracle Parallel Server).
4. Кластер с отражением памяти
Данный кластер (Reflective Memory Cluster-RMC) - это система с тиражированием памяти или механизмом копирования данных между узлами, взаимодействие узлов в которой реализуется методом блокировки (рисунок 2). Копирование памяти осуществляется с помощью программно реализованной техники когерентности. RMC-системы обеспечивают более быструю передачу сообщений приложениям и освобождают узлы от необходимости обращения к диску для получения одних и тех же страниц памяти. В системе RMC получение данных из памяти других узлов в сотни раз быстрее, чем обращение за ними к диску. Реальное повышение производительности будет иметь место только в том случае, когда узлы действительно разделяют данные, и приложение может этим воспользоваться.
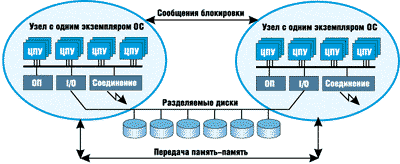
Рисунок 2.
Кластер с отражением памяти (RMC) с двумя SMP-узлами.
RMC-системы быстрее традиционных систем с передачей сообщений по сетям, так как, если связь однажды была установлена, сообщение может быть передано без вмешательства операционной системы. Копирование память-память здесь аналогично соединениям между МРР-узлами и выполняет те же функции. Примерами такого типа технологии являются Scalable Data Interconnect (SDI) компании Sequent, Memory Channel on the TruCluster (DEC) и ServerNet (Tandem).
Таким образом, сегодня существует несколько различных архитектур: RMC, MPP, CC-NUMA и COMA (о двух последних речь пойдет далее), для которых характерен доступ к неоднородной памяти и, следовательно, применим термин "NUMA". Однако, все эти архитектуры принципиально различны. RMC- и MPP-системы содержат множество узлов и их принадлежность к NUMA заключается в программно-реализованной когерентности между узлами. В CC-NUMA и СОМА когерентность реализована аппаратно и является внутриузловой.
Почему RMC можно рассматривать как реализацию NUMA? Дело в том, что, если узел запрашивает некоторые данные из своей памяти, задержка получается достаточно маленькой. Если тот же узел запрашивает данные, которые должны быть переданы или скопированы из памяти другого узла, с использованием аппаратных или программных средств для передачи сообщений, то задержка получается существенно большей. Поэтому, в широком смысле, мы имеем доступ к неоднородной памяти. Однако копирование памяти в RMC-системах использует когерентность с программной поддержкой, так как каждый из узлов имеет свою копию ОС и свою карту памяти. Это и отличает RMC систему NUMA от узла CC-NUMA, где одна память делится между процессорами внутри узла и аппаратно поддерживается когерентность кэшей. В таблице 1 приведена классификация различных архитектур.
Таблица 1.
Компьютерные архитектуры.
|
|
|
|
|||
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|||
|
|
|
||||
Если обратиться к истории, то первой NUMA-системой была машина Butterfly, разработанная BBN в 1981 году. Первой действующей системой с архитектурой СС-NUMA стала Stanford DASH. Группа, работавшая с ней, использовала возможность изучить функционирование операционной системы SGI IRIX на 32-процессорном узле CC-NUMA в 1992 году. Сегодня Стенфордская группа развивает новую версию DASH, получившую название FLASH. Одной из задач FLASH является интеграция в единую архитектуру SMP модели с кэш-когерентной разделяемой памятью и МРР модели с программно-реализованной кэш-когерентностью.
5. Аппаратная реализация когерентности кэшей
CC-NUMA - это кэш-когерентный доступ к неоднородной памяти. В системе CC-NUMA физически распределенная память объединяется, как в любой другой SMP-архитектуре, в единый массив. Не происходит никакого копирования страниц или данных между ячейками памяти. Нет никакой программно-реализованной передачи сообщений. Существует просто одна карта памяти, с частями, физически связанными медным кабелем, и очень умные (в большей степени, чем объединительная плата) аппаратные средства. Аппаратно-реализованная кэш-когерентность означает, что не требуется какого-либо программного обеспечения для сохранения множества копий обновленных данных или для передачи их между множеством экземпляров ОС и приложений. Со всем этим справляется аппаратный уровень точно так же, как в любом SMP-узле, с одной копией ОС и несколькими процессорами.
COMA или Cache-Only Memory Architecture - это архитектура, конкурирующая c СС-NUMA, спроектированная с аналогичными целями, но имеющая другую реализацию. Вместо того чтобы распределять части памяти и поддерживать их когерентность, как это делается в CC-NUMA, COMA-узел не имеет памяти, а только большие кэши (называемые attraction memories) в каждом обрабатывающем блоке - кводе (quad). Для значений данных нет "домашних" ячеек памяти, в узле работает одна общая для всех кводов копия ОС, а когерентность в узле поддерживается специальным аппаратным соединением. Аппаратные средства COMA способны компенсировать недостатки алгоритмов ОС по распределению памяти и диспетчеризации. Однако для COMA требуется внесение изменений в подсистему виртуальной памяти ОС и заказные платы памяти дополнительно к плате кэш-когерентного соединения.
6. NUMA-Q - реализация компанией Sequent архитектуры CC-NUMA
Элементарным блоком платформы NUMA-Q служит квод (NUMA-Q означает CC-NUMA с кводами), в котором объединены четыре процессора, блок разделяемой памяти и шина PCI с семью слотами. Несколько кводов могут быть соединены связями с аппаратно-реализованной кэш-когерентностью для формирования более крупного одиночного SMP-узла таким же образом, как процессорные платы добавляются к объединительной плате обычного SMP-узла с большой шиной.
Sequent рассматривает архитектуру NUMA-Q, как магистральную линию развития в будущем больших SMP-узлов, которая позволит преодолеть присущее SMP-платформам на основе общей шины ограничение в 32 процессора на узел и повысить возможности масштабирования систем SMP на порядок. Наиболее известную альтернативу традиционному подходу представляет аппаратно-реализованная кэш-когерентность на основе каталога. Специалисты Sequent пришли к заключению, что наилучшим вариантом является архитектура с кэш-когерентностью и неоднородной памятью, базирующейся на стандартизованном подходе SCI.
Квод NUMA-Q может быть единственным обрабатывающим элементом в системе. В этом случае сам квод является ее узлом. Если же система содержит несколько кводов, она все еще будет одноузловой, в ней со всеми кводами станет работать только одна копия ОС, и здесь квод уже не узел.
Кэш-когерентное соединение устанавливается между кводами и называется IQ-Link - это полностью аппаратное соединение, которое практически прозрачно для программ подобно обычному кэшу. Различие между SMP-узлом с объединительной платой и NUMA-Q-узлом с множеством кводов заключается в том, что соединение в системе NUMA-Q снимает ограничения одной объединительной платы и позволяет строить очень большие узлы с SMP подобной архитектурой. Резкое повышение масштабируемости достигается за счет того, что 12 процессорных блоков не устанавливаются на единую общую плату, а объединяются в группы - кводы, и между этими группами и памятью вставляются медные перемычки. IQ-Link поддерживает кэш-когерентность так же, как это делает объединительная плата SMP.
Системы с большими шинами проектировались для увеличения пропускной способности, но не снимали проблемы задержек. Используя короткие шины внутри каждого квода, можно достичь очень малых задержек для большинства операций доступа к памяти. Таким образом, IQ-Link позволяет построить большие системы с множеством коротких шин и малыми задержками.
Преимущества аппаратной поддержки когерентности проявляются, в частности, в том, что следующий уровень развития - кластерные системы из узлов NUMA-Q могут использовать то же программное обеспечение кластеризации, что и SMP-кластеры с общей шиной. В качестве среды для передачи данных между узлами NUMA-Q планируется волоконно-оптический канал и программное обеспечение системы Symmetry 5000 (ptx/SDI и Ptx/Clusters). Может возникнуть вопрос, зачем вообще нужно строить кластеры с NUMA-Q-узлами, если вместо этого можно построить очень большие узлы NUMA-Q. Причины те же, из-за которых кластеры применялись и ранее: надежность и масштабируемость.
7. Задержка - как основная характеристика различия архитектур
Одним их ключевых различий описанных архитектур является диктуемая ими модель программирования, а различия в способах программирования напрямую обусловлены задержками доступа. Достижение организации памяти NUMA-Q заключается в том, что доступ к часто используемым данным происходит за микросекунды, тогда как считывание их с диска требует миллисекунд, а в МРР-системах с разделяемыми дисками доступ к удаленному диску может занимать десятки миллисекунд. В кластерах с отражением памяти между узлами добавляются когерентные соединения с программной поддержкой, в результате чего время доступа к удаленной памяти снижается до сотни микросекунд. Это, конечно, в сотни раз быстрее, чем обращаться к дискам для тех же данных, но сотни микросекунд - это все еще в сотни раз медленнее, чем скорость локальной памяти. Поэтому программист должен позаботиться о том, чтобы минимизировать такого типа пересылки, планируя для этого, где только возможно, распределение данных вручную. Следует отметить, что даже в RMC удаленный доступ опирается как на аппаратную, так и на программную поддержку, тогда как доступ к локальной памяти реализуется исключительно аппаратными средствами - очень быстро и с гарантией когерентности. Вот почему программирование в SMP так выгодно для прикладных программистов, которые не должны заботиться о распределении данных в памяти, так как все ее части доступны для любого ЦПУ и доступ к ним одинаково быстр.
В реализации NUMA-Q в этом направлении был сделан еще один шаг. В самом худшем случае время доступа к памяти приблизительно такое же, как в архитектурах с большой шиной. В большинстве же случаев доступ будет в десять раз быстрее. Кроме того, уже 32-процессорная система NUMA-Q будет иметь большую пропускную способность памяти, чем любая другая современная SMP архитектура. Хотя производители "Гига-шины", возлагают большие надежды на шины с 256-битной шириной и пропускной способностью от 1 до 3 Гбайт/с, по-видимому, сейчас это верхний предел.
На рисунке 3приведена диаграмма задержек доступа для разных архитектур в логарифмической шкале. Интересно перевести эти времена из микросекунд в более привычный диапазон. Если микросекундная задержка доступа в памяти системы NUMA-Q была бы такая же, как ожидание реакции ПК в течение одной секунды, то RMC заставил бы ждать две-три минуты, доступ к диску занял бы три часа, а доступ к удаленному диску - от 6 до 12 часов.
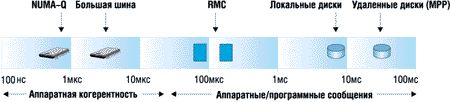
Рисунок 3.
Логарифмическая шкала, показывающая относительные задержки доступов
к памяти.
8. Порядок работы NUMA-Q
В качестве основного строительного блока для SMP-узлов платформы NUMA-Q компания Sequent использует кводы с четырьмя процессорами на блок распределенной памяти. В узле с тремя, например, кводами одна треть физической памяти будет близка (в смысле задержки доступа к памяти) к четырем процессорам квода, а две трети будут "не совсем близкими". Это может привести к выводу о том, что две трети обращений к памяти будут медленными и только одна треть - быстрой. К счастью, без модификации приложений, реализованных для традиционных SMP-архитектур, этого не происходит. В действительности основная часть процессорных доступов к памяти будет очень быстрой, и только маленький процент окажется не столь высокоскоростным. Это происходит из-за большой локальной памяти квода и большого удаленного кэша на плате IQ-Link.
8.1. Конфигурация памяти NUMA-Q
В традиционном смысле память в каждом кводе не является локальной. Скорее, это одна треть адресного пространства физической памяти, которая имеет собственный адресный диапазон. Адресная карта распределяется по памяти равномерно, при этом каждый квод содержит смежную часть адресного пространства. В примере из рисунка 4 квод 0 имеет физические адреса 0-1 Гбайт, квод 1 - 1-2 Гбайт и квод 3 - адреса 2-3 Гбайт. Как и в любой SMP-системе, работает только одна копия ОС, она размещает в памяти и запускает одновременно на одном или нескольких процессорах любые процессы без какого-либо различия между ними.
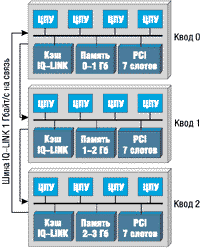
Рисунок 4.
NUMA-Q-узел с тремя кводами и шиной IQ-Link.
Далее будем называть сегмент памяти, расположенный в кводе, локальной памятью квода, а память из других кводов удаленной памятью квода. Ясно, что доступ к локальной памяти квода происходит быстрее, чем доступ к удаленной для него памяти. Задержки доступа к единому пространству адресов памяти не одинаковы, вот почему NUMA-Q является истинной NUMA-архитектурой.
В современной реализации архитектуры NUMA-Q компания Sequent использует процессоры Pentium Pro с двумя кэшами L1 и L2 внутри чипа. Как известно, в компьютерных системах кэши устанавливаются в предположении о "пространственной локальности" обращений к памяти. В соответствии с этим предположением основная часть всех кэш-промахов (cashe miss) в L2 будет попадать в диапазон локальной памяти квода и, таким образом, будет быстро обслуживаться. Если же адрес находится за пределами диапазона локальной памяти квода, поиск будет распространен на 32 мегабайтный кэш IQ-Link, который называется удаленным кэшем. Доступ к этому кэшу осуществляется с такой же скоростью, как и к локальной памяти квода. Если и в IQ-Link кэше данные не найдены, то для их получения отсылается запрос на шину IQ-Link. После того как требуемое значение загружено из другого квода, оно сохраняется в удаленном кэше платы IQ-Link запрашивающего квода, но не сохраняется в памяти этого квода. Последнее можно сделать только программно, явно скопировав одну часть памяти в другую.
Интервал времени с момента, когда Pentium Pro не находит нужные данные в своем внутреннем L2 кэше, до момента, когда данные возвращены этому Pentium Pro и он сможет их использовать, составляет около 3,3 микросекунд. Эта задержка практически равна той, которая наблюдается при кэш-промахах в традиционных архитектурах с большой шиной и одной объединительной платой, однако в NUMA-Q такая ситуация возникает значительно реже.
8.2. Кэш-когерентность в NUMA-Q
Передача данных по единственной шине в SMP-архитектурах с одной объединительной платой может происходить по разным причинам, и их следует различать. Во-первых, это передача между портом ввода-вывода и памятью, и, во-вторых, ситуации, в которых процессор обращается к памяти при отсутствии данных в L2 кэше. Кроме того, имеются еще и передачи кэш-кэш между разными процессорами, которые называются промахами когерентности.
Недостатком архитектур с большой шиной является то, что для поддержания когерентности нужно, чтобы все кэши следили за всеми пересылками, что и реализуется в протоколе слежения за шиной. При конструировании более быстрой шины можно либо уменьшить ее длину, либо уменьшить нагрузку на отдельную шину, например, продублировав ее. Как уже говорилось, некоторые производители пошли по второму пути, добавив отдельные шины ввода-вывода и двухпортовую память. Однако такой подход не позволяет получить удвоенную пропускную способность шин: в этих конфигурациях возникает большой поток когерентной активности, на который расходуется пропускная способность обеих шин и увеличивается средняя задержка.
Компания Sequent сделала попытку отделить в системе NUMA-Q промахи когерентности от передач данных, связанных с вводом-выводом и обменами процессор-память. В примененном подходе трафик процессор-память и трафик ввода-вывода могут идти одновременно на нескольких шинах производительностью 500 Мбайт/с, а в то же время шина IQ-Link осуществляет слежение за всеми шинами процессор-память и гарантирует когерентность данных между ними. Пропускная способность когерентной шины IQ-Link уже доведена до 1 Гбайт/с на связь. Пропускная способность шин ЦПУ-память и ввод-вывод - 500 Мбайт/с на каждый квод. С добавлением большего числа кводов увеличивается и интегральная пропускная способность.
В системе с восемью кводами (32 процессора) пропускная способность ЦПУ-память в восемь раз больше - 4 Гбайт/с. С двумя PCI-шинами в каждом кводе теоретически можно поддерживать пропускную способность шины ввода-вывода 2 Гбайт/с. Пропускная способность IQ-Link остается равной 1 Гбайт/с на связь, так как она подсоединяется ко всем восьми кводам. Однако большая часть ее трафика будет вызвана промахами когерентности и в меньшей степени подгрузкой из удаленной памяти, обслуживанием ввода-вывода и пр. Очень важна способность подсистем ввода-вывода работать централизованно, но при этом оставаться доступными из любого квода. Ценно и то, что трафик ввода-вывода проходит мимо IQ-Link.
При сравнении пропускной способности шины IQ-Link с обычными архитектурами следует суммировать производительность всех 500 Мбайт/с шин кводов, поскольку именно эти шины поддерживают весь трафик, присущий любым SMP-системам. Было бы неправильно сравнивать только шину IQ-Link с обычной большой шиной, так как основная часть трафика IQ-Link вызвана промахами когерентности. NUMA-Q-архитектура разработана для того, чтобы поддерживать до 63 кводов с одной копией ОС, и это означает, что теоретический максимум пропускной способности для ввода-вывода и подгрузки в кэши составляет 32 Гбайт/с (63*500 Мбайт/с). Для сравнения, скорости современных одиночных объединительных плат находятся в диапазоне от 240 Мбайт/с до 1,6 Гбайт/с. В системах с несколькими кводами связи IQ-Link образуют кольцо прямых точечных соединений. Имеющиеся данные позволяют сделать вывод, что такое кольцеобразное соединение множества звеньев с производительностью 1 Гбайт/с каждое будет иметь суммарную пропускную способность 1,6 Гбайт/с.
8.3. Нужно ли оптимизировать программы для NUMA-Q?
Эффективность работы приложения на платформе NUMA-Q зависит, главным образом, от того, насколько справедливы следующие предположения.
- Частота обращений к удаленной памяти существенно ниже, чем частота локальных обращений.
- Задержка удаленного доступа очень мала.
- Пропускная способность IQ-Link намного больше, чем та, которая требуется в приложениях OLTP и DSS.
Что должны делать разработчики программного обеспечения для систем SMP при переносе его на NUMA-Q? Если некоторые из приведенных пунктов неверны, можно попытаться изменить программное обеспечение, чтобы настроить его на NUMA-Q. Однако если предположения выполняются, тогда тот факт, что малый процент доступов занимает больше времени, чем остальные, может не учитываться программистами так же, как не принимается во внимание работа кэшей. Конечно, приспосабливаясь к архитектуре NUMA-Q, можно достичь некоторого роста производительности приложения, но он будет небольшим. Важно, однако, то, что большинство потенциальных системных характеристик будут улучшаться на NUMA-Q без изменения программного обеспечения SMP-приложений.
В ходе разработки соединения IQ-Link, компания Sequent провела тщательное тестирование с целью исследования рабочих характеристик приложений для СУБД Oracle и Informix. Тестирование показало, что эти приложения действительно демонстрируют хорошую пространственную локализацию кода и данных. В узле с восемью кводами, на котором производилось тестирование, более 51% L2 кэш-промахов разрешались в локальной памяти кводов, еще 30% приходились на 32 мегабайтный удаленный кэш в IQ-Link, и только 19% L2 кэш-промахов требовали доступа к удаленной памяти. Это свидетельствует о справедливости первого из вышеуказанных пунктов.
8.4. Задержки доступа к памяти в системе NUMA-Q
Какие задержки характерны для доступа к памяти в архитектурах NUMA-Q? В традиционных SMP-архитектурах с одной объединительной платой и большой шиной средняя задержка доступа к памяти составляет около двух микросекунд. В некоторой степени она еще сглаживается благодаря большим (2 Мбайт) L2 кэшам, но тем не менее играет существенную роль в формировании полной производительности узла. Причина того, что задержка значительно больше, чем время доступа в DRAMS (около 60 нс), заключается в том, что запрос должен пройти через обработку промахов в L2 кэше на процессорной плате, запросить доступ к шине объединительной платы, выйти на эту шину, попасть в очередь для доступа к плате памяти и в конце концов вернуться с данными.
В узле NUMA-Q доступ к локальной памяти квода приблизительно в десять раз быстрее, чем доступ к памяти в SMP-узле с одной объединительной платой. Это происходит по следующим причинам: 1) память расположена близко к процессорам, 2) есть только четыре процессора, 3) нет объединительной платы между процессорами и локальной памятью квода, 4) шина между процессорами и памятью может работать с очень высокой скоростью. Задержка локальной памяти квода может не превышать 180 нс c момента обнаружения отсутствия данных в L2 кэше и до засылки данных в процессор.
Следующая задержка - от 32 мегабайтного удаленного кэша IQ-Link, который является первым местом поиска данных, чьи адреса не попадают в диапазон локальной памяти квода. Доступ к этому удаленному кэшу происходит одновременно и с той же задержкой, что и у локальной памяти квода. Таким образом, дополнительные 32 Мбайт памяти удаленного кэша также в десять раз быстрее, чем память в архитектурах с одной объединительной платой и большой шиной.
И наконец, следует рассмотреть задержки доступа к удаленной памяти квода. Здесь требуется разобраться, во-первых, с величиной минимальной задержки, во-вторых, с факторами, которые вносят вклад в максимальную задержку, и, в-третьих, с частотой разных задержек. Минимальная задержка в восьмикводовой системе составляет 3,3 микросекунды, от момента обнаружения отсутствия данных в процессорном кэше L2 до того, как данные вернутся к процессору. Вся доставка данных происходит почти так же быстро, как доступ к памяти в SMP-системах с большой шиной, однако рассматриваемая ситуация возникает значительно реже из-за наличия 512 Мбайт - 4 Гбайт локальной памяти квода и 32 Мбайт удаленного кэша в каждом соединении IQ-Link. Для сравнения можно напомнить, что типичный процессорный кэш систем с большой шиной имеет объем 2-4 Мбайт.
Если все суммировать и принять во внимание коэффициент попаданий кэша, то средняя задержка в современном SMP-узле системы с большой шиной равняется 1-4 микросекундам, тогда как то же программное обеспечение на узле NUMA-Q, без всяких изменений, приводило бы к средней задержке 1-2,5 микросекунды. Это одна из причин, почему поставщики приложений не должны изменять свое программное обеспечение SMP, чтобы получить максимальную производительность от систем NUMA-Q: общий эффект задержки доступа к удаленной памяти квода действительно очень мал.
8.5. Пропускная способность шины IQ-Link
По оценкам разработчиков, если система из одного узла с 32 процессорами обрабатывает от 20 до 25 тыс. транзакций в минуту, то IQ-Link не будет загружена даже на 30% своих возможностей. Это является следствием эффективности протокола когерентности, хорошей пространственной локализации в современных приложениях и, конечно, очень большой пропускной способности IQ-Link. Компания Sequent рассчитывает, что 32-процессорный узел NUMA-Q в три раза повысит существующий предел производительности. Если разработчики приложений произведут их настройку на NUMA-Q, они смогут дополнительно получить еще 20% производительности.
В IQ-Link встроено много интеллектуальных способностей. Она способна следить за локализацией всех данных, которые были вытеснены из ее собственного квода, а также за данными, размещенными в 32 мегабайтном удаленном кэше. IQ-Link следит за шиной Pentium Pro и одновременно использует протокол поддержки когерентности на основе каталога, чтобы отслеживать все запросы и ответы на них, проходящие по шине IQ-Link.
Заключение
Определяющим фактором для производительности систем являются задержки доступа к данным. Для уменьшения их влияния в системы вводится дополнительная память. SMP-платформы обеспечили легко программируемую модель, так как время доступа ко всем частям памяти стало одинаково недолгим. Попытки распределять данные между узлами, передавая их между памятью, успешны только в том случае, если альтернативой является обращение за данными к диску. Однако для оптимизации производительности все еще требуется существенный объем перепрограммирования, так как задержки между узлами значительно больше, чем задержки внутри узла.
Наиболее эффективный способ достичь высокой производительности и сохранить при этом простую модель программирования - построить как можно больший одиночный узел, прежде чем переходить к архитектуре из нескольких узлов. Однако из-за ограничений на размер объединительных плат и системных шин, с использованием кэша слежения этого сделать нельзя, и максимально достигнутое число процессоров не превышает сегодня 32. Для того чтобы выйти за этот предел можно использовать кэш-протоколы на основе каталогов и архитектуры CC-NUMA. Такой подход имеет дополнительные достоинства, так как позволяет подсоединять до 252 процессоров, получая огромную память и пропускную способность шины ввода-вывода и при этом имея средние задержки доступа к памяти меньше, чем у любой современной системы. Основным же достижением является отсутствие необходимости менять программное обеспечение SMP-приложений для того, чтобы воспользоваться всеми этими возможностями.
Компания Sequent начала коммерческий выпуск SMP-систем на базе Unix еще в 1983 году, и сегодня многие фирмы-поставщики предлагаюттакие платформы. Сейчас Sequent опять первой прокладывает путь для следующего шага от SMP с большими шинами к NUMA-Q SMP-архитектурам. Возможно, что когда-нибудь все высокопроизводительные серверы будут строиться с использованием этой архитектуры.
